“Si possono avere dati senza informazioni, ma non si possono avere informazioni senza dati.” — *
Stime recenti suggeriscono che su Internet ci siano oltre di siti web, con circa 2 milioni di nuovi post pubblicati ogni giorno. Questo oceano di dati nasconde informazioni preziose per prendere decisioni migliori, ma c’è un problema: circa l' è non strutturato, quindi va elaborato prima di diventare davvero utile. Ed è qui che entrano in gioco gli strumenti di web scraping, ormai indispensabili per chi vuole sfruttare i dati online.
Se sei alle prime armi con il web scraping, termini come e possono sembrare un po’ intimidatori. Ma nell’era dell’AI, queste difficoltà si superano molto più facilmente. Gli strumenti di scraping basati sull’AI di oggi ti aiutano a partire senza richiedere competenze tecniche avanzate. Ti permettono di raccogliere ed elaborare dati in fretta, senza dover programmare.
I migliori strumenti e software di web scraping
- per un AI web scraper facile da usare e con ottimi risultati
- per monitoraggio in tempo reale ed estrazione massiva di dati
- per l’automazione no-code con ampie integrazioni con le app
- per un web scraping visivo più professionale
- per uno scraping no-code potente che evita il blocco IP e il rilevamento dei bot
- per API avanzate di estrazione dati basata sull’AI e knowledge graph
Prova l’AI per il Web Scraping
Provalo! Puoi cliccare, esplorare ed eseguire il flusso di lavoro mentre lo guardi.
Come funziona il web scraping?
Il web scraping consiste semplicemente nel raccogliere dati dai siti web. Tu dai a uno strumento una serie di istruzioni, e lui estrae testi, immagini o qualsiasi altro dato ti serva in una tabella da una pagina web. Può tornare utile in tantissimi casi: dal monitoraggio dei prezzi sui siti e-commerce alla raccolta di dati per ricerche, fino alla creazione di un buon foglio Excel o Google Sheets.
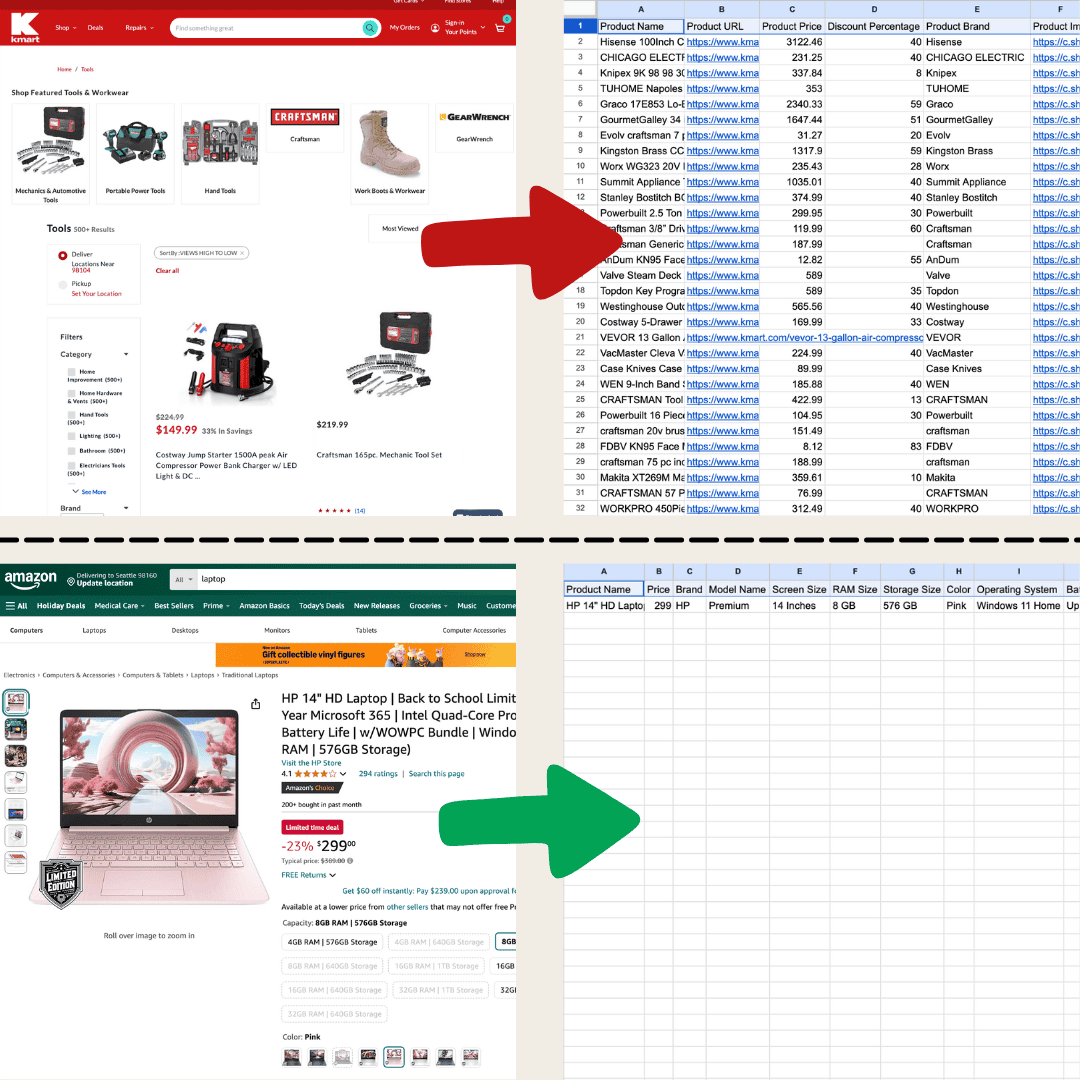 L’ho realizzato con Thunderbit usando l’AI Web Scraper.
L’ho realizzato con Thunderbit usando l’AI Web Scraper.
Ci sono diversi modi per farlo. Nel caso più semplice, potresti anche copiare e incollare tutto manualmente, ma diventa un lavoro infinito se i dati sono tanti. Per questo, la maggior parte delle persone usa uno di tre metodi: web scraper tradizionali, AI web scraper o codice personalizzato.
I web scraper tradizionali funzionano impostando regole specifiche su quali dati estrarre in base alla struttura della pagina. Per esempio, puoi configurarli per recuperare nomi dei prodotti o prezzi da determinati tag HTML. Funzionano meglio sui siti che cambiano di rado, perché basta un piccolo cambiamento nel layout per costringerti a tornare indietro e modificare lo scraper.
 Usare uno scraper tradizionale richiede molto tempo per imparare e probabilmente ti porterà via decine di clic solo per completare la configurazione.
Usare uno scraper tradizionale richiede molto tempo per imparare e probabilmente ti porterà via decine di clic solo per completare la configurazione.
Gli AI web scraper funzionano, in pratica, così: ChatGPT legge l’intero sito e poi estrae i contenuti in base a ciò che ti serve. Può gestire insieme estrazione dei dati, traduzione e sintesi. Usano l’elaborazione del linguaggio naturale per analizzare e capire il layout del sito, quindi si adattano più facilmente ai cambiamenti. Se il sito riorganizza leggermente le sezioni, un AI web scraper può adeguarsi senza che tu debba riscrivere nulla. Sono quindi ideali per siti che cambiano spesso o con strutture più complesse.
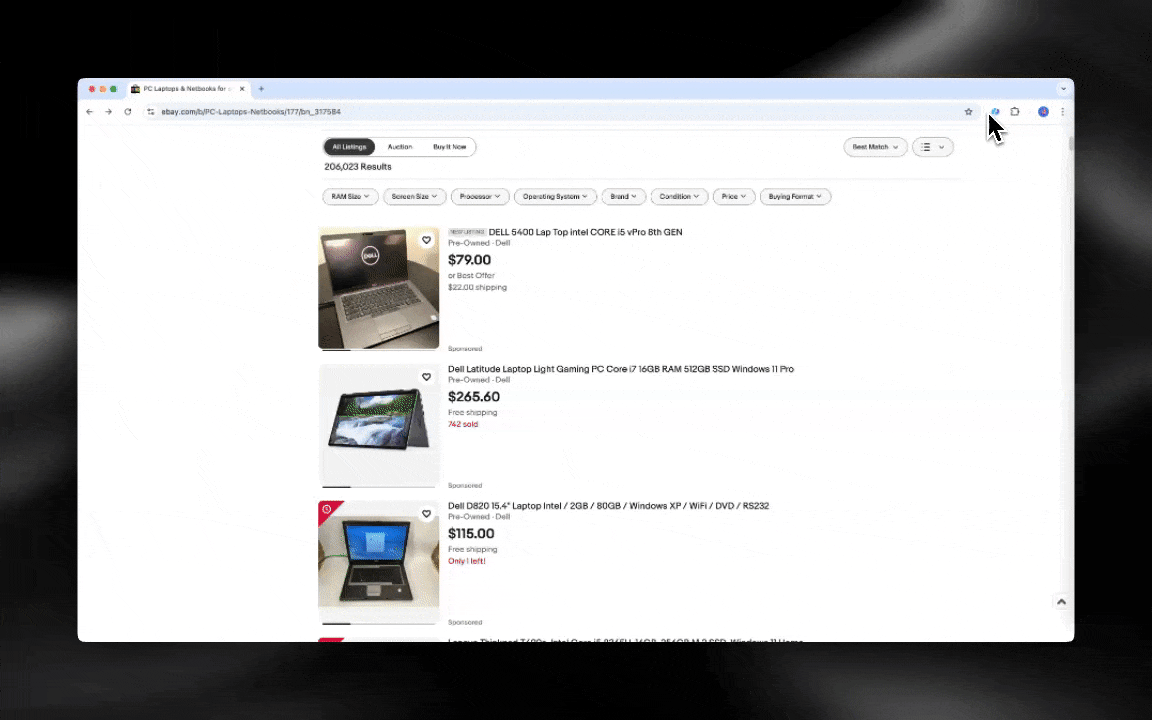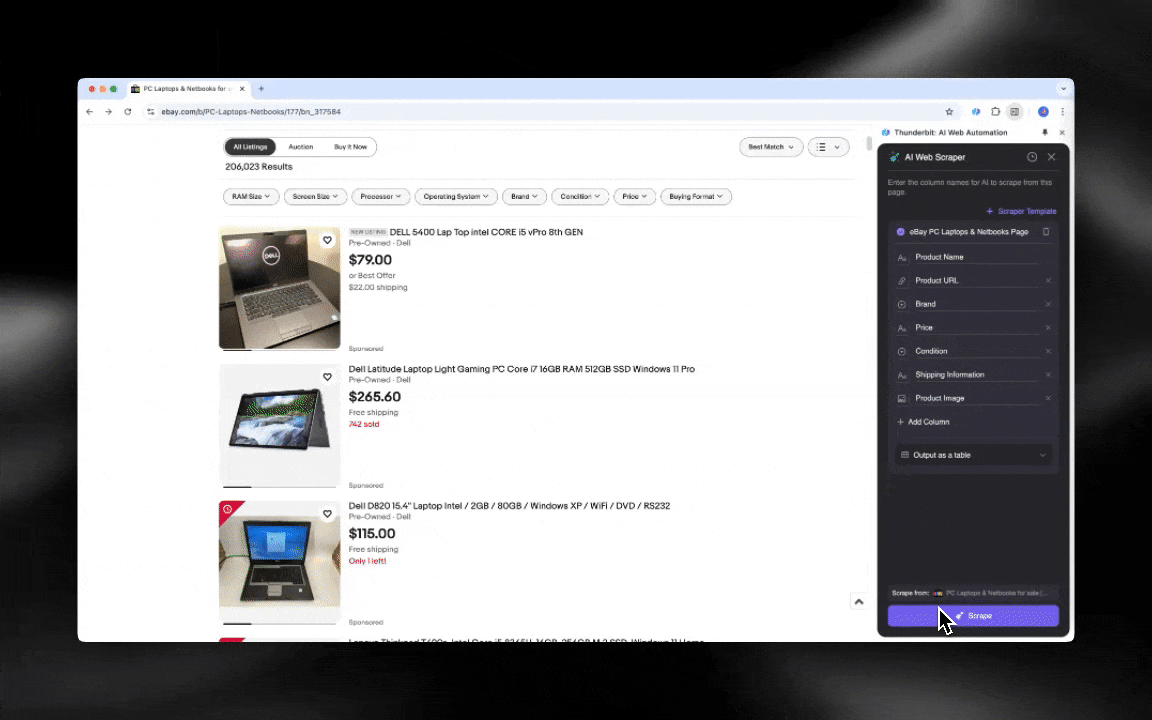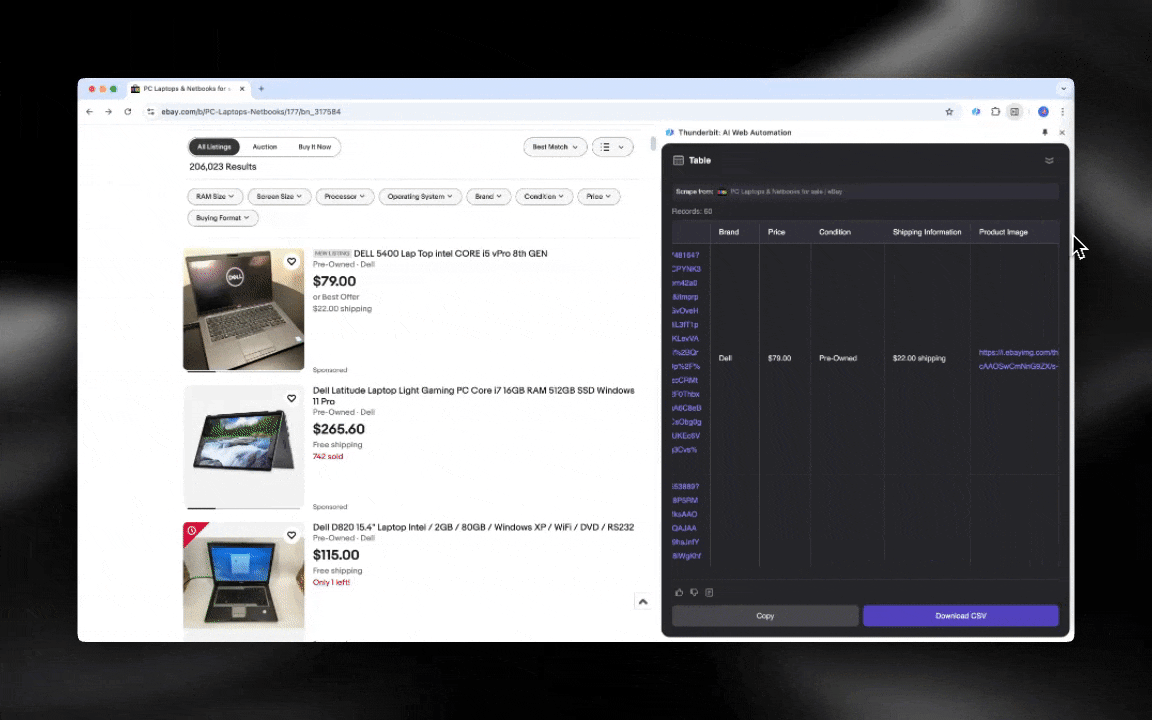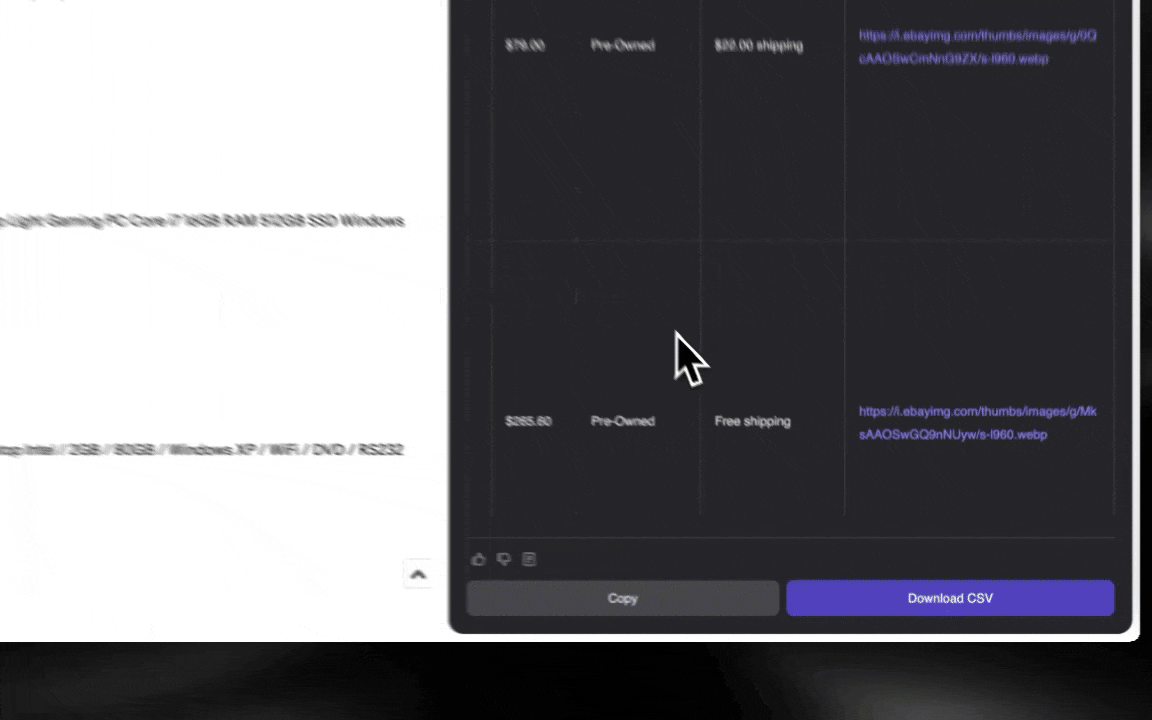 L’AI web scraper è facile da avviare e ti restituisce dati dettagliati in pochi clic!
L’AI web scraper è facile da avviare e ti restituisce dati dettagliati in pochi clic!
Quale dovresti scegliere? Dipende. Se ti senti a tuo agio a mettere mano al codice o devi raccogliere grandi quantità di dati da un sito molto usato, gli scraper tradizionali possono essere molto efficienti. Ma se sei nuovo al web scraping o vuoi uno strumento che sappia adattarsi agli aggiornamenti del sito, gli AI web scraper sono in genere la scelta migliore. Dai un’occhiata alla tabella qui sotto per scenari più dettagliati!
| Scenario | Scelta migliore |
|---|---|
| Scraping leggero su pagine come directory, siti di shopping o qualsiasi sito con un elenco | AI Web Scraper |
| La pagina contiene meno di 200 righe di dati e creare uno scraper con un web scraper tradizionale richiede troppo tempo | AI Web Scraper |
| I dati da estrarre devono avere un formato specifico per essere caricati altrove. Per esempio: estrarre informazioni di contatto da caricare in HubSpot. | AI Web Scraper |
| Siti molto usati su larga scala, come decine di migliaia di pagine prodotto Amazon o annunci immobiliari di Zillow. | Traditional Web Scraper |
I migliori strumenti e software di web scraping in sintesi
| Strumento | Prezzo | Funzionalità principali | Pro | Contro |
|---|---|---|---|---|
| Thunderbit | Da 9 $/mese, piano gratuito disponibile | AI web scraper, rileva e formatta automaticamente i dati, supporta più formati, export con un clic, interfaccia intuitiva. | Senza codice, supporto AI, integrazioni con app come Google Sheets | Lo scraping su larga scala può essere lento, le funzioni avanzate possono costare di più |
| Browse AI | Da 48,75 $/mese, piano gratuito disponibile | Interfaccia no-code, monitoraggio in tempo reale, estrazione massiva di dati, integrazione dei flussi di lavoro. | Facile da usare, si integra con Google Sheets e Zapier | Le pagine complesse richiedono configurazioni extra, lo scraping massivo può causare timeout |
| Bardeen AI | Da 60 $/mese, piano gratuito disponibile | Automazione no-code, integrazioni con oltre 130 app, MagicBox trasforma le attività in flussi di lavoro. | Integrazioni ampie, scalabile per le aziende | Curva di apprendimento ripida per i nuovi utenti, configurazione lunga |
| Web Scraper | Gratis per uso locale, 50 $/mese per il cloud | Creazione visiva delle attività, supporta siti dinamici (AJAX/JavaScript), scraping cloud. | Funziona bene sui siti dinamici | Richiede conoscenze tecniche per una configurazione ottimale |
| Octoparse | Da 119 $/mese, piano gratuito disponibile | Scraping no-code, rilevamento automatico degli elementi della pagina, scraping cloud con attività pianificate, libreria di template per siti comuni. | Funzioni potenti per i siti dinamici, gestisce le restrizioni | I siti complessi richiedono tempo per l’apprendimento |
| Diffbot | Da 299 $/mese | API per l’estrazione dei dati, API senza regole, NLP per testi non strutturati, knowledge graph esteso. | Forte estrazione AI, ampie integrazioni API, scraping su larga scala | Curva di apprendimento per utenti non tecnici, tempo di configurazione |
Il miglior web scraper nell’era dell’AI
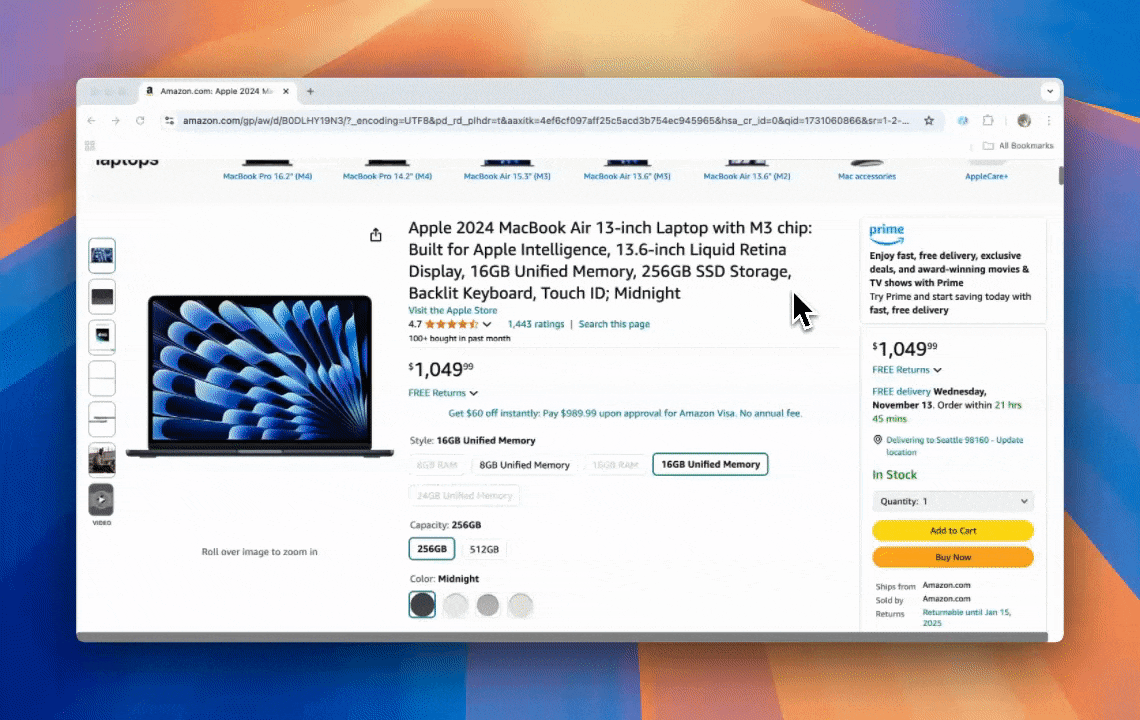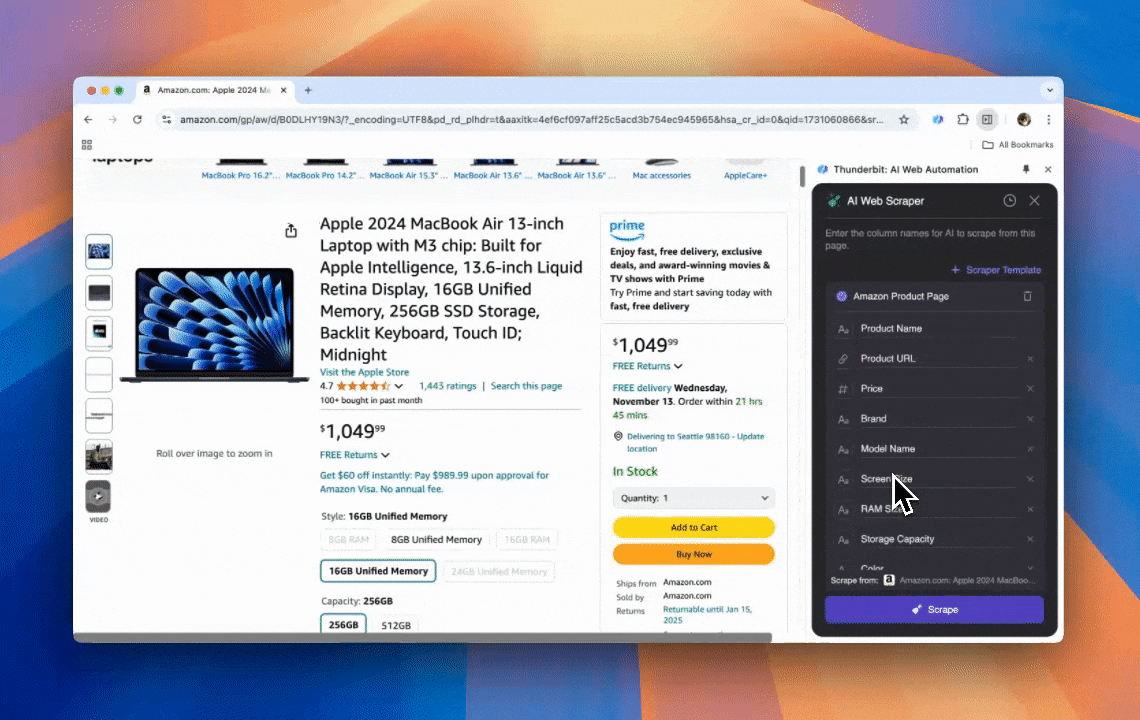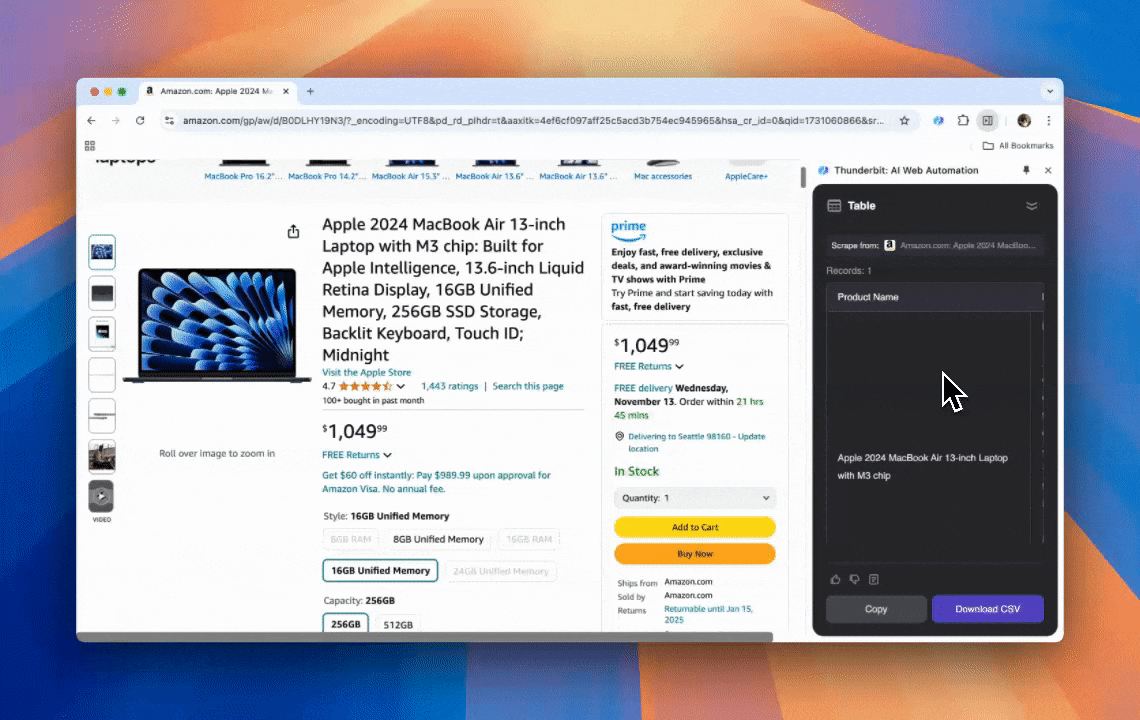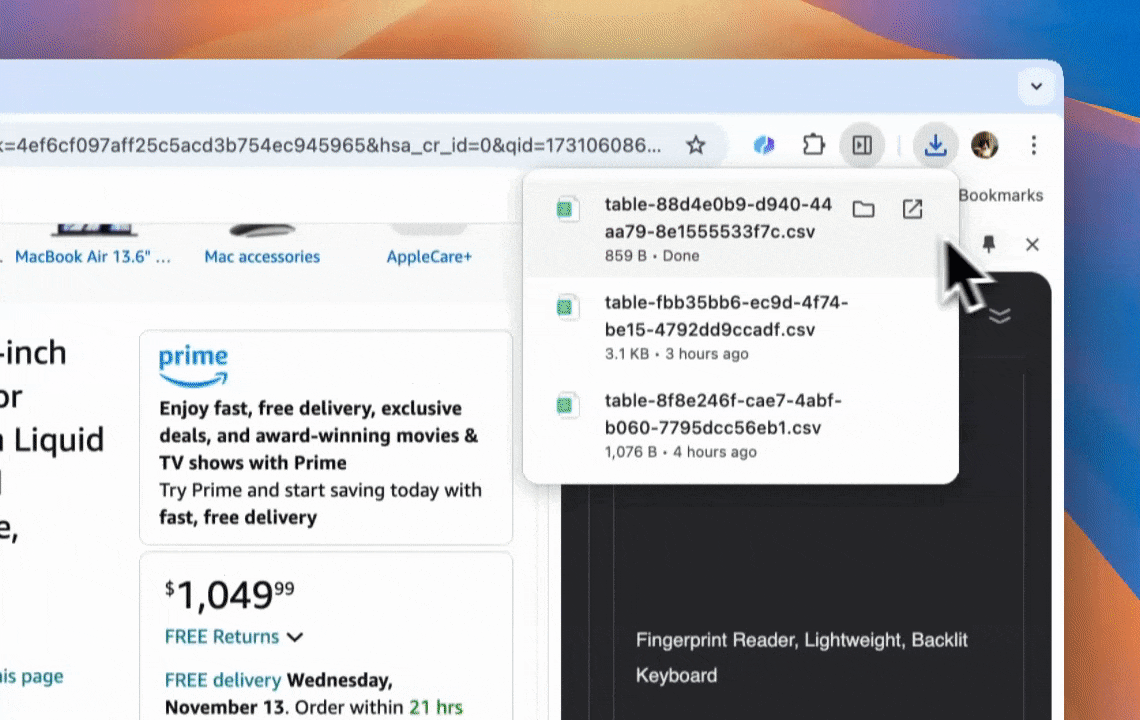
Thunderbit è un potente strumento di automazione web basato sull’AI, facile da usare, che permette anche a chi non sa programmare di estrarre e organizzare i dati senza fatica. Con la sua , l’ di Thunderbit semplifica l’estrazione dei dati: gli utenti possono recuperare rapidamente dati dal web senza interagire manualmente con gli elementi della pagina o configurare scraper diversi per layout differenti.
Funzionalità principali
- Flessibilità basata sull’AI: l’AI Web Scraper di Thunderbit rileva e formatta automaticamente i dati web, eliminando la necessità di CSS selector.
- L’esperienza di scraping più semplice: basta cliccare su “AI suggest column” e poi su “Scrape” nella pagina da cui vuoi estrarre i dati. Tutto qui.
- Supporto per vari formati di dati: Thunderbit può estrarre URL e immagini e mostrare i dati acquisiti in più formati.
- Elaborazione automatica dei dati: l’AI di Thunderbit può riformattare i dati al volo, inclusi riepilogo, categorizzazione e traduzione nel formato richiesto.
- Export dei dati semplice: esporta i dati su Google Sheets, Airtable o Notion con un clic, semplificando la gestione delle informazioni.
- Interfaccia intuitiva: un’interfaccia facile da usare lo rende accessibile a utenti di ogni livello.
Prezzi
Thunderbit offre piani a livelli, a partire da 9 $ al mese per 5.000 crediti. Si arriva fino a 199 $ per 240.000 crediti. Inoltre, con il piano annuale riceverai tutti i crediti in anticipo.
Pro:
- Il forte supporto AI semplifica estrazione ed elaborazione dei dati.
- Senza codice, accessibile a utenti di ogni livello.
- Perfetto per scraping leggeri, come directory, siti di shopping e simili.
- Ottime integrazioni per export diretto verso app popolari.
Contro:
- Lo scraping di grandi volumi di dati può richiedere tempo per garantire l’accuratezza.
- Alcune funzioni avanzate possono richiedere un abbonamento a pagamento.
Vuoi saperne di più? Inizia installando oppure scopri con Thunderbit.
Il miglior web scraper per monitoraggio dati ed estrazione massiva
Browse AI
Browse AI è uno strumento robusto di data scraping no-code progettato per aiutare gli utenti a estrarre e monitorare dati senza scrivere codice. Browse AI ha alcune funzioni AI, ma non arriva ancora al livello di un vero AI scraping completo. Detto questo, rende comunque più semplice iniziare.
Funzionalità principali
- Interfaccia no-code: consente di creare flussi di lavoro personalizzati con semplici clic.
- Monitoraggio in tempo reale: usa bot per tracciare le modifiche delle pagine web e fornire informazioni aggiornate.
- Estrazione massiva di dati: in grado di gestire fino a 50.000 record di dati in un solo passaggio.
- Integrazione dei flussi di lavoro: collega più bot per processi di dati più complessi.
Prezzi
A partire da 48,75 $ al mese, con 2.000 crediti inclusi. È disponibile un piano gratuito con 50 crediti al mese per provare le funzionalità di base.
Pro:
- Offre integrazioni con Google Sheets e Zapier.
- I bot predefiniti semplificano le attività comuni di estrazione dati.
Contro:
- Le pagine complesse possono richiedere configurazioni aggiuntive.
- La velocità dello scraping massivo può variare e talvolta causare timeout.
Il miglior web scraper per l’integrazione dei flussi di lavoro
Bardeen AI
Bardeen AI è uno strumento di automazione no-code progettato per semplificare i flussi di lavoro collegando diverse app. Anche se usa l’AI per creare automazioni personalizzate, non ha la stessa adattabilità di uno strumento di scraping AI completo.
Funzionalità principali
- Automazione no-code: consente agli utenti di impostare flussi di lavoro con i clic.
- MagicBox: descrive le attività in linguaggio semplice, che Bardeen AI converte in flussi di lavoro.
- Ampie opzioni di integrazione: si integra con oltre 130 app, tra cui Google Sheets, Slack e LinkedIn.
Prezzi
A partire da 60 $ al mese, con 1.500 crediti (circa 1.500 righe di dati). Un piano gratuito offre 100 crediti al mese per provare le funzionalità di base.
Pro:
- Le ampie opzioni di integrazione supportano esigenze aziendali diverse.
- È flessibile e scalabile per aziende di qualsiasi dimensione.
Contro:
- I nuovi utenti potrebbero aver bisogno di tempo per imparare la piattaforma completa.
- La configurazione iniziale può richiedere molto tempo.
Il miglior web scraper visivo per chi ha esperienza
Web Scraper
Sì, hai letto bene: lo strumento si chiama proprio “Web Scraper”. Web Scraper è una popolare estensione del browser per Chrome e Firefox che permette di estrarre dati senza programmare, offrendo un modo visivo per creare attività di scraping. Tuttavia, potresti dover passare alcuni giorni a guardare e seguire i tutorial qui sopra per padroneggiarlo davvero. Se vuoi rendere lo scraping facile per la tua mente, scegli AI Web Scraper.
Funzionalità principali
- Creazione visiva: consente agli utenti di impostare attività di scraping cliccando sugli elementi della pagina.
- Supporto per siti dinamici: può gestire richieste AJAX e JavaScript per i siti dinamici.
- Scraping cloud: consente di pianificare attività tramite Web Scraper Cloud per scraping periodici.
Prezzi
Gratis per uso locale; i piani a pagamento partono da 50 $/mese per le funzioni cloud.
Pro:
- Funziona bene sui siti dinamici.
- Gratis per uso locale.
Contro:
- Richiede conoscenze tecniche per una configurazione ottimale.
- Sono necessari test complessi per gestire le modifiche.
Il miglior web scraper per evitare blocchi IP e rilevamento dei bot
Octoparse
Octoparse è un software versatile, adatto a utenti più tecnici, per raccogliere e monitorare dati web specifici senza codice, ideale per esigenze di dati su larga scala. Octoparse non si basa sul browser dell’utente per funzionare; invece usa server cloud per lo scraping dei dati. Di conseguenza, può offrire diversi metodi per aggirare il blocco IP e alcuni sistemi di rilevamento bot dei siti.
Funzionalità principali
- Funzionamento no-code: gli utenti possono creare attività di scraping senza scrivere codice, rendendolo accessibile a persone con diversi livelli di competenza tecnica.
- Rilevamento automatico intelligente: identifica automaticamente i dati della pagina e gli elementi estraibili, semplificando la configurazione.
- Scraping cloud: supporta lo scraping cloud 24/7 con attività pianificate per un recupero flessibile dei dati.
- Ampia libreria di template: offre centinaia di template preimpostati, consentendo agli utenti di accedere rapidamente ai dati dai siti più popolari senza configurazioni complesse.
Prezzi
Il piano tariffario di Octoparse parte da 119 $ al mese e include 100 attività. È disponibile anche un piano gratuito con 10 attività al mese per testarne le funzionalità di base.
Pro:
- Funzioni potenti per lo scraping di siti dinamici con grande adattabilità.
- Offre soluzioni per gestire le restrizioni di scraping e i problemi dei contenuti dinamici.
Contro:
- Le strutture dei siti complessi possono richiedere più tempo per la configurazione.
- I nuovi utenti potrebbero aver bisogno di tempo per imparare a usarlo.
Il miglior web scraper per API avanzate di estrazione dati basata sull’AI
Diffbot
Diffbot è uno strumento avanzato di estrazione dei dati web che usa l’AI per trasformare contenuti web non strutturati in dati strutturati. Con API potenti e un knowledge graph, Diffbot aiuta gli utenti a estrarre, analizzare e gestire informazioni dal web, ed è adatto a diversi settori e applicazioni.
Funzionalità principali
- API di estrazione dati: Diffbot offre un’API senza regole per l’estrazione dei dati, consentendo agli utenti di fornire semplicemente un URL per l’estrazione automatica, senza dover impostare regole personalizzate per ogni sito.
- API di elaborazione del linguaggio naturale: estrae entità strutturate, relazioni e sentiment da testi non strutturati, aiutando gli utenti a costruire i propri knowledge graph.
- Knowledge graph: Diffbot dispone di uno dei più grandi knowledge graph, che collega un’enorme quantità di dati sulle entità, inclusi dettagli su persone e organizzazioni.
Prezzi
Il piano tariffario di Diffbot parte da 299 $ al mese e include 250.000 crediti (equivalenti a circa 250.000 estrazioni di pagine web tramite API).
Pro:
- Forti capacità di estrazione dati senza regole e con alta adattabilità.
- Ampie opzioni di integrazione API per collegarsi facilmente ai sistemi esistenti.
- Supporta lo scraping su larga scala, adatto ad applicazioni enterprise.
Contro:
- La configurazione iniziale può richiedere un po’ di tempo di apprendimento per gli utenti non tecnici.
- Per usarlo è necessario scrivere un programma che chiami l’API.
A cosa puoi usare gli scraper?
Se sei nuovo al web scraping, ecco alcuni casi d’uso popolari da cui partire. Molte persone usano gli scraper per recuperare inserzioni di prodotti Amazon, estrarre dati immobiliari da Zillow o raccogliere informazioni sulle aziende da Google Maps. Ma è solo l’inizio: puoi usare l’ di Thunderbit per raccogliere dati da quasi qualsiasi sito, semplificando le attività e risparmiando tempo nel tuo flusso di lavoro quotidiano. Che si tratti di ricerca, monitoraggio dei prezzi o creazione di database, il web scraping apre innumerevoli modi per mettere al lavoro i dati del web.
FAQ
-
Il web scraping è legale?
In genere il web scraping è legale, ma deve rispettare i termini di servizio del sito e la natura dei dati accessibili. Controlla sempre le policy pertinenti e rispetta le normative legali.
-
Servono competenze di programmazione per usare gli strumenti di web scraping?
La maggior parte degli strumenti presentati qui non richiede competenze di programmazione, ma strumenti come Octoparse e Web Scraper possono essere più efficaci se l’utente ha una conoscenza di base delle strutture web e un approccio mentale da programmatore.
-
Esistono strumenti gratuiti di web scraping?
Sì, sono disponibili strumenti gratuiti come BeautifulSoup, Scrapy e Web Scraper, e alcuni strumenti offrono anche piani gratuiti con funzionalità limitate.
-
Quali sono le sfide più comuni nel web scraping?
Le sfide più comuni includono la gestione dei contenuti dinamici, dei CAPTCHA, del blocco IP e delle strutture HTML complesse. Strumenti e tecniche avanzate possono affrontare efficacemente questi problemi.
Scopri di più:
-
Usa l’AI per lavorare senza sforzo.