
Nel 2025, i dati che si trovano online non sono più solo un “di più”: sono il vero carburante che fa girare le strategie delle aziende. Dai giganti dell’e-commerce che tengono d’occhio i prezzi dei rivali in tempo reale ai team commerciali che riempiono i loro database con nuovi contatti, le imprese trattano i dati pubblici del web come se fossero oro digitale. I numeri parlano chiaro: quasi , e oltre . Anche se tutti parlano di Python, , soprattutto in ambito enterprise dove affidabilità e integrazione sono la base.
 Dopo anni passati nel mondo SaaS e dell’automazione, ho visto con i miei occhi come lo scraping web in Java possa davvero cambiare il modo di lavorare delle aziende. Ma ho anche visto team bloccarsi tra codice complicato e siti pieni di trappole anti-bot. Ecco perché ho preparato questa guida pratica e aggiornata per dominare l’estrattore web in Java nel 2025, con un occhio di riguardo a come integrare codice e strumenti AI moderni come . Che tu sia uno sviluppatore, un responsabile operativo o semplicemente qualcuno che vuole i dati senza troppi grattacapi, questa guida fa al caso tuo.
Dopo anni passati nel mondo SaaS e dell’automazione, ho visto con i miei occhi come lo scraping web in Java possa davvero cambiare il modo di lavorare delle aziende. Ma ho anche visto team bloccarsi tra codice complicato e siti pieni di trappole anti-bot. Ecco perché ho preparato questa guida pratica e aggiornata per dominare l’estrattore web in Java nel 2025, con un occhio di riguardo a come integrare codice e strumenti AI moderni come . Che tu sia uno sviluppatore, un responsabile operativo o semplicemente qualcuno che vuole i dati senza troppi grattacapi, questa guida fa al caso tuo.
Cos’è il Java Web Scraping? Spiegato semplice
Facciamo chiarezza: Java web scraping vuol dire semplicemente usare Java per estrarre in automatico informazioni dai siti web. Immagina di avere un assistente virtuale super veloce che legge migliaia di pagine online e ti copia i dati che ti servono in un foglio Excel—ma questo assistente non si stanca mai, non sbaglia e va alla velocità della tua connessione.
Ecco come funziona, in parole povere:
- Manda una richiesta a un sito web (come quando navighi da browser).
- Scarica il contenuto HTML (il codice della pagina).
- Analizza quell’HTML in una struttura che il programma capisce.
- Estrae i dati che ti interessano (tipo nomi prodotti, prezzi, email).
- Salva i risultati in un formato comodo—CSV, Excel, database o Google Sheets.
Non serve essere dei maghi del codice per capire le basi. Con gli strumenti giusti e qualche dritta, anche chi lavora in business può automatizzare la raccolta dati e trasformare pagine web caotiche in informazioni utili.
Perché il Java Web Scraping è fondamentale per le aziende nel 2025
Lo scraping web non è più un passatempo da nerd: è una vera necessità strategica. Vediamo come le aziende usano l’estrattore web in Java per ottenere vantaggi concreti e perché conviene davvero.
| Caso d’uso Web Scraping | Benefici aziendali (ROI) | Settori di esempio |
|---|---|---|
| Monitoraggio prezzi concorrenti | Intelligence sui prezzi in tempo reale; aumento vendite del 20%+ grazie a reazioni rapide al mercato | E-commerce, Retail |
| Lead generation & Sales Intelligence | Liste di prospect aggiornate automaticamente; 70% di tempo risparmiato nella ricerca manuale | B2B Sales, Marketing, Recruiting |
| Analisi di mercato & trend | Individuazione precoce dei trend; 5–15% di ricavi in più e 10–20% di ROI marketing superiore | Prodotti di consumo, Agenzie Marketing |
| Dati finanziari & investimenti | Dati alternativi per il trading; mercato da oltre 5 miliardi $ per i dati “alt-data” estratti dal web | Finanza, Hedge Fund, Fintech |
| Automazione & monitoraggio processi | Raccolta dati di routine automatizzata; 73% di risparmio costi e 85% di implementazione più rapida | Real Estate, Supply Chain, Pubblica Amm. |
()
Perché Java? Perché è pensato per scalare, è affidabile e si integra facilmente. Tante pipeline dati aziendali sono già in Java, quindi aggiungere un estrattore web è naturale. In più, il multithreading e la gestione degli errori di Java lo rendono perfetto per grandi volumi—parliamo di migliaia di pagine al giorno, non solo qualche decina.
Come funziona il Java Web Scraping? Principi base e vantaggi unici
Ecco come si costruisce un tipico estrattore web in Java:
- Richieste HTTP: Java usa librerie come JSoup o Apache HttpClient per recuperare le pagine. Puoi impostare header, usare proxy e simulare browser veri per evitare blocchi.
- Parsing HTML: Librerie come JSoup trasformano l’HTML in un “DOM” (una struttura ad albero), così puoi trovare facilmente i dati con i selettori CSS.
- Estrazione dati: Definisci regole (tipo “prendi tutti gli elementi
<span class='price'>”) per estrarre le info che ti servono. - Salvataggio dati: Esporta i risultati in CSV, Excel, JSON o direttamente in un database.
Cosa rende Java speciale per il web scraping?
- Multithreading: Java può processare tante pagine in parallelo, accelerando di brutto le operazioni su larga scala. Il GIL di Python può essere un limite, ma i thread di Java sono davvero efficienti.
- Performance: Essendo compilato, Java gestisce senza problemi lavori pesanti e uso intenso di memoria.
- Integrazione aziendale: Gli estrattori Java si collegano facilmente a sistemi già esistenti—CRM, ERP, database—senza soluzioni complicate.
- Gestione errori: Il tipaggio forte e la gestione delle eccezioni rendono i progetti di scraping più robusti e facili da mantenere nel tempo.
Se gestisci pipeline dati critiche, la stabilità e la scalabilità di Java sono una garanzia.
Librerie e framework Java per Web Scraping: quali scegliere e perché
Ci sono tante librerie Java per il web scraping, ma tre sono le più usate in azienda: JSoup, HtmlUnit e Selenium. Ecco come si confrontano:
| Libreria | Gestisce JavaScript? | Facilità d’uso | Performance | Ideale per |
|---|---|---|---|---|
| JSoup | ❌ (No JS) | Molto facile | Alta | Pagine statiche, task rapidi, lavori leggeri |
| HtmlUnit | ⚠️ Parziale | Media | Media | JS semplice, form, scraping headless |
| Selenium | ✅ Sì (Completo) | Media/Difficile | Più bassa | Siti JS complessi, pagine dinamiche/interattive |
()
JSoup: la scelta rapida per il parsing HTML
è la mia prima scelta per la maggior parte dei lavori di scraping. Leggero, facile da usare e perfetto per pagine statiche dove i dati sono già nell’HTML.
Esempio:
1Document doc = Jsoup.connect("https://www.scrapingcourse.com/ecommerce/").get();
2String bannerTitle = doc.select("div.site-title").text();
3System.out.println("Banner: " + bannerTitle);Semplice e diretto. Se devi estrarre post di blog, elenchi prodotti o directory senza JavaScript, JSoup è l’ideale.
HtmlUnit: simulare un browser per compiti più complessi
è un browser headless scritto in Java. Gestisce un po’ di JavaScript, può compilare form e cliccare bottoni—tutto senza aprire una finestra vera.
Quando usarlo: Se devi fare login o gestire contenuti dinamici semplici, ma vuoi evitare la complessità di Selenium.
Esempio:
1WebClient webClient = new WebClient();
2HtmlPage page = webClient.getPage("https://example.com/login");
3// ... compila il form e invia ...Selenium: per siti dinamici e interattivi
è il top di gamma. Controlla un vero browser (Chrome, Firefox, ecc.), quindi può gestire qualsiasi sito, anche quelli interamente in JavaScript.
Quando usarlo: Per scraping di web app moderne, siti con infinite scroll o che richiedono interazione come un utente vero.
Esempio:
1WebDriver driver = new ChromeDriver();
2driver.get("https://www.scrapingcourse.com/ecommerce/");
3List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
4// ... estrai i dati ...
5driver.quit();Potenzia il Java Web Scraping con Thunderbit: automazione visuale e codice insieme
Qui si entra nel vivo—soprattutto per chi non vuole passare le giornate a scrivere codice. è un Estrattore Web AI che ti permette di impostare visivamente le attività di scraping (direttamente dal browser) ed esportare i dati su Excel, Google Sheets, Airtable o Notion.
Perché usare Thunderbit insieme a Java?
- Campi suggeriti dall’AI: La funzione “AI Suggest Fields” di Thunderbit legge la pagina e ti consiglia cosa estrarre—senza dover cercare nell’HTML o scrivere selettori.
- Estrazione da sottopagine: Vuoi più dettagli? Thunderbit può visitare automaticamente ogni sottopagina (tipo le schede prodotto) e arricchire il tuo dataset.
- Template pronti: Per siti famosi (Amazon, Zillow, LinkedIn), Thunderbit offre template già pronti—basta un click.
- Esportazione facile: Una volta estratti, i dati si esportano in pochi secondi—pronti per essere processati dal tuo codice Java.
Thunderbit è un enorme risparmio di tempo per prototipare, gestire siti complessi o permettere anche a chi non è sviluppatore di ottenere i dati che servono. E per i developer, è perfetto per delegare le parti più ripetitive o fragili dello scraping, così puoi concentrarti sulla logica di business.
Come combinare Thunderbit e Java per progetti avanzati
Ecco un flusso di lavoro che consiglio:
- Prototipa con Thunderbit: Usa l’estensione Chrome per configurare lo scraping in modo visuale. Lascia che l’AI suggerisca i campi, gestisca la paginazione ed esporta i dati su Google Sheets o CSV.
- Processa in Java: Scrivi codice Java per leggere i dati esportati (da Sheets, CSV o Airtable), poi esegui post-processing, analisi o integrazione con i sistemi aziendali.
- Automatizza e pianifica: Usa il pianificatore integrato di Thunderbit per mantenere i dati aggiornati e fai in modo che la pipeline Java recuperi automaticamente gli ultimi export.
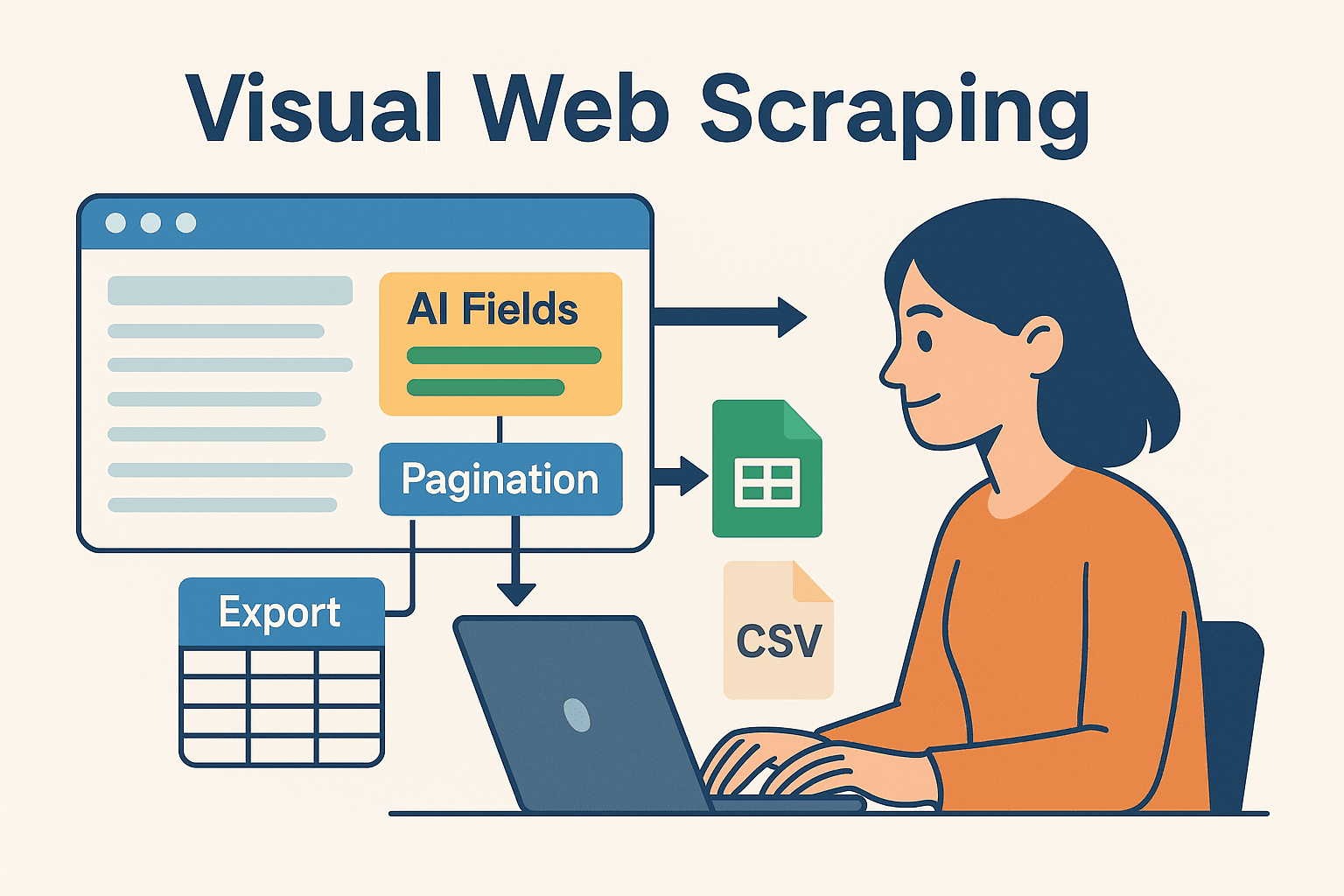 Questo approccio ibrido ti dà il meglio di entrambi i mondi: la velocità e flessibilità dello scraping AI no-code, più la potenza e affidabilità di Java per l’elaborazione successiva.
Questo approccio ibrido ti dà il meglio di entrambi i mondi: la velocità e flessibilità dello scraping AI no-code, più la potenza e affidabilità di Java per l’elaborazione successiva.
Guida pratica: crea il tuo primo Java Web Scraper
Passiamo alla pratica. Ecco come costruire da zero un semplice estrattore web in Java.
Configura l’ambiente Java
- Installa Java (JDK): Consigliato Java 17 o 21 per la massima compatibilità.
- Configura Maven: Gestisce le dipendenze in automatico.
- Scegli un IDE: IntelliJ IDEA, Eclipse o VSCode vanno benissimo.
- Aggiungi JSoup al tuo
pom.xml:1<dependency> 2 <groupId>org.jsoup</groupId> 3 <artifactId>jsoup</artifactId> 4 <version>1.16.1</version> 5</dependency>
Scrivi ed esegui il tuo scraper
Supponiamo di voler estrarre nomi e prezzi dei prodotti da un sito demo e-commerce.
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3import org.jsoup.select.Elements;
4import org.jsoup.nodes.Element;
5public class ProductScraper {
6 public static void main(String[] args) {
7 String url = "https://www.scrapingcourse.com/ecommerce/";
8 try {
9 Document doc = Jsoup.connect(url)
10 .userAgent("Mozilla/5.0")
11 .get();
12 Elements productElements = doc.select("li.product");
13 for (Element productEl : productElements) {
14 String name = productEl.selectFirst("h2").text();
15 String price = productEl.selectFirst("span.price").text();
16 System.out.println(name + " -> " + price);
17 }
18 } catch (Exception e) {
19 e.printStackTrace();
20 }
21 }
22}Consiglio: imposta sempre uno user-agent per simulare un browser vero. Alcuni siti bloccano il default di Java.
Esporta e utilizza i tuoi dati
- Esportazione CSV: Usa
FileWritero una libreria come OpenCSV per scrivere i risultati su file CSV. - Esportazione Excel: Usa Apache POI per file .xls/.xlsx.
- Integrazione database: Usa JDBC per inserire i dati direttamente nel database.
- Google Sheets: Esporta da Thunderbit e leggi i dati con le API Google Sheets di Java.
Come superare le sfide più comuni del Java Web Scraping
Fare scraping non è sempre una passeggiata. Ecco i problemi più frequenti—e come risolverli:
- Blocchi IP & rate limiting: Rallenta le richieste (
Thread.sleep()), ruota i proxy e randomizza i tempi. Per grandi volumi, usa servizi di proxy. - CAPTCHA & anti-bot: Usa Selenium per simulare il comportamento umano o affidati ad API anti-bot. A volte, lo scraping cloud di Thunderbit può aggirare questi ostacoli.
- Contenuti dinamici: Se JSoup restituisce risultati vuoti, probabilmente i dati sono caricati via JavaScript. Passa a Selenium o HtmlUnit, oppure cerca l’API sottostante del sito.
- Cambiamenti nella struttura del sito: Scrivi codice flessibile con selettori adattabili. Monitora i tuoi scraper e aggiornali quando i siti cambiano. L’AI di Thunderbit si adatta rapidamente: basta rilanciare “AI Suggest Fields”.
- Gestione sessioni: Per scraping autenticato, gestisci con attenzione cookie e sessioni. Selenium e Thunderbit (quando sei loggato su Chrome) gestiscono bene le pagine protette.
Consigli avanzati per aumentare l’efficienza del Java Web Scraping
Vuoi portare il tuo scraping a un altro livello? Ecco qualche trucco da professionista:
- Multithreading: Usa
ExecutorServicedi Java per processare più pagine in parallelo. Ma non esagerare, o rischi di essere bloccato! - Scheduling: Usa Quartz Scheduler in Java, oppure lascia che Thunderbit pianifichi in cloud con comandi in linguaggio naturale (“ogni lunedì alle 9”).
- Scalabilità cloud: Per lavori enormi, esegui browser headless in cloud o distribuisci i task su più macchine.
- Workflow ibridi: Usa Thunderbit per i siti più complessi e il codice Java per il resto. Unisci i risultati nel tuo data warehouse.
- Monitoraggio & logging: Sfrutta i framework di logging Java per monitorare la salute degli scraper, intercettare errori e ricevere alert in caso di problemi.
Conclusioni e punti chiave
I dati web sono il nuovo oro, e Java resta uno degli strumenti più affidabili—soprattutto per chi cerca scalabilità, integrazione e stabilità. Il flusso di lavoro è semplice: recupera, analizza, estrai e salva. Con librerie come JSoup, HtmlUnit e Selenium puoi gestire tutto, dai semplici elenchi ai siti più dinamici.
Ma non serve fare tutto a mano. Strumenti come portano l’AI e l’automazione visuale nel mix, permettendoti di prototipare, adattare e scalare i tuoi progetti di scraping più velocemente che mai. Il mio consiglio? Sfrutta sia il codice che il no-code. Usa Thunderbit per la configurazione rapida e la manutenzione, poi lascia che Java gestisca l’elaborazione pesante.
Vuoi vedere come Thunderbit può rivoluzionare il tuo workflow? e prova a estrarre dati dal tuo primo sito in pochi minuti. E se vuoi approfondire, visita il per guide, tutorial e novità sull’automazione del web scraping.
Buon scraping—che i tuoi dati siano sempre ordinati, aggiornati e pronti all’uso.
Domande frequenti
1. Java è ancora valido per il web scraping nel 2025?
Assolutamente sì. Python è ottimo per script rapidi, ma Java resta la scelta preferita per progetti enterprise, affidabili e di lunga durata—soprattutto dove contano integrazione e multithreading.
2. Quando usare JSoup, HtmlUnit o Selenium?
JSoup per pagine statiche, HtmlUnit per contenuti dinamici semplici o form, Selenium per siti complessi o interattivi. Scegli lo strumento in base alla complessità del sito.
3. Come evitare di essere bloccati durante lo scraping?
Rallenta le richieste, usa proxy rotanti, imposta user-agent realistici e simula il comportamento umano. Per siti difficili, valuta lo scraping cloud di Thunderbit o API anti-bot.
4. Thunderbit e Java possono lavorare insieme?
Certo. Usa Thunderbit per definire e pianificare scraping in modo visuale, esporta i dati e poi processali o integrali con il tuo codice Java. È una combinazione potente sia per business user che per sviluppatori.
5. Qual è il modo più veloce per iniziare con il Java web scraping?
Configura Java e Maven, aggiungi JSoup e prova a estrarre dati da un sito semplice. Per lavori più complessi o prototipazione rapida, installa e lascia che l’AI faccia il lavoro pesante—poi integra i risultati nel tuo workflow Java.
Vuoi altri consigli, esempi di codice o trucchi di automazione? Dai un’occhiata al o iscriviti al nostro per tutorial pratici e tutte le novità sull’estrattore web. Scopri di più