L’estrazione dati da Facebook vale ancora la pena nel 2026, ma solo se scegli il modello di raccolta giusto. Il Pew Research Center ha riportato il 20 novembre 2025 che , e Meta ha detto il 29 aprile 2026 che la sua nel marzo 2026. Questa scala rende Facebook utile per il monitoraggio di Marketplace, la ricerca su pagine pubbliche, la generazione di lead e il tracciamento dei competitor. La difficoltà non è trovare i casi d’uso. La difficoltà è ottenere dati puliti senza bloccarsi su barriere di accesso, caricamenti dinamici, blocchi temporanei o configurazioni di scraping fragili.
Questa selezione annuale è pensata per decidere in fretta. Ho ricontrollato le pagine prodotto ufficiali, la documentazione e i segnali di prezzo l’8 maggio 2026, poi ho mantenuto l’elenco focalizzato sugli strumenti che hanno ancora senso per utenti business reali. Se il tuo flusso di lavoro è soprattutto “prendi i dati da questa pagina e inviali a un foglio”, parti da Thunderbit. Se ti serve un’infrastruttura API su larga scala, Bright Data, Apify e Nimble by Nimbleway meritano un posto in alto nella lista. Se il tuo lavoro include automazioni cloud o azioni di follow-up dopo la raccolta, PhantomBuster merita uno sguardo più attento.
Scelte rapide in base al lavoro
- Ti serve l’esportazione no-code più veloce da Facebook o Marketplace? Parti da .
- Ti serve una scala enterprise via API e sblocco gestito? Seleziona .
- Ti servono flussi di scraping cloud flessibili? Dai un’occhiata a .
- Ti serve una raccolta dal web pubblico API-first con meno manutenzione dello scraper? Considera .
- Ti serve un’API economica per lavori leggeri? è ancora rilevante.
- Ti servono scraping e automazione dei flussi di lavoro? è la scelta migliore.
- Ti serve un builder visuale point-and-click con pianificazione? resta una solida opzione no-code.
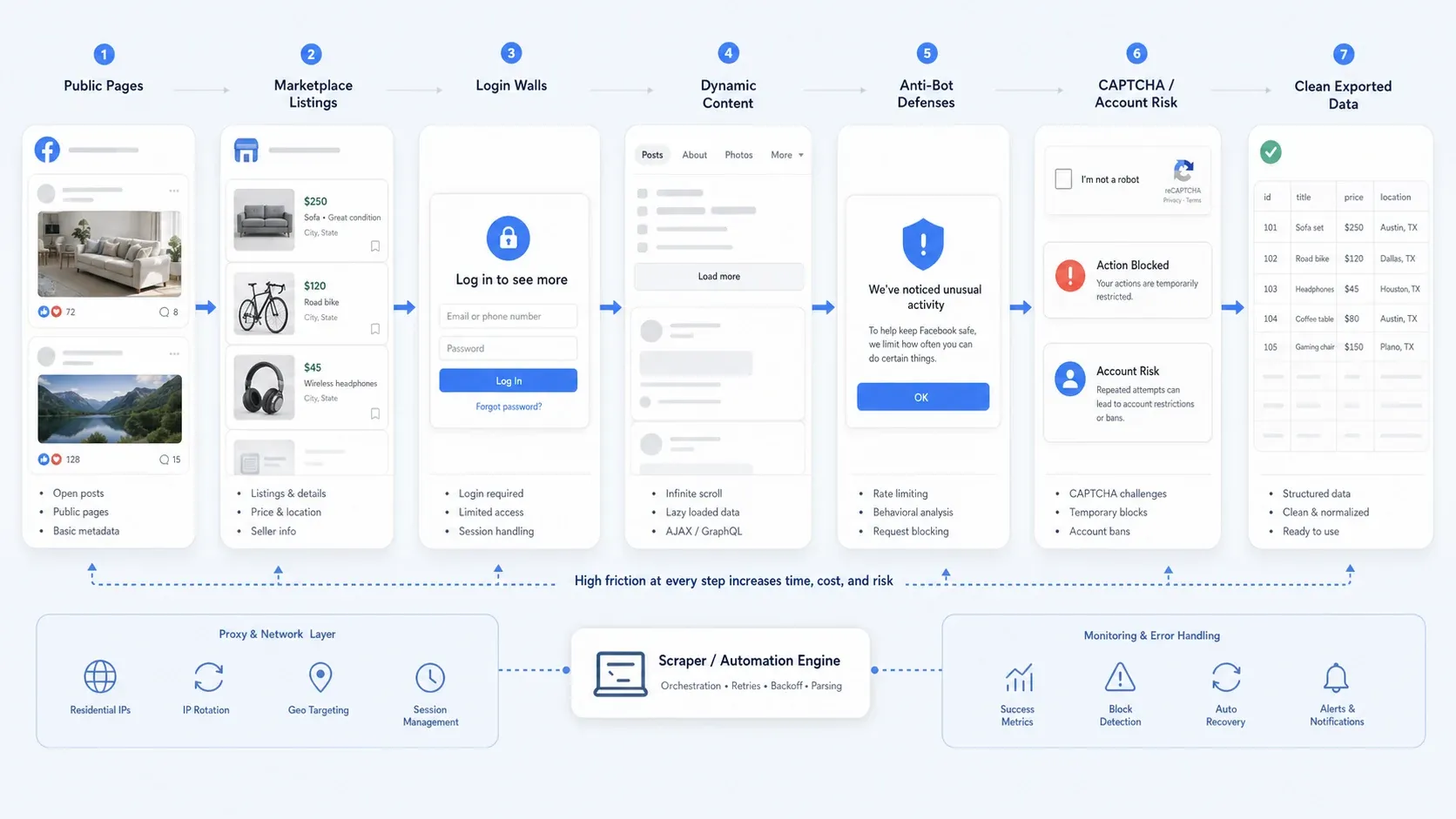
Perché estrarre dati da Facebook è ancora difficile nel 2026
La raccolta di dati da Facebook ormai raramente è solo una questione di selettori. Nella pratica, la maggior parte dei team incontra una o più di queste difficoltà:
- Accesso pubblico parziale: alcune pagine restano pubbliche, mentre altri flussi spingono verso il login per vedere più dettagli.
- Contenuti dinamici: le viste di Marketplace, le lunghe discussioni nei commenti e i contenuti delle pagine spesso si caricano in modo incrementale.
- Difese anti-bot: limiti di frequenza, controlli comportamentali, CAPTCHA e blocchi temporanei delle azioni mandano in crisi le automazioni ingenue.
- Rischio operativo: la raccolta basata sul login è molto più rischiosa dello scraping di pagine pubbliche, soprattutto se ti interessa la sicurezza dell’account e la ripetibilità.
Come ho valutato questi strumenti
Ho ottimizzato questa pagina per aiutare a costruire una shortlist, non per riempirla di feature. Gli strumenti qui sotto sono stati confrontati in base a:
- Aderenza al flusso di lavoro: il prodotto corrisponde davvero ai lavori di raccolta dati da Facebook e Marketplace che fanno i team reali?
- Facilità d’uso: i non sviluppatori o i team snelli riescono ad arrivare rapidamente a un output utilizzabile?
- Scalabilità e affidabilità: lo strumento ha ancora senso quando vai oltre uno scraping una tantum?
- Gestione anti-bot e sessioni: quanto dolore infrastrutturale elimina il prodotto?
- Qualità dell’output: riesci a ottenere dati strutturati in CSV, Sheets o sistemi a valle senza grandi pulizie?
- Segnale di prezzo: il prodotto è pratico da valutare, o richiede un ciclo enterprise pesante?
- Approccio alla conformità: lo strumento è chiaramente orientato alla raccolta di dati pubblici e a un uso responsabile?
Che tipo di scraper di Facebook ti serve?
Il modo più veloce per scegliere bene è prima scegliere la categoria giusta. Gli strumenti per estrarre dati da Facebook di solito rientrano in quattro modelli operativi:
- Strumenti browser no-code: ideali quando vuoi estrarre rapidamente i dati dalla pagina che hai già aperto davanti a te.
- API per scraper: ideali quando ti serve una raccolta affidabile e ripetibile su volumi più alti.
- Flussi di automazione: ideali quando lo scraping è solo un passaggio in un processo go-to-market più ampio.
- Stack fai-da-te per sviluppatori: ideali quando il team vuole il massimo controllo ed è pronto a farsi carico della manutenzione.
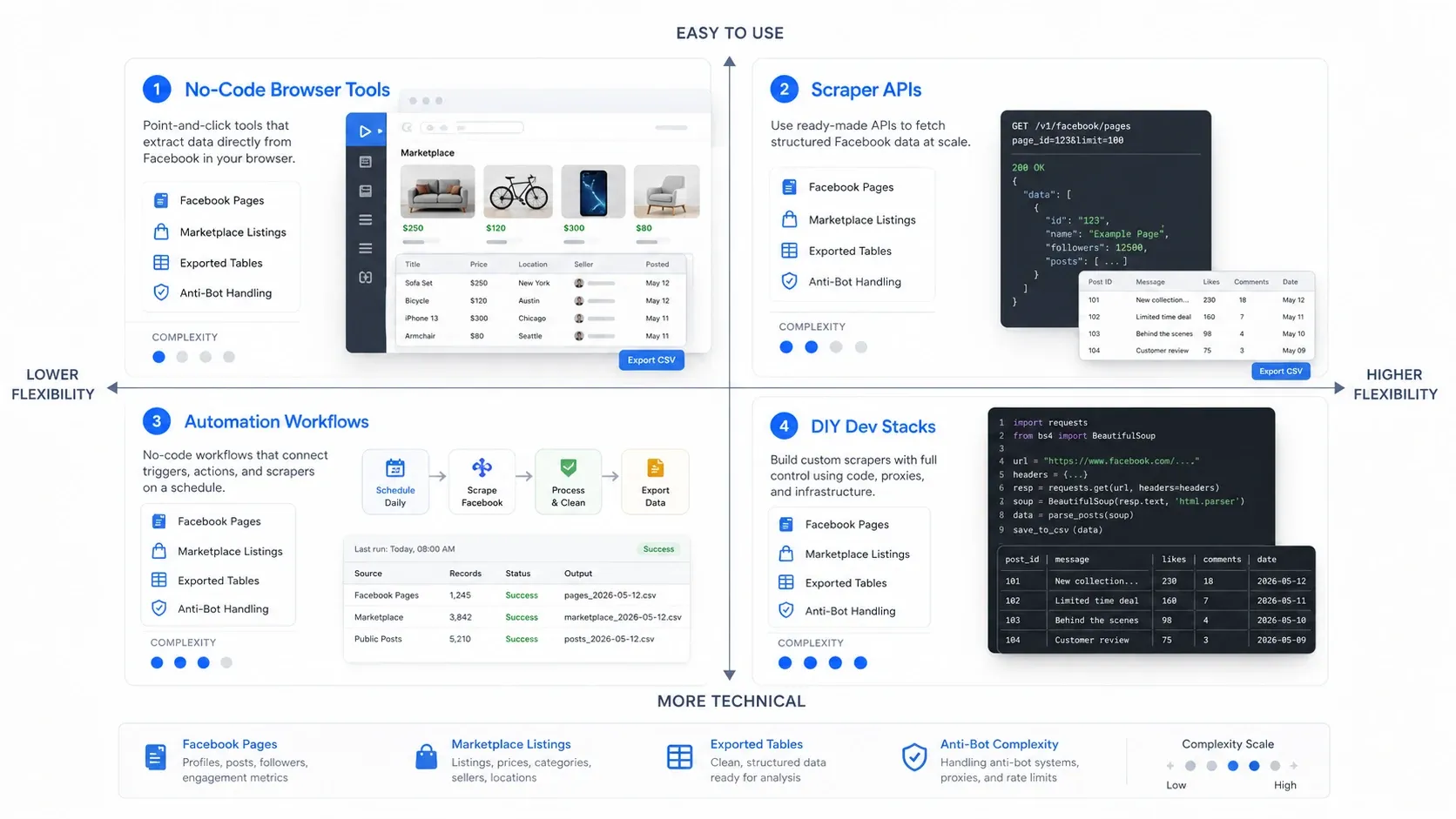
Tabella comparativa
| Strumento | Ideale per | Perché è entrato nella shortlist | Segnale di prezzo |
|---|---|---|---|
| Thunderbit | Team non tecnici e lavori ad hoc veloci | Rilevamento campi con IA, gestione nativa nel browser delle pagine dinamiche, esportazioni rapide | Prova gratuita; piani a pagamento basati su crediti |
| Bright Data | Pipeline di dati social pubblici su larga scala | API dedicate per lo scraping dei social media, sblocco gestito, forte scalabilità | Prezzi a consumo e enterprise |
| Apify | Flussi di scraping cloud flessibili | Actor di Facebook già pronti, pianificazione, accesso API, spazio per personalizzazioni | Piani della piattaforma a pagamento più uso misurato |
| Nimble by Nimbleway | Raccolta web pubblica API-first | Flusso API orientato agli URL e minore manutenzione dello scraper | Prezzi gestiti dal team commerciale |
| ScrapingBot | Piccoli lavori su dati pubblici e prototipi | API semplice, supporto al rendering, prezzo d’ingresso più basso | Piano gratuito; piani a pagamento da circa 22 $/mese |
| PhantomBuster | Flussi di automazione GTM | Automazioni cloud, flussi di browser action, adatto alla lead generation | Prova gratuita; piani a pagamento da circa 56 $/mese |
| Octoparse | Scraping visivo no-code pianificato | Builder point-and-click, estrazione cloud, flussi ripetibili | Piano gratuito; piani a pagamento da circa 119 $/mese |
1. Thunderbit
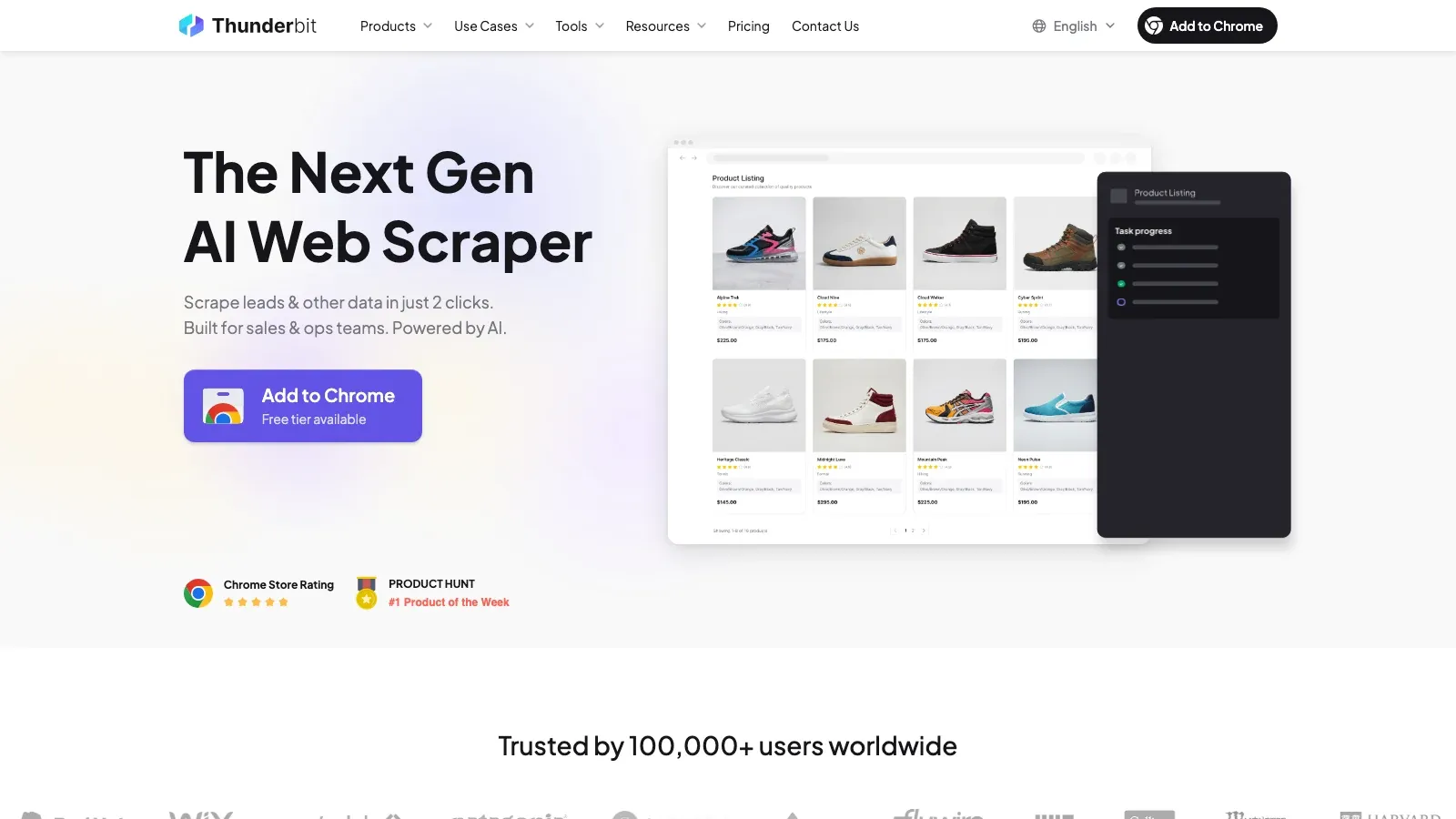
è la scelta più forte qui se il tuo obiettivo è trasformare rapidamente una pagina Facebook o un elenco risultati di Marketplace in dati strutturati, senza costruire o mantenere uno scraper. Il suo vantaggio principale è l’estrazione semantica: legge la pagina, suggerisce i campi utili e ti permette di esportare il risultato senza dover gestire selettori, proxy o codice.
Perché si distingue:
- AI Suggest Fields: Thunderbit identifica campi probabili come titolo, prezzo, venditore, posizione, dettagli di contatto e URL.
- Gestione nativa nel browser: poiché gira dove la pagina viene renderizzata, funziona bene su pagine dinamiche e ricche di scroll.
- Arricchimento delle sottopagine: puoi prima raccogliere i dati dell’elenco, poi aprire ogni annuncio o pagina per ottenere più dettagli.
- Esportazioni utili: Excel, Google Sheets, Airtable e Notion sono tutte destinazioni naturali.
Se vuoi vedere un video prima di testare tu stesso un flusso nativo nel browser, questa guida pratica di Thunderbit è il punto migliore da cui partire, perché mostra il flusso di estrazione reale invece di restare sul livello delle promesse di prodotto:
Ideale per: utenti non tecnici, team sales, operatori e ricercatori che vogliono risultati in fretta.
Segnale di prezzo: prova gratuita disponibile; i piani a pagamento si basano su crediti. Controlla i .
2. Bright Data
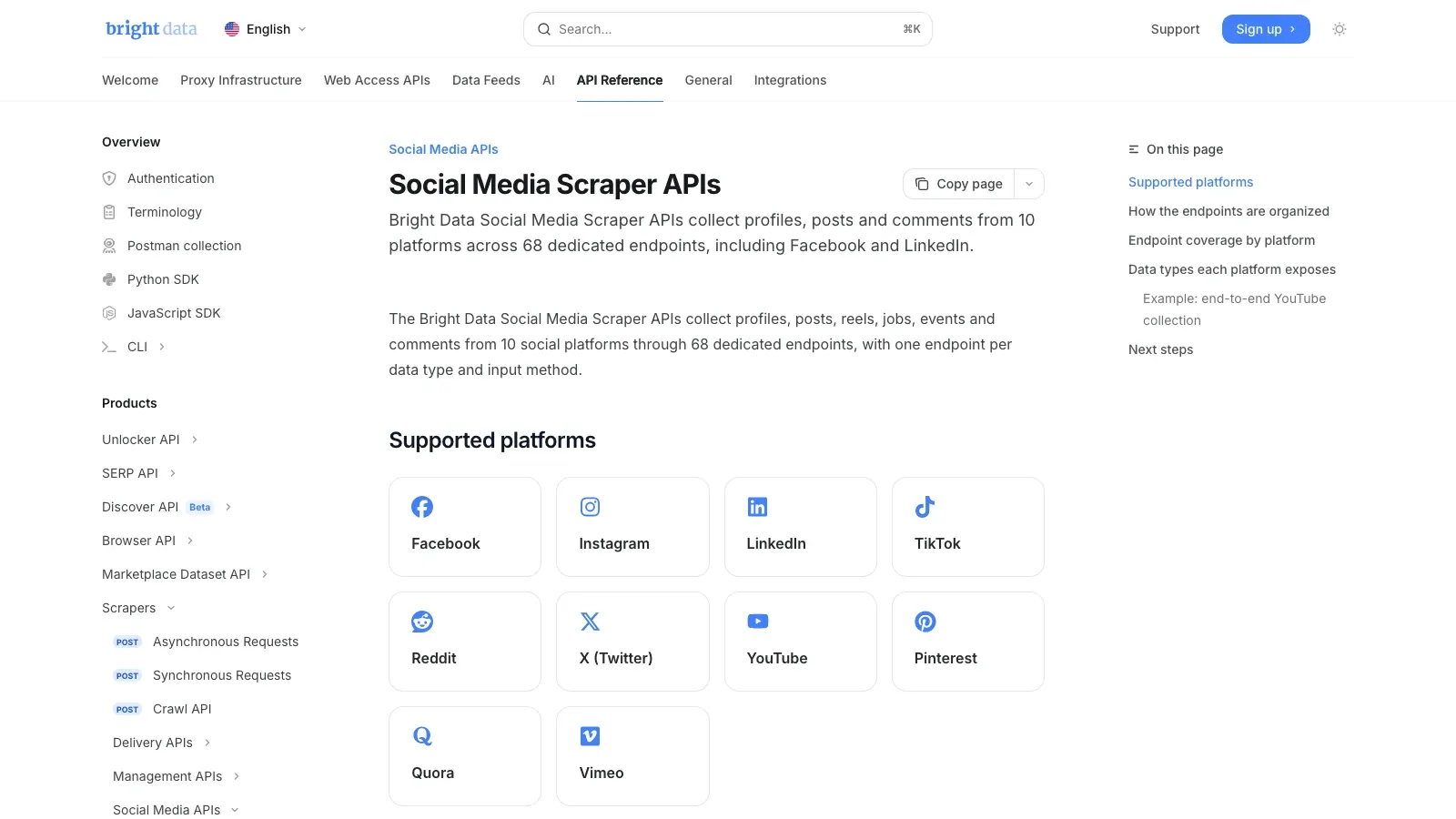
è la scelta orientata all’infrastruttura. La documentazione di Bright Data afferma che le sue coprono 10 piattaforme e 68 endpoint dedicati, incluso Facebook. Se il tuo lavoro è la raccolta di dati pubblici su larga scala, questo tipo di stack API gestito è in genere molto più realistico rispetto a cercare di scalare un’estensione browser o uno scraper fatto in casa.
Perché merita un posto nella shortlist:
- Endpoint dedicati per lo scraping dei social media
- Sblocco ed estrazione gestiti
- Consegna di output strutturati per pipeline di dati
- Adatto a lavori di monitoraggio e analytics sensibili all’affidabilità
Ideale per: analisti, team dati, grandi progetti di monitoraggio e dataset social pubblici su larga scala.
Segnale di prezzo: il prezzo varia in base al prodotto e al volume. Verifica i .
3. Apify
resta rilevante perché offre un buon equilibrio tra template e personalizzazione completa. Il suo actor Facebook Pages Scraper è un ottimo punto di partenza, mentre la piattaforma Apify più ampia fornisce esecuzioni cloud, pianificazione, API e spazio per estendere il flusso di lavoro se le esigenze diventano più complesse.
Perché è entrato nella lista:
- Actor Facebook già pronti
- Esecuzione cloud e pianificazioni ricorrenti
- Export flessibili e accesso API
- Più facile da estendere rispetto a un flusso browser no-code puro
Ideale per: marketing tecnico, agenzie, team operativi e lavori di raccolta ricorrenti su più siti.
Segnale di prezzo: i piani della piattaforma sono a pagamento e l’uso degli actor è misurato separatamente. Controlla i .
4. Nimble by Nimbleway
è l’opzione API-first per i team che vogliono inviare un URL e lasciare che la piattaforma gestisca accesso, rendering e consegna. Nimble presenta la sua come una raccolta end-to-end di dati dal web pubblico, quindi è utile quando lo scraping di Facebook è solo una parte di uno stack dati più ampio.
Perché vale la pena valutarlo:
- Flusso API orientato agli URL
- Minore carico di manutenzione dello scraper per i team di engineering
- Buona aderenza all’estrazione robusta dal web pubblico
- Utile quando i dati estratti alimentano prodotti interni o dashboard
Ideale per: team guidati dall’ingegneria, pipeline dati di prodotto e organizzazioni che preferiscono l’astrazione dell’infrastruttura ai tool puntuali.
Segnale di prezzo: Nimble non mette in evidenza un pricing self-serve pubblico sulle pagine della sua API principale, quindi aspettati prezzi gestiti commercialmente e verifica direttamente con .
5. ScrapingBot
è l’opzione API più attenta al budget in questa lista. Non è la piattaforma più specializzata in Facebook qui, ma ha comunque senso per lavori più piccoli su dati pubblici in cui vuoi un’API, supporto al rendering e una soglia di costo più bassa rispetto all’infrastruttura enterprise di scraping.
Dove si colloca:
- Scraping pubblico semplice guidato da API
- Prezzo d’ingresso più basso
- Rendering e gestione proxy inclusi
- Più adatto a prototipi e raccolte leggere ricorrenti che a programmi di intelligence di grandi dimensioni
Ideale per: startup, piccole imprese e sviluppatori che testano casi d’uso più leggeri di raccolta da pagine pubbliche.
Segnale di prezzo: piano gratuito disponibile; la pagina pubblica di pricing attuale parte da circa .
6. PhantomBuster
riguarda meno l’infrastruttura grezza di scraping e più ciò che succede dopo la raccolta. Se il tuo caso d’uso è “raccogli i dati e poi attiva outreach, enrichment o azioni di follow-up”, PhantomBuster spesso è più utile di un semplice estrattore perché è progettato attorno ad automazioni cloud e flussi di browser action.
Perché i team continuano a inserirlo nella shortlist:
- Flussi di automazione basati su cloud
- Utile per lead generation e operazioni GTM
- Più adatto quando lo scraping è un passaggio in un processo più ampio
- Pratico per chi si occupa di azioni, non solo di export
Ideale per: team GTM, team growth, recruiter e operatori che collegano la raccolta ad azioni a valle.
Segnale di prezzo: prova gratuita disponibile; i piani a pagamento nella pagina prezzi attuale partono da circa .
7. Octoparse
resta uno dei migliori strumenti di scraping visuale no-code per chi vuole flussi ripetibili e run cloud pianificati. Non è leggero come Thunderbit per lavori Facebook rapidi e una tantum, ma offre ai non sviluppatori un controllo più esplicito su come la logica di estrazione viene costruita e ripetuta.
Perché resta rilevante:
- Builder visuale point-and-click
- Estrazione cloud e pianificazione
- Buono per attività strutturate e ripetute
- Più adatto ad analisti che vogliono ripetibilità senza codice
Ideale per: analisti non tecnici, team operativi SMB e attività di raccolta ripetibili con una logica di workflow più esplicita.
Segnale di prezzo: la pagina pubblica dei prezzi di Octoparse indica piani a pagamento a partire da circa .
Shortlist per team
Se sai già quale tipo di team dovrà gestire il flusso, parti da qui:
- Operatore solitario o piccola impresa: Thunderbit, ScrapingBot o Octoparse
- Team sales / GTM: Thunderbit o PhantomBuster
- Analista operativo: Thunderbit, Apify o Octoparse
- Team di automazione growth: PhantomBuster o Apify
- Team di data engineering: Bright Data, Nimble o Apify

Come scegliere il giusto scraper di Facebook
- Scegli Thunderbit se velocità e semplicità contano più della massima scalabilità.
- Scegli Bright Data se ti serve scala sui dati pubblici e affidabilità gestita.
- Scegli Apify se vuoi flessibilità di piattaforma e flussi basati su actor.
- Scegli Nimble se vuoi un livello di astrazione API-first con meno manutenzione dello scraper.
- Scegli PhantomBuster se lo scraping è solo un passaggio in un flusso di automazione GTM più ampio.
- Scegli Octoparse se vuoi ripetibilità visuale senza codice.
- Scegli ScrapingBot se il budget conta e il lavoro è relativamente semplice.
Considerazione finale
Nel 2026 la divisione del mercato è più chiara di un anno fa. In realtà non stai scegliendo un unico “miglior scraper di Facebook” universale. Stai scegliendo un modello di raccolta: estrazione no-code veloce, scala via API gestita, automazione cloud o controllo visuale pratico del flusso di lavoro. Parti da lì e la shortlist diventa molto più semplice.
Se il tuo team vuole il percorso più rapido da una pagina Facebook o da un annuncio di Marketplace a dati strutturati utilizzabili, Thunderbit resta il posto più semplice da cui iniziare. Se il volume o i requisiti di engineering sono molto più pesanti, Bright Data, Apify e Nimble hanno più senso. Se il tuo flusso di lavoro inizia con lo scraping ma finisce con azioni di follow-up, PhantomBuster è la shortlist più intelligente.
FAQ
1. Qual è lo strumento più semplice per estrarre dati da Facebook per utenti non tecnici?
Thunderbit è il punto di partenza più semplice per la maggior parte degli utenti non tecnici perché funziona nel browser, suggerisce automaticamente i campi ed esporta i dati rapidamente senza codice.
2. Quale strumento per estrarre dati da Facebook è il migliore per la raccolta di dati pubblici su larga scala?
Bright Data è la scelta infrastrutturale più forte in questa lista quando il lavoro è la raccolta su larga scala di dati social pubblici e l’affidabilità conta più della facilità d’uso.
3. Cosa succede se mi servono scraping e automazione di follow-up?
PhantomBuster è la soluzione migliore quando la raccolta dati è solo un passaggio in un flusso più ampio di lead generation o GTM.
4. Estrarre dati da Facebook è ancora difficile nel 2026?
Sì. Contenuti dinamici, barriere di login, limiti di frequenza, sistemi anti-bot e rischi per l’account rendono Facebook ancora più difficile da estrarre rispetto ai siti pubblici più semplici.
5. Come dovrebbero ragionare i team sulla conformità?
Resta concentrato sui dati pubblici, usa frequenze ragionevoli, evita l’abuso delle credenziali e rivedi i termini della piattaforma e le regole sulla privacy applicabili prima di scalare un flusso di lavoro.
Ulteriori letture: