Immagina la scena: siamo nel 2025, ti stai godendo il tuo caffè del mattino e vuoi sapere se Walmart ha appena tagliato il prezzo di quel televisore da 65 pollici che hai puntato—oppure magari gestisci un e-commerce e hai bisogno di monitorare in tempo reale prezzi, disponibilità e recensioni su Walmart. Controllare ogni prodotto a mano ogni giorno? Sarebbe un lavoro infinito (e pure noioso). Ma con un po’ di Python e le giuste dritte sull’estrazione dati, puoi automatizzare tutto e accedere a una vera miniera di informazioni.
Negli ultimi anni mi sono occupato di automazione e AI per aziende. L’estrarre dati da Walmart è una di quelle “armi segrete” che trasformano ore di ricerche ripetitive in poche righe di codice—e in questa guida ti spiego come fare. Vedremo cos’è il Walmart scraping, perché è così prezioso per il business nel 2025 e come costruire un Walmart scraper robusto in Python—passo dopo passo, con esempi pratici e consigli utili. Prendi il tuo caffè (o il tuo snack preferito da debug) e partiamo.
Cos’è il Walmart Scraping? Le Basi per il 2025
In poche parole: Walmart scraping significa estrarre in automatico dati su prodotti, prezzi e recensioni dal sito di Walmart tramite software—di solito uno script che si comporta come un browser super veloce. Invece di copiare e incollare a mano (che nessuno ama fare), scrivi uno script Python che recupera le pagine di Walmart, estrae le informazioni che ti servono e le salva per l’analisi.
Perché Python? Perché è il coltellino svizzero dell’estrazione dati: facile da leggere, pieno di librerie (come Requests, BeautifulSoup e pandas) e supportato da una community enorme. Che tu sia un ricercatore indipendente o parte di un team aziendale, Python rende il Walmart scraping accessibile anche a chi non è uno sviluppatore a tempo pieno.
È importante distinguere tra scraping per uso personale (ad esempio, monitorare i prezzi di alcuni prodotti per i tuoi acquisti) e per uso aziendale (come monitorare migliaia di SKU per analisi di mercato). La complessità cresce in fretta per le aziende, così come le sfide tecniche—soprattutto perché Walmart non offre un’API pubblica per i prodotti nel 2025 ().
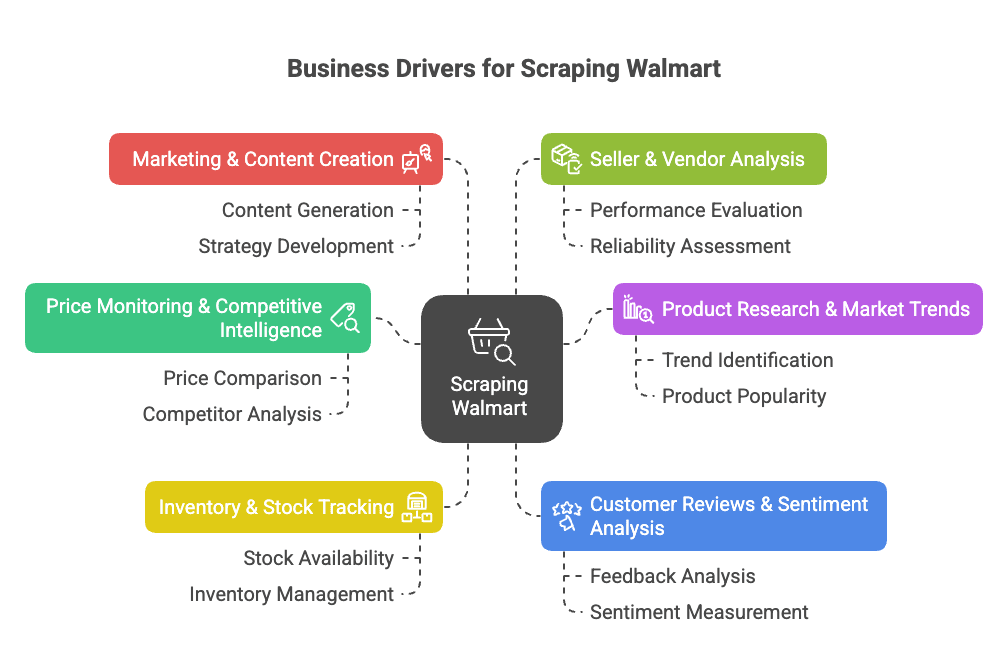
Perché Fare Scraping su Walmart? I Vantaggi per il Business
Walmart non è solo il più grande rivenditore fisico degli Stati Uniti—ormai è un colosso digitale, con vendite online che hanno superato e l’e-commerce che rappresenta quasi il 18% delle vendite totali (). Questo significa una quantità enorme di prodotti, prezzi, recensioni e trend—tutti dati preziosi da analizzare.
Perché puntare sull’estrarre dati da Walmart? Ecco i motivi principali per le aziende:
- Monitoraggio Prezzi & Analisi Competitiva: Tieni d’occhio in tempo reale prezzi, promozioni e cambi di catalogo per ottimizzare le tue strategie ().
- Ricerca Prodotti & Trend di Mercato: Analizza l’assortimento, le specifiche e le tendenze di categoria per scovare opportunità o lacune ().
- Monitoraggio Stock & Disponibilità: Controlla la disponibilità dei prodotti per ottimizzare la supply chain o sfruttare le carenze dei concorrenti ().
- Recensioni Clienti & Analisi del Sentiment: Raccogli e analizza le recensioni per migliorare i prodotti o individuare criticità ().
- Marketing & Creazione Contenuti: Scopri quali prodotti sono “Bestseller”, come vengono presentati e quali contenuti convertono meglio ().
- Analisi Venditori & Fornitori: Identifica i migliori venditori terzi o offerte non autorizzate ().
Ecco una tabella riassuntiva con i casi d’uso, i destinatari e i benefici:
| Caso d'Uso | Chi ne beneficia | Benefici & ROI |
|---|---|---|
| Monitoraggio Prezzi | Team Pricing & Sales | Prezzi dei concorrenti in tempo reale, pricing dinamico, protezione dei margini |
| Analisi Assortimento & Catalogo | Product Management, Merchandising | Individuazione di lacune, lancio nuovi prodotti, catalogo più completo |
| Monitoraggio Stock | Operations & Supply Chain | Migliore previsione della domanda, meno out-of-stock, distribuzione ottimizzata |
| Recensioni & Sentiment | Sviluppo Prodotto, Customer Experience | Miglioramenti basati sui dati, clienti più soddisfatti |
| Trend di Mercato & Analytics | Strategia & Ricerca Mercato | Individuazione trend, decisioni strategiche, ingresso anticipato in nuovi segmenti |
| Strategia Prezzi & Contenuti | Marketing & E-commerce | Ottimizzazione prezzi, apprendimento dai contenuti vincenti |
| Monitoraggio Venditori | Team Sales & Partnership | Trovare partner, proteggere il brand, monitorare venditori non autorizzati |
In sintesi? Estrarre dati da Walmart ti fa risparmiare tempo, aumenta i ricavi e ti dà un vantaggio competitivo sui dati. Invece di controllare manualmente decine di pagine ogni mattina, il tuo script può estrarre migliaia di prodotti in pochi minuti ().
L’estrazione dati da Walmart è una svolta per team e-commerce, vendite e ricerca di mercato. Con gli strumenti giusti, puoi automatizzare la raccolta dati e concentrarti sulle analisi, non sulle attività ripetitive.
Walmart Scraping con Python: Cosa Serve
Prima di iniziare, prepara l’ambiente Python. Ecco cosa ti serve:
- Python 3.9+ (meglio ancora 3.11 o 3.12 per il 2025)
- Requests: per scaricare le pagine web
- BeautifulSoup (bs4): per analizzare l’HTML
- pandas: per organizzare ed esportare i dati
- json: per gestire dati JSON (già incluso)
- Un browser con strumenti sviluppatore: per ispezionare la struttura delle pagine Walmart (F12 è il tuo migliore amico)
- pip: per installare i pacchetti Python
Comando rapido per installare:
1pip install requests beautifulsoup4 pandasOpzionale: per tenere il progetto ordinato, crea un ambiente virtuale:
1python3 -m venv walmart-scraper
2source walmart-scraper/bin/activate # Su Mac/Linux
3# oppure
4walmart-scraper\\Scripts\\activate.bat # Su WindowsTesta l’installazione con:
1import requests, bs4, pandas
2print("Librerie caricate correttamente!")Se vedi questo messaggio, sei pronto.
Step 1: Prepara il tuo Walmart Scraper in Python
Organizzati così:
- Crea una cartella di progetto (es.
walmart_scraper/). - Apri il tuo editor di codice (VSCode, PyCharm o anche Notepad++—nessun giudizio).
- Crea un nuovo script (es.
walmart_scraper.py).
Ecco un template di partenza:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4import jsonOra sei pronto per il passo successivo: scaricare le pagine prodotto di Walmart.
Step 2: Scarica le Pagine Prodotto di Walmart con Python
Per estrarre dati da Walmart, devi ottenere l’HTML di una pagina prodotto. Ma attenzione: Walmart è molto attento a bloccare i bot. Se usi solo requests.get(url), probabilmente ti ritroverai subito davanti a un controllo "Sei un robot o un umano?".
Il trucco? Simula un vero browser. Imposta header come User-Agent e Accept-Language per sembrare Chrome o Firefox.
Ecco come:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9"
4}
5response = requests.get(url, headers=headers)
6html = response.textConsiglio: Usa requests.Session() per mantenere i cookie e sembrare ancora più "umano":
1session = requests.Session()
2session.headers.update(headers)
3session.get("<https://www.walmart.com/>") # Visita la homepage per impostare i cookie
4response = session.get(product_url)Controlla sempre response.status_code (deve essere 200). Se ricevi una pagina strana o un CAPTCHA, rallenta, cambia IP o fai una pausa. I sistemi anti-bot di Walmart sono molto sofisticati ().
Come Gestire le Difese Anti-Bot di Walmart
Walmart utilizza strumenti come Akamai e PerimeterX per individuare i bot analizzando IP, header, cookie e persino il fingerprint TLS. Ecco come restare "invisibile":
- Imposta sempre header realistici (vedi sopra).
- Rallenta le richieste—attendi 3–6 secondi tra una pagina e l’altra.
- Randomizza i tempi di attesa per non sembrare un robot iperattivo.
- Ruota i proxy se fai scraping su larga scala (ne parliamo dopo).
- Se compare un CAPTCHA, fermati—non forzare.
Se vuoi essere ancora più "stealth", librerie come curl_cffi possono rendere le richieste Python ancora più simili a quelle di Chrome (). Ma per la maggior parte dei casi, header e pazienza bastano.
Step 3: Estrai i Dati Prodotto da Walmart con BeautifulSoup
Ora la parte interessante: estrarre i dati che ti servono. Il sito di Walmart è costruito con Next.js, quindi molte informazioni sono inserite in un tag <script id="__NEXT_DATA__"> come un grande JSON.
Ecco come recuperarlo:
1from bs4 import BeautifulSoup
2import json
3soup = BeautifulSoup(html, "html.parser")
4script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
5if script_tag:
6 json_text = script_tag.string
7 data = json.loads(json_text)Ora hai un dizionario Python con tutte le info del prodotto. Di solito, i dettagli sono qui:
1product_data = data["props"]["pageProps"]["initialData"]["data"]["product"]Poi estrai ciò che ti interessa:
1name = product_data.get("name")
2price_info = product_data.get("price", {})
3current_price = price_info.get("price")
4currency = price_info.get("currency")
5rating_info = product_data.get("rating", {})
6average_rating = rating_info.get("averageRating")
7review_count = rating_info.get("numberOfReviews")
8description = product_data.get("shortDescription") or product_data.get("description")Perché usare il JSON? Perché è strutturato, stabile e meno soggetto a cambiamenti rispetto all’HTML. Inoltre, spesso contiene più dettagli di quelli visibili sulla pagina ().
Gestire Contenuti Dinamici e Dati JSON
A volte, recensioni o disponibilità sono caricati dinamicamente via JavaScript o API. La buona notizia: il JSON iniziale spesso contiene già ciò che serve. Se manca qualcosa, usa la scheda Network degli strumenti sviluppatore per trovare le API usate da Walmart e replica quelle richieste.
Ma per la maggior parte dei dati prodotto, il JSON __NEXT_DATA__ è la soluzione migliore.
Step 4: Salva ed Esporta i Dati di Walmart
Una volta ottenuti i dati, salvali in formato strutturato—CSV, Excel o JSON vanno benissimo. Ecco come fare con pandas:
1import pandas as pd
2product_record = {
3 "Nome Prodotto": name,
4 "Prezzo (USD)": current_price,
5 "Valutazione": average_rating,
6 "Numero Recensioni": review_count,
7 "Descrizione": description
8}
9df = pd.DataFrame([product_record])
10df.to_csv("walmart_products.csv", index=False)Se estrai più prodotti, aggiungi ogni record a una lista e crea il DataFrame alla fine.
Vuoi Excel? Usa df.to_excel("walmart_products.xlsx", index=False) (assicurati di avere openpyxl). Per JSON: df.to_json("walmart_products.json", orient="records", indent=2).
Consiglio: Controlla sempre i dati esportati per assicurarti che corrispondano a quelli sul sito. Non c’è niente di peggio che scoprire di aver estratto 1.000 prezzi "None" perché Walmart ha cambiato un nome chiave.
Step 5: Scala il tuo Walmart Scraper
Vuoi estrarre dati su larga scala? Ecco come gestire più pagine prodotto:
1product_urls = [
2 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
3 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
4 # ...altre URL
5]
6all_records = []
7for url in product_urls:
8 resp = session.get(url)
9 # ...parsing ed estrazione come prima...
10 all_records.append(product_record)
11 time.sleep(random.uniform(3, 6)) # Sii gentile!Se non hai una lista di URL, puoi partire da una pagina di ricerca, estrarre i link ai prodotti e poi fare scraping su ciascuno ().
Attenzione: Estrarre dati da centinaia o migliaia di pagine velocemente ti farà quasi sicuramente bloccare l’IP. Qui entrano in gioco i proxy.
Usare Proxy e Scraper API per Walmart
I proxy ti permettono di cambiare indirizzo IP, rendendo più difficile per Walmart bloccarti. Puoi acquistare proxy residenziali (che sembrano utenti reali) o usare pool di proxy. Ecco come usarli con requests:
1proxies = {
2 "http": "<http://your.proxy.address>:port",
3 "https": "<https://your.proxy.address>:port"
4}
5response = session.get(url, proxies=proxies)Per scraping su larga scala, puoi usare una scraper API—questi servizi gestiscono proxy, CAPTCHA e anche il rendering JavaScript per te. Tu invii una URL di Walmart, loro ti restituiscono i dati (a volte già in JSON).
Ecco un confronto rapido:
| Approccio | Pro | Contro | Ideale per |
|---|---|---|---|
| Python + Proxy fai-da-te | Controllo totale, economico per piccoli volumi | Manutenzione, costi proxy, rischio blocchi | Sviluppatori, esigenze personalizzate |
| Scraper API di terze parti | Facile, gestisce anti-bot, scala bene | Costo su grandi volumi, meno flessibilità, dipendenza da terzi | Aziende, grandi volumi, risultati rapidi |
Se non sei uno sviluppatore o vuoi solo i dati in fretta, strumenti come fanno tutto in pochi click—senza codice, senza proxy, senza stress. (Ne parliamo tra poco.)
Le Sfide Più Comuni nell’Estrarre Dati da Walmart (e Come Superarle)
Estrarre dati da Walmart non è sempre una passeggiata. Ecco i problemi più frequenti—e come risolverli:
- Difese Anti-Bot Aggressive: Walmart usa controlli avanzati (IP, header, cookie, fingerprint TLS, JavaScript). Soluzione: header realistici, sessioni, ritardi, rotazione proxy ().
- CAPTCHA: Se incontri un CAPTCHA, fermati e riprova più tardi. Se il problema persiste, valuta servizi di risoluzione CAPTCHA (ma aumentano costi e complessità) ().
- Cambi Strutturali del Sito: Walmart aggiorna spesso il sito. Se lo scraper si rompe, ispeziona di nuovo la struttura JSON e aggiorna il codice. Un codice modulare aiuta.
- Paginazione & Sottopagine: Per grandi quantità di dati, gestisci la paginazione con loop e condizioni di stop corrette ().
- Volume Dati & Limiti di Richiesta: Per scraping massivo, suddividi le richieste e salva i risultati parziali. Non caricare 100.000 prodotti tutti in memoria.
- Aspetti Legali & Etici: Estrai solo dati pubblici, rispetta i termini di Walmart e non sovraccaricare i server. Se usi i dati per business, verifica sempre la conformità.
Quando passare a una soluzione gestita? Se passi più tempo a combattere i CAPTCHA che ad analizzare i dati, valuta strumenti come Thunderbit o una scraper API. Per chi non programma, i tool no-code sono spesso la scelta più intelligente ().
Walmart Scraping con Python: Codice Completo Esempio
Ecco uno script Python completo e commentato per estrarre dati prodotto da Walmart:
1import requests
2from bs4 import BeautifulSoup
3import json
4import pandas as pd
5import time
6import random
7# Imposta sessione e header
8session = requests.Session()
9session.headers.update({
10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
11 "Accept-Language": "en-US,en;q=0.9"
12})
13# Visita la homepage per impostare i cookie
14session.get("<https://www.walmart.com/>")
15# Lista di URL prodotto da estrarre
16product_urls = [
17 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
18 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
19 # Aggiungi altre URL se necessario
20]
21all_products = []
22for url in product_urls:
23 try:
24 response = session.get(url)
25 except Exception as e:
26 print(f"Errore richiesta per \{url\}: \{e\}")
27 continue
28 if response.status_code != 200:
29 print(f"Impossibile scaricare \{url\} (status \{response.status_code\})")
30 continue
31 soup = BeautifulSoup(response.text, "html.parser")
32 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
33 if not script_tag:
34 print(f"Script dati non trovato per \{url\} - forse bloccato o formato pagina cambiato.")
35 continue
36 try:
37 data = json.loads(script_tag.string)
38 except json.JSONDecodeError as e:
39 print(f"Errore parsing JSON per \{url\}: \{e\}")
40 continue
41 try:
42 product_info = data["props"]["pageProps"]["initialData"]["data"]["product"]
43 except KeyError:
44 print(f"Dati prodotto non trovati nel JSON per \{url\}.")
45 continue
46 name = product_info.get("name")
47 brand = product_info.get("brand", {}).get("name") or product_info.get("brand", "")
48 price_obj = product_info.get("price", {})
49 price = price_obj.get("price")
50 currency = price_obj.get("currency")
51 orig_price = price_obj.get("priceStrikethrough") or price_obj.get("price_strikethrough")
52 rating_obj = product_info.get("rating", {})
53 avg_rating = rating_obj.get("averageRating")
54 review_count = rating_obj.get("numberOfReviews")
55 desc = product_info.get("description") or product_info.get("shortDescription") or ""
56 product_record = {
57 "URL": url,
58 "Nome": name,
59 "Brand": brand,
60 "Prezzo": price,
61 "Valuta": currency,
62 "PrezzoOriginale": orig_price,
63 "ValutazioneMedia": avg_rating,
64 "NumeroRecensioni": review_count,
65 "Descrizione": desc
66 }
67 all_products.append(product_record)
68 # Ritardo casuale per evitare blocchi
69 time.sleep(random.uniform(3.0, 6.0))
70df = pd.DataFrame(all_products)
71print(df.head(5))
72df.to_csv("walmart_scrape_output.csv", index=False)Personalizza:
- Aggiungi altre URL a
product_urls. - Modifica i campi estratti secondo le tue esigenze.
- Regola il ritardo in base al rischio che vuoi correre.
Conclusioni & Cosa Ricordare
Ricapitolando:
- Estrarre dati da Walmart è un modo potente per ottenere dati su prezzi, prodotti e recensioni—fondamentali per analisi competitiva, pricing e sviluppo prodotto nel 2025.
- Python è lo strumento ideale: Requests, BeautifulSoup e pandas ti permettono di creare uno scraper robusto anche senza essere esperto di codice.
- Le difese anti-bot sono reali: Simula header browser, usa sessioni, inserisci ritardi e ruota proxy se aumenti il volume.
- Estrai i dati dal JSON
__NEXT_DATA__: È più pulito, stabile e meno soggetto a rotture rispetto all’HTML. - Esporta i dati per l’analisi: Usa pandas per salvare in CSV, Excel o JSON.
- Scala con attenzione: Per grandi volumi, valuta proxy o scraper API. Se non sei tecnico, gestisce Walmart (e altri siti) in pochi click—senza codice. Puoi anche esportare direttamente su Excel, Google Sheets, Airtable o Notion gratis ().
Il mio consiglio:
Inizia in piccolo—estrai un solo prodotto, poi qualche decina. Verifica sempre l’accuratezza dei dati. Rispetta i termini di Walmart e non sovraccaricare i server. Se le esigenze crescono, valuta strumenti gestiti o API per risparmiare tempo e fatica. E se ti stanchi di debuggare Python, ricorda: con Thunderbit puoi estrarre dati da Walmart (e quasi ogni sito) in due click, lasciando all’AI tutto il lavoro pesante ().
Vuoi approfondire scraping, automazione dati o produttività con l’AI? Trovi altre guide sul .
Buon scraping—che i tuoi dati siano sempre freschi, accurati e senza CAPTCHA.
P.S. Se ti ritrovi a fare scraping su Walmart alle 2 di notte borbottando davanti allo schermo, sappi che ci siamo passati tutti. Il debug fa parte della crescita di ogni data analyst!
Domande Frequenti
1. È legale estrarre dati dal sito di Walmart usando Python?
Estrarre dati pubblici per uso personale o analisi non commerciale di solito è permesso, ma per usi aziendali possono esserci questioni legali ed etiche. Consulta sempre i termini di servizio di Walmart e assicurati di non violare limiti di richiesta, sovraccaricare i server o raccogliere dati sensibili.
2. Che tipo di dati posso estrarre da Walmart con Python?
Puoi ottenere nomi prodotto, prezzi, brand, descrizioni, recensioni clienti, valutazioni, disponibilità e altro—soprattutto analizzando il JSON strutturato nel tag <script id="__NEXT_DATA__"> di Walmart.
3. Come evito di essere bloccato durante l’estrazione dati da Walmart?
Imposta header realistici, usa sessioni, inserisci ritardi casuali tra le richieste (3–6 secondi), ruota i proxy e non inviare troppe richieste in poco tempo. Per progetti grandi, valuta scraper API o strumenti come Thunderbit che gestiscono automaticamente le difese anti-bot.
4. Posso scalare l’estrazione dati a centinaia o migliaia di pagine prodotto Walmart?
Sì, ma dovrai gestire proxy, limitare le richieste e forse usare una scraper API per efficienza. Walmart ha difese anti-bot robuste, quindi scalare senza preparazione può portare a blocchi o CAPTCHA.
5. Qual è il modo più semplice per estrarre dati da Walmart se non so programmare?
Strumenti come Thunderbit AI Web Scraper Chrome Extension ti permettono di estrarre dati dalle pagine prodotto Walmart senza scrivere codice. Gestisce le protezioni anti-bot, supporta l’esportazione su Excel, Notion e Sheets, ed è perfetto per chi non programma o per team aziendali che vogliono risultati rapidi.