

Immagina la scena: lanci il tuo sito, pronto ad accogliere un’ondata di clienti entusiasti, e scopri che metà del traffico è… fatta di robot. Non quelli da film di fantascienza, ma crawler digitali — motori di ricerca, bot AI, spider di analytics — che frugano nel tuo sito giorno e notte, come una sfilata infinita di ospiti invisibili. Nel 2026 non è più una curiosità da nota a margine nei log del server: è la nuova normalità. Capire chi, o cosa, sta visitando il tuo sito, con quale frequenza e perché, è ormai una parte fondamentale della gestione di qualsiasi attività online.
Dopo anni passati tra SaaS, automazione e AI, ho visto il web crawling passare da dettaglio tecnico dietro le quinte a sfida aziendale in primo piano. I numeri sono impressionanti: oggi i bot rappresentano quasi metà di tutto il traffico Internet e, in alcuni casi, superano gli esseri umani. Con la crescita dei crawler guidati dall’AI che aspirano contenuti per addestrare i large language model, la posta in gioco non è mai stata così alta — per la tua infrastruttura, il tuo budget e il tuo brand. Vediamo allora le ultime statistiche sul web crawling, i benchmark di settore e cosa significano per il tuo business nel 2026.
Web Crawling nel 2026: uno sguardo al panorama
Estrai dati da qualsiasi sito web usando l'AI Get Started Free
Il web crawling ha raggiunto un livello di scala e complessità completamente nuovo. Ogni giorno, miliardi di richieste automatizzate attraversano Internet, generate da un numero sempre crescente di crawler. Tradizionalmente, i bot dei motori di ricerca come Googlebot e Bingbot erano i protagonisti, perché indicizzavano le pagine e permettevano agli utenti di trovarle nei risultati di ricerca. Ma oggi si affianca a loro una nuova generazione: crawler per i dati AI, scraper per i social media, bot di analytics e molto altro.
Ecco il dato principale, che cambia a seconda della fonte che prendi come riferimento. Il Year in Review 2025 di Cloudflare ha mostrato che bot e crawler AI insieme rappresentavano circa il 53% delle richieste HTML sulla sua rete all’inizio di dicembre 2025, mentre il traffico umano era sceso al 47%. Imperva, analizzando la propria base clienti enterprise nel Bad Bot Report 2026 (pubblicato il 29 aprile 2026), è arrivata alla stessa conclusione per l’anno solare 2025: 53% bot, 47% umani, rispetto a 51/49 dell’anno precedente. Due prospettive molto diverse, stessa conclusione: il traffico automatizzato è ormai la parte maggiore del web. La novità non è solo il volume, ma anche i protagonisti. Un tempo dominavano gli indicizzatori dei motori di ricerca. Nel 2026, una quota crescente è formata da crawler di training per l’AI che alimentano chatbot e motori di risposta.
Il panorama è più vario che mai:
- Bot buoni: indicizzatori dei motori di ricerca, monitor di uptime, scraper legittimi per i dati.
- Bot cattivi: spam, hacking, scraping non autorizzato.
- Crawler AI: i nuovi arrivati, che raccolgono contenuti per l’addestramento dell’AI e per risposte in tempo reale.
I crawler AI spesso si comportano in modo diverso dai loro equivalenti dei motori di ricerca. Possono prelevare l’intero contenuto di una pagina per analisi semantiche, non solo indicizzare le parole chiave, e tendono a operare su grandi volumi — a volte sommergendo i siti con milioni di richieste nel giro di pochi giorni. Il risultato? Il web crawling è ormai onnipresente, in crescita e sempre più diversificato, unendo l’indicizzazione tradizionale all’appetito insaziabile dell’AI per i dati.
Statistiche chiave sul web crawling che ogni azienda dovrebbe conoscere
Entriamo nei numeri che stanno plasmando il web nel 2026. Queste statistiche non servono solo per fare bella figura nei quiz: sono i benchmark che dovrebbero guidare la tua infrastruttura, la strategia dei contenuti e i risultati economici.
Bot vs esseri umani: chi sta vincendo la guerra del traffico?
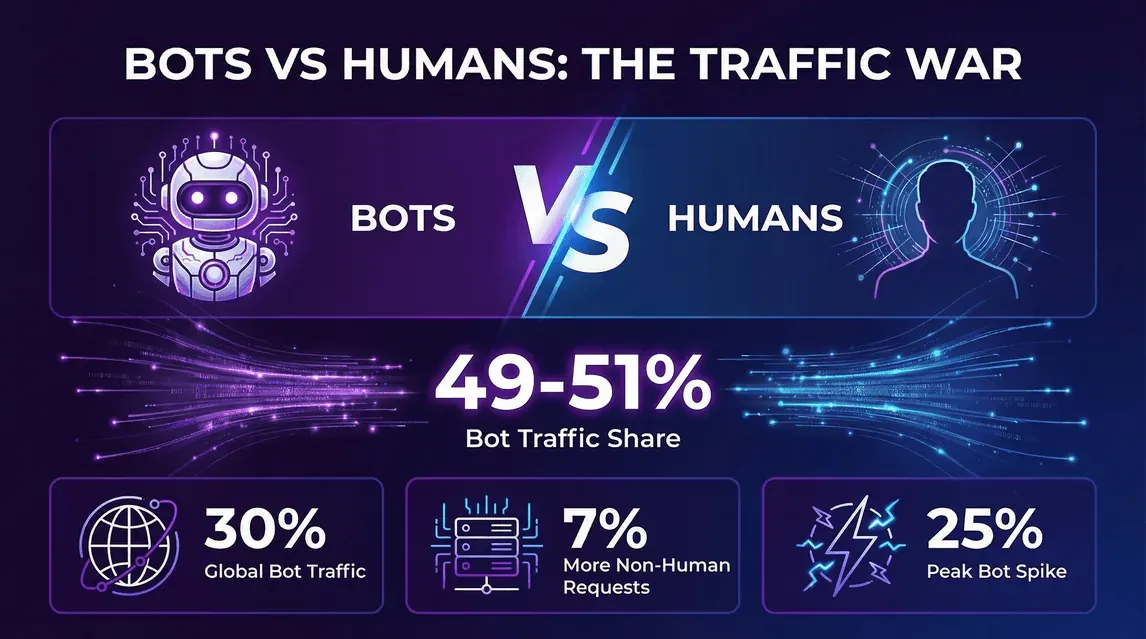
- Imperva, Bad Bot Report 2026 (aprile 2026): il traffico automatizzato ha raggiunto il 53% di tutto il traffico web nel 2025, rispetto al 51% del 2024. Il traffico umano è sceso di conseguenza dal 49% al 47%.
- Cloudflare Year in Review 2025: al 2 dicembre 2025, il 47% delle richieste HTML sulla rete di Cloudflare proveniva da esseri umani, il 44% da bot non-AI e un altro ~9% da bot AI e Googlebot combinati.
- La tendenza non è un semplice scarto di un trimestre: Imperva ha mostrato una quota di bot in aumento ogni anno dal 2019, e il salto tra 2024 e 2025 è stato trainato soprattutto dai crawler di training per l’AI, non dal solito mix di scraping e credential stuffing.
- Cosa significa per chi gestisce un sito: se le tue analytics non filtrano i bot, circa metà delle richieste grezze non proviene da una persona. Dimensionare l’infrastruttura sui log grezzi senza separare i bot porta a sovrastimare il fabbisogno — e sottodimensionare la capacità di gestione dei bot danneggerà proprio la metà che invece è umana.
L’impennata dei crawler AI
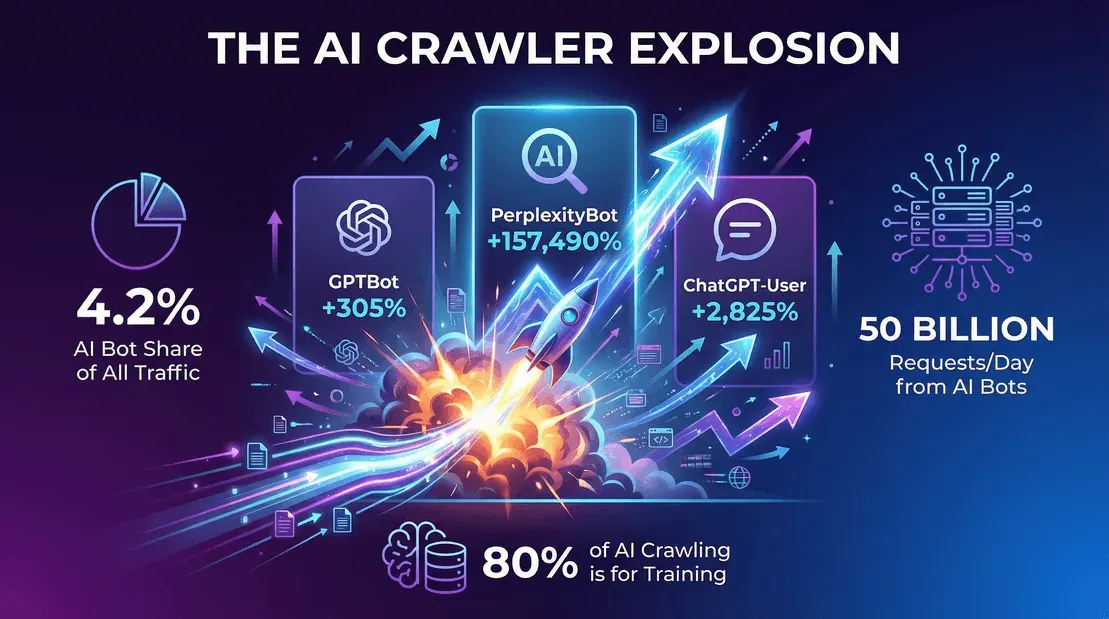
- La quota di traffico dei bot AI continua a crescere. Secondo il Year in Review 2025 di Cloudflare, i bot AI (escluso Googlebot) rappresentavano circa il 4,2% delle richieste HTML a fine 2025, mentre Googlebot da solo valeva un altro 4,5%. Una categoria che non esisteva tre anni fa è ormai quasi grande quanto Googlebot stesso.
- GPTBot di OpenAI è passato dal 7,7% delle richieste dei crawler a maggio 2025 al 3,6% delle richieste su pagine uniche a fine 2025 (Cloudflare YIR 2025) — la percentuale sembra più bassa, ma è perché Cloudflare ha cambiato il denominatore usando le pagine uniche e perché il settore si è affollato. In termini di volume grezzo, GPTBot resta uno dei tre principali crawler AI sul web aperto.
- ClaudeBot di Anthropic si trova insieme a Meta-ExternalAgent intorno al 2,4% delle richieste su pagine uniche a fine 2025. La quota relativa di ClaudeBot è scesa su base annua (è calata del 46% nella finestra maggio 2024–maggio 2025 di Cloudflare), per poi risalire quando Anthropic ha intensificato il retraining.
- PerplexityBot è ancora minuscolo in termini assoluti — circa 0,06% delle richieste su pagine uniche a fine 2025 — ma la sua traiettoria di crescita è la più ripida tra i principali bot AI.
- Googlebot resta di gran lunga il crawler singolo più grande sul web aperto. Il Year in Review di Cloudflare lo colloca a circa 200 volte il volume di pagine uniche di PerplexityBot.
Il traffico dei crawler nel contesto
Ecco un esempio reale da un thread su Reddit di fine 2025 — uno sviluppatore che ha estratto 30 giorni di log del server:
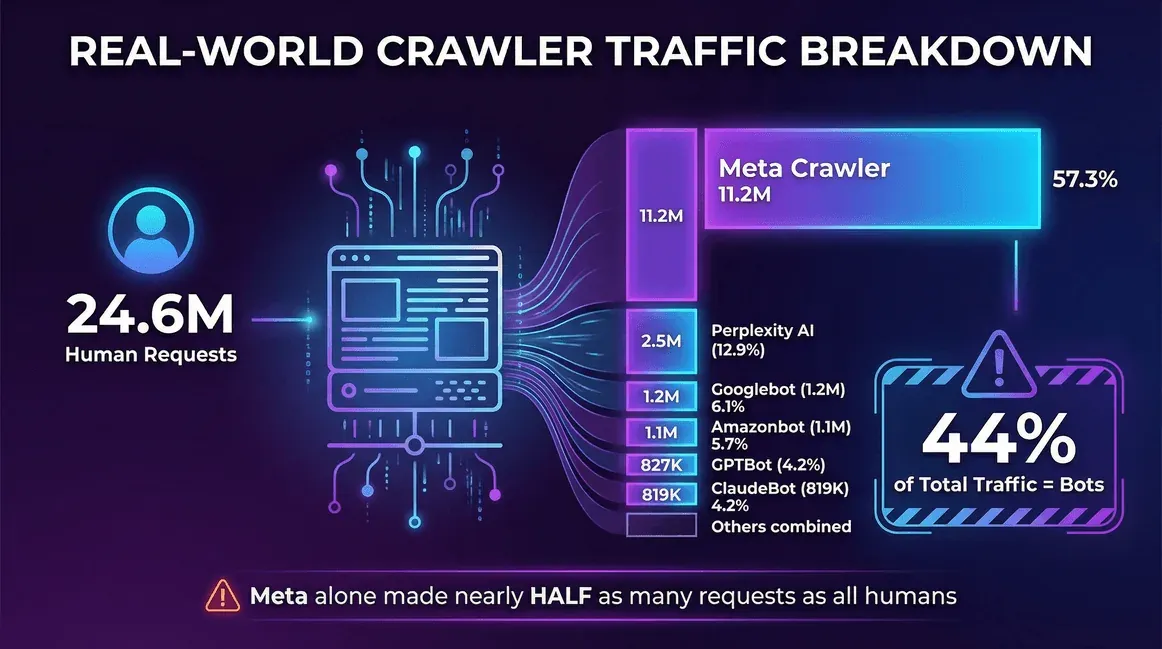
| Fonte del traffico | Richieste (mensili) | Quota dei crawler |
|---|---|---|
| Utenti reali (umani) | 24,647,904 | -- |
| Meta Crawler (Facebook) | 11,175,701 | 57,3% |
| Perplexity AI | 2,512,747 | 12,9% |
| Googlebot | 1,180,737 | 6,1% |
| Amazonbot | 1,120,382 | 5,7% |
| OpenAI GPTBot | 827,204 | 4,2% |
| ClaudeBot (Anthropic) | 819,256 | 4,2% |
| Bingbot | 599,752 | 3,1% |
| ChatGPT-User (OpenAI) | 557,511 | 2,9% |
| Ahrefs Crawler | 449,161 | 2,3% |
| ByteDance Spider | 267,393 | 1,4% |
Su questo sito, i bot rappresentavano il 44% del traffico totale — e il crawler di Meta da solo generava quasi la metà delle richieste fatte da tutti gli utenti reali messi insieme.
Il quadro generale
- Il traffico dei crawler (search + bot AI) è cresciuto del 18% tra maggio 2024 e maggio 2025 per un insieme coerente di siti (blog.cloudflare.com).
- I bot di training per gli LLM rappresentavano quasi l’80% di tutto il traffico “bot” su alcune grandi CDN (webscraft.org).
- La rete di Cloudflare ha visto circa 50 miliardi di richieste dei crawler al giorno solo dai bot AI a fine 2025 (webscraft.org).
L’ascesa dei crawler AI: come l’AI sta cambiando il web crawling
Parliamo dell’elefante nella stanza — o meglio, del robot: i crawler AI. Questi bot non si limitano a indicizzare il tuo sito per la ricerca: stanno divorando contenuti per addestrare i large language model o per fornire risposte AI immediate. E lo fanno su una scala che farebbe arrossire perfino il motore di ricerca più ambizioso.
Cosa sta alimentando il boom dei crawler AI?
- Modelli AI affamati di dati: i moderni LLM hanno bisogno di dataset enormi e diversificati. Il web è il loro buffet, e i tuoi contenuti sono nel menu.
- Training vs risposte in tempo reale: circa l’80% del crawling dei bot AI è per finalità di training, non solo per rispondere a query live.
- Nuovi pattern di crawling: i bot AI possono colpire i siti con raffiche enormi, a volte estraendo milioni di pagine in pochi giorni, soprattutto durante il retraining o l’aggiornamento dei modelli.
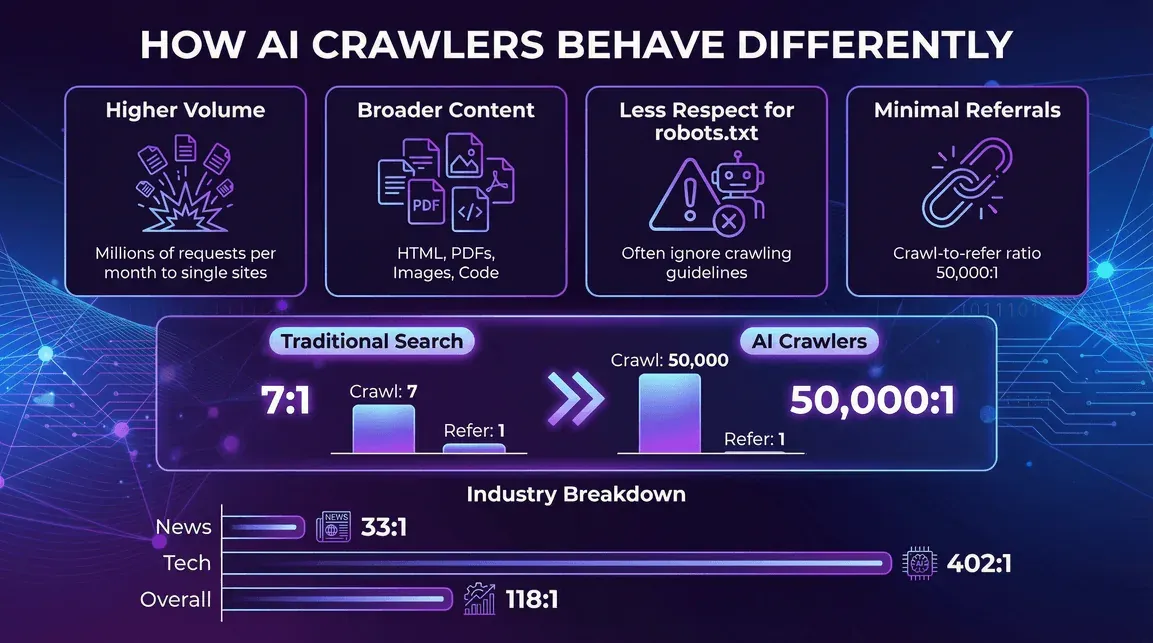
Come si comportano in modo diverso i crawler AI
- Volume più alto per singolo crawler: un solo bot AI può generare milioni di richieste al mese verso un singolo sito (esempio su Reddit).
- Tipologie di contenuto più ampie: non solo HTML, ma anche PDF, immagini, codice e tutto il resto.
- Minore rispetto per robots.txt: alcuni crawler AI ignorano, o rispettano solo in parte, le direttive di crawling (blog.cloudflare.com).
- Traffico di referral minimo. Questa è la parte che dovrebbe preoccupare di più gli editori. L’analisi crawl-to-click di Cloudflare di luglio 2025 ha stimato il rapporto a circa 38.000 pagine crawlate per ogni visita di referral per Anthropic, 1.091:1 per OpenAI e 194:1 per Perplexity. A confronto, il crawler di ricerca tradizionale di Google continua a rimandare un referral ogni poche pagine crawlate. I crawler AI prendono molto e restituiscono pochissimo — e il divario sta aumentando, perché sempre più risposte vengono mostrate direttamente nell’interfaccia del chatbot invece di portare l’utente al sito.
Traffico dei crawler AI per settore
Non tutti i settori vengono crawlati allo stesso modo. Per esempio:
- News e pubblicazioni: intensa attività dei crawler AI, ma rapporti di referral leggermente migliori (per esempio, il rapporto crawl-to-refer di Perplexity è 33:1 nei siti di news, contro 118:1 complessivo) (blog.cloudflare.com).
- Tecnologia ed elettronica: dominano GPTBot e Amazonbot, con rapporti crawl-to-refer ancora elevati (per esempio, il rapporto di OpenAI è 402:1 nel settore tech) (blog.cloudflare.com).
- Finanza, accademia e altri settori: ogni comparto ha il proprio mix di bot e tassi di referral, ma la tendenza è chiara: i crawler AI sono ovunque e la maggior parte non rimanda molto traffico indietro.
I principali crawler web nel 2026: chi sta crawlando di più il web?
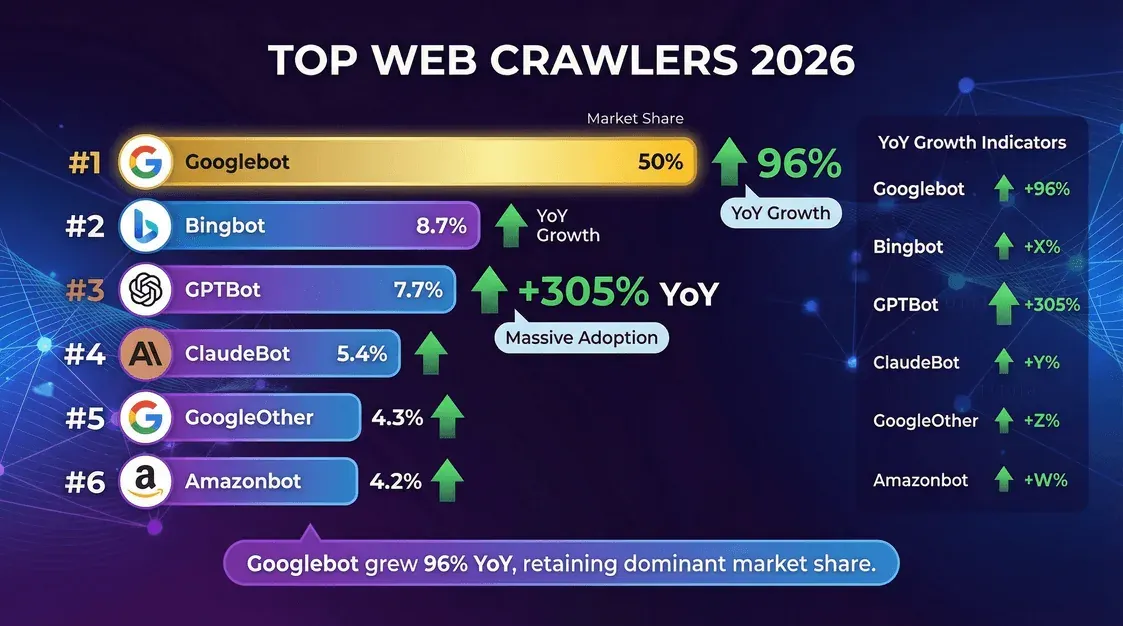
Chi sono i protagonisti di questo dramma del crawling? Ecco la classifica, basata sui dati di Cloudflare di metà 2025:
| Crawler (proprietario) | Quota delle richieste su pagine uniche (ott–nov 2025) | Note |
|---|---|---|
| Googlebot (Google) | 11,6% | Resta il crawler singolo più grande. Cloudflare YIR 2025: circa 200× il volume di PerplexityBot. |
| GPTBot (OpenAI) | 3,6% | Il più grande crawler dedicato al training AI. In calo rispetto alla quota di maggio 2025 dopo il cambio di denominatore di Cloudflare e l’affollamento del settore. |
| Bingbot (Microsoft) | 2,6% | Alimenta sia la ricerca Bing sia il grounding di Copilot. |
| Meta-ExternalAgent | 2,4% | Il crawler di ingestion dei contenuti di Meta per l’addestramento di Llama. Entrato nella top five nel 2025. |
| ClaudeBot (Anthropic) | 2,4% | In ripresa a fine 2025 dopo un forte calo anno su anno nella prima parte dell’anno. |
| Applebot (Apple) | in forte crescita | È balzato nella fascia alta nel Q1 2026, secondo analisi secondarie dei dati Cloudflare. |
| PerplexityBot | 0,06% | Quota assoluta minima, ma crescita relativa più rapida tra i principali bot AI. |
Fonte: Cloudflare Year in Review 2025, misurato in base alla quota di pagine uniche crawlate tra ottobre e novembre 2025. Nota: questo denominatore è diverso dalla cifra di “quota di tutte le richieste dei crawler” usata nei report precedenti di maggio 2025 — le classifiche sono confrontabili, ma le percentuali non lo sono direttamente.
Alcuni punti chiave:
- Googlebot è ancora il re, responsabile della metà di tutta l’attività di crawling.
- GPTBot e il crawler di Meta sono i più rapidi in crescita, con la quota di GPTBot triplicata in un anno.
- PerplexityBot e gli agenti ChatGPT-User hanno quote totali piccole, ma crescono a ritmo vertiginoso.
Benchmark del web crawling: tassi di crawling, throughput e prestazioni
 Il web crawling non riguarda solo il volume: riguarda velocità ed efficienza. Ecco cosa devi sapere su tassi di crawling e benchmark di prestazione nel 2026.
Il web crawling non riguarda solo il volume: riguarda velocità ed efficienza. Ecco cosa devi sapere su tassi di crawling e benchmark di prestazione nel 2026.
Crawl rate: quanto velocemente i crawler recuperano le pagine?
- Il crawl rate si misura di solito in pagine al secondo (o richieste al secondo) (IBM).
- Thread/connessioni parallele: più thread = maggiore crawl rate potenziale. Per esempio, 200 thread con un ritardo di 2 secondi per sito possono arrivare a circa 100 pagine al secondo (IBM).
- Benchmark reali: 100–200 pagine al secondo è tipico per un crawler ben ottimizzato su un cluster di server decente.
- Google e Bing: probabilmente recuperano migliaia di pagine al secondo a livello globale, distribuite su milioni di siti.
Fattori che influenzano il crawl rate
- Numero di thread/fetcher paralleli: più thread, più velocità (fino a incontrare altri colli di bottiglia).
- Numero di siti attivi: crawl parallelo su più domini moltiplica il throughput.
- Ritardo di crawling/tempo di attesa: più ritardo = crawl rate più lento.
- Limiti delle risorse: larghezza di banda, CPU e velocità di scrittura del database possono diventare colli di bottiglia.
- Prestazioni del sito target: siti lenti o con rate limit rallentano il crawling.
Per esempio, se il tuo crawler ha 100 thread e un ritardo di 1 secondo per sito, potresti recuperare circa 100 pagine al secondo — a meno che il database non regga il ritmo; in quel caso, il collo di bottiglia sarebbe lo storage, non la rete.
L’impatto del web crawling sul business: costi, opportunità e rischi
Il web crawling non è solo una curiosità tecnica: è una questione di business, con costi e opportunità reali.
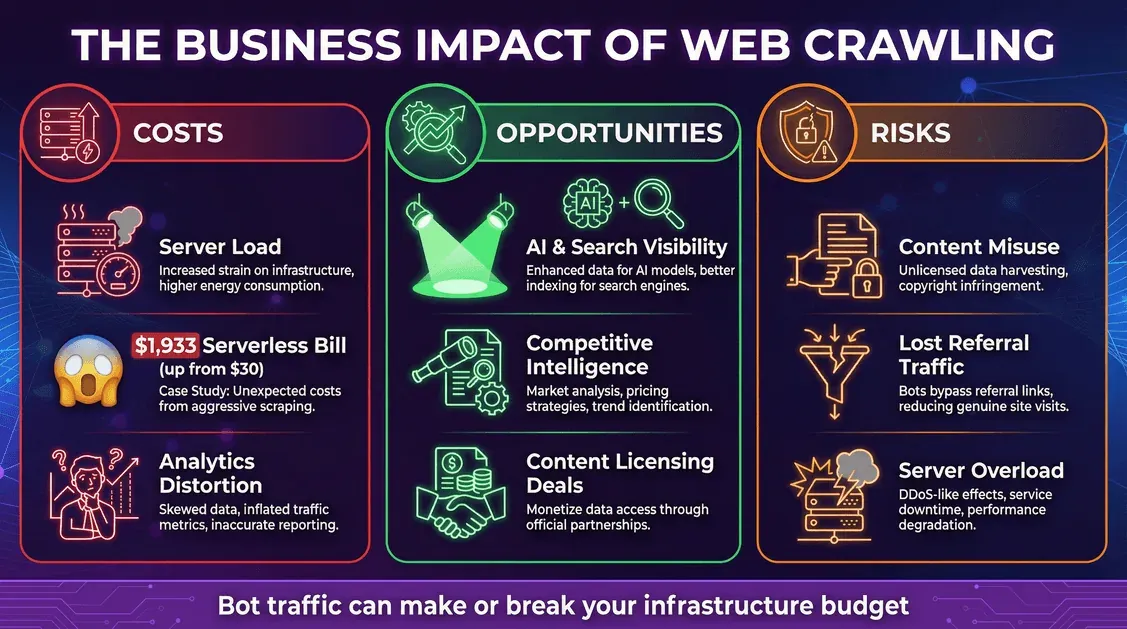
Costi: infrastruttura e bollette inattese
- Carico sul server: ogni richiesta di un bot consuma CPU, memoria e banda.
- Costi cloud: se usi un modello pay-per-use (come il serverless), i bot possono generare spese importanti. Uno sviluppatore ha visto il crawler di Meta generare 11 milioni di richieste in un mese, portando a una bolletta serverless di 1.933 dollari (da 30).
- Distorsione delle analytics: i bot possono alterare i dati web, rendendo più difficile interpretare il comportamento reale degli utenti.
Opportunità: visibilità e leva sui dati
- Visibilità su AI e ricerca: essere inclusi nei dati di training dell’AI o negli indici dei motori di ricerca può ampliare la portata del tuo brand (blog.cloudflare.com).
- Competitive intelligence: le aziende usano i crawler per ricerche di mercato, monitoraggio dei prezzi e altro ancora.
- Monetizzazione: alcuni editori stanno ormai concedendo in licenza i propri contenuti alle aziende AI.
Rischi: uso improprio dei contenuti e perdita di traffico
- Uso improprio dei contenuti: i crawler AI possono assorbire i tuoi contenuti nei propri modelli, a volte senza consenso o compenso chiari.
- Perdita di traffico di referral: le risposte AI possono soddisfare l’utente senza portarlo sul tuo sito, creando una sorta di “disintermediazione”.
- Sicurezza e downtime: crawler aggressivi possono sovraccaricare i server, causando rallentamenti o interruzioni.
Gestire il traffico dei web crawler: best practice
Quindi, come fai a evitare che i bot si mangino il tuo pranzo — o il tuo budget cloud?
1. Ottimizza il tuo robots.txt
- Usa
robots.txtper consentire o bloccare bot specifici. La maggior parte dei crawler affidabili (come Googlebot) lo rispetta, ma molti bot AI potrebbero non farlo (blog.cloudflare.com). - A metà 2025, circa il 14% dei principali siti aveva iniziato ad aggiungere regole esplicite per i bot AI (blog.cloudflare.com).
2. Usa strumenti di gestione dei bot
- I Web Application Firewall (WAF) e i servizi di bot management possono bloccare o limitare il rate di traffico sospetto.
- Cloudflare e altri provider offrono funzioni di mitigazione dei bot e persino strumenti di “AI Audit” per i creatori di contenuti (blog.cloudflare.com).
3. Implementa rate limiting e caching
- Limita le richieste troppo ravvicinate da un singolo bot.
- Servi contenuti in cache ai bot ogni volta che è possibile — non lasciare che facciano scattare funzioni serverless costose o query sul database (esempio su Reddit).
4. Monitora e analizza il traffico dei bot
- Tieni d’occhio i log del server. Sappi quali bot ti stanno visitando, con quale frequenza e quando.
- Imposta avvisi per picchi di traffico insoliti.
5. Anticipa i nuovi standard emergenti
- Tieni d’occhio nuovi meta tag o header HTTP per le autorizzazioni all’uso da parte dell’AI (per esempio,
<meta name="ai:allow" content="no">). - Segui iniziative di settore come ContentSignals.org) e protocolli di pagamento come x402.
Tendenze del web crawling da tenere d’occhio nel 2026 e oltre
Cos'è il data scraping e come farlo nel 2025 Get Started Free
Il panorama del web crawling si sta evolvendo rapidamente. Ecco cosa sto osservando io — e cosa dovresti osservare anche tu:
- Il crawling guidato dall’AI è destinato a crescere ancora: aspettati ancora più bot AI, capaci di crawlare più tipi di contenuti (testo, immagini, video).
- Licenze sui contenuti e standard di pagamento. La narrazione del “Far West” sta iniziando a sembrare superata. Anthropic ha annunciato a fine 2025 un accordo da 1,5 miliardi di dollari con gli autori per le rivendicazioni sui dati di training, il più grande accordo editore-AI fino a oggi. Meta ha firmato accordi pluriennali di licenza dei contenuti con CNN, Fox News, People Inc. e USA Today, e gli accordi AP–Google e Axios–OpenAI dell’inizio 2025 sono ormai considerati il modello da seguire più che l’eccezione. Continuano comunque a essere depositate nuove cause — cinque case editrici hanno citato in giudizio Meta a Manhattan il 5 maggio 2026 — quindi il quadro legale è tutt’altro che definito, ma la direzione è chiara: i contenuti vengono valutati, pagati e contesi in tribunale, non solo crawlati. Sul fronte dei protocolli, x402 e ContentSignals.org stanno iniziando a sembrare candidati seri rispettivamente per il livello dei pagamenti macchina-macchina e per quello delle autorizzazioni macchina-macchina.
- La regolamentazione sta arrivando: aspettati maggiore chiarezza legale su ciò che i bot possono e non possono fare, soprattutto per i dati di training dell’AI (reuters.com).
- Standard tecnici per l’uso dei contenuti: tieni d’occhio nuovi meta tag, estensioni di robots.txt e dichiarazioni leggibili dalle macchine sui bot.
- Collaborazione tra editori e AI: invece di essere bersagli passivi, sempre più editori negozieranno feed strutturati o API dedicate per le aziende AI.
Conclusione: cosa significano queste statistiche sul web crawling per il tuo business
Ecco il punto chiave: il web crawling è una forza dominante nel 2026, e non sta rallentando. I bot automatizzati — soprattutto i crawler AI — sono ormai responsabili di una fetta enorme del tuo traffico, e il loro impatto su infrastruttura, budget e strategia dei contenuti continua a crescere.
Cosa dovresti fare?
- Aspettati un traffico bot intenso: pianifica di conseguenza infrastruttura, budget e monitoraggio.
- Conosci i tuoi crawler: non tutti i bot sono uguali — adatta l’approccio a ciascuno.
- Monitora le metriche: traccia il traffico dei bot proprio come tracci i visitatori umani.
- Proteggi i tuoi contenuti e il tuo portafoglio: usa controlli tecnici, accordi legali e standard emergenti.
- Sfrutta il lato positivo: essere incluso negli indici AI e di ricerca può rafforzare il tuo brand — assicurati però di ricevere valore in cambio.
- Resta informato e adatta la strategia: il panorama del crawling cambia in fretta. Tieni d’occhio nuovi standard, normative e modelli di business.
Da persona che ha passato anni a costruire strumenti di automazione e AI — e oggi lavora in Thunderbit — posso dirti questo: le aziende che prosperano in questa nuova era sono quelle che considerano il web crawling una priorità strategica, non un semplice fastidio tecnico. Che tu lavori in sales, ecommerce, marketing o real estate, capire le statistiche sul web crawling e i benchmark di settore è ormai un requisito di base.
Quindi, la prossima volta che controlli i log del server e vedi sfilare una parata di bot, non limitarti a sospirare e andare avanti. Usa i dati. Metti il tuo sito a confronto con un benchmark. Adatta le tue tattiche. E ricorda: nell’era dell’AI, i bot non stanno arrivando soltanto — sono già qui. Fai in modo che lavorino per te, non il contrario.
Resta vigile, resta curioso, e che i log del tuo server siano sempre dalla tua parte.
Prova gratis Thunderbit AI Web Scraper
Vuoi saperne di più su data scraping, automazione e produttività alimentata dall’AI? Dai un’occhiata al blog di Thunderbit per approfondimenti, guide pratiche e le ultime tendenze. E se sei pronto a prendere il controllo dei tuoi dati, prova l’estensione Chrome di Thunderbit per il web scraping con l’AI: niente codice, niente complicazioni, solo risultati.
Prova l'Estrattore Web AI Get Started Free
Citazioni e letture aggiuntive:
- Da Googlebot a GPTBot: chi sta crawlando il tuo sito nel 2025 (Cloudflare)
- Il report di Cloudflare rivela che il traffico Internet globale è cresciuto del 19% nel 2025 — ma gran parte era solo bot (TechRadar)
- Come funziona il crawling nell’era dell’AI 2025 (Webscraft)
- Il crawler di Meta ha fatto 11 milioni di richieste al mio sito in 30 giorni (Reddit)
- Monitoring - Web Crawler Crawl Rate (IBM)
- Una timeline dei principali accordi tra editori e aziende AI nel 2025 (Digiday)
- Lancio della fondazione x402 con Coinbase (Cloudflare)




