Dopo aver fatto ben più di mille scraping con Simplescraper, ho smesso di contare i successi e ho iniziato a catalogare i fallimenti. Quel passaggio — da “ha funzionato?” a “perché si è rotto stavolta?” — mi ha insegnato più di qualunque pagina di documentazione.
Simplescraper è una solida estensione di Chrome per estrarre dati dai siti web senza scrivere codice. Con nel Chrome Web Store e un’interfaccia point-and-click davvero accessibile, si è guadagnato un posto di tutto rispetto nel toolkit no-code per lo scraping. Ma ecco quello che nessuno ti dice nella landing page: ottenere risultati coerenti e affidabili su larga scala richiede di capire dove gli estrattori visivi iniziano a scricchiolare. Un che i lavoratori spendono più di nove ore alla settimana in inserimento dati ripetitivo — ed è proprio questa fatica che spinge molti verso strumenti come Simplescraper. Ma se non conosci le stranezze dello strumento, quelle nove ore le passerai a fare debug invece che a fare qualcosa di utile. Questo articolo copre le cinque best practice che ho ricavato dall’esperienza sul campo: risolvere i problemi di selezione, scegliere la modalità di scraping giusta, sfruttare al massimo il piano gratuito, evitare i blocchi e capire quando è il momento di passare oltre.

Che cos’è Simplescraper e perché le best practice contano
Simplescraper è un’estensione di Chrome che ti permette di selezionare visivamente gli elementi di una pagina web — titoli dei prodotti, prezzi, immagini, informazioni di contatto — ed estrarli in dati strutturati senza scrivere una riga di codice. Clicchi, selezioni e lui crea una “ricetta” riutilizzabile su pagine simili.
Il modello di base funziona così:
- Selezione visiva degli elementi: clicchi su ciò che ti serve. Simplescraper rileva automaticamente i pattern ricorrenti (elenchi di prodotti, risultati di ricerca, annunci di lavoro).
- Ricette: salvi la configurazione di estrazione per riutilizzarla più tardi o per eseguirla su batch di URL.
- Due modalità di scraping: Browser (locale, eseguito nel tuo Chrome) e Cloud (eseguito sui server di Simplescraper, senza supervisione).
- Integrazioni: esportazione verso Google Sheets, Airtable, webhook, Zapier, Make, CSV e JSON.
- Estrazione AI: una funzione più recente, , che genera selettori CSS a partire da un prompt di schema.
Il pubblico di riferimento è ampio — marketer, team sales, operatori e-commerce, ricercatori — insomma chiunque debba estrarre dati strutturati dai siti web senza assumere uno sviluppatore. E per le pagine semplici, Simplescraper funziona in fretta.
Allora perché le best practice contano? Perché nel momento in cui vai oltre un semplice elenco di prodotti o una directory pulita, emerge l’attrito. Contenuti dinamici, misure anti-bot, immagini con lazy loading, strutture HTML annidate: sono queste le condizioni reali che separano un’esperienza frustrante da una produttiva. Sapere in anticipo qual è l’approccio giusto ti fa risparmiare ore di tentativi ed errori.
Best practice 1: cosa fare quando Simplescraper non riesce a selezionare gli elementi
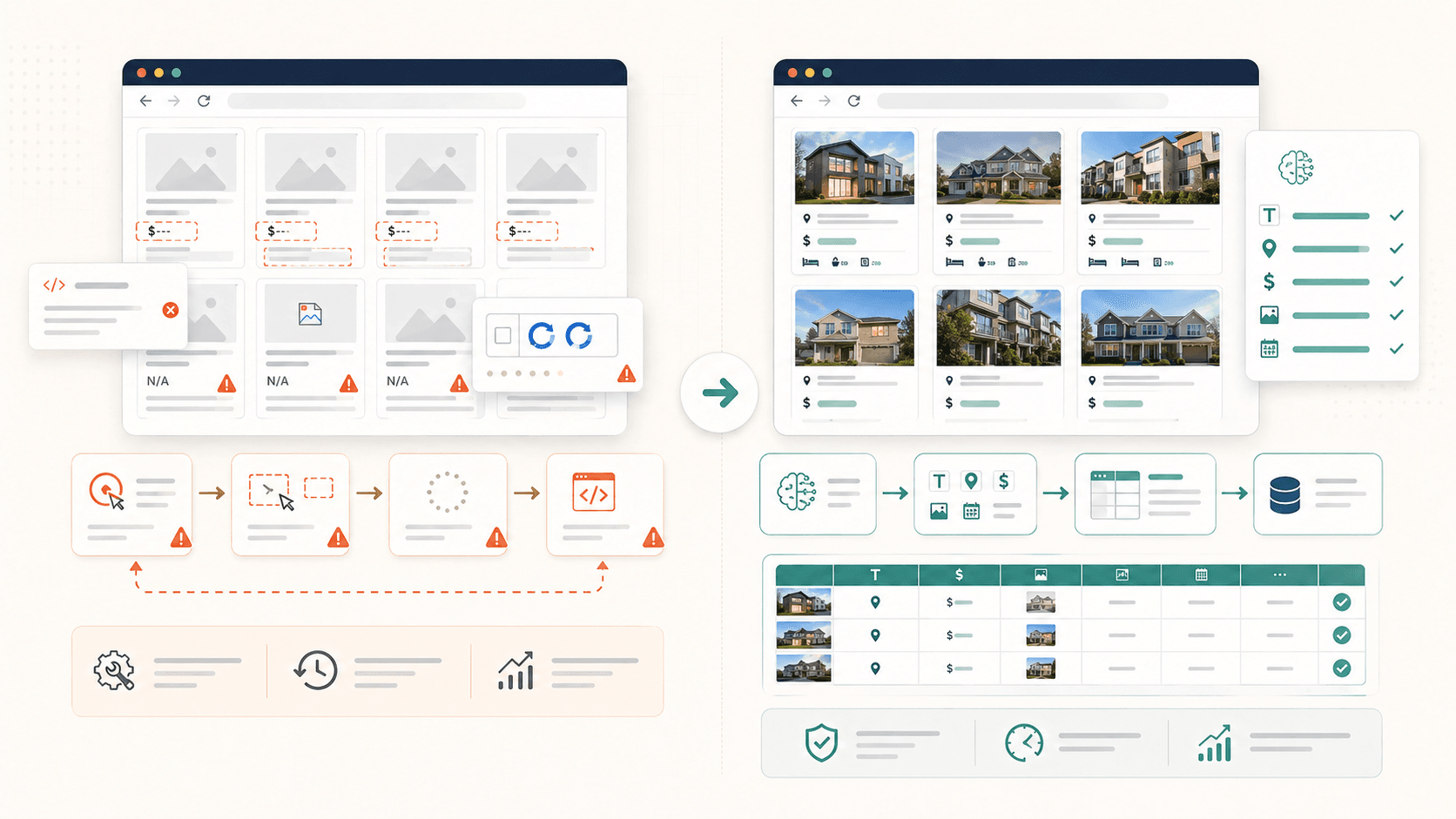
È di gran lunga la frustrazione più comune che abbia visto. Clicchi un elemento, Simplescraper lo evidenzia, ti senti al sicuro — e poi l’output perde metà dei dati. Le foto sono vuote. Le bio mancano. Le località spariscono.
Il fondatore stesso che “the element/css selector still ain't 100%.” È un’onestà apprezzabile, ma non ti risolve lo scraping rotto alle 11 di sera di mercoledì.
Errori di selezione comuni e perché succedono
Quattro pattern mandano più spesso in crisi Simplescraper:
- Immagini con lazy loading: l’elemento immagine letteralmente finché non arrivi a quel punto con lo scrolling. Se fai scraping prima, i campi immagine restano vuoti.
- Contenitori annidati o raggruppati: il rilevamento automatico di Simplescraper , e a volte questo significa catturare solo una sezione della pagina invece dell’intero blocco ripetuto. Gli utenti segnalano tabelle che “non selezionano tutte le righe in un colpo solo”.
- Contenuti dinamici JavaScript: gli elementi renderizzati dopo il caricamento iniziale della pagina tramite React, Vue o chiamate AJAX semplicemente non sono presenti quando lo scraper parte troppo presto.
- Paginazione con infinite scroll: i dati che ti servono non sono ancora stati caricati nell’HTML perché richiedono lo scrolling o il clic su “carica altro”.
Passi pratici di troubleshooting
Prima di passare ai selettori manuali, prova questo:
- Scorri tutta la pagina prima. Così immagini e contenuti caricati con lazy loading entrano nel DOM.
- Usa “Include Similar” quando il numero di elementi sembra sospettosamente basso. La documentazione di Simplescraper consiglia questa opzione per i contenuti raggruppati.
- Aspetta che la pagina abbia finito di caricarsi sui siti pesanti di JS. Concedi qualche secondo in più prima di avviare lo scraping.
- Parti da un campione piccolo. Verifica il numero di righe su 2-3 pagine prima di lanciare un batch da 500 pagine.
Passare ai selettori CSS manuali
Quando la selezione visiva continua a fallire, è il momento di passare al manuale. È la mossa da power user che distingue chi usa lo strumento ogni tanto da chi lo sfrutta davvero bene.
Ecco il flusso:
- Fai clic destro sull’elemento che ti serve in Chrome → Ispeziona.
- In DevTools, individua il nome della classe o l’attributo data dell’elemento (ad es.
.product-card .priceo[data-test="location"]). - In Simplescraper, passa alla scheda e incolla il selettore.
- Testa il selettore con uno scraping su piccola scala.
Suggerimenti per selettori robusti:
- Preferisci i nomi delle classi (
.listing-title) ai selettori posizionali (div:nth-child(3)) - Usa gli quando sono disponibili: di solito sono più stabili tra un aggiornamento e l’altro del sito
- Evita percorsi troppo annidati che si rompono quando cambia la struttura HTML del sito
L’alternativa AI: lascia che Thunderbit rilevi automaticamente i campi
Lo dico apertamente: il mio team ha creato proprio perché eravamo stanchi di questo problema. La funzione “AI Suggest Fields” di Thunderbit legge la struttura della pagina e suggerisce automaticamente colonne e logica di estrazione. Non devi conoscere CSS. L’AI si adatta al layout di ogni sito, compresi i contenuti annidati e le immagini caricate con lazy loading.
Se passi più di qualche minuto per scraping a fare debug dei selettori, vale la pena provare un approccio completamente diverso.
Best practice 2: scegliere tra scraping cloud e scraping nel browser
La maggior parte degli utenti di Simplescraper sceglie una modalità per abitudine — di solito la prima provata — senza chiedersi quale sia davvero adatta al caso d’uso. E così si finisce per incappare in fallimenti evitabili.
Quando usare lo scraping nel browser (locale)
- Pagine che richiedono login: LinkedIn, dashboard CRM, strumenti interni — qualsiasi cosa dietro autenticazione richiede la tua sessione browser attiva.
- Estrazioni rapide una tantum: sei già sulla pagina e vuoi subito i dati.
- Risparmiare i crediti gratuiti: lo scraping nel browser non consuma crediti cloud.
Il compromesso: il computer deve restare acceso e i lavori grandi sono lenti rispetto al cloud.
Quando usare lo scraping cloud
- Pagine pubbliche (listing e-commerce, directory, siti immobiliari) che non richiedono login.
- Monitoraggio pianificato: esecuzione automatica e ricorrente.
- Job batch: in un singolo batch cloud.
- Consegna verso integrazioni: invio automatico a Google Sheets, Airtable o webhook.
Il compromesso: lo scraping cloud — 2 per ogni pagina con JavaScript abilitato, 1 per le pagine senza JS — e brucia in fretta il limite di 100 crediti del piano gratuito.
Quadro decisionale
| Scenario | Modalità consigliata | Perché | Rischio se sbagli |
|---|---|---|---|
| Pagine che richiedono login (LinkedIn, dashboard) | Browser | Serve la tua sessione autenticata | La modalità cloud incontra barriere di accesso |
| Listing pubblici di prodotti e-commerce | Cloud | Più veloce, funziona senza supervisione | La modalità browser occupa la tua macchina |
| Monitoraggio periodico pianificato | Cloud | Funziona senza di te | Il browser richiede la tua presenza |
| Siti con forti misure anti-bot (Amazon, Yelp) | Browser (fallback) o Cloud con proxy | Serve rotazione IP o riuso della sessione | Il cloud senza proxy viene bloccato in fretta |
| Estrazione rapida una tantum | Browser | Immediata, senza costo crediti | Impostare il cloud per una sola pagina è eccessivo |

Come Thunderbit semplifica tutto questo
In , la scelta è un semplice interruttore nella stessa interfaccia. La modalità cloud elabora fino a 50 pagine in parallelo — senza un livello a pagamento separato per l’accesso cloud. La modalità browser gestisce i siti che richiedono login senza configurazioni extra. Il peso mentale del “quale modalità mi serve?” cala molto quando entrambe convivono nello stesso flusso di lavoro.
Best practice 3: ottenere il massimo dal piano gratuito di Simplescraper
La confusione sui prezzi è reale. Ho visto post nei forum in cui si dà per scontato che “estensione Chrome gratuita” significhi “tutto gratis”. Non è così. E dall’altra parte ho visto persone pensare che Simplescraper fosse costoso perché i piani a pagamento non sono mostrati in modo evidente. Nessuna delle due ipotesi è utile.
Cosa include davvero il piano gratuito di Simplescraper
Secondo gli :
- Scraping nel browser: illimitato (eseguito localmente nel tuo Chrome)
- Crediti cloud: 100 al mese
- Ricette salvate: 3
- Formati di esportazione: CSV e JSON
- Cosa NON è incluso: supporto prioritario, opzioni proxy avanzate, limiti di crediti cloud più alti
Uno scenario realistico per il piano gratuito
Immagina di dover estrarre 50 pagine prodotto da un sito e-commerce pubblico.
- Modalità browser (gratuita): puoi farlo interamente gratis. Apri ogni pagina (oppure usi un elenco), esegui la ricetta, esporti in CSV. Tempo richiesto: dipende dalla tua pazienza e dalla velocità della connessione, ma aspettati 15-30 minuti di lavoro attivo per 50 pagine con navigazione manuale.
- Modalità cloud (piano gratuito): con il rendering JavaScript attivato, ogni pagina costa 2 crediti. 50 pagine = 100 crediti. È l’intero budget mensile cloud in un solo job. Niente pianificazione, niente retry se qualcosa fallisce.
Il piano gratuito è davvero utile per scraping piccoli e occasionali. Ma si esaurisce in fretta appena ti servono automazione cloud o scalabilità.
Confronto del piano gratuito: Simplescraper vs Thunderbit
| Funzionalità | Simplescraper Free | Thunderbit Free |
|---|---|---|
| Pagine/crediti | Browser illimitato + 100 crediti cloud | 6 pagine con tutte le funzioni AI |
| Estrazione basata su AI | Limitata (Smart Extract usa crediti) | Include AI Suggest Fields completo |
| Destinazioni di esportazione | CSV, JSON | Excel, Google Sheets, Airtable, Notion — tutto gratis |
| Configurazioni salvate | 3 ricette | Template disponibili |
| Scraping di sottopagine | Configurazione manuale della ricetta | Incluso nel conteggio pagine |
I modelli sono davvero diversi. Simplescraper ti offre scraping locale illimitato con cloud limitato. ti dà meno pagine, ma concentra capacità AI complete in ciascuna, oltre a esportazioni gratuite verso gli strumenti che i team usano davvero. Il piano gratuito di Simplescraper funziona se ti serve uno scraping locale di base e accetti il lavoro manuale. Ma se vuoi estrazione AI con esportazioni flessibili, il piano gratuito di Thunderbit offre molto più valore per pagina.
Best practice 4: come evitare di essere bloccati durante lo scraping
Nessuno pensa alle misure anti-bot finché non si ritrova davanti a un CAPTCHA o a un dataset vuoto. A quel punto hai già perso tempo e magari anche crediti.
La difesa preventiva costa sempre meno del troubleshooting reattivo.
Imposta limiti di frequenza e distribuisci le richieste
Il motivo principale per essere bloccati: martellare un sito con richieste rapidissime. Per un server web, 50 richieste in 10 secondi da un solo IP sembrano un attacco, non una ricerca curiosa.
Regole generali:
- Aggiungi 2-5 secondi tra una richiesta di pagina e l’altra per la maggior parte dei siti commerciali.
- Per target sensibili (marketplace, siti di recensioni), rallenta ancora: 5-10 secondi.
- Se usi l’API di Simplescraper, il parametro può aiutare a garantire che le pagine siano completamente caricate prima dell’estrazione, e rallenta anche in modo naturale il ritmo.
Quando abilitare la rotazione dei proxy
La rotazione dei proxy cambia il tuo indirizzo IP tra una richiesta e l’altra, facendoti sembrare utenti diversi. Ti serve per:
- Amazon, Yelp, TripAdvisor, LinkedIn (sistemi anti-bot aggressivi)
- Qualsiasi sito che limiti la frequenza per IP
- Job batch di grandi dimensioni (centinaia di pagine dallo stesso dominio)
La piattaforma di Simplescraper standard, premium e residential. Tuttavia, la disponibilità esatta a livello di piano non è sempre chiarissima nella documentazione pubblica — verifica prima di dare per scontato che il piano gratuito copra target difficili. I proxy residential di solito costano di più, ma hanno meno probabilità di essere segnalati.
Gestire siti pesanti in JavaScript
I siti moderni costruiti con React, Vue o Angular rendono i contenuti dopo il caricamento iniziale della pagina. Se il tuo scraper parte prima che JavaScript abbia finito di eseguire, ottieni campi vuoti.
Strategie:
- Usa la modalità di scraping cloud per un rendering migliore (il cloud di Simplescraper può eseguire JavaScript).
- Scorri manualmente la pagina prima di avviare uno scraping nel browser per attivare i contenuti con lazy loading.
- Usa
waitForSelectornei flussi basati su API per mettere in pausa finché non compaiono gli elementi target. - Accetta il fatto che alcune app single-page molto dinamiche possano semplicemente andare oltre ciò che uno scraper visivo può gestire in modo affidabile.
L’alternativa senza intervento manuale
gestisce automaticamente protezioni anti-bot, CAPTCHA e rendering JavaScript — senza configurare proxy, senza regolare ritardi, senza scorrere manualmente. Per chi non vuole trasformarsi in un ingegnere DevOps improvvisato solo per estrarre un catalogo prodotti, questo conta. I problemi non spariscono — semplicemente diventano il problema di qualcun altro.
Best practice 5: capire quando Simplescraper è arrivato al limite
Vorrei che qualcuno mi avesse scritto questa sezione due anni fa.
C’è un punto in cui lo strumento smette di farti risparmiare tempo e inizia a fartene perdere. Riconoscere presto quella soglia ti salva dalla trappola dei costi sommersi del tipo “ho già costruito 15 ricette, non posso cambiare adesso”.
I limiti pratici di Simplescraper
- Applicazioni single-page dinamiche che caricano i contenuti via AJAX senza una navigazione tradizionale tra pagine
- Infinite scroll che richiede scorrimento continuo per caricare tutti gli elementi (non la paginazione standard basata su clic)
- Arricchimento delle sottopagine: estrarre una pagina elenco e poi visitare ogni pagina dettaglio per dati aggiuntivi. Simplescraper può farlo con , ma la complessità di configurazione cresce rapidamente.
- Cambiamenti di layout che rompono le ricette esistenti. Quando un sito aggiorna la propria struttura HTML, i selettori CSS che avevi ottimizzato con cura smettono di funzionare.
Segnali che hai superato lo strumento
Probabilmente hai raggiunto il limite quando:
- Modifichi manualmente i selettori CSS a ogni scraping perché il rilevamento automatico continua a fallire
- Le ricette si rompono dopo gli aggiornamenti del sito e devono essere ricreate da zero
- Devi estrarre decine o centinaia di pagine contemporaneamente ma continui a scontrarti con limiti di crediti o di velocità
- I dati delle sottopagine richiedono catene di ricette multi-step complesse
- Passi più tempo a mantenere gli scraping che a usare davvero i dati estratti
Quest’ultimo è il segnale più chiaro. Quando la manutenzione diventa il lavoro, il vantaggio di comodità del no-code è svanito.
Passare a un flusso di lavoro basato su AI
Qui parlo di ciò che il mio team ha costruito con , perché è stato progettato proprio per le modalità di fallimento descritte sopra:

- L’AI legge ogni pagina da zero ogni volta — niente ricette fragili o selettori CSS da mantenere. Se un sito cambia layout, l’AI si adatta alla run successiva.
- Lo scraping delle sottopagine arricchisce la tua tabella dati con un clic. Estrai un elenco e poi visita automaticamente ogni pagina dettaglio per campi aggiuntivi.
- Scraping pianificato usando il linguaggio naturale (“ogni lunedì alle 9”) invece di configurare preset temporali.
- Scraping cloud fino a 50 pagine in parallelo per ottenere velocità sui siti pubblici.
- Esportazioni native gratuite verso Google Sheets, Airtable, Notion ed Excel senza configurare webhook.
Simplescraper vs Thunderbit: confronto affiancato
Ecco tutto in un unico posto:

| Capacità | Simplescraper | Thunderbit |
|---|---|---|
| Configurazione dei campi | Selettori CSS manuali / selezione visiva | AI Suggest Fields (inglese semplice) |
| Arricchimento delle sottopagine | Possibile tramite workflow batch (configurazione complessa) | Auto-arricchimento con 1 clic |
| Adattamento automatico ai cambiamenti di layout | Si rompe (serve correzione manuale) | L’AI rilegge ogni volta la struttura della pagina |
| Concorrenza delle pagine cloud | Batch fino a 5.000 URL (varia in base al piano) | 50 pagine contemporaneamente |
| Esportazione su Notion/Airtable | Tramite webhook (piani a pagamento) | Nativo, gratuito |
| Pianificazione | Preset + controlli temporali personalizzati | Descrizione in linguaggio naturale |
| Gestione anti-bot / CAPTCHA | Modalità proxy disponibili (dipende dal piano) | Automatica, senza configurazione |
| Piano gratuito | 100 crediti cloud + browser illimitato + 3 ricette | 6 pagine con tutte le funzioni AI + esportazioni gratuite |
In breve: Simplescraper dà il meglio di sé per estrazioni semplici, visive e con poca configurazione, dove una regolazione manuale occasionale è accettabile. Thunderbit entra in gioco quando quel modello si inceppa — gestendo interpretazione della pagina, adattamento del layout e complessità del flusso di lavoro al posto tuo.
Nessuno dei due strumenti è universalmente migliore. Si collocano in punti diversi della curva di complessità — e va benissimo così.
Riferimento rapido: checklist delle best practice di Simplescraper
Salva questo per la tua prossima sessione di scraping:
- Prova sempre prima su un campione piccolo. Verifica il numero di righe e la completezza dei campi su 2-3 pagine prima di scalare.
- Scorri la pagina prima dello scraping per attivare i contenuti con lazy loading.
- Usa “Include Similar” quando il rilevamento dell’elenco sembra troppo ristretto.
- Scegli deliberatamente la modalità di scraping. Browser per i siti che richiedono login; cloud per pagine pubbliche e job pianificati.
- Imposta ritardi tra le richieste — minimo 2-5 secondi per i siti commerciali, di più per i target con forti difese anti-bot.
- Conosci la matematica del piano gratuito. 100 crediti cloud = 50 pagine con JavaScript abilitato. Pianifica di conseguenza.
- Salva le ricette solo per pagine stabili. Se un sito si aggiorna spesso, le ricette si romperanno.
- Impara le basi dei selettori CSS come fallback. I nomi delle classi e gli attributi data battono i selettori posizionali.
- Monitora i blocchi in modo proattivo. Se ottieni risultati vuoti o CAPTCHA, rallenta o cambia modalità.
- Riconosci il limite. Quando il tempo di manutenzione supera il tempo di utilizzo dei dati, valuta alternative.
Conclusione: fai contare ogni scraping
La lezione generale che emerge da più di mille scraping non riguarda uno strumento specifico. È che l’approccio conta più del software. Capire perché uno scraping fallisce — lazy loading, modalità sbagliata, anti-bot aggressivo, selettori fragili — è più prezioso di qualunque elenco di funzionalità.
Simplescraper funziona davvero bene per lavori di estrazione semplici e lineari. Se le tue pagine sono pulite, le tue esigenze sono moderate e non ti dispiace qualche ritocco manuale occasionale, mantiene ciò che promette.
Ma se ti accorgi che stai lottando più con lo strumento che usandolo — fai debug dei selettori, ricrei ricette rotte, configuri proxy, scorri manualmente le pagine — quello è un segnale, non un fallimento personale. Significa che hai superato ciò che il solo scraping visivo può gestire in modo efficiente.
Se ti suona familiare, prova il — sei pagine con tutte le funzioni AI, esportazioni gratuite su Sheets, Airtable e Notion. Confrontalo con il tuo flusso di lavoro attuale e vedi cosa funziona meglio. A volte la best practice è sapere quando prendere in mano uno strumento completamente diverso.
FAQ
Simplescraper è gratuito?
Sì, Simplescraper ha un piano gratuito che include scraping locale illimitato nel browser, , 3 ricette salvate ed esportazione CSV/JSON. Le pagine cloud con JavaScript costano 2 crediti ciascuna, quindi quei 100 crediti coprono circa 50 pagine in modalità cloud. I piani a pagamento partono da 39 $/mese (Plus) per 6.000 crediti e 70 $/mese (Pro) per 15.000 crediti.
Simplescraper può gestire siti web con molti contenuti JavaScript?
A volte sì. La modalità cloud di Simplescraper può renderizzare JavaScript e lo strumento dichiara il supporto per le single-page app. Tuttavia, SPA complesse con rendering dinamico pesante, infinite scroll o sistemi anti-bot aggressivi possono comunque produrre risultati incompleti. Usare la modalità cloud con tempi di attesa adeguati migliora l’affidabilità, ma i siti molto dinamici restano una sfida per qualunque scraper visivo.
Qual è la differenza tra scraping cloud e browser in Simplescraper?
Lo scraping nel browser viene eseguito localmente nel tuo browser Chrome — usa la tua sessione attiva (ottimo per siti che richiedono login), non costa crediti, ma richiede che il computer resti acceso. viene eseguito sui server di Simplescraper — è più veloce, funziona senza supervisione, supporta pianificazione e integrazioni, ma consuma crediti per pagina e non può accedere alle pagine dietro il tuo login personale.
Quando dovrei passare da Simplescraper a un’alternativa come Thunderbit?
Il segnale più chiaro è quando il tempo di manutenzione supera il tempo di utilizzo dei dati. Se ripari regolarmente selettori rotti dopo gli aggiornamenti dei siti, configuri manualmente i proxy, ricrei ricette da zero o passi più tempo a fare troubleshooting che ad analizzare i dati estratti, hai superato ciò che lo scraping visivo manuale può offrire in modo efficiente. Strumenti come che usano l’AI per interpretare la struttura della pagina a ogni esecuzione eliminano gran parte di questo carico di manutenzione.
Come evito di essere bloccato quando faccio scraping con Simplescraper?
Tre pratiche chiave: prima di tutto, distribuisci le richieste con ritardi di 2-5 secondi tra le pagine (di più per i siti con forti misure anti-bot come Amazon o Yelp). In secondo luogo, usa la modalità browser come fallback per i siti che bloccano in modo aggressivo gli IP cloud — la tua sessione browser assomiglia di più al traffico normale. In terzo luogo, abilita la rotazione dei proxy per grandi batch su target sensibili, ma verifica quali opzioni proxy sono incluse nel tuo piano prima di farci affidamento.
Scopri di più