Il web non è più quello di una volta. Oggi quasi ogni sito che visiti è alimentato da JavaScript e carica i contenuti al volo — pensa allo scroll infinito, ai pop-up e alle dashboard che svelano i loro segreti solo dopo uno o due clic. In effetti, un impressionante , il che significa che i vecchi strumenti di scraping che leggono solo HTML statico si perdono una quantità enorme di dati preziosi. Se hai mai provato a estrarre i prezzi dei prodotti da un moderno sito e-commerce o a raccogliere annunci immobiliari da una mappa interattiva, conosci bene la frustrazione: i dati che ti servono semplicemente non sono presenti nel codice sorgente.
È qui che entra in gioco lo scraping con Selenium. Da persona che ha passato anni a costruire strumenti di automazione (e sì, a fare scraping di più siti di quanto sia educato ammettere), posso dirti che padroneggiare Selenium è una vera superpotenza per chiunque abbia bisogno di dati dinamici e aggiornati. In questo tutorial pratico sul web scraping con Selenium, ti guiderò attraverso i passaggi chiave — dalla configurazione all’automazione — e ti mostrerò come combinare Selenium con per ottenere dati strutturati, pronti da esportare. Che tu sia un business analyst, un professionista sales o semplicemente un utente Python curioso, ne uscirai con competenze concrete e qualche sorriso (perché, diciamocelo, fare debug di selettori XPath forma il carattere).
Che cos’è Selenium e perché usarlo per il web scraping?
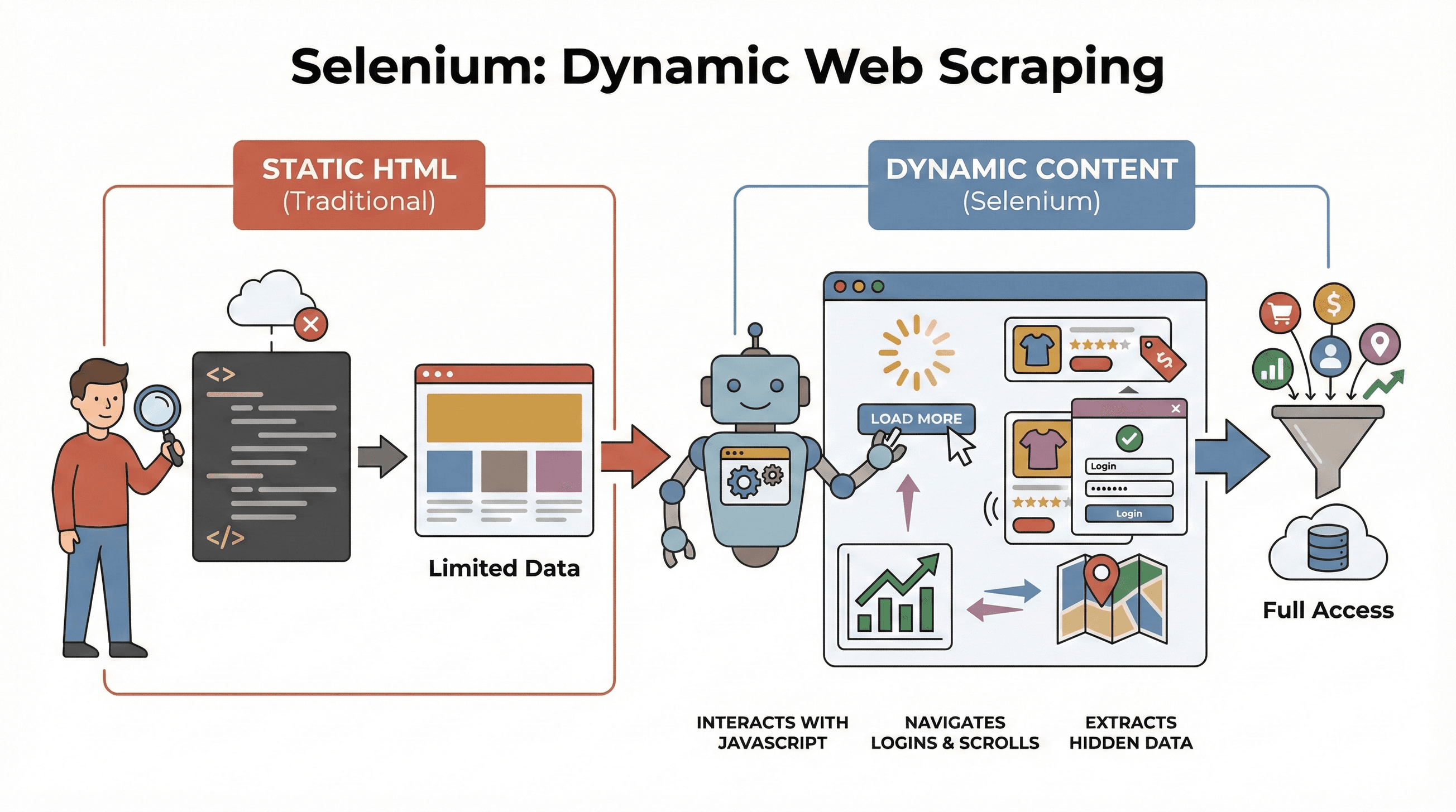 Partiamo dalle basi. è un framework open source che ti permette di controllare un vero browser web — come Chrome o Firefox — tramite codice. Pensalo come un robot capace di aprire pagine, cliccare pulsanti, compilare moduli, scorrere la pagina e persino eseguire JavaScript, proprio come farebbe un utente umano. È un aspetto fondamentale, perché la maggior parte dei siti moderni non mostra tutti i dati subito. Al contrario, carica i contenuti in modo dinamico, spesso dopo che interagisci con la pagina.
Partiamo dalle basi. è un framework open source che ti permette di controllare un vero browser web — come Chrome o Firefox — tramite codice. Pensalo come un robot capace di aprire pagine, cliccare pulsanti, compilare moduli, scorrere la pagina e persino eseguire JavaScript, proprio come farebbe un utente umano. È un aspetto fondamentale, perché la maggior parte dei siti moderni non mostra tutti i dati subito. Al contrario, carica i contenuti in modo dinamico, spesso dopo che interagisci con la pagina.
Perché è importante nello scraping? Strumenti tradizionali come BeautifulSoup o Scrapy sono ottimi per l’HTML statico, ma non riescono a “vedere” nulla che venga caricato da JavaScript dopo il caricamento iniziale della pagina. Selenium, invece, può interagire con la pagina in tempo reale, il che lo rende perfetto per:
- Estrarre elenchi di prodotti che compaiono solo dopo aver cliccato su “Carica altro”
- Prelevare prezzi o recensioni che si aggiornano dinamicamente
- Navigare tra moduli di accesso, pop-up o scroll infinito
- Estrarre dati da dashboard, mappe o altri elementi interattivi
In breve, Selenium è lo strumento ideale quando devi estrarre dati che compaiono solo dopo il caricamento della pagina — o dopo un’azione dell’utente.
Passaggi chiave per il web scraping con Python e Selenium
Fare scraping con Selenium si riduce a tre passaggi essenziali:
| Passaggio | Cosa fai | Perché è importante |
|---|---|---|
| 1. Configurazione dell’ambiente | Installa Selenium, WebDriver e le librerie Python | Prepara gli strumenti ed evita problemi di configurazione |
| 2. Individuazione degli elementi | Trova i dati che ti servono usando ID, classi, XPath, ecc. | Punta alle informazioni giuste, anche se sono nascoste da JavaScript |
| 3. Estrazione e salvataggio dei dati | Estrai testo, link o tabelle e salva in CSV/Excel | Trasforma i dati web grezzi in qualcosa che puoi usare |
Vediamo ciascun passaggio con esempi pratici e codice che puoi copiare, modificare e mostrare con orgoglio ai tuoi amici.
Passaggio 1: configurare l’ambiente Python per Selenium
Prima di tutto: devi installare Selenium e un driver del browser (come ChromeDriver per Chrome). La buona notizia? Oggi è più semplice che mai.
Installa Selenium
Apri il terminale ed esegui:
1pip install seleniumOttieni un WebDriver
- Chrome: scarica (assicurati che sia compatibile con la tua versione di Chrome).
- Firefox: scarica .
Suggerimento da professionista: con Selenium 4.6+, puoi usare Selenium Manager per scaricare automaticamente i driver, quindi forse non dovrai nemmeno più occuparti delle variabili PATH ().
Il tuo primo script Selenium
Ecco un rapido “hello world” per Selenium:
1from selenium import webdriver
2driver = webdriver.Chrome() # Oppure webdriver.Firefox()
3driver.get("https://example.com")
4print(driver.title)
5driver.quit()Suggerimenti per la risoluzione dei problemi:
- Se ricevi un errore “driver not found”, controlla il PATH oppure usa Selenium Manager.
- Assicurati che le versioni di browser e driver coincidano.
- Se usi un server headless (senza GUI), vedi i suggerimenti sulla modalità headless più sotto.
Passaggio 2: individuare gli elementi web per estrarre i dati
Ora arriva la parte divertente: indicare a Selenium quali dati ti servono. I siti web sono costruiti con elementi — div, span, tabelle, tutto quello che vuoi — e Selenium ti offre diversi modi per trovarli.
Strategie di localizzazione comuni
By.ID: trova un elemento con un ID univocoBy.CLASS_NAME: trova elementi per classe CSSBy.XPATH: usa espressioni XPath (molto flessibili, ma possono essere fragili)By.CSS_SELECTOR: usa selettori CSS (ottimi per query complesse)
Ecco come potresti usarli:
1from selenium.webdriver.common.by import By
2# Trova per ID
3price = driver.find_element(By.ID, "price").text
4# Trova per XPath
5title = driver.find_element(By.XPATH, "//h1").text
6# Trova tutte le immagini dei prodotti con un selettore CSS
7images = driver.find_elements(By.CSS_SELECTOR, ".product img")
8for img in images:
9 print(img.get_attribute("src"))Suggerimento da professionista: usa sempre il selettore più semplice e stabile possibile (ID > classe > CSS > XPath). E se stai facendo scraping di una pagina che carica i dati con ritardo, usa attese esplicite:
1from selenium.webdriver.support.ui import WebDriverWait
2from selenium.webdriver.support import expected_conditions as EC
3wait = WebDriverWait(driver, 10)
4price_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".price")))Così lo script non va in crash se i dati impiegano un secondo a comparire.
Passaggio 3: estrarre e salvare i dati
Una volta trovati gli elementi, è il momento di prendere i dati e salvarli in un formato utile.
Estrarre testo, link e tabelle
Supponiamo che tu stia estraendo una tabella di prodotti:
1data = []
2rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
3for row in rows:
4 cells = row.find_elements(By.TAG_NAME, "td")
5 data.append([cell.text for cell in cells])Salvare in CSV con Pandas
1import pandas as pd
2df = pd.DataFrame(data, columns=["Nome", "Prezzo", "Disponibilità"])
3df.to_csv("products.csv", index=False)Puoi anche salvare in Excel (df.to_excel("products.xlsx")) o persino inviare i dati a Google Sheets tramite la loro API.
Esempio completo: estrarre titoli e prezzi dei prodotti
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3import pandas as pd
4driver = webdriver.Chrome()
5driver.get("https://example.com/products")
6data = []
7products = driver.find_elements(By.CLASS_NAME, "product-card")
8for p in products:
9 title = p.find_element(By.CLASS_NAME, "title").text
10 price = p.find_element(By.CLASS_NAME, "price").text
11 data.append([title, price])
12driver.quit()
13df = pd.DataFrame(data, columns=["Titolo", "Prezzo"])
14df.to_csv("products.csv", index=False)Selenium vs BeautifulSoup e Scrapy: cosa rende Selenium unico?
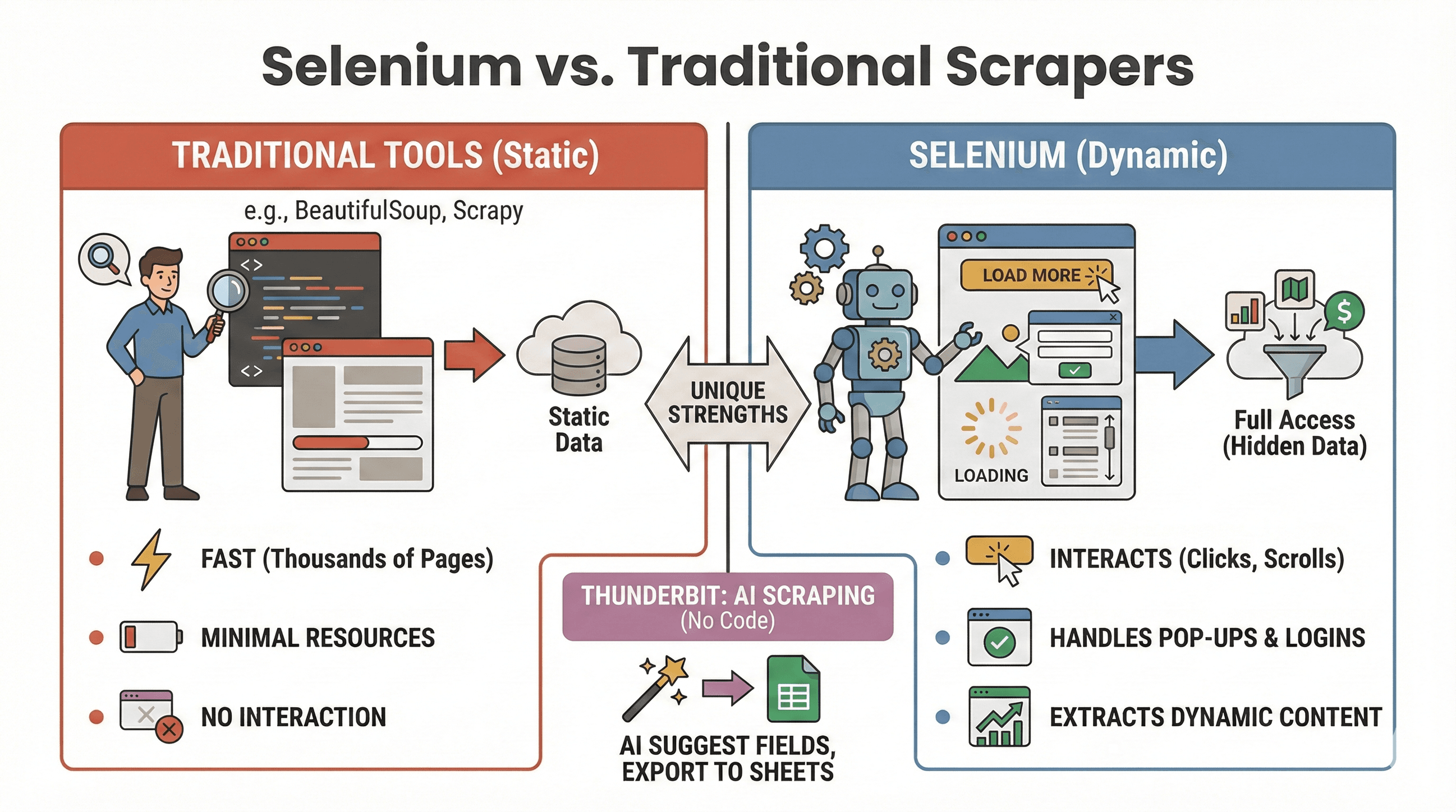 Chiariamo il dibattito: quando conviene usare Selenium e quando invece strumenti come BeautifulSoup o Scrapy sono più adatti? Ecco un confronto rapido:
Chiariamo il dibattito: quando conviene usare Selenium e quando invece strumenti come BeautifulSoup o Scrapy sono più adatti? Ecco un confronto rapido:
| Strumento | Ideale per | Gestisce JavaScript? | Velocità e uso delle risorse |
|---|---|---|---|
| Selenium | Siti dinamici/interattivi | Sì | Più lento, usa più memoria |
| BeautifulSoup | Scraping di HTML statico semplice | No | Molto veloce, leggero |
| Scrapy | Crawling di siti statici ad alto volume | Limitato* | Molto veloce, asincrono, poco RAM |
| Thunderbit | Scraping no-code per il business | Sì (AI) | Veloce per lavori piccoli/medi |
*Scrapy può gestire alcuni contenuti dinamici con plugin, ma non è il suo punto forte ().
Quando usare Selenium:
- I dati compaiono solo dopo un clic, uno scroll o un login
- Devi interagire con pop-up, scroll infinito o dashboard dinamiche
- Gli scraper statici semplicemente non bastano
Quando usare BeautifulSoup/Scrapy:
- I dati sono già presenti nell’HTML iniziale
- Devi estrarre migliaia di pagine rapidamente
- Vuoi un consumo minimo di risorse
E se vuoi evitare del tutto di scrivere codice, ti permette di estrarre siti dinamici con l’AI — basta cliccare su “AI Suggest Fields” ed esportare su Sheets, Notion o Airtable. (Ne parliamo meglio più avanti.)
Automatizzare le attività di web scraping con Selenium e Python
Diciamolo chiaramente: nessuno vuole svegliarsi alle 2 di notte per eseguire uno script di scraping. La buona notizia è che puoi automatizzare i lavori Selenium usando gli strumenti di pianificazione di Python o lo scheduler del tuo sistema operativo (come cron su Linux/Mac o Task Scheduler su Windows).
Usare la libreria schedule
1import schedule
2import time
3def job():
4 # Il tuo codice di scraping qui
5 print("Scraping...")
6schedule.every().day.at("09:00").do(job)
7while True:
8 schedule.run_pending()
9 time.sleep(1)Oppure con cron (Linux/Mac)
Aggiungi questo al tuo crontab per eseguirlo ogni ora:
10 * * * * python /path/to/your_script.pySuggerimenti per l’automazione:
- Esegui Selenium in modalità headless (vedi sotto) per evitare finestre grafiche indesiderate.
- Registra gli errori e invia avvisi quando qualcosa va storto.
- Chiudi sempre il browser con
driver.quit()per liberare risorse.
Aumentare l’efficienza: consigli per uno scraping Selenium più veloce e affidabile
Selenium è potente, ma può essere lento e consumare molte risorse se non stai attento. Ecco come accelerarlo ed evitare i problemi più comuni:
1. Esegui in modalità headless
Non c’è bisogno di vedere Chrome aprirsi e chiudersi cento volte. La modalità headless esegue il browser in background:
1from selenium.webdriver.chrome.options import Options
2opts = Options()
3opts.headless = True
4driver = webdriver.Chrome(options=opts)2. Blocca immagini e altri contenuti non necessari
Perché caricare immagini se stai estraendo solo testo? Bloccarle accelera il caricamento della pagina:
1prefs = {"profile.managed_default_content_settings.images": 2}
2opts.add_experimental_option("prefs", prefs)3. Usa selettori efficienti
- Preferisci ID o semplici selettori CSS rispetto a XPath complessi.
- Evita
time.sleep()— usa invece attese esplicite (WebDriverWait).
4. Randomizza i ritardi
Aggiungi pause casuali per imitare la navigazione umana ed evitare blocchi:
1import random, time
2time.sleep(random.uniform(1, 3))5. Ruota user agent e IP (se necessario)
Se fai molto scraping, cambia la stringa user agent e valuta l’uso di proxy per aggirare i semplici sistemi anti-bot.
6. Gestisci sessioni ed errori
- Usa blocchi try/except per gestire con grazia gli elementi mancanti.
- Registra gli errori e acquisisci screenshot per il debug.
Per altri consigli di ottimizzazione, consulta la .
Avanzato: combinare Selenium con Thunderbit per esportare dati strutturati
Qui le cose diventano davvero interessanti — soprattutto se vuoi risparmiare tempo nella pulizia dei dati e nell’esportazione.
Dopo aver estratto i dati grezzi con Selenium, puoi usare per:
- Rilevare automaticamente i campi: l’AI di Thunderbit può leggere le pagine o i CSV estratti e suggerire i nomi delle colonne (“AI Suggest Fields”).
- Scraping delle sottopagine: se hai un elenco di URL (come le pagine prodotto), Thunderbit può visitarne ognuno e arricchire la tua tabella con altri dettagli, senza codice aggiuntivo.
- Arricchimento dei dati: traduci, categorizza o analizza i dati al volo.
- Esporta ovunque: esportazione con un clic su Google Sheets, Airtable, Notion, CSV o Excel.
Esempio di workflow:
- Usa Selenium per estrarre un elenco di URL e titoli dei prodotti.
- Esporta i dati in CSV.
- Apri Thunderbit, importa il CSV e lascia che l’AI suggerisca i campi.
- Usa lo scraping delle sottopagine di Thunderbit per estrarre più dettagli (come immagini o specifiche) da ciascun URL prodotto.
- Esporta il dataset finale e strutturato su Sheets o Notion.
Questa combinazione fa risparmiare ore di pulizia manuale e ti permette di concentrarti sull’analisi, non sulla gestione di dati sporchi. Per saperne di più su questo flusso di lavoro, consulta la .
Best practice e risoluzione dei problemi per il web scraping con Selenium
Il web scraping è un po’ come pescare: a volte prendi un pesce grosso, altre volte finisci impigliato nelle alghe. Ecco come mantenere gli script affidabili — ed etici:
Best practice
- Rispetta robots.txt e i termini del sito: controlla sempre se lo scraping è consentito.
- Limita la frequenza delle richieste: non sovraccaricare i server — aggiungi ritardi e controlla gli errori HTTP 429.
- Usa le API quando disponibili: se i dati sono accessibili pubblicamente via API, usa quella strada — è più sicura e affidabile.
- Estrai solo dati pubblici: evita informazioni personali o sensibili e tieni conto delle leggi sulla privacy.
- Gestisci pop-up e CAPTCHA: usa Selenium per chiudere i pop-up, ma fai attenzione ai CAPTCHA — sono difficili da automatizzare.
- Randomizza user agent e ritardi: aiuta a evitare rilevamento e blocchi.
Errori comuni e soluzioni
| Errore | Cosa significa | Come risolvere |
|---|---|---|
NoSuchElementException | Impossibile trovare l’elemento | Ricontrolla il selettore; usa attese |
| Errori di timeout | La pagina o l’elemento hanno impiegato troppo tempo | Aumenta il tempo di attesa; controlla la velocità di rete |
| Disallineamento driver/browser | Selenium non riesce ad avviare il browser | Aggiorna le versioni di driver e browser |
| Crash della sessione | Il browser si è chiuso in modo inatteso | Usa la modalità headless; gestisci le risorse |
Per altri suggerimenti sulla risoluzione dei problemi, consulta il .
Conclusione e punti chiave
Lo scraping dinamico del web non è più solo per sviluppatori esperti. Con Python e Selenium puoi automatizzare qualsiasi browser, interagire con i siti più ostici e pieni di JavaScript e ottenere i dati di cui la tua azienda ha bisogno — che sia per le vendite, la ricerca o semplicemente per soddisfare la tua curiosità. Ricorda:
- Selenium è lo strumento ideale per siti dinamici e interattivi.
- I tre passaggi chiave: configurare, individuare, estrarre e salvare.
- Automatizza gli script per aggiornamenti regolari dei dati.
- Ottimizza velocità e affidabilità con modalità headless, attese intelligenti e selettori efficienti.
- Combina Selenium con Thunderbit per strutturare ed esportare i dati con facilità — soprattutto se vuoi evitare il mal di testa dei fogli di calcolo.
Pronto a provarci? Parti dagli esempi di codice qui sopra e, quando sarai pronto a portare lo scraping al livello successivo, prova per una pulizia ed esportazione dei dati istantanea, alimentata dall’AI. E se vuoi approfondire, visita il per guide dettagliate, tutorial e le ultime novità sull’automazione web.
Buono scraping — e che i tuoi selettori trovino sempre ciò che cerchi.
FAQ
1. Perché dovrei usare Selenium per il web scraping invece di BeautifulSoup o Scrapy?
Selenium è l’ideale per estrarre dati da siti dinamici in cui i contenuti si caricano dopo azioni dell’utente o l’esecuzione di JavaScript. BeautifulSoup e Scrapy sono più veloci per HTML statico, ma non possono interagire con elementi dinamici né simulare clic e scroll.
2. Come posso rendere più veloce il mio scraper Selenium?
Usa la modalità headless, blocca immagini e risorse non necessarie, usa selettori efficienti e aggiungi ritardi casuali per imitare la navigazione umana. Per altri suggerimenti, consulta la .
3. Posso pianificare attività di scraping con Selenium per farle partire automaticamente?
Sì! Usa la libreria schedule di Python oppure lo scheduler del sistema operativo (cron o Task Scheduler) per eseguire gli script a intervalli prestabiliti. Automatizzare lo scraping aiuta a mantenere i dati aggiornati.
4. Qual è il modo migliore per esportare i dati estratti con Selenium?
Usa Pandas per salvare i dati in CSV o Excel. Per esportazioni più avanzate (Google Sheets, Notion, Airtable), importa i dati in e usa le funzioni di esportazione con un clic.
5. Come posso gestire pop-up e CAPTCHA in Selenium?
Puoi chiudere i pop-up individuando e cliccando il relativo pulsante di chiusura. I CAPTCHA sono molto più difficili: se ne incontri uno, valuta un workaround manuale o un servizio di risoluzione CAPTCHA e rispetta sempre i termini di servizio del sito.
Vuoi vedere altri tutorial di scraping, consigli di automazione AI o le ultime novità sugli strumenti per i dati aziendali? Iscriviti al oppure visita il nostro per demo pratiche.
Scopri di più