Yelp raccoglie su — e trasformare questi dati in un formato davvero utilizzabile non è mai stato così complicato. La stretta anti-bot di Yelp nel 2024–2025 ha mandato quasi in tilt, in silenzio, la maggior parte dei tutorial Python esistenti per lo scraping.
Se di recente hai provato a usare uno scraper per Yelp e ti sei trovato davanti a una sfilza di errori 403, risposte HTML vuote o CAPTCHA che sei mesi fa non c’erano, non te lo stai immaginando. Oggi Yelp usa fingerprint TLS/JA3, nomi di classe CSS offuscati e a rotazione, oltre a un punteggio aggressivo di reputazione degli IP — quindi il vecchio approccio requests + BeautifulSoup che quasi tutti i tutorial continuano a consigliare si rompe già alla prima richiesta. Ho passato settimane a testare diversi approcci contro lo stack attuale di Yelp, e questa guida copre tutto ciò che funziona davvero nel 2025: la Fusion API ufficiale (e perché probabilmente non basta), un flusso completo di scraping in Python con una strategia anti-blocco a più livelli, e un’alternativa no-code in 2 clic con per chi vuole solo i dati, senza una maratona di debug.
Perché fare scraping di Yelp con Python (e chi ci guadagna davvero)
Prima ancora di scrivere una riga di codice, qual è il vero caso d’uso dei dati di Yelp? La piattaforma non è solo un sito di recensioni di ristoranti: è di fatto un database vivo di attività locali con informazioni strutturate su contatti, valutazioni, categorie, orari e centinaia di milioni di recensioni dei clienti.
Ecco chi ne trae più vantaggio e cosa estrae:
| Caso d’uso | Campi dati chiave | Perché conta |
|---|---|---|
| Sales e lead generation | Nome attività, telefono, sito web, indirizzo, categoria, valutazione | Crea liste mirate di potenziali clienti locali — 4 utenti Yelp su 5 sono già pronti all’acquisto quando arrivano |
| Competitive intelligence | Recensioni, stelle, volume recensioni, sentiment | Monitora la reputazione dei competitor, individua gap nel servizio, segue i trend |
| Ricerca di mercato e NLP | Testo completo delle recensioni, date, metadati dei recensori | Analisi del sentiment, topic modeling — le recensioni Yelp sono uno dei corpora NLP più usati nella ricerca accademica |
| Real estate e site selection | Densità delle attività, mix di categorie, qualità delle recensioni per area | Scelta delle sedi per franchise e retail — Yelp vende Location Intelligence come prodotto B2B su licenza proprio per questo |
| Ecommerce e operations | Segnali sui prezzi, lamentele dei clienti, orari di servizio | Osserva come vengono recensiti i competitor e individua pattern operativi |
Il filo conduttore è sempre lo stesso: l’obiettivo vero sono i dati strutturati, e Python è solo uno dei mezzi per arrivarci. Alcuni lettori vorranno il pieno controllo via codice. Altri avranno solo bisogno di un foglio con i contatti dei idraulici di Austin. Qui trovi entrambe le strade.
Yelp Fusion API vs scraping Python: quale conviene usare?
Molte guide saltano del tutto questa scelta e vanno subito al codice, senza chiedersi se la ufficiale (oggi ribattezzata “Yelp Places API”) sarebbe stata sufficiente. Nella mia esperienza, fare questa valutazione fa risparmiare ore di lavoro sprecate — perché l’API è ottima per alcune cose e del tutto insufficiente per altre.
Cosa offre davvero la Fusion API
La Fusion API fornisce ricerca strutturata delle attività, dettagli delle aziende, autocomplete e un endpoint per le recensioni. È autorizzata, ben documentata e non richiede acrobazie anti-bot.
Ma è proprio l’endpoint delle recensioni che fa crollare tutto. Ecco cosa ha confermato lo staff di Yelp su GitHub:
"The Yelp API does not return full review text. Three review excerpts of 160 characters are provided by default." —
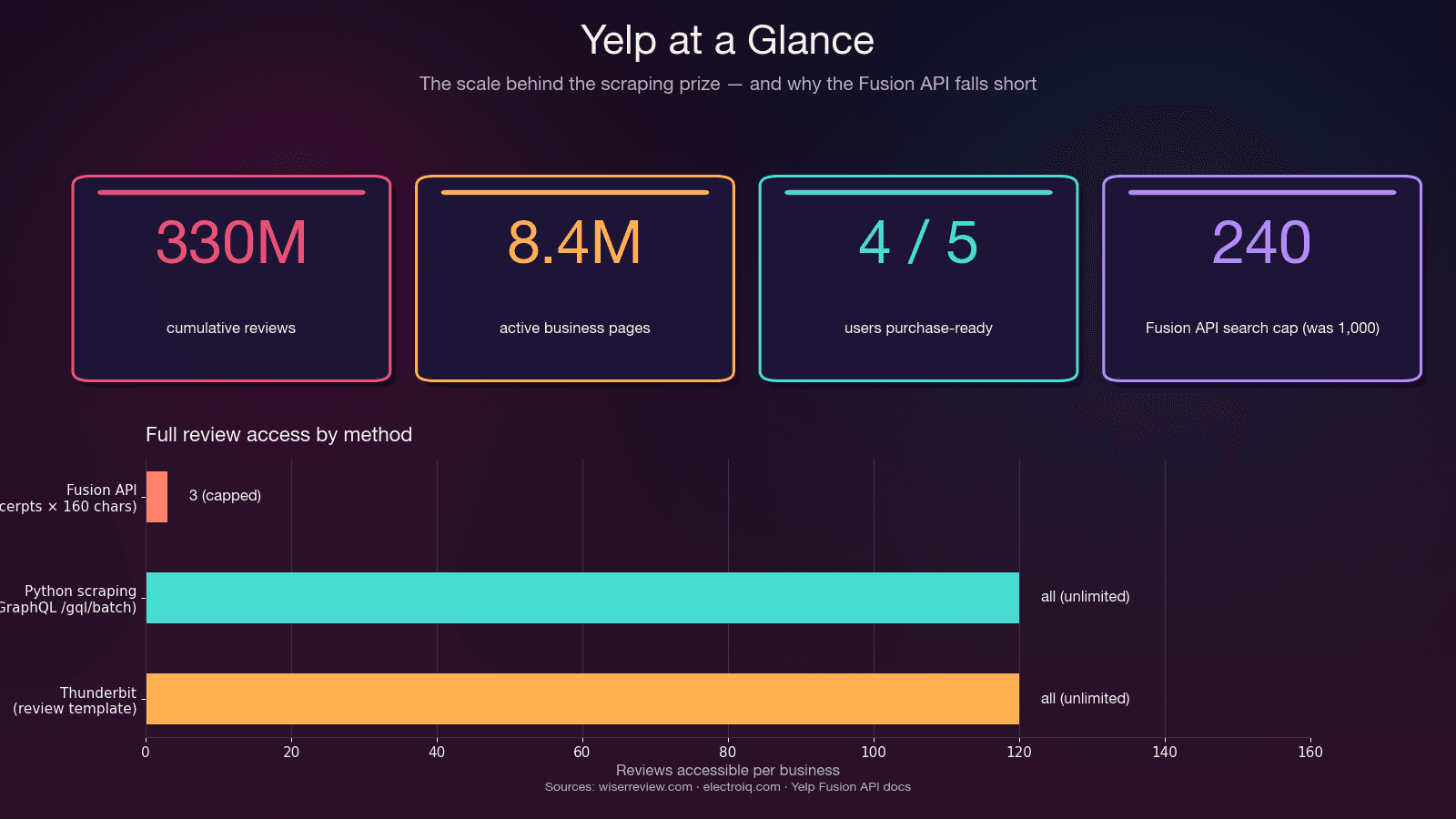
Non è un bug: è una scelta voluta. L’API si ferma fisicamente a 3 estratti di recensione (7 con Premium), ciascuno troncato a circa 160 caratteri. Nessun metadato della recensione (voti useful/funny/cool), nessuna cronologia del recensore, nessuna risposta del proprietario. E il dopo maggio 2023 — rispetto alle 5.000 precedenti. Il prezzo d’ingresso parte da .
Il quadro decisionale
| Fattore | Yelp Fusion API | Scraping Python | Thunderbit (No-Code) |
|---|---|---|---|
| Recensioni complete | ❌ Solo 3 estratti (~160 caratteri ciascuno) | ✅ Tutte le recensioni via GraphQL | ✅ Tutte le recensioni visibili |
| Limiti di richieste | 300–500/giorno (nuovi); 5.000 (legacy) | Gestiti da te (budget proxy) | Basato su crediti |
| Impegno iniziale | ~15 min (API key + SDK) | Da ore a giorni | ~2 minuti |
| Campi business | ~20 campi strutturati | Illimitati (parse HTML/JSON) | Campi suggeriti dall’AI |
| Gestione anti-bot | N/A (autorizzato) | Da costruire manualmente | Gestita automaticamente |
| Rischio legale | ✅ Autorizzato | ⚠️ Zona grigia ToS | ⚠️ Come lo scraping |
| Costo | Minimo $29/mese | Gratis (+ proxy $0,75–$4/GB) | Disponibile piano free |
| Manutenzione | Bassa (API stabile) | Alta (i selettori si rompono, l’anti-bot si irrigidisce) | Bassa (l’AI si riadatta) |
Usa la Fusion API se: ti servono informazioni di base sull’attività, ricerche su piccola scala o un’integrazione autorizzata — e ti bastano 3 snippet di recensioni per attività.
Usa lo scraping in Python se: ti servono il testo completo delle recensioni, tutte le recensioni di un’attività, metadati delle recensioni, più di 240 risultati per ricerca o un budget sotto i $29/mese.
Usa Thunderbit se: vuoi i dati in fretta, senza scrivere o mantenere codice. Ne parlo meglio nella sezione no-code qui sotto.
La scorciatoia no-code: estrarre dati da Yelp con Thunderbit (senza Python)
Prima di entrare nel dettaglio di Python, ecco il percorso più rapido per chi ha come obiettivo i dati, non l’esercizio di programmazione. Tutte le guide concorrenti danno per scontato che tu sappia usare Python, ma nel mio lavoro con Thunderbit ho visto che gran parte di chi cerca “scrape Yelp” è fatta da sales rep, operations manager e piccoli imprenditori che vogliono solo un foglio con le attività locali — non un corso accelerato sul fingerprint TLS.
offre già template Yelp pronti all’uso:
- — estrae nome attività, valutazione, contatti, indirizzo, orari, categoria
- — estrae username del recensore, contenuto della recensione, valutazione, data, località del recensore
Come funziona in pratica
- Apri una pagina risultati di ricerca Yelp o una pagina business in Chrome
- Fai clic su AI Suggest Fields nell’ — l’AI legge la pagina e propone le colonne (nome attività, valutazione, numero recensioni, fascia prezzo, categoria, indirizzo, telefono, URL)
- Fai clic su Scrape — fatto
Con i template Yelp già pronti è ancora più semplice: apri il template e premi Scrape.
Lo scraping delle sottopagine gestisce automaticamente il loop di arricchimento — parti da una pagina risultati Yelp, attiva il subpage scraping e Thunderbit visita ogni pagina business per raccogliere orari, recensioni complete, sito web, foto e servizi. Nessuna configurazione aggiuntiva.
La paginazione è automatica — sia click-based sia scroll-based, gestita nativamente. (Per capire meglio come funziona, vedi la nostra .)
Le esportazioni sono gratuite in ogni piano — Excel, Google Sheets, Airtable, Notion, CSV, JSON. Niente pandas, niente codice per scrivere CSV.
Confronto dei tempi
| Tempo | Scraper Python | Thunderbit |
|---|---|---|
| Primo run | Da ore a giorni (scrivere selettori, gestire paginazione, proxy, retry) | ~30 secondi con il template Yelp già pronto |
| Quando Yelp cambia il markup | Riscrivere manualmente i selettori | Rifai clic su AI Suggest Fields — si riadatta da solo |
| Quando l’IP viene bloccato | Debug, rotazione dei proxy, nuovi test | La modalità cloud gestisce la rotazione IP |
| Export su Google Sheets | Scrivere OAuth + collegamenti con pandas | Un clic, gratis |
Se provi prima Thunderbit e scopri che copre le tue esigenze, puoi saltare il resto dell’articolo. Se invece ti serve pieno controllo via codice, campi personalizzati o una scala superiore a poche migliaia di record al mese — continua a leggere.
Librerie Python per estrarre dati da Yelp: quale scegliere
"Meglio Scrapy, BS4+requests o Selenium?" è una delle domande più comuni nei thread r/webscraping su Yelp. Eppure ogni tutorial sceglie la propria libreria preferita e va avanti senza spiegare il perché. Ecco una panoramica onesta.
La realtà del 2025: requests + BeautifulSoup è rotto per Yelp
Lo stack che ogni tutorial classico su Yelp consiglia — pip install requests beautifulsoup4 — viene bloccato già alla prima richiesta nel 2025. Non alla cinquantesima. Alla prima.
Il motivo: la libreria requests di Python espone un fingerprint TLS/JA3 che non corrisponde a nessun browser reale. Il layer anti-bot di Yelp lo intercetta a livello di handshake TLS, prima ancora di leggere l’header User-Agent. L’ho testato più volte — IP nuovo, header realistici, ritardi casuali — e ottenevo comunque un 403 Forbidden immediato con requests puro.
Matrice di scelta delle librerie
| Libreria | Ideale per | Gestisce JS? | Anti-Bot? | Curva di apprendimento | Velocità |
|---|---|---|---|---|---|
requests + BeautifulSoup | ❌ | ❌ | Molto bassa | Veloce (finché non viene bloccato) | |
httpx async + parsel | Scraping asincrono su larga scala | ❌ | ❌ | Bassa | Molto veloce |
curl_cffi + parsel | Specifico per Yelp: impersonificazione TLS | ❌ | ✅ TLS/JA3/HTTP2 | Bassa | Molto veloce |
Scrapy 2.14 | Pipeline complete con paginazione | Parziale (via scrapy-playwright) | AutoThrottle, retry middleware | Medio-alta | Veloce |
Selenium 4.43 / Playwright 1.58 | Pagine molto JS-heavy, workaround per CAPTCHA | ✅ | Parziale | Media | Lento (~10–30 pagine/min) |
| Thunderbit | Non-coder, estrazione rapida | ✅ (browser) | Integrato (Cloud mode) | Molto bassa | Veloce |
La svolta di curl_cffi
La libreria che ha cambiato il mio flusso di lavoro su Yelp è — un binding Python per curl-impersonate. Genera esattamente lo stesso fingerprint TLS/JA3 + HTTP/2 di Chrome reale, e la sua API sostituisce direttamente requests:
1from curl_cffi import requests
2r = requests.get(
3 "https://www.yelp.com/biz/some-restaurant",
4 impersonate="chrome131",
5)
6print(r.status_code, len(r.text))Questa singola modifica — from curl_cffi import requests più impersonate="chrome131" — aggira il senza avviare un browser. Nei miei test, è la differenza tra 403 immediati e risposte 200 pulite.
Il mio stack consigliato per Yelp nel 2025: curl_cffi + parsel + jmespath + proxy residenziali. Se ti serve una pipeline completa con scheduling, avvolgila in Scrapy 2.14 con un downloader middleware basato su curl_cffi.
Configurare l’ambiente Python per estrarre dati da Yelp
- Difficoltà: Intermedia
- Tempo richiesto: ~15 minuti per la configurazione, 1–2 ore per uno scraper funzionante
- Cosa ti serve: Python 3.10+ (consigliato 3.12), un terminale e, opzionalmente, un provider di proxy residenziali
Passo 1: creare un ambiente virtuale e installare i pacchetti
1python3.12 -m venv .venv
2source .venv/bin/activate # Su Windows: .venv\Scripts\activate
3pip install "curl_cffi>=0.11" "parsel>=1.9" "jmespath>=1.0" pandasCosa fa ciascun pacchetto:
curl_cffi— invia richieste HTTP con il fingerprint TLS di Chrome (il bypass anti-bot)parsel— selettori CSS/XPath per il parsing dell’HTML (lo stesso motore usato da Scrapy, ma più leggero)jmespath— query dichiarative per JSON (più pulite dell’accesso a dict annidati per il JSON embedded di Yelp)pandas— esportazione dei dati in CSV/Excel
Opzionale ma utile:
1pip install fake-useragent # Nota: il repository è stato archiviato ad aprile 2026 ma è ancora installabilePasso per passo: come estrarre dati da Yelp con Python
Questo è il tutorial centrale. L’intuizione chiave che rende tutto più robusto: salta i selettori CSS e prendi invece il JSON nascosto. Yelp randomizza i nomi delle classi CSS a ogni build (y-css-14xwok2 una settimana, y-css-hcq7b9 la successiva), quindi qualsiasi scraper legato a quelli si rompe nel giro di poche settimane. I payload JSON incorporati — application/ld+json e react-root-props — sono stabili.
Passo 2: estrarre i risultati di ricerca Yelp
Gli URL di ricerca Yelp seguono un pattern prevedibile: https://www.yelp.com/search?find_desc={term}&find_loc={location}. I dati dei risultati sono incorporati in un tag <script data-id="react-root-props"> come JSON — non dentro il marasma di classi CSS.
1import re, json, jmespath
2from curl_cffi import requests
3from parsel import Selector
4HEADERS = {
5 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
6 "AppleWebKit/537.36 (KHTML, like Gecko) "
7 "Chrome/124.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
9 "image/avif,image/webp,image/apng,*/*;q=0.8",
10 "accept-language": "en-US,en;q=0.9",
11 "accept-encoding": "gzip, deflate, br",
12 "cookie": "intl_splash=false",
13}
14def scrape_search(term: str, location: str, max_pages: int = 3):
15 results = []
16 for page in range(max_pages):
17 url = (f"https://www.yelp.com/search?"
18 f"find_desc={term}&find_loc={location}&start={page * 10}")
19 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
20 if r.status_code != 200:
21 print(f"Bloccato alla pagina {page}: {r.status_code}")
22 break
23 sel = Selector(text=r.text)
24 script = sel.xpath(
25 "//script[@data-id='react-root-props']/text()"
26 ).get() or ""
27 m = re.search(r"react_root_props\s*=\s*(\{.*?\});", script, re.S)
28 if not m:
29 print(f"Nessun react-root-props trovato alla pagina {page} — possibile soft block")
30 break
31 data = json.loads(m.group(1))
32 businesses = jmespath.search(
33 "legacyProps.searchAppProps.searchPageProps"
34 ".mainContentComponentsListProps"
35 "[?searchResultBusiness].searchResultBusiness.{"
36 "name: name, url: businessUrl, rating: rating, "
37 "reviews: reviewCount, phone: phone, "
38 "neighborhoods: neighborhoods}",
39 data,
40 ) or []
41 results.extend(businesses)
42 import time, random
43 time.sleep(random.uniform(3, 7))
44 return resultsDovresti ottenere una lista di dict con nome attività, URL, valutazione e numero di recensioni. Se react-root-props manca dalla risposta, ti è stato servito un blocco “vuoto” — ruota l’IP e riprova.
L’header Cookie: intl_splash=false è un workaround standard per il redirect di Yelp alla schermata paese. Senza di esso, gli IP non USA vengono reindirizzati a una splash page che sembra un soft block, ma non lo è.
Passo 3: estrarre le pagine business di Yelp
Ogni URL business ottenuto dai risultati di ricerca porta a una pagina dettaglio con dati più ricchi. Il target di estrazione più stabile è il blocco <script type="application/ld+json"> — contiene dati strutturati schema.org che Yelp mantiene per SEO e non offusca.
1def scrape_business(biz_url: str) -> dict:
2 url = f"https://www.yelp.com{biz_url}" if biz_url.startswith("/") else biz_url
3 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
4 if r.status_code != 200:
5 return {"url": url, "error": r.status_code}
6 sel = Selector(text=r.text)
7 biz_id = sel.css('meta[name="yelp-biz-id"]::attr(content)').get()
8 for raw in sel.css('script[type="application/ld+json"]::text').getall():
9 try:
10 data = json.loads(raw)
11 except json.JSONDecodeError:
12 continue
13 for node in (data if isinstance(data, list) else [data]):
14 if node.get("@type") in (
15 "Restaurant", "LocalBusiness", "FoodEstablishment",
16 "HealthAndBeautyBusiness", "HomeAndConstructionBusiness",
17 ):
18 return {
19 "biz_id": biz_id,
20 "name": node.get("name"),
21 "rating": (node.get("aggregateRating") or {}).get("ratingValue"),
22 "review_count": (node.get("aggregateRating") or {}).get("reviewCount"),
23 "address": node.get("address"),
24 "telephone": node.get("telephone"),
25 "price_range": node.get("priceRange"),
26 "hours": node.get("openingHours"),
27 "url": url,
28 }
29 return {"biz_id": biz_id, "url": url}Il valore meta[name="yelp-biz-id"] è l’ID business codificato che ti servirà per l’endpoint delle recensioni. Prendilo qui — ti servirà nel passo successivo.
Passo 4: estrarre le recensioni Yelp con paginazione
Qui la Fusion API mostra i suoi limiti e lo scraping dà il meglio. L’endpoint GraphQL interno di Yelp restituisce testo completo delle recensioni, info sul recensore, date, valutazioni e conteggi dei voti — tutto quello che l’API non espone.
L’endpoint è https://www.yelp.com/gql/batch, e usa un documentId statico per l’operazione GetBusinessReviewFeed. La paginazione avviene tramite un cursor codificato in base64.
1import base64
2GQL_URL = "https://www.yelp.com/gql/batch"
3DOC_ID = "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
4def fetch_reviews(enc_biz_id: str, num_pages: int = 5):
5 all_reviews = []
6 for page in range(num_pages):
7 offset = page * 10
8 cursor = base64.b64encode(
9 json.dumps({"version": 1, "offset": offset}).encode()
10 ).decode()
11 payload = [{
12 "operationName": "GetBusinessReviewFeed",
13 "variables": {
14 "encBizId": enc_biz_id,
15 "reviewsPerPage": 10,
16 "after": cursor,
17 "sortBy": "DATE_DESC",
18 "language": "en",
19 },
20 "extensions": {
21 "operationType": "query",
22 "documentId": DOC_ID,
23 },
24 }]
25 r = requests.post(
26 GQL_URL,
27 json=payload,
28 headers={
29 **HEADERS,
30 "content-type": "application/json",
31 "x-apollo-operation-name": "GetBusinessReviewFeed",
32 "apollographql-client-name": "yelp-main-frontend",
33 },
34 impersonate="chrome131",
35 )
36 if r.status_code != 200:
37 print(f"Recupero recensioni fallito all’offset {offset}: {r.status_code}")
38 break
39 data = r.json()
40 # Naviga nella struttura della risposta per estrarre le recensioni
41 try:
42 reviews = data[0]["data"]["business"]["reviews"]["edges"]
43 for edge in reviews:
44 node = edge.get("node", {})
45 all_reviews.append({
46 "reviewer": node.get("author", {}).get("displayName"),
47 "rating": node.get("rating"),
48 "date": node.get("localizedDate"),
49 "text": node.get("text", {}).get("full"),
50 })
51 except (KeyError, IndexError, TypeError):
52 break
53 import time, random
54 time.sleep(random.uniform(3, 7))
55 return all_reviewsOgni pagina restituisce 10 recensioni. Incrementa l’offset nel cursor base64 per paginare. Il parametro sortBy accetta DATE_DESC (più recenti prima), RATING_ASC, RATING_DESC e altri valori.
Passo 5: esportare i dati Yelp estratti
1import pandas as pd
2# Supponendo di aver già raccolto business e recensioni
3df_businesses = pd.DataFrame(businesses)
4df_businesses.to_csv("yelp_businesses.csv", index=False)
5df_reviews = pd.DataFrame(all_reviews)
6df_reviews.to_csv("yelp_reviews.csv", index=False)
7# Oppure salva in JSON per maggiore flessibilità
8import json
9with open("yelp_data.json", "w") as f:
10 json.dump({"businesses": businesses, "reviews": all_reviews}, f, indent=2)Per chi segue il percorso no-code, Thunderbit esporta gli stessi dati direttamente in Excel, Google Sheets, Airtable o Notion — senza bisogno di pandas o di codice per scrivere file.
Il playbook anti-blocco: come estrarre dati da Yelp senza farsi bloccare
Questa sezione è il vero motivo per cui esiste l’articolo. Le contromisure anti-bot di Yelp sono diventate molto più dure dalla fine del 2024 — sono tutti in gioco. Molte guide in circolazione sono ormai superate, perché scritte prima di questa stretta.
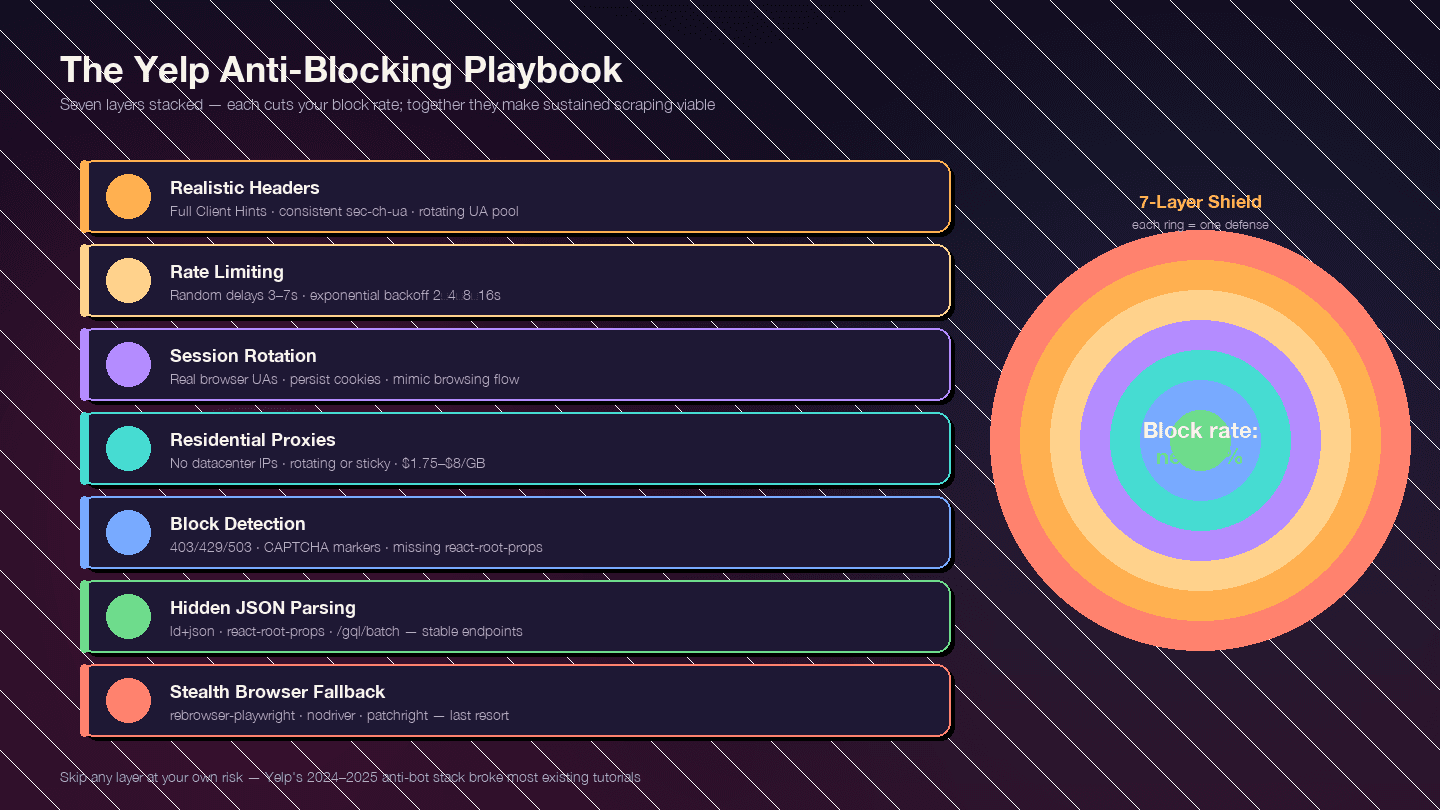
La strategia è stratificata. Ogni livello riduce il tasso di blocco; insieme rendono lo scraping continuo davvero praticabile.
Livello 1: header realistici nelle richieste
Gli header predefiniti di Python requests inviano User-Agent: python-requests/2.x — bloccato all’istante. Ma nemmeno un User-Agent realistico basta da solo. Yelp controlla l’intero set di header per verificare la coerenza.
1FULL_HEADERS = {
2 "authority": "www.yelp.com",
3 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36",
6 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
7 "image/avif,image/webp,image/apng,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 "accept-encoding": "gzip, deflate, br",
10 "sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
11 "sec-ch-ua-mobile": "?0",
12 "sec-ch-ua-platform": '"Windows"',
13 "sec-fetch-dest": "document",
14 "sec-fetch-mode": "navigate",
15 "sec-fetch-site": "same-origin",
16 "sec-fetch-user": "?1",
17 "upgrade-insecure-requests": "1",
18 "referer": "https://www.yelp.com/",
19 "cookie": "intl_splash=false",
20}Tre errori che ti fanno finire sotto osservazione:
- L’UA dice Chrome ma
sec-ch-uamanca o contraddice la versione dell’UA sec-ch-ua-platformdice "Windows" ma la stringa UA dice macOS- Stesso identico UA su migliaia di richieste dallo stesso IP — ruota un pool di 10–20 stringhe recenti di Chrome/Firefox/Safari
Livello 2: limitazione della velocità e ritardi casuali
Pattern temporali prevedibili sono un segnale d’allarme. Aggiungi intervalli di sleep casuali e un backoff esponenziale sulle risposte d’errore.
1import random, time
2def polite_get(client_get, url, attempt=0):
3 r = client_get(url, headers=FULL_HEADERS, impersonate="chrome131")
4 if r.status_code in (403, 429, 503):
5 if attempt >= 4:
6 raise RuntimeError(f"Bloccato dopo {attempt + 1} tentativi su {url}")
7 backoff = 2 ** (attempt + 1) + random.random()
8 print(f" Ricevuto {r.status_code}, backoff {backoff:.1f}s (tentativo {attempt + 1})")
9 time.sleep(backoff)
10 return polite_get(client_get, url, attempt + 1)
11 time.sleep(random.uniform(3, 7))
12 return r| Parametro | Valore consigliato |
|---|---|
| Sleep casuale tra richieste | random.uniform(3, 7) secondi |
| Backoff su 429/403/503 | 2 → 4 → 8 → 16s, massimo 5 tentativi |
| Worker concorrenti per IP | 1 (serializza per IP; usa proxy per parallelismo) |
| Rate sostenuto massimo per IP residenziale | ~1 richiesta / 5s (~12 rpm) |
Livello 3: rotazione di User-Agent e sessioni
Ruota un pool di User-Agent realistici di browser veri. Mantieni sessioni e cookie persistenti per simulare un comportamento di navigazione reale — Yelp usa rilevamento basato sui cookie, quindi creare una sessione nuova a ogni richiesta è di per sé sospetto.
1UA_POOL = [
2 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
3 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14.4; rv:125.0) Gecko/20100101 Firefox/125.0",
6 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 Safari/17.4.1",
7 # Aggiungi altre 5-10 stringhe recenti
8]Livello 4: rotazione dei proxy
A volumi reali, servono proxy residenziali. I proxy datacenter e quelli gratuiti non funzionano su Yelp — il layer di reputazione IP di Yelp blocca in anticipo gli intervalli AWS, GCP e DigitalOcean.
| Provider | $/GB d’ingresso | Note |
|---|---|---|
| IPRoyal | $1,75/GB | Il più economico; alimenta il tutorial Yelp più citato |
| Decodo (ex-Smartproxy) | $3,20–$3,50 | Miglior rapporto GB/$ su volumi elevati |
| Bright Data | $4,00 (PAYG) | Pool di 150M+ IP; pagina dedicata ai proxy Yelp |
| Oxylabs | $6,00–$8,00 | Premium; 10M+ IP |
| Aluvia (SIM mobile) | $3,00 | IP mobili reali di operatori USA, pensati per Yelp |
Il rotating residential (nuovo IP per ogni richiesta) funziona meglio per crawl di ricerca ad alto volume. Le sticky session (mantenere lo stesso IP per 10 minuti) sono più adatte quando devi conservare i cookie lungo il flusso pagina business → recensioni → paginazione.
Livello 5: rilevare e gestire i blocchi
Non tutti i blocchi si presentano allo stesso modo. Yelp spesso mostra una shell generica “page not available” invece di un CAPTCHA, motivo per cui gli scraper ingenui credono di ricevere dati quando in realtà stanno ottenendo risposte vuote.
1BLOCK_MARKERS = (
2 "captcha", "px-captcha", "page not available",
3 "access denied", "unusual traffic",
4)
5def is_blocked(resp):
6 if resp.status_code in (401, 403, 429, 503):
7 return True
8 body = resp.text.lower()
9 if any(m in body for m in BLOCK_MARKERS):
10 return True
11 # Se è una pagina search/business ma react-root-props manca,
12 # Yelp ha servito una risposta bloccata e svuotata
13 if "react-root-props" not in body and "/biz/" in str(resp.url):
14 return True
15 return False| Segnale | Significato |
|---|---|
| HTTP 403 | Blocco duro — IP/header/TLS compromessi |
| HTTP 429 | Rate limit — spesso recuperabile con backoff |
| HTTP 503 | Blocco generico o riduzione del carico |
Redirect a /error o corpo con "page not available" | Soft block |
| vuoto con solo | Pagina challenge in attesa di JS |
captcha / g-recaptcha / px-captcha nel body | Escalation — CAPTCHA richiesto |
react-root-props mancante su una pagina listing | Risposta bloccata e svuotata |
Livello 6: il trucco di parsing resiliente — JSON nascosto invece dei selettori CSS
Vale la pena ripeterlo: Yelp randomizza i nomi delle classi CSS a ogni build. Uno scraper ancorato a h3.y-css-14xwok2 si romperà nel giro di poche settimane, quando Yelp rilancia con h3.y-css-hcq7b9.
I payload che non cambiano:
<script type="application/ld+json">— dati strutturati schema.org (nome, indirizzo, telefono, rating, orari)<script data-id="react-root-props">— dati completi dei risultati di ricerca in JSONhttps://www.yelp.com/gql/batch— endpoint GraphQL delle recensioni con undocumentIdstabile
Se stai parsando classi CSS, stai costruendo sulla sabbia. Analizza invece il JSON.
Livello 7: il fallback con browser stealth
Passa a un browser headless solo quando curl_cffi + proxy residenziali non bastano — in genere quando Yelp mostra una pagina challenge JavaScript o un CAPTCHA.
Per il 95% dello scraping di attività/ricerche/recensioni, curl_cffi + JSON nascosto + proxy residenziali è più veloce, economico e affidabile di un browser. Ma quando un browser serve davvero:
| Strumento | Stato (2025) | Note |
|---|---|---|
| rebrowser-playwright | Punto di partenza consigliato | Playwright patchato in drop-in per correggere i leak CDP |
| nodriver | Il migliore per lo stealth su Chrome | Successore di undetected-chromedriver; evita del tutto il protocollo WebDriver |
| patchright | Fork Playwright attivamente mantenuto | Supera i test di rilevamento moderni |
| playwright-stealth | Maturo | Patcha navigator.webdriver, rimuove HeadlessChrome dall’UA |
Evita il Selenium tradizionale per Yelp. È troppo facile da fingerprintare.
Yelp Fusion API vs scraping Python vs Thunderbit: confronto completo
| Dimensione | Yelp Fusion API | Scraping Python | Thunderbit |
|---|---|---|---|
| Testo completo delle recensioni | ❌ 3 estratti × ~160 caratteri | ✅ Illimitato (GraphQL) | ✅ Template recensioni integrato |
| Metadati recensioni (voti, risposte del proprietario) | ❌ | ✅ | ✅ Tramite campi suggeriti dall’AI |
| Foto | ❌ (0 nel piano Base) | ✅ Illimitate | ✅ |
| Risultati massimi per ricerca | 240 (erano 1.000 prima del 2024) | Illimitati (con paginazione) | Illimitati |
| Limite giornaliero | 300–500 (nuovi) / 5.000 (legacy) | Solo budget proxy | Basato su crediti (3.000/mese nel Pro) |
| Impegno di setup | ~15 min | Da ore a giorni | ~2 minuti |
| Gestione anti-bot | N/A | Problema tuo | Gestita (Cloud mode) |
| Rischio legale | Basso (autorizzato) | Medio (zona grigia ToS) | Medio (come lo scraping) |
| Costo (ingresso) | $29/mese | ~$0,75–$4/GB per proxy + tempo di sviluppo | Piano free |
| Costo (uso intensivo) | $643+/mese | $50–$500/mese di proxy + sviluppo | $38–$49/mese |
| Export dati | JSON | CSV/JSON (da creare tu) | Excel / Sheets / Airtable / Notion — gratis |
| Manutenzione | Bassa | Alta (i selettori si rompono, l’anti-bot si irrigidisce) | Bassa (l’AI si riadatta) |
Suggerimenti legali ed etici per estrarre dati da Yelp
Non sono un avvocato, e questo non è un parere legale. Ma il quadro normativo è cambiato abbastanza negli ultimi due anni da rendere utile conoscere almeno le basi prima di investire tempo in un progetto di scraping di Yelp.
Cosa dice i termini di servizio di Yelp: l’ vieta esplicitamente di usare "any robot, spider... or other automated device" per "access, retrieve, copy, scrape, or index any portion of the Service". Aggiunge anche riferimenti a "AI Technologies and/or other automated tools."
: "Yelp does not allow any scraping of the site."
Cosa dice robots.txt: il contiene un wildcard User-agent: * / Disallow: / e blocca in modo specifico GPTBot, ClaudeBot, PerplexityBot, CCBot e Meta-ExternalAgent. Sono autorizzati solo Googlebot, Bingbot e pochi crawler dei social media.
Il precedente legale che conta: in (N.D. Cal. gennaio 2024), il tribunale ha stabilito che lo scraping di dati pubblicamente disponibili e accessibili senza login non violava i Termini di Servizio di Meta. La distinzione chiave è: dati pubblici senza login vs dati dietro login. Il caso ha chiarito che lo scraping di dati pubblici probabilmente non viola il CFAA, ma hiQ ha comunque perso sulle richieste per illecito civile statale (trespass to chattels, misappropriation) ed è stato colpito da una condanna da $500.000.
Linee guida pratiche:
- Estrarre solo pagine pubbliche e accessibili senza login
- Limitare la velocità delle richieste (i ritardi di questa guida servono anche come rate limit etico)
- Non rivendere testo grezzo delle recensioni attribuito a utenti nominativi — rispetta la privacy dei recensori
- Rispettare le leggi locali sulla protezione dei dati (CCPA, GDPR)
- Non fare login per estrarre dati — supereresti il confine dell’autorizzazione
- Trattare le informazioni business (nome/indirizzo/telefono/valutazione) come dati fattuali pubblici; considerare il testo delle recensioni più sensibile
Consulta un professionista legale per il tuo caso specifico.
Conclusione
Tre strade, un solo obiettivo.
La Yelp Fusion API è l’opzione autorizzata e a bassa manutenzione — ma si ferma a 3 estratti di recensione e parte da $29/mese. Lo scraping in Python ti dà il controllo totale su ogni dato di Yelp, ma richiede un investimento reale: curl_cffi per impersonare il fingerprint TLS, proxy residenziali, ritardi casuali, parsing del JSON nascosto e manutenzione continua mentre le difese di Yelp evolvono. Thunderbit ti porta da "mi serve il dato di Yelp" a "ecco il mio foglio di calcolo" in circa 30 secondi, senza codice e senza configurazione proxy.
Gli elementi anti-blocco che funzionano davvero nel 2025: header realistici con Client Hints completi, curl_cffi per impersonare il fingerprint TLS, ritardi casuali con backoff esponenziale, rotazione di proxy residenziali e — soprattutto — parsing del JSON nascosto (application/ld+json e react-root-props) invece di selettori CSS fragili.
Non sai quale strada scegliere? Prova prima il . Se copre le tue esigenze, hai risparmiato ore di lavoro. Se ti serve più controllo — pipeline programmatiche complete, campi personalizzati, integrazione stretta con il CRM — la guida Python qui sopra fa al caso tuo. E per uno sguardo più ampio sul panorama degli strumenti di scraping, dai un’occhiata alla nostra rassegna delle oppure alla guida su .
FAQ
Posso fare scraping di Yelp gratis con Python?
Sì — usando librerie gratuite come curl_cffi, parsel e jmespath. Ma a volumi reali (più di poche decine di pagine), avrai bisogno di proxy residenziali a pagamento, che partono da circa . Thunderbit offre anche un piano gratuito con 6 pagine al mese per estrazioni rapide e no-code.
Yelp blocca gli scraper?
Sì, in modo aggressivo. Yelp usa . requests puro viene bloccato al primo colpo. La strategia anti-blocco a più livelli di questa guida — curl_cffi per l’impersonificazione TLS, header realistici, ritardi casuali e proxy residenziali — è ciò che funziona nel 2025.
La Yelp Fusion API è migliore dello scraping?
Dipende dalle esigenze. L’API è autorizzata e a basso rischio, ma restituisce solo , limita i risultati di ricerca a 240 e parte da $29/mese. Se ti servono il testo completo delle recensioni, i metadati o più di qualche centinaio di record al giorno, lo scraping è l’unica strada.
Come faccio a estrarre recensioni Yelp con Python?
Usa curl_cffi con impersonate="chrome131" per scaricare la pagina business, prendi l’ID business codificato da <meta name="yelp-biz-id">, poi fai una POST a https://www.yelp.com/gql/batch con l’operazione GetBusinessReviewFeed e paginazione tramite cursor after codificato in base64. Il codice passo per passo è nella sezione tutorial sopra. Anche il è un’ottima implementazione di riferimento.
Posso fare scraping di Yelp senza programmare?
Sì — include template già pronti per e . Apri una pagina Yelp, fai clic su AI Suggest Fields, poi su Scrape. Le esportazioni verso Google Sheets, Excel, Airtable e Notion sono gratuite in ogni piano, incluso quello free.
Scopri di più