Redfin aggiorna dalla pubblicazione. Un livello di aggiornamento così rapido è oro puro per chi costruisce una pipeline di dati immobiliari — ed è proprio il motivo per cui tanti scraper puntano Redfin e finiscono bloccati nel giro di pochi minuti.
Ho lavorato per anni su strumenti di estrazione dati in e posso dirtelo chiaro e tondo: il salto tra “scrape Redfin” e “scrape Redfin senza farsi bloccare” è il punto in cui la maggior parte delle guide si perde. Ti mostrano il codice con BeautifulSoup, saltano la parte in cui Cloudflare ti seppellisce le richieste e ti lasciano a fissare una pagina 403 chiedendoti dove sia l’errore. Questa guida è diversa. Ti accompagno in tre approcci concreti — parsing HTML, API nascosta di Redfin e una strada no-code con Thunderbit — dedicando spazio serio alle difese anti-bot che contano davvero. Alla fine saprai esattamente quale metodo si adatta al tuo livello, alla tua scala e alla tua tolleranza per la manutenzione.
Cos’è Redfin e perché i suoi dati sono importanti?
Redfin è un’agenzia immobiliare basata sulla tecnologia, con agenti stipendiati che recuperano gli annunci direttamente dai feed MLS. Copre e serve quasi 50 milioni di visitatori al mese. A differenza dei portali che fanno solo aggregazione, i dati di Redfin vengono verificati da agenti, e il suo Redfin Estimate AVM proprietario copre con un errore mediano di appena l’1,96% per le case sul mercato.
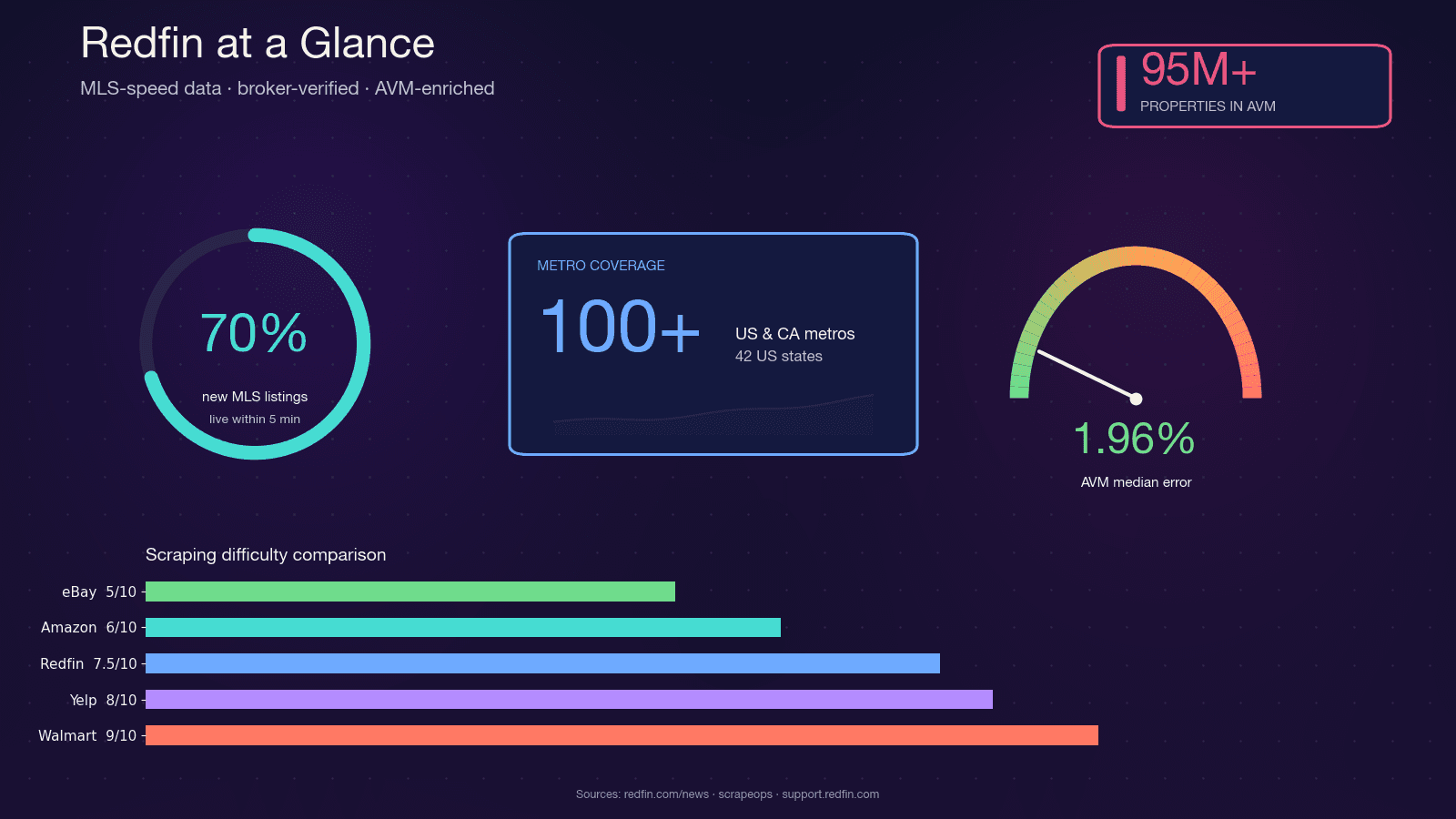
Questa combinazione — aggiornamento alla velocità del MLS, qualità verificata dal broker e un AVM molto accurato — è il motivo per cui investitori immobiliari, agenti, startup proptech e data analyst vogliono tutti un accesso programmatico ai dati di Redfin. Python è la scelta naturale: il suo ecosistema per lo scraping (requests, BeautifulSoup, Selenium, Playwright) è maturo, il supporto della community è enorme e l’integrazione con pandas e Jupyter per l’analisi è immediata.
Perché fare scraping di Redfin con Python?
I casi d’uso sono tanti quanto le persone che hanno bisogno di questi dati. Ecco come diversi profili utilizzano di solito i dati estratti da Redfin:
| Pubblico | Obiettivo principale di scraping | Caso d’uso di esempio |
|---|---|---|
| Agenti immobiliari | Generazione contatti, intelligence di mercato | Nuovi annunci e annunci scaduti nella propria area; directory agenti per confronto competitivo |
| Investitori immobiliari | Deal flow, analisi cap rate | Analisi del rendimento da locazione, individuazione di immobili sottovalutati, avvisi giornalieri sui nuovi annunci |
| Startup proptech | Pipeline di dati prodotto | Dati di training per AVM, dashboard di mercato, motori di acquisizione iBuyer |
| Data analyst | Ricerche di mercato, BI | Trend del prezzo mediano per ZIP code, serie storiche dei giorni sul mercato, rapporto vendita/listino |
| Wholesaler / flipper | Monitoraggio immobili in difficoltà | Rilevamento ribassi di prezzo, pignoramenti, comparabili fuori mercato |
Il trend generale conferma tutto questo: usa oggi analisi predittive per identificare opportunità e gestire il rischio. Il mercato PropTech dovrebbe raggiungere con un CAGR del 16,4%. I dati immobiliari strutturati non sono più un vantaggio extra: sono ormai una necessità.
Tutti i campi dati di Redfin che puoi estrarre (riferimento completo)
Prima di scrivere una sola riga di codice, devi sapere cosa è davvero disponibile. Ho analizzato le pagine dei risultati di ricerca, le schede dettaglio degli immobili e i profili agenti di Redfin — e ho incrociato il tutto con wrapper open source dell’API Stingray come i progetti e . Il totale arriva a 117 campi distinti tra le varie tipologie di pagina.
Questa tabella vale la pena salvarla nei preferiti. Conoscere lo schema dei dati prima di partire ti fa risparmiare ore di tentativi alla cieca con i selettori.
Campi della pagina dei risultati di ricerca
Sono i campi essenziali disponibili sulle card degli annunci — spesso estraibili senza rendering JavaScript completo:
| Campo | Tipo di dato | Note |
|---|---|---|
| ID immobile | Numero | Intero interno di Redfin, ricavato da /home/{id} nell’href |
| Prezzo di listino | Numero | |
| Indirizzo completo | Testo | |
| Letti / bagni / mq | Numero | Tre valori in sequenza |
| Tipo di immobile | Selezione singola | SFH, Condo, Townhouse, Multi |
| Stato | Testo | Active, Pending, Contingent |
| Giorni sul mercato | Numero | |
| Indicatore ribasso prezzo | Numero | Delta rispetto al prezzo iniziale |
| Foto principale | URL immagine | Una foto per card |
| Badge Hot Home | Booleano | |
| Data/ora open house | Testo | |
| Attribuzione agenzia | Testo |
Campi della pagina dettaglio immobile
La pagina dettaglio è dove si trova il vero valore. Molti di questi campi richiedono rendering JavaScript o l’API Stingray:
| Campo | Tipo di dato | Note |
|---|---|---|
| Redfin Estimate (sul mercato) | Numero | Tramite /stingray/api/home/details/avm |
| Redfin Estimate (fuori mercato) | Numero | Tramite /stingray/api/home/details/owner-estimate; errore mediano 7,52% |
| Anno di costruzione / ristrutturazione | Numero | |
| Dimensione lotto | Numero | |
| Spese HOA | Numero | Mensili, se previste |
| Tassa immobiliare annuale | Numero | |
| Valore catastale | Numero | |
| Tabella storico vendite | Tabella | Prezzo, data, tipo evento |
| Descrizione dell’immobile | Testo | Paragrafo marketing |
| URL foto (carousel) | URL immagini | 20+ per annuncio |
| Nome agente, telefono, email | Testo / Telefono / Email | Il telefono è spesso mascherato |
| Valutazioni scuole (elementari/medie/superiori) | Numero | Più nome del distretto |
| Walk / Transit / Bike Score | Numero | |
| Punteggi rischio climatico | Numero | Alluvione, incendio, calore, vento |
| Immobili simili attivi / venduti / vicini | URL | Dati del carousel |
| Parcheggio, garage, riscaldamento, raffreddamento | Testo | Gruppi di servizi |
Campi del profilo agente
| Campo | Tipo di dato | Note |
|---|---|---|
| Nome agente, foto, agenzia, bio | Testo / Immagine | |
| Telefono, modulo contatto | Telefono / Testo | Click-to-reveal |
| Numero di annunci attivi | Numero | |
| Vendite ultimi 12 mesi / volume totale | Numero | |
| Rapporto medio listino-vendita | Numero | |
| Valutazione a stelle / numero recensioni | Numero | |
| Anni di esperienza / n. licenza | Testo / Numero |
Quando usi la funzione AI Suggest Fields di Thunderbit su una pagina Redfin, il sistema rileva automaticamente la maggior parte di queste colonne e assegna il tipo di dato corretto — senza bisogno di mappare manualmente i selettori CSS. Ne parliamo tra poco.
Le difese anti-bot di Redfin spiegate bene (non solo “usa un proxy”)
Qui voglio essere molto chiaro, perché la maggior parte delle guide liquida il problema del blocco con un generico “compra proxy dal nostro sponsor”. Non basta. Se non capisci cosa fa Redfin per individuare gli scraper, finirai per bruciare credito proxy e verrai comunque bloccato. , mentre — “meno aggressiva del WAF enterprise di Zillow, ma basata su rate limiting personalizzato e challenge JavaScript”.
Redfin usa una struttura a più livelli: Cloudflare sul bordo (challenge JS, Turnstile, fingerprinting TLS/JA3) più un rate limiter applicativo specifico di Redfin. Nel loro robots.txt non c’è alcuna direttiva Crawl-delay, perché l’enforcement avviene a livello WAF.
Perché requests + BeautifulSoup da soli falliscono su Redfin
Se lanci un semplice requests.get() su una pagina immobile di Redfin con header di default, di solito succede questo:
- HTTP 403 — la challenge JS di Cloudflare non viene superata, quindi ricevi la pagina di challenge al posto dell’annuncio.
- Una pagina interstiziale di challenge — il body HTML contiene il widget Turnstile di Cloudflare, non i dati dell’immobile.
- HTTP 200 con HTML parziale — ottieni una shell con un grande blob JSON incorporato sotto
root.__reactServerState.InitialContext, ma senza card pre-renderizzate, senza storico prezzi e senza valutazioni scolastiche.
Redfin usa il proprio (non Next.js), e la chiave di hydration è specifica di Redfin — root.__reactServerState.InitialContext con i dati dell’annuncio annidati sotto ReactServerAgent.cache.dataCache. Non si tratta di __NEXT_DATA__ né di window.__INITIAL_STATE__.
La causa più comune dei 403 silenziosi? Mancano gli header Sec-Fetch-*. Redfin/Cloudflare controlla esplicitamente Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest e Sec-Fetch-User. Se mancano, vieni segnalato subito.
Il playbook di mitigazione: ritardi, header, proxy e sessioni
Ecco la panoramica completa, difesa per difesa, con le relative contromisure:
| Difesa di Redfin | Cosa fa | Segnale di rilevamento | Strategia di mitigazione |
|---|---|---|---|
| Challenge JS di Cloudflare | Interstiziale che rilascia il cookie cf_clearance | 403 + body HTML di Cloudflare | curl_cffi con impersonate="chrome120"; sessione riscaldata tramite homepage; proxy residenziale USA |
| Cloudflare Turnstile | CAPTCHA interattivo per sessioni a rischio | 403 + widget Turnstile | Browser headless con stealth + proxy residenziale |
| Errore Cloudflare 1020 (ban ASN) | Blocca IP/ASN segnalati a livello WAF | Body 403 "Error 1020 Access Denied" | Passare a proxy residenziale/mobile; mai usare ASN datacenter |
| Fingerprinting TLS/JA3 | Rileva stack TLS non browser | 403 silenzioso anche con header perfetti | Impersonificazione con curl_cffi o browser reale |
| Fingerprinting HTTP/2 | Controlla SETTINGS HTTP/2 e ordine HPACK | Blocco silenzioso | curl_cffi parla HTTP/2 come Chrome |
| Validazione header (UA, Sec-Fetch-*) | Set di header coerente con un browser | 403 alla prima richiesta | Header completi di Chrome inclusi Sec-Fetch-Site/Mode/Dest/User, Referer realistico |
| Continuità cookie/sessione | Traccia cf_clearance, RF_BROWSER_ID | Challenge su accessi diretti a URL profondi | Sessione persistente; prima visita alla homepage |
| Rate limit applicativo | Limitatore richieste per IP | 429 | Ritardo di 2–5 secondi con jitter; backoff esponenziale |
| Reputazione IP datacenter | Blocca ASN noti dei datacenter | 1020/403 immediato | Solo proxy residenziali o mobili negli USA |
| Rilevamento concorrenza | Più richieste parallele dallo stesso IP | Escalation improvvisa a Turnstile | ≤2 richieste concorrenti per IP |
Soglie pratiche emerse dai test della community:
- Ritmo sicuro: 1 richiesta ogni 2–3 secondi per IP
- Oltre 20–30 richieste/minuto da un singolo IP datacenter, la challenge arriva nel giro di pochi minuti
- I rate limit soft si attenuano in 5–15 minuti se il traffico si ferma
- I ban degli IP datacenter (AWS, GCP, Azure, OVH) possono durare da ore a giorni
Il requests standard di Python (urllib3 + OpenSSL) produce un — e viene bloccato in silenzio anche con header perfetti. La soluzione usata nel settore è curl_cffi con impersonate="chrome120", che replica TLS e HTTP/2 in modo molto simile a Chrome.
Tre modi per fare scraping di Redfin con Python (e quale scegliere)
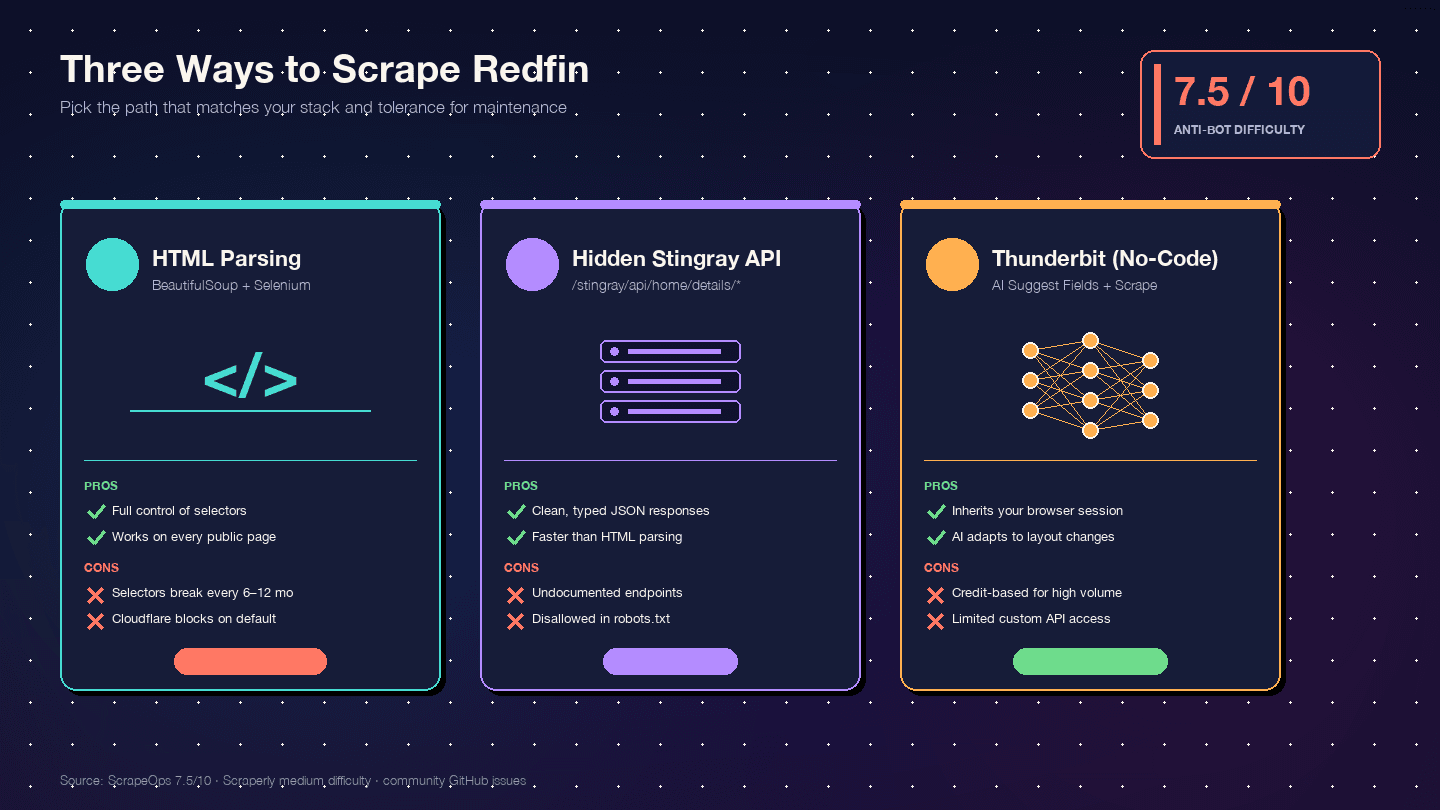
Non ho trovato una sola guida concorrente che confronti tutti e tre gli approcci fianco a fianco. Ecco la matrice decisionale:
| Criterio | Parsing HTML (BS4 + Selenium) | API Stingray nascosta | Thunderbit (No-Code) |
|---|---|---|---|
| Difficoltà di setup | Media (ambiente Python + driver browser) | Alta (reverse engineering degli endpoint) | Bassa (installazione estensione Chrome) |
| Rischio anti-bot | Alto (le richieste al DOM sono le più visibili) | Medio (richieste tipo API sembrano più pulite) | Basso (usa la tua vera sessione browser) |
| Qualità della struttura dati | Media (HTML non strutturato → parsing manuale) | Eccellente (JSON già strutturato) | Alta (l’AI rileva automaticamente campi e tipi) |
| Carico di manutenzione | Alto — basta un cambio layout e i selettori si rompono | Medio — gli endpoint possono cambiare senza preavviso | Basso — l’AI si adatta ai cambi di layout |
| Scala | Bassa-media (centinaia con proxy) | Media-alta (migliaia, richieste più pulite) | Media (50 pagine per batch via cloud scraping) |
| Ideale per | Sviluppatori che vogliono il controllo totale | Sviluppatori che hanno bisogno di JSON pulito | Non sviluppatori, progetti rapidi, dati ricorrenti senza risorse dev |
Il tema manutenzione merita enfasi. Redfin ha introdotto due generazioni di card DOM — la vecchia (homecardV2Price) e l’attuale (span.bp-Homecard__Price--value). Dallo storico dei problemi su GitHub emerge una rottura dei selettori CSS circa ogni 6–12 mesi. Quando succede, uno scraper con BeautifulSoup si rompe da un giorno all’altro. Un rilevatore di campi basato su AI si adatta.
Prima di iniziare
- Difficoltà: Intermedia (Approcci 1 e 2), Principiante (Approccio 3)
- Tempo necessario: circa 30 minuti per l’Approccio 1 o 2; circa 5 minuti per l’Approccio 3
- Cosa ti serve:
- Python 3.8+ con pip (Approcci 1 e 2)
- Browser Chrome (tutti gli approcci)
- (Approccio 3)
- Proxy residenziali USA per scraping su larga scala (Approcci 1 e 2)
Approccio 1: fare scraping di Redfin con Python usando il parsing HTML (BeautifulSoup + Selenium)
Questa è la strada del “controllo totale”. Scrivi tu i selettori, gestisci tu il browser, gestisci tu gli errori.
È l’approccio più istruttivo. È anche il più fragile.
Passo 1: configurare l’ambiente Python
Crea un ambiente virtuale e installa le librerie necessarie:
1python -m venv redfin-scraper
2source redfin-scraper/bin/activate # Su Windows: redfin-scraper\Scripts\activate
3pip install requests beautifulsoup4 selenium webdriver-manager pandas curl_cfficurl_cffi è fondamentale qui — è ciò che permette alle tue richieste HTTP di imitare il fingerprint TLS di un vero Chrome, invece del fingerprint di base di Python requests che Cloudflare blocca subito.
Passo 2: configurare header del browser e sessione
Qui falliscono molti principianti. Ti serve il set completo di header di Chrome, compresi gli header Sec-Fetch-* che Redfin/Cloudflare controlla esplicitamente:
1from curl_cffi import requests as curl_requests
2HEADERS = {
3 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/120.0.0.0 Safari/537.36",
6 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Fetch-Site": "none",
10 "Sec-Fetch-Mode": "navigate",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-User": "?1",
13}
14session = curl_requests.Session(impersonate="chrome120")
15session.headers.update(HEADERS)
16# Riscalda la sessione — raccoglie i cookie cf_clearance e RF_BROWSER_ID
17session.get("https://www.redfin.com/")Il riscaldamento della sessione è essenziale — aprire direttamente una pagina immobile profonda (senza cookie precedenti e senza Referer) abbassa il punteggio assegnato da Cloudflare.
Inizia sempre dalla homepage.
Passo 3: estrarre i risultati di ricerca di Redfin
Con la sessione pronta, puoi recuperare una pagina di ricerca di una città e analizzare le card degli annunci. I selettori della generazione attuale (2024–2026):
1import time
2import random
3from bs4 import BeautifulSoup
4base_url = "https://www.redfin.com/city/17151/CA/San-Francisco"
5listings = []
6for page_num in range(1, 6): # Pagine 1-5
7 url = f"{base_url}/page-{page_num}" if page_num > 1 else base_url
8 resp = session.get(url)
9 if resp.status_code != 200:
10 print(f"Bloccato alla pagina {page_num}: HTTP {resp.status_code}")
11 break
12 soup = BeautifulSoup(resp.text, "html.parser")
13 cards = soup.select("[data-rf-test-id='property-card'], a.bp-Homecard")
14 for card in cards:
15 price_el = card.select_one("span.bp-Homecard__Price--value")
16 addr_el = card.select_one("a.bp-Homecard__Address")
17 stats = card.select("span.bp-Homecard__LockedStat--value")
18 listing = {
19 "price": price_el.text.strip() if price_el else None,
20 "address": addr_el.text.strip() if addr_el else None,
21 "beds": stats[0].text.strip() if len(stats) > 0 else None,
22 "baths": stats[1].text.strip() if len(stats) > 1 else None,
23 "sqft": stats[2].text.strip() if len(stats) > 2 else None,
24 "url": "https://www.redfin.com" + addr_el["href"] if addr_el else None,
25 }
26 listings.append(listing)
27 # Ritardo casuale tra 2 e 5 secondi
28 time.sleep(random.uniform(2, 5))
29print(f"Estratti {len(listings)} annunci")Dovresti ottenere un elenco crescente di dizionari, ognuno con prezzo, indirizzo, letti/bagni/mq e URL della scheda dettaglio per un annuncio di San Francisco. Se ottieni 0 card, controlla il codice di stato HTTP — un 403 significa che Cloudflare ti ha intercettato e probabilmente ti servono proxy residenziali.
Passo 4: estrarre le pagine dettaglio dei singoli immobili
I risultati di ricerca forniscono le basi. Le pagine dettaglio danno Redfin Estimate, anno di costruzione, HOA, storico vendite, info agente e foto. Queste pagine richiedono il rendering JavaScript, quindi conviene passare a Selenium:
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service
3from webdriver_manager.chrome import ChromeDriverManager
4from selenium.webdriver.common.by import By
5import time
6options = webdriver.ChromeOptions()
7options.add_argument("--headless=new")
8options.add_argument("--disable-blink-features=AutomationControlled")
9options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
10 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
11driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
12for listing in listings[:10]: # Arricchisci i primi 10
13 driver.get(listing["url"])
14 time.sleep(random.uniform(3, 6)) # Attendi il rendering JS
15 try:
16 estimate_el = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='avmLdpPrice']")
17 listing["redfin_estimate"] = estimate_el.text.strip()
18 except:
19 listing["redfin_estimate"] = None
20 try:
21 year_built = driver.find_element(By.XPATH, "//span[contains(text(),'Year Built')]/following-sibling::span")
22 listing["year_built"] = year_built.text.strip()
23 except:
24 listing["year_built"] = None
25driver.quit()Dopo questo passaggio, i primi 10 annunci dovrebbero essere arricchiti con i valori di Redfin Estimate e i dati sull’anno di costruzione. I selettori XPath sono più robusti dei CSS per questi campi annidati dei servizi, ma restano fragili — qualsiasi ristrutturazione del DOM li manda in errore.
Passo 5: gestire blocchi ed errori
Implementa una logica di retry con backoff esponenziale:
1import time
2def fetch_with_retry(session, url, max_retries=3):
3 for attempt in range(max_retries):
4 resp = session.get(url)
5 if resp.status_code == 200:
6 return resp
7 elif resp.status_code in (403, 429, 503):
8 wait = (2 ** attempt) + random.uniform(1, 3)
9 print(f"Bloccato ({resp.status_code}). Nuovo tentativo tra {wait:.1f}s...")
10 time.sleep(wait)
11 else:
12 print(f"Stato inatteso: {resp.status_code}")
13 break
14 return NoneSegnali che sei stato bloccato: HTTP 403 con HTML di Cloudflare nel body, HTTP 429 (rate limit esplicito), body della risposta vuoto oppure “Error 1020 Access Denied” nel contenuto della pagina. Se ti capita con costanza, è il momento di aggiungere proxy residenziali o passare all’approccio API.
Approccio 2: fare scraping di Redfin con Python usando la hidden API Stingray
Questo è il mio approccio preferito. Il frontend di Redfin parla con una API JSON interna su /stingray/api/home/details/*, e le risposte arrivano come JSON pulito e tipizzato — senza bisogno di parsing HTML.
Come scoprire gli endpoint della hidden API di Redfin
Apri Chrome DevTools → scheda Network → filtra per Fetch/XHR → visita una qualsiasi pagina immobile di Redfin. Vedrai richieste verso endpoint come:
api/home/details/initialInfo— risolve URL → propertyId, listingIdapi/home/details/aboveTheFold— prezzo, letti, bagni, mq, foto, stato, agente, MLS#api/home/details/belowTheFold— servizi, HOA, tasse, parcheggio, anno di costruzione, lotto, storicoapi/home/details/avm— Redfin Estimate per immobili sul mercatoapi/home/details/owner-estimate— Redfin Estimate per immobili fuori mercatoapi/home/details/descriptiveParagraph— descrizione marketing
Per le pagine affitto, il rentalId (un UUID di 36 caratteri) viene estratto dall’URL del tag <meta property="og:image">.
Estrarre i dati dell’immobile tramite la API Stingray
C’è una particolarità importante: le risposte JSON di Stingray sono precedute dalla stringa letterale {}&& come misura anti-CSRF. Devi rimuoverla prima di fare il parsing:
1import json
2from curl_cffi import requests as curl_requests
3session = curl_requests.Session(impersonate="chrome120")
4session.headers.update(HEADERS)
5# Riscalda la sessione
6session.get("https://www.redfin.com/")
7# Recupera una pagina immobile per ottenere cookie e property ID
8property_url = "https://www.redfin.com/CA/San-Francisco/123-Main-St-94102/home/12345678"
9page_resp = session.get(property_url)
10# Ora chiama la Stingray API
11api_url = "https://www.redfin.com/stingray/api/home/details/aboveTheFold?propertyId=12345678"
12api_resp = session.get(api_url, headers={"Referer": property_url})
13# Rimuovi il prefisso anti-CSRF
14payload = json.loads(api_resp.text.replace("{}&&", "", 1))
15# Estrai i dati strutturati
16listing_data = payload.get("payload", {})
17print(json.dumps(listing_data, indent=2))La risposta include campi tipizzati: prezzo come intero, letti/bagni come numeri, URL delle foto come array, info agente come oggetti annidati. Niente parsing con BeautifulSoup, niente selettori CSS, niente supposizioni.
Vantaggi e limiti dell’approccio con hidden API
Vantaggi:
- JSON già strutturato — molto più pulito del parsing HTML
- Più veloce per richiesta (payload più piccoli, niente overhead di rendering)
- Rischio di blocco più basso (richieste in stile API con header corretti sembrano più naturali)
Limiti:
- Gli endpoint possono cambiare senza preavviso — non esiste documentazione ufficiale
robots.txtvieta esplicitamente/stingray/per il wildcard user-agent- Serve comunque reverse engineering per scoprire nuovi endpoint
- Restano necessari session warming e header corretti per evitare Cloudflare
L’alternativa no-code: fare scraping di Redfin con Thunderbit
Se ti servono i dati di Redfin ma non vuoi mantenere script Python — o vuoi semplicemente un risultato in cinque minuti — parti da qui. Abbiamo costruito proprio per questo: estrazione di dati strutturati da qualsiasi sito, senza scrivere codice.
Passo 1: installa Thunderbit e apri Redfin
Installa la dal Chrome Web Store. Apri Redfin e vai a una pagina dei risultati di ricerca — per esempio, case in vendita a San Francisco.
Passo 2: clicca su “AI Suggest Fields”
Fai clic sull’icona di Thunderbit nella barra del browser, poi su “AI Suggest Fields.” L’AI legge la pagina Redfin e suggerisce automaticamente colonne come “Address”, “Price”, “Beds”, “Baths”, “SqFt”, “Property Type” e “Listing Photo” — assegnando i tipi di dato corretti in automatico.
Puoi rimuovere le colonne che non ti servono oppure aggiungerne di personalizzate cliccando su “+ Add Column” e descrivendo in inglese semplice ciò che vuoi, ad esempio “listing agent name” o “days on market”.
Dovresti vedere un’anteprima della tabella con le colonne configurate e pronta per essere popolata.
Passo 3: clicca su “Scrape” e guarda arrivare i dati
Fai clic su “Scrape.” Thunderbit elabora gli annunci visibili e popola la tabella. Per i risultati su più pagine, gestisce automaticamente la paginazione — nessuna logica di loop richiesta.
Nei miei test, una tabella da 50 righe si riempie in circa 45 secondi. Dati strutturati, pronti per l’esportazione.
Come Thunderbit gestisce le protezioni anti-bot di Redfin
Poiché Thunderbit gira nel tuo browser, eredita i cookie Redfin, la sessione e il fingerprint del browser già presenti. Per Cloudflare sembra un normale utente che naviga Redfin — perché, tecnicamente, lo è. Niente browser headless, niente IP datacenter, niente fingerprint TLS non allineato. Per le pagine pubbliche, la modalità cloud scraping di Thunderbit può processare 50 pagine alla volta.
È un approccio completamente diverso rispetto a lanciare requests da uno script Python su un server.
La tua sessione browser è già considerata affidabile.
Fare scraping delle sottopagine di Redfin con Thunderbit
Dopo aver estratto i risultati di ricerca, fai clic su “Scrape Subpages” per far visitare all’AI ogni URL di dettaglio dell’immobile e arricchire la tabella con altri campi — Redfin Estimate, anno di costruzione, spese HOA, info agente, foto dell’immobile e storico vendite.
È l’equivalente del loop Selenium da 40 righe dell’Approccio 1 — solo che richiede un clic e zero manutenzione.
Quando Redfin cambia il DOM da homecardV2Price a span.bp-Homecard__Price--value, l’AI si adatta. I tuoi selettori Python no.
Oltre il CSV: esportare i dati Redfin in Google Sheets, Airtable e Notion
La maggior parte delle guide si ferma a df.to_csv(). Va bene per un’analisi una tantum. Ma se lavori in un team immobiliare, ti servono dati collaborativi e aggiornabili, non file statici abbandonati sul desktop di qualcuno.
Esportare con Python (gspread + Airtable API)
Google Sheets con gspread:
1import gspread
2import pandas as pd
3from gspread_dataframe import set_with_dataframe
4df = pd.DataFrame(listings)
5gc = gspread.service_account(filename="service_account.json")
6sh = gc.open("Redfin Listings")
7ws = sh.worksheet("Sheet1")
8ws.clear()
9set_with_dataframe(ws, df, include_index=False, resize=True)
10# Mostra le foto immobiliari inline tramite la formula IMAGE()
11image_col = df.columns.get_loc("image_url") + 1
12for row_idx, url in enumerate(df["image_url"], start=2):
13 ws.update_cell(row_idx, image_col, f'=IMAGE("{url}")')Attenzione: Sheets ha un limite rigido di 10 milioni di celle per spreadsheet, e l’API consente . Per qualsiasi cosa oltre qualche decina di righe, usa ws.batch_update() invece di cicli cella per cella.
Airtable con pyairtable:
Cambio critico del 2024: Airtable ha . Ora devi usare i Personal Access Token (PAT): qualsiasi guida che mostra ancora api_key=... è rotta.
1from pyairtable import Api
2api = Api("patXXXXXXXXXXXXXX.yyyyyyyyyyyyyyyyyyyy")
3table = api.table("appBaseId123", "Redfin Listings")
4records = [
5 {
6 "Address": row["address"],
7 "Price": row["price"],
8 "Beds": row["beds"],
9 "Photo": [{"url": row["image_url"]}], # Airtable recupera e re-hosta
10 }
11 for row in listings
12]
13created = table.batch_create(records, typecast=True)Il rate limit di Airtable è , con blocco di 30 secondi in caso di violazione. Il campo allegato accetta payload del tipo [{"url": ...}] — i server di Airtable recuperano l’URL, lo ospitano sulla loro CDN e generano automaticamente le miniature.
Esportare con Thunderbit (1 clic verso Sheets, Airtable, Notion)
Thunderbit offre esportazione nativa in un clic verso Google Sheets, Airtable e Notion — e questa è la parte di cui sono davvero orgoglioso: le foto degli immobili vengono caricate e mostrate come immagini inline in Notion e Airtable. Nessun trucco con formule =IMAGE(), nessun link CDN rotto. Clicchi “Export to Airtable” e il tuo team ottiene un database visivo di immobili con miniature consultabili anche da smartphone.
Per i team immobiliari che fanno triage visivo degli annunci, questa è la differenza tra uno strumento davvero utile e un mucchio di righe CSV.
È legale fare scraping di Redfin? Cosa dicono ToS, robots.txt e la giurisprudenza
Non sono un avvocato e questo non è un parere legale. Ma dopo anni nel mondo dell’estrazione dati, posso dirti che la domanda “è legale?” è quella che tutti fanno e che molte guide evitano.
Il robots.txt di Redfin
Il di Redfin è dettagliato. I punti chiave:
- Bot completamente bloccati:
peer39_crawler/1.0,AmazonAdBot,FireCrawlAgent— Redfin nomina esplicitamente il servizio di scraping in stile LLM più noto - Wildcard
User-agent: *con Disallow evidenti:/stingray/(l’intero namespace API interno),/myredfin/,/api/v1/rentals/,/api/v1/properties/,/owner-estimate/ - Nessuna direttiva
Crawl-delay:per nessun user agent - Oltre 50 sitemap dichiarate — le sitemap sono il modo più pulito e meno invasivo per elencare gli URL
I Termini di utilizzo di Redfin
La dice: “You may not automatedly crawl or query the Services for any purpose or by any means... unless you have received prior express written permission.”
Si tratta di un accordo browsewrap — accettazione tramite uso continuato, non con click esplicito. I tribunali USA sono storicamente diffidenti nel far valere il browsewrap contro utenti che non avevano effettiva conoscenza del vincolo (vedi Nguyen v. Barnes & Noble, 9th Cir. 2014).
Giurisprudenza rilevante (in breve)
- Van Buren v. United States (Corte Suprema, 2021): la clausola CFAA “exceeds authorized access” segue un test “gate-up-or-down”. Usare una porta aperta per uno scopo non gradito non è hacking federale.
- hiQ Labs v. LinkedIn (9th Cir., 2022): fare scraping di dati pubblicamente disponibili non viola la CFAA. Però hiQ ha poi pagato 500.000 dollari in una causa chiusa per violazione contrattuale — perché aveva registrato account LinkedIn e cliccato “I agree.”
- Meta Platforms v. Bright Data (N.D. Cal., gennaio 2024): il tribunale ha concesso il summary judgment a Bright Data — lo scraping di dati pubblici da utente disconnesso non rende Bright Data un “utente” vincolato ai ToS di Meta.
- X Corp. v. Bright Data (N.D. Cal., maggio 2024): il giudice Alsup ha respinto le richieste di X, stabilendo che le pretese di diritto statale volte a controllare la copia di contenuti pubblici erano precluse dal Copyright Act.
Indicazioni pratiche
- Estrai solo dati pubblicamente accessibili — non registrare un account e poi fare scraping (si crea esposizione contrattuale da clickwrap)
- Rispetta i rate limit — volumi aggressivi possono sostenere accuse di trespass to chattels
- Non ripubblicare in massa dati grezzi o foto — la causa (depositata a luglio 2025, con danni potenziali superiori a 1 miliardo di dollari) ricorda che il copyright delle foto è una questione seria
- L’approccio browser-based di Thunderbit — che gira nella tua sessione autenticata — è più vicino a una “navigazione manuale a velocità macchina” che a un bot headless su datacenter, quindi è una posizione molto più difendibile rispetto a un’API con licenza
Consigli e errori comuni
Qualche lezione imparata sul campo costruendo strumenti di estrazione e osservando migliaia di utenti fare scraping su siti immobiliari:
- Riscalda sempre la sessione. Apri
redfin.com/prima di qualsiasi URL profondo. Gli accessi diretti a URL profondi sono il trigger n. 1 delle challenge Cloudflare. - Ruota gli User-Agent in modo realistico. Non usare sempre lo stesso — alterna 5–10 UA recenti di Chrome/Firefox. Ma non ruotare troppo in fretta (un UA diverso a ogni richiesta sembra sospetto).
- Deduplica per ID immobile. La paginazione di Redfin a volte si sovrappone. Estrai
/home/{id}dall’URL di ogni annuncio e deduplica prima dell’arricchimento. - Se puoi, evita le ore di punta. Nella mia esperienza, tarda notte / primissimo mattino negli USA comportano meno controlli WAF.
- Se ricevi un 429, rallenta in modo esponenziale. Non riprovare subito — è così che passi da un rate limit soft a un ban IP duro.
- Per progetti su larga scala (1.000+ pagine), metti in conto proxy residenziali. Gli IP datacenter (AWS, GCP, Azure, OVH) sono blacklistati dal sistema di reputazione ASN di Cloudflare. In quel caso incontrerai Error 1020 quasi subito.
Scegliere il modo giusto per fare scraping di Redfin
Quindi, quale approccio dovresti scegliere? Dipende da chi sei e da cosa ti serve.
Parsing HTML (BeautifulSoup + Selenium): ideale per sviluppatori che vogliono controllo totale, che si trovano a loro agio nel mantenere selettori CSS e che non hanno problemi a ricostruire lo scraper quando Redfin cambia il DOM. Aspettati di rivedere il codice ogni 6–12 mesi.
Hidden Stingray API: perfetto per sviluppatori che vogliono JSON pulito e strutturato e sanno gestire il reverse engineering di endpoint non documentati. Meno manutenzione del parsing HTML, ma gli endpoint possono cambiare senza avviso. Ricorda che /stingray/ è esplicitamente vietato in robots.txt.
Thunderbit (No-Code): la scelta migliore per non sviluppatori, progetti rapidi e team che hanno bisogno di dati Redfin continui senza risorse di sviluppo. L’AI si adatta ai cambi di layout, lo scraping delle sottopagine arricchisce i dati con un clic e l’esportazione verso , Airtable o Notion è integrata. Se sei un team immobiliare che ha bisogno di un database vivo degli immobili — non di un CSV una tantum — questa è la strada con meno attriti.
Qualunque strada tu scelga: capisci le difese anti-bot di Redfin prima di iniziare, sappi quali campi ti servono, scegli un formato di esportazione adatto al flusso di lavoro del tuo team e resta dalla parte giusta delle .
Pronto a provare la strada no-code? Il ti permette di sperimentare lo scraping di Redfin e vedere i risultati in pochi minuti. Per gli approcci Python, gli esempi di codice qui sopra sono un punto di partenza funzionante — ti basta aggiungere proxy e pazienza.
FAQ
Redfin ha una API pubblica?
No. Redfin non offre una API pubblica ufficiale. La hidden API Stingray (/stingray/api/home/details/*) restituisce JSON strutturato ed è usata dal frontend di Redfin, ma non è ufficiale, non è documentata, può cambiare senza preavviso ed è esplicitamente vietata nel robots.txt di Redfin. Wrapper open source come su PyPI offrono accesso in Python, ma vanno usati consapevolmente dei rischi.
Posso fare scraping di Redfin senza Python?
Sì. è un’estensione Chrome basata su AI che eredita la tua sessione browser per una maggiore resistenza anti-bot — installala, apri Redfin, clicca “AI Suggest Fields” ed esporta su Excel, Google Sheets, Airtable o Notion. Sul mercato esistono anche altri strumenti no-code e fornitori di dataset preconfezionati, se vuoi esplorare alternative.
Con quale frequenza Redfin cambia il layout del sito?
Dallo storico dei problemi su GitHub emerge una rottura dei selettori CSS circa ogni 6–12 mesi. Redfin ha già introdotto due generazioni di DOM delle card — la vecchia (homecardV2Price, homeAddressV2) e l’attuale (bp-Homecard__Price--value, bp-Homecard__Address). Gli scraper maturi provano entrambe le versioni in sequenza.
Gli strumenti basati su AI come Thunderbit perché identificano i campi in base al contenuto e non ai selettori CSS.
Qual è il tipo di proxy migliore per fare scraping di Redfin?
Proxy residenziali USA per scraping su larga scala — i benchmark della community indicano un tasso di successo intorno all’80%. I proxy datacenter incappano quasi subito nell’Error 1020 di Cloudflare; le range IP di AWS, GCP, Azure e OVH sono blacklistate. I proxy mobile hanno il tasso di successo più alto, ma costano 5–10 volte di più.
Per scraping personale su piccola scala (<100 pagine), header corretti + impersonificazione curl_cffi + ritardi di 2–5 secondi possono funzionare anche senza proxy.
Posso estrarre dati di immobili venduti o fuori mercato da Redfin?
Sì. I dati degli immobili venduti e il Redfin Estimate fuori mercato (errore mediano ) sono disponibili nelle pagine dettaglio usando gli stessi approcci di scraping. I campi differiscono dagli annunci attivi: le pagine fuori mercato mostrano prezzo di vendita, data di vendita, storico dell’immobile e l’endpoint owner-estimate, ma non includono il prezzo di listino attuale, i giorni sul mercato e le informazioni sull’open house. L’endpoint Stingray per le stime fuori mercato è api/home/details/owner-estimate, non api/home/details/avm.
Scopri di più