

Torniamo indietro di qualche anno: io alla scrivania, caffè in mano, davanti a un foglio di calcolo più vuoto del frigo di domenica sera. Il commerciale vuole i prezzi dei concorrenti, il marketing reclama nuovi lead, le operations chiedono le schede prodotto da una dozzina di siti — e tutto, ovviamente, per ieri. So che quei dati esistono. Il problema è andarli a prendere. Se ti sei mai sentito intrappolato in una partita digitale di acchiappa-la-talpa fatta di copia e incolla, benvenuto nel club.
Salto al presente: lo scenario è un altro pianeta. Il web scraping è passato da hobby smanettone a leva di business vera e propria, e JavaScript con Node.js sono finiti in prima fila, a far girare di tutto: dagli script usa-e-getta alle pipeline dati complete. Resta un però: gli strumenti sono più potenti che mai, ma la curva d’apprendimento può ancora sembrare l’Everest scalato in infradito. Quindi, che tu sia un business user, un appassionato di dati o semplicemente uno stanco dell’inserimento manuale, questa guida è per te. Ti racconto l’ecosistema, le librerie che contano, i punti dolenti e perché, ogni tanto, la mossa più intelligente è lasciare il lavoro pesante all’AI.
Perché il Web Scraping con JavaScript e Node.js conta per il business
Partiamo dal “perché”. Nel 2026 i dati dal web non sono più un lusso: sono benzina. Da ricerche recenti, il 73% delle aziende attribuisce ai dati pubblici del web decisioni più rapide e accurate e circa il 42% dei budget aziendali per i dati finisce oggi nella raccolta di dati web. Il mercato dei dati alternativi, che include il web scraping, vale già 4,9 miliardi di dollari ed è in piena corsa.
Cosa alimenta questa febbre dell’oro? Ecco i casi d’uso aziendali più comuni:
- Prezzi competitivi ed e-commerce: i retailer estraggono prezzi e disponibilità dai siti dei concorrenti, a volte spingendo le vendite del 4% o più.
- Lead generation e sales intelligence: i team sales automatizzano la raccolta di email, numeri di telefono e dettagli aziendali da directory e piattaforme social.
- Ricerche di mercato e aggregazione di contenuti: gli analisti raccolgono notizie, recensioni e dati di sentiment per fiutare trend e fare previsioni.
- Advertising e ad tech: le aziende ad tech tengono d’occhio in tempo reale i posizionamenti pubblicitari e le campagne dei concorrenti.
- Immobiliare e travel: le agenzie estraggono annunci, prezzi e recensioni per alimentare modelli di valutazione e analisi di mercato.
- Aggregatori di contenuti e dati: le piattaforme uniscono dati da più fonti per far girare strumenti di confronto e dashboard.
JavaScript e Node.js sono diventati lo stack di riferimento per questi compiti, soprattutto perché sempre più siti puntano su contenuti dinamici renderizzati in JavaScript. Node.js va forte sulle operazioni asincrone, il che lo rende perfetto per lo scraping su larga scala. E con un ecosistema di librerie vivace come pochi, ci costruisci di tutto: dallo script al volo allo scraper robusto pronto per la produzione.
Che cos’è il data scraping e come farlo nel 2025 Get Started Free
Il flusso di lavoro di base: come funziona il Web Scraping con JavaScript e Node.js
Sbroghiamo il tipico flusso di lavoro dello scraping. Che tu stia estraendo da un blog spartano o da un e-commerce zeppo di JavaScript, i passaggi sono più o meno questi:
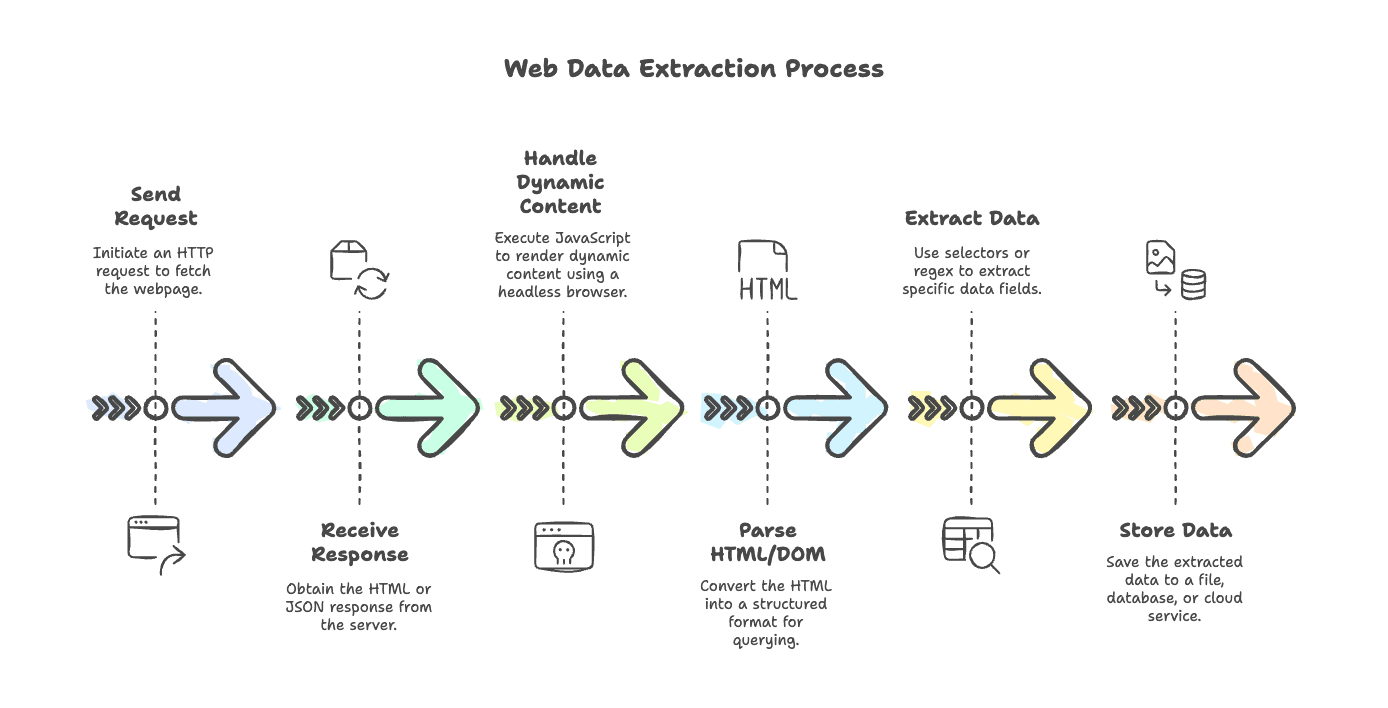
- Invia la richiesta: con un client HTTP recuperi la pagina (per esempio
axios,node-fetchogot). - Ricevi la risposta: ti torna l’HTML (o, a volte, JSON) dal server.
- Gestisci i contenuti dinamici: se la pagina la renderizza JavaScript, usa un browser headless (come Puppeteer o Playwright) per eseguire gli script e ottenere il contenuto finale.
- Analizza HTML/DOM: con un parser (
cheerio,jsdom) trasformi l’HTML in una struttura interrogabile. - Estrai i dati: con selettori o regex tiri fuori i campi che ti servono.
- Archivia i dati: salvi i risultati in un file, in un database o su un servizio cloud.
Ogni passaggio ha i suoi strumenti e le sue best practice, che vediamo a breve.
Librerie HTTP essenziali per il Web Scraping in JavaScript
Il primo gradino di qualsiasi scraper è fare richieste HTTP. Node.js offre un ventaglio di opzioni, alcune storiche, altre moderne. Ecco una carrellata delle più usate:
1. Axios
Un client HTTP basato su promesse per Node e browser. È il coltellino svizzero per la maggior parte dei lavori di scraping.
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
Pro: ricco di funzioni, supporta async/await, parsing JSON automatico, interceptor e proxy.
Contro: un po’ più pesante, e a volte gestisce i dati in modo “magico”.
2. node-fetch
Porta l’API fetch del browser dentro Node.js. Minimale e moderno.
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
Pro: leggero, API familiare per chi arriva dal frontend JavaScript.
Contro: poche funzioni, gestione manuale degli errori, configurare il proxy è verboso.
3. SuperAgent
Una libreria HTTP di lungo corso con API concatenabile.
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
Pro: matura, supporta form, upload di file e plugin.
Contro: l’API mostra qualche ruga, dipendenza piuttosto grande.
4. Unirest
Un client HTTP semplice e indipendente dal linguaggio.
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
Pro: sintassi facile, ottimo per gli script al volo.
Contro: meno funzioni, community meno viva.
5. Got
Un client HTTP veloce e robusto per Node.js con funzioni avanzate.
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
Pro: veloce, supporta HTTP/2, retry e stream.
Contro: solo per Node, e l’API può risultare densa per chi è alle prime armi.
6. http/https integrati in Node
Si può sempre tornare al metodo classico:
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('Lunghezza della risposta:', data.length);
});
});
Pro: zero dipendenze.
Contro: verboso, tutto a colpi di callback, niente promesse.
Qui trovi un confronto dettagliato di funzioni e snippet di codice.
Come scegliere il client HTTP giusto per il tuo progetto
Come si fa a scegliere lo strumento giusto? Ecco cosa guardo io:
- Facilità d’uso: Axios e Got brillano con async/await e una sintassi pulita.
- Prestazioni: Got e node-fetch sono leggeri e rapidi nello scraping ad alta concorrenza.
- Supporto proxy: Axios e Got rendono indolore la rotazione dei proxy.
- Gestione errori: Axios solleva eccezioni sugli errori HTTP di default; node-fetch richiede controlli a mano.
- Community: Axios e Got hanno community attive e una valanga di esempi.
I miei consigli lampo:
- Script o prototipi rapidi: node-fetch o Unirest.
- Scraping in produzione: Axios (per le funzioni) o Got (per le prestazioni).
- Automazione del browser: Puppeteer o Playwright gestiscono le richieste internamente.
Parsing HTML ed estrazione dei dati: Cheerio, jsdom e dintorni
Una volta in mano l’HTML, devi trasformarlo in qualcosa di davvero lavorabile. Entrano in scena i parser.
Cheerio
Immagina Cheerio come jQuery per il server. È veloce, leggero e perfetto per l’HTML statico.
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
Pro: velocissimo, API familiare, regge bene l’HTML disordinato.
Contro: non esegue JavaScript — vede solo ciò che c’è già nell’HTML.
Scopri di più sulla velocità e sui casi d’uso di Cheerio.
jsdom
jsdom simula in Node.js un DOM simile a quello del browser. Esegue script semplici ed è più “browser-like” di Cheerio.
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Hello</p><script>document.querySelector('#greet').textContent += ", world!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
Pro: esegue script, supporta l’intera API DOM.
Contro: più lento e pesante di Cheerio, e non è un browser vero e proprio.
Confronta Cheerio e jsdom nel dettaglio.
Quando usare le espressioni regolari o altri metodi di parsing
Le regex nello scraping sono come la salsa piccante: deliziose con moderazione, un disastro se le versi su tutto. Sono utili per:
- Estrarre pattern dal testo (email, numeri di telefono, prezzi).
- Pulire o validare i dati estratti.
- Recuperare dati da blocchi di testo o tag script.
Esempio: estrarre un numero dal testo
const text = "Vendite totali: 1.234 unità";
const match = text.match(/([\d.,]+)\s*unità/);
if (match) {
const units = parseInt(match[1].replace(/\./g, '').replace(/,/g, ''));
console.log("Unità vendute:", units);
}
Ma non provare a fare il parsing di un intero HTML con le regex: per quello esiste un parser DOM. Altri consigli sulle regex per lo scraping.
Gestire siti dinamici: Puppeteer, Playwright e browser headless
I siti moderni vanno matti per JavaScript. A volte i dati che cerchi non sono nell’HTML iniziale: li disegnano gli script dopo il caricamento. Qui entrano in gioco i browser headless.
Puppeteer
Una libreria Node.js di Google che pilota Chrome/Chromium. È come avere un robot che clicca e scorre le pagine al posto tuo.
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
Pro: rendering completo di Chrome, API facile, ottimo per i contenuti dinamici.
Contro: solo Chromium, più esoso di risorse.
Approfondisci i punti di forza di Puppeteer.
Playwright
Una libreria più recente di Microsoft: Playwright supporta Chromium, Firefox e WebKit. È un po’ il cugino più sveglio e multi-browser di Puppeteer.
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
Pro: multi-browser, contesti paralleli, attesa automatica degli elementi.
Contro: curva d’apprendimento un filo più ripida, installazione più corposa.
Perché Playwright sta guadagnando terreno.
Nightmare
Uno strumento di automazione basato su Electron che anni fa andava forte. Il repository è finito nell’organizzazione GitHub segment-boneyard — il cimitero dove Segment parcheggia i progetti che non segue più — e l’ultima release su npm risale al 2019. Nel 2026 non lo userei per niente di nuovo; se erediti uno script che lo usa ancora, pazienza, ma per un progetto da zero punta dritto su Playwright o Puppeteer.
Confronto tra le soluzioni di browser headless
| Aspetto | Puppeteer (Chrome) | Playwright (multibrowser) | Nightmare (Electron) |
|---|---|---|---|
| Supporto browser | Chrome/Edge | Chrome, Firefox, WebKit | Chrome (vecchio) |
| Prestazioni e scala | Veloce, ma pesante | Veloce, parallelismo migliore | Più lento, meno stabile |
| Scraping dinamico | Eccellente | Eccellente + più funzioni | Buono sui siti semplici |
| Manutenzione | Ben mantenuto | Molto attivo | Archiviato (segment-boneyard, ultimo publish npm nel 2019) |
| Ideale per | Scraping su Chrome | Progetti complessi, cross-browser | Attività semplici e legacy |
Il mio consiglio: Playwright per i progetti nuovi e complessi. Puppeteer resta ottimo per i compiti solo Chrome. Nightmare ormai è più che altro nostalgia o script ereditati.
Strumenti di supporto: pianificazione, ambiente, CLI e archiviazione dei dati
Uno scraper vero è molto più di un fetch e un parse. Ecco alcuni strumenti di supporto su cui faccio affidamento:
Pianificazione: node-cron
Programma gli scraper perché partano da soli.
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('Scraping alle 9:00 ogni lunedì');
});
Node-cron è perfetto per automatizzare le attività ripetitive.
Gestione dell’ambiente: dotenv
Tieni segreti e configurazioni fuori dal codice.
require('dotenv').config();
const apiKey = process.env.API_KEY;
Strumenti CLI: chalk, commander, inquirer
- chalk: colora l’output della console.
- commander: analizza le opzioni da riga di comando.
- inquirer: prompt interattivi per l’input dell’utente.
Archiviazione dei dati
- fs: scrive su file (JSON, CSV).
- lowdb: database JSON leggero.
- sqlite3: database SQL locale.
- mongodb: database NoSQL per i progetti più grandi.
Esempio: salvare i dati in JSON
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
I punti deboli del Web Scraping tradizionale con JavaScript e Node.js
Diciamocelo: lo scraping tradizionale non è tutto rose e fiori. Ecco i grattacapi più grossi che ho visto — e provato sulla mia pelle:

- Curva d’apprendimento ripida: devi padroneggiare DOM, selettori, logica asincrona e, a volte, le bizzarrie dei browser.
- Peso della manutenzione: i siti cambiano, i selettori si rompono e tu a rincorrere il codice.
- Scarsa scalabilità: ogni sito vuole il suo script; nulla è davvero “taglia unica”.
- Pulizia dei dati complicata: i dati estratti sono disordinati — pulizia, formattazione e deduplicazione diventano un lavoro a parte.
- Limiti di prestazioni: l’automazione del browser è lenta e affamata di risorse sui lavori grandi.
- Blocchi e misure anti-bot: i siti bloccano gli scraper, sparano CAPTCHA o nascondono i dati dietro login.
- Zone grigie legali ed etiche: devi muoverti tra termini di servizio, privacy e conformità.
Approfondisci questi punti dolenti con statistiche reali.
Thunderbit vs. Web Scraping tradizionale: un salto di produttività
Affrontiamo l’elefante nella stanza: e se potessi saltare codice, selettori e manutenzione in un colpo solo?
Qui entra in scena Thunderbit. Da cofondatore e CEO sono un po’ di parte, lo ammetto, ma lascia che ti spieghi: Thunderbit è pensato per chi vuole dati, non grattacapi.
Come si comporta Thunderbit nel confronto
| Aspetto | Thunderbit (AI senza codice) | Web scraping tradizionale in JS/Node |
|---|---|---|
| Configurazione | 2 clic, zero codice | Scrivere script, fare debug |
| Contenuti dinamici | Gestiti nel browser | Scripting con browser headless |
| Manutenzione | L’AI si adatta ai cambiamenti | Aggiornamenti manuali del codice |
| Estrazione dati | L’AI suggerisce i campi | Selettori a mano |
| Scraping di sottopagine | Integrato, 1 clic | Loop e codice per ogni sito |
| Esportazione | Excel, Sheets, Notion | Integrazione manuale con file/db |
| Post-elaborazione | Riassumi, tagga, formatta | Codice o strumenti aggiuntivi |
| Chi può usarlo | Chiunque abbia un browser | Solo sviluppatori |
L’AI di Thunderbit legge la pagina, suggerisce i campi ed estrae i dati in un paio di clic. Gestisce le sottopagine, si adatta ai cambi di layout e può perfino riassumere, taggare o tradurre i dati mentre li estrae. Esporti su Excel, Google Sheets, Airtable o Notion — senza una sola configurazione tecnica.
Dove Thunderbit dà il meglio di sé:
- Team e-commerce che monitorano SKU e prezzi dei concorrenti
- Team sales che estraggono lead e contatti
- Ricercatori di mercato che aggregano notizie o recensioni
- Agenti immobiliari che raccolgono annunci e dettagli degli immobili
Per lo scraping ad alta frequenza e critico per il business, Thunderbit ti regala un sacco di tempo. Per i progetti su misura, su larga scala o profondamente integrati, lo scripting tradizionale ha ancora il suo posto — ma per la maggior parte dei team, Thunderbit è la via più rapida per passare da “mi servono dati” a “ho i dati”.
Guarda l’estensione Chrome di Thunderbit in azione oppure scopri altri casi d’uso sul blog di Thunderbit.
Prova Thunderbit AI Web Scraper
Riferimento rapido: librerie popolari per il Web Scraping in JavaScript e Node.js
Ecco la tua cheat sheet sull’ecosistema dello scraping in JavaScript nel 2026:
Richieste HTTP
- Axios: client HTTP basato su promesse e ricco di funzioni.
- node-fetch: l’API Fetch per Node.js.
- Got: client HTTP veloce e avanzato.
- SuperAgent: richieste HTTP mature e concatenabili.
- Unirest: client semplice e indipendente dal linguaggio.
Parsing HTML
Contenuti dinamici
- Puppeteer: automazione headless di Chrome.
- Playwright: automazione multibrowser.
- Nightmare: automazione browser su Electron, legacy.
Pianificazione
- node-cron: job cron in Node.js.
CLI e utility
- chalk: stile del testo nel terminale.
- commander: parser per argomenti da CLI.
- inquirer: prompt interattivi da CLI.
- dotenv: caricatore di variabili d’ambiente.
Archiviazione
- fs: file system integrato.
- lowdb: piccolo database JSON locale.
- sqlite3: database SQL locale.
- mongodb: database NoSQL.
Framework
- Crawlee: framework di crawling e scraping di alto livello firmato Apify. La versione JavaScript/TypeScript è alla v3.16 a maggio 2026 ed è il ramo più maturo (il port Python è più recente). Incapsula Puppeteer, Playwright, Cheerio e JSDOM in un’unica API, con rotazione dei proxy e code già pronte — comodo se ti ritrovi a ricostruire sempre la stessa impalcatura attorno agli scraper.
(Controlla sempre documentazione e repository GitHub più recenti per eventuali novità.)
Risorse consigliate per padroneggiare il Web Scraping in JavaScript
Vuoi scavare più a fondo? Ecco una selezione di risorse per affinare le tue competenze di scraping:
Documentazione ufficiale e guide
- MDN Web Docs: Web Scraping
- Documentazione di Puppeteer
- Documentazione di Playwright
- Documentazione di Crawlee
- Apify Web Scraping Academy
Tutorial e corsi
- freeCodeCamp: La guida definitiva al Web Scraping con Node.js
- YouTube: Web Scraping con Node.js (freeCodeCamp)
- DigitalOcean: Come fare scraping di un sito web con Node.js e Puppeteer
Progetti open source ed esempi
Community e forum
- Stack Overflow: Web Scraping
- Reddit: r/webscraping
- Discord della community di Apify
- Blog di Thunderbit
Libri e guide complete
- “Web Scraping with Python” di O’Reilly (per i concetti trasversali tra linguaggi)
- Corsi Udemy/Coursera: “Web Scraping in Node.js”
(Controlla sempre edizioni e aggiornamenti più recenti.)
Come fare scraping di qualsiasi sito web usando l’AI Get Started Free
Conclusione: scegliere l’approccio giusto per il tuo team
Ecco il punto. JavaScript e Node.js ti mettono in mano una potenza e una flessibilità fuori scala per il web scraping. Puoi costruire qualunque cosa, dallo script improvvisato al crawler robusto e scalabile. Ma a grande potere… corrisponde grande manutenzione. Lo scripting tradizionale è la scelta giusta per i progetti su misura, molto tecnici e dove ti serve pieno controllo — a patto di essere pronto a occuparti della manutenzione continua.
Per tutti gli altri — business user, analisti, marketer e chiunque voglia solo i dati — le soluzioni no-code moderne come Thunderbit sono una boccata d’aria. L’estensione Chrome di Thunderbit, mossa dall’AI, ti fa estrarre, strutturare ed esportare i dati in minuti, non in giorni. Niente codice, niente selettori, niente stress.
Quindi, qual è l’approccio giusto? Se il tuo team ha le competenze ingegneristiche e requisiti particolari, tuffati nel toolbox di Node.js. Se invece cerchi velocità, semplicità e la libertà di concentrarti sulle informazioni e non sull’infrastruttura, prova Thunderbit. In entrambi i casi, il web è il tuo database: vai a prenderti quei dati.
E se mai dovessi impallarti, ricorda: anche i migliori scraper sono partiti da una pagina vuota e da una tazza di caffè bello carico. Buono scraping.
Vuoi saperne di più sullo scraping basato su AI o vedere Thunderbit in azione?
- Sito ufficiale di Thunderbit
- Scarica l’estensione Chrome di Thunderbit
- Blog di Thunderbit
- Come fare scraping di qualsiasi sito web usando l’AI
- Che cos’è il data scraping e come farlo nel 2025
Se hai domande, storie o i tuoi racconti dell’orrore preferiti sullo scraping, lascia un commento o scrivimi. Adoro vedere come ognuno trasforma il web nel proprio parco giochi di dati.
Resta curioso, resta caffeinato e continua a fare scraping in modo più intelligente, non più faticoso.
Scarica l’estensione Chrome di Thunderbit
Prova AI Web Scraper Get Started Free
FAQ:
1. Perché usare JavaScript e Node.js per il web scraping nel 2025?
Perché la maggior parte dei siti moderni è costruita con JavaScript. Node.js è veloce, a suo agio con l’asincronia e con un ecosistema ricchissimo (Axios, Cheerio, Puppeteer e compagnia) che copre tutto: dalle semplici richieste allo scraping di contenuti dinamici su larga scala.
2. Qual è il flusso di lavoro tipico per fare scraping di un sito con Node.js?
Di solito questo:
Richiesta → Gestione della risposta → (Esecuzione JS opzionale) → Parsing HTML → Estrazione dati → Salvataggio o esportazione
Ogni passaggio può essere affidato a uno strumento dedicato come axios, cheerio o puppeteer.
3. Come si estraggono le pagine dinamiche renderizzate in JavaScript?
Con browser headless come Puppeteer o Playwright. Caricano la pagina completa, JavaScript incluso, così puoi estrarre ciò che gli utenti vedono davvero.
4. Quali sono le sfide più grandi dello scraping tradizionale?
- Cambiamenti nella struttura del sito
- Rilevamento anti-bot
- Consumo di risorse del browser
- Pulizia manuale dei dati
- Manutenzione pesante nel tempo
Tutto questo rende difficile tenere lo scraping su larga scala sostenibile, o lo rende poco adatto a chi non sviluppa.
5. Quando dovrei usare qualcosa come Thunderbit invece del codice?
Quando ti servono velocità e semplicità e non hai voglia di scrivere o mantenere codice. È ideale per i team sales, marketing o ricerca che vogliono estrarre e strutturare dati in fretta — soprattutto da siti complessi o multi-pagina.




