
Caratteristiche della REST API spiegate (con gli errori più comuni)
Ogni volta che sincronizzi il tuo CRM, scarichi aggiornamenti sulle spedizioni o colleghi due strumenti SaaS, è una REST API a fare il lavoro pesante dietro le quinte. La maggior parte delle persone non ci pensa mai, finché qualcosa non smette di funzionare.
Ecco l’aspetto curioso: anche tra gli sviluppatori c’è parecchia confusione su cosa renda davvero un’API "RESTful". Il termine viene usato con troppa leggerezza, al punto che in un thread su Reddit qualcuno l’ha detto senza mezzi termini: "Non credo di aver mai costruito una singola API davvero RESTful secondo la definizione di Roy Fielding." E stiamo parlando di uno sviluppatore, non di un responsabile business. Il concetto nasce nella di Roy Fielding alla UC Irvine, dove REST viene descritto come uno stile architetturale — cioè un insieme di vincoli progettuali — non un protocollo, non un prodotto, non una specifica da scaricare. Eppure, secondo il , l’uso di REST arriva al 93% tra i professionisti delle API. Quindi quasi tutti lo usano, ma sorprendentemente molti team non sanno davvero cosa comporti. Questo articolo passa in rassegna le 6 caratteristiche fondamentali di una REST API in modo semplice, mostra quali vengono più spesso implementate male, introduce un modello di maturità per autovalutarti e confronta REST con le alternative: SOAP, GraphQL e gRPC.
Cos’è una REST API? (Definizione in parole semplici)
REST (Representational State Transfer) è un insieme di regole di progettazione che definiscono come i sistemi software dovrebbero comunicare su una rete.
Più precisamente, è uno stile architetturale che stabilisce vincoli — come l’assenza di stato, la cacheabilità e un’interfaccia uniforme — e guida il modo in cui i client (il browser, l’app mobile o uno strumento di automazione) interagiscono con i server (dove risiedono i dati). REST di solito gira su HTTP e restituisce in genere JSON, ma REST in sé non è legato a un protocollo o a un formato dati specifico.
Pensalo come al galateo di una cena. REST non dice quali piatti servire o in che lingua parlare: definisce come passarsi i piatti, come chiedere il bis e come segnalare che hai finito. Due sistemi che seguono lo stesso galateo possono comunicare in modo prevedibile, anche se non si sono mai incontrati.
Cosa NON è REST: REST non è un prodotto da installare. Non è un protocollo come HTTP o SOAP. E chiamare un’API "RESTful" non significa che rispetti in pieno i vincoli originali di Fielding: di solito vuol dire solo che l’API usa URL delle risorse e metodi HTTP. Il divario tra "quasi REST" e "davvero RESTful" è una delle principali fonti di confusione nel settore, e lo vedremo meglio tra poco.
Le 6 caratteristiche di una REST API in sintesi
Prima di entrare nel dettaglio, ecco una sintesi rapida. Fielding definì 6 vincoli che un’API dovrebbe seguire per essere considerata RESTful. Cinque sono obbligatori; uno è opzionale.
This paragraph contains content that cannot be parsed and has been skipped.
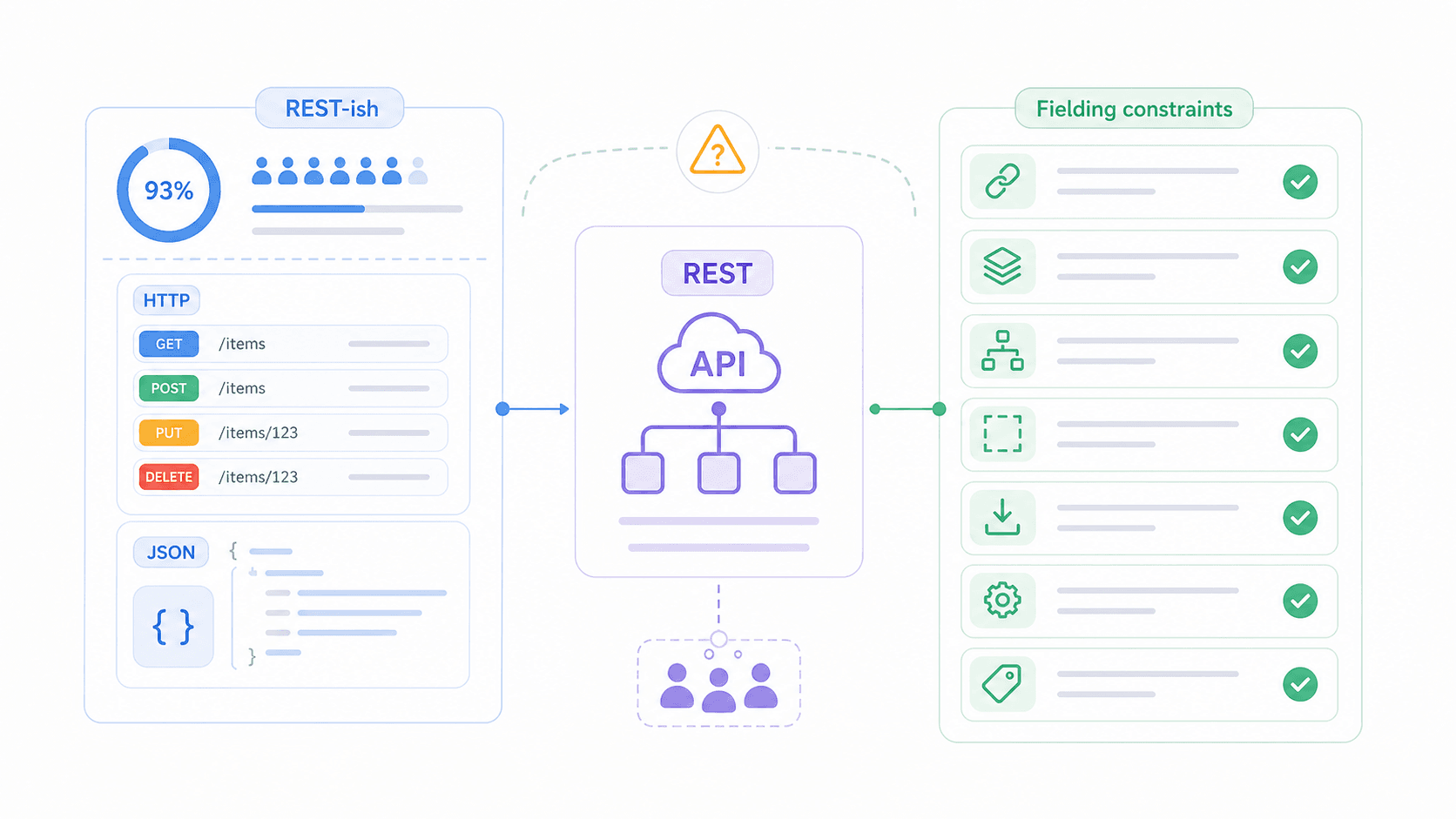
Per capire come questi vincoli lavorano insieme in un sistema reale, immagina questa architettura a strati:
1Client / App mobile
2 ↓
3CDN / Cache di edge (ad es. Cloudflare)
4 ↓
5API Gateway (rate limiting, autenticazione, CORS)
6 ↓
7Load Balancer
8 ↓
9Server applicativi
10 ↓
11Database / Servizi interniIl client parla solo con il livello CDN. Non ha idea di quanti strati ci siano dietro. Questo è il vincolo del sistema a strati in azione — ed è anche il punto in cui avvengono sicurezza, caching e scaling senza che il client debba saperlo.
Ora entriamo nel dettaglio.
Le caratteristiche della REST API spiegate una per una
Separazione client-server
Il primo vincolo di Fielding: il client (ciò con cui interagiscono gli utenti) e il server (dove vivono i dati e gira la logica) devono essere separati. Lui la chiamava separazione delle responsabilità.
Perché è importante nella pratica? Perché significa che un’app di mobile banking può rinnovare completamente l’interfaccia senza che la banca tocchi il database dei conti o il motore delle transazioni. La , per esempio, espone contatti, campagne, journey e notifiche push tramite endpoint di risorse. Che tu stia costruendo una dashboard personalizzata, un’app mobile o un’integrazione con uno strumento di terze parti, il back end resta lo stesso.
Per i team business, questo si traduce in iterazioni più rapide. I designer del front end e gli ingegneri del back end non devono seguire lo stesso ciclo di rilascio. Finché il contratto dell’API resta stabile, le due parti possono muoversi in modo indipendente.
Assenza di stato
Nessuna memoria tra una richiesta e l’altra. Ogni chiamata dal client al server deve includere tutte le informazioni necessarie per essere elaborata: il server non conserva nulla delle interazioni precedenti.
Mi piace pensarla come una chiamata all’assistenza, dove devi rispiegare il problema ogni volta. Fastidioso? Certo. Ma il vantaggio è enorme: qualsiasi operatore disponibile può aiutarti, e il call center può aggiungere altri 500 operatori senza riprogettare tutto. Questa è la scalabilità orizzontale.
In termini tecnici, l’assenza di stato significa niente sticky session. Un load balancer può indirizzare la richiesta successiva verso qualsiasi server sano. Se un server va in crash, un altro prende il suo posto senza perdere un colpo. La tesi di Fielding che l’assenza di stato migliora la visibilità (gli strumenti di monitoraggio possono comprendere ogni richiesta in modo isolato), l’affidabilità (i guasti non corrompono lo stato di sessione condiviso) e la scalabilità (i server possono liberare risorse tra una richiesta e l’altra).
La precisazione pratica: i sistemi reali hanno comunque token di autenticazione, carrelli della spesa e flussi OAuth. Il punto non è che non esista alcuno stato da nessuna parte: è che il server non memorizza nella propria memoria lo stato di sessione del client tra una richiesta e l’altra. A questo servono invece token, database e cache condivise.
Cacheabilità
Questa risposta può essere riutilizzata? È la domanda a cui risponde la cacheabilità. Le risposte dovrebbero dichiarare esplicitamente se possono essere memorizzate in cache e, in caso affermativo, client e intermediari (come le CDN) le riutilizzano per richieste future equivalenti, riducendo il carico sul server e migliorando la velocità.
Il meccanismo HTTP è semplice: header come Cache-Control, ETag, Last-Modified ed Expires dicono alle cache per quanto tempo una risposta è valida e quando ricontrollarla. Per un lettore business, pensalo come un’etichetta sulla risposta che dice "questa risposta vale per la prossima ora" oppure "chiedimi sempre una versione aggiornata".
L’impatto sulle prestazioni è reale. I test della hanno registrato un miglioramento di 50–100 ms nei tempi di risposta della cache sul tail. E la stessa tesi di Fielding documenta come il traffico Web sia passato da 100.000 richieste/giorno nel 1994 a 600.000.000 richieste/giorno nel 1999, con il caching come fattore di progettazione critico.
Tipicamente cacheabili: cataloghi prodotti, contenuti pubblici di blog, elenchi di paesi/valute, documentazione API.
Tipicamente non cacheabili: dashboard personali, totali del checkout, saldi bancari, report amministrativi.
Interfaccia uniforme
È il vincolo che Fielding stesso definì la caratteristica centrale che distingue REST dagli altri stili architetturali. Standardizza il modo in cui i client interagiscono con le risorse, rendendo le API prevedibili.
Dentro questo principio ci sono quattro sotto-vincoli:
- Identificazione delle risorse: ogni risorsa ha un URI stabile.
/customers/123è un cliente./orders/456è un ordine. - Manipolazione tramite rappresentazioni: i client lavorano con rappresentazioni delle risorse (JSON, XML, HTML), non con gli oggetti interni del server.
- Messaggi auto-descrittivi: richieste e risposte contengono abbastanza metadati — metodo, codice di stato, tipo di contenuto, dettagli dell’errore — perché qualsiasi intermediario o client possa capirli.
- HATEOAS (Hypermedia as the Engine of Application State): le risposte includono link ad azioni e risorse correlate, così i client possono capire cosa fare dopo senza dover codificare a mano ogni endpoint.
La mappatura dei metodi HTTP è la parte più visibile dell’interfaccia uniforme:
This paragraph contains content that cannot be parsed and has been skipped.
Le affermano esplicitamente che GET deve essere sicuro, e che GET, PUT e DELETE devono essere idempotenti. API note come quelle di GitHub, Stripe e Spotify seguono molto da vicino questi schemi, ed è per questo che chi ne impara una può capire rapidamente le altre.
Sistema a strati
Il tuo client non sa se sta parlando con il server origin, una cache CDN, un API gateway o un load balancer. Ed è proprio questo il punto: ogni componente vede solo il livello adiacente.
Questo è ciò che consente:
- CDN come Cloudflare davanti alla tua API per memorizzare in cache e velocizzare le risposte
- API gateway (AWS API Gateway, Kong, Apigee) per gestire autenticazione, rate limiting e quote
- Load balancer per distribuire le richieste stateless su più server applicativi
Il osserva che il usa AWS API Gateway, il 26% usa il gateway di Azure e il 31% usa più gateway contemporaneamente. L’architettura a strati non è teorica: è così che funzionano davvero i sistemi in produzione.
Il compromesso è che ogni livello aggiunge un po’ di latenza. Ma Fielding sosteneva che il caching condiviso nei livelli intermedi compensa ampiamente questo sovraccarico nella maggior parte dei sistemi reali.
Code-on-Demand (opzionale)
Questa è l’eccezione. Code-on-Demand è l’unico vincolo REST opzionale: il server può inviare codice eseguibile — come JavaScript — per estendere al volo le funzionalità del client.
L’esempio reale più comune è semplicemente una pagina web che carica JavaScript da un server. Ma per le tipiche API REST JSON consumate da app mobile, processi backend o strumenti di automazione, il code-on-demand non viene quasi mai usato. In generale, i client API non vogliono eseguire codice arbitrario proveniente da un server remoto.
Per la maggior parte dei lettori, questo vincolo è una nota a margine. Esiste nel modello di Fielding per completezza, ma non peserà nelle tue valutazioni quotidiane delle API.
Cosa sbaglia la maggior parte delle persone: le REST API sono davvero RESTful?
Ecco la parte di cui nessuno vuole parlare: la maggior parte delle API in produzione che si definiscono "RESTful" sono in realtà API HTTP JSON con convenzioni più o meno REST. Usano URL delle risorse, metodi HTTP e codici di stato — e poco altro. Un thread su Reddit in r/softwarearchitecture mostrava sviluppatori che ammettevano di non aver mai costruito una REST API davvero conforme a Fielding. Un’altra discussione in r/learnprogramming degenerava in dibattiti su se qualcuno riesca davvero a mettersi d’accordo su cosa significhi "RESTful".
Uno studio del 2026 che ha intervistato 16 esperti di REST API ha rilevato che, sebbene le linee guida migliorino l’usabilità, gli sviluppatori mostrano una forte resistenza alle regole REST più rigide, citando come ostacoli la lunghezza delle linee guida e la scarsa aderenza al contesto della propria organizzazione.
Quindi, nella pratica, dove si collocano davvero i vincoli?
This paragraph contains content that cannot be parsed and has been skipped.
Perché i team saltano HATEOAS: gli sviluppatori lato client preferiscono leggere la documentazione OpenAPI e usare gli SDK piuttosto che seguire dinamicamente i link in runtime. HATEOAS richiede tipi di media stabili, definizioni delle relazioni di link e modellazione dei workflow: il costo iniziale è alto e il vantaggio non è chiaro per la maggior parte dei team.
Il messaggio pragmatico: un’API non deve essere conforme al 100% a Fielding per essere utile. Ma sapere quali vincoli hai saltato — e cosa perdi saltandoli — ti aiuta a prendere decisioni migliori di progettazione e integrazione.
Il Richardson Maturity Model: quanto è davvero RESTful la tua API?
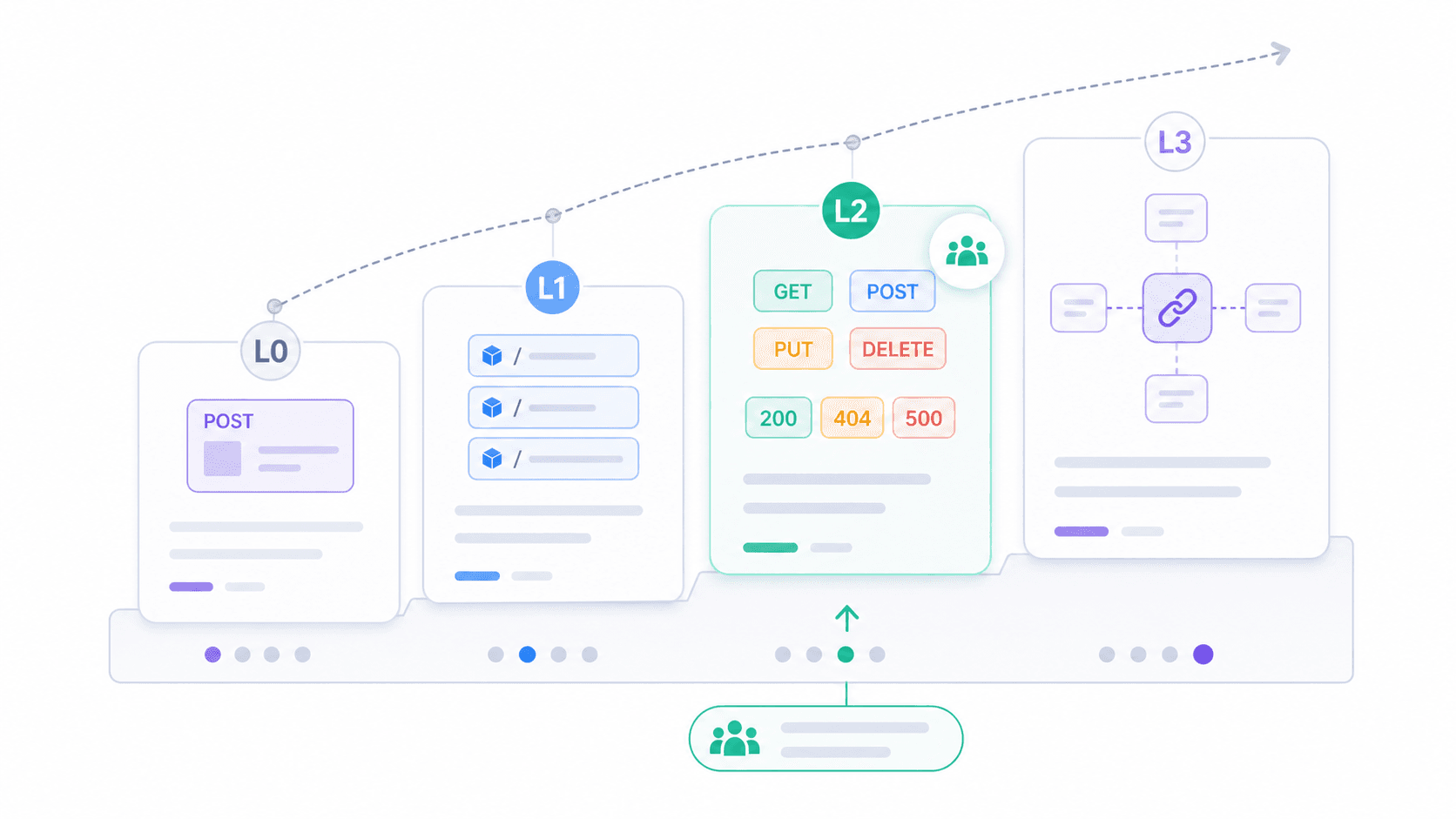
Se la domanda binaria "È RESTful o no?" ti sembra poco utile, il Richardson Maturity Model offre una cornice più pratica. Proposto da Leonard Richardson e , suddivide l’adozione di REST in quattro livelli.
This paragraph contains content that cannot be parsed and has been skipped.
La maggior parte delle API che incontrerai nel mondo reale si colloca al Livello 2. Usano correttamente risorse, verbi e codici di stato. È abbastanza per essere pratiche, interoperabili e ben supportate dagli strumenti. Il Livello 3 è la visione completa di Fielding, ma l’adozione resta limitata.
Dove si colloca la tua API? Chiediti:
- L’API ha un unico endpoint per tutto? (Livello 0)
- Ogni oggetto di business ha il proprio URI? (Livello 1+)
- Metodi HTTP e codici di stato sono usati correttamente? (Livello 2)
- Le risposte dicono al client cosa può fare dopo, senza dipendere da documentazione esterna? (Livello 3)
Questo modello è lo strumento più utile che abbia trovato per superare il dibattito "è REST oppure no?". Sostituisce un giudizio binario con uno spettro.
Errori comuni nelle REST API (e come evitarli)
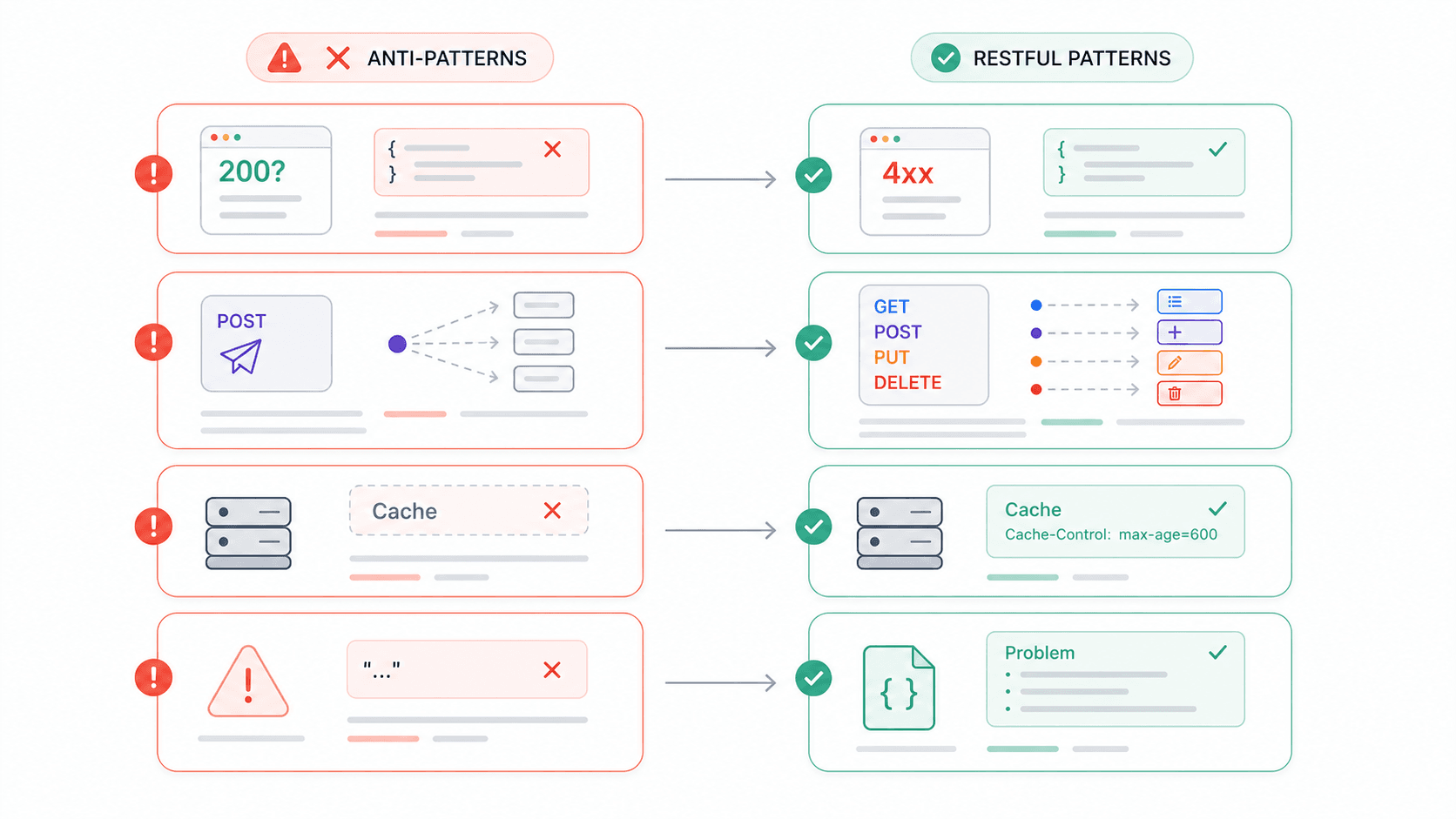
Ho passato abbastanza tempo a integrare API di terze parti da avere un elenco fisso di frustrazioni. E, stando ai forum degli sviluppatori, non sono il solo. Ecco gli anti-pattern che compaiono più spesso — e ognuno corrisponde direttamente alla violazione di un vincolo REST.
This paragraph contains content that cannot be parsed and has been skipped.
Le richiedono codici di stato HTTP ufficiali e raccomandano Problem JSON per le risposte di errore. Le specificano che Problem Detail dovrebbe essere usato solo per 4xx/5xx, mai mescolato con 2xx. Non si tratta di preferenze accademiche: sono standard di produzione di team che gestiscono API su larga scala.
Un thread su Reddit in r/learnprogramming conteneva un developer che chiedeva seriamente se fosse accettabile restituire sempre HTTP 200 anche in caso di errore. Il fatto che questa domanda circoli ancora nel 2026 ti dice quanto siano persistenti questi anti-pattern.
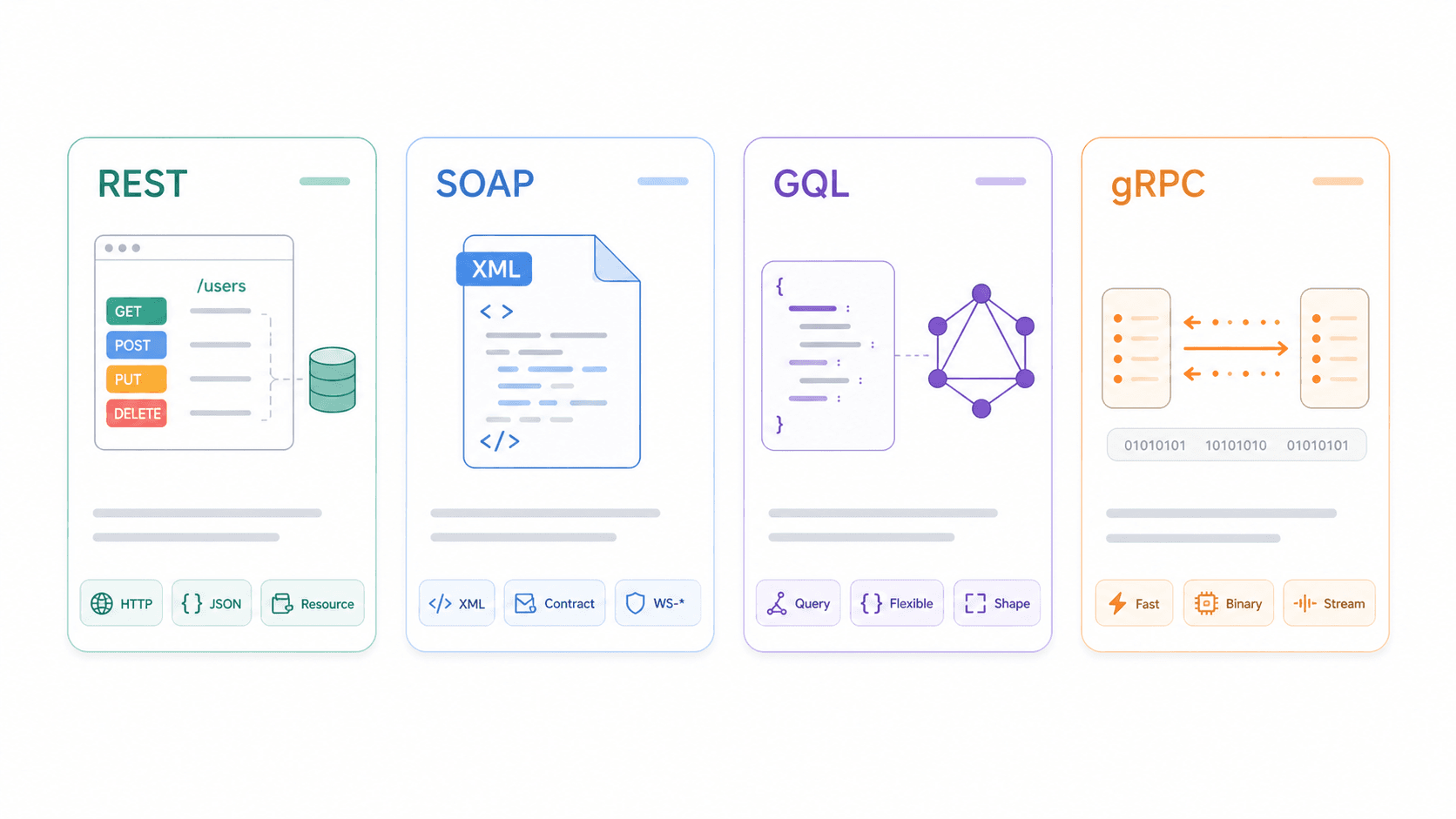
REST vs SOAP vs GraphQL vs gRPC: come si confrontano le caratteristiche delle REST API
Capire REST da solo è utile. Capirlo in rapporto alle alternative è meglio.
| Dimensione | REST | SOAP | GraphQL | gRPC |
|---|---|---|---|---|
| Protocollo / Trasporto | Stile architetturale, di solito HTTP | Protocollo di messaggistica basato su XML; HTTP, SMTP, ecc. | Linguaggio/runtime di query, di solito su HTTP | Framework RPC su HTTP/2 |
| Formato dati | JSON (tipicamente), anche XML/HTML | Solo XML (contratti WSDL) | JSON che corrisponde alla forma della query | Protocol Buffers (binario) |
| Caching | ✅ Cache HTTP nativa se progettato bene | ❌ Complesso; poco adatto alla cache HTTP | ⚠️ Più difficile (POST + endpoint singolo + variazioni della query) | ❌ Non orientato alla cache HTTP |
| Supporto tempo reale | ❌ Polling/webhook | ❌ Pattern di messaggistica enterprise | ✅ Subscription | ✅ Streaming, bassa latenza |
| Curva di apprendimento | Bassa-media | Alta | Media | Media-alta |
| Ideale per | API pubbliche, CRUD, integrazioni web/mobile | Enterprise/legacy, contratti rigidi, compliance | Query complesse, front end flessibili, app mobile | Comunicazione microservizio-microservizio, alte prestazioni interne |
Il raccomanda di scegliere in base a compatibilità, forma dei dati, operazioni e strumenti a disposizione degli utenti.
Quando scegliere cosa:
- REST vince quando ti servono ampia compatibilità, operazioni CRUD semplici e caching HTTP. È la scelta predefinita per API pubbliche e integrazioni web/mobile.
- SOAP ha ancora senso per sistemi enterprise con contratti rigidi, requisiti WS-Security o integrazioni legacy che non spariranno.
- GraphQL eccelle quando il front end ha bisogno di query flessibili e annidate e vuoi evitare over-fetching o under-fetching dei dati — cosa comune nelle app mobile complesse.
- gRPC è pensato per la comunicazione interna tra microservizi, dove latenza bassa e serializzazione binaria contano più della compatibilità con il browser.
Come esempio reale di REST: la usa endpoint POST semplici (/distill e /extract), body JSON per richiesta e risposta, autenticazione con bearer token e codici di stato HTTP standard (400, 401, 402, 408, 422, 429, 500, 502, 503, 504). Mostra le caratteristiche REST in un prodotto AI in produzione senza richiedere contratti SOAP o la complessità di gRPC. Non è una vetrina HATEOAS, ma un’API di Livello 2 pratica, facile da integrare per team business e sviluppatori.
Perché le caratteristiche REST sono importanti per i team business
Sales, Operations, Ecommerce: nessuno di questi team scrive codice API. Ma continuate comunque a scegliere fornitori, collegare strumenti e costruire flussi di automazione — e la qualità di una REST API influisce direttamente su quanto quelle integrazioni siano dolorose o semplici.
Integrazione degli strumenti: quando il tuo CRM si sincronizza con una piattaforma di marketing automation, il design della REST API determina se quella sincronizzazione sarà affidabile o fragile. La gestisce contatti, campagne, journey e notifiche push tramite endpoint di risorse prevedibili. Se questi endpoint seguono le convenzioni REST, il tuo team RevOps può automatizzare senza soluzioni artigianali.
Operazioni ecommerce: le gestiscono ordini evasi, numeri di tracking e stati di spedizione. Le app di spedizione e gli strumenti di fulfillment dipendono da questo livello. Quando l’API è ben progettata — codici di stato corretti, dati di catalogo cacheabili, messaggi di errore chiari — la pipeline logistica scorre senza intoppi. Quando non lo è, compaiono guasti misteriosi alle 2 di notte.
Valutazione dei fornitori: conoscere i 6 vincoli ti dà una checklist pratica:
- L’API usa codici di stato standard o ogni errore sembra un 200 OK?
- Gli errori sono abbastanza specifici da permettere al tuo strumento di automazione di recuperare?
- La documentazione su limiti di velocità, paginazione e autenticazione è chiara?
- Le risposte comuni possono essere messe in cache per ridurre il carico?
Estrazione dati e automazione: strumenti come usano un’architettura basata su REST per consentire agli utenti business di estrarre dati strutturati da siti web, PDF e immagini, per poi esportarli in Google Sheets, Airtable, Notion o Excel. L’ gestisce la complessità dietro un’interfaccia in 2 clic, ma sotto il cofano sono i principi REST — richieste senza stato, risposte JSON, errori standard — a rendere affidabile il livello di integrazione.
Un altro dato da tenere presente: il report Postman 2025 ha rilevato che solo il progetta attivamente le API pensando agli agenti AI, mentre il 51% teme chiamate API non autorizzate o eccessive da parte di agenti AI. Con l’automazione e i workflow guidati dall’AI che diventano standard nei team business, pattern REST prevedibili, chiavi API con privilegi minimi e rate limit non sono più solo questioni da sviluppatori: sono fattori di rischio operativo.
Come Thunderbit applica i principi REST per gli utenti business
Abbiamo costruito partendo dall’idea che la maggior parte dei nostri utenti non avrebbe mai letto una specifica REST — e non dovrebbe farlo. Ma le scelte di design che rendono Thunderbit semplice da usare affondano le radici nelle stesse caratteristiche REST trattate in questo articolo.
Ecco una rapida panoramica di come funziona nella pratica:
- Installa l’estensione Chrome dal e apri qualsiasi sito web, PDF o immagine da cui vuoi estrarre dati.
- Fai clic su "AI Suggest Fields" e l’AI di Thunderbit legge la pagina e propone una tabella strutturata di colonne — nomi prodotto, prezzi, email, qualunque cosa contenga la pagina.
- Modifica le colonne se necessario, poi fai clic su "Scrape." Thunderbit gestisce automaticamente paginazione, sottopagine e contenuti dinamici.
- Esporta i tuoi dati su Google Sheets, Airtable, Notion, CSV o Excel — gratis, senza paywall.
Per sviluppatori e flussi di automazione, la espone /distill (estrazione Markdown pulita) e /extract (estrazione di dati strutturati) come endpoint POST in stile REST con body JSON e codici di errore HTTP standard. In termini di Richardson Maturity Model, è un ottimo Livello 2: risorse, metodi corretti, codici di stato significativi.
Se stai esplorando più in generale web scraping o data extraction, abbiamo scritto guide più approfondite su , e .
Punti chiave
- REST è uno stile architetturale, non un protocollo. Definisce 6 vincoli — client-server, assenza di stato, cacheabilità, interfaccia uniforme, sistema a strati e code-on-demand opzionale — che guidano la progettazione delle API.
- La maggior parte delle API "RESTful" non è completamente RESTful. La maggior parte si ferma al Livello 2 di Richardson (risorse + verbi HTTP + codici di stato). HATEOAS e code-on-demand sono raramente implementati.
- Il Richardson Maturity Model è il miglior strumento di autovalutazione. Sostituisce la domanda binaria "REST o no" con uno spettro pratico (Livelli 0–3).
- Gli errori comuni — 200 OK per gli errori, POST per tutto, header di cache mancanti — sono ancora diffusissimi. Conoscere i vincoli ti aiuta a riconoscere e correggere questi anti-pattern.
- Il confronto REST vs SOAP vs GraphQL vs gRPC non riguarda il "migliore", ma l’adeguatezza. REST domina le API pubbliche e le integrazioni CRUD. GraphQL è adatto a front end complessi. gRPC eccelle nei microservizi interni. SOAP persiste in contesti enterprise/legacy.
- I team business traggono vantaggio dalla comprensione delle caratteristiche REST quando valutano fornitori, collegano strumenti e costruiscono flussi di automazione. Strumenti come applicano i principi REST per rendere l’estrazione dati accessibile senza richiedere competenze tecniche.
FAQ
Quali sono le 6 caratteristiche di una REST API?
I 6 vincoli REST sono: (1) separazione client-server, (2) assenza di stato, (3) cacheabilità, (4) interfaccia uniforme, (5) sistema a strati e (6) code-on-demand (opzionale). I primi cinque sono obbligatori perché un’API sia considerata RESTful secondo la definizione originale di Fielding.
Qual è la differenza tra REST e RESTful?
REST è lo stile architetturale — l’insieme di vincoli progettuali definiti da Roy Fielding. "RESTful" descrive un’API che segue quei vincoli. Nella pratica, molte API etichettate come "RESTful" rispettano solo parzialmente il modello, implementando in genere risorse, metodi HTTP e codici di stato, ma saltando HATEOAS e code-on-demand.
Tutte le REST API seguono ogni vincolo REST?
No. La maggior parte delle API in produzione segue la separazione client-server, l’assenza di stato e l’interfaccia uniforme di base (risorse + verbi HTTP). La cacheabilità e il sistema a strati sono implementati in modo incoerente. HATEOAS è raro e il code-on-demand è quasi mai usato nelle API JSON.
Qual è la differenza tra REST e GraphQL?
REST espone risorse tramite più endpoint con metodi HTTP standard (GET, POST, PUT, DELETE). GraphQL di solito usa un singolo endpoint in cui i client specificano esattamente quali campi vogliono in una query. REST offre un caching HTTP nativo più forte; GraphQL offre più flessibilità per esigenze di dati complesse e annidate e riduce over-fetching.
Che cos’è HATEOAS e lo usa davvero qualcuno?
HATEOAS (Hypermedia as the Engine of Application State) significa che le risposte API includono link che dicono ai client quali azioni sono disponibili dopo, così i client possono navigare l’API senza codificare a mano ogni endpoint. È centrale nella visione REST di Fielding (Livello 3 di Richardson), ma nella pratica pochissime API pubbliche lo implementano. La maggior parte dei team si ferma al Livello 2 e si affida invece a documentazione e SDK.
Scopri di più