Walmart cambia i prezzi di alcuni articoli . Se hai mai provato a monitorarli in modo programmatico, sai bene quanto possa essere frustrante: lo script funziona per 20 minuti e poi, senza alcun avviso, inizia a restituire pagine CAPTCHA mascherate da normali risposte 200 OK.
Ho dedicato tantissimo tempo a studiare le difese anti-bot di Walmart nel nostro lavoro di estrazione dati su e voglio condividere tutto quello che ho imparato: i metodi che funzionano davvero nel 2025, i fallimenti silenziosi che corrompono i dati e i compromessi reali tra scrivere uno scraper personalizzato, pagare una scraping API o usare semplicemente uno strumento no-code. Questa guida copre tre metodi di estrazione (parsing HTML, JSON di __NEXT_DATA__ e intercettazione delle API interne), la gestione degli errori pronta per la produzione che la maggior parte dei tutorial ignora del tutto e un quadro decisionale concreto per scegliere l’approccio giusto. Qui trovi qualcosa di utile sia se scrivi in Python, sia se vuoi solo un foglio di calcolo pieno di prezzi entro l’ora di pranzo.
Perché fare scraping di Walmart con Python?
Walmart è il più grande rivenditore al mondo per fatturato — nell’esercizio 2025, mantenendo il . Il sito ospita circa , e il CFO di Walmart ha parlato di sul marketplace. Circa , il che rende il catalogo estremamente variabile: i venditori cambiano, le varianti si modificano e le scorte fluttuano ogni giorno.
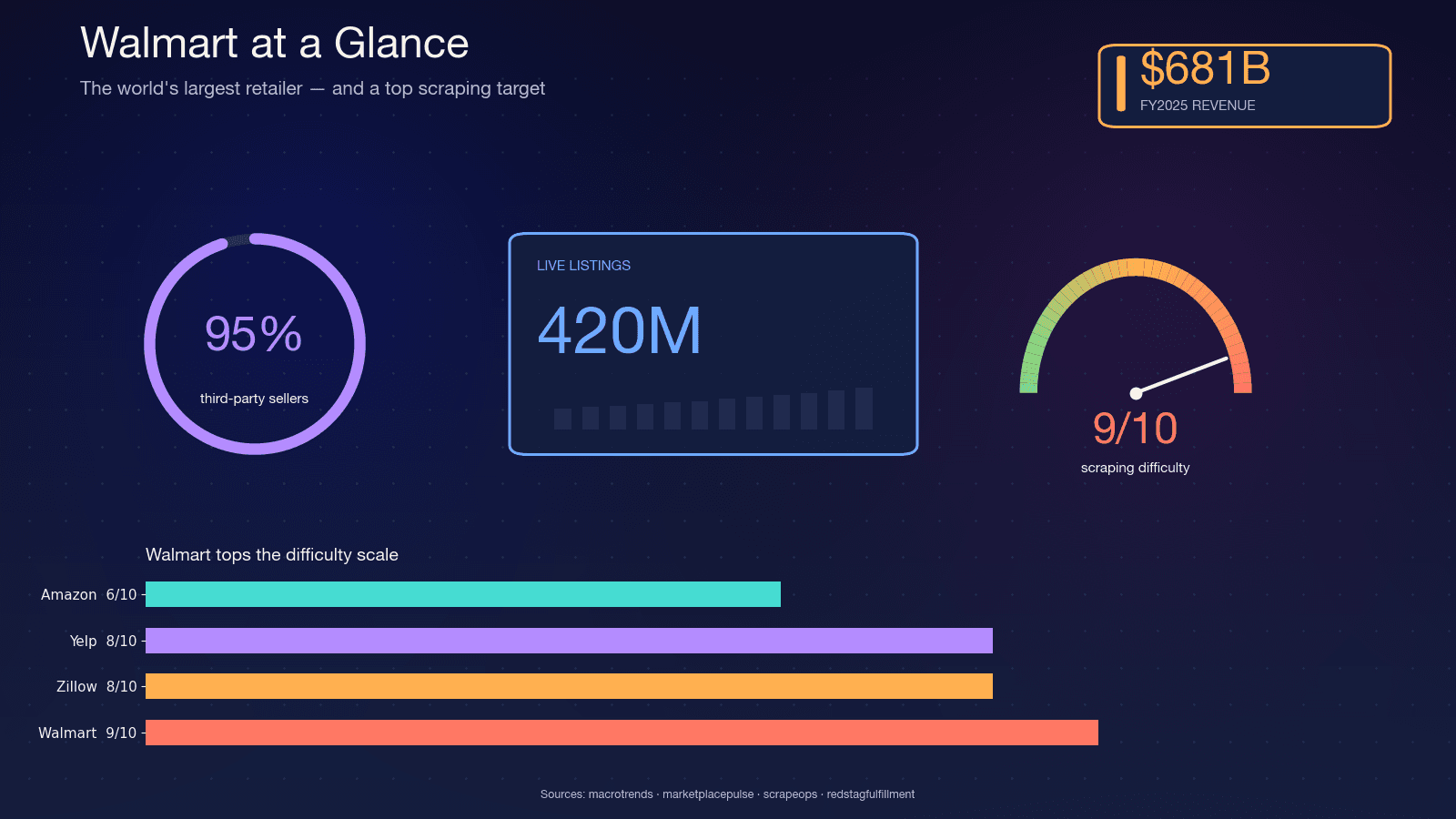
È proprio questa variabilità a rendere importante lo scraping. Un report trimestrale non può catturare ciò che uno scraping notturno riesce a vedere. Ecco i casi d’uso più comuni che incontro:
| Caso d'uso | Chi ne ha bisogno | Cosa estrae |
|---|---|---|
| Monitoraggio prezzi dei concorrenti | E-commerce, strumenti di repricing | Prezzi, promozioni, conformità MAP |
| Arricchimento del catalogo prodotti | Team sales e merchandising | Descrizioni, immagini, specifiche, varianti |
| Monitoraggio disponibilità stock | Supply chain, dropshipper | Stato inventario, info venditore |
| Ricerca di mercato e analisi trend | Marketing, product manager | Valutazioni, recensioni, assortimento categorie |
| Generazione lead | Team sales | Nomi dei venditori, numero di prodotti, categorie |
Il solo mercato del software per il e si prevede che arrivi a 5,09 miliardi entro il 2033. Il comportamento dei consumatori alimenta questa spesa: , e l’83% confronta i prezzi su più siti.
Python è il linguaggio di riferimento per questo tipo di lavoro. Il rapporto 2026 di Apify sull’infrastruttura indica , e la libreria centrale (requests) registra . Se fai scraping su qualsiasi scala, è quasi certo che tu lo stia facendo in Python.
Perché Walmart è uno dei siti più difficili da sottoporre a scraping
Walmart è particolarmente difficile perché esegue due prodotti commerciali anti-bot in serie: come layer WAF edge e di fingerprinting TLS, e come layer di sfida JavaScript comportamentale. Scrape.do definisce questa combinazione "rara ed estremamente difficile da bypassare".
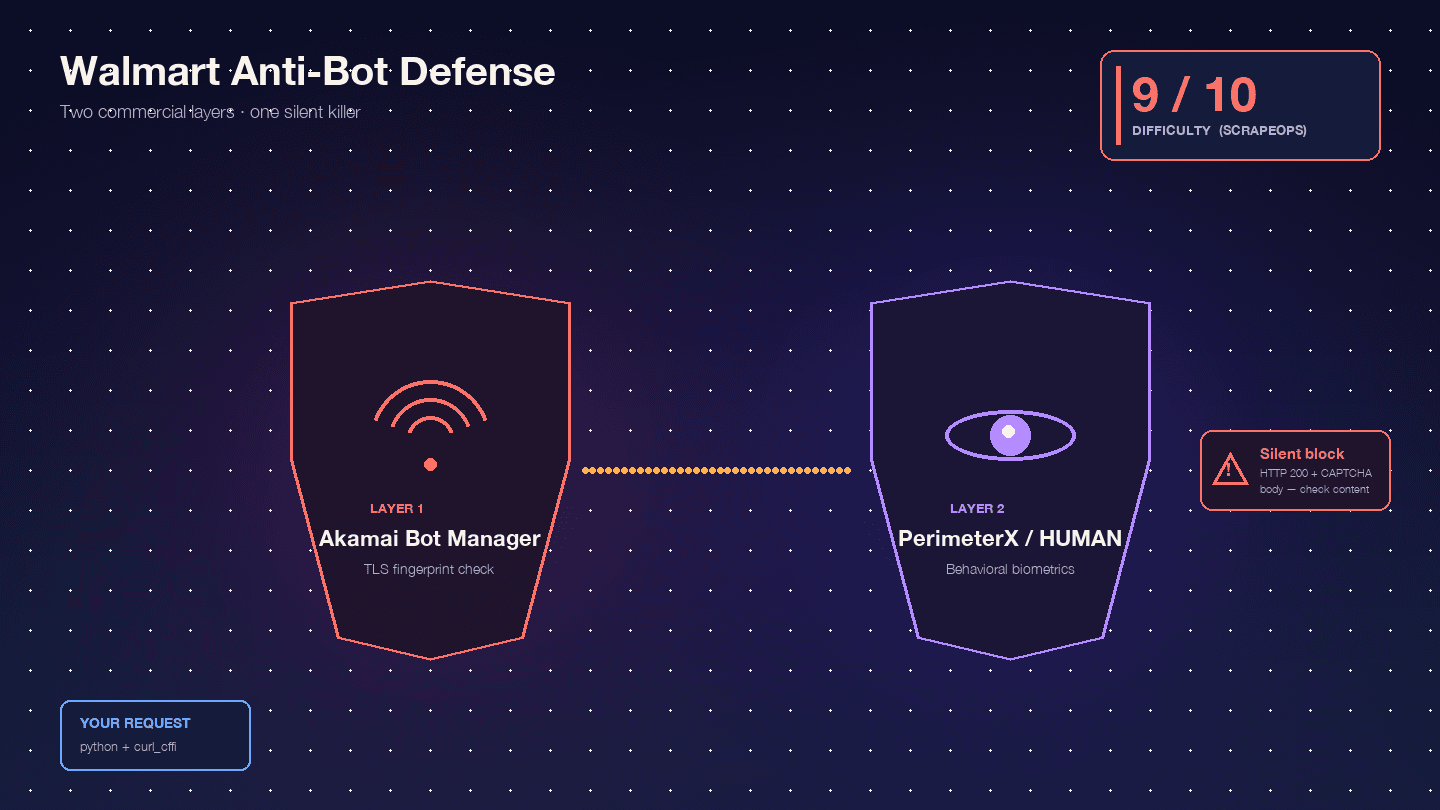
, con Akamai da solo a 9/10. Per esperienza, è una valutazione corretta.
Ecco con cosa hai davvero a che fare:
Akamai Bot Manager ispeziona il fingerprint TLS (hash JA3/JA4), l’ordine dei frame HTTP/2, l’ordine e il casing delle intestazioni e i cookie di sessione (_abck, ak_bmsc). Una chiamata standard di Python requests emette un fingerprint TLS che nessun browser reale produce — Akamai lo segnala prima ancora che la richiesta raggiunga i server di Walmart.
PerimeterX/HUMAN entra in azione dopo Akamai ed esegue fingerprinting JavaScript (px.js) che controlla le proprietà di navigator, il rendering canvas, WebGL, l’audio context e i biometrics comportamentali (movimenti del mouse, velocità di scorrimento, dinamica della digitazione). Il fallimento visibile è il famigerato — un pulsante che devi tenere premuto per circa 10 secondi mentre vengono campionati i segnali comportamentali. Oxylabs è molto diretto: "Walmart usa il modello CAPTCHA 'Press & Hold', fornito da PerimeterX, che è noto per essere quasi impossibile da risolvere via codice".
Il comportamento davvero pericoloso è il blocco silenzioso. Walmart restituisce HTTP 200 con un corpo CAPTCHA invece di un 403. : "Walmart restituisce uno status code 200 OK anche quando mostra una pagina CAPTCHA. Non puoi affidarti solo allo status code per capire se la richiesta è andata a buon fine." Lo script analizza felicemente l’HTML del CAPTCHA come se fosse un "prodotto non trovato" e va avanti. Metà del dataset diventa spazzatura, e non te ne accorgi.
Poi c’è il problema dei dati vincolati al negozio. I prezzi e le disponibilità di Walmart dipendono dalla località, controllati da cookie come locDataV3 e assortmentStoreId. Senza i cookie giusti, ottieni dati "nazionali di default" che possono sembrare completi ma non corrispondono a ciò che vede un vero cliente. I cookie mancanti non producono una pagina di blocco — producono dati sbagliati senza alcun errore visibile, che è peggio.
Tre metodi per estrarre dati da Walmart (e come si confrontano)
Prima della guida passo per passo, ecco i tre principali approcci di estrazione. La maggior parte dei tutorial concorrenti ne copre solo uno o due. Li vedremo tutti e tre, così puoi scegliere quello più adatto al tuo caso.
| Metodo | Affidabilità | Completezza dei dati | Difficoltà anti-bot | Carico di manutenzione |
|---|---|---|---|---|
| HTML + BeautifulSoup | ⚠️ Bassa (i selettori si rompono a ogni deploy) | Media | Alta | Alta |
JSON __NEXT_DATA__ | ✅ Buona | Alta | Medio-alta | Media |
| Intercettazione API interne | ✅ Migliore | Massima (varianti, stock, recensioni) | Medio-alta | Bassa (JSON strutturato) |
| Thunderbit (no-code) | ✅ Buona | Alta | Bassa (gestita dall’IA) | Nessuna |
Il parsing HTML è l’opzione peggiore per Walmart: il sito usa bundle Next.js con classi CSS hashate che cambiano a ogni deploy. Il metodo JSON di __NEXT_DATA__ è la scelta pragmatica usata da ogni serio scraper open-source di Walmart del periodo 2024–2026. L’intercettazione delle API interne è la più potente, ma comporta caveat che la maggior parte dei tutorial ignora. E Thunderbit è la scelta giusta quando non ti serve affatto una pipeline personalizzata.
Configurare l’ambiente Python per fare scraping di Walmart
Ti serve questo:
- Difficoltà: Intermedia
- Tempo richiesto: circa 30 minuti per la configurazione, più il tempo di sviluppo
- Cosa ti serve: Python 3.10+, pip, un editor di codice e, per l’uso in produzione, un servizio proxy o una scraping API
Crea la cartella del progetto e l’ambiente virtuale:
1mkdir walmart-scraper && cd walmart-scraper
2python -m venv venv
3source venv/bin/activate # Su Windows: venv\Scripts\activateInstalla le librerie necessarie:
1pip install curl_cffi parsel beautifulsoup4 lxmlcurl_cffi è lo standard del 2025 per fare scraping di target difficili. È un binding di libcurl che può impersonare con precisione il fingerprint TLS di un browser. : "Walmart usa il fingerprinting TLS come parte del suo rilevamento bot e nemmeno impostare l’User-Agent per simulare un browser reale lo aggira." Il semplice requests o httpx non può superare Akamai, indipendentemente dalle intestazioni impostate. È curl_cffi con impersonate="chrome124" a fare la differenza.
Ti serviranno anche json (incluso nella libreria standard), csv (incluso), time, random e logging per i pattern di produzione che vedremo più avanti.
Passo per passo: fare scraping delle pagine prodotto Walmart con Python
Passo 1: recuperare la pagina prodotto Walmart
Il primo compito è fare una richiesta HTTP che non venga bloccata immediatamente. Ecco l’insieme di header canonico usato in modo ricorrente da Scrapfly, Scrapingdog, Oxylabs e ScrapeOps nel periodo 2024–2026:
1from curl_cffi import requests
2HEADERS = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
5 "AppleWebKit/537.36 (KHTML, like Gecko) "
6 "Chrome/124.0.0.0 Safari/537.36"
7 ),
8 "Accept": (
9 "text/html,application/xhtml+xml,application/xml;q=0.9,"
10 "image/avif,image/webp,*/*;q=0.8"
11 ),
12 "Accept-Language": "en-US,en;q=0.9",
13 "Accept-Encoding": "gzip, deflate, br",
14 "Upgrade-Insecure-Requests": "1",
15 "Sec-Fetch-Dest": "document",
16 "Sec-Fetch-Mode": "navigate",
17 "Sec-Fetch-Site": "none",
18 "Sec-Fetch-User": "?1",
19 "Referer": "https://www.google.com/",
20}
21session = requests.Session(impersonate="chrome124")
22url = "https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/1752657021"
23response = session.get(url, headers=HEADERS)Il parametro impersonate="chrome124" sta facendo il grosso del lavoro. Dice a curl_cffi di corrispondere esattamente al ClientHello TLS, all’ordine dei frame HTTP/2 e alla sequenza dei pseudo-header di Chrome 124. Senza di esso, Akamai vede un hash JA3 specifico di Python e blocca la richiesta prima ancora che raggiunga il livello applicativo di Walmart.
Come appare una risposta bloccata: se vedi "Robot or human?" nel titolo HTML della risposta, oppure se la risposta reindirizza a walmart.com/blocked, sei stato intercettato. La parte insidiosa è che Walmart spesso restituisce uno status 200 con il corpo CAPTCHA — quindi controllare solo response.ok non basta.
Per qualsiasi uso in produzione o ripetuto, ti serviranno proxy residenziali. Gli IP datacenter vengono bruciati quasi subito dal sistema di reputazione IP di Akamai. Nella sezione sulla produzione vedremo la strategia completa di gestione degli errori e dei proxy.
Passo 2: estrarre i dati prodotto dal JSON di __NEXT_DATA__
Walmart.com è un’applicazione Next.js e l’HTML renderizzato lato server incorpora il payload completo di hydration all’interno di un singolo tag script: <script id="__NEXT_DATA__" type="application/json">. Questa è la miniera d’oro.
: "Nel 2026, Walmart usa Next.js con JSON strutturato nei tag script __NEXT_DATA__, rendendo l’estrazione dei dati nascosti più affidabile del tradizionale parsing dei selettori CSS." Ogni scraper open-source di Walmart molto noto — , , — usa questo metodo.
Ecco come estrarlo:
1import json
2from parsel import Selector
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6product = data["props"]["pageProps"]["initialData"]["data"]["product"]
7idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})La maggior parte dei tutorial si ferma qui. Qui sotto trovi una mappa completa dei percorsi JSON per i campi che contano davvero — verificata su pagine Walmart live nel 2024–2026:
| Campo dati | Percorso JSON (sotto initialData) | Tipo | Note |
|---|---|---|---|
| Nome prodotto | data > product > name | Stringa | — |
| Marca | data > product > brand | Stringa | — |
| Prezzo attuale (numero) | data > product > priceInfo > currentPrice > price | Float | Può differire in base al cookie del negozio |
| Prezzo attuale (stringa) | data > product > priceInfo > currentPrice > priceString | Stringa | Formattato, ad es. "$9.99" |
| Breve descrizione | data > product > shortDescription | Stringa HTML | Analizza con BeautifulSoup per ottenere testo |
| Descrizione estesa | data > idml > longDescription | Stringa HTML | Si trova su idml, NON dentro product — è qui che i tutorial più vecchi sbagliano |
| Tutte le immagini | data > product > imageInfo > allImages | Array | Elenco di oggetti {id, url} |
| Valutazione media | data > product > averageRating | Float | La chiave è averageRating, non il vecchio rating |
| Numero di recensioni | data > product > numberOfReviews | Intero | — |
| Varianti | data > product > variantCriteria | Array | Gruppi di opzioni (taglia, colore) |
| Disponibilità | data > product > availabilityStatus | Stringa | IN_STOCK, OUT_OF_STOCK, LIMITED_STOCK |
| Venditore | data > product > sellerDisplayName | Stringa | — |
| Produttore | data > product > manufacturerName | Stringa | — |
Il percorso longDescription è la trappola che fa cadere molte persone. Un post di ScrapeHero del 2023 lo collocava in product.longDescription, ma le fonti dal 2024 in poi lo indicano costantemente nella chiave sorella idml. Leggi sempre prima idml.longDescription e, per le pagine più vecchie, fai il fallback su product.longDescription.
Ecco il pattern di estrazione sicura con catene .get():
1def extract_product(data):
2 product = data["props"]["pageProps"]["initialData"]["data"]["product"]
3 idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})
4 price_info = product.get("priceInfo", {})
5 current_price = price_info.get("currentPrice", {})
6 image_info = product.get("imageInfo", {})
7 return {
8 "name": product.get("name"),
9 "brand": product.get("brand"),
10 "price": current_price.get("price"),
11 "price_string": current_price.get("priceString"),
12 "short_desc": product.get("shortDescription"),
13 "long_desc": idml.get("longDescription", product.get("longDescription")),
14 "images": [img.get("url") for img in image_info.get("allImages", [])],
15 "rating": product.get("averageRating"),
16 "review_count": product.get("numberOfReviews"),
17 "variants": product.get("variantCriteria"),
18 "availability": product.get("availabilityStatus"),
19 "seller": product.get("sellerDisplayName"),
20 "manufacturer": product.get("manufacturerName"),
21 }Per chi non vuole affatto gestire la navigazione dei percorsi JSON, identifica e struttura automaticamente questi campi — senza mappare manualmente i percorsi. Fai clic su "AI Suggest Fields", legge la pagina e ottieni una tabella. Ma se stai costruendo una pipeline personalizzata, la mappa sopra è il tuo riferimento.
Passo 3: intercettare gli endpoint API interni di Walmart per ottenere dati più ricchi
Nessun articolo concorrente copre bene questo metodo. È il percorso di estrazione più potente — e il più complicato.
Il front-end di Walmart chiama un . Gli endpoint vivono sotto www.walmart.com/orchestra/*:
/orchestra/pdp/graphql/...— hydration dei dettagli prodotto + cambi variante/orchestra/snb/graphql/...— paginazione search-n-browse/orchestra/reviews/graphql/...— recensioni paginate
Questi restituiscono JSON pulito e strutturato con dati che __NEXT_DATA__ a volte tronca — prezzi a livello di variante, quantità stock in tempo reale, paginazione completa delle recensioni.
Il punto critico che i post del blog aggirano: Walmart usa . Il body della richiesta invia solo un hash SHA-256 (persistedQuery.sha256Hash), non il testo della query. Se l’hash non è noto al server, ottieni PersistedQueryNotFound. Walmart ruota questi hash a ogni deploy. Ecco perché nessuno dei più noti scraper open-source di Walmart pubblica codice /orchestra/ copiabile e incollabile.
La versione pratica e onesta di questo metodo è un esercizio con DevTools:
- Apri una pagina prodotto Walmart in Chrome
- Apri DevTools → scheda Network, filtra per "Fetch/XHR"
- Naviga normalmente nella pagina — clicca sulle varianti, scorri fino alle recensioni, cambia la località del negozio
- Cerca richieste agli endpoint
/orchestra/*che restituiscono JSON con i dati prodotto - Fai clic destro sulla richiesta → "Copy as cURL"
- Converti il comando cURL in Python usando
curl_cffi
Ecco come appare una chiamata API riprodotta:
1import json
2from curl_cffi import requests
3session = requests.Session(impersonate="chrome124")
4# Prima riscalda la sessione visitando la pagina prodotto
5session.get("https://www.walmart.com/ip/some-product/1234567", headers=HEADERS)
6# Poi riproduci la chiamata API interna (copiata da DevTools)
7api_url = "https://www.walmart.com/orchestra/pdp/graphql"
8api_headers = {
9 **HEADERS,
10 "accept": "application/json",
11 "content-type": "application/json",
12 "referer": "https://www.walmart.com/ip/some-product/1234567",
13 "wm_qos.correlation_id": "your-copied-correlation-id",
14}
15payload = {
16 # Incolla qui il body esatto della richiesta da DevTools
17 "variables": {"productId": "1234567"},
18 "extensions": {
19 "persistedQuery": {
20 "version": 1,
21 "sha256Hash": "the-hash-you-copied"
22 }
23 }
24}
25api_response = session.post(api_url, headers=api_headers, json=payload)
26api_data = api_response.json()La fase di riscaldamento della sessione è fondamentale. I cookie PerimeterX di Walmart (_px3, _pxhd, ACID) devono essere impostati dal fetch HTML iniziale prima che la chiamata API possa avere successo. Senza di essi, otterrai un 412 o un 403.
Quando usare questo metodo: quando ti servono dati che __NEXT_DATA__ non include — prezzi profondi per variante, conteggi stock in tempo reale o dati delle recensioni oltre il primo batch. Per la maggior parte dei casi d’uso, __NEXT_DATA__ è sufficiente e molto più semplice.
Fare scraping dei risultati di ricerca Walmart e di più pagine
I risultati di ricerca seguono un pattern simile a __NEXT_DATA__, ma con un percorso JSON diverso:
1search_url = "https://www.walmart.com/search?q=laptops&page=1"
2response = session.get(search_url, headers=HEADERS)
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6search_result = data["props"]["pageProps"]["initialData"]["searchResult"]
7items = search_result["itemStacks"][0]["items"]
8# Filtra i prodotti sponsorizzati
9organic_items = [i for i in items if i.get("__typename") == "Product"]
10for item in organic_items:
11 print(item.get("name"), item.get("priceInfo", {}).get("currentPrice", {}).get("price"))La paginazione funziona incrementando il parametro page: &page=1, &page=2 e così via. Ma c’è un limite non documentato: Walmart limita i risultati di ricerca a 25 pagine, indipendentemente dal totale effettivo. : "Walmart imposta a 25 il numero massimo di pagine di risultati accessibili, indipendentemente dal numero totale di pagine disponibili."
Soluzioni alternative per ottenere una copertura più ampia:
- Inversione dell’ordine di ordinamento: esegui la stessa query con
&sort=price_lowe poi con&sort=price_highper ottenere circa 50 pagine di copertura - Suddivisione per intervallo di prezzo: aggiungi
&min_price=X&max_price=Yper dividere il catalogo in finestre più piccole - Suddivisione per categoria: cerca all’interno di categorie specifiche invece che su tutto il sito
Nota che itemStacks è un array. Scrapfly nel proprio repository usa in modo fisso [0], ma le pagine categoria e browse a volte contengono più stack ("Top picks", "More results"). Il pattern robusto itera tutti gli stack:
1for stack in search_result.get("itemStacks", []):
2 for item in stack.get("items", []):
3 if item.get("__typename") == "Product":
4 # processa l'elemento
5 passVale anche la pena notare che il robots.txt di Walmart . Le pagine prodotto (/ip/...) e la maggior parte delle pagine categoria (/cp/...) non sono disallowate. Se ti preoccupa la conformità, parti dalle pagine prodotto e dagli alberi di categoria invece che dalla ricerca.
Non lasciare che i blocchi silenziosi rovinino i tuoi dati: gestione degli errori pronta per la produzione
La maggior parte dei tutorial qui si sgretola. Ti mostrano come recuperare una pagina, analizzare un prodotto e fermarti lì. In produzione, stai recuperando migliaia di pagine, e Walmart sta attivamente cercando di fermarti. La differenza tra uno scraper demo e uno che funziona davvero sta nel modo in cui gestisce i fallimenti.
Rilevare i blocchi silenziosi prima che corrompano i dati
La singola funzione più importante in uno scraper Walmart è il rilevatore di blocchi. Sulla base del consenso dei vendor tra , , e , servono quattro controlli indipendenti:
1BLOCK_MARKERS = (
2 "Robot or human",
3 "Press & Hold",
4 "Press & Hold",
5 "px-captcha",
6 "perimeterx",
7)
8def is_walmart_blocked(response) -> bool:
9 # 1. Redirect verso l'endpoint di blocco dedicato
10 if "/blocked" in str(response.url):
11 return True
12 # 2. Codici di stato critici
13 if response.status_code in (403, 412, 428, 429, 503):
14 return True
15 # 3. 200 OK con body CAPTCHA (il caso di blocco silenzioso)
16 body = response.text or ""
17 if any(m.lower() in body.lower() for m in BLOCK_MARKERS):
18 return True
19 # 4. Controllo della lunghezza della risposta — i PDP reali sono 300-900 KB
20 if len(response.content) < 50_000 and "/ip/" in str(response.url):
21 return True
22 return FalseQuel quarto controllo — la lunghezza della risposta — intercetta i casi in cui Walmart restituisce una pagina ridotta che non contiene marker CAPTCHA evidenti ma nemmeno i dati prodotto necessari.
Logica di retry con exponential backoff e jitter
Quando una richiesta fallisce, non vuoi martellare subito Walmart. Il pattern standard usa exponential backoff con jitter per desincronizzare i retry:
1import time
2import random
3import logging
4from curl_cffi import requests as cffi_requests
5log = logging.getLogger("walmart")
6def fetch_with_retry(session, url, max_retries=5, base_delay=2, max_delay=60):
7 for attempt in range(max_retries):
8 try:
9 response = session.get(url, headers=HEADERS, timeout=15)
10 if response.status_code in (429, 503):
11 raise Exception(f"Throttled: \{response.status_code\}")
12 if is_walmart_blocked(response):
13 raise Exception("Silent block detected")
14 return response
15 except Exception as e:
16 if attempt == max_retries - 1:
17 raise
18 wait = min(max_delay, base_delay * (2 ** attempt)) + random.uniform(0, 3)
19 log.warning(f"Tentativo {attempt + 1} fallito: \{e\}. Nuovo tentativo tra {wait:.1f}s")
20 time.sleep(wait)
21 return NoneIl jitter (random.uniform(0, 3)) non è estetico — desincronizza i worker, così una flotta di scraper non ritenta nello stesso secondo e non fa scattare i rilevatori di velocità di Akamai.
Limitazione della frequenza
Sia sia convergono su un ritardo casuale di 3–6 secondi per richiesta per Walmart: "limita le richieste aspettando 3–6 secondi tra il caricamento di una pagina e l’altra e randomizza i ritardi".
1import time
2import random
3def rate_limited_fetch(session, url):
4 response = fetch_with_retry(session, url)
5 time.sleep(random.uniform(3.0, 6.0))
6 return responseSu scala più ampia, considera aiolimiter per il rate limiting asincrono:
1from aiolimiter import AsyncLimiter
2limiter = AsyncLimiter(max_rate=10, time_period=60) # 10 richieste al minutoValidazione dei dati
Anche quando la risposta non è bloccata, i dati analizzati potrebbero essere errati (negozio sbagliato, payload degradato). Valida prima di scrivere l’output:
1def validate_product(product):
2 """Restituisce True se i dati del prodotto sembrano legittimi."""
3 if not product.get("name"):
4 return False
5 price = (product.get("priceInfo") or {}).get("currentPrice", {}).get("price")
6 if not isinstance(price, (int, float)) or price <= 0:
7 return False
8 if product.get("availabilityStatus") not in ("IN_STOCK", "OUT_OF_STOCK", "LIMITED_STOCK"):
9 return False
10 return TrueLogging di sessione
Tieni traccia del tasso di successo per sessione. Quando scende sotto l’80% per 10 minuti, qualcosa è cambiato: o il tuo IP è bruciato, o i cookie sono scaduti, o Walmart ha distribuito una nuova regola anti-bot.
1class ScrapeMetrics:
2 def __init__(self):
3 self.total = 0
4 self.success = 0
5 self.blocks = 0
6 self.errors = 0
7 def record(self, result):
8 self.total += 1
9 if result == "success":
10 self.success += 1
11 elif result == "blocked":
12 self.blocks += 1
13 else:
14 self.errors += 1
15 @property
16 def success_rate(self):
17 return (self.success / self.total * 100) if self.total > 0 else 0
18 def check_health(self):
19 if self.total > 20 and self.success_rate < 80:
20 log.critical(f"Il tasso di successo è sceso al {self.success_rate:.1f}% — valuta di ruotare i proxy o mettere in pausa")Niente di glamour. Ma è ciò che mantiene puliti i dati.
Python fai-da-te vs. scraping API vs. no-code: scegliere il modo giusto per fare scraping di Walmart
Molti sviluppatori saltano subito alla scrittura di uno scraper personalizzato senza chiedersi se sia davvero la scelta giusta. . Gli utenti dei forum lo descrivono come "praticamente 9/10" e si chiedono se "una scraping API dedicata sarebbe eccessiva". La risposta dipende da volume, budget e capacità ingegneristiche.
| Fattore | Python fai-da-te (requests + proxy) | Scraping API (Oxylabs, Bright Data, ecc.) | Strumento no-code (Thunderbit) |
|---|---|---|---|
| Tempo di setup per la prima riga | Ore | 15–60 min | ~2 min |
| Tempo di setup per la produzione | 40–80 ore | 4–16 ore | ~30 min |
| Gestione anti-bot | La gestisci tu (difficile) | Gestita dal provider | Gestita automaticamente |
| Costo su piccola scala (<1K pagine/mese) | Basso (proxy ~4–8 $/GB) | Piani base da 40–49 $/mese | Gratis–15 $/mese |
| Costo su larga scala (100K+ pagine/mese) | Minore per richiesta | Maggiore per richiesta | Variabile |
| Personalizzazione | Controllo completo | Parametri API | Limitata da UI/campi |
| Manutenzione continua | 4–8 ore/mese | Quasi zero | Nessuna (si adatta l’IA) |
| Ideale per | Sviluppatori che costruiscono pipeline personalizzate | Scraping di produzione su scala media | Utenti business, estrazioni rapide occasionali |
Quando ha senso il Python fai-da-te
Il fai-da-te vince quando hai già un contratto proxy, ti serve un controllo rigoroso su header, targeting per CAP o gruppi di venditori, stai indicizzando milioni di pagine al mese dove le fee API per record si accumulano, oppure ti servono garanzie on-prem o di compliance. Il compromesso è il tempo reale di engineering: uno spider Scrapy pronto per la produzione con paginazione, retry, rotazione proxy, impersonificazione TLS e schemi multipli per tipi di pagina richiede , più 4–8 ore al mese di manutenzione mentre Walmart ruota i fingerprint.
Quando una scraping API ti fa risparmiare tempo
Le scraping API gestiscono il layer anti-bot al posto tuo. I mostrano tassi di successo del e del 98% per Scrape.do su Walmart. I prezzi entry-level partono da 40–49 $/mese per strumenti come , e . Se sei un team di 2–5 ingegneri e il tuo volume di scraping è tra 10K e 1M di pagine al mese, un’API è quasi sempre la scelta giusta. Scambi il costo per richiesta con manutenzione praticamente nulla.
Quando il no-code è la scelta giusta
si adatta a un profilo diverso. Se sei un PM, un analista o un operatore e-commerce che ha bisogno dei dati prodotto Walmart in un foglio di calcolo questo pomeriggio — non nel prossimo sprint — uno strumento no-code è la risposta più onesta.
Il flusso di lavoro: installa la , vai su una pagina prodotto o di ricerca Walmart, fai clic su "AI Suggest Fields" e l’IA di Thunderbit legge la pagina e suggerisce le colonne (nome prodotto, prezzo, valutazione, ecc.). Fai clic su "Scrape" e i dati vengono popolati in una tabella. Esporta in Excel, Google Sheets, Airtable o Notion — tutto gratis, senza paywall.
Thunderbit gestisce l’anti-bot nel cloud, quindi non devi occuparti di CAPTCHA, proxy o fingerprinting TLS. L’IA si adatta automaticamente ai cambiamenti di layout, quindi non c’è manutenzione. Per chi non vuole proprio gestire la navigazione dei percorsi JSON, questa è la strada con meno attrito.
Limiti sinceri: Thunderbit non è pensato per 100K+ pagine al giorno. I budget in crediti e i limiti cloud rendono ingestioni ad alto volume poco economiche rispetto alle API pure. Inoltre non puoi fissare un CAP specifico o un ASN, a meno che lo strumento non lo supporti. Per pipeline continue e ad alto volume, il fai-da-te o una scraping API restano la scelta migliore.
Prezzi a spanne: 1.000 righe di prodotti Walmart su Thunderbit costano circa 2.000 crediti (circa 0,60–1,10 $ nei piani Starter/Pro). È comparabile all’API Walmart di Oxylabs e più economico di molte API di scraping per hobbisti a basso volume. per i dettagli aggiornati.
Esportare i dati Walmart estratti
Una volta ottenuti i dati, devi metterli in un formato utile. Tre formati coprono la maggior parte delle esigenze:
CSV — il formato base che gli analisti aprono davvero:
1import csv
2def export_csv(products, filename="walmart_products.csv"):
3 fieldnames = ["name", "price", "availability", "rating", "review_count", "seller", "url"]
4 with open(filename, "w", newline="", encoding="utf-8-sig") as f:
5 writer = csv.DictWriter(f, fieldnames=fieldnames, quoting=csv.QUOTE_MINIMAL)
6 writer.writeheader()
7 for p in products:
8 writer.writerow({k: p.get(k) for k in fieldnames})Usa la codifica utf-8-sig per la compatibilità con Excel. Il marker BOM evita che Excel rovini i caratteri speciali.
JSONL — il formato di produzione per le pipeline di scraping:
1import json
2import gzip
3def export_jsonl(products, filename="walmart_products.jsonl.gz"):
4 with gzip.open(filename, "at", encoding="utf-8") as f:
5 for p in products:
6 f.write(json.dumps(p, ensure_ascii=False) + "\n")(una scrittura interrotta perde solo l’ultima riga), è trasmissibile in streaming con memoria costante e mantiene intatti i dati annidati come varianti e recensioni.
Excel — per consegne una tantum agli analisti:
1from openpyxl import Workbook
2def export_excel(products, filename="walmart_products.xlsx"):
3 wb = Workbook(write_only=True)
4 ws = wb.create_sheet("Products")
5 ws.append(["Name", "Price", "Availability", "Rating", "Reviews", "Seller"])
6 for p in products:
7 ws.append([p.get("name"), p.get("price"), p.get("availability"),
8 p.get("rating"), p.get("review_count"), p.get("seller")])
9 wb.save(filename)Thunderbit copre lo scenario export anche per chi non usa Python: esportazione con un clic in Google Sheets, Airtable, Notion, Excel, CSV e JSON — tutto gratis nel piano base. Per il monitoraggio continuo, la funzione di scraper pianificato di Thunderbit può eseguire estrazioni ricorrenti in automatico.
Un avvertimento sulla pianificazione: . I runner di GitHub Actions si trovano su range IP Azure che l’anti-bot di Walmart blocca all’istante. Usa APScheduler su un VPS, oppure instrada tutto il traffico attraverso proxy residenziali.
Linee guida legali ed etiche per fare scraping di Walmart
Gli utenti dei forum esprimono esplicitamente questo timore: "Non mi dispiace giocare al gatto e al topo con gli sviluppatori, ma sono più cauto quando si tratta del loro team legale".
I Termini di utilizzo di Walmart l’uso di "qualsiasi robot, spider… o altro dispositivo manuale o automatico per recuperare, indicizzare, 'scrapare', 'data mine' o raccogliere in altro modo qualsiasi Materiale" senza "previo consenso scritto esplicito".
Il robots.txt di Walmart /search, /account, /api/ e decine di endpoint interni. Le pagine prodotto (/ip/...) e le recensioni (/reviews/product/) non sono disallowate.
Il precedente hiQ v. LinkedIn (9° Circuito, ) ha stabilito che fare scraping di dati pubblicamente accessibili difficilmente viola il CFAA federale. Ma lo stesso tribunale ha poi stabilito che e ha imposto un contro di essa. Decisioni più recenti del 2024 (, ) hanno ulteriormente ristretto il CFAA e creato difese basate sul preemption del copyright, ma quelle sentenze dipendevano da un linguaggio specifico dei ToU che non si applica in modo lineare a Walmart.
Linee guida pratiche: non sovraccaricare i server. Rispetta i limiti di velocità. Non fare scraping di dati personali o degli utenti. Usa i dati in modo responsabile. Fare scraping di pagine pubbliche di Walmart a un ritmo moderato per ricerca personale è un profilo di rischio molto diverso rispetto a fare scraping su scala commerciale in violazione dei Termini di Walmart. Se stai costruendo un prodotto basato sui dati Walmart, parla con un avvocato e valuta le API ufficiali di Walmart.
Disclaimer: queste informazioni hanno finalità educative e non costituiscono consulenza legale.
Conclusione e punti chiave
Fare scraping di Walmart con Python è una sfida da a causa del doppio stack anti-bot Akamai + PerimeterX. Non impossibile — ma servono gli strumenti e i pattern giusti.
Punti chiave:
- L’estrazione JSON da
__NEXT_DATA__è la scelta pragmatica per la maggior parte dei casi d’uso. È ciò che usano tutti gli scraper open-source seri di Walmart tra 2024 e 2026. Il percorso base èprops.pageProps.initialData.data.productper i PDP esearchResult.itemStacksper ricerca/browse. curl_cfficonimpersonate="chrome124"è obbligatorio. Il semplicerequestsohttpxnon può superare il fingerprinting TLS di Akamai, indipendentemente dagli header.- I blocchi silenziosi sono il vero pericolo. Walmart restituisce 200 OK con body CAPTCHA. Controlla il contenuto della risposta, non solo gli status code.
- Gli scraper di produzione hanno bisogno di più del codice del percorso felice. Exponential backoff con jitter, rilevamento blocchi su quattro segnali, rate limiting a 3–6 secondi per richiesta, validazione dei dati e monitoraggio della salute della sessione sono tutti essenziali.
- L’intercettazione delle API interne via
/orchestra/*è potente ma fragile. Usala come esercizio con DevTools per esigenze dati specifiche, non come metodo principale di estrazione. - Walmart limita i risultati di ricerca a 25 pagine. Vai più in profondità con inversione dell’ordine di ordinamento e suddivisione per intervallo di prezzo.
- Scegli con onestà il tuo approccio: Python fai-da-te per sviluppatori con esigenze personalizzate e volumi alti. Scraping API per team di media scala senza un ingegnere dello scraping. per utenti business che vogliono i dati in Google Sheets oggi pomeriggio.
Se vuoi provare la strada no-code, la ha un piano gratuito — puoi estrarre alcune pagine Walmart e vedere i risultati con i tuoi occhi. Se invece scegli Python, i pattern di codice di questo articolo sono testati in produzione. In ogni caso, ora hai una mappa delle difese di Walmart e tre strade per superarle.
Per approfondire le tecniche di web scraping, consulta le nostre guide su , e . Puoi anche guardare i tutorial sul .
FAQ
È legale fare scraping dei dati prodotto di Walmart?
I Termini di utilizzo di Walmart vietano lo scraping automatizzato senza consenso scritto. La sentenza hiQ v. LinkedIn del 9° Circuito (2022) ha stabilito che il CFAA federale difficilmente si applica allo scraping di pagine pubbliche, ma lo stesso caso si è concluso con un contro lo scraper. Fare scraping di pagine pubbliche a ritmo moderato per ricerca personale comporta un profilo di rischio molto diverso rispetto all’estrazione commerciale su larga scala. Consulta un avvocato se stai costruendo un business sui dati Walmart.
Perché il mio scraper Walmart continua a essere bloccato?
Le cause più comuni sono: uso di requests o httpx puri (che emettono un fingerprint TLS specifico di Python che Akamai segnala subito), header mancanti o errati, assenza di rotazione dei proxy, frequenze di richiesta più rapide di 3–6 secondi per pagina e cookie di sessione mancanti (_px3, _abck, locDataV3). Passa a curl_cffi con impersonate="chrome124", usa proxy residenziali e implementa i pattern di rilevamento blocchi e retry descritti in questo articolo.
Quali dati posso estrarre da Walmart con Python?
Nomi prodotto, prezzi (attuali e rollback), immagini, descrizioni brevi e lunghe, valutazioni, numero di recensioni, disponibilità stock, nomi dei venditori, informazioni sul produttore, opzioni di variante (taglia, colore) e posizionamento nelle categorie. Usando il metodo __NEXT_DATA__, tutti questi dati sono disponibili come JSON strutturato. L’intercettazione delle API interne può inoltre restituire prezzi a livello di variante, conteggi stock in tempo reale e dati delle recensioni paginate.
Ho bisogno di proxy per fare scraping di Walmart?
Sì, per qualsiasi uso in produzione o ripetuto. — anche con header perfetti, un IP non residenziale viene segnalato dal sistema di reputazione IP di Akamai. Sono necessari proxy residenziali o mobili. Gli IP datacenter vengono bruciati quasi immediatamente. Metti in conto circa 3–17 dollari ogni 1.000 pagine, a seconda del provider proxy e del piano.
Posso fare scraping di Walmart senza scrivere codice?
Sì. è un’estensione Chrome basata su IA che fa scraping di Walmart in due clic: "AI Suggest Fields" per rilevare automaticamente le colonne dei dati prodotto, poi "Scrape" per estrarli. Gestisce le sfide anti-bot nel cloud ed esporta direttamente in Excel, Google Sheets, Airtable o Notion — tutto gratis. È ideale per analisti, PM e utenti business che hanno bisogno di dati rapidamente senza costruire una pipeline personalizzata. Per scraping ad alto volume o molto personalizzato, Python o una scraping API restano la scelta migliore.
Scopri di più