Il web trabocca di dati preziosi: che tu lavori nelle vendite, nell’ecommerce o nelle ricerche di mercato, il web scraping è un’arma segreta per la generazione di lead, il monitoraggio dei prezzi e l’analisi competitiva. Ma c’è un problema: mentre sempre più aziende fanno scraping, i siti web rispondono in modo sempre più aggressivo. Oggi, infatti, oltre , e sono ormai la norma. Se ti è mai capitato di vedere uno script Python girare senza problemi per 20 minuti e poi sbattere all’improvviso contro una parete di errori 403, sai bene quanto possa essere frustrante.
Ho passato anni nel mondo SaaS e dell’automazione, e ho visto in prima persona quanto i progetti di scraping possano passare in un attimo da “wow, è facilissimo” a “perché mi bloccano ovunque?”. Quindi andiamo dritti al punto: ti mostrerò come fare web scraping senza essere bloccati in Python, condividerò le tecniche migliori e gli snippet di codice più utili, e ti farò vedere quando conviene prendere in considerazione alternative basate su AI come . Che tu sia un veterano di Python o che tu stia solo cercando di “raspare” un po’ di dati, qui troverai un kit di strumenti per estrarre informazioni in modo affidabile e senza blocchi.
Che cosa significa fare web scraping senza essere bloccati in Python?
In sostanza, fare web scraping senza essere bloccati significa estrarre dati dai siti web senza attivare le loro difese anti-bot. Nel mondo Python, non vuol dire solo scrivere un ciclo requests.get(); vuol dire mimetizzarsi, imitare utenti reali e stare un passo avanti ai sistemi di rilevamento.
Perché Python? grazie alla sua sintassi semplice, all’enorme ecosistema (pensa a requests, BeautifulSoup, Scrapy, Selenium) e alla flessibilità che va dagli script rapidi ai crawler distribuiti. Ma la popolarità ha un prezzo: molti sistemi anti-bot oggi sono tarati per riconoscere i pattern di scraping basati su Python.
Quindi, se vuoi fare scraping in modo affidabile, devi andare oltre le basi. Significa capire come i siti rilevano i bot e come puoi superarli, senza oltrepassare limiti etici o legali.
Perché evitare i blocchi è fondamentale nei progetti di web scraping in Python
Essere bloccati non è solo un intoppo tecnico: può mandare all’aria interi flussi di lavoro aziendali. Vediamolo nel concreto:
| Caso d’uso | Impatto del blocco |
|---|---|
| Generazione di lead | Liste di prospect incomplete o obsolete, opportunità di vendita perse |
| Monitoraggio prezzi | Mancato rilevamento delle variazioni dei concorrenti, decisioni sui prezzi sbagliate |
| Aggregazione contenuti | Lacune in notizie, recensioni o dati di ricerca |
| Intelligence di mercato | Punti ciechi nel monitoraggio di concorrenti o settore |
| Annunci immobiliari | Dati sulle proprietà imprecisi o vecchi, opportunità perse |
Quando uno scraper viene bloccato, non perdi solo dati: sprechi risorse, rischi problemi di conformità e potenzialmente prendi decisioni commerciali sbagliate basandoti su informazioni incomplete. In un mondo in cui , l’affidabilità è tutto.
Come i siti web rilevano e bloccano gli scraper Python
I siti web sono diventati davvero bravi a riconoscere i bot. Ecco le difese anti-scraping più comuni che incontrerai (, ):
- Blacklist degli indirizzi IP: troppe richieste dallo stesso IP? Bloccato.
- Controlli su User-Agent e header: richieste senza header o con header generici (come il default di Python
python-requests/2.25.1) saltano subito all’occhio. - Rate limiting: troppe richieste in poco tempo attivano limitazioni o ban.
- CAPTCHA: rompicapi del tipo “dimostra di essere umano”, che i bot non risolvono facilmente.
- Analisi comportamentale: i siti osservano pattern robotici, come cliccare sempre lo stesso pulsante allo stesso intervallo.
- Honeypot: link o campi nascosti con cui interagiscono solo i bot.
- Browser fingerprinting: raccolta di dettagli sul browser e sul dispositivo per individuare l’automazione.
- Tracciamento di cookie e sessioni: i bot che non gestiscono bene cookie o sessioni vengono segnalati.
Pensa a tutto questo come ai controlli in aeroporto: se sembri, ti muovi e ti comporti come tutti gli altri, passi in fretta. Se ti presenti con un trench e gli occhiali da sole, aspettati qualche domanda in più.
Tecniche essenziali in Python per fare web scraping senza essere bloccati
Passiamo alla parte interessante: come evitare davvero i blocchi quando fai scraping con Python. Ecco le strategie fondamentali che ogni scraper dovrebbe conoscere:

Proxy e indirizzi IP rotanti
Perché conta: se tutte le richieste arrivano dallo stesso IP, sei un bersaglio facile per i ban IP. I proxy rotanti ti permettono di distribuire le richieste su molti IP, rendendo molto più difficile bloccarti.
Come farlo in Python:
1import requests
2proxies = [
3 "<http://proxy1.example.com:8000>",
4 "<http://proxy2.example.com:8000>",
5 # ...altri proxy
6]
7for i, url in enumerate(urls):
8 proxy = {"http": proxies[i % len(proxies)]}
9 response = requests.get(url, proxies=proxy)
10 # elabora la rispostaPuoi usare servizi proxy a pagamento (come proxy residenziali o rotanti) per maggiore affidabilità ().
Impostare User-Agent e header personalizzati
Perché conta: gli header predefiniti di Python gridano “bot”. Imita i browser reali impostando user-agent e altri header.
Codice di esempio:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4 "Accept-Encoding": "gzip, deflate, br",
5 "Connection": "keep-alive"
6}
7response = requests.get(url, headers=headers)Ruota gli user-agent per aumentare ancora un po’ la furtività ().
Randomizzare tempi e pattern delle richieste
Perché conta: i bot sono veloci e prevedibili; gli esseri umani sono più lenti e imprevedibili. Aggiungi ritardi e varia il tuo comportamento di navigazione.
Suggerimento Python:
1import time, random
2for url in urls:
3 response = requests.get(url)
4 time.sleep(random.uniform(2, 7)) # Attendi 2–7 secondiPuoi anche randomizzare i percorsi di clic e i pattern di scroll se usi Selenium.
Gestire cookie e sessioni
Perché conta: molti siti richiedono cookie o token di sessione per accedere ai contenuti. I bot che li ignorano vengono bloccati.
Come gestirli in Python:
1import requests
2session = requests.Session()
3response = session.get(url)
4# la sessione gestirà i cookie automaticamentePer flussi più complessi, usa Selenium per catturare e riutilizzare i cookie.
Simulare il comportamento umano con browser headless
Perché conta: alcuni siti usano JavaScript, movimento del mouse o scroll come segnali di utenti reali. I browser headless come Selenium o Playwright possono imitare queste azioni.
Esempio con Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.action_chains import ActionChains
3import random, time
4driver = webdriver.Chrome()
5driver.get(url)
6actions = ActionChains(driver)
7actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
8time.sleep(random.uniform(2, 5))Questo aiuta a bypassare l’analisi comportamentale e i contenuti dinamici ().
Strategie avanzate: aggirare CAPTCHA e honeypot in Python
I CAPTCHA sono progettati per fermare i bot sul nascere. Anche se alcune librerie Python riescono a risolvere CAPTCHA semplici, la maggior parte degli scraper seri si affida a servizi terzi (come 2Captcha o Anti-Captcha) per risolverli a pagamento ().
Integrazione di esempio:
1# Pseudocodice per usare l'API di 2Captcha
2import requests
3captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
4# Attendi la soluzione, poi inviala con la tua richiestaGli honeypot sono campi o link nascosti con cui interagiscono solo i bot. Evita di cliccare o inviare qualsiasi cosa che non sia visibile in un browser reale ().
Progettare header di richiesta robusti con le librerie Python
Oltre allo user-agent, puoi ruotare e randomizzare altri header (come Referer, Accept, Origin, ecc.) per mimetizzarti ancora meglio.
Con Scrapy:
1class MySpider(scrapy.Spider):
2 custom_settings = {
3 'DEFAULT_REQUEST_HEADERS': {
4 'User-Agent': '...',
5 'Accept-Language': 'en-US,en;q=0.9',
6 # Altri header
7 }
8 }Con Selenium: usa profili del browser o estensioni per impostare gli header, oppure iniettali tramite JavaScript.
Tieni aggiornata la tua lista di header: copia le richieste reali del browser usando strumenti DevTools come riferimento.
Quando lo scraping tradizionale in Python non basta: l’ascesa della tecnologia anti-bot
Ecco la realtà: più lo scraping diventa popolare, più si evolvono le difese anti-bot. . Il rilevamento basato su AI, le soglie dinamiche per le richieste e il browser fingerprinting stanno rendendo sempre più difficile perfino agli script Python avanzati passare inosservati ().
A volte, per quanto il tuo codice sia intelligente, ti ritrovi comunque contro un muro. È lì che conviene valutare un approccio diverso.
Thunderbit: un’alternativa AI Web Scraper allo scraping Python
Quando Python arriva ai suoi limiti, entra in gioco come AI Web Scraper no-code pensato per utenti business e non solo per sviluppatori. Invece di impazzire con proxy, header e CAPTCHA, l’agente AI di Thunderbit legge il sito, suggerisce i campi migliori da estrarre e gestisce tutto, dalla navigazione nelle sottopagine all’esportazione dei dati.
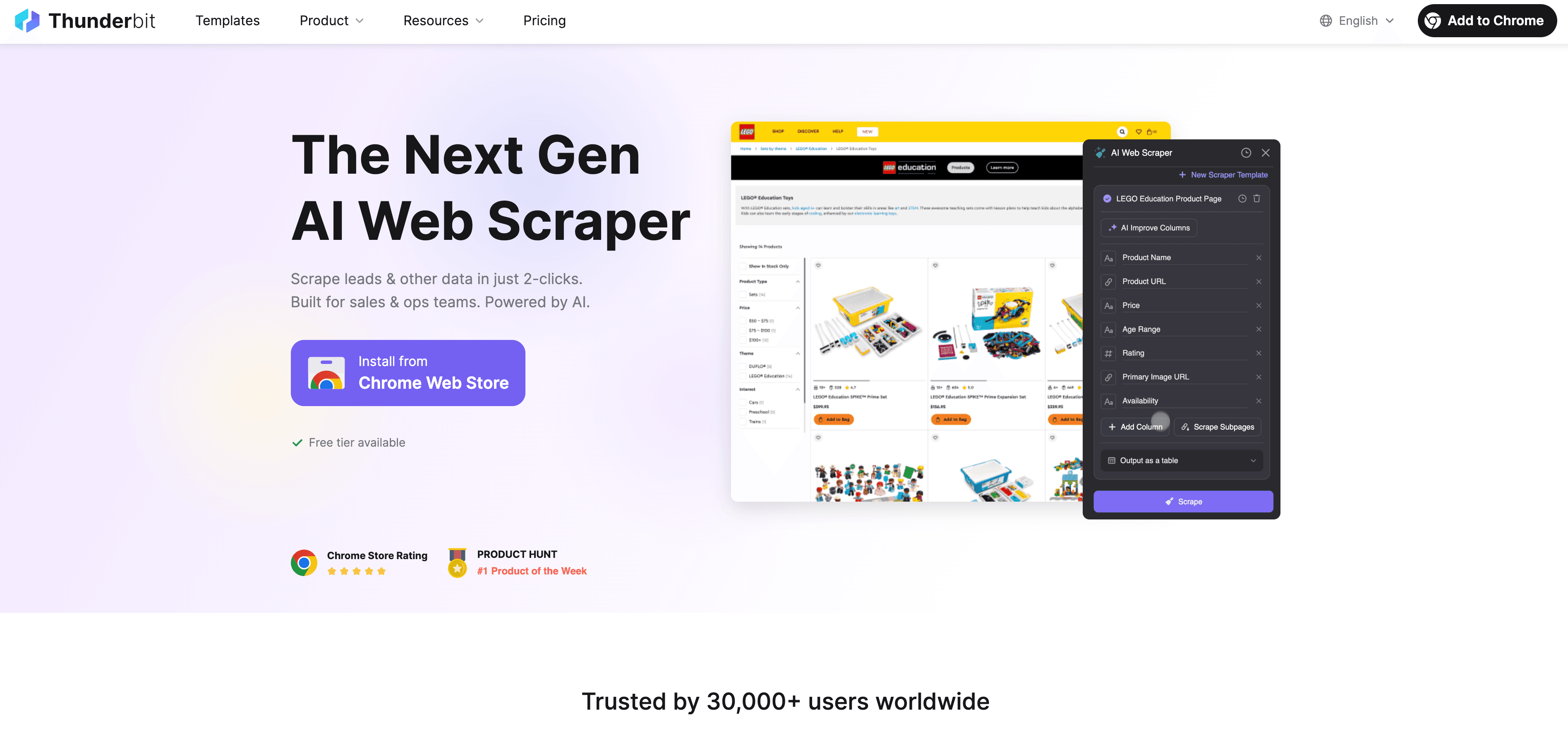
Cosa rende Thunderbit diverso?
- Suggerimento AI dei campi: fai clic su “AI Suggest Fields” e Thunderbit analizza la pagina, consiglia le colonne e genera persino le istruzioni di estrazione.
- Scraping delle sottopagine: Thunderbit può visitare ogni sottopagina (come dettagli prodotto o profili LinkedIn) e arricchire automaticamente la tua tabella.
- Scraping cloud o nel browser: scegli l’opzione più veloce: cloud per i siti pubblici, browser per le pagine protette da login.
- Scraping pianificato: imposta e dimentica: Thunderbit può eseguire lo scraping secondo una pianificazione, così i tuoi dati restano sempre aggiornati.
- Template immediati: per i siti più popolari (Amazon, Zillow, Shopify, ecc.), Thunderbit offre template in 1 clic, senza configurazione.
- Export gratuito dei dati: esporta in Excel, Google Sheets, Airtable o Notion, senza costi extra.
Thunderbit è scelto da oltre e non devi scrivere nemmeno una riga di codice.
Come Thunderbit aiuta gli utenti a evitare i blocchi e automatizzare l’estrazione dei dati
L’AI di Thunderbit non si limita a imitare il comportamento umano: si adatta a ogni sito in tempo reale, riducendo il rischio di essere bloccati. Ecco come:
- L’AI si adatta ai cambiamenti di layout: niente più script rotti quando un sito aggiorna il design.
- Gestione di sottopagine e paginazione: Thunderbit segue automaticamente link e liste paginate, proprio come farebbe un utente reale.
- Scraping cloud su larga scala: estrai fino a 50 pagine alla volta, a velocità fulminea.
- Niente codice, niente manutenzione: dedica il tempo all’analisi, non al debug.
Per un approfondimento, leggi .
Confronto tra scraping Python e Thunderbit: quale scegliere?
Mettiamoli a confronto:
| Funzionalità | Scraping Python | Thunderbit |
|---|---|---|
| Tempo di configurazione | Medio-alto (script, proxy, ecc.) | Basso (2 clic, l’AI fa il resto) |
| Competenze tecniche | Richiede programmazione | Nessun codice richiesto |
| Affidabilità | Variabile (si rompe facilmente) | Alta (l’AI si adatta ai cambiamenti) |
| Rischio di blocco | Medio-alto | Basso (l’AI imita l’utente e si adatta) |
| Scalabilità | Richiede codice personalizzato/configurazione cloud | Scraping cloud/batch integrato |
| Manutenzione | Frequente (cambiamenti del sito, blocchi) | Minima (l’AI si regola automaticamente) |
| Opzioni di export | Manuale (CSV, DB) | Diretto su Sheets, Notion, Airtable, CSV |
| Costo | Gratis, ma richiede molto tempo | Piano gratuito, piani a pagamento per scalare |
Quando usare Python:
- Ti serve controllo totale, logica personalizzata o integrazione con altri flussi Python.
- Stai estraendo dati da siti con difese anti-bot minime.
Quando usare Thunderbit:
- Vuoi velocità, affidabilità e zero configurazione.
- Stai estraendo dati da siti complessi o che cambiano spesso.
- Non vuoi avere a che fare con proxy, CAPTCHA o codice.
Guida passo per passo: impostare il web scraping senza essere bloccati in Python
Vediamo un esempio pratico: estrarre dati di prodotto da un sito demo applicando le migliori pratiche anti-blocco.
1. Installa le librerie necessarie
1pip install requests beautifulsoup4 fake-useragent2. Prepara lo script
1import requests
2from bs4 import BeautifulSoup
3from fake_useragent import UserAgent
4import time, random
5ua = UserAgent()
6urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Sostituisci con i tuoi URL
7for url in urls:
8 headers = {
9 "User-Agent": ua.random,
10 "Accept-Language": "en-US,en;q=0.9"
11 }
12 response = requests.get(url, headers=headers)
13 if response.status_code == 200:
14 soup = BeautifulSoup(response.text, "html.parser")
15 # Estrai qui i dati
16 print(soup.title.text)
17 else:
18 print(f"Bloccato o errore su \{url\}: \{response.status_code\}")
19 time.sleep(random.uniform(2, 6)) # Ritardo casuale3. Aggiungi la rotazione dei proxy (facoltativo)
1proxies = [
2 "<http://proxy1.example.com:8000>",
3 "<http://proxy2.example.com:8000>",
4 # Altri proxy
5]
6for i, url in enumerate(urls):
7 proxy = {"http": proxies[i % len(proxies)]}
8 headers = {"User-Agent": ua.random}
9 response = requests.get(url, headers=headers, proxies=proxy)
10 # ...resto del codice4. Gestisci cookie e sessioni
1session = requests.Session()
2for url in urls:
3 response = session.get(url, headers=headers)
4 # ...resto del codice5. Consigli per il troubleshooting
- Se vedi molti errori 403/429, rallenta le richieste o prova nuovi proxy.
- Se incontri CAPTCHA, considera Selenium o un servizio per la risoluzione dei CAPTCHA.
- Controlla sempre il file
robots.txtdel sito e i termini di servizio.
Conclusione e punti chiave
Il web scraping in Python è potente, ma essere bloccati è un rischio costante mentre la tecnologia anti-bot continua a evolversi. Il modo migliore per evitare i blocchi? Combinare buone pratiche tecniche — proxy rotanti, header intelligenti, ritardi casuali, gestione delle sessioni e browser headless — con un sano rispetto delle regole e dell’etica del sito.
Ma a volte nemmeno i migliori trucchi in Python bastano. È qui che brillano strumenti basati su AI come : offrono un modo no-code, resistente ai blocchi e adatto al business per estrarre rapidamente i dati di cui hai bisogno.
Vuoi vedere quanto può essere semplice fare scraping? e provane la comodità in prima persona — oppure visita il nostro per altri consigli e tutorial sullo scraping.
FAQ
1. Perché i siti web bloccano gli scraper Python?
I siti bloccano gli scraper per proteggere i propri dati, prevenire il sovraccarico dei server e impedire ai bot automatizzati di abusare dei servizi. Gli script Python sono facili da individuare se usano header predefiniti, non gestiscono cookie o inviano troppe richieste troppo velocemente.
2. Quali sono i modi più efficaci per evitare di essere bloccati quando si fa scraping con Python?
Usa proxy rotanti, imposta user-agent e header realistici, randomizza i tempi delle richieste, gestisci cookie e sessioni e simula il comportamento umano con strumenti come Selenium o Playwright.
3. In che modo Thunderbit aiuta a evitare i blocchi rispetto agli script Python?
Thunderbit usa l’AI per adattarsi ai layout dei siti, imitare la navigazione umana e gestire automaticamente sottopagine e paginazione. Riduce il rischio di blocchi mimetizzandosi e aggiornando il proprio approccio in tempo reale, senza bisogno di codice o proxy.
4. Quando dovrei usare lo scraping Python invece di uno strumento AI come Thunderbit?
Usa Python quando ti servono logiche personalizzate, integrazione con altro codice Python o quando stai estraendo dati da siti semplici. Usa Thunderbit per uno scraping veloce, affidabile e scalabile, soprattutto quando i siti sono complessi, cambiano spesso o bloccano in modo aggressivo gli script.
5. Il web scraping è legale?
Il web scraping è legale per i dati pubblicamente disponibili, ma devi rispettare i termini di servizio, le privacy policy e le leggi applicabili di ogni sito. Non estrarre mai dati sensibili o privati e fai sempre scraping in modo etico e responsabile.
Pronto a fare scraping in modo più intelligente, non più faticoso? Prova Thunderbit e lasciati i blocchi alle spalle.
Scopri di più:
- Scraping di Google News con Python: guida passo per passo
- Creare uno strumento di monitoraggio prezzi Best Buy con Python
- 14 modi per fare web scraping senza essere bloccati
- 10 migliori consigli su come non essere bloccati quando si fa web scraping