
Se ti sei mai cimentato nell’estrazione di dati dal web usando Python, sai bene come va a finire: un momento stai raccogliendo prezzi o contatti utili, e quello dopo—puff—il tuo script viene bloccato, il tuo IP finisce in blacklist e ti ritrovi davanti a una sfilza di CAPTCHA che farebbero perdere la pazienza anche al più zen dei developer. Nel 2025, questa non è più una semplice seccatura: è la normalità per chi lavora in vendite, marketing o operations e ha bisogno di dati pubblici online per restare competitivo.
Il punto è questo: oltre il sono causati da sistemi anti-bot come ban degli IP e CAPTCHA, e circa il si scontra regolarmente con questi ostacoli. Ormai i bot sono quasi metà del traffico web, quindi i siti stanno alzando sempre di più le difese. Ma niente panico—che tu sia un mago di Python o cerchi una soluzione più rapida, qui ti spiego come evitare i blocchi, sfruttare i proxy in modo furbo e potenziare lo scraping con strumenti AI come .
Web Scraping senza Blocchi in Python: Le Basi
Partiamo dalle basi. Web scraping vuol dire automatizzare la raccolta di dati dai siti web. Python è la scelta top— usa strumenti Python per lo scraping. Ma i siti non sono certo contenti dei bot. Perché? Perché troppe richieste automatiche possono mettere sotto stress i server, copiare contenuti o dare vantaggi ai concorrenti.
Come si difendono i siti? Ecco le mosse più comuni:
- Blocco IP & Limitazione della frequenza: Se fai troppe richieste dallo stesso IP, scatta il blocco o ti rallentano.
- CAPTCHA: Quei puzzle “dimostra che sei umano” che fanno impazzire tutti.
- Filtraggio User-Agent e Header: Se il tuo script si presenta come “python-requests/2.x”, è come dire “sono un bot!” a gran voce.
- Sfide JavaScript & Browser Fingerprinting: Alcuni siti vogliono che tu esegua JavaScript o controllano i dettagli del browser.
- Honeypot: Link o campi nascosti che solo i bot attivano.
Se non stai attento, il tuo script Python farà scattare questi allarmi in un attimo.
Perché Evitare il Blocco IP è Fondamentale nello Scraping con Python
Essere bloccati non è solo una rogna tecnica—può avere impatti reali sul business. Immagina se il tuo team vendite non può più trovare nuovi contatti, l’analista prezzi si perde un ribasso della concorrenza, o la tua ricerca di mercato si basa su dati incompleti. Non è solo fastidioso: può costare caro.
Ecco qualche esempio concreto:
| Caso d'Uso | Scenario Tipico | Rischio se Bloccato | Vantaggio di uno Scraping Affidabile |
|---|---|---|---|
| Generazione Lead Vendite | Estrazione di contatti da directory o LinkedIn | Liste incomplete, opportunità perse | Lead aggiornati e continui per il team commerciale |
| Monitoraggio Prezzi | Controllo quotidiano dei prezzi dei concorrenti | Dati obsoleti, occasioni mancate | Intelligence prezzi sempre aggiornata |
| Analisi Competitor | Raccolta dettagli prodotti o recensioni | Zone d’ombra, lanci non rilevati | Visione completa della concorrenza |
| Ricerca di Mercato & SEO | Aggregazione news, forum o SERP | Analisi distorte, tempo sprecato | Dataset completi e tempestivi per analisi migliori |
Per , i dati web non sono un lusso, ma una risorsa fondamentale.
Come i Siti Bloccano lo Scraping Python: I Fattori Chiave
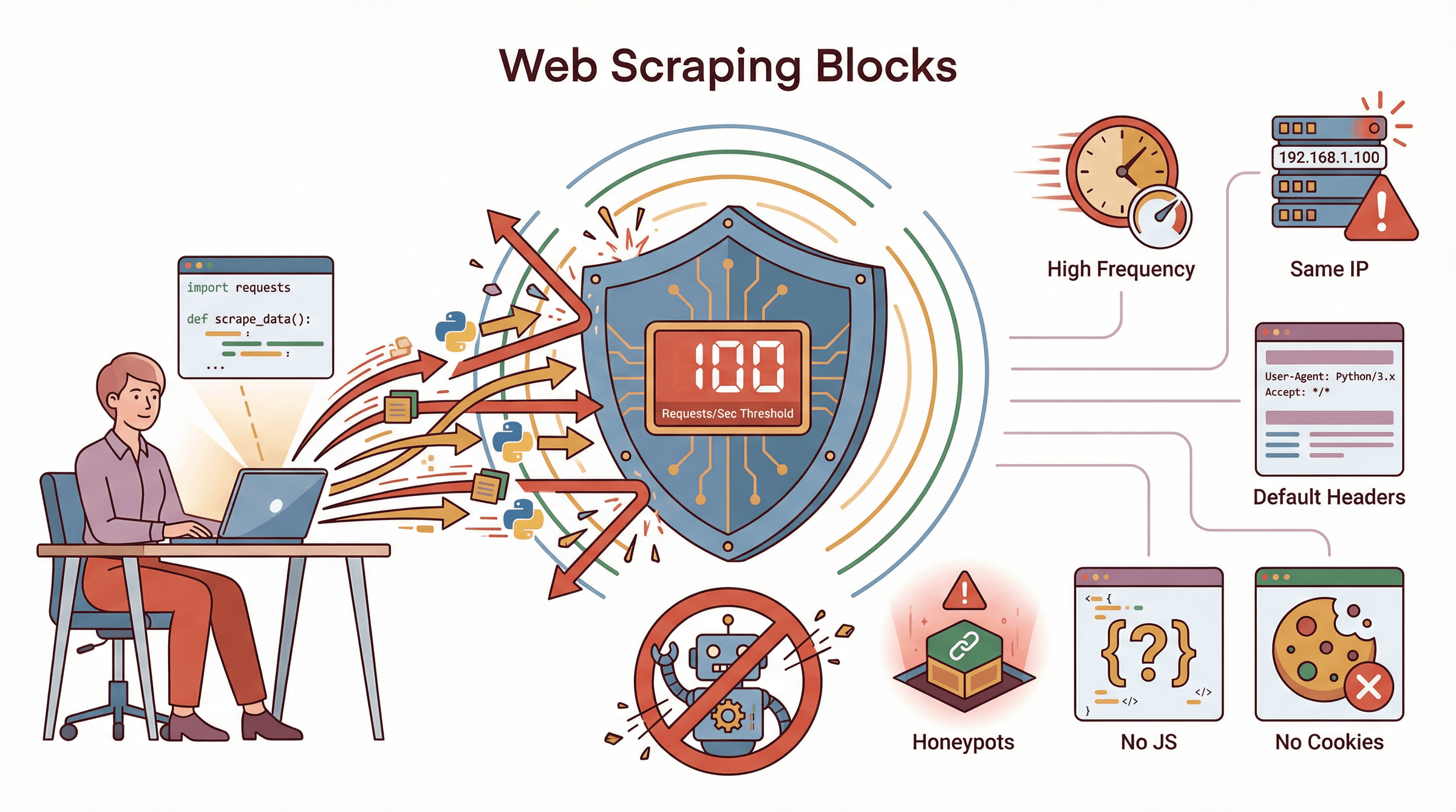 Cosa fa scattare il blocco di uno scraper Python? Ecco gli errori più comuni:
Cosa fa scattare il blocco di uno scraper Python? Ecco gli errori più comuni:
- Frequenza di richieste troppo alta: Nessuno apre 100 pagine al secondo. Se lo fai, vieni subito segnalato.
- Uso ripetuto dello stesso IP: Tutte le richieste dallo stesso indirizzo? Sospetto, soprattutto se arriva da un datacenter.
- Header di default: Usare user-agent standard di Python o header mancanti è un segnale chiaro.
- Assenza di cookie o sessioni: Gli utenti veri accumulano cookie navigando. I bot che non lo fanno sono sospetti.
- Ignorare il rendering JavaScript: Se il tuo scraper non esegue JS, rischi di perdere dati o fallire i controlli anti-bot.
- Ignorare Robots.txt: Non è un blocco tecnico, ma attira subito l’attenzione.
- Honeypot: Cliccare link nascosti o compilare campi invisibili? Ban immediato.
Gli errori più comuni tra i principianti sono inviare troppe richieste, non ruotare i proxy e dimenticare di variare user-agent e tempi di attesa. Ho visto intere reti universitarie bannate dal NASDAQ per aver inviato migliaia di richieste in pochi secondi. Un vero disastro.
Usare Proxy nello Scraping Python per Evitare Blocchi IP
Qui entrano in gioco i proxy: il tuo asso nella manica contro i ban degli IP. Un proxy fa da intermediario, inoltrando le tue richieste con un indirizzo IP diverso. Per il sito, sembri un utente completamente nuovo.
Tipi di Proxy
- Proxy Datacenter: Economici e veloci, ma facili da individuare. Perfetti per scraping a basso rischio.
- Proxy Residenziali: IP di case vere—più difficili da bloccare, ma più lenti e costosi.
- Proxy Rotanti: Cambiano IP ad ogni richiesta. Ideali per scraping su larga scala.
- Proxy Mobile: Usano IP di operatori mobili. Servono solo per i siti più tosti.
Per la maggior parte delle aziende, i proxy residenziali rotanti sono la scelta migliore: affidabili e difficili da bloccare.
Come Integrare i Proxy con Requests, Selenium e Beautiful Soup in Python
Ecco come aggiungere i proxy ai tuoi script Python:
Con Requests:
1import requests
2proxy = "http://USERNAME:PASSWORD@PROXY_IP:PORT"
3proxies = {"http": proxy, "https": proxy}
4headers = {"User-Agent": "Mozilla/5.0 ..."}
5response = requests.get("https://target-website.com/data", proxies=proxies, headers=headers)
6html = response.textCon Beautiful Soup:
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html, 'html.parser')
3data_items = soup.find_all('div', class_='item')Con Selenium:
1from selenium import webdriver
2proxy = "PROXY_IP:PORT"
3chrome_options = webdriver.ChromeOptions()
4chrome_options.add_argument(f'--proxy-server=http://{proxy}')
5driver = webdriver.Chrome(options=chrome_options)
6driver.get("https://target-website.com")Per i proxy rotanti, puoi ciclare una lista o affidarti a servizi che gestiscono la rotazione. Ricorda: se un proxy fallisce, intercetta l’errore e riprova con un altro.
Best Practice per Gestire e Ruotare i Proxy
- Usa un pool ampio: Più proxy hai, meglio è. Ruotali dopo ogni richiesta o gruppo di richieste.
- Monitora la salute dei proxy: Elimina quelli che non funzionano. Riprova con un nuovo IP in caso di errore.
- Non sovraccaricare un singolo proxy: Distribuisci le richieste. Non far lavorare sempre lo stesso IP.
- Target geografico: Usa proxy dello stesso paese del sito target se serve.
- Mescola i tipi di proxy: Parti con datacenter, passa ai residenziali se vieni bloccato.
- Evita i proxy gratuiti: Sono lenti, inaffidabili e spesso già in blacklist.
- Rispetta i limiti del provider: Non consumare tutto il traffico proxy troppo in fretta.
Gestire i proxy è quasi un’arte. Ma anche la configurazione migliore non basta da sola.
Oltre i Proxy: Tecniche Intelligenti per Evitare Blocchi in Python
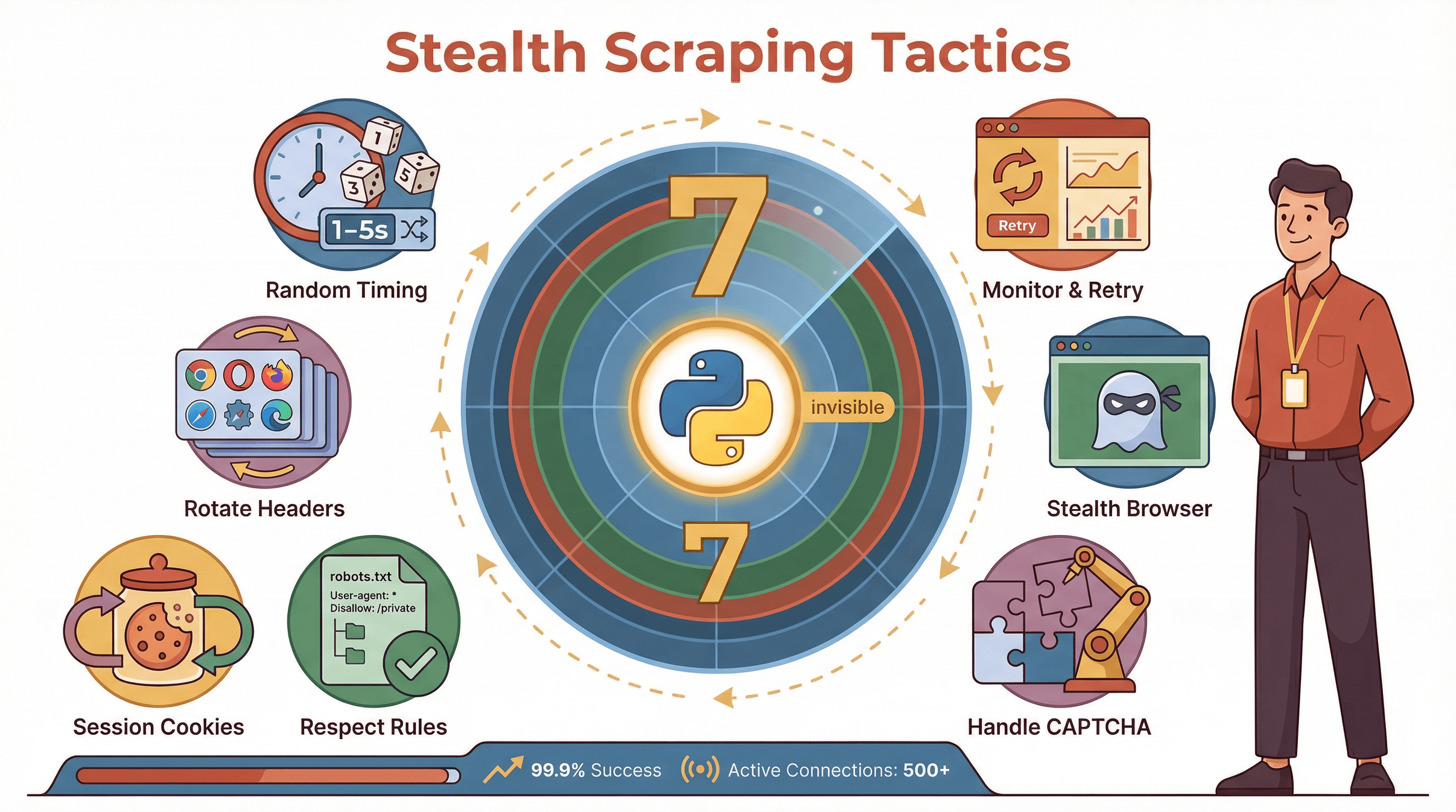 Vuoi davvero passare inosservato? Aggiungi queste strategie alla tua gestione dei proxy:
Vuoi davvero passare inosservato? Aggiungi queste strategie alla tua gestione dei proxy:
- Tempi di richiesta casuali: Non inviare richieste a intervalli regolari. Usa pause casuali (es. tra 1 e 5 secondi).
- Rotazione User-Agent e Header: Usa una lista di user-agent reali. Varia anche Accept-Language, Referer, ecc.
- Sessioni e Cookie: Mantieni i cookie tra le richieste per simulare una navigazione reale.
- Rispetta Robots.txt e rallenta in caso di errori: Non ignorare le regole del sito. Se ricevi errori 429 o 503, rallenta.
- Gestione CAPTCHA: Integra servizi di risoluzione CAPTCHA o riprova con un nuovo proxy se incontri un blocco.
- Browser headless stealth: Usa strumenti come undetected-chromedriver o plugin stealth di Playwright.
- Monitoraggio e retry: Tieni traccia dei log, controlla i picchi di errori e riprova automaticamente con nuovi proxy.
Ci sono ottime librerie Python per queste tecniche—fake-useragent, requests.Session() e plugin stealth per browser sono ottimi alleati.
Potenzia lo Scraping: Strumenti AI vs. Metodi Tradizionali con Proxy in Python
E qui viene il bello. E se potessi saltare tutta la fatica di gestire proxy, header e blocchi? Qui entra in gioco .
Thunderbit è un Estrattore Web AI come estensione Chrome che ti permette di estrarre dati da qualsiasi sito in due click—senza codice, senza configurare proxy, senza manutenzione. Basta cliccare su “AI Suggerisci Campi”, lasciare che l’AI individui cosa estrarre e premere “Estrai”. Thunderbit gestisce proxy, anti-blocco, paginazione e anche la navigazione tra sottopagine in automatico.
Ecco un confronto tra i due approcci:
| Aspetto | Scraping Python (Proxy) | Estrattore Web AI Thunderbit |
|---|---|---|
| Tempo di setup | Ore (codice, proxy, parsing) | Minuti (punta, clicca, fatto) |
| Competenze tecniche | Alte (codice, HTTP, proxy) | Basse (chiunque può usarlo) |
| Evitare blocchi | Manuale (ruota proxy, header) | Automatico (AI + gestione proxy integrata) |
| Manutenzione | Continua (aggiorna codice, proxy) | Minima (AI si adatta, template aggiornati) |
| Paginazione/Subpagine | Serve codice manuale | Un click, ci pensa l’AI |
| Esportazione dati | Manuale (CSV, Excel via codice) | Un click su Sheets, Excel, Notion, Airtable |
| Scalabilità | Dipende da infrastruttura/proxy | Alta (cloud scraping, pagine in parallelo) |
| Costo | Proxy + tempo sviluppo | Piano gratuito, poi prezzi accessibili |
| Affidabilità | Variabile (dipende dalla configurazione) | Alta (ottimizzato per aziende) |
Thunderbit è perfetto per team non tecnici o chi vuole solo i dati, subito.
Guida Pratica: Scraping Senza Blocchi con Thunderbit
Ecco come uso Thunderbit per estrarre dati da un sito che normalmente bloccherebbe gli script Python:
- Installa l’estensione Chrome Thunderbit: .
- Vai sul sito target: Accedi se necessario—Thunderbit usa la tua sessione browser.
- Clicca “AI Suggerisci Campi”: Thunderbit analizza la pagina e suggerisce le colonne da estrarre (es. “Nome”, “Prezzo”, “Email”).
- Clicca “Estrai”: Thunderbit raccoglie i dati in una tabella strutturata.
- Gestisci la paginazione: Attiva “Estrai tutte le pagine” e Thunderbit sfoglia ogni pagina, aggregando i risultati.
- Estrai sottopagine: Usa “Estrai sottopagine” per visitare ogni pagina di dettaglio e arricchire i dati.
- Esporta: Un click per inviare i dati su Google Sheets, Excel, Notion o Airtable.
Thunderbit si occupa di tutto il lavoro pesante—rotazione IP, gestione delle richieste, risoluzione di piccoli CAPTCHA. Per la maggior parte degli utenti business, funziona senza problemi.
Come Thunderbit Gestisce Paginazione e Sottopagine
Thunderbit non si limita a estrarre i dati della prima pagina. Può:
- Scorrere e cliccare come un umano: Per scroll infinito o pulsanti “pagina successiva”, Thunderbit simula la navigazione reale.
- Mantenere la sessione: Se sei loggato, Thunderbit mantiene la sessione su tutte le pagine.
- Distribuire il carico: In modalità cloud, Thunderbit estrae più pagine in parallelo, ognuna da un IP diverso.
- Gestire contenuti dinamici: Thunderbit esegue JavaScript, quindi raccoglie anche i dati che si caricano dopo.
- Estrazione sottopagine: Thunderbit può entrare nelle pagine di dettaglio di ogni elemento, estrarre campi aggiuntivi e unirli alla tabella principale.
Dal punto di vista del sito, sembra un gruppo di utenti reali che navigano normalmente—non un esercito di bot.
Python con Proxy vs Thunderbit: Quale Scegliere per il Business?
Qual è la soluzione migliore per te? Ecco un confronto veloce:
| Fattore | Python + Proxy | Thunderbit |
|---|---|---|
| Velocità | Più lento da configurare | Risultati immediati |
| Manutenzione | Alta (codice, proxy) | Bassa (AI si adatta, template) |
| Competenze | Sviluppatore | Chiunque |
| Rischio blocco | Medio (se non attento) | Basso (AI/proxy automatici) |
| Costo | Proxy + sviluppo | Piano gratuito, poi da 15$/mese |
| Ideale per | Scraping complesso su misura | Team vendite, marketing, ricerca |
Se sei uno sviluppatore che ama personalizzare e vuole il massimo controllo, Python e proxy restano una scelta valida. Ma per la maggior parte degli utenti business—soprattutto chi vuole evitare la fatica dei proxy—Thunderbit è un enorme salto di produttività.
In Sintesi: Fai Scraping in Modo Intelligente
Ecco cosa ho imparato (e che avrei voluto sapere prima):
- I proxy sono fondamentali per evitare blocchi IP nello scraping Python—ma gestirli richiede attenzione.
- Le tecniche anti-blocco intelligenti (ritardi casuali, rotazione header, sessioni) fanno la differenza.
- Strumenti AI come Thunderbit automatizzano tutto—proxy, anti-blocco, paginazione, sottopagine, esportazione—così puoi concentrarti solo sui dati.
- Scegli lo strumento giusto per il tuo team: Se vuoi velocità e affidabilità, Thunderbit è la scelta ovvia. Se ami il codice e hai esigenze personalizzate, Python + proxy resta potente.
Vuoi vedere quanto può essere semplice lo scraping? e provalo sul tuo prossimo progetto. E se vuoi altri consigli, dai un’occhiata al .
Buono scraping—che i tuoi IP restino sempre sbloccati e i tuoi dati sempre freschi.
Domande Frequenti
1. Qual è il motivo principale per cui gli scraper Python vengono bloccati?
La causa più comune è inviare troppe richieste dallo stesso IP o usare header di default che segnalano chiaramente un bot. I siti individuano subito questi schemi e bloccano o limitano l’accesso.
2. Come aiutano i proxy a evitare il blocco IP nello scraping Python?
I proxy instradano le richieste attraverso IP diversi, facendo sembrare che il traffico provenga da più utenti. I proxy rotanti sono particolarmente efficaci per lo scraping su larga scala.
3. Quali sono le best practice per gestire i proxy in Python?
Usa un ampio pool di proxy, ruotali spesso, monitora i fallimenti, evita i proxy gratuiti e scegli IP del paese target. Varia sempre tempi e header delle richieste.
4. Come fa Thunderbit a evitare i blocchi senza configurare proxy manualmente?
Thunderbit automatizza la rotazione dei proxy, la gestione dei tempi e le tecniche anti-blocco. Il suo agente AI simula il comportamento umano, gestisce paginazione e sottopagine ed esporta i dati in un click—senza bisogno di codice.
5. Meglio usare Python o Thunderbit per le esigenze di scraping aziendale?
Se sei uno sviluppatore con esigenze complesse e personalizzate, Python più proxy è flessibile. Ma per la maggior parte dei team vendite, marketing e ricerca che vogliono dati rapidi e affidabili senza complicazioni tecniche, Thunderbit è la scelta più semplice e intelligente.
Vuoi fare scraping in modo più smart? e dimentica i blocchi.
Approfondisci