Il web trabocca di dati, ma c’è un problema: raccoglierli manualmente è divertente quasi quanto guardare asciugare la vernice — e anche un po’ meno produttivo. Nel 2025, le aziende nuotano in più contenuti web che mai, con l’accesso giornaliero ai dati web dell’azienda media salito da 1,2 TB nel 2020 a 8 TB nel 2025 (). Che tu lavori in sales, marketing, ecommerce o operations, la necessità di dati web rapidi, strutturati e accurati non è solo un “nice to have” — è un’esigenza operativa. E diciamocelo: nessuno ha tempo per maratone infinite di copia-incolla.
Ecco perché gli strumenti di content crawling hanno conosciuto un boom di popolarità. Questi strumenti — dalle estensioni Chrome basate su AI alle piattaforme enterprise — ti permettono di automatizzare l’intero processo, trasformando pagine web caotiche in fogli di calcolo puliti, database o dashboard in tempo reale. Lavoro da anni nel SaaS e nell’automazione, e posso dirti che lo strumento giusto non fa solo risparmiare tempo: può cambiare il modo in cui lavora il tuo team. Quindi, vediamo i migliori 18 strumenti di content crawling per un web scraping efficiente nel 2025, con un focus su ciò che rende unico ciascuno, su come si adattano a diverse esigenze aziendali e su come scegliere quello più adatto al tuo flusso di lavoro.
Perché le aziende hanno bisogno dei migliori strumenti di content crawling
Se hai mai provato a costruire una lista di lead, monitorare i prezzi dei concorrenti o tracciare il sentiment del mercato a mano, sai quanto rapidamente la raccolta manuale dei dati può trasformarsi in un incubo. È lenta, soggetta a errori e, quando hai finito, i dati potrebbero essere già obsoleti. Ecco perché oltre il 70% delle aziende ha adottato l’estrazione web automatizzata entro il 2025, riducendo il lavoro manuale di circa il 60% ().
Gli strumenti di content crawling automatizzano l’estrazione di dati strutturati dai siti web, rendendo possibile:
- Inserire lead freschi nel CRM (niente più copia-incolla da directory)
- Monitorare prezzi e livelli di stock dei concorrenti in tempo reale
- Raccogliere recensioni, notizie e menzioni sui social media per insight di marketing
- Creare dataset personalizzati per ricerca o analisi
- Programmare estrazioni periodiche dei dati per report ricorrenti
E il ROI è reale: le aziende che usano il web scraping hanno dichiarato di aver risparmiato complessivamente oltre 500 milioni di dollari tra il 2020 e il 2025, con un aumento dell’efficienza operativa del 20–40% (). La conclusione? Gli strumenti di content crawling liberano il tuo team per concentrarsi sulla strategia, non sulla fatica ripetitiva.
Come abbiamo selezionato i migliori strumenti di content crawling
Non tutti i web scraper sono uguali. Quando ho preparato questa lista, ho valutato gli strumenti dal punto di vista di utenti aziendali reali — team sales, marketing, operations e research che hanno bisogno di risultati, non di grattacapi. Ecco cosa contava di più:
- Facilità d’uso: gli utenti non tecnici possono iniziare rapidamente? C’è un’interfaccia point-and-click o assistenza AI?
- Automazione e funzionalità: lo strumento gestisce paginazione, sottopagine, pianificazione e contenuti dinamici? Può girare nel cloud per velocità e scalabilità?
- Output e integrazione dei dati: puoi esportare in Excel, CSV, Google Sheets, Airtable, Notion o collegarti via API?
- Scalabilità: è adatto a lavori occasionali o a progetti enormi e continuativi?
- Personalizzazione: puoi modificare la logica di estrazione, aggiungere campi personalizzati o gestire siti complessi?
- Conformità e privacy: lo strumento ti aiuta a restare in linea con GDPR, CCPA e i termini dei siti?
- Supporto e community: ci sono documentazione, assistenza o una community di utenti per aiutarti a risolvere i problemi?
- Costo: c’è un piano gratuito o una prova? Il prezzo è adatto alla tua scala e al tuo budget?
E naturalmente, ho dedicato un’attenzione speciale a Thunderbit — lo strumento che io e il mio team abbiamo costruito — perché credo sinceramente che sia il modo più semplice per iniziare con il web scraping basato su AI per gli utenti business.
I 18 migliori strumenti di content crawling per un web scraping efficiente
Vediamo il meglio del meglio, dalla semplicità potenziata dall’AI ai tool per sviluppatori e tutto ciò che sta nel mezzo.
1. Thunderbit
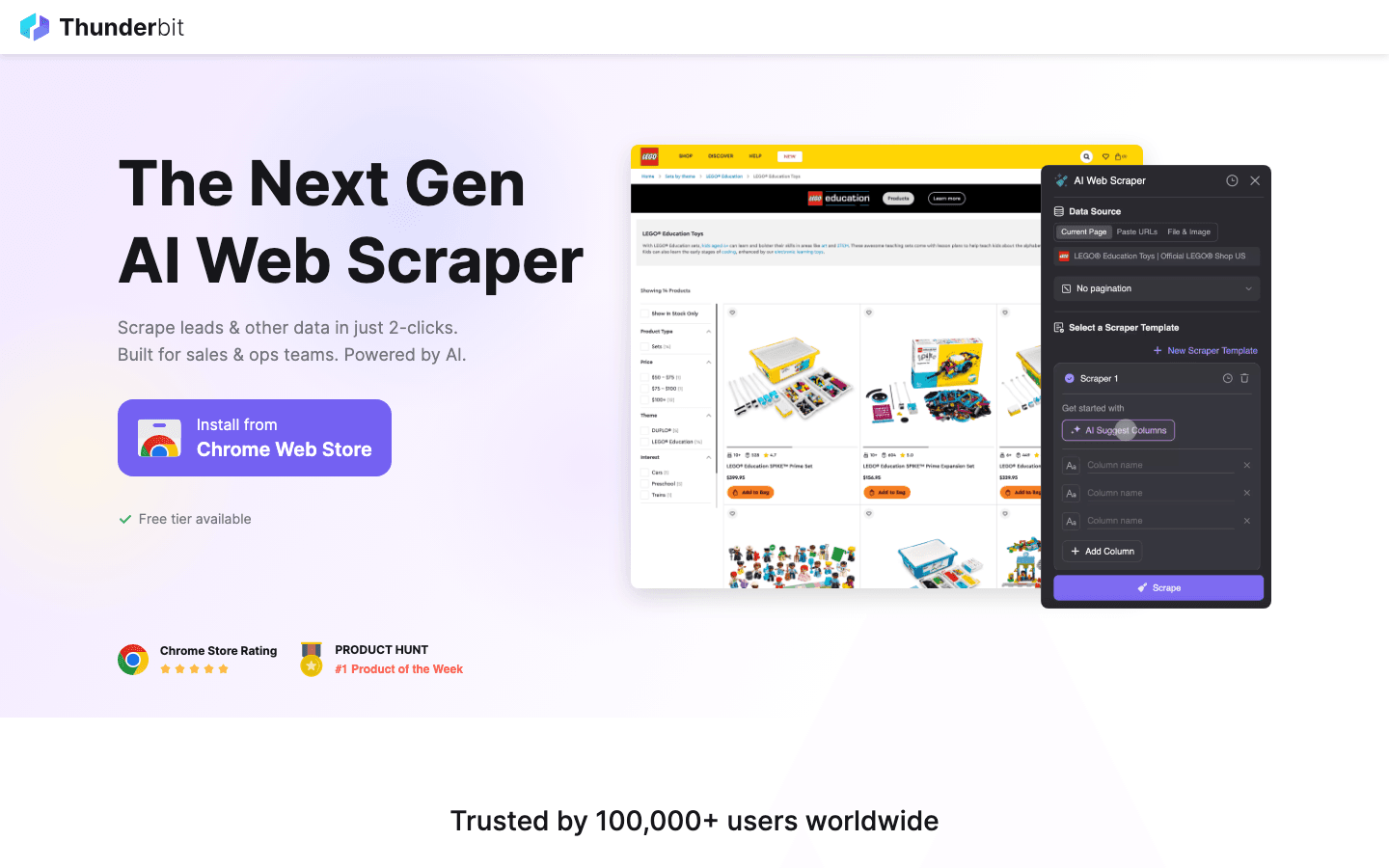 è un’estensione Chrome per AI web scraping pensata per utenti business che vogliono risultati, e in fretta. La sua funzione distintiva è AI Suggest Fields: basta visitare una pagina web, fare clic su “AI Suggest” e l’AI di Thunderbit legge la pagina, suggerisce i campi da estrarre e configura lo scraper per te. Niente codice, niente smanettamenti con i selettori: solo clic, estrazione ed export.
è un’estensione Chrome per AI web scraping pensata per utenti business che vogliono risultati, e in fretta. La sua funzione distintiva è AI Suggest Fields: basta visitare una pagina web, fare clic su “AI Suggest” e l’AI di Thunderbit legge la pagina, suggerisce i campi da estrarre e configura lo scraper per te. Niente codice, niente smanettamenti con i selettori: solo clic, estrazione ed export.
- Scraping di sottopagine: Thunderbit può visitare automaticamente ogni sottopagina (come i dettagli di prodotto o profilo) e arricchire il dataset, perfetto per lead generation o ricerche ecommerce.
- Paginazione e template: gestisce elenchi multi-pagina e offre template immediati per siti come Amazon, Zillow e Instagram.
- Export dati gratuito: esporta in Excel, Google Sheets, Airtable, Notion, CSV o JSON — senza paywall.
- AI Autofill: automatizza la compilazione di form online con l’AI, andando oltre lo scraping e arrivando all’automazione dei flussi di lavoro.
- Scraping cloud e browser: scegli lo scraping cloud veloce per i siti pubblici o la modalità browser per le sessioni con login.
- Prezzi: gratuito fino a 6 pagine (o 10 con una prova), con piani a pagamento a partire da soli 15 $/mese.
Thunderbit è perfetto per team sales, marketing e operations che vogliono automatizzare la raccolta dati senza problemi tecnici. È lo strumento che avrei voluto avere anni fa: oggi chiunque può creare una lista di lead o monitorare i concorrenti in pochi minuti.
2. Scrapy
 è una potenza open source per sviluppatori. È un framework basato su Python che ti consente di scrivere spider personalizzati per fare crawling ed estrarre dati su larga scala. Scrapy è progettato per velocità e flessibilità, con supporto per crawling asincrono, pipeline personalizzate, rotazione dei proxy e integrazione con database o API.
è una potenza open source per sviluppatori. È un framework basato su Python che ti consente di scrivere spider personalizzati per fare crawling ed estrarre dati su larga scala. Scrapy è progettato per velocità e flessibilità, con supporto per crawling asincrono, pipeline personalizzate, rotazione dei proxy e integrazione con database o API.
- Ideale per: sviluppatori e data engineer che costruiscono progetti di scraping grandi, complessi o ricorrenti.
- Punti di forza: controllo totale, estendibilità, community enorme e affidabilità collaudata.
- Limiti: curva di apprendimento ripida per chi non programma; nessuna interfaccia visuale.
Se mastichi Python e vuoi creare crawler robusti e scalabili, Scrapy è lo standard di riferimento.
3. Octoparse
 è un web scraper no-code basato sul cloud con un’interfaccia visuale drag-and-drop. Puoi selezionare i dati con point-and-click, configurare la paginazione e persino usare il rilevamento pattern assistito dall’AI per velocizzare la configurazione.
è un web scraper no-code basato sul cloud con un’interfaccia visuale drag-and-drop. Puoi selezionare i dati con point-and-click, configurare la paginazione e persino usare il rilevamento pattern assistito dall’AI per velocizzare la configurazione.
- Template predefiniti: estrai dati da siti popolari come Amazon, Twitter e Google Maps in pochi minuti.
- Scraping cloud e pianificazione: esegui i job sui server di Octoparse, programma attività ricorrenti e gestisci progetti su larga scala.
- Opzioni di export: CSV, Excel, JSON, integrazione API.
- Prezzi: piano gratuito con limiti; i piani a pagamento partono da circa 75 $/mese.
Octoparse è ideale per business analyst e non programmatori che vogliono uno scraping potente senza scrivere codice.
4. ParseHub
 è un web scraper visuale che eccelle nella gestione di contenuti dinamici e strutture complesse dei siti. La sua interfaccia point-and-click ti consente di creare flussi di lavoro con logica condizionale, loop e navigazione multilivello.
è un web scraper visuale che eccelle nella gestione di contenuti dinamici e strutture complesse dei siti. La sua interfaccia point-and-click ti consente di creare flussi di lavoro con logica condizionale, loop e navigazione multilivello.
- Contenuti dinamici: gestisce menu a tendina, infinite scroll ed elementi interattivi.
- Esecuzioni cloud e locali: puoi eseguire i progetti nel cloud (a pagamento) o in locale per lavori più piccoli.
- Export: CSV, Excel, JSON, API.
- Prezzi: piano gratuito generoso; piani a pagamento da 49 $/mese.
ParseHub è ottimo per chi non programma ma ha bisogno di flessibilità e potenza su siti difficili.
5. Data Miner
 è un’estensione per Chrome/Edge per scraping rapido basato su template. Con oltre 50.000 ricette di estrazione pubbliche per più di 15.000 siti web, spesso puoi estrarre una pagina con un solo clic.
è un’estensione per Chrome/Edge per scraping rapido basato su template. Con oltre 50.000 ricette di estrazione pubbliche per più di 15.000 siti web, spesso puoi estrarre una pagina con un solo clic.
- Integrazione con Google Sheets: carica i dati estratti direttamente su Sheets.
- Ricette personalizzate: crea la tua logica di estrazione con point-and-click o XPath.
- Paginazione e automazione: gestisce scraping multi-pagina ed esecuzioni pianificate.
- Prezzi: piano gratuito; piani a pagamento da 19 $/mese.
Perfetto per analisti e marketer che hanno bisogno di estrazioni rapide e di piccola o media scala direttamente dal browser.
6. WebHarvy
 è un’app desktop per Windows con interfaccia point-and-click e rilevamento automatico dei pattern. Basta cliccare un elemento e WebHarvy evidenzia tutti gli elementi simili da estrarre.
è un’app desktop per Windows con interfaccia point-and-click e rilevamento automatico dei pattern. Basta cliccare un elemento e WebHarvy evidenzia tutti gli elementi simili da estrarre.
- Supporta immagini, testo e paginazione: estrai foto di prodotti, email, URL e altro ancora.
- Pianificazione su desktop: programma le estrazioni sul tuo PC.
- Licenza una tantum: circa 199 $ per PC.
Ottimo per piccole imprese che vogliono uno strumento semplice, senza abbonamento, per scraping periodico.
7. Import.io
 è una piattaforma cloud di livello enterprise per l’estrazione dati su larga scala. Offre pulizia dei dati con AI, monitoraggio in tempo reale e solide funzionalità di conformità.
è una piattaforma cloud di livello enterprise per l’estrazione dati su larga scala. Offre pulizia dei dati con AI, monitoraggio in tempo reale e solide funzionalità di conformità.
- Integrazioni API: invia i dati direttamente a database, dashboard BI o applicazioni.
- Conformità: progettato con GDPR e CCPA in mente.
- Prezzi: contratti enterprise; fascia alta.
Ideale per grandi organizzazioni che hanno bisogno di pipeline di dati web affidabili, conformi e scalabili.
8. Apify
 è una piattaforma di automazione cloud e un marketplace di “actor” per il web scraping (bot). Puoi usare actor già pronti per siti comuni oppure crearne di tuoi in JavaScript o Python.
è una piattaforma di automazione cloud e un marketplace di “actor” per il web scraping (bot). Puoi usare actor già pronti per siti comuni oppure crearne di tuoi in JavaScript o Python.
- Marketplace: centinaia di scraper pronti all’uso per siti come LinkedIn, Amazon e molti altri.
- Pianificazione e API: esegui, pianifica e integra gli actor via API.
- Prezzi: piano gratuito; l’uso a pagamento parte da 49 $/mese.
Ideale per sviluppatori e team tech-savvy che vogliono automazione, flessibilità e soluzioni guidate dalla community.
9. Visual Web Ripper
 è uno strumento desktop per l’estrazione avanzata di dati in massa. Il suo workflow builder ti permette di progettare crawler multilivello e automatizzare progetti su larga scala.
è uno strumento desktop per l’estrazione avanzata di dati in massa. Il suo workflow builder ti permette di progettare crawler multilivello e automatizzare progetti su larga scala.
- Pianificazione e automazione: esegui i progetti a intervalli prestabiliti.
- Integrazione con database: esporta direttamente in SQL, Excel, CSV, XML o JSON.
- Licenza una tantum: circa 349 $.
Ideale per team IT o utenti esperti che devono estrarre grandi dataset in-house.
10. Dexi.io
 è una piattaforma cloud per progetti collaborativi di dati web. Offre automazione dei flussi di lavoro, pianificazione e funzionalità di gestione del team.
è una piattaforma cloud per progetti collaborativi di dati web. Offre automazione dei flussi di lavoro, pianificazione e funzionalità di gestione del team.
- Automazione dei flussi di lavoro: crea e condividi pipeline di dati tra team.
- API ed export: integrazione con database, cloud storage o strumenti BI.
- Prezzi: personalizzati; pensato per team e aziende enterprise.
Ottimo per organizzazioni che gestiscono progetti dati continuativi e collaborativi.
11. Content Grabber
 è uno strumento di scraping di livello professionale per agenzie e aziende. Offre automazione avanzata, gestione degli errori e persino opzioni white-label.
è uno strumento di scraping di livello professionale per agenzie e aziende. Offre automazione avanzata, gestione degli errori e persino opzioni white-label.
- Scripting e personalizzazione: usa C# o VB.NET per un controllo profondo.
- Recupero errori e logging: progettato per essere affidabile nei lavori di grandi dimensioni.
- Prezzi enterprise: fascia alta; prova gratuita disponibile.
Ideale per agenzie o aziende che costruiscono soluzioni di scraping personalizzate e ripetibili per i clienti.
12. Helium Scraper
 è uno strumento desktop che unisce estrazione visuale e flessibilità di scripting. Usa il point-and-click per la maggior parte delle attività, oppure passa a JavaScript personalizzato per logiche avanzate.
è uno strumento desktop che unisce estrazione visuale e flessibilità di scripting. Usa il point-and-click per la maggior parte delle attività, oppure passa a JavaScript personalizzato per logiche avanzate.
- Gestisce contenuti dinamici: estrae dati da siti molto basati su AJAX.
- Pulizia e trasformazione dei dati: scripting integrato per workflow personalizzati.
- Licenza una tantum: circa 99 $.
Perfetto per utenti esperti che vogliono flessibilità senza abbonamento.
13. Web Scraper
 è un’estensione Chrome gratuita che avvicina molte persone al web scraping. Definisci una sitemap, fai clic per selezionare gli elementi ed esporta in CSV o JSON.
è un’estensione Chrome gratuita che avvicina molte persone al web scraping. Definisci una sitemap, fai clic per selezionare gli elementi ed esporta in CSV o JSON.
- Crawling multilivello: segui i link, gestisci la paginazione ed estrai dati nidificati.
- Gratis in locale: è disponibile una versione cloud a pagamento per pianificazione e scalabilità.
Ideale per principianti, studenti o chiunque abbia bisogno di una soluzione rapida e gratuita per lavori piccoli.
14. Mozenda
 è una piattaforma cloud enterprise con forte attenzione a conformità, scalabilità e servizi gestiti. La sua interfaccia point-and-click ti consente di creare “agent” per l’estrazione dati.
è una piattaforma cloud enterprise con forte attenzione a conformità, scalabilità e servizi gestiti. La sua interfaccia point-and-click ti consente di creare “agent” per l’estrazione dati.
- Servizi gestiti: il team di Mozenda può costruire e mantenere gli scraper per te.
- Conformità e supporto: forte attenzione a GDPR, CCPA e alle esigenze enterprise.
- Prezzi: a partire da circa 500 $/mese.
Ideale per grandi organizzazioni che vogliono una soluzione chiavi in mano, scalabile, per i dati web con supporto solido.
15. SimpleIndex
 è uno strumento di automazione per l’estrazione sia di documenti sia di dati web, con un forte focus su OCR e indicizzazione.
è uno strumento di automazione per l’estrazione sia di documenti sia di dati web, con un forte focus su OCR e indicizzazione.
- OCR per screen scraping: estrai dati da documenti scansionati, PDF o persino moduli web visualizzati a schermo.
- Integrazione: output verso database e sistemi di document management.
- Licenza una tantum: qualche centinaio di dollari per postazione.
Ottimo per organizzazioni che uniscono flussi di lavoro documentali e dati web.
16. Spinn3r
 è una piattaforma di content crawling in tempo reale per blog, notizie e social media. La sua Firehose API fornisce un flusso continuo di nuovi contenuti da milioni di fonti.
è una piattaforma di content crawling in tempo reale per blog, notizie e social media. La sua Firehose API fornisce un flusso continuo di nuovi contenuti da milioni di fonti.
- Filtraggio spam e elaborazione linguistica: feed di dati puliti e strutturati.
- Accesso API: integrazione diretta nei tuoi sistemi.
- Prezzi in abbonamento: basati sull’uso.
Ideale per media monitoring, aggregazione di notizie o team di ricerca che hanno bisogno di flussi di contenuti in tempo reale.
17. FMiner
 è un builder visuale di workflow per crawler web complessi. La sua interfaccia drag-and-drop ti consente di progettare routine di scraping multilivello e condizionali.
è un builder visuale di workflow per crawler web complessi. La sua interfaccia drag-and-drop ti consente di progettare routine di scraping multilivello e condizionali.
- Scripting Python: inserisci codice personalizzato per logiche avanzate.
- Cross-platform: disponibile per Windows e Mac.
- Licenza una tantum: a partire da circa 168 $.
Perfetto per analisti o data scientist che vogliono modellare visivamente workflow sofisticati.
18. G2 Webscraper
 (riferito agli strumenti meglio valutati su G2) è apprezzato per semplicità ed efficacia. Gli utenti amano gli strumenti gratuiti, facili e che fanno risparmiare tantissimo tempo — come l’estensione Web Scraper Chrome o Data Miner.
(riferito agli strumenti meglio valutati su G2) è apprezzato per semplicità ed efficacia. Gli utenti amano gli strumenti gratuiti, facili e che fanno risparmiare tantissimo tempo — come l’estensione Web Scraper Chrome o Data Miner.
- Recensioni utenti solide: valutazioni alte per facilità d’uso e affidabilità.
- Configurazione rapida: curva di apprendimento minima per attività da base a intermedie.
Se vuoi uno strumento che “funzioni e basta” per uno scraping semplice, i favoriti degli utenti su G2 sono una scelta sicura.
Tabella comparativa: i migliori strumenti di content crawling in sintesi
| Strumento | Facilità d’uso | Automazione e funzionalità | Formati di export | Conformità e privacy | Prezzi | Ideale per |
|---|---|---|---|---|---|---|
| Thunderbit | ⭐⭐⭐⭐⭐ | Campi AI, sottopagine, cloud | Excel, CSV, Sheets, Notion, Airtable, JSON | Guidato dall’utente | Gratis, da 15 $/mese | Non programmatori, sales, ops |
| Scrapy | ⭐ | Codice completo, async, plugin | CSV, JSON, DB | Gestita dall’utente | Gratis, open source | Sviluppatori, progetti grandi |
| Octoparse | ⭐⭐⭐⭐ | Visuale, template, cloud | CSV, Excel, JSON, API | Guidata dall’utente | Gratis, da 75 $/mese | Analyst, ecommerce, no-code |
| ParseHub | ⭐⭐⭐⭐ | Visuale, dinamico, cloud | CSV, Excel, JSON, API | Guidata dall’utente | Gratis, da 49 $/mese | Non programmatori, siti complessi |
| Data Miner | ⭐⭐⭐⭐⭐ | Template, browser, Sheets | CSV, Excel, Sheets | Guidata dall’utente | Gratis, da 19 $/mese | Lavori rapidi dal browser |
| WebHarvy | ⭐⭐⭐⭐⭐ | Visuale, rilevamento pattern | Excel, CSV, XML, JSON | Guidata dall’utente | 199 $ una tantum | Utenti Windows, piccole imprese |
| Import.io | ⭐⭐⭐⭐ | AI, cloud, monitoraggio | CSV, API, DB | GDPR, CCPA | Enterprise | Grandi aziende, compliance |
| Apify | ⭐⭐⭐ | Cloud, marketplace, API | JSON, API, Sheets | Gestita dall’utente | Gratis, da 49 $/mese | Dev, automazione, integrazioni |
| Visual Web Ripper | ⭐⭐⭐ | Workflow, pianificazione | CSV, Excel, DB | Guidata dall’utente | 349 $ una tantum | Team IT, grandi volumi |
| Dexi.io | ⭐⭐⭐ | Cloud, team, workflow | CSV, API, DB, Storage | Guidata dall’utente | Personalizzato | Team, progetti continui |
| Content Grabber | ⭐⭐⭐ | Scripting, automazione | CSV, XML, DB | Guidata dall’utente | Enterprise | Agenzie, soluzioni personalizzate |
| Helium Scraper | ⭐⭐⭐ | Visuale + scripting | CSV, DB | Guidata dall’utente | 99 $ una tantum | Power user, logiche personalizzate |
| Web Scraper | ⭐⭐⭐⭐⭐ | Sitemap, browser | CSV, JSON | Guidata dall’utente | Gratis (locale) | Principianti, lavori piccoli |
| Mozenda | ⭐⭐⭐ | Cloud, gestito, compliance | CSV, API, DB | GDPR, CCPA | 500 $+/mese | Enterprise, servizio gestito |
| SimpleIndex | ⭐⭐⭐ | OCR, web, documenti | DB, DMS | Guidata dall’utente | 500 $ una tantum | Documenti + dati web |
| Spinn3r | ⭐⭐ | Tempo reale, API | JSON, API | Guidata dall’utente | Abbonamento | Media, news, ricerca |
| FMiner | ⭐⭐⭐ | Workflow visuale, Python | CSV, DB | Guidata dall’utente | 168 $ una tantum | Workflow complessi e visivi |
| G2 Webscraper | ⭐⭐⭐⭐⭐ | Semplice, browser | CSV, JSON | Guidata dall’utente | Gratis/varia | Semplicità, risultati rapidi |
Come scegliere lo strumento di content crawling giusto per la tua azienda
Scegliere lo strumento giusto significa abbinare le tue esigenze ai punti di forza del tool. Ecco la mia checklist rapida:
- Definisci il caso d’uso: una tantum o continuo? Piccola scala o massiva? Dati pubblici o dietro login?
- Allinealo al livello di competenza: chi non programma dovrebbe iniziare con Thunderbit, Octoparse, ParseHub o WebHarvy. Gli sviluppatori possono andare su Scrapy o Apify.
- Controlla le esigenze di export: ti servono Excel, Sheets o integrazioni API? Verifica che lo strumento lo supporti.
- Valuta la conformità: se lavori in un settore regolamentato o estrai dati personali, dai priorità agli strumenti con funzioni di compliance (Import.io, Mozenda).
- Inizia in piccolo: usa piani gratuiti o prove per testare dati reali prima di impegnarti.
- Pensa in prospettiva: cresceranno le tue esigenze? Scegli uno strumento con cui puoi scalare.
E ricorda: a volte lo strumento più semplice è quello più adatto. Non complicarti la vita se ti serve solo un foglio di calcolo veloce.
Privacy e conformità dei dati: cosa tenere d’occhio
Il web scraping apre un mondo di possibilità — ma anche di responsabilità. Ecco come restare dalla parte giusta della legge e delle buone pratiche:
- Rispetta robots.txt e le policy dei siti: controlla sempre se un sito consente lo scraping e segui le sue linee guida.
- Evita di estrarre dati personali a meno che tu non abbia un motivo legittimo e il consenso: GDPR e CCPA non scherzano.
- Non sovraccaricare i server: usa i limiti di velocità integrati, i ritardi e la pianificazione per evitare blocchi (e per essere un buon cittadino di Internet).
- Usa strumenti con funzioni di conformità se operi in un settore sensibile: Import.io e Mozenda sono stati progettati pensando a GDPR/CCPA.
- Documenta le tue azioni: conserva traccia di ciò che estrai e del perché, soprattutto nei casi aziendali o regolamentati.
Uno scraping etico è uno scraping sostenibile — e tiene la tua azienda lontana dai problemi.
Conclusione: dai al tuo team più potere con lo strumento di content crawling giusto
Il web è il database più grande e più disordinato della tua azienda — e con il giusto strumento di content crawling, puoi finalmente metterlo al lavoro. Che tu stia creando liste di lead, monitorando i concorrenti o alimentando dashboard in tempo reale, questi 18 strumenti coprono ogni scenario, ogni livello di competenza e ogni budget.
Se vuoi la strada più veloce verso i risultati, è la mia scelta top per gli utenti business: basato su AI, no-code e pronto a trasformare qualsiasi sito web in un dataset strutturato in pochi minuti. Ma qualunque siano le tue esigenze, inizia con una prova gratuita, sperimenta e scopri cosa si adatta meglio al tuo flusso di lavoro.
Pronto a dire addio alla fatica del copia-incolla? Scarica la e scopri quanto possono essere semplici i dati web. E se vuoi approfondire il web scraping, visita il per altre guide, consigli e tutorial.
FAQ
1. Che cos’è uno strumento di content crawling e in cosa si differenzia da un normale web scraper?
Uno strumento di content crawling è un tipo di web scraper progettato per automatizzare l’estrazione di dati strutturati dai siti web. Sebbene tutti i web scraper raccolgano dati, gli strumenti di content crawling offrono spesso funzioni come pianificazione, navigazione tra sottopagine, rilevamento dei campi con AI e integrazione con i flussi di lavoro aziendali — rendendoli più potenti e più facili da usare per i team business.
2. Quale strumento di content crawling è il migliore per gli utenti non tecnici?
Thunderbit, Octoparse, ParseHub, Data Miner e WebHarvy sono tutti eccellenti per chi non programma. Thunderbit si distingue per la semplicità basata su AI e l’export immediato in Excel, Sheets, Airtable o Notion.
3. Come posso assicurarmi che il mio web scraping sia legale e conforme?
Rispetta sempre i termini del sito, robots.txt e le leggi sulla privacy come GDPR e CCPA. Evita di estrarre dati personali a meno che tu non abbia un motivo legittimo e il consenso. Per i settori sensibili, scegli strumenti con funzionalità di conformità integrate (ad esempio Import.io, Mozenda).
4. Questi strumenti possono gestire siti dinamici con JavaScript o infinite scroll?
Sì — strumenti come Thunderbit, Octoparse, ParseHub, Apify e FMiner possono gestire contenuti dinamici, infinite scroll e navigazione multilivello. Alcuni potrebbero richiedere una configurazione aggiuntiva o esecuzioni cloud per i siti complessi.
5. Cosa devo considerare quando scelgo uno strumento di content crawling per la mia azienda?
Considera le competenze tecniche del tuo team, la scala del fabbisogno di dati, i requisiti di export/integrazione, le questioni di conformità e il budget. Inizia con un piano gratuito o una prova, e testa lo strumento sul tuo caso d’uso reale prima di decidere.
Buon scraping — e che i tuoi dati siano sempre freschi, strutturati e pronti all’azione.
Scopri di più