Zillow raccoglie oltre , e riuscire a estrarre questi dati su larga scala è uno dei lavori più richiesti — e anche uno dei più frustranti — quando si lavora con i dati immobiliari. Se hai mai provato a fare scraping su Zillow e ti sei ritrovato davanti a una pagina CAPTCHA invece che ai dati degli annunci, tranquillo: non sei affatto il solo.
Ho passato parecchio tempo a studiare e testare diversi approcci per lo scraping di Zillow — sia con Python sia con gli strumenti no-code che abbiamo creato in Thunderbit. Questa guida copre entrambe le strade. Che tu stia cercando un tutorial completo in Python con strategie anti-bot, oppure ti servano solo 200 annunci in un foglio di calcolo entro l’ora di pranzo, qui troverai la sezione giusta. Vedremo perché i dati di Zillow contano, com’è costruito il sito sotto il cofano, un tutorial Python passo passo, i motivi precisi per cui gli scraper si rompono e come automatizzare estrazioni ricorrenti per monitorare i prezzi.
Perché estrarre dati da Zillow?
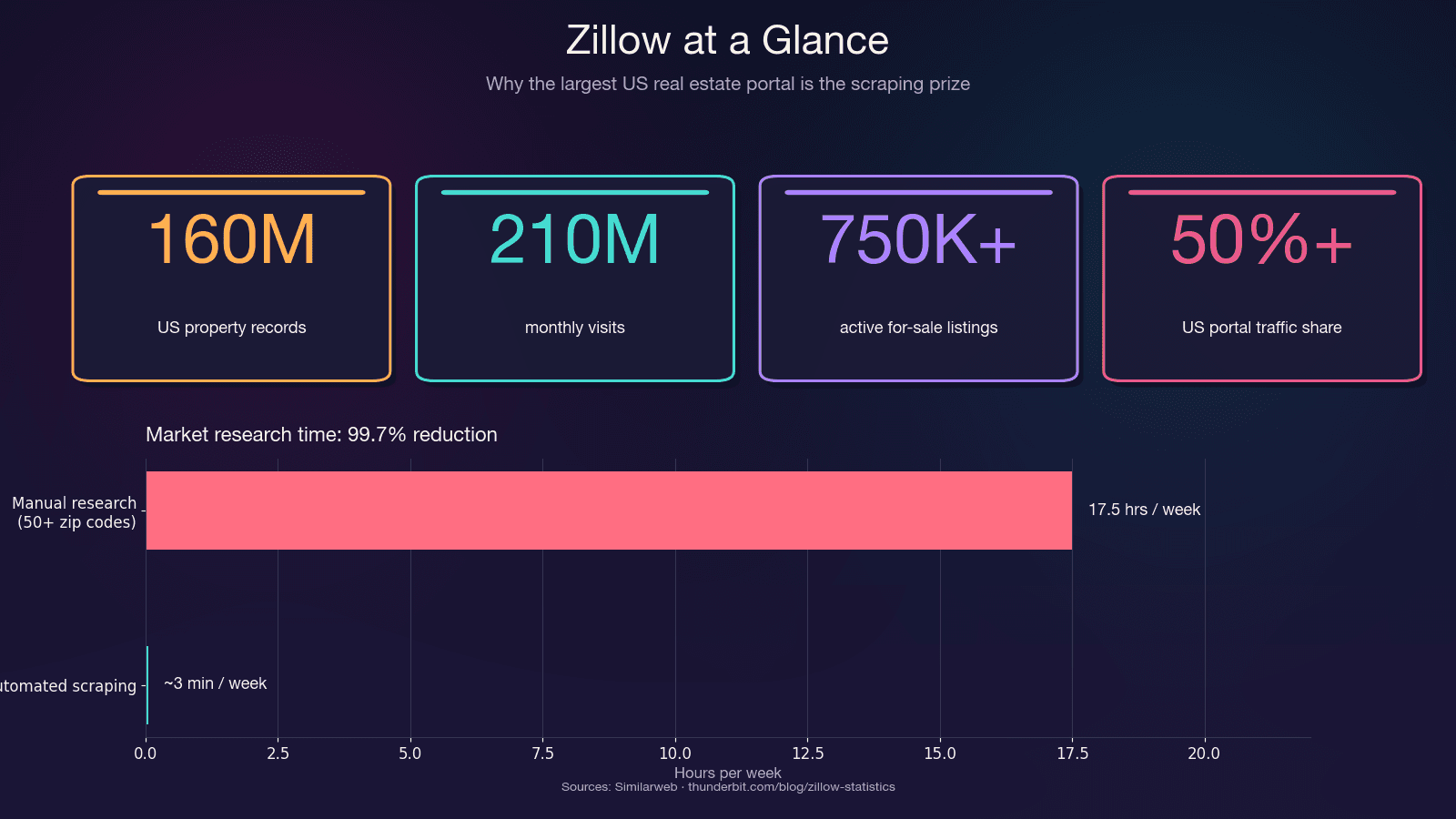
Zillow è il più grande archivio di dati immobiliari residenziali negli Stati Uniti. Riceve e ospita circa 750.000+ annunci attivi in vendita, oltre a 1,9 milioni di annunci in affitto. La piattaforma intercetta più del 50% del traffico totale dei portali immobiliari negli USA — più del doppio rispetto al concorrente più vicino.
Prima di buttarti nel codice Python, è bene sapere che fare scraping su Zillow con Python non è l’unica opzione, e scegliere il metodo sbagliato può farti perdere un sacco di tempo. Gli strumenti Python come httpx e BeautifulSoup richiedono competenze intermedie, gestione manuale di header e proxy, hanno velocità moderate (1–3 secondi per pagina) e richiedono manutenzione frequente, anche se sono gratuiti; Selenium o Playwright migliorano la gestione anti-bot renderizzando JavaScript, ma sono più lenti (5–15 secondi per pagina) e comunque impegnativi da mantenere; le scraping API come ScraperAPI o ScrapFly sono più veloci, includono supporto anti-bot e richiedono manutenzione media, ma costano da 30 a 599 dollari al mese; l’API ufficiale di Zillow tramite Bridge Interactive è veloce e richiede poca manutenzione, ma ha accesso limitato e costa circa 500 dollari al mese; infine, gli strumenti no-code come Thunderbit sono adatti ai principianti, veloci, non richiedono manutenzione grazie all’adattamento tramite AI e di solito offrono un modello freemium.
Il risparmio di tempo, da solo, è enorme. Una ricerca manuale su oltre 50 CAP può richiedere 15–20 ore a settimana. Lo scraping automatizzato fa lo stesso lavoro in pochi minuti — una riduzione del tempo speso del 99,7%.
Tutti i modi per estrarre dati da Zillow: Python, API e no-code a confronto
Prima di entrare nel codice Python, sappi che "estrarre dati da Zillow con Python" non è l’unica strada. Scegliere il metodo sbagliato fa perdere ore. Ecco un confronto affiancato per aiutarti a scegliere:
| Metodo | Livello di competenza | Gestione anti-bot | Velocità | Manutenzione | Costo |
|---|---|---|---|---|---|
| Python + httpx/BeautifulSoup | Intermedio | Manuale (header, proxy) | Media (1–3s/pagina) | Alta (i selettori si rompono) | Gratis |
| Python + Selenium/Playwright | Intermedio | Migliore (renderizza JS) | Lenta (5–15s/pagina) | Alta | Gratis |
| Scraping API (ScraperAPI, ScrapFly) | Intermedio | Integrata | Veloce | Media | $30–599/mese |
| API ufficiale di Zillow (Bridge Interactive) | Principiante–Intermedio | N/D | Veloce | Bassa | ~500$/mese, accesso limitato |
| Strumento no-code (Thunderbit) | Principiante | Integrata (l’AI si adatta) | Veloce | Nessuna (l’AI rilegge la pagina) | Freemium |
Se ti servono dati subito senza scrivere codice, inizia con Thunderbit. Se invece vuoi capire l’architettura dietro o ti serve personalizzazione completa, continua con il tutorial Python.
Il metodo più rapido: estrarre dati da Zillow con Thunderbit (senza codice)
Prima di passare in profondità a Python, ecco il percorso ideale per chi ha bisogno di dati Zillow in fretta — senza configurare Python, senza proxy, senza mantenere selettori. Abbiamo costruito questo flusso in Thunderbit proprio per ottenere dati immobiliari strutturati senza complicazioni tecniche.
Difficoltà: Principiante
Tempo necessario: ~2 minuti
Cosa ti serve: Browser Chrome, (il piano gratuito basta)
Passo 1: Installa Thunderbit e apri Zillow
Installa l’estensione Thunderbit dal Chrome Web Store. Vai su una pagina dei risultati di ricerca di Zillow — per esempio, cerca case a Houston, TX.
Passo 2: Clicca su "AI Suggest Fields"
Apri la barra laterale di Thunderbit e fai clic su "AI Suggest Fields". L’AI legge la pagina e propone in automatico le colonne: prezzo, indirizzo, camere, bagni, metratura, Zestimate, URL dell’annuncio e altro ancora. Nei miei test, di solito individua oltre 20 campi senza nessuna configurazione manuale.
Passo 3: Clicca su "Scrape"
Premi il pulsante Scrape. I dati compaiono in una tabella strutturata dentro l’estensione. Thunderbit gestisce automaticamente la paginazione di Zillow — sia quella a clic sia lo scroll infinito.
Passo 4: Arricchisci con lo scraping delle sottopagine
Vuoi dati più dettagliati, come storico fiscale, valutazioni delle scuole o storico dei prezzi? Usa "Scrape Subpages" per arricchire la tabella. Thunderbit visita ogni URL dell’annuncio e recupera i campi aggiuntivi — senza scrivere codice.
Passo 5: Esporta
Esporta in Google Sheets, Excel, Airtable o Notion. L’esportazione è gratuita.
Perché Thunderbit funziona bene con Zillow
Il vero punto di forza qui è la robustezza. L’AI di Thunderbit rilegge la struttura della pagina da zero ogni volta che esegui lo scraping. Quando Zillow cambia layout (e succede spesso), non ci sono selettori CSS fragili da correggere. L’AI si adatta da sola. Questo risolve davvero la natura "intrinsecamente fragile" degli scraper basati su codice, che manda in crisi così tanti utenti.
Quali dati puoi estrarre da Zillow? (oltre 20 campi)
La maggior parte delle guide si ferma a prezzo e indirizzo. In realtà, gli annunci Zillow contengono molti più dati estraibili di quanto si pensi — ecco una tabella di riferimento:
| Campo | Dove si trova | Difficoltà di estrazione |
|---|---|---|
| Prezzo di listino | Ricerca + dettaglio | Facile |
| Indirizzo / CAP | Ricerca + dettaglio | Facile |
| Zestimate | Ricerca + dettaglio | Facile |
| Storico dei prezzi (ogni evento) | Dettaglio | Difficile (JSON annidato) |
| Storico fiscale | Dettaglio | Difficile (JSON annidato) |
| Camere / bagni / mq | Ricerca + dettaglio | Facile |
| Anno di costruzione | Dettaglio | Facile |
| Spese HOA | Dettaglio | Medio |
| Walk Score / Transit Score | Dettaglio (iframe) | Difficile (richiede rendering JS) |
| Valutazioni delle scuole | Dettaglio | Medio |
| Dimensione del lotto | Dettaglio | Facile |
| Giorni su Zillow | Ricerca | Facile |
| Agente / agenzia | Ricerca + dettaglio | Medio |
| Numero MLS | Dettaglio | Facile |
| Tipo di immobile | Ricerca + dettaglio | Facile |
| Latitudine / longitudine | JSON __NEXT_DATA__ | Medio |
| Testo descrittivo | Dettaglio | Facile |
| URL delle foto | Ricerca + dettaglio | Medio |
| Rent Zestimate | Dettaglio | Medio |
| Vendite comparabili nelle vicinanze | Dettaglio | Difficile |
I campi "difficili" — storico dei prezzi, storico fiscale, vendite comparabili — si trovano in JSON annidati nelle pagine di dettaglio. La sezione Python qui sotto mostra esattamente come estrarli. E se preferisci saltare il codice, l’opzione AI Suggest Fields di Thunderbit rileva automaticamente la maggior parte di queste colonne, e lo scraping delle sottopagine recupera i campi delle pagine di dettaglio in automatico.
Configurare l’ambiente Python per estrarre dati da Zillow
Difficoltà: Intermedio
Tempo necessario: ~5 minuti per la configurazione, ~30 minuti per il tutorial completo
Cosa ti serve: Python 3.8+, browser Chrome (per ispezionare le pagine), un editor di testo o un IDE
Installa le librerie necessarie:
1pip install httpx beautifulsoup4 pandas lxmlEcco a cosa serve ciascuna:
- httpx — client HTTP con prestazioni migliori rispetto a
requestse supporto async - beautifulsoup4 + lxml — parsing HTML
- pandas — esportazione dei dati in CSV/Excel
- Opzionale: selenium o playwright se devi renderizzare pagine molto ricche di JavaScript
Capire la struttura delle pagine Zillow prima di fare scraping
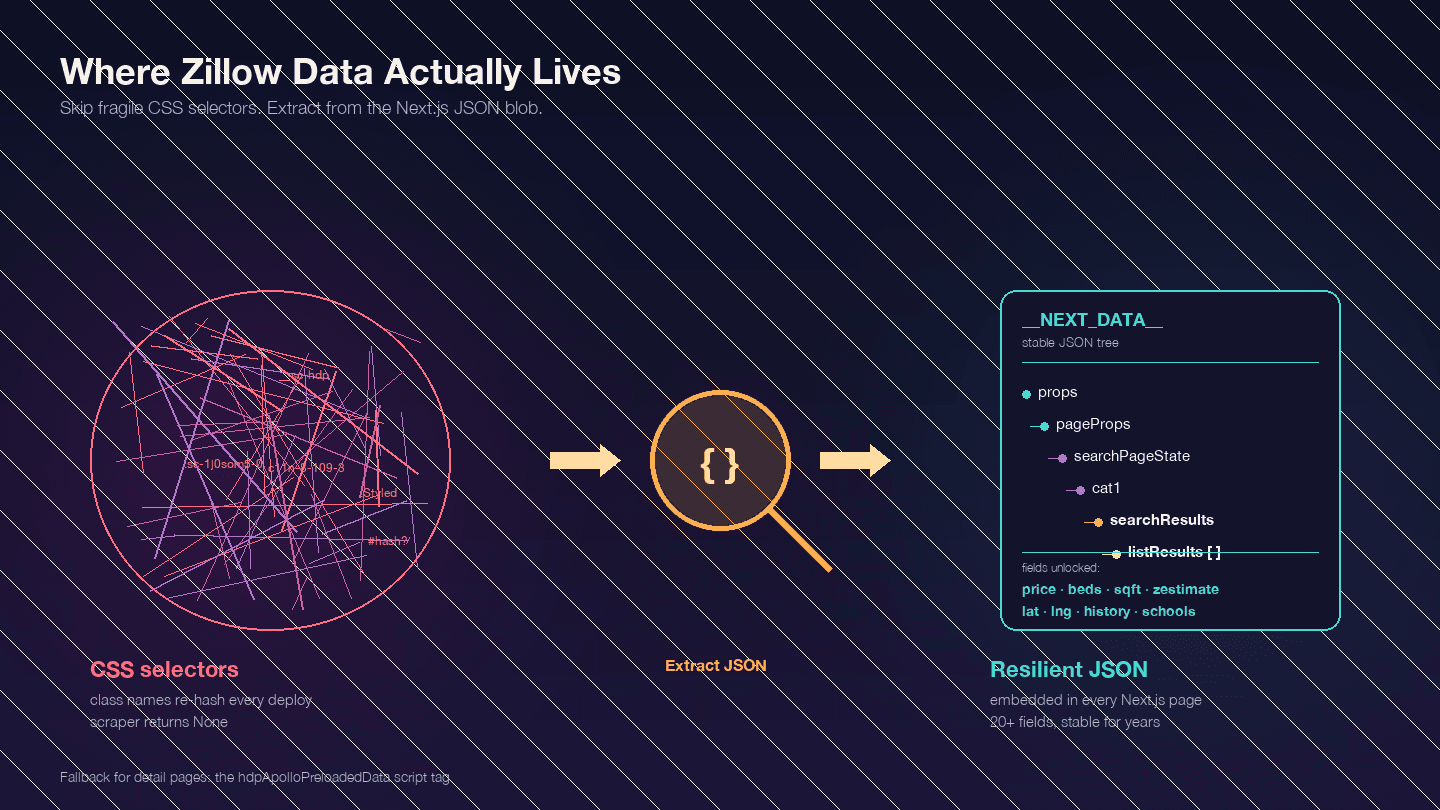
Questa è la cosa più importante da capire prima di scrivere qualsiasi codice. Zillow è una applicazione Next.js — confermato da . Questo significa che gran parte dei dati che ti servono non si trova negli elementi HTML visibili. È incorporata in un blob JSON dentro <script id="__NEXT_DATA__">.
Apri una qualsiasi pagina immobile di Zillow, premi F12, vai su Elements e cerca __NEXT_DATA__. Troverai un enorme oggetto JSON con tutti i dati dell’annuncio — prezzi, coordinate, dettagli dell’immobile, storico prezzi, dati fiscali, valutazioni scolastiche e molto altro.
Perché è importante? I nomi delle classi CSS di Zillow sono hashati (generati da styled-components) e cambiano a ogni deploy. Una classe come StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 avrà un hash completamente diverso la settimana successiva. Qualsiasi scraper basato su selettori CSS si romperà regolarmente.
L’approccio JSON __NEXT_DATA__ è molto più stabile perché non dipende affatto dalla struttura HTML.
Percorsi JSON chiave per i risultati di ricerca:
| Percorso | Contenuto |
|---|---|
props.pageProps.searchPageState.cat1.searchResults.listResults | Array dei risultati di ricerca |
props.pageProps.searchPageState.cat1.searchResults.mapResults | Risultati vista mappa |
props.pageProps.searchPageState.cat1.searchList.totalPages | Numero totale di pagine disponibili |
Per le pagine di dettaglio, alcune usano __NEXT_DATA__ e altre un tag script alternativo chiamato hdpApolloPreloadedData. Il codice qui sotto gestisce entrambi i casi.
Passo passo: come estrarre dati da Zillow con Python
Passo 1: Impostare gli header HTTP per evitare blocchi immediati
Inviare un semplice httpx.get() a Zillow restituisce una pagina CAPTCHA, non i dati degli annunci. Zillow usa PerimeterX (HUMAN Security) insieme a Cloudflare — entrambi valutati nei benchmark di scraping. Il sistema controlla fingerprint TLS, header HTTP e reputazione dell’IP.
Ecco gli header minimi che funzionano nel 2025:
1import httpx
2headers = {
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
5 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
6 "image/avif,image/webp,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
10 "Sec-Ch-Ua-Platform": '"Windows"',
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "none",
14 "Sec-Fetch-User": "?1",
15 "Upgrade-Insecure-Requests": "1",
16}Gli header Sec-Ch-Ua sono fondamentali. Molti tutorial li saltano — ed è proprio per questo che il loro codice non funziona contro PerimeterX.
Passo 2: fare scraping dei risultati di ricerca di Zillow
Gli URL di ricerca Zillow seguono un formato prevedibile. Per Houston, TX:
- Pagina 1:
https://www.zillow.com/houston-tx/ - Pagina 2:
https://www.zillow.com/houston-tx/2_p/ - Pagina 3:
https://www.zillow.com/houston-tx/3_p/
Ogni pagina contiene circa 41 annunci. Zillow limita i risultati a 20 pagine (~820 annunci). Per dataset più grandi, dovrai dividere per area geografica (ne parliamo più avanti).
Ecco il codice per estrarre i risultati di ricerca prendendo i dati dal JSON __NEXT_DATA__:
1from bs4 import BeautifulSoup
2import json
3import time
4import random
5def scrape_zillow_search(url):
6 """Estrae i dati degli annunci da una pagina di risultati Zillow."""
7 response = httpx.get(url, headers=headers, timeout=15)
8 if response.status_code != 200:
9 print(f"Status {response.status_code} ricevuto per {url}")
10 return []
11 soup = BeautifulSoup(response.text, "lxml")
12 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
13 if not script_tag:
14 print("Nessun __NEXT_DATA__ trovato — probabilmente bloccato da CAPTCHA")
15 return []
16 next_data = json.loads(script_tag.string)
17 try:
18 results = (
19 next_data["props"]["pageProps"]["searchPageState"]
20 ["cat1"]["searchResults"]["listResults"]
21 )
22 except KeyError:
23 print("Struttura JSON inattesa — Zillow potrebbe aver cambiato formato")
24 return []
25 listings = []
26 for item in results:
27 listing = {
28 "zpid": item.get("zpid"),
29 "address": item.get("addressStreet"),
30 "city": item.get("addressCity"),
31 "state": item.get("addressState"),
32 "zipcode": item.get("addressZipcode"),
33 "price": item.get("unformattedPrice") or item.get("price"),
34 "beds": item.get("beds"),
35 "baths": item.get("baths"),
36 "sqft": item.get("area"),
37 "zestimate": item.get("zestimate"),
38 "days_on_zillow": item.get("daysOnZillow"),
39 "listing_url": item.get("detailUrl"),
40 "img_src": item.get("imgSrc"),
41 "property_type": item.get("hdpData", {}).get("homeInfo", {}).get("homeType"),
42 "latitude": item.get("latLong", {}).get("latitude"),
43 "longitude": item.get("latLong", {}).get("longitude"),
44 }
45 listings.append(listing)
46 return listingsPer estrarre più pagine, usa un ciclo con pause:
1all_listings = []
2base_url = "https://www.zillow.com/houston-tx/"
3for page in range(1, 6): # Prime 5 pagine
4 url = base_url if page == 1 else f"{base_url}{page}_p/"
5 print(f"Estrazione pagina {page}...")
6 page_listings = scrape_zillow_search(url)
7 all_listings.extend(page_listings)
8 # Pausa casuale tra 3 e 7 secondi
9 delay = random.uniform(3, 7)
10 time.sleep(delay)
11print(f"Totale annunci estratti: {len(all_listings)}")Dovresti vedere i dati strutturati degli annunci accumularsi in all_listings. Se ottieni risultati vuoti, controlla la sezione "Perché gli scraper si rompono" più sotto.
Passo 3: estrarre le pagine di dettaglio degli immobili Zillow
I risultati di ricerca danno le informazioni base. Le pagine di dettaglio contengono i dati più approfonditi: storico prezzi, storico fiscale, valutazioni scolastiche, informazioni sull’agente e descrizione dell’immobile. Ogni URL ottenuto nel Passo 2 porta a una pagina di dettaglio.
Le pagine di dettaglio Zillow usano due possibili formati dati. Ecco un codice che gestisce entrambi:
1def scrape_zillow_detail(url):
2 """Estrae i dati dettagliati di un immobile da una pagina annuncio Zillow."""
3 response = httpx.get(url, headers=headers, timeout=15)
4 if response.status_code != 200:
5 return None
6 soup = BeautifulSoup(response.text, "lxml")
7 # Prova prima __NEXT_DATA__ (il caso più comune)
8 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
9 if script_tag:
10 next_data = json.loads(script_tag.string)
11 try:
12 cache_str = next_data["props"]["pageProps"]["componentProps"]["gdpClientCache"]
13 cache = json.loads(cache_str)
14 first_key = next(iter(cache))
15 prop = cache[first_key]["property"]
16 return extract_property_fields(prop)
17 except (KeyError, StopIteration):
18 pass
19 # Fallback: hdpApolloPreloadedData
20 apollo_tag = soup.find("script", {"id": "hdpApolloPreloadedData"})
21 if apollo_tag:
22 raw = json.loads(apollo_tag.string)
23 api_cache = json.loads(raw["apiCache"])
24 for key, value in api_cache.items():
25 if "ForSale" in key or "property" in str(value)[:100]:
26 prop = value.get("property", value)
27 return extract_property_fields(prop)
28 return None
29def extract_property_fields(prop):
30 """Estrae campi strutturati da un oggetto JSON di proprietà Zillow."""
31 return {
32 "zpid": prop.get("zpid"),
33 "zestimate": prop.get("zestimate"),
34 "rent_zestimate": prop.get("rentZestimate"),
35 "description": prop.get("description"),
36 "year_built": prop.get("yearBuilt"),
37 "lot_size": prop.get("lotSize"),
38 "hoa_fee": prop.get("monthlyHoaFee"),
39 "mls_id": prop.get("mlsid"),
40 "broker_name": prop.get("brokerName") or prop.get("attributionInfo", {}).get("brokerName"),
41 "price_history": [
42 {
43 "date": event.get("date"),
44 "event": event.get("event"),
45 "price": event.get("price"),
46 }
47 for event in prop.get("priceHistory", [])
48 ],
49 "tax_history": [
50 {
51 "year": record.get("time"),
52 "tax_paid": record.get("taxPaid"),
53 "value": record.get("value"),
54 }
55 for record in prop.get("taxHistory", [])
56 ],
57 "schools": [
58 {
59 "name": school.get("name"),
60 "rating": school.get("rating"),
61 "distance": school.get("distance"),
62 }
63 for school in prop.get("schools", [])
64 ],
65 }Scorri gli URL degli annunci con delle pause:
1detail_data = []
2for listing in all_listings[:10]: # Inizia con 10 per testare
3 detail_url = listing.get("listing_url")
4 if not detail_url:
5 continue
6 if not detail_url.startswith("http"):
7 detail_url = f"https://www.zillow.com{detail_url}"
8 print(f"Estrazione dettaglio: {detail_url}")
9 detail = scrape_zillow_detail(detail_url)
10 if detail:
11 detail_data.append({**listing, **detail})
12 time.sleep(random.uniform(3, 8))Dopo questo passaggio, dovresti avere una lista di dizionari che contiene sia i dati di ricerca sia quelli di dettaglio per ciascun immobile.
Passo 4: gestire la paginazione per estrarre più pagine
Per aree con più di 820 annunci (il limite di 20 pagine), devi dividere per geografia. L’API interna di Zillow accetta parametri mapBounds. La strategia: dividere la mappa in quadranti ed estrarre ciascuno separatamente.
1def split_bounds(bounds):
2 """Divide i limiti della mappa in 4 quadranti."""
3 mid_lat = (bounds["north"] + bounds["south"]) / 2
4 mid_lng = (bounds["east"] + bounds["west"]) / 2
5 return [
6 {"north": bounds["north"], "south": mid_lat, "east": bounds["east"], "west": mid_lng},
7 {"north": bounds["north"], "south": mid_lat, "east": mid_lng, "west": bounds["west"]},
8 {"north": mid_lat, "south": bounds["south"], "east": bounds["east"], "west": mid_lng},
9 {"north": mid_lat, "south": bounds["south"], "east": mid_lng, "west": bounds["west"]},
10 ]Per la maggior parte dei casi d’uso — monitorare 50–200 annunci in un’area specifica — la paginazione standard via URL è sufficiente. L’approccio a quadranti serve per estrazioni su scala cittadina o regionale.
Passo 5: esportare i dati Zillow estratti
Salva tutto in CSV con pandas:
1import pandas as pd
2df = pd.DataFrame(detail_data)
3df.to_csv("zillow_houston_listings.csv", index=False)
4print(f"Esportati {len(df)} annunci in zillow_houston_listings.csv")Per esportare in JSON:
1with open("zillow_houston_listings.json", "w") as f:
2 json.dump(detail_data, f, indent=2)Se vuoi saltare del tutto la fase di esportazione, Thunderbit esporta gratuitamente su Google Sheets, Airtable e Notion — utile se vuoi i dati subito in un formato collaborativo.
Perché gli scraper Zillow si rompono (e come costruirli in modo resiliente)
Questa è la guida di sopravvivenza.
Nella mia esperienza, gli scraper si rompono su Zillow per tre motivi specifici — e per ciascuno esiste una soluzione concreta.
PerimeterX e CAPTCHA: perché le tue richieste restituiscono dati vuoti
L’integrazione PerimeterX di Zillow controlla più segnali contemporaneamente: fingerprint TLS, header HTTP, reputazione dell’IP e pattern delle richieste. Quando rileva automazione, restituisce una pagina CAPTCHA "Press & Hold" invece dei dati dell’annuncio.
Scenario di errore preciso: invii una richiesta con gli header predefiniti di Python. L’HTML della risposta contiene script di sfida PerimeterX invece dei dati dell’immobile — e il tuo parsing con BeautifulSoup non trova alcun tag __NEXT_DATA__.
La soluzione: usa tutti gli header che imitano il browser mostrati nel Passo 1. Se fai più di qualche decina di richieste, ti serve anche la rotazione dei proxy (coperta qui sotto). Per scraping intensivo, valuta una libreria come curl_cffi con impersonate="chrome" — è il client HTTP Python più vicino nel comportamento reale al fingerprint TLS di Chrome.
Selettori CSS dinamici: perché BeautifulSoup restituisce None
Se usi selettori CSS come .list-card-price o nomi di classe con hash, il tuo scraper si romperà ogni volta che Zillow distribuisce nuovo codice.
Zillow usa styled-components, che generano classi come StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0. La parte hash cambia a ogni build.
La soluzione: non usare proprio i selettori CSS. Estrai i dati dal blob JSON __NEXT_DATA__ come mostrato nel codice sopra. Questo approccio è stabile da anni perché la struttura JSON cambia molto meno spesso del markup HTML.
Se devi per forza usare il parsing HTML, cerca gli attributi data-test (ad esempio data-test="property-card") oppure usa una corrispondenza parziale delle classi, come [class*="PropertyCard"]. Ma l’estrazione JSON resta la strada più affidabile.
Rotazione dei proxy ed exponential backoff: codice che sopravvive ai ban IP
Gli IP dei datacenter vengono da Zillow. Per un accesso affidabile servono proxy residenziali. Ritmo sicuro: 1 richiesta ogni 3–8 secondi per IP, restando sotto circa 500 richieste/ora.
Ecco un decoratore di retry con exponential backoff e jitter:
1import random
2import time
3def backoff_with_jitter(attempt, base_delay=2, max_delay=60):
4 """Exponential backoff con jitter completo in stile AWS."""
5 delay = min(max_delay, base_delay * (2 ** attempt))
6 return random.uniform(0, delay)
7def fetch_with_retry(url, max_retries=5):
8 for attempt in range(max_retries):
9 try:
10 response = httpx.get(url, headers=headers, timeout=15)
11 if response.status_code == 200:
12 return response
13 if response.status_code in (403, 429):
14 delay = backoff_with_jitter(attempt, base_delay=5)
15 print(f"Bloccato ({response.status_code}). Nuovo tentativo tra {delay:.1f}s...")
16 time.sleep(delay)
17 continue
18 except Exception as e:
19 if attempt == max_retries - 1:
20 raise
21 time.sleep(backoff_with_jitter(attempt))
22 return NoneE un semplice pool per la rotazione dei proxy:
1class ProxyPool:
2 def __init__(self, proxies):
3 self.proxies = proxies
4 self.index = 0
5 self.failures = {}
6 def get_next(self):
7 proxy = self.proxies[self.index % len(self.proxies)]
8 self.index += 1
9 return {"http://": proxy, "https://": proxy}
10 def report_failure(self, proxy):
11 self.failures[proxy] = self.failures.get(proxy, 0) + 1
12 if self.failures[proxy] > 3:
13 self.proxies.remove(proxy)
14# Utilizzo:
15pool = ProxyPool(proxies=[
16 "http://user:pass@residential1.example.com:8080",
17 "http://user:pass@residential2.example.com:8080",
18])Tra i provider di proxy, offre proxy residenziali a circa 1$/GB (l’opzione più economica), mentre IPRoyal e Smartproxy sono scelte solide di fascia media a 4–7$/GB.
L’alternativa senza manutenzione
Se fai scraping di Zillow con regolarità e sei stanco di correggere selettori rotti o gestire pool di proxy, l’AI di Thunderbit legge la struttura della pagina da zero a ogni estrazione. Nessun selettore da mantenere, nessuna configurazione proxy. Risolve davvero il problema della fragilità che rende gli scraper tradizionali un fastidio continuo.
Automatizzare lo scraping di Zillow: pianificazione e monitoraggio dei prezzi
Ogni investitore immobiliare con cui ho parlato lo vuole, e nessun’altra guida allo scraping di Zillow ne parla: estrazioni automatiche ricorrenti per tenere traccia dei prezzi.
Per chi usa Python: cron job e rilevamento delle variazioni di prezzo
Imposta un cron job che esegue lo scraper ogni settimana e segnala i cambi di prezzo:
1import pandas as pd
2from datetime import datetime
3def detect_price_changes(new_data, historical_file, threshold=0.05):
4 """Confronta la nuova estrazione con i dati storici e segnala le variazioni oltre soglia."""
5 try:
6 old = pd.read_csv(historical_file)
7 except FileNotFoundError:
8 new_data.to_csv(historical_file, index=False)
9 print("Prima esecuzione — salvati i dati di base.")
10 return pd.DataFrame()
11 merged = new_data.merge(old, on="zpid", suffixes=("_new", "_old"))
12 merged["price_change_pct"] = (
13 (merged["price_new"] - merged["price_old"]) / merged["price_old"]
14 )
15 alerts = merged[merged["price_change_pct"].abs() > threshold]
16 # Aggiungi i nuovi dati con timestamp
17 new_data["scraped_at"] = datetime.now().isoformat()
18 new_data.to_csv(historical_file, mode="a", header=False, index=False)
19 return alertsAggiungi questo al tuo crontab per eseguire il task ogni lunedì alle 6:00:
10 6 * * 1 cd /path/to/scraper && python zillow_monitor.pyEsempio pratico: monitora ogni settimana 50 annunci a Austin, TX. Ogni lunedì lo script estrae i prezzi correnti, li confronta con la settimana precedente e produce un CSV con tutte le diminuzioni superiori al 5%.
Per chi non programma: Scheduled Scraper di Thunderbit
Lo Scheduled Scraper di Thunderbit ti permette di descrivere l’intervallo in linguaggio semplice ("ogni lunedì alle 9"), inserire gli URL di ricerca Zillow e cliccare su Schedule. I dati vengono esportati automaticamente in Google Sheets a ogni esecuzione. Niente Python, niente cron, nessun server da mantenere. È particolarmente utile per agenti immobiliari o team operativi che hanno bisogno di monitorare i prezzi in modo costante senza supporto tecnico.
Consigli per estrarre dati da Zillow in modo responsabile
Qualche nota per restare nel perimetro giusto:
- Estrai solo dati pubblicamente accessibili. Non accedere a pagine protette da login o autenticazione.
- Usa un ritmo di richiesta ragionevole. 3–8 secondi tra una richiesta e l’altra. Non bombardare il server.
- Non estrarre dati personali o privati degli utenti. I nomi degli agenti e le informazioni delle agenzie negli annunci sono pubblici; i dati degli account utente no.
- Conserva e usa i dati in modo etico. Analisi di mercato, ricerca sugli investimenti e lead generation sono usi legittimi. Lo spam no.
- Contesto legale: la sentenza ha stabilito che estrarre dati pubblicamente accessibili non viola il CFAA. Anche la sentenza Meta v. Bright Data (2024) ha confermato principi simili. Detto questo, i termini di servizio di Zillow limitano l’accesso automatizzato, e la piattaforma applica questi limiti tramite ban IP e CAPTCHA più che con azioni legali. Verifica sempre le indicazioni aggiornate e rispetta .
Scegliere l’approccio giusto per estrarre dati da Zillow con Python
La strada migliore dipende dalla tua situazione:
Hai bisogno dei dati subito, senza codice? ti porta da una pagina di ricerca Zillow a un foglio strutturato in circa 2 minuti. L’AI si adatta ai cambi di layout, gestisce la paginazione ed esporta gratuitamente. Installa la e provala su una pagina di ricerca Zillow.
Vuoi il massimo controllo? Usa il codice Python di questa guida. Estrai dal JSON __NEXT_DATA__ (non dai selettori CSS) per avere maggiore stabilità. Imposta header realistici che imitino il browser. Ruota proxy residenziali e usa exponential backoff per aumentare l’affidabilità.
Devi scalare? Le scraping API come (99% di successo su Zillow) o ScraperAPI gestiscono per te l’infrastruttura proxy e CAPTCHA, a un costo di 30–599 dollari al mese a seconda del volume.
Devi monitorare i prezzi nel tempo? Imposta un cron job con lo script di rilevamento delle variazioni di prezzo, oppure usa lo Scheduled Scraper di Thunderbit per un approccio senza manutenzione.
I dati ci sono. L’unica domanda è quanta energia tecnica vuoi investire per estrarli. Per approfondire come portare i dati dal web ai fogli di calcolo, consulta la nostra guida su o il nostro per i dati più recenti sulla piattaforma. Puoi anche guardare i tutorial sul .
FAQ
Si può estrarre dati da Zillow con Python gratuitamente?
Sì — httpx, BeautifulSoup e pandas sono tutti gratuiti e open source. Il compromesso è il tempo: dovrai gestire da solo header, rotazione dei proxy e manutenzione dei selettori. Considera 4–8 ore per la configurazione iniziale e 4–10 ore al mese di manutenzione quando Zillow modifica il sito. Anche Thunderbit offre un piano gratuito se vuoi evitare del tutto il lavoro di programmazione.
Zillow ha un’API ufficiale?
Zillow ha dismesso la sua API pubblica gratuita nel settembre 2021. L’accesso ora passa da Bridge Interactive, che richiede approvazione, costa circa 500 dollari al mese ed è pensato per professionisti immobiliari con licenza. Per la maggior parte degli utenti — investitori, ricercatori, agenti che fanno analisi di mercato — lo scraping è l’alternativa più pratica. Zillow pubblica comunque dati di ricerca gratuiti in CSV scaricabili su , incluso il Zillow Home Value Index e il Zillow Observed Rent Index.
Come evitare di essere bloccati quando si estraggono dati da Zillow?
Tre cose: (1) usa header realistici da browser, incluso Sec-Ch-Ua — è l’header che molti tutorial dimenticano, ed è il primo che PerimeterX controlla; (2) ruota proxy residenziali — gli IP dei datacenter vengono bloccati subito; (3) estrai i dati dal JSON __NEXT_DATA__ invece che dai selettori HTML, così eviti rotture dovute ai cambi di layout. Mantieni il ritmo a 1 richiesta ogni 3–8 secondi per IP. In alternativa, usa uno strumento come Thunderbit che gestisce automaticamente la protezione anti-bot.
Qual è il modo migliore per estrarre dati da Zillow senza programmare?
L’AI Web Scraper di Thunderbit è il percorso più rapido. Installa la , apri una pagina di ricerca Zillow, clicca su "AI Suggest Fields" per rilevare automaticamente le colonne, poi fai clic su "Scrape." Esporta in Google Sheets, Excel, Airtable o Notion senza scrivere codice. L’AI rilegge la pagina ogni volta, quindi non si rompe quando Zillow aggiorna il layout.
Quanto spesso Zillow modifica la struttura del sito e che impatto ha sugli scraper?
Zillow rilascia aggiornamenti di frequente — a volte ogni settimana. Poiché usa styled-components, i nomi delle classi CSS cambiano a ogni deploy e gli scraper basati su selettori CSS si rompono regolarmente. L’approccio più resiliente in Python è estrarre dal blob JSON __NEXT_DATA__, che cambia struttura molto meno spesso. Per un approccio senza manutenzione, l’AI di Thunderbit rilegge la struttura della pagina a ogni estrazione e si adatta automaticamente ai cambi di layout.
Approfondisci