

Lasciami tornare alla prima volta in cui ho provato a estrarre dati di prodotto da un sito ecommerce. Avevo con me Python, una tazza di caffè e un sogno: creare un tracker dei prezzi per Amazon. Qualche ora dopo, il mio “progettino veloce” si era trasformato in un groviglio di selettori XPath, problemi di paginazione e più debug di quanto mi piaccia ammettere. Se hai mai provato a domare dati web con il codice, probabilmente conosci quella sensazione: metà entusiasmo e metà “perché è così complicato?”.
Ecco il punto: il web scraping non è più solo roba da data scientist o ingegneri. È diventato una competenza indispensabile per team di vendita, responsabili ecommerce, marketer e per chiunque voglia trasformare il caos del web in business intelligence. Anzi, il mercato dei software di web scraping ha raggiunto 1,01 miliardi di dollari nel 2024 e si prevede che arriverà a 2,49 miliardi di dollari entro il 2032, e la curva non si sta appiattendo. Però, anche se Python e framework come Scrapy restano lo standard d’oro per scraping personalizzati su larga scala, non sono certo i più adatti ai principianti. Per questo, in questo tutorial ti guiderò passo dopo passo su Scrapy — usando un caso reale su Amazon — e ti mostrerò un’alternativa molto più semplice, basata su AI, per chi non programma: Thunderbit.
Cos’è Scrapy Python? Il tuo coltello svizzero per il web scraping
Partiamo dalle basi. Scrapy è un framework Python open source creato appositamente per il crawling e lo scraping di siti web. Pensalo come un kit tutto in uno per costruire spider personalizzati (così Scrapy chiama i suoi crawler) in grado di navigare i siti, seguire i link, gestire la paginazione ed estrarre dati strutturati su larga scala.
In cosa Scrapy si differenzia dal semplice uso di requests e BeautifulSoup in Python? Beh, mentre quelle librerie sono ottime per estrazioni semplici e occasionali, Scrapy è progettato per progetti grandi e complessi — quelli in cui devi:
- Scansionare migliaia di pagine (pensa: ogni prodotto di un catalogo ecommerce)
- Seguire automaticamente i link e gestire la paginazione
- Elaborare i dati in modo asincrono per ottenere più velocità
- Strutturare, pulire ed esportare i dati in modo ripetibile
In breve, Scrapy è come il coltellino svizzero del web scraping: potente, flessibile e, nel bene e nel male, un po’ intimidatorio per chi è alle prime armi.
Perché usare Scrapy Python per il web scraping?
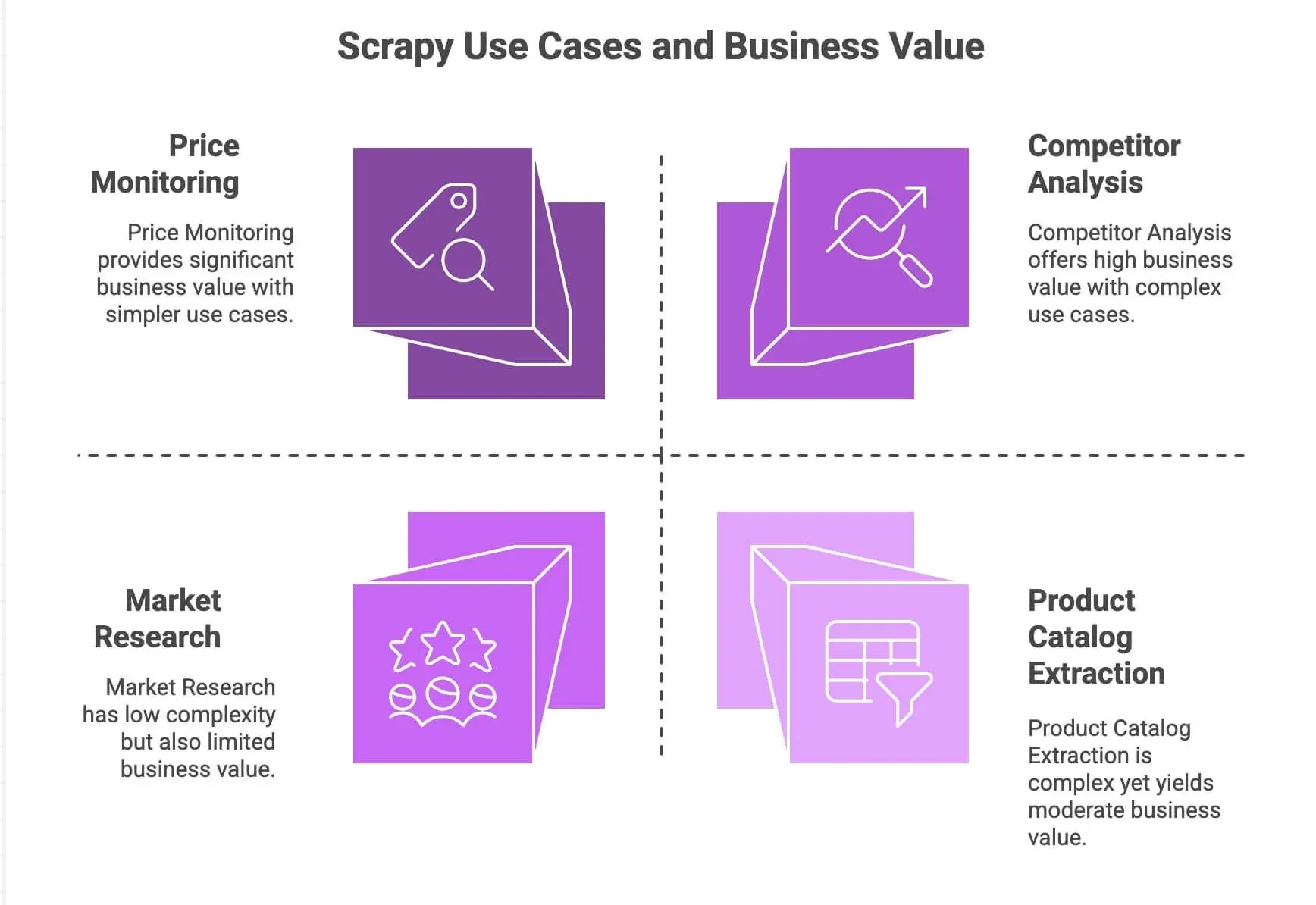
Allora, perché sviluppatori e team dati continuano a scegliere Scrapy? Ecco una rapida panoramica dei suoi punti di forza:
| Caso d’uso | Punti di forza di Scrapy | Valore per il business |
|---|---|---|
| Monitoraggio dei prezzi | Gestisce paginazione, richieste asincrone, pianificazione | Restare davanti ai concorrenti, pricing dinamico |
| Estrazione di cataloghi prodotti | Segue i link, estrae dati strutturati | Creare database prodotti, alimentare le analisi |
| Analisi dei concorrenti | Scalabile, robusto contro i cambiamenti del sito | Monitorare trend, nuovi lanci, livelli di stock |
| Ricerche di mercato | Pipeline modulari per pulire/trasformare i dati | Aggregare recensioni, eseguire sentiment analysis |
Il motore asincrono di Scrapy (basato su Twisted) gli permette di recuperare più pagine in parallelo, rendendolo veloce e scalabile. Il suo design modulare ti consente di aggiungere logiche personalizzate (come proxy, user-agent o passaggi di pulizia dei dati). E con le pipeline puoi elaborare, validare ed esportare i dati come preferisci: CSV, JSON, database, insomma tutto quello che ti serve.
Per i team che conoscono Python, Scrapy è una vera potenza. Ma diciamolo chiaramente: non è esattamente “plug and play” per l’utente business medio.
Configurare il tuo ambiente Scrapy Python
Pronto a sporcarti le mani? Ecco come configurare Scrapy da zero:
1. Installa Scrapy
Per prima cosa, assicurati di avere Python 3.10+ installato (Scrapy 2.15.x ha rimosso il supporto per la 3.9 nel 2026). Poi apri il terminale ed esegui:
pip install scrapy
Verifica l’installazione con:
scrapy version
Se usi Windows o Anaconda, ti conviene impostare un ambiente virtuale per evitare conflitti. Scrapy funziona su Windows, macOS e Linux.
2. Crea un nuovo progetto Scrapy
Iniziamo un nuovo progetto chiamato amazonscraper:
scrapy startproject amazonscraper
Otterrai una struttura di cartelle simile a questa:
amazonscraper/
├── scrapy.cfg
├── amazonscraper/
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── middlewares.py
│ ├── settings.py
│ └── spiders/
A cosa servono questi file?
scrapy.cfg: configurazione del progetto (ci metti mano raramente)items.py: definisci i modelli dei dati (per esempio un Product con nome, prezzo e così via)pipelines.py: qui pulisci, validi ed esporti i datimiddlewares.py: roba avanzata (proxy, header personalizzati)settings.py: per regolare il comportamento di Scrapy (concorrenza, ritardi, ecc.)spiders/: qui vive la logica vera e propria dello scraping
Se già ti senti un po’ sopraffatto, non sei solo. È qui che molti non programmatori iniziano a sudare.
Creare uno scraper Python: estrarre dati prodotto da Amazon con Scrapy
Facciamo un esempio reale: estrarre dati prodotto dai risultati di ricerca di Amazon. (Attenzione: i termini di servizio di Amazon non permettono lo scraping e i loro sistemi anti-bot sono aggressivi. Questo esempio è solo a scopo didattico!)
1. Crea uno spider
Dentro la cartella spiders/, crea un file chiamato amazon_spider.py:
import scrapy
class AmazonSpider(scrapy.Spider):
name = "amazon_example"
allowed_domains = ["amazon.com"]
start_urls = ["https://www.amazon.com/s?k=smartphones"]
def parse(self, response):
products = response.xpath("//div[@data-component-type='s-search-result']")
for product in products:
yield {
'name': product.xpath(".//span[@class='a-size-medium a-color-base a-text-normal']/text()").get(),
'price': product.xpath(".//span[@class='a-price-whole']/text()").get(),
'rating': product.xpath(".//span[@aria-label]/text()").get()
}
next_page = response.xpath("//li[@class='a-last']/a/@href").get()
if next_page:
yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)
Cosa succede qui?
- Partiamo da una pagina dei risultati di ricerca Amazon per “smartphone”.
- Per ogni prodotto estraiamo nome, prezzo e valutazione usando selettori XPath.
- Cerchiamo il link alla “pagina successiva” e diciamo a Scrapy di seguirlo, per raccogliere altri prodotti.
2. Esegui il tuo spider
Dalla root del progetto, esegui:
scrapy crawl amazon_example -o products.json
Boom: Scrapy passerà in rassegna i risultati di ricerca, seguirà la paginazione e salverà i dati in un file JSON.
Gestire paginazione e contenuti dinamici
Il supporto integrato di Scrapy per seguire i link e gestire la paginazione è uno dei suoi superpoteri. Ma cosa succede con i contenuti dinamici, cioè pagine che caricano dati con JavaScript? Di base, Scrapy vede solo l’HTML statico. Se devi estrarre contenuti caricati via JavaScript (come infinite scroll o recensioni in pop-up), dovrai integrarlo con strumenti come Selenium o Splash. E lì si apre tutto un altro capitolo.
Elaborare ed esportare dati con Scrapy Python
Una volta estratti i dati, probabilmente vorrai pulirli ed esportarli in un posto utile.
- Pipeline: in
pipelines.pypuoi scrivere classi Python per pulire, validare o arricchire i dati (per esempio convertire i prezzi in numeri, scartare righe incomplete o perfino chiamare una API di traduzione). - Esportazione: Scrapy può esportare direttamente in CSV, JSON o XML con il flag
o. Per esportazioni più avanzate (come l’invio a Google Sheets), dovrai scrivere codice aggiuntivo o usare librerie di terze parti.
Vuoi fare sentiment analysis o tradurre le descrizioni dei prodotti? Dovrai integrare API esterne o librerie Python: non c’è nulla di già pronto.
I costi nascosti: le difficoltà di Scrapy Python per gli utenti business
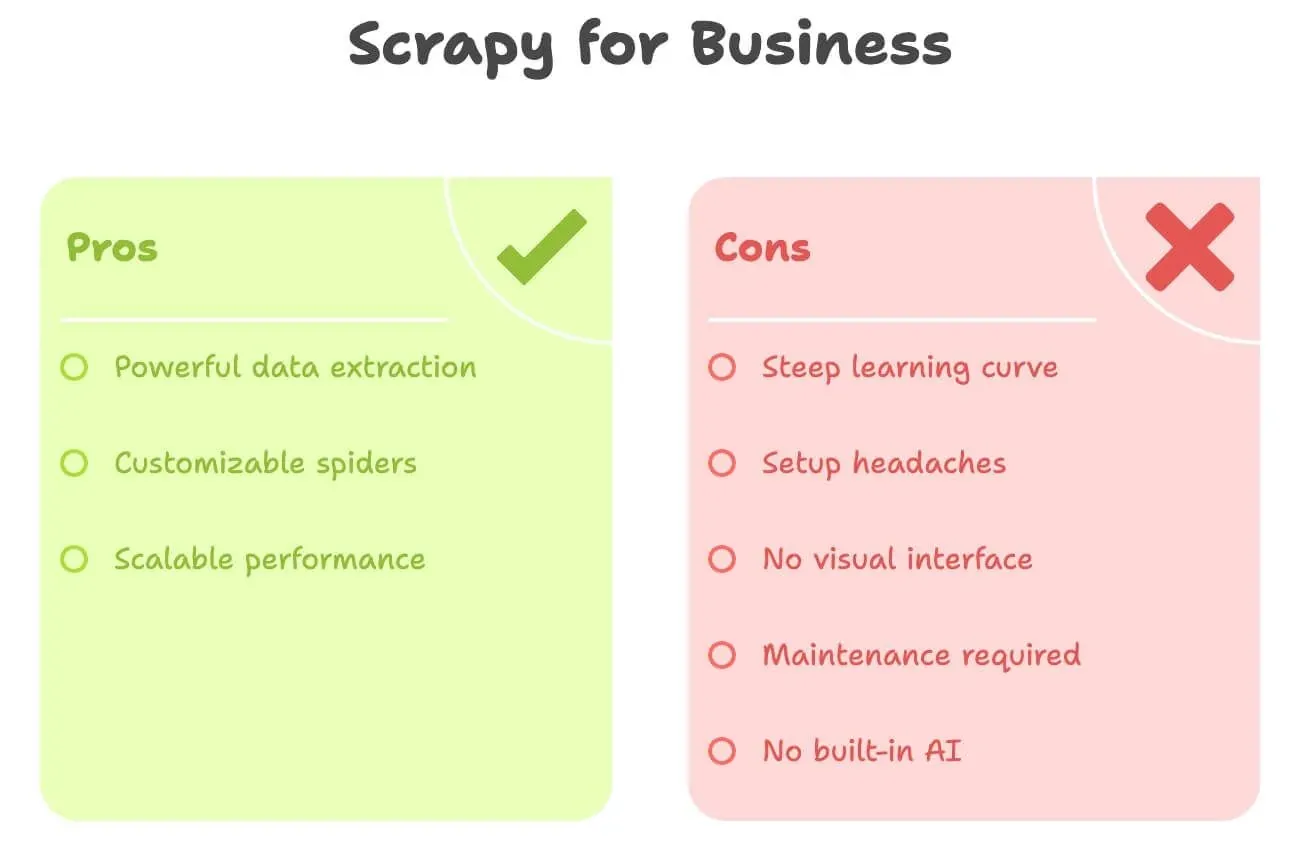
Diciamolo senza giri di parole: Scrapy è potente, ma non è proprio user-friendly per chi non sviluppa. Ecco cosa mette più in difficoltà la maggior parte degli utenti business:
- Curva di apprendimento ripida: devi conoscere Python, HTML, selettori XPath/CSS e la struttura dei progetti Scrapy. Possono volerci giorni o persino settimane per sentirti a tuo agio.
- Problemi di installazione: installare Python, gestire le dipendenze e risolvere gli errori può essere fastidioso, soprattutto su Windows.
- Nessuna interfaccia visuale: è tutto codice. Non puoi semplicemente fare clic su una pagina per selezionare i dati.
- Manutenzione: se il sito cambia, il tuo spider si rompe. Tocca a te sistemarlo.
- Niente AI integrata: vuoi tradurre, riassumere o analizzare il sentiment? Serve tutto codice aggiuntivo.
Ecco un rapido confronto:
| Sfida | Scrapy (Python) | Esigenze dell’utente business |
|---|---|---|
| Necessità di scrivere codice | Sì | Meglio no-code |
| Tempo di configurazione | Ore (o giorni) | Minuti |
| Manutenzione | Continua (se il sito cambia) | Minima |
| Esportazione dati | CSV/JSON (integrazione manuale) | Direttamente in Excel/Sheets/Notion |
| Funzionalità AI | Nessuna (integrazione fai-da-te) | Traduzione/sentiment integrati |
Se sei un marketer solitario, un commerciale o un responsabile operativo, Scrapy può sembrare come portare un bazooka a una battaglia di palloncini d’acqua.
Ti presento Thunderbit: l’alternativa no-code a Scrapy Python
Ed è qui che entra in gioco Thunderbit. Da persona che ha passato anni a costruire strumenti di automazione, posso dirti una cosa: la maggior parte degli utenti business non vuole programmare — vuole solo i dati, e in fretta.
Thunderbit è un Estrattore Web AI disponibile come estensione Chrome. È pensato per utenti non tecnici che vogliono:
- Estrarre dati da qualsiasi sito in pochi clic
- Descrivere con linguaggio naturale ciò che vogliono (“Nome prodotto, Prezzo, Valutazione”)
- Gestire automaticamente paginazione e sottopagine
- Esportare i dati direttamente in Excel, Google Sheets, Airtable o Notion
- Tradurre, riassumere o analizzare il sentiment al volo
Niente Python. Niente selettori. Niente problemi di manutenzione.
Come estrarre dati da qualsiasi sito usando l’AI Get Started Free
Thunderbit è pensato per chi in azienda vuole muoversi veloce e lasciare che sia l’AI a fare il lavoro pesante.
Thunderbit vs. Scrapy Python: confronto diretto
Mettiamoli uno accanto all’altro:
| Aspetto | Scrapy (Python) | Thunderbit (strumento AI) |
|---|---|---|
| Competenze richieste | Python, HTML, selettori | Nessuna: punta e clicca, linguaggio naturale |
| Tempo di configurazione | Ore (installazione, codice, debug) | Minuti (installa l’estensione Chrome, accedi) |
| Strutturazione dei dati | Manuale (definisci item, pipeline) | L’AI rileva automaticamente le colonne e suggerisce i campi |
| Paginazione/Sottopagine | Serve codice | 1 clic (la AI gestisce tutto) |
| Traduzione | Codice personalizzato o integrazione API | Integrata: basta attivare “Traduci” |
| Sentiment analysis | Libreria/API esterna | Integrata: aggiungi una colonna “Sentiment” |
| Opzioni di esportazione | CSV/JSON (importazione manuale in Sheets/Excel) | Esportazione in 1 clic verso Excel, Google Sheets, Airtable, Notion |
| Manutenzione | Manuale (aggiorna il codice se il sito cambia) | L’AI si adatta automaticamente ai piccoli cambiamenti del sito |
| Scala | Ideale per progetti grandi e continui | Ideale per task rapidi, scala media (centinaia/migliaia di righe) |
| Costo | Gratis (ma costa tempo/risorse di sviluppo) | Piano gratuito + piani a pagamento (da 9 $/mese, ma fa risparmiare tantissimo tempo e stress) |
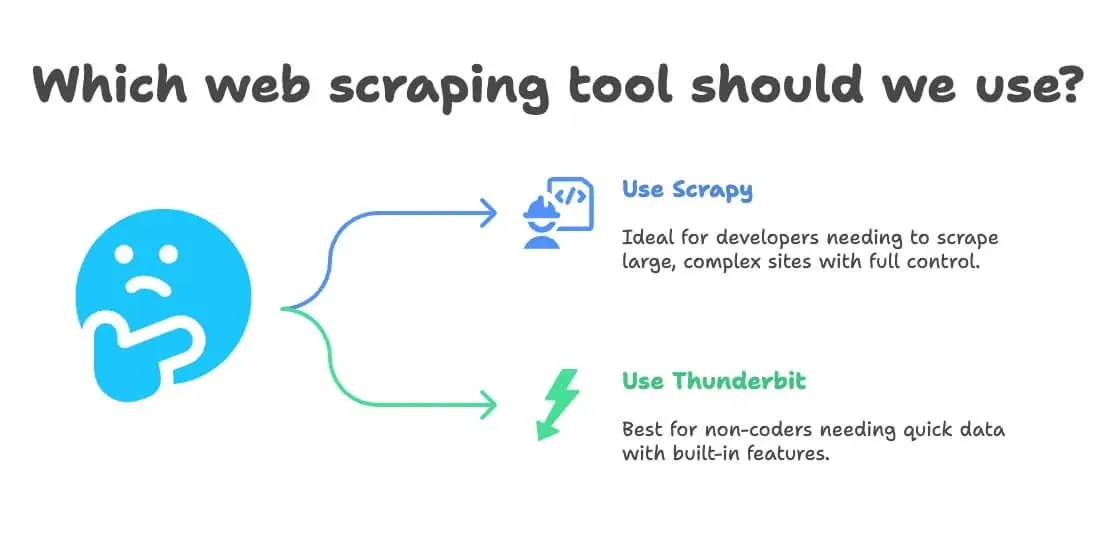
Quando scegliere Scrapy Python e quando Thunderbit per il web scraping
La mia regola pratica è questa:
- Usa Scrapy se:
- Sei uno sviluppatore o ne hai uno nel team
- Devi estrarre decine di migliaia di pagine, oppure creare una pipeline personalizzata e continua
- Il sito è molto complesso o richiede logiche avanzate
- Vuoi il controllo totale (e non ti dispiace la manutenzione)
- Usa Thunderbit se:
- Non programmi (o non vuoi programmare)
- Ti servono dati rapidamente, per un’attività una tantum o ricorrente
- Vuoi traduzione, sentiment o arricchimento dei dati integrati
- Dai più valore alla velocità e alla flessibilità che alla personalizzazione estrema
Ecco un rapido flusso decisionale:
- Sai programmare in Python?
- Sì → Scrapy o Thunderbit (per risultati rapidi)
- No → Thunderbit
- Il tuo progetto è enorme e continuo?
- Sì → Scrapy
- No → Thunderbit
- Ti servono traduzione o sentiment analysis?
- Sì → Thunderbit
- No → Entrambi
Passo dopo passo: estrarre dati prodotto da Amazon con Thunderbit (senza codice)
Rifacciamo il nostro esempio su Amazon — questa volta, nel modo più semplice.
1. Installa Thunderbit
- Scarica l’estensione Thunderbit per Chrome
- Registrati (è disponibile un piano gratuito)
Prova gratuitamente l’estensione Chrome di Thunderbit
2. Vai su Amazon e cerca il tuo prodotto
- Apri Amazon.com e cerca “laptop” (o qualsiasi altro prodotto)
3. Avvia Thunderbit sulla pagina
- Fai clic sull’icona di Thunderbit nel browser
- Si apre il pannello laterale, che riconosce la pagina Amazon
4. Usa AI Suggerisci campi
- Fai clic su “AI Suggest Fields”
- L’AI di Thunderbit analizza la pagina e suggerisce colonne come “Nome prodotto”, “Prezzo”, “Valutazione”, “Numero di recensioni”
- Aggiungi o rimuovi colonne come preferisci (vuoi “URL del prodotto” o “Idoneità Prime”? Basta scriverlo)
5. Attiva la paginazione e l’estrazione delle sottopagine
- Attiva Paginazione: Thunderbit cliccherà automaticamente su “Next” ed estrarrà tutte le pagine
- Attiva Estrazione sottopagine: Thunderbit visiterà la pagina dettaglio di ogni prodotto e raccoglierà informazioni extra (come descrizioni o numeri ASIN)
6. Avvia l’estrazione
- Fai clic su Estrai
- Guarda Thunderbit raccogliere i dati in tempo reale, pagina dopo pagina
7. Traduci e analizza il sentiment (opzionale)
- Vuoi tradurre le descrizioni dei prodotti? Attiva “Traduci” per quella colonna
- Vuoi analizzare il sentiment delle recensioni? Aggiungi una colonna “Sentiment” — l’AI di Thunderbit la compilerà per te
8. Esporta i dati
- Fai clic su Esporta
- Scegli Excel, Google Sheets, Airtable o Notion
- I tuoi dati sono pronti all’uso: niente importazioni manuali, niente caos da CSV
9. Pianifica estrazioni ricorrenti (opzionale)
- Imposta una pianificazione, ad esempio ogni giorno alle 8:00
- Thunderbit eseguirà l’estrazione automaticamente e aggiornerà la destinazione scelta
Tutto qui. Niente codice, niente selettori, niente manutenzione. Solo dati, pronti per il business.
Consigli extra: ottenere di più dai tuoi progetti di web scraping
Che tu stia usando Scrapy, Thunderbit o qualsiasi altro strumento, ecco alcune best practice che ho imparato nel modo più duro:
- Valida i tuoi dati: controlla sempre che non manchino valori o che non ci siano anomalie (come prezzi di 0 $ o nomi vuoti)
- Resta conforme: verifica i termini di servizio del sito, rispetta
robots.txte non sovraccaricare i server - Automatizza con criterio: usa la pianificazione per mantenere i dati aggiornati, ma non estrarre più spesso del necessario
- Sfrutta gli strumenti gratuiti: Thunderbit include gratis estrattori di email, telefono e immagini — ottimi per lead generation o curatela di contenuti
- Organizza per l’analisi: esporta direttamente in Sheets/Excel così puoi filtrare, creare tabelle pivot e visualizzare tutto rapidamente
Per altri consigli, visita il blog di Thunderbit o la loro guida su come estrarre dati da qualsiasi sito usando l’AI.
Come estrarre dati da un sito in Excel usando l’AI Get Started Free
Per altri consigli, visita il blog di Thunderbit o la loro guida su come estrarre dati da qualsiasi sito usando l’AI.
Conclusione: il web scraping diventa semplice — scegli lo strumento giusto per il tuo team
Ecco il punto chiave: Scrapy è una potenza per gli sviluppatori, ma per la maggior parte degli utenti business è troppo. Se ti trovi a tuo agio con Python e devi costruire uno scraper personalizzato su larga scala, Scrapy è un’ottima scelta. Ma se vuoi andare veloce, saltare il codice e ottenere dati con traduzione e sentiment analysis già inclusi, Thunderbit è la strada giusta.
Ho visto in prima persona quanto tempo e quanta frustrazione Thunderbit faccia risparmiare ai team non tecnici. Puoi passare da “vorrei avere questi dati” a “sono nel mio foglio di calcolo” in pochi minuti, non in ore o giorni. E con funzionalità come AI Suggest Fields, l’estrazione delle sottopagine e l’esportazione in un clic, non è mai stato così facile trasformare il web in business intelligence.
Quindi, la prossima volta che devi estrarre dati di prodotto, monitorare prezzi o creare una lista di lead, chiediti: vuoi scrivere Python o vuoi risultati? Prova il piano gratuito di Thunderbit e scopri quanto può essere più semplice il web scraping.
Prova Thunderbit gratuitamente
Vuoi saperne di più? Visita il sito ufficiale di Thunderbit, scarica l’estensione Chrome o approfondisci le best practice del web scraping sul blog di Thunderbit.
Approfondimenti:
- Che cos’è il data scraping e come farlo nel 2026
- Come estrarre dati da un sito in Excel usando l’AI
- I migliori strumenti e software per il web scraping nel 2026
- Rapporto sullo stato del web scraping
Disclaimer: assicurati sempre che le attività di web scraping siano conformi ai termini del sito e alle leggi locali. In caso di dubbio, consulta un legale: nessuno vuole essere lo “scraper” che riceve una lettera di diffida per un foglio di calcolo.
Scritto da Shuai Guan, cofondatore e CEO di Thunderbit. Ho passato anni tra SaaS, automazione e AI — così non devi farlo tu.
Prova AI Web Scraper Get Started Free




