Da qualche parte intorno al mio cinquantesimo copia-incolla di un titolo di lavoro da Indeed in un foglio di calcolo, ho iniziato a mettere in discussione le mie scelte di carriera. Se hai mai provato a estrarre in modo programmatico dati strutturati da Indeed, sai già qual è il finale: l’errore 403 non è un bug, è una funzione del sistema di difesa di Indeed.
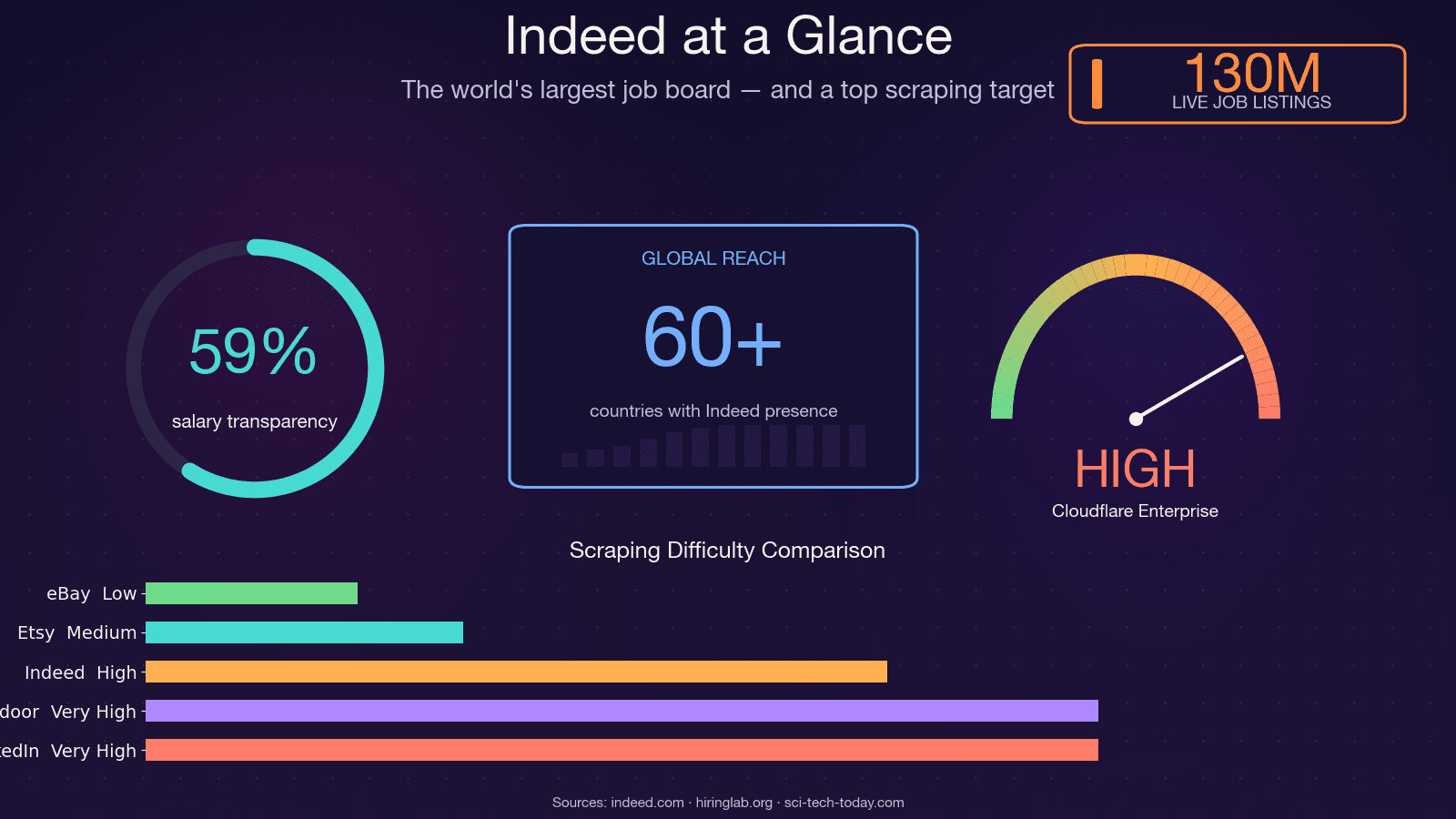
Indeed è la più grande bacheca di annunci di lavoro al mondo, con circa , in qualsiasi momento e attività in . Questo la rende una delle fonti più ricche di dati sul mercato del lavoro al mondo — e una delle più difficili da estrarre. Lo scraper open source JobFunnel (migliaia di stelle su GitHub) è stato letteralmente nel dicembre 2025 dopo anni di sconfitta nella corsa agli armamenti contro i bot. Parole del maintainer: "Tutti gli utenti riescono a estrarre alcuni annunci, ma vengono rapidamente bloccati dal captcha, e l’estrazione fallisce, senza restituire alcun annuncio." Un altro contributore ha segnalato di aver ricevuto un CAPTCHA . Insomma: non è un obiettivo banale da estrarre. In questa guida ti mostrerò ogni metodo pratico per estrarre Indeed con Python, ti farò vedere come sopravvivere davvero al guado del 403 e — per chi preferisce saltare del tutto il debugging — ti mostrerò un’alternativa no-code usando .
Cosa significa estrarre Indeed con Python?
Il web scraping, nella sua essenza, è l’estrazione automatica di dati strutturati dalle pagine web. Quando parliamo di estrarre Indeed con Python, intendiamo scrivere uno script che visita i risultati di ricerca e le pagine di dettaglio degli annunci di Indeed, legge l’HTML sottostante (o i dati incorporati) ed estrae campi come titolo del lavoro, azienda, località, stipendio e descrizione in un formato utilizzabile — un CSV, un database, un Google Sheet.
Le librerie Python tipiche coinvolte sono Requests (per le chiamate HTTP), BeautifulSoup (per il parsing HTML) e Selenium o Playwright (per l’automazione del browser). Ma Indeed non è un semplice sito statico. È un ibrido: HTML renderizzato lato server con un blob JSON di stato incorporato, protetto da Cloudflare Bot Management. Questo significa che il tuo scraper deve gestire contenuti renderizzati da JavaScript, nomi di classe CSS che ruotano e protezioni anti-bot aggressive — tutto prima ancora di analizzare un singolo titolo di lavoro.
Nel 2026 non esiste nemmeno una API ufficiale, gratuita e in sola lettura di Indeed. La vecchia Publisher Jobs API è stata dismessa intorno al 2020 e ciò che resta è solo lato datore di lavoro (Job Sync, Sponsored Jobs). Quindi le opzioni realistiche sono soltanto lo scraping oppure il pagamento di un fornitore terzo di dati.
Perché estrarre dati di lavoro da Indeed?
Il caso d’uso è semplice: consultare manualmente migliaia di annunci è impraticabile, e i dati contenuti in quegli annunci sono davvero preziosi.
| Caso d’uso | Chi ne beneficia | Esempio |
|---|---|---|
| Generazione di lead | Team sales e recruiting | Creare liste di aziende che assumono con i contatti |
| Ricerca sul mercato del lavoro | Analisti, team HR | Individuare competenze di tendenza, benchmark salariali per area |
| Competitive intelligence | Datori di lavoro, agenzie per il lavoro | Monitorare i modelli di assunzione dei concorrenti e le offerte salariali |
| Automazione della ricerca di lavoro personale | Candidati | Aggregare annunci che corrispondono ai tuoi criteri in più località |
| Dati di training per modelli ML | Data scientist | Creare modelli di previsione salariale dai dati storici sugli stipendi |
La stessa ricerca di Indeed Hiring Lab che i dati degli annunci seguono da vicino i dati BLS JOLTS e possono fungere da proxy quasi in tempo reale delle condizioni del mercato del lavoro statunitense. Gli hedge fund usano la velocità di pubblicazione degli annunci come segnale di dati alternativi. I team HR confrontano le retribuzioni usando gli intervalli salariali estratti. E i recruiter costruiscono liste di prospect partendo dalle aziende che stanno assumendo attivamente.
Una nota pratica: i dati sugli stipendi su Indeed stanno migliorando, ma restano incompleti. A metà 2025, circa include informazioni salariali, ma solo circa riporta una cifra esatta — il resto sono range. Qualunque analisi salariale basata sui dati di Indeed dovrebbe tenere conto di questa scarsità.
Scegliere il metodo giusto per estrarre Indeed con Python
Non esiste un solo modo “giusto” per estrarre Indeed. L’approccio migliore dipende dal tuo livello, dalla quantità di dati che ti serve e da quanta manutenzione sei disposto a tollerare. Ho testato tutti e quattro i principali approcci, e questo è il confronto:
| Criterio | BS4 + Requests | Selenium | JSON nascosto (window.mosaic) | No-code (Thunderbit) |
|---|---|---|---|---|
| Difficoltà | Principiante | Intermedio | Intermedio-avanzato | Nessuna (2 clic) |
| Velocità | Veloce | Lenta (render del browser) | Veloce | Veloce (cloud scraping) |
| Contenuti renderizzati da JS | No | Sì | Sì (dati incorporati) | Sì |
| Resistenza ai bot | Bassa | Media (rilevabile) | Medio-alta | Alta (gestita automaticamente) |
| Manutenzione quando cambia l’HTML | Alta (i selettori si rompono) | Alta | Media (struttura JSON più stabile) | Nessuna (l’AI si adatta) |
| Ideale per | Prototipi rapidi | Pagine dinamiche, contenuti protetti da login | Dati strutturati in massa | Non sviluppatori, risultati rapidi |
Questa guida illustra ogni metodo. Se sei uno sviluppatore Python, vorrai leggere le sezioni BS4, JSON nascosto e Selenium. Se non programmi (o sei semplicemente stanco di debuggare 403), passa direttamente alla sezione Thunderbit.
Prima di iniziare
- Difficoltà: Principiante-intermedio (sezioni Python); Nessuna (sezione Thunderbit)
- Tempo necessario: ~20–60 minuti per configurare Python e fare il primo scraping; ~2 minuti con Thunderbit
- Cosa ti serve: Python 3.9+, un editor di codice, browser Chrome e (per la via no-code) l’
Configurare l’ambiente Python per lo scraping di Indeed
Prima di scrivere qualsiasi codice di scraping, prepara il tuo ambiente.
Installa le librerie necessarie
Crea un ambiente virtuale e installa i pacchetti che ti servono:
1python -m venv indeed_env
2source indeed_env/bin/activate # Su Windows: indeed_env\Scripts\activate
3# Per l’approccio HTTP + parsing
4pip install requests beautifulsoup4 lxml httpx
5# Per l’approccio con JSON nascosto (consigliato)
6pip install curl_cffi parsel tenacity
7# Per l’approccio con automazione del browser
8pip install seleniumAlcune note:
curl_cffiè il valore predefinito nel 2026 per estrarre siti protetti da Cloudflare. Imita le impronte TLS reali del browser, cosa cherequestsehttpxnon possono fare. Ne parleremo meglio nella sezione anti-bot.- Selenium 4.6+ include Selenium Manager, quindi non devi più scaricare manualmente ChromeDriver — gestisce tutto in automatico.
- Usa
lxmlcome backend parser di BeautifulSoup. È circa del parserhtml.parserdella libreria standard.
Crea la struttura del progetto
Mantienila semplice:
1indeed_scraper/
2├── scraper.py
3├── requirements.txt
4└── output/Tutti gli esempi di codice qui sotto si basano su scraper.py.
Come estrarre Indeed con Python usando BeautifulSoup
Questo è l’approccio adatto ai principianti: usa requests per recuperare la pagina e BeautifulSoup per analizzare l’HTML. È il più rapido da configurare, ma anche il più fragile su Indeed.
Passo 1: costruire l’URL di ricerca Indeed
Gli URL di ricerca di Indeed seguono uno schema prevedibile:
1https://www.indeed.com/jobs?q=<query>&l=<location>&start=<offset>Per esempio, per cercare “data analyst” ad “Austin, TX” partendo dalla prima pagina:
1from urllib.parse import urlencode
2params = {
3 "q": "data analyst",
4 "l": "Austin, TX",
5 "start": 0,
6}
7url = f"https://www.indeed.com/jobs?{urlencode(params)}"
8print(url)
9# https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX&start=0Indeed impagina i risultati a blocchi di 10, con un limite massimo rigido di 1.000 risultati (start <= 990). Qualsiasi offset superiore a 990 restituisce in silenzio la stessa pagina.
Passo 2: inviare una richiesta HTTP con header corretti
Indeed blocca immediatamente le richieste con le stringhe user-agent predefinite di Python. Ti servono header realistici:
1import requests
2headers = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
5 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.indeed.com/",
11}
12response = requests.get(url, headers=headers, timeout=30)
13print(response.status_code)Se ottieni un 200, per il momento sei dentro. Se ottieni un 403, Cloudflare ti ha intercettato. (Più avanti vedremo come sopravvivere.)
Passo 3: analizzare gli annunci dall’HTML
Usa BeautifulSoup per selezionare gli elementi delle schede lavoro. Punta agli attributi data-testid — sono più stabili dei nomi di classe CSS randomizzati di Indeed:
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(response.text, "lxml")
3cards = soup.find_all("div", attrs={"data-testid": "slider_item"})
4jobs = []
5for card in cards:
6 title_el = card.find("h2", class_="jobTitle")
7 title = title_el.get_text(strip=True) if title_el else None
8 company = card.find(attrs={"data-testid": "company-name"})
9 location = card.find(attrs={"data-testid": "text-location"})
10 link = title_el.find("a")["href"] if title_el and title_el.find("a") else None
11 jobs.append({
12 "title": title,
13 "company": company.get_text(strip=True) if company else None,
14 "location": location.get_text(strip=True) if location else None,
15 "url": f"https://www.indeed.com\{link\}" if link else None,
16 })
17print(f"Trovati {len(jobs)} annunci")Passo 4: gestire la paginazione
Scorri le pagine incrementando il parametro start:
1import time, random
2all_jobs = []
3for page in range(0, 50, 10): # Prime 5 pagine
4 params["start"] = page
5 url = f"https://www.indeed.com/jobs?{urlencode(params)}"
6 response = requests.get(url, headers=headers, timeout=30)
7 # ... analizza come sopra ...
8 all_jobs.extend(jobs)
9 time.sleep(random.uniform(3, 6))Limiti di questo approccio
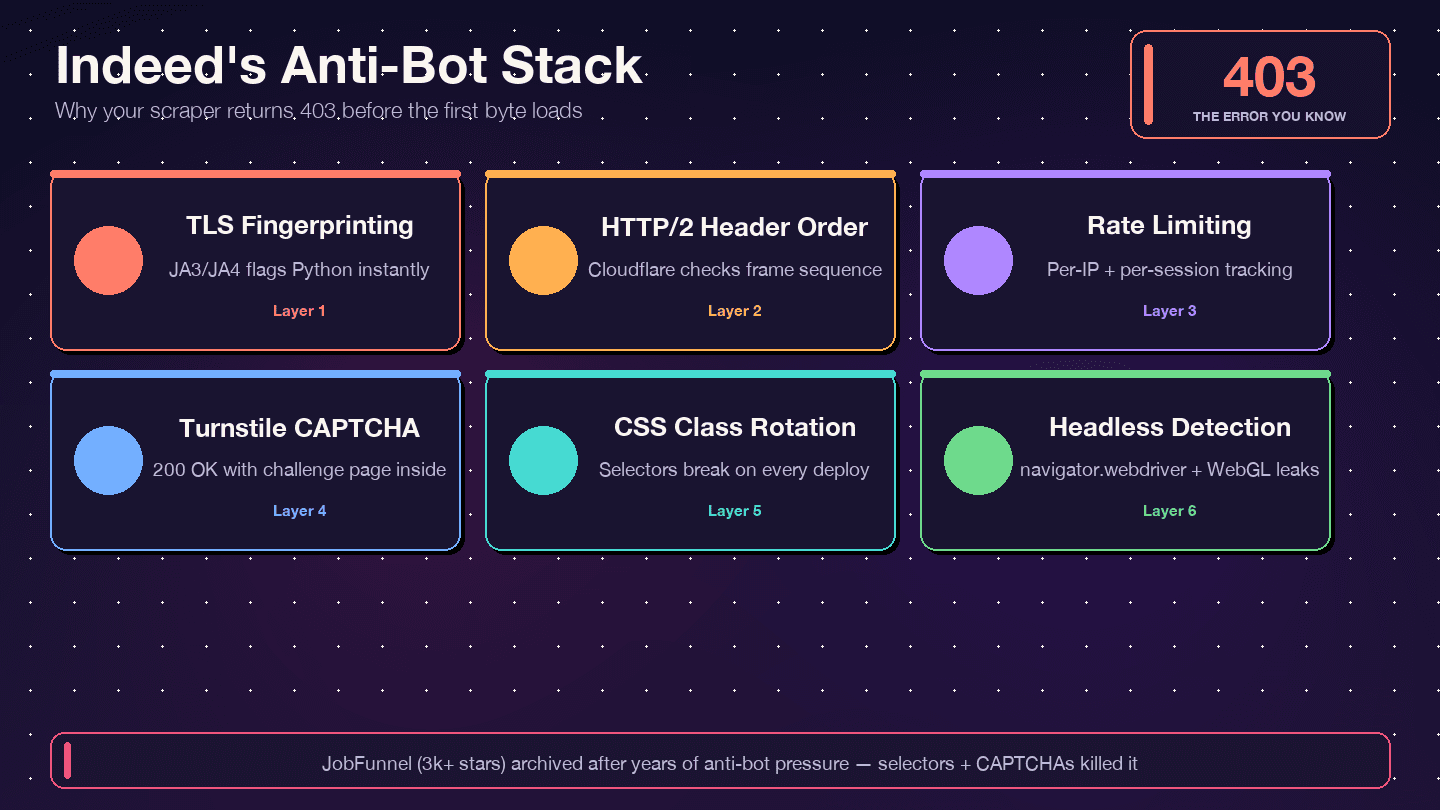
Lo dico chiaramente: BS4 + Requests è il metodo più debole per Indeed nel 2026. requests usa la libreria TLS standard di Python, che produce una che Cloudflare identifica all’istante come “non un browser”. Inoltre non supporta HTTP/2, mentre Indeed lo serve. È molto probabile che tu venga bloccato dopo poche pagine. E i selettori CSS? Indeed ruota frequentemente nomi di classe come css-1m4cuuf e jobsearch-JobComponent-embeddedBody-1n0gh5s — quindi qualsiasi selettore che li usi è una bomba a orologeria.
Usa questo metodo per prototipare rapidamente su una singola pagina. Per qualunque cosa su scala maggiore, usa l’approccio con JSON nascosto.
Come estrarre Indeed con Python usando dati JSON nascosti
Questo è il metodo che consiglio alla maggior parte degli sviluppatori Python. Invece di analizzare elementi HTML fragili, estrai i dati strutturati da una variabile JavaScript incorporata nel sorgente della pagina di Indeed: window.mosaic.providerData["mosaic-provider-jobcards"].
Tutti i campi che ti interessano — titolo del lavoro, azienda, località, stipendio, job key, data di pubblicazione, flag remoto — sono già presenti in questo blob JSON. Non serve eseguire JavaScript. Lo schema è , quindi è molto più resistente dei selettori DOM.
Passo 1: recuperare l’HTML della pagina
Usa curl_cffi invece di requests — imita le impronte TLS reali del browser, ed è fondamentale per sopravvivere a Cloudflare:
1from curl_cffi import requests as cffi_requests
2response = cffi_requests.get(
3 "https://www.indeed.com/jobs?q=python+developer&l=Remote&start=0",
4 impersonate="chrome124",
5 headers={
6 "Accept-Language": "en-US,en;q=0.9",
7 "Referer": "https://www.indeed.com/",
8 },
9 timeout=30,
10)
11print(response.status_code, len(response.text))Perché curl_cffi? È un binding Python di curl-impersonate, che riproduce esattamente il ClientHello TLS, il frame HTTP/2 SETTINGS e l’ordine degli header dei browser reali. È l’unico client HTTP Python attivamente mantenuto che aggira in una sola chiamata. I target di impersonificazione supportati includono chrome120, chrome124, chrome131, Safari e varianti Edge.
Passo 2: estrarre il JSON con una regex
Il blob JSON è incorporato in un tag <script>. Estrailo con una regex:
1import re, json
2MOSAIC_RE = re.compile(
3 r'window\.mosaic\.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});',
4 re.DOTALL,
5)
6match = MOSAIC_RE.search(response.text)
7if match:
8 data = json.loads(match.group(1))
9 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
10 print(f"Trovati {len(results)} annunci nel JSON nascosto")
11else:
12 print("JSON nascosto non trovato — possibile blocco o modifica della pagina")Passo 3: analizzare i campi degli annunci dal JSON
Ogni elemento in results contiene più dati di quanti ne siano visibili sulla pagina:
1jobs = []
2for job in results:
3 jobs.append({
4 "jobkey": job["jobkey"],
5 "title": job["title"],
6 "company": job.get("company"),
7 "location": job.get("formattedLocation"),
8 "remote": job.get("remoteLocation"),
9 "salary": (job.get("salarySnippet") or {}).get("text"),
10 "posted": job.get("formattedRelativeTime"),
11 "job_type": job.get("jobTypes"),
12 "easy_apply": job.get("indeedApplyEnabled"),
13 "url": f"https://www.indeed.com/viewjob?jk={job['jobkey']}",
14 })Il JSON include spesso stime salariali, attributi di tassonomia (tag di competenze) e valutazioni aziendali che non sono sempre visibili nell’HTML renderizzato.
Passo 4: estrarre più pagine
Usa tierSummaries nel JSON per capire il numero totale di risultati, poi fai il loop:
1import time, random
2all_jobs = []
3for start in range(0, 50, 10): # Prime 5 pagine
4 url = f"https://www.indeed.com/jobs?q=python+developer&l=Remote&start=\{start\}&sort=date"
5 response = cffi_requests.get(
6 url,
7 impersonate="chrome124",
8 headers={"Accept-Language": "en-US,en;q=0.9", "Referer": "https://www.indeed.com/"},
9 timeout=30,
10 )
11 match = MOSAIC_RE.search(response.text)
12 if match:
13 data = json.loads(match.group(1))
14 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
15 all_jobs.extend([{
16 "jobkey": j["jobkey"],
17 "title": j["title"],
18 "company": j.get("company"),
19 "location": j.get("formattedLocation"),
20 "salary": (j.get("salarySnippet") or {}).get("text"),
21 "url": f"https://www.indeed.com/viewjob?jk={j['jobkey']}",
22 } for j in results])
23 time.sleep(random.uniform(3, 7))
24print(f"Totale: {len(all_jobs)} annunci estratti")Perché il JSON nascosto è più resistente
La struttura window.mosaic.providerData cambia meno spesso dei nomi di classe CSS. Ottieni dati puliti e strutturati senza analizzare HTML disordinato. Detto questo, serve comunque una mitigazione anti-bot (header, ritardi, proxy) — che vedremo tra poco.
Come estrarre Indeed con Python usando Selenium
Selenium è l’approccio basato sull’automazione del browser. È utile quando devi interagire con la pagina — cliccare nei pannelli di dettaglio del lavoro, gestire contenuti protetti da login o estrarre descrizioni caricate dinamicamente che non sono nell’HTML iniziale.
Quando usare Selenium invece dei client HTTP
- Indeed carica alcuni contenuti dinamicamente (descrizioni complete nella barra laterale destra)
- Devi estrarre pagine che richiedono stato di sessione o login
- Stai facendo scraping su piccola scala, dove la velocità non è critica
Guida rapida
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.chrome.options import Options
4import time
5options = Options()
6options.add_argument("--disable-blink-features=AutomationControlled")
7# options.add_argument("--headless=new") # L’headless è più rilevabile — usalo con cautela
8driver = webdriver.Chrome(options=options)
9driver.get("https://www.indeed.com/jobs?q=data+engineer&l=New+York")
10time.sleep(3)
11cards = driver.find_elements(By.CSS_SELECTOR, "[data-testid='slider_item']")
12for card in cards:
13 try:
14 title = card.find_element(By.CSS_SELECTOR, "h2.jobTitle").text
15 company = card.find_element(By.CSS_SELECTOR, "[data-testid='company-name']").text
16 location = card.find_element(By.CSS_SELECTOR, "[data-testid='text-location']").text
17 print(f"\{title\} | \{company\} | \{location\}")
18 except Exception:
19 continue
20driver.quit()Limiti
Selenium è lento — ogni pagina richiede il rendering completo del browser. Chrome in modalità headless è (Cloudflare controlla navigator.webdriver, le stringhe del vendor WebGL, il numero di plugin e altro ancora). Anche undetected-chromedriver al massimo ritarda il rilevamento; non lo impedisce per sempre. E, come con BS4, i tuoi selettori si romperanno quando Indeed aggiornerà la UI.
Per la maggior parte dei casi d’uso, l’approccio con JSON nascosto ti dà gli stessi dati più velocemente e con meno manutenzione. Riserva Selenium ai casi limite in cui hai davvero bisogno di un browser.
Come evitare gli errori 403 quando estrai Indeed con Python
Questa è la sezione più importante. Se sei arrivato qui dopo una ricerca Google frustrante, sei nel posto giusto.
Perché Indeed blocca il tuo scraper
Indeed usa — non DataDome, non PerimeterX. Lo confermano gli header di risposta: server: cloudflare, cf-ray e il cookie di bot management __cf_bm. Cloudflare esamina la tua impronta TLS (JA3/JA4), l’ordine degli header HTTP/2, i pattern delle richieste e i segnali di comportamento del browser. Se uno di questi elementi sembra non umano, ottieni un 403, un 429, un 503 o — nel caso più subdolo — un 200 OK con una pagina di sfida Turnstile al posto dei veri dati di lavoro.
Ruota User-Agent e header della richiesta
Un singolo User-Agent statico è il modo più rapido per farsi bloccare. Ruota tra una serie di stringhe attuali e realistiche. Importante: i campi minor version di Chrome sono dalla User-Agent Reduction — non inventare versioni minori non zero, altrimenti i sistemi anti-bot se ne accorgeranno.
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
6 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
7 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
8 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.3800.97",
9 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
10 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 "
11 "(KHTML, like Gecko) Version/17.4 Safari/605.1.15",
12]
13headers = {
14 "User-Agent": random.choice(USER_AGENTS),
15 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
16 "Accept-Language": "en-US,en;q=0.9",
17 "Accept-Encoding": "gzip, deflate, br, zstd",
18 "Referer": "https://www.indeed.com/",
19 "Sec-Fetch-Dest": "document",
20 "Sec-Fetch-Mode": "navigate",
21 "Sec-Fetch-Site": "same-origin",
22}Assicurati anche che i Client Hints sec-ch-ua corrispondano alla versione del tuo UA. Un sec-ch-ua: "Chrome";v="131" accanto a un User-Agent che dichiara Chrome 145 è un segnale d’allarme immediato.
Aggiungi ritardi casuali tra le richieste
Intervalli fissi vengono individuati dal rilevamento di pattern. Usa jitter casuale:
1import time, random
2# Tra una richiesta e l’altra
3time.sleep(random.uniform(3, 6))
4# In caso di retry dopo un blocco
5def backoff_sleep(attempt):
6 base = 4
7 sleep_time = base * (2 ** attempt) + random.uniform(0, 2)
8 time.sleep(min(sleep_time, 60))Il consenso emerso da e è di 3–6 secondi tra le richieste per IP, con un tetto rigido di circa 100 richieste per IP per sessione prima della rotazione.
Usa la rotazione dei proxy
Questo è il singolo fattore più determinante per il successo. I proxy datacenter da range AWS/GCP ottengono circa il 5–15% di successo contro target Cloudflare Enterprise — di fatto inutilizzabili su Indeed. I proxy residenziali, insieme a un corretto fingerprint TLS, salgono all’80–95% di successo.
1PROXIES = [
2 "http://user:pass@us.residential.example:7777",
3 "http://user:pass@us.residential.example:7778",
4 "http://user:pass@us.residential.example:7779",
5]
6proxy = random.choice(PROXIES)
7response = cffi_requests.get(
8 url,
9 impersonate="chrome124",
10 headers=headers,
11 proxies={"https": proxy},
12 timeout=30,
13)Nel 2026 il prezzo dei proxy residenziali si aggira intorno a , a seconda del provider e del livello di impegno. Per Indeed in particolare, parti con un piccolo pool e scala solo quando serve.
Gestire in modo elegante i codici di stato 403, 429 e 503
Non limitarti a riprovare alla cieca. Codici diversi significano cose diverse:
1def fetch_with_retry(url, proxy_pool, max_retries=5):
2 for attempt in range(max_retries):
3 proxy = random.choice(proxy_pool)
4 headers["User-Agent"] = random.choice(USER_AGENTS)
5 try:
6 r = cffi_requests.get(
7 url,
8 impersonate=random.choice(["chrome124", "chrome120", "edge101"]),
9 headers=headers,
10 proxies={"https": proxy},
11 timeout=30,
12 )
13 # Controlla il caso subdolo "200 con challenge"
14 if r.status_code == 200 and "cf-turnstile" not in r.text and "Just a moment" not in r.text:
15 return r
16 if r.status_code == 403:
17 print(f"403 — bloccato. Cambio proxy, tentativo {attempt + 1}")
18 elif r.status_code == 429:
19 print(f"429 — rate limit raggiunto. Rallento.")
20 elif r.status_code == 503:
21 print(f"503 — server sovraccarico o challenge JS.")
22 backoff_sleep(attempt)
23 except Exception as e:
24 print(f"Errore nella richiesta: \{e\}")
25 backoff_sleep(attempt)
26 raise RuntimeError(f"Fallito dopo \{max_retries\} tentativi: \{url\}")Il caso 200-con-challenge è il più insidioso. Cerca sempre nel corpo della risposta i marker cf-turnstile o Just a moment prima di considerare un 200 come successo.
L’alternativa più semplice: lascia che Thunderbit gestisca l’anti-bot
Per chi non vuole costruire e mantenere pool di proxy, rotazione degli header e impersonificazione delle impronte TLS, lo scraping cloud di gestisce automaticamente CAPTCHA, rotazione dei proxy e protezioni anti-bot. Niente configurazione proxy, niente setup di curl_cffi, nessuna libreria per risolvere CAPTCHA. È la strada con meno attriti quando ti servono solo i dati.
Perché il tuo scraper di Indeed continua a rompersi (e come risolvere)
Il muro del 403 è il dolore acuto. Il dolore cronico è la manutenzione — gli scraper che funzionano oggi si rompono la settimana dopo, restituendo in silenzio dati vuoti o risultati obsoleti.
Come Indeed rompe i tuoi selettori
Indeed ruota in modo aggressivo i nomi delle classi CSS. La guida di Bright Data che classi come css-1m4cuuf e css-1rqpxry “sembrano generate casualmente — probabilmente in fase di build”. I test A/B fanno sì che sessioni diverse vedano layout diversi. E la ristrutturazione del DOM avviene senza preavviso.
La vicenda JobFunnel è istruttiva. Un contributore ha segnalato: "CaptchaBuster ha mitigato con successo il captcha, e il motivo per cui la pagina [veniva ancora estratta senza successo] è dovuto a selettori Beautiful Soup obsoleti." Lo scraper non era bloccato — stava analizzando gli elementi sbagliati.
Strategia: preferire il JSON nascosto al parsing del DOM
Il blob window.mosaic.providerData ha mantenuto uno schema stabile almeno dal 2023. Il percorso metaData.mosaicProviderJobCardsModel.results[] è nel 2026. I selettori DOM si rompono ogni mese. L’estrazione da JSON si rompe, se va male, una volta l’anno.
Strategia: usare gli attributi data invece dei nomi di classe
Quando devi davvero toccare il DOM, punta ad attributi funzionali:
| Selettore | Scopo |
|---|---|
[data-testid="slider_item"] | Il contenitore di ogni scheda lavoro |
[data-testid="job-title"] oppure h2.jobTitle > a | Il link del titolo del lavoro |
[data-testid="company-name"] | Il nome del datore di lavoro |
[data-testid="text-location"] | Il testo della località |
data-jk="<jobkey>" su ogni scheda | L’aggancio più stabile in assoluto — invariato dal 2019 |
Aggiungi asserzioni per rilevare selettori obsoleti
Non lasciare mai che il tuo scraper giri in silenzio con zero risultati. Aggiungi un controllo dopo ogni fetch:
1results = parse_hidden_json(html)
2assert len(results) > 0, (
3 f"Indeed ha restituito un set di risultati vuoto a start=\{start\} — "
4 "possibile blocco, CAPTCHA o deriva dei selettori. "
5 f"Primi 500 caratteri della risposta: {html[:500]}"
6)Registra i primi 500–2000 caratteri della risposta grezza in caso di errore. In questo modo capirai subito se hai ricevuto una sfida Turnstile, una barriera di accesso o una modifica dello schema. Esegui un test giornaliero di smoke test in CI su una query fissa (ad es. q=python&l=remote) che verifichi che i risultati siano diversi da zero.
L’alternativa AI: scraper che non si rompono mai
L’AI di Thunderbit legge la struttura della pagina ogni volta da zero — non si basa su selettori hardcoded o pattern regex. Quando Indeed cambia il suo HTML, Thunderbit si adatta automaticamente. Questo affronta direttamente il peso della manutenzione che gli utenti nei forum citano costantemente come principale frustrazione. Se ti sei mai svegliato con un messaggio Slack che dice “lo scraper sta restituendo di nuovo righe vuote”, sai quanto vale non doverlo sistemare.
Estrarre Indeed senza scrivere Python: l’alternativa no-code
Ogni guida concorrente dà per scontato che tu scriva codice Python. Ma i dati dei forum raccontano una storia diversa. Gli utenti dicono cose come "è semplicemente troppo difficile con bug ed errori continui" e alcuni suggeriscono di assumere qualcuno su Fiverr solo per ottenere i dati. Se ti riconosci in questo, questa sezione è la tua via d’uscita.
Come estrarre Indeed con Thunderbit (passo dopo passo)
Passo 1: Installa l’ dal Chrome Web Store. È gratis per iniziare.
Passo 2: Vai in una pagina dei risultati di ricerca di Indeed nel tuo browser — per esempio, https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX.
Passo 3: Fai clic sull’icona di Thunderbit nella barra degli strumenti del browser, poi su "Suggerisci campi con AI." L’AI di Thunderbit analizza la pagina e rileva automaticamente colonne come Titolo del lavoro, Azienda, Località, Stipendio, URL del lavoro e Data di pubblicazione. Puoi rivedere e modificare i campi suggeriti — rimuovere le colonne che non ti servono oppure aggiungerne di personalizzate descrivendo ciò che vuoi in linguaggio naturale.
Passo 4: Fai clic su "Estrai." Thunderbit estrae i dati dalla pagina e li mostra in una tabella strutturata. Dovresti vedere righe di annunci con i campi che hai configurato.
Arricchisci con lo scraping delle sottopagine
Dopo aver estratto la pagina elenco, fai clic su "Estrai sottopagine" per far visitare a Thunderbit ogni singola pagina di dettaglio del lavoro. Recupera descrizioni complete, qualifiche, benefit e link di candidatura — senza bisogno di configurazione aggiuntiva. È l’equivalente di scrivere un secondo scraper Python per visitare ogni URL /viewjob?jk=<jobkey>, ma basta un clic.
Gestione automatica della paginazione
Thunderbit gestisce automaticamente la paginazione basata sui clic di Indeed. Non serve costruire manualmente URL con offset o scrivere cicli di paginazione. Clicca tra le pagine e aggrega i risultati.
Esporta nei tuoi strumenti preferiti
Esporta i dati estratti in CSV, Excel, Google Sheets, Airtable o Notion — . Nessun bisogno di scrivere codice csv.writer() o pandas.to_csv().
Quando usare Python vs Thunderbit
| Scenario | Strumento migliore |
|---|---|
| Pipeline dati personalizzate, automazione pianificata via cron/Airflow | Python |
| Integrazione in una codebase più grande | Python |
| Logica di parsing altamente personalizzata | Python |
| Ricerca una tantum o analisi di mercato | Thunderbit |
| I membri del team non tecnici hanno bisogno dei dati | Thunderbit |
| Ottenere subito i dati senza debuggare i 403 | Thunderbit |
| Arricchimento delle sottopagine senza alcuna configurazione | Thunderbit |
Confronto dei tempi: configurazione Python + debugging anti-bot = ore o giorni (soprattutto la prima volta). Thunderbit = meno di 2 minuti per gli stessi dati. Non sto dicendo che Python sia sbagliato — sto dicendo che dipende da ciò di cui hai bisogno.
È legale estrarre Indeed? Quello che devi sapere
Nessuna delle guide meglio posizionate sull’estrazione di Indeed affronta la legalità, il che è sorprendente visto quanto spesso viene fuori la domanda "È legale estrarre Indeed?" nei forum. Questo non è un parere legale, ma ecco il quadro generale.
Termini di servizio di Indeed
I Termini di servizio di Indeed () non contengono una clausola generale di “divieto di scraping”. L’unica proibizione esplicita sull’automazione è la sezione A.3.5, che vieta "l’uso di automazione, scripting o bot per automatizzare il processo Indeed Apply". È una limitazione circoscritta al flusso di candidatura, non alla lettura passiva degli annunci pubblici. Il principale strumento di enforcement di Indeed è tecnico — sfide Cloudflare, ban IP, fingerprinting del dispositivo — non il tribunale.
Precedenti legali rilevanti
Il caso statunitense più citato è hiQ Labs v. LinkedIn. La 9th Circuit che lo scraping di dati pubblicamente accessibili “probabilmente non viola il CFAA” (Computer Fraud and Abuse Act). Tuttavia, hiQ è stata poi ritenuta perché i suoi dipendenti avevano creato falsi profili LinkedIn e accettato i ToS.
Più di recente, Meta v. Bright Data (N.D. Cal., gennaio 2024) ha prodotto una decisione ancora più chiara. Il giudice Chen che i Termini di Facebook e Instagram “non vietano lo scraping, quando si è disconnessi, dei dati pubblici”. Il mese successivo Meta ha ritirato volontariamente le restanti richieste.
robots.txt di Indeed
Il di Indeed vieta in modo ampio /jobs/ e /job/ per il User-agent: * predefinito, ma consente esplicitamente a Googlebot e Bingbot di accedere a /viewjob? — le singole pagine di dettaglio degli annunci. I crawler per l’addestramento dell’AI (GPTBot, CCBot, anthropic-ai) sono fortemente limitati. robots.txt non è giuridicamente vincolante negli USA, ma rispettarlo è una buona pratica ed è prova di buona fede.
Linee guida pratiche per uno scraping responsabile
- Estrai solo dati pubblicamente disponibili — non effettuare mai login, non creare account falsi
- Rispetta i limiti di frequenza: 1 richiesta ogni 3–6 secondi per IP, concorrenza a una cifra
- Non ripubblicare i dati estratti come se fossero una tua bacheca di lavoro
- Usa i dati per ricerche personali o interne, non per rivenderli commercialmente senza permesso
- Elimina o rendi hash i dati personali non necessari; imposta un tetto di conservazione per i dati vicini a informazioni personali
- Se operi su larga scala o nell’UE/UK, consulta un avvocato — gli obblighi di trasparenza dell’Articolo 14 del GDPR si applicano ai dati personali estratti
La scala del rischio: l’automazione della ricerca di lavoro personale è nella fascia bassa. La rivendita commerciale su larga scala dei dati di Indeed è nella fascia alta.
Conclusione e punti chiave
Estrarre Indeed con Python è fattibile, ma non è un progetto da weekend da impostare e dimenticare. La protezione Cloudflare di Indeed, i selettori che ruotano e le misure anti-bot aggressive significano che devi affrontare il tutto con gli strumenti giusti e le aspettative giuste.
Ecco cosa mi porto via da tutto questo:
- Indeed è la fonte più ricca di dati sul mercato del lavoro sul web — 350 milioni di visitatori mensili, 130 milioni di annunci — ma reagisce duramente contro gli scraper.
- L’estrazione del JSON nascosto (
window.mosaic.providerData) è l’approccio Python più resistente. Lo schema è stabile da anni, mentre i selettori CSS si rompono ogni mese. curl_cfficon impersonificazione del browser è il client HTTP predefinito del 2026 per i siti protetti da Cloudflare.requestsehttpxstandard vengono bloccati già per la sola impronta TLS.- Usa sempre header rotanti, ritardi casuali e proxy residenziali per evitare errori 403. I proxy datacenter sono quasi inutili contro Cloudflare Enterprise.
- Aggiungi controlli con assert così sai subito quando i selettori si rompono o quando ti viene servita una pagina di challenge invece dei dati di lavoro.
- Per chi non è tecnico o per chi vuole semplicemente risultati rapidi, offre un percorso no-code, basato su AI, che si adatta automaticamente ai cambiamenti del sito — niente proxy, niente debugging, niente manutenzione.
Se vuoi provare la strada no-code, così puoi testarlo su Indeed senza alcun impegno. E se invece scegli la via Python, gli esempi di codice qui sopra sono un buon punto di partenza — ricordati solo di trattare la resilienza anti-bot come una priorità, non come un ripensamento.
Per approfondire altri approcci e strumenti di web scraping, consulta le nostre guide su , e . Puoi anche guardare tutorial sul .
FAQ
Quali librerie Python sono migliori per estrarre Indeed?
Per le richieste HTTP, curl_cffi è la scelta più forte nel 2026 — imita le impronte TLS reali del browser, cosa essenziale per aggirare Cloudflare. httpx con HTTP/2 è un buon piano B per target meno protetti. Per il parsing HTML, BeautifulSoup4 con lxml resta lo standard. Per l’automazione del browser, Playwright (con playwright-stealth) o undetected-chromedriver funzionano, anche se entrambi sono sempre più rilevabili. L’approccio con regex sul JSON nascosto (window.mosaic.providerData) evita del tutto la necessità di un parsing pesante.
Perché continuo a ricevere errori 403 quando estraggo Indeed?
Indeed usa Cloudflare Bot Management, che controlla la tua impronta TLS (JA3/JA4), l’ordine degli header HTTP/2, i pattern delle richieste e il comportamento del browser. Se usi requests standard, la tua impronta TLS ti identifica subito come script Python — il 403 arriva prima ancora che i tuoi header vengano letti. Risolvi passando a curl_cffi con impersonificazione del browser, ruotando stringhe User-Agent realistiche, aggiungendo ritardi casuali (3–6 secondi) e usando proxy residenziali. Controlla anche il caso “200 con challenge Turnstile” — cerca i marker cf-turnstile nel corpo della risposta.
Posso estrarre Indeed senza programmare?
Sì. Strumenti come ti permettono di estrarre gli annunci di Indeed in pochi clic — installa l’estensione Chrome, vai su una pagina di ricerca Indeed, fai clic su "Suggerisci campi con AI" e poi su "Estrai". L’AI di Thunderbit rileva automaticamente campi come titolo del lavoro, azienda, località e stipendio. Gestisce paginazione, arricchimento delle sottopagine (descrizioni complete) e protezioni anti-bot in automatico. Esporta in CSV, Google Sheets, Airtable o Notion gratuitamente.
Quanto spesso Indeed cambia la sua struttura HTML?
Indeed ruota regolarmente i nomi delle classi CSS (ad esempio css-1m4cuuf, stringhe hash casuali) e ristruttura gli elementi DOM senza preavviso. I test A/B fanno sì che utenti diversi possano vedere layout diversi nello stesso momento. L’approccio con JSON nascosto (window.mosaic.providerData) è molto più stabile — lo schema è coerente almeno dal 2023. Quando devi usare selettori DOM, punta agli attributi data-testid e a data-jk (job key) invece che alle classi CSS.
È legale estrarre Indeed?
Lo scraping, quando si è disconnessi, di URL pubblicamente accessibili di Indeed è improbabile che generi responsabilità CFAA negli USA, sulla base della sentenza della 9th Circuit hiQ v. LinkedIn (2022) e della decisione Meta v. Bright Data (2024). I ToS di Indeed vietano specificamente l’automazione del processo Apply, non la lettura passiva degli annunci pubblici. Detto questo, estrai sempre in modo responsabile: non effettuare login, non creare account falsi, rispetta i limiti di frequenza, non ripubblicare i dati come se fossero una tua bacheca di lavoro e gestisci con attenzione eventuali dati personali (nomi di recruiter, email) ai sensi di GDPR/CCPA. Per operazioni commerciali su larga scala, consulta un avvocato.
Scopri di più