

C’è qualcosa di intramontabile nell’aprire un terminale, digitare un solo comando e vedere i dati web grezzi arrivare a cascata, quasi come se avessi appena aperto la Matrix. Per sviluppatori e utenti tecnici esperti, cURL è proprio questa bacchetta magica: uno strumento da riga di comando discreto che lavora in silenzio su miliardi di dispositivi, dai server cloud al frigorifero smart. E ancora nel 2026, con tutti gli strumenti no-code e di scraping con AI che ci sono in giro, il web scraping con cURL resta una scelta di riferimento per chi cerca velocità, controllo e possibilità di scripting.
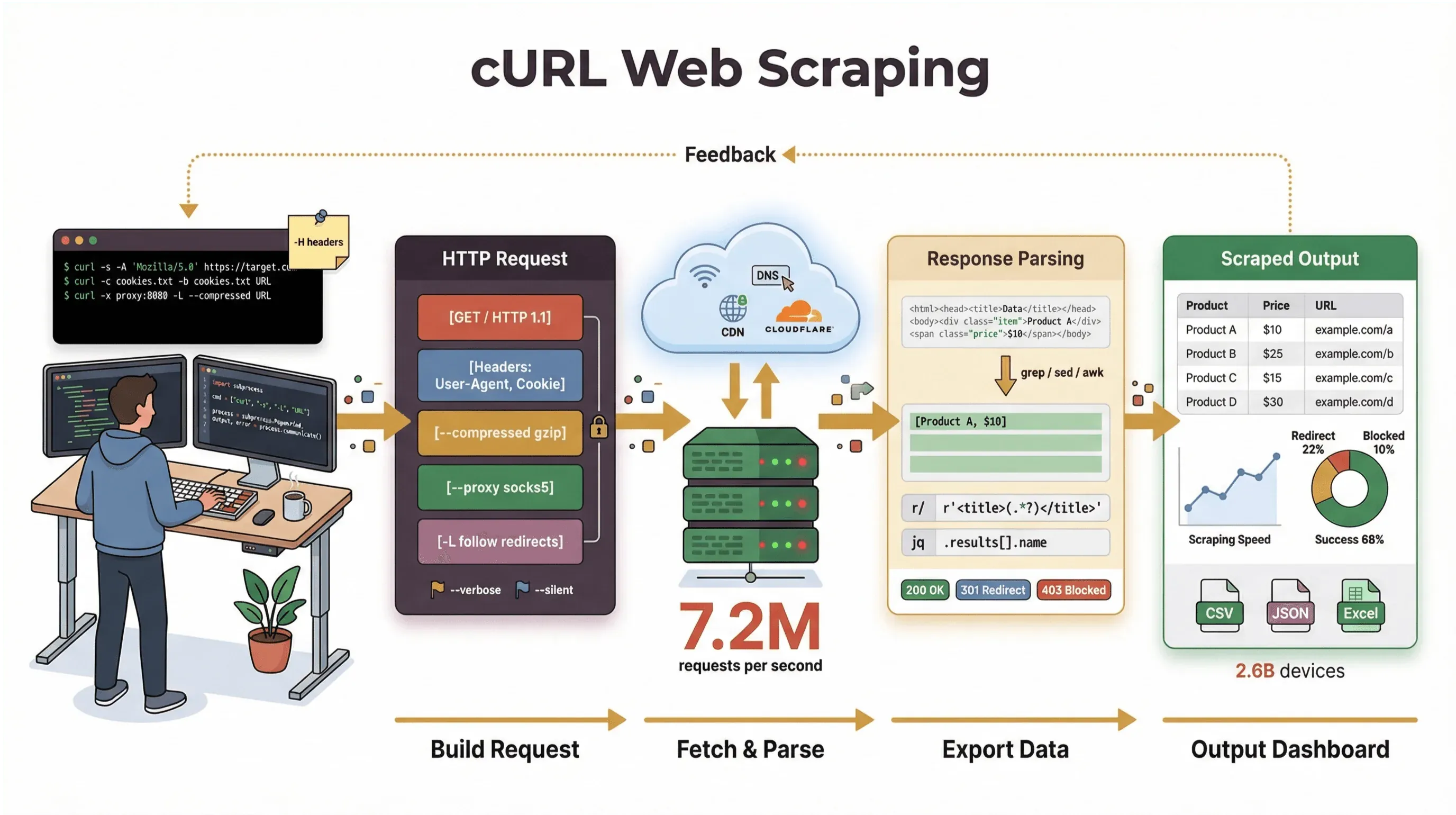 Ho passato anni a creare strumenti di automazione e ad aiutare i team a gestire dati web, e continuo a usare cURL quando devo recuperare una pagina, fare debug di un’API o prototipare un flusso di scraping. In questa guida ti accompagnerò in un tutorial di web scraping con cURL che copre sia le basi sia i trucchi da professionisti, con esempi di comandi reali, consigli pratici e uno sguardo lucido su dove cURL brilla davvero e dove invece si ferma. E se sei più un utente business che preferisce non mettere mano alla riga di comando, ti mostrerò come Thunderbit, il nostro estrattore web con AI, può portarti da “mi servono questi dati” a “ecco il mio foglio di calcolo” in due clic, senza bisogno di codice.
Ho passato anni a creare strumenti di automazione e ad aiutare i team a gestire dati web, e continuo a usare cURL quando devo recuperare una pagina, fare debug di un’API o prototipare un flusso di scraping. In questa guida ti accompagnerò in un tutorial di web scraping con cURL che copre sia le basi sia i trucchi da professionisti, con esempi di comandi reali, consigli pratici e uno sguardo lucido su dove cURL brilla davvero e dove invece si ferma. E se sei più un utente business che preferisce non mettere mano alla riga di comando, ti mostrerò come Thunderbit, il nostro estrattore web con AI, può portarti da “mi servono questi dati” a “ecco il mio foglio di calcolo” in due clic, senza bisogno di codice.
Tuffiamoci e vediamo perché cURL è ancora rilevante per il web scraping nel 2026, come usarlo in modo efficace e quando è il momento di passare a qualcosa di ancora più potente.
Che cos’è cURL? La base del web scraping con cURL
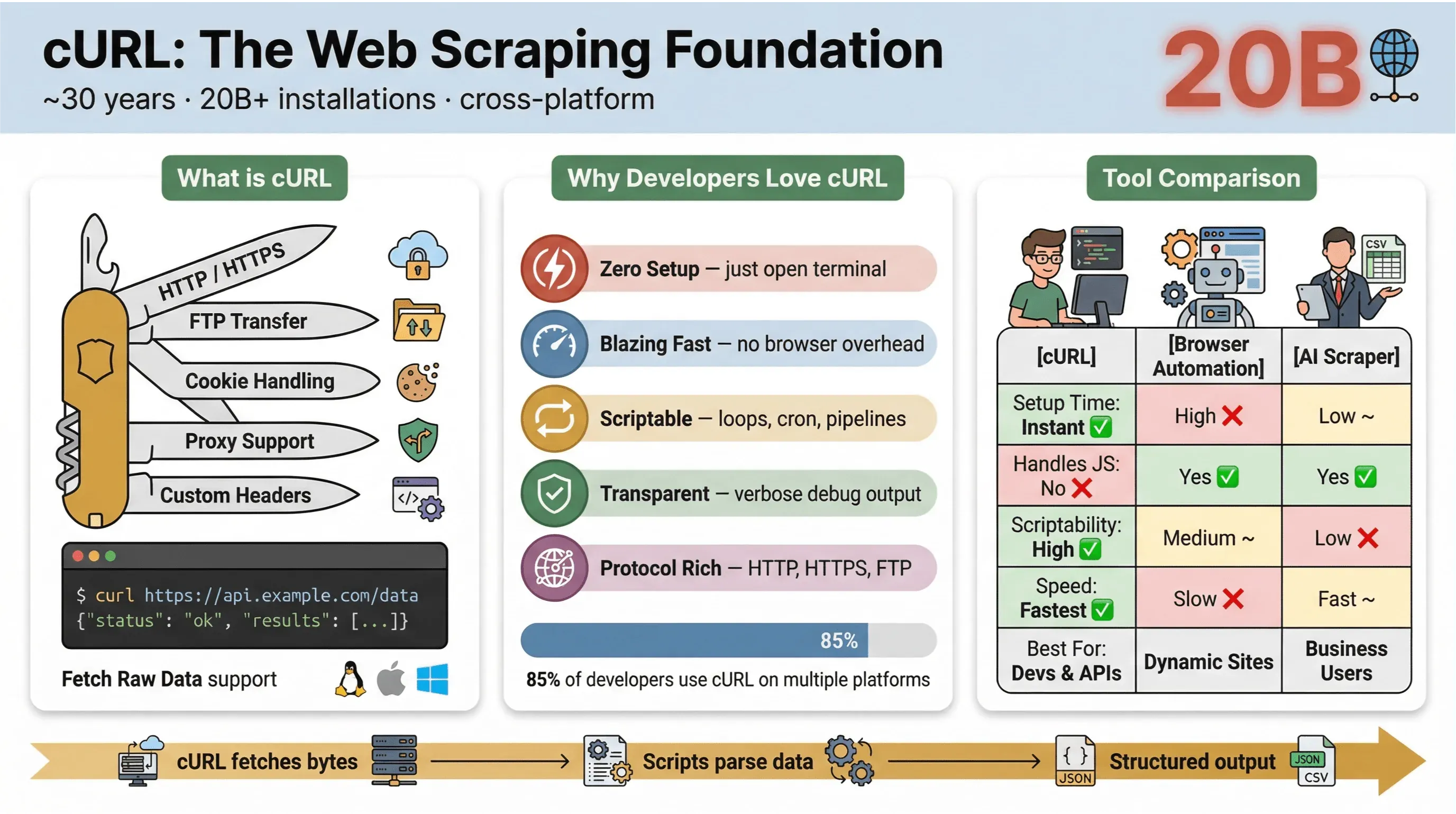
Alla base, cURL è uno strumento da riga di comando e una libreria per trasferire dati tramite URL. Esiste da quasi 30 anni, sul serio, ed è ovunque: integrato nei sistemi operativi, alla base di script e impegnato silenziosamente a gestire trasferimenti di dati in oltre venti miliardi di installazioni. Se ti è mai capitato di eseguire un comando veloce per recuperare una pagina web, testare un’API o scaricare un file, è molto probabile che tu abbia già usato cURL.
 Ecco perché cURL è così popolare per il web scraping:
Ecco perché cURL è così popolare per il web scraping:
- Leggero e multipiattaforma: funziona su Linux, macOS, Windows e persino su dispositivi embedded.
- Supporto per i protocolli: gestisce HTTP, HTTPS, FTP e altro ancora.
- Adatto allo scripting: perfetto per automazione, cron job e codice di collegamento.
- Non richiede interazione dell’utente: progettato per l’uso non interattivo, ottimo per elaborazioni batch e pipeline.
Ma chiariamolo bene: il compito principale di cURL è recuperare dati grezzi, HTML, JSON, immagini, insomma tutto. Non li analizza, non li renderizza e non li struttura per te. Pensa a cURL come al “primo miglio” del web scraping: ti porta i byte, ma per trasformarli in informazioni strutturate ti serviranno altri strumenti, come script Python, grep/sed/awk o un estrattore web con AI.
Se vuoi consultare la documentazione ufficiale, dai un’occhiata alla guida di cURL allo scripting HTTP.
Perché usare cURL per il web scraping? (tutorial di web scraping con cURL)
Allora perché sviluppatori e utenti tecnici continuano a tornare a cURL per il web scraping, anche con tutti i nuovi strumenti disponibili? Ecco cosa lo rende così utile:
- Configurazione minima: niente installazioni, nessuna dipendenza, basta aprire il terminale e partire.
- Velocità: recupera i dati all’istante, senza aspettare che si apra un browser.
- Adatto allo scripting: puoi ciclare facilmente sugli URL, automatizzare richieste e concatenare comandi.
- Supporto per protocolli e funzionalità: gestisce cookie, proxy, redirect, intestazioni personalizzate e molto altro.
- Trasparenza: vedi esattamente cosa succede grazie all’output verbose e di debug.
Nel sondaggio utenti cURL 2025, l’85,7% degli intervistati ha dichiarato di usare lo strumento da riga di comando cURL, e il 96,2% ha detto di usarlo su Linux, ancora la piattaforma principale per cURL, con un margine enorme.
--- È ancora il coltellino svizzero per richieste HTTP, estrazioni rapide di dati e troubleshooting.
Ecco un rapido confronto tra cURL e altri metodi di scraping:
| Funzionalità | cURL | Automazione browser (ad es. Selenium) | Estrattore Web AI (ad es. Thunderbit) |
|---|---|---|---|
| Tempo di configurazione | Istantaneo | Alto | Basso |
| Adatto allo scripting | Alto | Medio | Basso (non serve codice) |
| Gestisce JavaScript | No | Sì | Sì (Thunderbit: tramite browser) |
| Supporto cookie/sessione | Manuale | Automatico | Automatico |
| Strutturazione dei dati | Manuale (da analizzare dopo) | Manuale (da analizzare dopo) | Basata su AI/modello |
| Ideale per | Sviluppatori, estrazioni rapide | Siti complessi e dinamici | Utenti business, esportazione strutturata |
In breve: cURL è imbattibile per estrazioni rapide e scriptabili, soprattutto per pagine statiche, API o quando vuoi automatizzare flussi semplici. Ma non appena hai bisogno di analizzare HTML complesso, gestire JavaScript o esportare dati strutturati, ti servirà qualcosa di più specializzato.
Per iniziare: esempi di comandi base per il web scraping con cURL
Passiamo alla pratica. Ecco come usare cURL per attività base di web scraping, passo dopo passo.
Recuperare HTML grezzo con cURL
Il caso d’uso più semplice: prendere l’HTML di una pagina web.
curl https://books.toscrape.com/
Questo comando recupera la homepage di Books to Scrape, un sito demo pubblico per il web scraping. Vedrai l’output HTML grezzo nel terminale: cerca tag come <title> o frammenti come “In stock”.
Salvare l’output in un file
Vuoi salvare quell’HTML per analizzarlo in seguito? Usa il flag -o:
curl -o page.html https://books.toscrape.com/
Ora avrai un file page.html con l’intero contenuto HTML. È perfetto per fare ulteriori analisi o per il parsing con altri strumenti.
Inviare richieste POST con cURL
Devi inviare un modulo o interagire con un’API? Usa il flag -d per le richieste POST. Ecco un esempio con httpbin, un sito pensato per il testing HTTP:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
Riceverai una risposta JSON che restituisce i dati inviati, ottima per test e prototipazione.
Ispezionare gli header e fare debug
A volte vuoi vedere gli header della risposta o fare debug della richiesta:
-
Solo header (richiesta HEAD):
curl -I https://books.toscrape.com/ -
Includere gli header nel corpo:
curl -i https://httpbin.org/get -
Output verbose/di debug:
curl -v https://books.toscrape.com/
Questi flag ti aiutano a capire cosa succede sotto il cofano, ed è fondamentale per il troubleshooting.
Ecco una tabella di riferimento rapida per questi comandi:
| Attività | Esempio di comando | Note |
|---|---|---|
| Recuperare HTML | curl URL | Mostra l’HTML nel terminale |
| Salvare su file | curl -o file.html URL | Scrive l’output in un file |
| Ispezionare gli header | curl -I URL oppure curl -i URL | -I solo HEAD, -i include gli header con il corpo |
| Inviare dati di form | curl -d "a=1&b=2" URL | Invia dati codificati come form |
| Debug richiesta/risposta | curl -v URL | Mostra informazioni dettagliate su richiesta/risposta |
Per altri esempi, consulta la documentazione ufficiale di cURL sullo scripting.
Fai un salto di qualità: web scraping avanzato con cURL (web scraping con cURL)
Quando hai dimestichezza con le basi, cURL apre un mondo di funzionalità avanzate per attività di scraping più complesse.
Gestire cookie e sessioni
Molti siti richiedono i cookie per mantenere le sessioni di accesso o tracciare gli utenti. Con cURL puoi salvare e riutilizzare i cookie tra diverse richieste:
# Salva i cookie dopo il login
curl -c cookies.txt https://example.com/login
# Usa i cookie per le richieste successive
curl -b cookies.txt https://example.com/account
Questo ti permette di simulare le sessioni del browser e accedere a pagine protette da login, purché non ci sia una sfida JavaScript.
Camuffare User-Agent e intestazioni personalizzate
Alcuni siti mostrano contenuti diversi in base al tuo User-Agent o agli header. Per impostazione predefinita, cURL si identifica come “curl/VERSION”, e questo può attivare blocchi o contenuti alternativi. Per imitare un browser:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
Puoi anche impostare header personalizzati, ad esempio le preferenze di lingua:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
Questo ti aiuta a ottenere lo stesso contenuto che vedrebbe un browser reale.
Usare proxy per il web scraping
Devi far passare le richieste attraverso un proxy, per test geografici o per evitare blocchi IP? Usa il flag -x:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Assicurati solo di usare i proxy in modo responsabile e nel rispetto dei termini di servizio del sito.
Automatizzare lo scraping di più pagine
Vuoi fare scraping di più pagine, ad esempio elenchi di prodotti con paginazione? Usa un semplice ciclo shell:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Questo recupera le pagine da 2 a 5 del catalogo Books to Scrape e salva ciascuna in un file separato. (La pagina 1 è la homepage.)
Limiti del web scraping con cURL: cosa devi sapere
Per quanto ami cURL, non è una soluzione miracolosa. Ecco dove mostra i suoi limiti:
- Nessuna esecuzione JavaScript: cURL non può gestire pagine che richiedono JavaScript per renderizzare il contenuto o risolvere sfide anti-bot (developers.cloudflare.com).
- Parsing manuale necessario: ottieni HTML o JSON grezzi, ma dovrai analizzarli da solo, spesso con script o strumenti aggiuntivi.
- Gestione limitata delle sessioni: amministrare login complessi, token o moduli in più passaggi può diventare rapidamente macchinoso.
- Nessuna strutturazione dati integrata: cURL non trasforma le pagine web in righe, tabelle o fogli di calcolo.
- Vulnerabile ai sistemi anti-bot: molti siti usano oggi difese avanzate contro i bot, come JavaScript, fingerprinting e CAPTCHA, che cURL semplicemente non può aggirare (datadome.co).
Ecco una tabella di confronto rapida:
| Limite | Solo cURL | Strumenti moderni di scraping (ad es. Thunderbit) |
|---|---|---|
| Supporto JavaScript | No | Sì |
| Strutturazione dei dati | Manuale | Automatica (AI/modello) |
| Gestione delle sessioni | Manuale | Automatica |
| Superamento anti-bot | Limitato | Avanzato (basato su browser/AI) |
| Facilità d’uso | Tecnico | Non tecnico |
Per pagine statiche e API, cURL è fantastico. Per qualsiasi cosa più dinamica o protetta, dovrai passare a uno strumento più adatto.
Thunderbit vs cURL: il miglior approccio al web scraping per utenti non tecnici
Ora parliamo di Thunderbit, la nostra estensione Chrome per lo scraping web con AI. Se sei un commerciale, un marketer o un professionista operations che vuole semplicemente portare i dati da un sito in Excel, Google Sheets o Notion, senza toccare la riga di comando, Thunderbit è pensato per te.
Ecco come Thunderbit si confronta con cURL:
| Funzionalità | cURL | Thunderbit |
|---|---|---|
| Interfaccia utente | Riga di comando | Point-and-click (estensione Chrome) |
| Suggerimento campi con AI | No | Sì (l’AI legge la pagina e suggerisce le colonne) |
| Gestione paginazione/sottopagine | Scripting manuale | Automatica (l’AI rileva e estrae) |
| Esportazione dati | Manuale (analisi + salvataggio) | Diretta in Excel, Google Sheets, Notion, Airtable |
| Pagine JavaScript/protette | No | Sì (scraping basato su browser) |
| Nessun codice richiesto | No (serve scripting) | Sì (chiunque può usarlo) |
| Piano gratuito | Sempre gratuito | Gratis fino a 6 pagine (10 con bonus prova) |
Con Thunderbit, devi solo aprire l’estensione, fare clic su “AI Suggest Fields” e lasciare che l’AI capisca quali dati estrarre. Puoi fare scraping di tabelle, elenchi, dettagli di prodotto e persino visitare automaticamente le sottopagine. Poi esporti i dati direttamente nei tuoi strumenti aziendali preferiti, senza parsing e senza grattacapi.
Thunderbit è usato con fiducia da oltre 100.000 utenti in tutto il mondo, ed è particolarmente apprezzato dai team di sales, e-commerce e real estate che hanno bisogno di dati strutturati in tempi rapidi.
Prova l’estensione Chrome di Thunderbit per il web scraping
Vuoi provarlo? Scarica qui l’estensione Chrome.
Combinare cURL e Thunderbit: strategie flessibili per il web scraping
Se sei un utente tecnico, non c’è bisogno di scegliere un solo strumento. Anzi, molti team usano cURL e Thunderbit insieme per ottenere la massima flessibilità:
- Prototipa con cURL: usa cURL per testare rapidamente gli endpoint, ispezionare gli header e capire come risponde un sito.
- Fai scalare il lavoro con Thunderbit: quando ti servono dati strutturati, scraping di più pagine o un flusso ripetibile, passa a Thunderbit per l’estrazione point-and-click e le esportazioni dirette.
Ecco un flusso di lavoro di esempio per una ricerca di mercato:
- Usa cURL per recuperare alcune pagine e ispezionare la struttura HTML.
- Identifica i campi dati che ti servono, ad esempio nomi dei prodotti, prezzi e recensioni.
- Apri Thunderbit, fai clic su “AI Suggest Fields” e lascia che l’AI configuri lo scraper.
- Fai scraping di tutte le pagine, comprese sottopagine o liste paginate, ed esporta su Google Sheets.
- Analizza, condividi e agisci sui tuoi dati, senza bisogno di parsing manuale.
Ecco una tabella decisionale rapida:
| Scenario | Usa cURL | Usa Thunderbit | Usa entrambi |
|---|---|---|---|
| Recupero rapido di un’API o pagina statica | ✅ | ||
| Ti servono dati strutturati in un foglio | ✅ | ||
| Debug di header/cookie | ✅ | ||
| Scraping di pagine dinamiche o pesanti di JS | ✅ | ||
| Creare un flusso no-code ripetibile | ✅ | ||
| Prototipare e poi scalare | ✅ | ✅ | Flusso ibrido |
Sfide comuni e ostacoli nel web scraping con cURL
Prima di lanciarti a capofitto con cURL, parliamo delle sfide reali che incontrerai:
- Sistemi anti-bot: molti siti usano oggi difese avanzate, come sfide JavaScript, CAPTCHA e fingerprinting, che cURL non può aggirare (developers.cloudflare.com).
- Problemi di qualità dei dati: cambiamenti nell’HTML, campi mancanti o layout incoerenti possono rompere i tuoi script.
- Costo di manutenzione: ogni volta che un sito cambia, dovrai aggiornare la logica di parsing.
- Rischi legali e di conformità: controlla sempre i termini di servizio del sito, il file robots.txt e le leggi applicabili prima di fare scraping. Il fatto che i dati siano pubblici non significa che siano liberi da usare (calawyers.org, polsinelli.com).
- Limiti di scalabilità: cURL è ottimo per lavori piccoli, ma per scraping su larga scala dovrai gestire proxy, rate limit e gestione degli errori.
Consigli per il troubleshooting e per restare in regola:
- Inizia sempre da siti demo o con permesso, come Books to Scrape.
- Rispetta i rate limit: non martellare gli endpoint.
- Evita di fare scraping di dati personali, a meno che tu non abbia una base giuridica valida.
- Se incontri barriere JavaScript o CAPTCHA, valuta di passare a uno strumento basato su browser come Thunderbit.
Riepilogo passo dopo passo: come fare scraping di siti web con cURL
Ecco la tua checklist di riferimento rapido per il web scraping con cURL:
- Identifica l’URL o gli URL di destinazione: parti da una pagina statica o da un endpoint API.
- Recupera la pagina:
curl URL - Salva l’output in un file:
curl -o file.html URL - Ispeziona gli header/fai debug:
curl -I URL,curl -v URL - Invia dati POST:
curl -d "a=1&b=2" URL - Gestisci cookie/sessioni:
curl -c cookies.txt ...,curl -b cookies.txt ... - Imposta header personalizzati/User-Agent:
curl -A "..." -H "..." URL - Segui i redirect:
curl -L URL - Usa proxy, se necessario:
curl -x proxy:port URL - Automatizza lo scraping di più pagine: usa cicli shell o script.
- Analizza e struttura i dati: usa strumenti/script aggiuntivi se serve.
- Passa a Thunderbit per scraping strutturato, no-code o pagine dinamiche.
Conclusione e punti chiave: scegliere lo strumento giusto per il web scraping
Estrai dati da qualsiasi sito web usando l’AI Get Started Free
Il web scraping con cURL è ancora una competenza potente per gli utenti tecnici nel 2026, soprattutto per estrazioni rapide, prototipazione e automazione. La velocità, la possibilità di scripting e l’ubiquità di cURL lo rendono un elemento fisso nel kit di ogni sviluppatore. Ma con un web sempre più dinamico e protetto, e con utenti business che chiedono dati strutturati senza codice, strumenti come Thunderbit stanno ridefinendo ciò che è possibile.
Punti chiave:
- Usa cURL per pagine statiche, API e prototipi rapidi, soprattutto quando vuoi il pieno controllo.
- Passa a Thunderbit, o a estrattori web AI simili, quando ti servono dati strutturati, pagine dinamiche o pesanti di JavaScript, oppure un flusso di lavoro no-code e adatto al business.
- Combina entrambi per la massima flessibilità: prototipa con cURL, poi scala e struttura con Thunderbit.
- Fai sempre scraping in modo responsabile, rispettando i termini del sito, i rate limit e i limiti legali.
Curioso di vedere quanto può essere semplice il web scraping? Prova l’estensione Chrome gratuita di Thunderbit e prova di persona l’estrazione dati con AI. E se vuoi approfondire, dai un’occhiata al blog di Thunderbit per altri tutorial, consigli e approfondimenti di settore. Potrebbero interessarti anche:
- Come fare scraping di qualsiasi sito web usando l’AI
- Come estrarre dati da un sito web in Excel usando l’AI
- Che cos’è il data scraping e come farlo nel 2025
Buon scraping, e che i tuoi dati siano sempre puliti, strutturati e a un comando, o a un clic, di distanza.
Scopri i piani Thunderbit per uno scraping web scalabile
FAQ
1. cURL può gestire pagine web renderizzate con JavaScript?
No, cURL non può eseguire JavaScript. Recupera l’HTML grezzo così come viene fornito dal server. Se una pagina richiede JavaScript per mostrare il contenuto o per superare sfide anti-bot, cURL non sarà in grado di accedere ai dati. In quei casi, usa strumenti basati su browser come Thunderbit.
2. Come salvo l’output di cURL direttamente in un file?
Usa il flag -o: curl -o filename.html URL. In questo modo il corpo della risposta viene scritto in un file invece di essere mostrato nel terminale.
3. Qual è la differenza tra cURL e Thunderbit per il web scraping?
cURL è uno strumento da riga di comando per recuperare dati web grezzi, ottimo per utenti tecnici e automazione. Thunderbit è un’estensione Chrome con AI, pensata per utenti business che vogliono estrarre dati strutturati da qualsiasi sito, gestire pagine dinamiche ed esportare direttamente in strumenti come Excel o Google Sheets, senza bisogno di codice.
4. È legale fare scraping di siti web con cURL?
In generale, negli Stati Uniti lo scraping di dati pubblici è legale, secondo recenti decisioni dei tribunali, ma dovresti sempre controllare i termini di servizio del sito, il file robots.txt e le leggi applicabili. Evita di fare scraping di dati personali o protetti senza autorizzazione e rispetta i rate limit e le linee guida etiche (calawyers.org, polsinelli.com).
5. Quando dovrei passare da cURL a uno strumento più avanzato come Thunderbit?
Se devi fare scraping di pagine dinamiche o pesanti di JavaScript, vuoi dati strutturati in un foglio di calcolo, oppure preferisci un flusso no-code, Thunderbit è la scelta migliore. Usa cURL per attività rapide e tecniche; usa Thunderbit per un’estrazione dati ripetibile e adatta al business.
Per altri consigli e tutorial sul web scraping, visita il blog di Thunderbit oppure il nostro canale YouTube.
Prova Thunderbit AI Web Scraper Get Started Free




