è un'estensione Chrome AI Web Scraper che aiuta gli utenti business a estrarre dati dai siti web con l'intelligenza artificiale. Il punto davvero centrale è questo: quello che sulla pagina prezzi di ScrapingBee sembra conveniente, quando entri nel vivo della produzione può diventare tutt'altra storia, con crediti che si bruciano a una velocità da 5× a 75× rispetto al costo base. Questa recensione mette sotto la lente cinque aspetti che la maggior parte degli articoli lascia fuori: il costo reale su larga scala, l'estrazione basata su selector rispetto a quella AI, l'usabilità per chi non sviluppa, i flussi di lavoro sui dati dopo l'estrazione e i benchmark di affidabilità del 2026. Se stai valutando ScrapingBee per il tuo team — che tu sia uno sviluppatore, un responsabile sales ops o un founder — questa è l'analisi che ti serve.
Cos'è ScrapingBee? Panoramica rapida
ScrapingBee è una web scraping API che si occupa di rotazione dei proxy, rendering JavaScript e risoluzione dei CAPTCHA, così gli sviluppatori possono estrarre dati dai siti web senza dover costruire una propria infrastruttura di scraping. Tu mandi una richiesta HTTP con alcuni parametri e ricevi in risposta HTML (oppure JSON per alcuni endpoint). Non c'è un'interfaccia visuale o click-based per creare gli scraping.
Le funzionalità principali includono:
- Proxy rotanti e premium (classici, premium, stealth, residential)
- Rendering con browser headless (Chrome completo, attivo di default)
- Bypass automatico dei CAPTCHA
- Google Search API (JSON strutturato: risultati organici, annunci, mappe, knowledge graph, People Also Ask, immagini, news)
- Acquisizione screenshot (standard, pagina intera o mirata a un selettore CSS)
- Targeting geografico tramite parametro
country_code - Regole di estrazione CSS/XPath (dichiarative, basate su JSON, restituiscono JSON strutturato)
- API dedicate per scraping di Amazon, Walmart, YouTube e ChatGPT
- Estrazione AI (aggiunta circa nel 2024–2025): parametri
ai_query,ai_extract_rules,ai_selector(+5 crediti per richiesta) - Strumento CLI (lanciato circa nel 2025–2026): elaborazione batch, crawling, parsing della sitemap, arricchimento CSV, job cron pianificati, escalation dei proxy
Fondato nel 2019 in Francia, ScrapingBee è cresciuto fino a circa entro l'inizio del 2026 con oltre 2.500 clienti (SAP, Zapier, Deloitte, Zillow) — il tutto in modalità bootstrapped e con un team di 4–6 persone. Nel giugno 2025, in un'operazione a otto cifre. Il brand e la leadership restano indipendenti, e il team di supporto è per coprire meglio i fusi orari.
Una nota importante: ScrapingBee non ha ancora un builder visuale nativo, un'interfaccia GUI point-and-click o uno scheduler integrato nella dashboard web. La pianificazione richiede il tool CLI, i cron job o automazioni di terze parti (Zapier, Make, n8n). Le guide “no-code” che pubblicano riguardano l'uso delle integrazioni con Make e Zapier — non un'interfaccia no-code nativa.
Per chi è davvero pensato ScrapingBee?
ScrapingBee è pensato per sviluppatori che sanno muoversi con Python o chiamate cURL, leggere HTML e costruire selector CSS/XPath. La documentazione è molto orientata al codice, con esempi soprattutto in Python e cURL. Un recensore su ha fatto notare che "non forniscono esempi in JavaScript", mentre un altro ha descritto la documentazione come "voluminosa, serve da un giorno a una settimana per leggerla tutta".
Ma il pubblico che cerca una "recensione di ScrapingBee" nel 2026 va ben oltre i soli backend engineer. Ci sono marketing manager che costruiscono liste lead, team sales ops che arricchiscono i dati CRM, team ecommerce che tengono d'occhio i prezzi dei competitor e founder che valutano strumenti per il proprio team. In ogni sezione qui sotto, segnalerò se una funzione o un limite conta per gli sviluppatori, per gli utenti business o per entrambi.
I piani tariffari di ScrapingBee in sintesi
Ecco i livelli di piano attuali di ScrapingBee (ad aprile 2026):
| Piano | Prezzo mensile | Crediti API/mese | Richieste simultanee |
|---|---|---|---|
| Freelance | $49 | 250.000 | 10 |
| Startup | $99 | 1.000.000 | 50 |
| Business | $249 | 3.000.000 | 100 |
| Business+ | $599 | 8.000.000 | 200 |
| Enterprise | Contatta le vendite | 41M+ | Personalizzato |
La fatturazione annuale offre uno . Una prova gratuita dà 1.000 crediti API senza bisogno di carta di credito. La Google Search API è stata recentemente per chiamata dopo l'acquisizione.
Quei numeri in evidenza sembrano generosi. Ma non sono quello che sembrano.
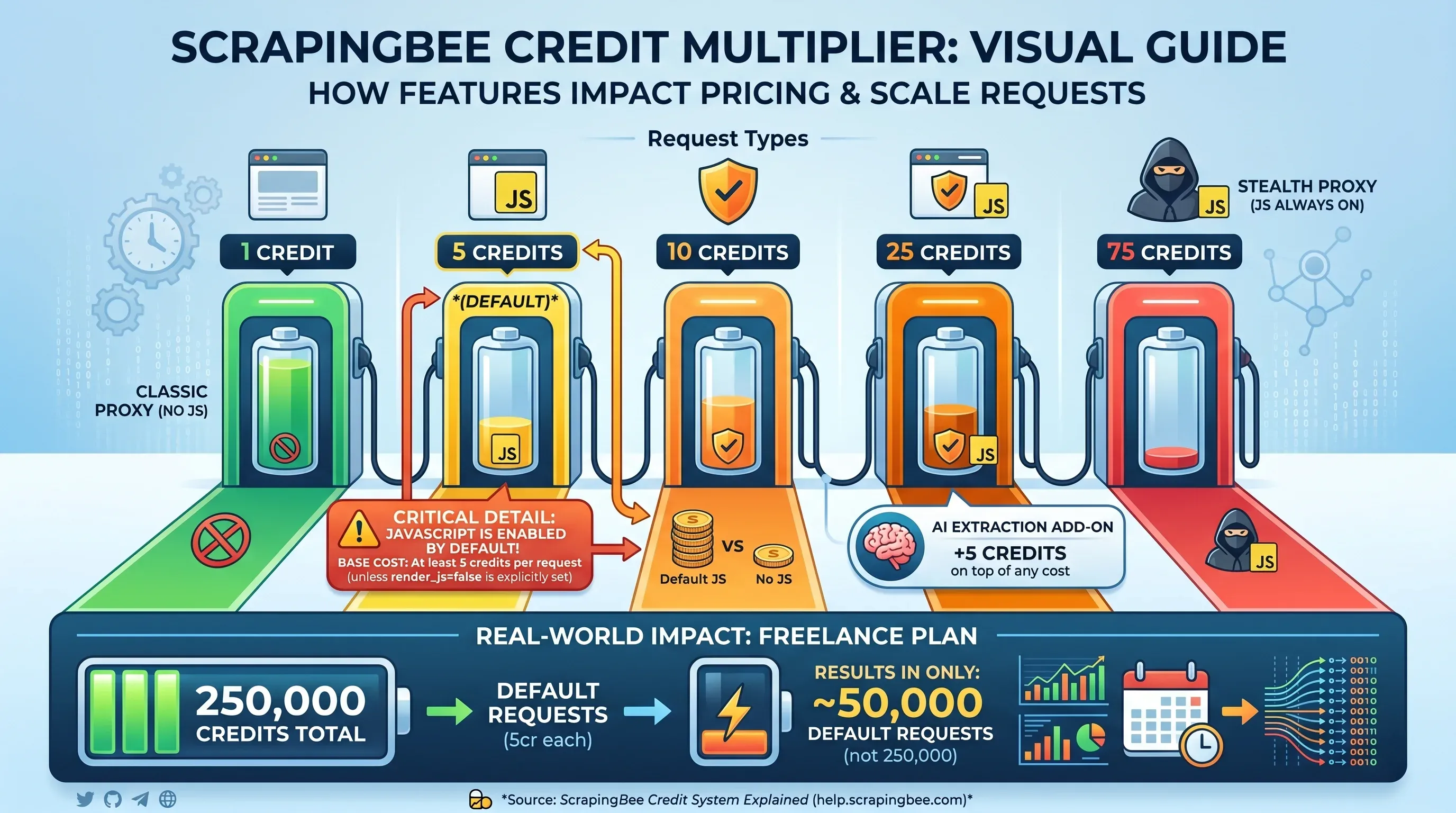
La tabella del moltiplicatore dei crediti
Qui la tariffazione di ScrapingBee inizia a farsi complicata. Il numero di crediti che vedi non corrisponde al numero di pagine che puoi estrarre: dipende dalle funzionalità che attivi per ogni richiesta.
| Tipo di richiesta | Crediti per richiesta |
|---|---|
Proxy classico, senza rendering JS (render_js=false) | 1 credito |
| Proxy classico, rendering JS (predefinito) | 5 crediti |
| Proxy premium, senza rendering JS | 10 crediti |
| Proxy premium, rendering JS | 25 crediti |
| Proxy stealth (JS sempre attivo) | 75 crediti |
| Add-on per estrazione AI | +5 crediti extra |
Dettaglio critico: il rendering JavaScript è . Se non imposti in modo esplicito render_js=false, ogni richiesta costa almeno 5 crediti. Questo vuol dire che i 250.000 crediti del piano Freelance coprono in realtà solo 50.000 richieste standard — non 250.000.
La matematica nascosta dei crediti che nessuno ti mostra
Ecco quanto costa davvero ScrapingBee per 10.000 pagine in diversi scenari e livelli di piano:
| Scenario | Crediti necessari | Freelance ($49/250K) | Startup ($99/1M) | Business ($249/3M) |
|---|---|---|---|---|
| 10K pagine (HTML statico, 1 cr) | 10.000 | ✅ Coperto ($0,20/1K) | ✅ Coperto ($0,10/1K) | ✅ Coperto ($0,08/1K) |
| 10K pagine (render JS, 5 cr) | 50.000 | ✅ Coperto ($0,98/1K) | ✅ Coperto ($0,50/1K) | ✅ Coperto ($0,42/1K) |
| 10K pagine (proxy premium + JS, 25 cr) | 250.000 | ⚠️ Esattamente al limite ($4,90/1K) | ✅ Coperto ($2,48/1K) | ✅ Coperto ($2,08/1K) |
| 10K pagine (proxy stealth, 75 cr) | 750.000 | ❌ Oltre il limite | ✅ Appena coperto ($7,43/1K) | ✅ Coperto ($6,23/1K) |
Le stesse 10.000 pagine possono costare da $0,20 a $7,43 per mille a seconda della configurazione di proxy e rendering. E non sempre sai quale configurazione ti serve finché non provi davvero.
Scenario budget: lead generation su 10.000 pagine/mese
Un team sales che estrae 10.000 pagine aziendali al mese per fare lead generation. La maggior parte dei siti B2B moderni usa React o Vue, quindi il rendering JS è necessario:
- Crediti necessari: 50.000 (10K × 5 crediti)
- Piano Freelance ($49): lo copre con 200K crediti di margine
- Ma se i target richiedono proxy premium: 250.000 crediti — esattamente l'allocazione di un piano Freelance, senza nessun cuscinetto
- Se servono proxy stealth: 750.000 crediti — serve il piano Startup a $99/mese
Scenario budget: monitoraggio prezzi ecommerce su 100.000 pagine/mese
Un team ecommerce che monitora 100.000 pagine prodotto sui siti dei competitor:
| Configurazione | Crediti necessari | Piano richiesto | Costo mensile |
|---|---|---|---|
| HTML statico (1 cr) | 100.000 | Freelance | $49 |
| Rendering JS (5 cr) | 500.000 | Startup | $99 |
| Proxy premium + JS (25 cr) | 2.500.000 | Business | $249 |
| Proxy stealth (75 cr) | 7.500.000 | Business+ | $599 |
Lo stesso lavoro va da 49 a 599 dollari al mese. Non è un errore di arrotondamento: è una differenza di costo 12× in base alla configurazione.
"Il prezzo d'ingresso da $49 è il numero più fuorviante del mercato delle scraping API." —
"I crediti si consumano rapidamente quando si usa il rendering JavaScript o funzionalità avanzate, rendendo più difficile giustificarne l'uso per progetti piccoli o team con volumi di scraping imprevedibili." — Nick S, Manager, Computer Software,
E i crediti non utilizzati da un mese all'altro.
Come i costi di ScrapingBee si confrontano con i competitor

Usando piani di fascia media per un confronto corretto:
| Scenario (per 1K pagine) | ScrapingBee ($99/1M) | ScraperAPI ($149/1M) | Scrapfly ($100/1M) |
|---|---|---|---|
| HTML statico | $0,10 | $0,15 | $0,10 |
| Pagine renderizzate in JS | $0,50 | $1,64 | $0,60 |
| Premium + JS | $2,48 | $3,73 | $3,00 |
| Stealth/ultra premium + JS | $7,43 | $11,18 | N/D |
ScrapingBee è in genere il più economico, o comunque tra i più economici, per pagine statiche e renderizzate in JS. è costantemente il più caro — il rendering JS costa +10 crediti contro i +5 di ScrapingBee e Scrapfly. Però un test indipendente di racconta una storia diversa quando entrano in gioco la complessità reale dei siti:
| Servizio | Costo medio per 1K richieste | Tasso di successo | Tempo medio di risposta |
|---|---|---|---|
| Scrape.do | $0,80 | 98,19% | 4,7s |
| ScrapingBee | $3,90 | 92,69% | 11,7s |
| Scrapfly | $4,11 | — | — |
| ZenRows | $4,48 | 92,64% | 10,0s |
| ScraperAPI | $8,49 | 92,70% | 15,7s |
Il modello crediti di Thunderbit: un approccio diverso
usa un modello di pricing molto più semplice: 1 credito = 1 riga di output, senza moltiplicatori per rendering JS, tipo di proxy o dominio target. Lo scraping delle subpage costa 2 crediti per riga.
| Piano | Prezzo mensile | Crediti | Costo per riga |
|---|---|---|---|
| Free | $0 | 6 pagine/mese | Gratis |
| Starter | $15 | 500 | $0,030 |
| Pro 1 | $38 | 3.000 | $0,013 |
| Pro 2 | $75 | 6.000 | $0,013 |
| Pro 3 | $125 | 10.000 | $0,013 |
| Pro 4 | $249 | 20.000 | $0,012 |
Un utente Thunderbit che estrae 10.000 schede prodotto da siti ecommerce pesanti in JS paga $125/mese indipendentemente dal fatto che quei siti richiedano rendering JavaScript, proxy premium o bypass anti-bot. Con ScrapingBee, lo stesso lavoro potrebbe costare da $49 a $599 a seconda della configurazione. La prevedibilità del budget conta davvero.
Selector CSS contro estrazione AI: il costo di manutenzione che devi conoscere
La maggior parte delle recensioni di ScrapingBee salta completamente questo punto. Ed è probabilmente la cosa più importante per chiunque voglia fare scraping su larga scala per mesi o anni.
ScrapingBee usa selector CSS/XPath per estrarre i dati dall'HTML. Definisci le regole di estrazione come oggetti JSON che specificano i selector CSS, e ScrapingBee ti restituisce i dati corrispondenti. All'inizio funziona bene. Il problema arriva dopo.
Il problema della rottura dei selector
Quando un sito target cambia layout — classi, struttura DOM, versione del framework — i tuoi selector CSS si rompono. Nei sistemi di scraping maturi che operano su oltre 2.500 job attivi, le ricerche mostrano un , con la necessità di 30–35 correzioni a settimana solo per tenere vivi gli extractor. Per le organizzazioni che estraggono da 50 siti, la manutenzione annuale arriva a 850–1.300 ore, con un costo di $64.000–$156.000 ai tassi pienamente caricati degli ingegneri.
I team sottostimano regolarmente questa voce. Le stime iniziali parlano in genere di 10–15 ore di manutenzione al mese, ma la realtà effettiva è (40–90 ore/mese). Un singolo guasto silenzioso — quando un selector si rompe ma continua a restituire dati vuoti senza avvisare nessuno — costa in media tra $38.000 e $57.000 in vendite perse, recupero del ranking e tempo del personale.
Cause comuni: rinomina delle classi CSS durante gli aggiornamenti del framework, nuovi contenitori inseriti attorno agli elementi target, upgrade di versione di React/Vue/Angular che ristrutturano il DOM, A/B test con classi dinamiche e offuscamento anti-scraping.
L'estrazione AI riduce la manutenzione del 60–80%
Uno studio DataRobot del 2025 ha rilevato che gli scraper con AI richiedono rispetto agli scraper tradizionali basati su selector dopo il redesign dei siti. La distribuzione del tempo si ribalta di fatto:
| Metrica | Tradizionale (selector CSS) | Basato su AI |
|---|---|---|
| Manutenzione dopo i redesign | Baseline | 70% in meno |
| Suddivisione del tempo (setup : manutenzione) | 20% : 80% | 5% : 95% usando i dati |
| Riduzione complessiva della manutenzione | Baseline | riduzione del 60–80% |
| Velocità su pagine pesanti in JS | Baseline | 30–40% più veloce |
Tempo di setup: scrivere selector vs campi suggeriti dall'AI
Setup con ScrapingBee: ispeziona il sorgente della pagina → identifica i selector CSS → scrivi le regole di estrazione in JSON → testa e fai debug → gestisci i casi limite per varianti della pagina → monitora eventuali rotture → correggi i selector quando il sito si aggiorna.
Setup con Thunderbit: apri la pagina in Chrome → clicca su "AI Suggest Fields" → l'AI legge la pagina e propone le colonne con i relativi tipi di dato → clicca su "Scrape". Niente scrittura di selector, niente ispezione del codice sorgente. L'AI di Thunderbit è alimentata da più foundation model (ChatGPT, Gemini, Claude, DeepSeek R1) che leggono le pagine web un po' come farebbe una persona.
I di Thunderbit aggiungono un livello in più: ogni colonna può avere un'istruzione AI personalizzata che trasforma i dati mentre li estrai — formattare date, tradurre testi, categorizzare prodotti, dividere nomi, normalizzare numeri di telefono. Così salti un passaggio separato di post-processing che gli utenti ScrapingBee devono costruire da soli.
Output strutturato: HTML grezzo vs righe pronte all'uso
| Dimensione | ScrapingBee (basato su selector) | Thunderbit (basato su AI) |
|---|---|---|
| Output predefinito | HTML grezzo | Righe strutturate con colonne tipizzate |
| Estrazione strutturata | Richiede regole CSS/XPath o add-on AI (+5 crediti) | L'AI rileva automaticamente i campi |
| Tipi di dato supportati | Testo (serve parsing HTML) | Testo, numero, data, URL, email, telefono, immagine |
| Resilienza ai cambi di layout | ⚠️ Servono aggiornamenti manuali dei selector | ✅ L'AI rilegge la pagina da zero ogni volta |
| Competenza tecnica richiesta | Python/cURL, selector CSS, comprensione di HTML | Nessuna — estensione Chrome con workflow in 2 clic |
| Manutenzione nel tempo | Continua (tasso di rottura dell'1–2% settimanale) | Minima (l'AI si adatta automaticamente) |
ScrapingBee ha aggiunto funzioni di estrazione AI (ai_query, ai_extract_rules) che affrontano in parte il problema della manutenzione dei selector. Ma queste aggiungono +5 crediti per richiesta oltre al costo base, e lo strumento resta sostanzialmente API-first, senza interfaccia visuale.
ScrapingBee per chi non sviluppa: una valutazione onesta dell'usabilità
ScrapingBee non è pensato per utenti non tecnici. È un'API. La usi scrivendo codice. Se sei un marketing manager o un responsabile sales ops, questo è già tutto il discorso.
Ecco cosa deve affrontare davvero un utente non tecnico con ScrapingBee:
- Scrivere una chiamata API in Python, cURL o un altro linguaggio
- Capire i parametri HTTP come
render_js=true,premium_proxy=true,country_code=us - Analizzare risposte HTML grezze con una libreria come BeautifulSoup
- Scrivere selector CSS per estrarre campi dati specifici
- Gestire la paginazione scrivendo logica di crawling personalizzata (ScrapingBee gestisce solo richieste a singola pagina)
- Creare una pipeline dati per pulire, strutturare e salvare i dati estratti
Non c'è un builder drag-and-drop. Nessuna interfaccia point-and-click. Nessuna anteprima visuale di ciò che stai estraendo.
"C'è una curva di apprendimento. E la documentazione è corposa, serve da un giorno a una settimana per leggerla tutta." — Arvind K, Proprietor, Financial Services,
"Il loro sistema è molto particolare e ci vuole un po' per imparare i loro codici e la loro struttura." —
Gli sviluppatori apprezzano molto questo approccio. Un recensore l'ha definito "completamente basato su API: molto moderno ed elegante: semplicemente funziona". Ma la "facilità d'uso" per uno sviluppatore che valuta API è una cosa molto diversa dalla "facilità d'uso" per chi sta cercando di costruire una lista lead senza scrivere codice.
Quando ha più senso un'alternativa no-code
La offre un'esperienza completamente diversa:
- Apri una pagina web in Chrome con l'estensione installata
- Clicca su "AI Suggest Fields" — l'AI analizza la pagina e propone colonne (nome prodotto, prezzo, valutazione, URL, ecc.) con i tipi di dato corretti
- Rivedi e personalizza — aggiungi, rimuovi o rinomina le colonne; aggiungi Field AI Prompts per le trasformazioni
- Clicca su "Scrape" — i dati vengono estratti in righe strutturate
- Esporta — un clic su Google Sheets, Airtable, Notion, Excel, CSV o JSON (tutte le esportazioni sono gratuite)
Niente API, niente selector, niente codice. Thunderbit supporta ad aprile 2026.
Per i siti più comuni, Thunderbit offre anche — template predefiniti e mantenuti per Amazon, Zillow, Shopify, LinkedIn, Google Maps, Instagram, eBay, Apollo e altri. Non devi nemmeno aspettare che l'AI suggerisca i campi; il template è già pronto.
In più, Thunderbit include diversi che non richiedono alcun piano: email extractor, phone number extractor e image extractor — utili per i team sales e marketing che hanno solo bisogno di estrazioni rapide.
Framework decisionale: chi dovrebbe usare cosa
| Se sei… | La scelta migliore |
|---|---|
| Uno sviluppatore a proprio agio con API e parsing HTML | ScrapingBee o ScraperAPI |
| Un utente tecnico che vuole dati strutturati senza lavorare sui selector | Thunderbit API (endpoint Extract) |
| Un utente business (sales, marketing, ecommerce ops) senza competenze di coding | Thunderbit Chrome Extension |
| Un team che ha bisogno di monitoraggio pianificato senza DevOps | Thunderbit Scheduled Scraper (pianificazione in linguaggio naturale) |
| Stai costruendo pipeline LLM/RAG e ti servono Markdown puliti | Thunderbit Distill API o Firecrawl |
| Ti interessa la prevedibilità del budget e non vuoi moltiplicatori di crediti | Thunderbit (1 credito = 1 riga) |
Dopo lo scraping: dove finiscono davvero i tuoi dati?
Lo scraping è solo metà del lavoro. L'altra metà — portare quei dati in un posto utile — è il punto su cui la maggior parte delle recensioni di ScrapingBee tace.
ScrapingBee: output HTML grezzo, pipeline da costruire tu
ScrapingBee restituisce HTML grezzo come default. Da lì devi:
- Fare il parsing dell'HTML con BeautifulSoup o lxml
- Eliminare navigazione, footer, script e style, che costituiscono
- Estrarre i campi dati specifici
- Convertire tutto in formati strutturati
- Gestire paginazione e stati di errore
- Archiviare e distribuire i dati
"ScrapingBee restituisce HTML grezzo. Gli agenti AI hanno bisogno di Markdown pulito, ricerca semantica e webhook." —
ScrapingBee offre return_page_markdown=true e return_page_text=true come alternative opzionali, e la Google Search API restituisce JSON strutturato. Ma il workflow predefinito — e l'esperienza generale di scraping general-purpose — resta HTML grezzo che devi elaborare da solo.
Di solito gli utenti hanno bisogno di strumenti aggiuntivi: BeautifulSoup/lxml per il parsing, Pandas per pulire i dati, cron/Airflow per la pianificazione, logica di crawling personalizzata per lo scraping multi-pagina e . Tra "ho estratto i dati" e "posso usarli" c'è parecchia ingegneria.
Thunderbit: output strutturato con export integrato
Thunderbit restituisce righe strutturate con tipi di dato definiti (testo, numero, data, URL, email, telefono, immagine) pronte per l'esportazione. Tutte le esportazioni sono gratuite su tutti i piani:
| Destinazione di export | Costo |
|---|---|
| Excel (.xlsx) | Gratis |
| Google Sheets | Gratis (integrazione diretta) |
| Airtable | Gratis (integrazione diretta) |
| Notion | Gratis (integrazione diretta) |
| CSV | Gratis |
| JSON | Gratis |
Per i team che già usano Google Sheets o Airtable come CRM o hub operativo, questo elimina un intero livello di lavoro ingegneristico. Quando esporti verso Notion o Airtable, le immagini vengono caricate nella libreria immagini così gli utenti possono vederle inline — un dettaglio piccolo, ma nella pratica molto utile.
L'ecosistema di integrazioni di ScrapingBee
ScrapingBee offre integrazioni di terze parti: (oltre 8.000 app), (oltre 3.000 app), n8n e Microsoft Power Automate. Queste possono colmare il divario tra HTML grezzo e i tuoi strumenti di destinazione — ma aggiungono costi, complessità e un ulteriore punto di possibile rottura.
Per gli sviluppatori: l'API aperta di Thunderbit
Per chi vuole davvero pipeline programmabili, Thunderbit offre una Open API con due endpoint chiave:
- Endpoint Distill — converte le pagine in Markdown pulito, ideale per pipeline LLM/RAG (1 credito per chiamata)
- Endpoint Extract — restituisce JSON strutturato che corrisponde a uno schema definito dall'utente (20 crediti per chiamata)
- Elaborazione batch — fino a 100 URL per richiesta
Questo vuol dire che Thunderbit copre sia gli utenti no-code (Chrome Extension) sia gli sviluppatori (Open API) con lo stesso motore AI. Non chiederti solo "sa fare scraping" — chiediti "dove vanno i dati?"
Verifica dell'affidabilità nel 2026: ScrapingBee regge in produzione?
Vecchi thread su Reddit (2021–2023) contengono lamentele sull'affidabilità di ScrapingBee. Riflettono ancora la realtà del 2026? Ho raccolto dati da sei benchmark indipendenti. I risultati sono misti — e a volte si contraddicono tra loro.
Benchmark quindicinale di Scrapeway (aprile 2026)
Totale: — 7° posto su 9 servizi testati.
| Sito | Tasso di successo |
|---|---|
| Amazon | 48% |
| 41% | |
| Indeed | 38% |
| Etsy | 21% |
| Booking | 17% |
| Realtor | 0% |
| StockX | 0% |
| Twitter/X | 0% |
| Zillow | 0% |
| Walmart | 0% |
| 0% |
Test diretto di Scrapingdog (2025)
| Sito | ScrapingBee | Scrapingdog | ScraperAPI |
|---|---|---|---|
| Amazon | 100% | 100% | 100% |
| Glassdoor | 0% | 100% | 100% |
| eBay | 100% | 100% | 100% |
| Walmart | 40% | 100% | 100% |
| 90% | 100% | 80% |
Benchmark Proxyway (dicembre 2025)
- 72,98% di successo a 10 richieste/secondo — un calo di 12 punti sotto carico
- 25,46s di tempo medio di risposta — il più lento del gruppo di benchmark
Benchmark Scrape.do (2025–2026)
- Molto forte sui singoli siti: Amazon 99,11%, Indeed 99,29%, GitHub 100%, X/Twitter 99,6%
- Debole su Capterra: solo 59% di successo con tempi di risposta di 36 secondi
Il pattern
I dati fanno emergere un pattern abbastanza chiaro:
- ScrapingBee funziona bene su siti mainstream con protezione moderata — Amazon, eBay, GitHub e Indeed mostrano in modo costante tassi di successo del 90–100%
- ScrapingBee fallisce del tutto su siti fortemente protetti — 0% costante su LinkedIn, Zillow, Realtor.com, StockX e Twitter in più benchmark
- Le prestazioni peggiorano in modo significativo sotto carico — dall'84% a 2 req/s si scende al 73% a 10 req/s
- I risultati dei benchmark variano molto in base alla metodologia — dal 33,3% (Scrapeway, mix ampio di siti) al 92,69% (Scrape.do, target moderati)
Il di ScrapingBee (137 recensioni) è un segnale positivo, ma i punteggi alti sulla facilità di setup iniziale non riflettono sempre l'affidabilità a lungo termine in produzione e su larga scala. Chi migra via da questi strumenti cita spesso l'aumento dei failure rate e dei costi — non la difficoltà iniziale di configurazione.
"Molto positivo. ScrapingBee è stato stabile, prevedibile e facile da integrare in produzione." — Verified Reviewer, CEO,
ScrapingBee ha mostrato "un'affidabilità incoerente", in particolare raggiungendo "0% di successo su Glassdoor" e "."
Come lo scraping basato su AI gestisce l'affidabilità in modo diverso
L'AI di Thunderbit legge la pagina renderizzata in tempo reale, adattandosi alle misure anti-bot e ai cambi di layout in ogni sessione. Due modalità di scraping affrontano sfide di affidabilità diverse:
- Cloud scraping — gira sui server cloud di Thunderbit, gestisce fino a 50 pagine alla volta, ideale per grandi lavori di scraping pubblico su siti come Amazon, Zillow e Shopify
- Browser scraping — gira localmente nel browser Chrome dell'utente, usando la sessione autenticata dell'utente stesso — ideale per siti con login (LinkedIn, dashboard private, piattaforme SaaS) dove strumenti API come ScrapingBee non possono accedere ai contenuti dietro autenticazione
Thunderbit offre anche per siti popolari, già pronti e mantenuti, così continuano a funzionare anche quando la struttura dei siti cambia. Nei siti in cui ScrapingBee mostra 0% di successo (LinkedIn, Zillow), la modalità browser scraping di Thunderbit — usando la tua sessione già loggata — è un approccio proprio diverso alla base.
ScrapingBee vs principali alternative: confronto affiancato
| Dimensione | ScrapingBee | Thunderbit | ScraperAPI | Scrapfly |
|---|---|---|---|---|
| Tipo | Solo API | Chrome Extension + API | Solo API | Solo API |
| Prezzo iniziale | $49/mese | Gratis ($0) | $49/mese | $30/mese |
| Modello crediti | Moltiplicatori (1×–75×) | 1 credito = 1 riga (nessun moltiplicatore) | Moltiplicatori (1×–75×) | Moltiplicatori (1×–30×) |
| Estrazione AI | Sì (+5 crediti/richiesta) | Integrata (AI Suggest Fields) | Nessuna AI nativa | Sì |
| Opzione no-code | No (solo API) | Sì (Chrome Extension) | No (solo API) | No (solo API) |
| Output strutturato | Richiede regole CSS o add-on AI | Predefinito (colonne tipizzate) | Endpoint strutturati per siti specifici | Variabile |
| Destinazioni di export | HTML/JSON grezzo (da costruire) | Excel, Sheets, Airtable, Notion, CSV, JSON (tutto gratis) | HTML/JSON grezzo | HTML/JSON grezzo |
| Scraping delle subpage | Manuale (scrivi la logica di crawling) | Integrato (2 crediti/riga) | Manuale | Manuale |
| Scraping pianificato | Solo CLI (nessun scheduler nella dashboard) | Integrato (linguaggio naturale) | Non integrato | Non integrato |
| Free tier | Prova da 1.000 crediti | 6 pagine/mese (per sempre) | 5.000 crediti (prova di 7 giorni) | 1.000 crediti |
| Rendering JS di default | ON (costo 5×) | Incluso (senza costi extra) | OFF | OFF |
| Curva di apprendimento | Alta (API + selector) | Bassa (workflow in 2 clic) | Alta (API + selector) | Alta (API) |
| Ideale per | Dev che vogliono controllo sui proxy | Utenti business + sviluppatori | Dev + endpoint strutturati | Dev che vogliono bypass ASP |
| Rating Capterra | 4,9/5 (137 recensioni) | — | 4,6/5 (62 recensioni) | 4,9/5 (221 recensioni) |
ScrapingBee vs Thunderbit: differenze chiave
Le differenze davvero importanti riguardano architettura e pubblico:
- Solo API vs Chrome Extension + API: ScrapingBee richiede codice per ogni interazione. Thunderbit offre una per gli utenti no-code e una Open API per gli sviluppatori — stesso motore AI, due interfacce.
- Estrazione basata su selector vs AI: ScrapingBee richiede di scrivere e mantenere selector CSS/XPath. L'AI di Thunderbit suggerisce automaticamente i campi e si adatta quando i siti cambiano.
- Output HTML grezzo vs righe strutturate con export gratuito: ScrapingBee restituisce HTML che devi parsare. Thunderbit restituisce righe tipizzate e etichettate che puoi con un clic.
- Scraping delle subpage: l'AI di Thunderbit visita ogni pagina di dettaglio e arricchisce la tabella principale — integrato, senza logica di crawling personalizzata. ScrapingBee richiede che tu scriva quella logica.
- Template istantanei: Thunderbit ha template predefiniti per siti popolari (Amazon, Zillow, Shopify, LinkedIn, Google Maps, eBay) che funzionano subito. ScrapingBee ha API dedicate per Amazon e Walmart, ma devi comunque scrivere codice per usarle.
Altre alternative degne di nota
- — costo indipendente più basso a $0,80/1K richieste con tasso di successo del 98,19%; parte da $29/mese
- Apify — piattaforma basata su actor con oltre 415 recensioni G2 (4,7/5), ma le "Pricing Issues" sono la lamentela numero 1
- — AI/LLM-native, restituisce Markdown con il 67% di token in meno rispetto all'HTML grezzo; core open-source; parte da $16/mese
- — livello enterprise con oltre 72M di IP, parte da $499/mese; pricing flat-rate
- ZenRows — 55M IP residential, scraper predefiniti per Amazon/Walmart/Zillow, parte da $69/mese
Qual è lo strumento di scraping giusto per il tuo team?
Raccomandazioni in base al caso d'uso:
- Se sei uno sviluppatore che costruisce una pipeline di scraping personalizzata e vuoi un controllo granulare sui proxy → ScrapingBee o ScraperAPI. Avrai parametri HTTP molto dettagliati, selezione del tipo di proxy e controllo completo sul rendering. Però metti in budget i moltiplicatori di crediti.
- Se sei un team sales o marketing che ha bisogno di lead dai siti web senza scrivere codice → . Due clic per ottenere dati strutturati, un clic per mandarli su Google Sheets. Niente API, niente selector, niente parsing.
- Se ti servono dati strutturati dai siti più diffusi e devi fare in fretta → Thunderbit Instant Templates. Amazon, Zillow, Shopify, LinkedIn — già pronti e mantenuti, senza configurazione AI.
- Se devi monitorare prezzi o stock a intervalli regolari senza DevOps → Thunderbit Scheduled Scraper. Descrivi l'intervallo in linguaggio naturale ("ogni lunedì alle 9:00") e lascialo girare.
- Se stai costruendo pipeline LLM/RAG e ti servono Markdown puliti su larga scala → Thunderbit Distill API o Firecrawl. Entrambi restituiscono Markdown ottimizzato per il consumo da parte dell'AI.
- Se per te conta la prevedibilità del budget e non vuoi moltiplicatori di crediti → Thunderbit. 1 credito = 1 riga, indipendentemente da rendering JS o tipo di proxy.
Il costo totale di possesso non è solo il prezzo dell'API. È tempo di setup + ore di manutenzione + lavoro di parsing + workflow di esportazione dei dati. Il prezzo di listino di ScrapingBee è competitivo; la visione completa dei costi, molto meno.
Punti chiave di questa recensione di ScrapingBee
Cinque conclusioni da tenere a mente:
- I costi in crediti salgono in fretta su larga scala. Il prezzo d'ingresso da $49 può arrivare a $599+ quando servono rendering JS e proxy premium. Il modello flat di Thunderbit, 1 credito per riga, elimina questa imprevedibilità.
- I selector CSS hanno un costo di manutenzione continuo che l'estrazione AI evita. Aspettati con strumenti AI e nessuna rottura dei selector quando i siti si aggiornano.
- Chi non sviluppa si trova davanti una curva di apprendimento ripida con ScrapingBee. È uno strumento solo API che richiede codice, ispezione HTML e costruzione di selector. Gli utenti business dovrebbero guardare alternative no-code.
- L'esportazione dei dati richiede ingegneria personalizzata. ScrapingBee restituisce HTML grezzo; la pipeline la costruisci tu. Thunderbit esporta dati strutturati su gratuitamente.
- L'affidabilità è solida per alcuni siti ma incoerente per altri. ScrapingBee funziona bene su Amazon ed eBay ma mostra 0% su LinkedIn, Zillow e altri target fortemente protetti.
ScrapingBee resta uno strumento valido per gli sviluppatori che vogliono accesso HTTP con proxy gestiti e controllo granulare. Ma il panorama del web scraping nel 2026 si sta spostando verso strumenti AI e no-code — e è costruito proprio per questo cambio di passo. Prova il piano gratuito (6 pagine gratis, o di più con la trial) per vedere con i tuoi occhi la differenza.
FAQ
ScrapingBee vale la pena nel 2026?
Dipende dalle tue competenze tecniche e dalla scala. Per gli sviluppatori che estraggono pagine statiche con volumi moderati, ScrapingBee offre un'API solida e ben documentata, supporto reattivo e un . Per utenti business, scraping ad alto volume o team che vogliono dati strutturati senza codice, alternative AI come Thunderbit offrono più valore e un costo totale di possesso nettamente più basso.
ScrapingBee funziona senza programmare?
No. ScrapingBee è uno strumento solo API che richiede di scrivere codice (Python, cURL o simili) e di capire i parametri HTTP. Non esiste un'interfaccia visuale per creare scraping. Gli utenti non tecnici dovrebbero prendere in considerazione opzioni no-code come la , che permette di estrarre ed esportare dati senza scrivere una sola riga di codice.
Quanto costa davvero ScrapingBee per pagina?
Dipende dalle funzionalità attivate. Una pagina HTML statica costa 1 credito. Una pagina renderizzata in JS (il default) costa . Una pagina con proxy premium + JS costa 25 crediti. Una pagina con proxy stealth costa 75 crediti. L'estrazione AI aggiunge +5 crediti extra. Sul piano Freelance ($49/250K crediti), questo equivale a $0,20 per 1.000 pagine statiche o $14,70 per 1.000 pagine con proxy stealth. Vedi le tabelle dettagliate sopra per la ripartizione completa.
Quali sono le migliori alternative a ScrapingBee nel 2026?
Le principali alternative includono (AI-powered, Chrome Extension no-code + API, 1 credito = 1 riga), (API per sviluppatori con endpoint strutturati per siti specifici), (API per sviluppatori con forte bypass anti-bot), (il costo più basso per richiesta nei test indipendenti) e (AI/LLM-native, restituisce Markdown pulito). Ognuno ha il suo punto forte: Thunderbit per utenti business e prevedibilità del budget, ScraperAPI e Scrapfly per il controllo dei proxy da parte degli sviluppatori, Firecrawl per le pipeline LLM.
ScrapingBee può fare scraping di siti pesanti in JavaScript?
Sì, ma costa 5× i crediti base con un proxy rotante o 25× con un proxy premium. Il rendering JavaScript è , quindi stai già pagando il tasso 5× a meno che tu non lo disattivi esplicitamente. Thunderbit gestisce automaticamente il rendering JS senza moltiplicatori di crediti — 1 credito per riga, indipendentemente da come è costruita la pagina.
Scopri di più