
Siamo sinceri: se hai mai provato a mettere le mani sui dati aziendali, probabilmente ti sei imbattuto nel dibattito “web scraping vs. data mining”. Ho visto team girare in tondo: da una parte c’era chi voleva raccogliere ogni minima informazione dal web, dall’altra chi voleva analizzarla per ottenere insight profondi, e a volte finiva che tutti fissavano un foglio di calcolo chiedendosi: “Aspetta, ma cosa stiamo facendo esattamente?” Se ti suona familiare, non sei il solo.
Da qualcuno che ha passato anni a costruire SaaS e strumenti di automazione (e che oggi è cofondatore di ), ho visto questa confusione ovunque: dai reparti sales alle sale riunioni del management. Quindi, facciamo chiarezza e andiamo al concreto: qual è davvero la differenza tra web scraping e data mining, chi usa cosa e — soprattutto — come puoi farli lavorare insieme per ottenere risultati per il tuo team?
Web Scraping vs. Data Mining: definizioni rapide per team sempre di corsa
Partiamo dalle basi, senza tirare in ballo dizionari tecnici.
- Web scraping: è il processo di raccolta dei dati dai siti web. Pensalo come un modo automatizzato di fare copia-incolla dalle pagine web a un foglio di calcolo. Gli strumenti di estrazione dati dal web analizzano le pagine, estraggono informazioni specifiche (come prezzi dei prodotti, nomi di aziende o articoli) e le organizzano in un formato strutturato (righe e colonne). In questa fase non c’è ancora analisi: l’obiettivo è ottenere i dati grezzi di cui hai bisogno.
- Data mining: qui entra in gioco la parte interessante, cioè il valore reale, una volta ottenuti i dati. Il data mining consiste nell’analizzare dataset — usando statistica, algoritmi o AI — per far emergere tendenze, pattern e insight. È come prendere quel enorme foglio di calcolo e capire cosa significa: segmentare i clienti, prevedere le vendite o individuare frodi.
L’analogia che uso sempre:
Il web scraping è fare la spesa e raccogliere gli ingredienti; il data mining è cucinarli per trasformarli in un pasto. Ti servono entrambi se vuoi che la cena sia qualcosa di più di una semplice pila di alimenti.
Chi usa il web scraping e chi usa il data mining — e perché?
Qui le cose si fanno interessanti. La differenza non è solo “raccolta vs. analisi”: riguarda chi fa cosa e con quale obiettivo.
Chi usa il web scraping?
Utenti tipici:
- Team sales (creazione di liste di lead, raccolta di contatti)
- Team marketing (market intelligence, monitoraggio dei competitor)
- Operations (monitoraggio prezzi, insight sulla supply chain)
- Team di ricerca (real estate, finanza, ecc.)
Obiettivo:
Ottenere dati freschi ed esterni, in fretta. Che si tratti di estrarre migliaia di prezzi di prodotti, fare scraping di LinkedIn per trovare lead o monitorare i lanci dei competitor, queste persone hanno bisogno di informazioni aggiornate per alimentare le decisioni quotidiane (, ).
Chi usa il data mining?
Utenti tipici:
- Data analyst e team di business intelligence (BI)
- Data scientist
- Product manager e team strategici
Obiettivo:
Trovare significato nei dati. Queste persone prendono le informazioni grezze — che siano state estratte dal web o recuperate da sistemi interni — e cercano pattern, tendenze e insight utilizzabili. Si preoccupano meno di come i dati siano stati raccolti e più di cosa possano rivelare ().
Tabella di scenario: chi fa cosa?
| Ruolo | Esempio di Web Scraping | Esempio di Data Mining |
|---|---|---|
| Sales | Estrarre lead dalle directory aziendali | Analizzare quali lead convertono meglio |
| Marketing | Estrarre i lanci di prodotto dei competitor | Segmentare i clienti in base al comportamento d'acquisto |
| Operations | Estrarre ogni giorno i prezzi dei fornitori | Prevedere la domanda, ottimizzare l'inventario |
| BI/Data Science | (Di solito non fanno scraping direttamente) | Costruire modelli predittivi, trovare trend |
| Product Management | Estrarre le recensioni degli app store per raccogliere feedback | Individuare gap di funzionalità, dare priorità alla roadmap |
Web scraping: trasformare i siti web in dati pronti per il business
Diciamolo chiaramente: Internet è una miniera d’oro di dati aziendali, ma gran parte di essi è nascosta in pagine web confuse e non strutturate. Il web scraping è la chiave che ti permette di sbloccare quei dati e trasformarli in qualcosa che il tuo team può davvero usare.
Perché il web scraping conta davvero (soprattutto per i team non tecnici)
- Fa risparmiare tempo: niente più stagisti a fare copia-incolla per giorni. Uno scraper può estrarre migliaia di dati in pochi minuti.
- Scala facilmente: vuoi monitorare 50 siti dei competitor ogni giorno? Con lo scraping è possibile.
- Ti mantiene aggiornato: ottieni aggiornamenti in tempo reale su prezzi, inventario o notizie, senza lavoro manuale.
Il quadro generale: il stima il mercato del web scraping a 1,17 miliardi di dollari nel 2026, con crescita fino a 2,23 miliardi entro il 2031. E secondo un sondaggio BrowserCat del 2024 citato in quel report, il 65% delle aziende stava già usando il web scraping per alimentare progetti di AI e machine learning — la parte del flusso che spinge l’adozione fuori dall’IT e dentro sales, marketing e operations.
Casi d’uso pratici
-
Generazione di lead: estrai da directory pubbliche o social network nomi, email e numeri di telefono.
-
Monitoraggio prezzi: tieni traccia in tempo reale dei prezzi dei competitor o della disponibilità dei prodotti. L’adozione è ormai mainstream — riporta che l’81% dei retailer statunitensi usa oggi scraping automatizzato dei prezzi per il repricing dinamico, rispetto al 34% del 2020 (dato originariamente rilevato da Actowiz Solutions).
-
Ricerche di mercato: aggrega recensioni online, fai scraping dei social media per analizzare il sentiment o monitora i siti di news per individuare trend.
-
Arricchimento dei dati: integra il tuo CRM con nuove informazioni dai siti aziendali o da LinkedIn.
-
Real estate e finanza: estrai annunci immobiliari, notizie finanziarie o dati alternativi per ricerche di investimento ().
Ecco il punto decisivo: non serve più essere programmatori. Una quota crescente dei nuovi strumenti di scraping — Octoparse, Browse AI, Bardeen, Thunderbit — offre come impostazione predefinita configurazione drag-and-drop o point-and-click, non come opzione secondaria in modalità coder. Solo questo ha spostato lo scraping dal backlog dell’ingegneria alla scrivania di sales e operations.
Come Thunderbit semplifica il web scraping per tutti
Lo ammetto: quando abbiamo iniziato a costruire , il nostro obiettivo era semplice: rendere il web scraping facile quanto chiedere a uno stagista di fare copia-incolla dei dati — con la differenza che lo “stagista” è un agente AI che non dorme mai, non si lamenta mai e non si distrae mai con video di gatti.
Ecco come Thunderbit colma il divario tra raccolta dati e analisi di business:
- AI Suggest Fields: basta cliccare “AI Suggest Fields” e l’AI di Thunderbit analizza la pagina, suggerisce quali campi estrarre e propone i nomi delle colonne. Niente più smanettamenti con HTML o selector: scegli solo ciò che ti serve ().
- Estrazione delle sottopagine: ti servono più dettagli da sottopagine (come schede prodotto o descrizioni di lavoro)? Thunderbit può cliccare automaticamente, recuperare le informazioni extra e aggiungerle al dataset.
- Esportazione dati istantanea: esporta con un clic in Excel, Google Sheets, Airtable, Notion o CSV/JSON. Nessun costo nascosto, nessun passaggio complicato: i tuoi dati sono subito pronti all’uso.
- No-code, point-and-click: Thunderbit vive nel tuo browser. Selezioni ciò che vuoi e hai finito. Anche se non hai mai fatto scraping prima, in pochi minuti sei operativo.
- Resilienza guidata dall’AI: i siti cambiano continuamente, ma l’AI di Thunderbit si adatta automaticamente a molte modifiche di layout. Meno manutenzione, meno frustrazione.
- Scheduled Scraper e AI Autofill: programma le estrazioni oppure lascia che l’AI compili form e accessi per te. Thunderbit gestisce persino PDF, immagini, email e numeri di telefono con un solo clic.
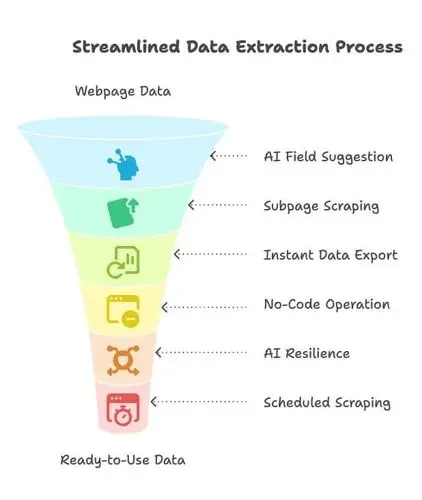
Il risultato? Thunderbit riduce il divario di competenze. Ora sales ops, marketing o persino il CEO possono impostare uno scraping senza chiamare l’IT. È lo “strato intermedio” che collega i dati web disordinati agli strumenti che usi davvero per l’analisi.
Vuoi vederlo in azione? Dai un’occhiata alla nostra oppure approfondisci altri casi d’uso nel .
Data mining: scoprire insight dai dati raccolti
Bene, hai estratto una montagna di dati. E adesso? Qui entra in gioco il data mining.
Cos’è il data mining, in parole semplici?
Il data mining è il processo di analisi di grandi dataset per trovare pattern nascosti, correlazioni o anomalie che possano offrire insight di business. Significa trasformare numeri grezzi in conoscenza utilizzabile — per esempio scoprire che i clienti che comprano il prodotto A tendono anche a comprare il prodotto B, oppure che certi comportamenti segnalano un alto rischio di churn.
Obiettivi aziendali comuni
- Scoperta di trend e previsione: individuare trend di vendita, stagionalità o cambiamenti di mercato — e prevedere cosa succederà dopo.
- Segmentazione dei clienti: raggruppare i clienti per comportamento o dati demografici per un marketing mirato.
- Rilevamento di anomalie: trovare outlier che potrebbero indicare frodi, rischi o nuove opportunità.
- Insight strategici: combinare più dataset (interni + estratti) per guidare decisioni importanti — come entrare in un nuovo mercato o modificare i prezzi.
Ecco il problema: il data mining vale quanto i dati che gli fornisci. Il vecchio detto “garbage in, garbage out” è dolorosamente vero. Infatti, spesso gli analisti spendono fino all’ solo per pulire e preparare i dati prima di poterli davvero analizzare.
Per questo lo scraping strutturato — come quello prodotto da Thunderbit — è così prezioso: ti fornisce un dataset pulito e pronto per l’analisi, così i tuoi analisti possono arrivare subito alla parte che conta.
Web scraping vs. data mining: confronto affiancato
Mettiamo le due cose una contro l’altra, così puoi vedere esattamente dove differiscono e dove si sovrappongono.
| Aspetto | Web Scraping | Data Mining |
|---|---|---|
| Scopo principale | Raccolta di dati grezzi dai siti web (estrazione dati) | Analisi dei dataset per scoprire pattern e insight (analisi dati) |
| Utenti tipici | Sales, marketing, operations, ricerca (spesso non tecnici, esperti di dominio) | Data analyst, team BI, data scientist, responsabili strategici (ruoli analitici/tecnici) |
| Fonti dei dati | Pagine web, fonti online, directory pubbliche, API | Dataset strutturati: dati estratti, database interni, CSV, data warehouse |
| Processo e strumenti | Crawling, estrazione (strumenti no-code come Thunderbit, estensioni browser) | Analisi dati (strumenti BI, Python/R, SQL, piattaforme di machine learning) |
| Output | Dataset strutturato (CSV, foglio di calcolo, tabella database) | Insight, report, dashboard, modelli predittivi |
| Esempi d’uso | Raccolta prezzi dei competitor, scraping delle menzioni social, estrazione di listing | Segmentazione clienti, previsione del churn, scoring dei lead |
| Sfide principali | Cambiamenti dei siti, difese anti-scraping, qualità dei dati, aspetti legali/etici | Dati sporchi/incompleti, scelta dei modelli giusti, privacy, interpretazione dei risultati |
Punto chiave:
Il web scraping è il “carburante” (i dati), il data mining è il “motore” (l’insight). Ti servono entrambi per andare da qualche parte.
Come web scraping e data mining lavorano insieme nel business
Qui succede la vera magia: web scraping e data mining non sono concorrenti, ma compagni di squadra. Pensali come la parte upstream e downstream del tuo flusso dati.
Scenario 1: Market intelligence
- Passo 1: estrai listing di prodotti, prezzi e recensioni dei competitor da più siti.
- Passo 2: fai mining dei dati per individuare trend: lacune di mercato, reclami ricorrenti dei clienti o variazioni di prezzo nel tempo.
- Risultato: ottieni insight utilizzabili per guidare la strategia di prodotto o il pricing.
Scenario 2: Lead scoring per il sales
- Passo 1: estrai da LinkedIn o dalle directory aziendali dati aggiuntivi per arricchire il database dei lead con dimensione aziendale, settore e notizie recenti.
- Passo 2: analizzi quali attributi sono correlati a tassi di conversione elevati, poi dai priorità ai lead di conseguenza.
- Risultato: il team sales si concentra sui prospect più adatti, non solo sulla lista più lunga.
Scenario 3: Ottimizzazione dei prezzi
- Passo 1: estrai in tempo reale prezzi e inventario dei competitor.
- Passo 2: inserisci quei dati nei tuoi algoritmi di pricing per aggiornare dinamicamente i tuoi prezzi.
- Risultato: resti competitivo e massimizzi i ricavi.
Il rischio di trattarli come attività isolate?
Se fai solo scraping e non analizzi mai, stai annegando nei dati ma resti affamato di insight. Se analizzi solo i dati interni, ti manca il contesto più ampio del mercato. I team migliori usano entrambi: scraping per avere un dataset completo, mining per ricavare insight significativi ().
Superare le sfide più comuni nel web scraping e nel data mining
Mettiamola così: sia il web scraping sia il data mining portano con sé il loro bel carico di problemi. Ecco come affrontare i principali — e come aiuta Thunderbit:
1. Qualità e pulizia dei dati
- Problema: i dati estratti possono essere disordinati — campi mancanti, formati incoerenti, duplicati.
- Soluzione: usa strumenti che permettano di pulire i dati durante l’estrazione. Thunderbit può formattare e categorizzare i dati al volo con l’AI, così l’output è già pronto per l’analisi (). Controlla sempre a campione i dati prima di iniziare l’analisi.
2. Cambiamenti dei siti e misure anti-scraping
- Problema: i siti cambiano layout, aggiungono CAPTCHA o bloccano i bot.
- Soluzione: usa scraper potenziati dall’AI come Thunderbit, che si adattano automaticamente ai cambiamenti di layout. Rispetta
robots.txt, evita di sovraccaricare i siti e, se necessario, valuta l’uso di proxy ().
3. Questioni legali ed etiche
- Problema: lo scraping di dati pubblici è in genere legale, ma contano le leggi sulla privacy e i termini di servizio.
- Soluzione: leggi sempre i termini del sito, concentrati sui dati pubblici, anonimizza dove possibile e rispetta il GDPR/CCPA. Sii un “cittadino etico dei dati”: la tua reputazione vale più di qualsiasi dataset ().
4. Dai dati agli insight azionabili
- Problema: i team raccolgono dati ma faticano a trasformarli in decisioni.
- Soluzione: parti da domande di business chiare, usa la visualizzazione e coinvolgi esperti del dominio nell’interpretazione dei risultati. Integra gli insight nei flussi di lavoro (per esempio segnalando i clienti a rischio nel CRM).
5. Gap di strumenti e competenze
- Problema: non tutti i team hanno programmatori o data scientist.
- Soluzione: sfrutta strumenti no-code e facili da usare come Thunderbit per lo scraping, e piattaforme BI moderne per il mining. Investi in una formazione di base sulla data literacy: a volte basta una semplice tabella pivot.
Scegliere l’approccio giusto: web scraping, data mining o entrambi?
Quindi, come decidi di cosa hai bisogno? Ecco una guida rapida:
- Hai già i dati di cui hai bisogno?
- No: inizia con il web scraping per raccoglierli.
- Sì: passa al data mining per estrarre insight.
- Le tue domande riguardano il mondo esterno o i pattern interni?
- Esterno (competitor, mercato, lead): web scraping.
- Interno (comportamento dei clienti, trend di vendita): data mining.
- Ti servono entrambi?
- Nella maggior parte dei progetti reali, sì! Estrai i dati esterni e poi analizzali insieme a quelli interni per avere il quadro completo.
- Capacità del team:
- Non sai programmare? Usa strumenti di scraping no-code come Thunderbit.
- Non hai data scientist? Usa strumenti BI facili da usare o inizia con analisi di base.
- Quanto è urgente?
- Serve in tempo reale? Imposta scraping e analisi continui.
- È un progetto una tantum? Fai uno scraping singolo e poi analizzalo.
Checklist:
- “Ho tutti i dati di cui ho bisogno internamente?” Se no, fai scraping.
- “Capisco i dati che ho?” Se no, fai mining.
- “Il problema è abbastanza grande da richiedere entrambi gli approcci?” Se sì, fai entrambi.
- “Il mio team ha le competenze necessarie?” Se no, usa strumenti no-code o chiedi aiuto.
E ricorda: non devi fare tutto in una volta. Parti in piccolo, avvia un pilot e scala man mano che vedi risultati.
Conclusioni chiave: far lavorare i dati per il tuo team
Ricapitoliamo gli elementi essenziali:
- Web scraping e data mining sono due fasi dello stesso percorso. Lo scraping raccoglie i dati (soprattutto da fonti esterne), il mining li analizza per generare insight.
- Ruoli diversi, obiettivi diversi: sales, marketing e operations usano lo scraping per ottenere dati; analisti e team BI li usano per ricavarne significato.
- Sono complementari, non in competizione: i risultati migliori arrivano combinando entrambi — scraping per ottenere un dataset ricco, mining per ricavare insight azionabili.
- Gli strumenti no-code e l’AI hanno abbassato la barriera: Thunderbit e strumenti simili rendono lo scraping accessibile a tutti. Anche le moderne piattaforme BI rendono il mining più semplice.
- Qualità dei dati ed etica contano: pulisci i dati, rispetta la privacy e agisci sempre in modo etico.
- Lascia che sia il caso d’uso a guidare l’approccio: parti dalla tua domanda di business, poi decidi quali dati ti servono e come analizzarli.
- Inizia in piccolo, poi scala: usa piani gratuiti, progetti pilota e quick win per creare slancio.
Alla fine, l’obiettivo è dare al tuo team gli strumenti per prendere decisioni migliori grazie ai dati. Magari significa far passare il team sales meno tempo nelle ricerche manuali (grazie allo scraping), oppure far sì che le riunioni strategiche siano guidate da insight reali (grazie al mining). In ogni caso, combinare i due approcci è il modo in cui i team moderni costruiscono un vantaggio competitivo.
Quindi, raccogli quegli ingredienti di dati web, cucinali in insight e servi al tuo team l’intelligenza operativa di cui ha bisogno. E se ti serve una mano in cucina, è qui per rendere la preparazione un gioco da ragazzi.
Ti incuriosisce provarlo? Scarica la e scopri quanto può essere semplice il web scraping. Per altri consigli e storie dal fronte dei dati, dai un’occhiata al .
FAQ
1. Qual è la differenza principale tra web scraping e data mining?
Il web scraping è il processo di raccolta di dati grezzi dai siti web, mentre il data mining consiste nell’analizzare quei dati per scoprire pattern, insight o trend. Pensa allo scraping come alla raccolta degli ingredienti e al mining come alla preparazione del pasto.
2. Chi usa in genere il web scraping rispetto al data mining?
Il web scraping è usato soprattutto da team sales, marketing, operations e ricerca che hanno bisogno rapidamente di dati esterni e aggiornati. Il data mining è usato da analisti, data scientist e team di prodotto che vogliono ricavare insight strategici dai dati.
3. Servono competenze di programmazione per fare web scraping?
Non più. Strumenti come offrono interfacce no-code, potenziate dall’AI, che permettono a chiunque — indipendentemente dal background tecnico — di estrarre dati con azioni point-and-click e funzioni di esportazione immediata.
4. Come lavorano insieme web scraping e data mining?
Il web scraping fornisce i dati grezzi e strutturati su cui si basa il data mining. Insieme creano una pipeline: raccogli i dati esterni con lo scraping, poi analizzali con il mining per guidare le decisioni di business.
5. Quali sono alcuni casi d’uso reali per ciascuno?
Il web scraping viene usato per attività come generazione di lead, monitoraggio dei prezzi e tracking dei competitor. Il data mining supporta segmentazione dei clienti, previsione dei trend, rilevamento delle frodi e pianificazione strategica basata sui dati estratti.