Google ha chiuso la sua API Flights nel 2018, ma i prezzi dei voli continuano a cambiare — per una singola tratta nazionale. Se vuoi accedere a questi dati in modo programmatico, lo scraping è praticamente l’unica strada disponibile.
Negli ultimi tempi ho testato a lungo diversi approcci per recuperare i dati dei voli da Google, e il panorama è cambiato in modo drastico — soprattutto dopo il lancio di SearchGuard da parte di Google nel gennaio 2025. In questa guida ti mostrerò come costruire un crawler Python funzionante per Google Flights con Playwright, come gestire le difese anti-bot che mettono in difficoltà la maggior parte delle persone e come trasformare il tutto in un tracker automatico dei prezzi con avvisi. Se preferisci saltare completamente il codice, ti mostrerò anche una scorciatoia no-code con che porta allo stesso risultato in circa due minuti.
Perché estrarre Google Flights con Python?
Google Flights domina la ricerca dei voli. La sua visibilità su mobile negli Stati Uniti è , superando tutti i principali OTA. Il mercato dei metasearch travel che lo supporta è stato valutato a e cresce con un CAGR del 30,2%. Eppure, da quando la QPX Express API è stata , non esiste un modo ufficiale per accedere a questi dati in modo programmatico.
Nel frattempo, i prezzi dei voli oscillano per lo stesso itinerario, con uno scarto medio di circa 20 dollari tra il prezzo minimo e quello massimo. Compagnie come Delta usano 77 fasce tariffarie per il dynamic pricing. La media dei voli A/R negli Stati Uniti all’inizio del 2026 si attesta a 408 dollari, con tariffe .
Piattaforma dominante, niente API, prezzi volatili. Ecco perché lo scraping di Google Flights con Python è diventato uno dei progetti più popolari su GitHub e nei forum di viaggio.
Ecco chi ne trae vantaggio e in che modo:
| Tipo di utente | Caso d'uso | Vantaggio principale |
|---|---|---|
| Viaggiatori singoli | Monitorare nel tempo i prezzi di tratte specifiche | Risparmiare in media $50 per volo |
| Agenzie di viaggio | Intelligence sui prezzi della concorrenza | Monitoraggio in tempo reale della parità tariffaria |
| Team travel aziendali | Ottimizzazione dei costi sulle tratte | Risparmi del 10–30% sui viaggi business |
| Sviluppatori | Creare app di confronto tariffe | Accesso programmatico ai dati sui prezzi |
| Ricercatori | Analisi della volatilità dei prezzi delle compagnie aeree | Ricerca accademica e di mercato |
Chi frequenta i forum è molto diretto sul motivo per cui ha scelto lo scraping: "Google Flights API was discontinued and I should use web scraping instead" è un commento che ricorre spesso. E il ritorno sull’investimento è reale — analizzando oltre 5 miliardi di quotazioni al giorno, mentre i dati Expedia del 2026 mostrano che prenotare con 8–15 giorni di anticipo fa risparmiare circa .
Quali dati puoi estrarre da Google Flights?
Una pagina dei risultati di Google Flights contiene una quantità sorprendentemente ricca di informazioni. Ecco cosa è in genere disponibile:
- Nome della compagnia aerea (e logo)
- Orario di partenza e codice aeroporto
- Orario di arrivo e codice aeroporto
- Durata totale del volo
- Numero di scali e dettagli sulle coincidenze (aeroporto, durata, overnight sì/no)
- Prezzo del biglietto (in base alla valuta)
- Emissioni di CO2 (kg CO2e, con differenza percentuale rispetto ai voli tipici)
- Classe di viaggio, numero del volo, modello dell’aereo
- Dati sullo spazio per le gambe
- Servizi aggiuntivi (Wi‑Fi, prese di corrente, streaming multimediale)
- Indicatore del livello di prezzo (basso/normale/alto)
- Avvisi di ritardo ("Often delayed by over 30 min")
La disponibilità dei dati varia in base alla tratta, alla data e al tipo di biglietto (solo andata vs andata e ritorno). Ecco come appare un singolo record di volo estratto in formato JSON:
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}Configurare l’ambiente Python
Prima di scrivere qualsiasi codice di scraping, devi predisporre alcune cose.
Prerequisiti:
- Difficoltà: Intermedia
- Tempo richiesto: circa 1–2 ore per il tutorial completo
- Cosa ti serve: Python 3.7+, conoscenze base di Python, un browser basato su Chrome
Installa le librerie necessarie
Useremo Playwright per l’automazione del browser (Google Flights è al 100% renderizzato in JavaScript — le richieste HTTP statiche non restituiscono nulla di utile), più alcuni strumenti di supporto:
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — automazione browser headless, gestisce il rendering JavaScript e include meccanismi di attesa integrati
- playwright-stealth — attenua i segnali più comuni di rilevamento bot
- pandas — per l’analisi dei dati e l’esportazione CSV in seguito
Perché Playwright invece di Selenium o requests
Google Flights non funziona con requests + BeautifulSoup da soli — il contenuto della pagina viene renderizzato interamente via JavaScript. Ti serve un browser vero.
| Funzione | Playwright | Selenium | requests + BS4 |
|---|---|---|---|
| Rendering JS | Supporto completo | Supporto completo | Nessuno |
| Velocità | 42% più veloce in generale | Base | N/D per questo caso d'uso |
| Supporto async | Nativo | Solo sequenziale | N/D |
| Uso memoria | 30% in meno | Più alto | Minimo |
| Elusione anti-bot | Buona (con stealth) | Più facile da rilevare | N/D |
Playwright è più veloce, più moderno e offre un supporto async migliore. Per Google Flights, in particolare, è la scelta più solida.
Passo dopo passo: come estrarre Google Flights con Python
Questa è la parte centrale del tutorial. Costruiremo lo scraper un pezzo alla volta.
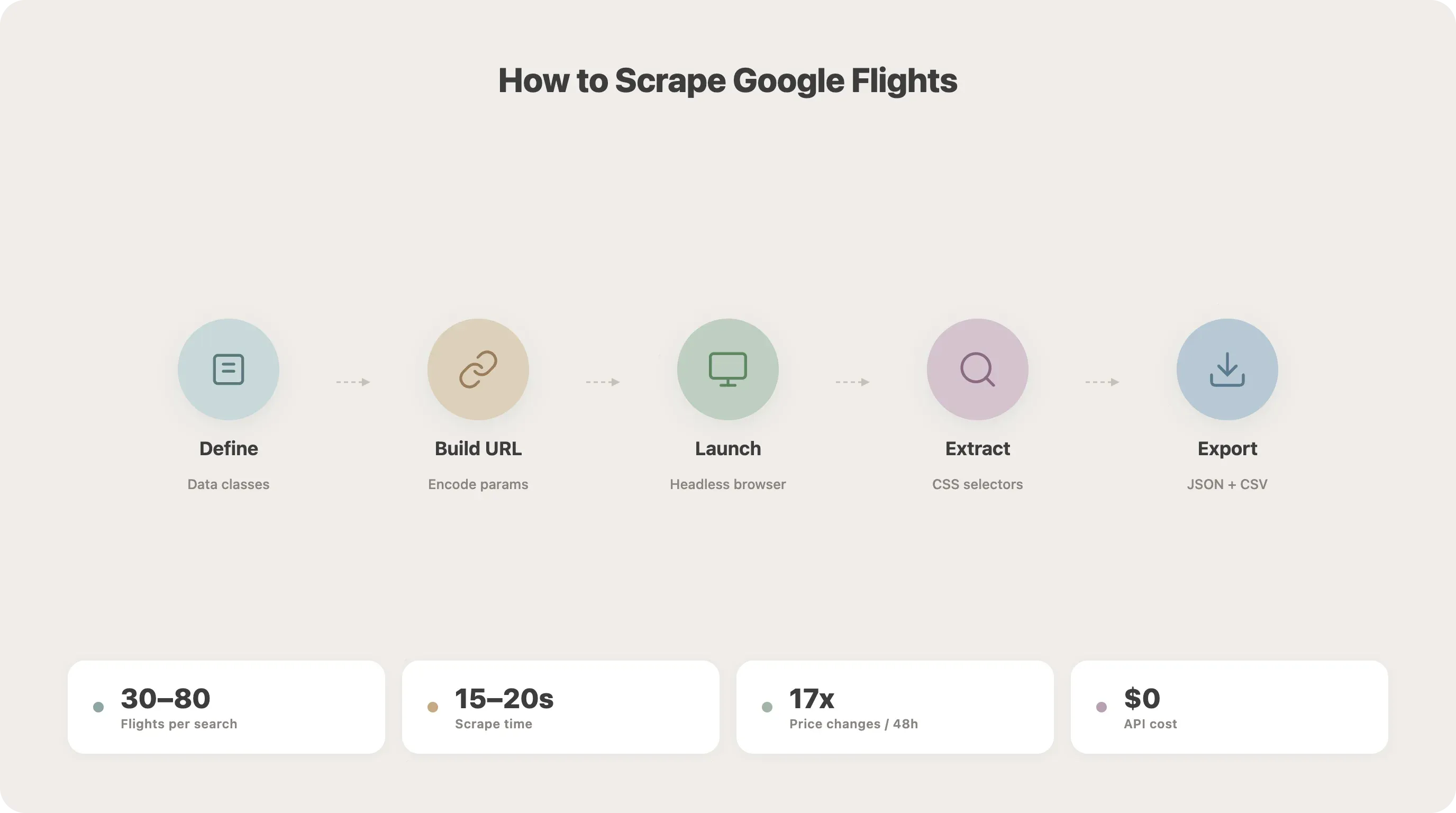
Passo 1: definisci le tue classi dati
Inizia strutturando i parametri di ricerca e i dati dei voli con le dataclass di Python. In questo modo il codice resta pulito ed è più facile ampliarlo in seguito.
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # e.g., "SFO"
6 destination: str # e.g., "JFK"
7 departure_date: str # e.g., "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" or "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""Ogni campo corrisponde direttamente a ciò che estrarremo dalla pagina. Avere questa struttura fin dall’inizio evita di dover passare in giro dizionari disordinati più avanti.
Passo 2: capire la struttura dell’URL di Google Flights
Google Flights codifica i parametri di ricerca usando Protobuf codificato in Base64 nel parametro URL tfs. Puoi provare a decodificare questo formato, oppure scegliere l’approccio più semplice: costruire un URL in linguaggio naturale.
Il metodo più semplice è usare il formato della query di ricerca:
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USDPer avere più controllo, puoi generare gli URL in modo programmatico:
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"L’alternativa — fare reverse engineering della codifica Protobuf — dà un controllo più preciso, ma si rompe ogni volta che Google modifica il formato interno. Librerie come su GitHub usano la decodifica Protobuf per evitare del tutto il parsing dell’HTML, ma si tratta di un approccio più avanzato.
Passo 3: avvia il browser e apri Google Flights
Ecco la configurazione Playwright. Usiamo playwright-stealth per ridurre il rischio di rilevamento fin dall’inizio.
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # Pre-imposta il cookie di consenso per saltare il popup
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()Stiamo eseguendo tutto in headless per la produzione (passa a headless=False per il debug), impostando un viewport e un user agent realistici, e preconfigurando il cookie SOCS per saltare il popup del consenso — torneremo su questo nella sezione anti-bot.
Passo 4: vai alla pagina dei risultati
Carica l’URL costruito e attendi che appaiano i risultati dei voli:
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # Attendi il caricamento dei risultati dei voli
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )Se qui vai in timeout, di solito significa che il popup di consenso ha bloccato la pagina (vedi il fix con il cookie nel Passo 3) oppure che Google sta servendo un CAPTCHA. Nella sezione anti-bot vedremo entrambe le situazioni.
Passo 5: carica tutti i risultati dei voli
Google Flights nasconde altri risultati dietro il pulsante "Show more flights". Devi cliccarlo più volte finché tutti i voli non sono visibili:
1 # Clicca "Show more flights" finché tutti i risultati non sono caricati
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 breakQuesto ciclo clicca il pulsante, attende 2 secondi che i nuovi risultati vengano renderizzati e si ferma quando il pulsante non è più visibile. Nei miei test, la maggior parte delle tratte mostra 1–3 pagine di risultati.
Passo 6: estrai i dati dei voli con i selettori CSS
Ora analizziamo i dati reali dei voli dalla pagina caricata. Ecco i selettori (verificati ad aprile 2026 — vedi la sezione manutenzione più sotto per capire perché questa data è importante):
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # Nome compagnia
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # Orario di partenza
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # Orario di arrivo
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # Durata
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # Scali
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # Prezzo
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # Emissioni di CO2
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flightsAttenzione: classi come pIav2d, sSHqwe e FpEdX sono generate dal Closure Compiler di Google e possono cambiare da una build all’altra. I selettori basati su aria-label sono più stabili. Più avanti vedremo una strategia completa di manutenzione.
Passo 7: salva i risultati in JSON o CSV
Infine, salva i dati estratti con un timestamp (fondamentale per il price tracking successivo):
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # Salva anche in CSV
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"Scraped {len(flights)} flights")
25asyncio.run(main())Eseguendo questo script dovresti ottenere flights.json e flights.csv con i risultati. Nei miei test, una ricerca SFO-JFK restituisce in genere 30–80 opzioni di volo e richiede circa 15–20 secondi per completarsi.
Guida di sopravvivenza anti-bot per lo scraping di Google Flights
La maggior parte dei tutorial si ferma qui. La maggior parte degli scraper fallisce qui. Google ha introdotto , e questo ha rotto quasi tutti gli scraper SERP da un giorno all’altro. Google lo descrive come "il risultato di decine di migliaia di ore-uomo e milioni di dollari di investimento". Google Flights è classificato con difficoltà per lo scraping.
Nessun articolo concorrente affronta questo aspetto in profondità, eppure è il motivo numero uno per cui gli scraper smettono di funzionare. Ecco contro cosa devi misurarti e come gestirlo.

Ritardi casuali tra le richieste
La difesa più semplice contro il rate limiting. Due righe di codice, efficacia media:
1import time
2import random
3time.sleep(random.uniform(3, 7))Aggiungile tra una navigazione e l’altra. Intervalli fissi (per esempio sempre 5 secondi esatti) sono un segnale d’allarme — meglio randomizzare.
Rotazione dello User-Agent
Inviare sempre la stessa stringa user-agent è un indizio facile da individuare. Ruotala prendendola da una lista:
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)Bypass del rilevamento headless
Google controlla il flag navigator.webdriver e altri segnali di automazione. La libreria playwright-stealth gestisce già gran parte di questi aspetti, ma dovresti comunque impostare anche gli argomenti di avvio mostrati nel Passo 3. I flag chiave:
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]Questo ti aiuta a superare il rilevamento di base. SearchGuard va più a fondo — monitora velocità del mouse, tempi di pressione dei tasti e pattern di scrolling — ma per scraping a volume moderato la modalità stealth, insieme a ritardi realistici, è di solito sufficiente.
Rotazione proxy: datacenter vs residential
Per qualsiasi cosa oltre poche ricerche, ti serviranno dei proxy. La differenza conta:
I proxy residential sono circa quando si estraggono siti protetti. Prezzi dei provider nel 2026: Smartproxy da $7/GB, Bright Data $8,40/GB, Oxylabs $8/GB.
Puoi aggiungere un proxy a Playwright così:
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)Gestione del popup di consenso cookie
Gli utenti segnalano in modo ricorrente il popup "I agree to terms" come blocco: "first google will show you the 'I agree to terms and conditions' popup." La soluzione più pulita è preimpostare il cookie SOCS (come visto nel Passo 3). Se non basta, clicca direttamente sul popup:
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # Nessun popup presenteNota: il testo del pulsante varia in base alla lingua — "Alle akzeptieren" in tedesco, "Tout accepter" in francese.
Riferimento rapido anti-bot
| Tecnica | Difficoltà | Efficacia | Richiede codice? |
|---|---|---|---|
| Ritardi casuali (2–7s) | Bassa | Media | 2 righe |
| Rotazione user-agent | Bassa | Media | 5 righe |
| Bypass rilevamento headless | Media | Alta | Argomenti di avvio Playwright |
| Plugin playwright-stealth | Media | 60–80% su siti base | pip install |
| Rotazione proxy (datacenter) | Media | Media | Configurazione |
| Rotazione proxy (residential) | Media | 85–95% di successo | Configurazione |
| Preimpostazione consenso cookie (SOCS) | Bassa | Richiesto | 1 riga |
Per le frequenze sicure consigliate: mantieni intervalli di 10–20 secondi tra le richieste con rotazione IP. Le soglie di Google sono circa 100 richieste/minuto per IP prima di ricevere un 429, e volumi sostenuti oltre 1.000 richieste/giorno per IP possono attivare blocchi temporanei.
Perché i selettori di Google Flights continuano a rompersi (e come risolvere)
È il problema n. 1, di gran lunga. I thread nei forum sono pieni di varianti del tipo "all I get back is 14 empty lists." Ogni tutorial ti dà dei selettori. Nessuno spiega perché smettono di funzionare.
Perché i selettori di Google Flights cambiano
Dipende da tre fattori:
-
Offuscamento tramite Closure Compiler. Google usa per generare nomi di classe come
BVAVmfeYMlIztramitegoog.setCssNameMapping(). Questi cambiano a ogni build — a volte ogni settimana. -
A/B testing. Utenti diversi vedono contemporaneamente strutture HTML diverse. Il tuo scraper può funzionare sulla tua macchina ma fallire per qualcuno in un’altra regione.
-
Differenze di localizzazione. Gli utenti UE vedono termini, layout e perfino campi dati diversi rispetto a quelli negli Stati Uniti.
Scrivi selettori più robusti
Preferisci selettori legati al significato invece che all’aspetto:
1# Fragile — si rompe a ogni build
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# Più resistente — legato alle etichette di accessibilità
4dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# Anch'esso resistente — matching basato sul testo
6more_btn = page.locator('button:has-text("Show more flights")')Gerarchia di stabilità dei selettori (dal più stabile al meno stabile):
- Attributi
aria-label— legati all’accessibilità, raramente modificati - Attributi
data-*— aggiunti esplicitamente per la funzionalità - Attributi
role— i ruoli ARIA sono semantici - Selettori basati sul testo — corrispondono al contenuto visibile
- Matching parziale delle classi — ad es.
[class*="price"] - Nomi di classe completi offuscati — da evitare quando possibile
Aggiungi una funzione di validazione
Non lasciare che selettori rotti producano dati vuoti senza accorgertene. Intercettali subito:
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"Missing '{field_name}' — selectors may need updating"
11 )
12 valid = False
13 return validEsegui questa verifica su ogni volo estratto. Se inizi a vedere warning, è il momento di ispezionare la pagina e aggiornare i selettori.
Strategia di manutenzione dei selettori
- Controlla i selettori ogni mese, oppure subito quando la qualità dei risultati cala
- Tieni i selettori in un dizionario di configurazione separato, così è facile aggiornarli
- I selettori di questo articolo sono stati verificati l’ultima volta: aprile 2026
- Valuta la libreria come alternativa — usa la decodifica Protobuf invece dei selettori CSS, aggirando del tutto questo problema (anche se resta comunque esposta quando Google cambia i formati dati interni)
Da scraping una tantum a tracker automatico dei prezzi di Google Flights
La maggior parte dei tutorial finisce con "salva in JSON". Il titolo di questo articolo parla di "Price Alerts". È il momento di mantenere la promessa.
![]()
Pianifica l’esecuzione automatica dello scraper
Opzione 1: libreria schedule di Python (la più semplice, multipiattaforma):
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)Opzione 2: cron job (Linux/Mac):
1# Esegui alle 6:00 e alle 18:00 ogni giorno
20 6,18 * * * cd /path/to/scraper && python scraper.pyOpzione 3: Utilità di pianificazione di Windows — crea un’attività di base che esegue python scraper.py secondo la frequenza che preferisci.
Il compromesso è che tutte queste soluzioni richiedono una macchina sempre accesa. Se lo fai girare su un laptop che va in sospensione, perderai alcune esecuzioni.
Conserva lo storico dei prezzi
Passa dalla sovrascrittura di un file JSON all’inserimento progressivo in un database SQLite:
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()Dopo una settimana di scraping due volte al giorno, avrai abbastanza dati per iniziare a cogliere dei trend.
Analizza l’andamento dei prezzi e imposta avvisi
Trova l’opzione più economica nei dati storici:
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"Più economico: ${cheapest['price_usd']:.0f} il "
13 f"{cheapest['scrape_date']} ({cheapest['airline']})"
14)Attiva un avviso email quando il prezzo scende sotto la soglia desiderata:
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"Price drop alert! {route}: ${price:.0f} "
6 f"(below your ${threshold:.0f} threshold)"
7 )
8 msg["Subject"] = f"Flight Deal: {route} at ${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# Dopo ogni scraping, controlla se ci sono offerte
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")Per una frequenza di scraping consigliata: due volte al giorno è sufficiente per il monitoraggio personale dei prezzi (la tempistica casuale riduce il rischio di rilevamento). Ogni 4–6 ore se stai monitorando per un’azienda. Ogni ora solo durante i periodi di forte promozione, e solo temporaneamente.
La strada più semplice: lo Scheduled Scraper di Thunderbit
Se gestire cron job, un server sempre acceso e configurazioni proxy ti sembra più infrastruttura di quanta tu ne voglia mantenere, lo copre lo stesso caso d’uso senza quel peso operativo. Descrivi in linguaggio naturale l’intervallo di scraping, inserisci gli URL di Google Flights e lo scraper gira automaticamente sull’infrastruttura cloud di Thunderbit — con gestione anti-bot integrata ed export diretto verso . Non sostituisce completamente l’approccio Python (rinunci alla personalizzazione), ma per il caso d’uso specifico "voglio un foglio di calcolo con il monitoraggio dei prezzi", è la strada più rapida. Puoi provarlo nel .
Quando Python è eccessivo: modi no-code per estrarre Google Flights
Dopo aver costruito tutto questo, lo dico con sincerità: ci sono parecchi pezzi in gioco. Non tutti hanno bisogno di un livello così alto di controllo. I selettori si rompono, i proxy vanno ruotati, i cron job vanno monitorati. Se il tuo obiettivo è "portare regolarmente i prezzi dei voli in un foglio di calcolo", esistono opzioni più veloci.
Confronto: Python fai-da-te vs servizi API vs Thunderbit
| Approccio | Tempo di configurazione | Serve codice | Gestione anti-bot | Pianificazione | Costo |
|---|---|---|---|---|---|
| Playwright fai-da-te (questo tutorial) | 1–2 ore | Python (intermedio) | Configurazione manuale | Manuale (cron) | Gratis + costi proxy |
| Endpoint Google Flights di SerpApi | 15 min | Solo chiamate API | Gestita | Via API | circa $50+/mese |
| Estensione Chrome di Thunderbit | 2 min | Nessuno | Scraping cloud | Scheduler integrato | Piano gratuito disponibile |
Una nota su SerpApi: Google , sostenendo che le loro richieste siano aumentate del 25.000% in due anni. Questa incertezza legale vale la pena considerarla se stai valutando provider API.
Come Thunderbit estrae Google Flights
Apri i risultati di ricerca di Google Flights in Chrome, clicca il pulsante "AI Suggest Fields" di Thunderbit — l’AI legge la pagina e suggerisce colonne come compagnia, prezzo, orario di partenza, scali — controlla i campi proposti e clicca "Scrape." I risultati compaiono in una tabella che puoi esportare in Excel, Google Sheets, Airtable o Notion — tutto nel .
Per il caso d’uso del price tracking, in particolare, lo Scheduled Scraper di Thunderbit e il (capace di gestire 50 pagine in contemporanea) sostituiscono tutta l’infrastruttura fatta di cron, proxy e server.
Python ti dà pieno controllo e personalizzazione illimitata. Thunderbit ti offre velocità e manutenzione zero. Scegli in base al tuo obiettivo reale. Se vuoi approfondire gli approcci no-code allo scraping, dai un’occhiata alla nostra guida sui .

È legale fare scraping di Google Flights? Cosa devi sapere
Gli utenti nei forum sollevano spesso questo punto: "scraping Google Flights directly violates the TOS that Google has." Preoccupazione legittima — soprattutto perché l’API è stata dismessa e non esiste un’alternativa ufficialmente autorizzata.
Violazione dei TOS vs responsabilità legale
I Termini di servizio di Google (aggiornati il 22 maggio 2024) stabiliscono che gli utenti non devono "accedere o utilizzare i Servizi o qualsiasi contenuto tramite mezzi automatizzati (come robot, spider o scraper)." La violazione dei ToS è un inadempimento contrattuale (materia civile) — non equivale automaticamente a violare la legge.
Il precedente legale chiave: hiQ v. LinkedIn (Nono Circuito, 2022) ha stabilito che lo scraping di dati pubblicamente disponibili non viola il Computer Fraud and Abuse Act (CFAA). Tuttavia, il caso si è chiuso con un accordo, e la causa di dicembre 2025 contro SerpApi usa una teoria legale diversa — la Sezione 1201 del DMCA (elusione delle misure tecnologiche di protezione) — potenzialmente più seria.
Best practice per uno scraping responsabile
- Limita la frequenza delle richieste — ritardi di 10–20 secondi con rotazione IP
- Non estrarre dati personali — i prezzi dei voli sono dati aggregati mostrati pubblicamente
- Non aggirare i CAPTCHA in modo programmatico (qui entra in gioco il rischio DMCA)
- Usa i dati per ricerca personale, non per costruire un prodotto commerciale concorrente senza licenza adeguata
- Valuta le API ufficiali dove disponibili
Fonti dati alternative
Se per il tuo caso d’uso lo scraping ti sembra troppo rischioso, esistono opzioni API legittime:
| Provider | Costo | Piano gratuito | Note |
|---|---|---|---|
| SerpApi | $75–$3.750+/mese | 250 ricerche/mese | JSON di Google Flights diretto (sotto esame legale) |
| Kiwi Tequila | Gratis (modello affiliate) | Illimitato | Ottimo per startup e test |
| Amadeus | Pay-as-you-go | 2.000 richieste/mese | Oltre 400 compagnie, possibilità di prenotazione |
| Skyscanner | Personalizzato | Richiede approvazione | 52 mercati, 30 lingue |
Abbiamo scritto un approfondimento più dettagliato sulle se vuoi una panoramica completa.
Conclusione e punti chiave
È stato tanto, lo so. Ecco ciò che conta davvero:
- Python + Playwright è l’approccio più flessibile per estrarre Google Flights, ma richiede manutenzione continua
- Le difese anti-bot (ritardi, rotazione user-agent, proxy residential) non sono opzionali — sono fondamentali per l’affidabilità, soprattutto dopo SearchGuard
- I selettori si rompono spesso — usa
aria-labele selettori basati sul testo quando possibile, valida l’output e tieni una routine di manutenzione - Automatizza con
scheduleo cron per trasformare uno scraping una tantum in un vero tracker dei prezzi con storico e avvisi email - offre un’alternativa no-code con pianificazione integrata, scraping cloud e gestione anti-bot — ideale se il tuo obiettivo è un foglio di calcolo per il tracking dei prezzi più che un progetto di programmazione
- Rispetta i limiti legali — limita la frequenza, estrai solo dati pubblici e valuta alternative API per usi commerciali
Scarica il codice di questo tutorial oppure installa l’ per la strada più rapida. In ogni caso, passerai a monitorare i prezzi dei voli invece di aggiornare manualmente Google Flights.
Per altre tecniche di scraping in Python, consulta le nostre guide su e sui .
FAQ
1. Posso estrarre Google Flights senza Python?
Sì. Servizi API come SerpApi e Kiwi Tequila forniscono dati strutturati sui voli tramite chiamate API (senza bisogno di automazione browser). Per un approccio completamente no-code, può estrarre direttamente i risultati di Google Flights dal browser con campi suggeriti dall’AI ed export con un clic.
2. Google blocca lo scraping dei voli?
Google usa sistemi di rilevamento bot (SearchGuard), CAPTCHA e rate limiting. Con misure anti-bot adeguate — ritardi casuali, rotazione user-agent, proxy residential e impostazioni stealth del browser — puoi mantenere uno scraping affidabile a volumi moderati. Consulta la sezione anti-bot sopra per tecniche e soglie specifiche.
3. Con che frequenza dovrei estrarre Google Flights per il price tracking?
Due volte al giorno (in orari casuali) bastano per il monitoraggio personale dei prezzi e mantengono basso il rischio di rilevamento. Per il monitoraggio business, ogni 4–6 ore con rotazione dei proxy. Evita lo scraping orario, salvo brevi periodi di promozione delle tariffe — aumenta molto la probabilità di blocco.
4. Esiste una API gratuita di Google Flights?
L’API ufficiale Google QPX Express è stata . Non esiste un sostituto ufficiale gratuito. L’opzione più vicina e gratuita è la (modello affiliate, ricerche illimitate). SerpApi offre 250 ricerche gratuite al mese. Per la maggior parte degli utenti, lo scraping o uno strumento no-code come Thunderbit è la strada più pratica.
5. Perché i selettori CSS di Google Flights continuano a restituire dati vuoti?
Google usa il Closure Compiler per generare nomi di classe offuscati che cambiano a ogni build. Anche gli A/B test e le differenze di localizzazione fanno variare la struttura HTML tra utenti diversi. La soluzione: usare attributi aria-label e selettori basati sul testo invece dei nomi di classe, aggiungere una funzione di validazione per intercettare presto i problemi e controllare i selettori ogni mese. Vedi la sezione sulla manutenzione dei selettori per una strategia dettagliata.
Scopri di più