Se il tuo scraper per Glassdoor andava benissimo nel 2022 e oggi ti spara solo errori 403, non sei certo l’unico. Forum dopo forum sono pieni della stessa domanda: "Qualcuno sa perché questo scraper non funziona più?"
La risposta corta: Glassdoor ha cambiato tutto. Recruit Holdings ha integrato Glassdoor in Indeed nel luglio 2025, ha licenziato e ha reso lo stack anti-bot così rigido che gli scraper basati su Selenium standard e requests vengono fermati ancora prima che venga caricato il primo byte di HTML. A febbraio 2026, i login di Glassdoor sono gestiti interamente tramite Indeed Login: quindi qualsiasi tutorial che codifica in modo fisso un form di accesso specifico per Glassdoor ormai si rompe alla base. Nel frattempo, la piattaforma continua a ospitare distribuiti su . Sono dati davvero preziosi per benchmarking HR, competitive intelligence e prospecting commerciale — se riesci davvero ad accedervi. Questa guida è la versione che funziona dopo tutti questi cambiamenti e copre in un unico posto tutti e tre i tipi di dati di Glassdoor (lavori, recensioni e stipendi). Ti accompagno nell’approccio con Python e codice funzionante del 2025, ti spiego con precisione cosa ti blocca e come superarlo, e ti mostro anche una scorciatoia no-code per chi preferisce saltare del tutto la parte di engineering.
Perché fare scraping di Glassdoor con Python nel 2025?
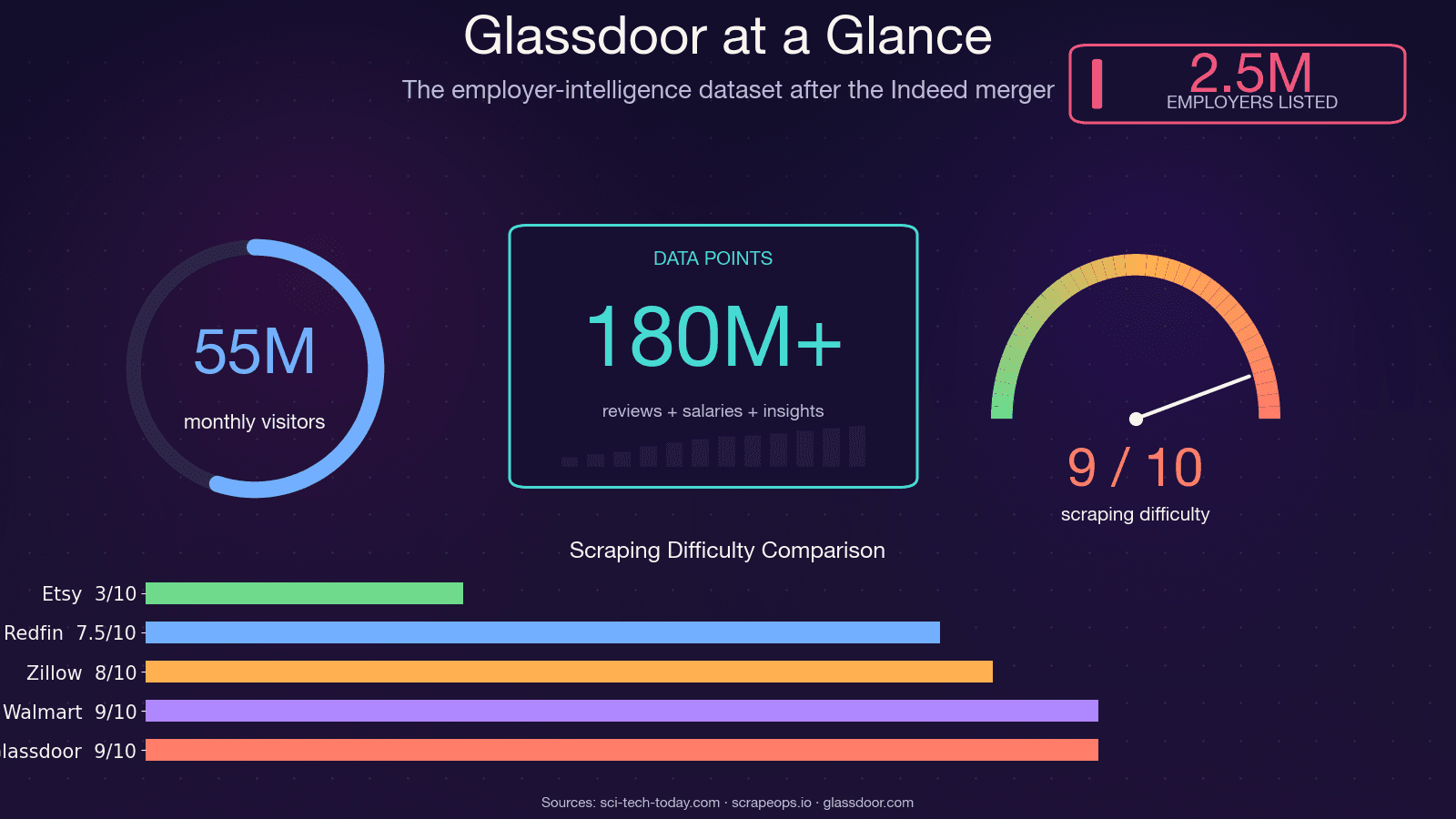
Glassdoor non è solo una bacheca di annunci. È uno dei dataset più ricchi sul web per l’intelligence sui datori di lavoro — usato da circa e visitato da circa 55 milioni di utenti unici al mese. I dati dietro quelle pagine alimentano decisioni concrete in più team aziendali.
Ecco come i diversi team usano davvero i dati di Glassdoor:
| Caso d’uso | Tipo di dato richiesto | Chi ne beneficia |
|---|---|---|
| Benchmarking salariale | Distribuzioni degli stipendi, numerosità dei campioni | HR, Total Rewards, Operations |
| Monitoraggio delle assunzioni dei competitor | Annunci di lavoro, frequenza di pubblicazione | Sales, Strategy, VC/Corp Dev |
| Controllo della reputazione del datore di lavoro | Testo delle recensioni, trend dei punteggi, approvazione del CEO | HR, Marketing, Comunicazione |
| Lead generation (aziende in crescita) | Annunci di lavoro + informazioni aziendali | Team commerciali, SDR |
| Ricerca di mercato/accademica | Tutti e tre | Analisti, consulenti, ricercatori |
Quando il BLS non è riuscito a pubblicare i dati sul lavoro durante lo shutdown del governo nell’ottobre 2025, il team di Economic Research di Glassdoor ha usando il proprio dataset. Questo fa capire quanto ormai gli analisti istituzionali considerino importanti questi dati.
Python resta il linguaggio di riferimento perché l’ecosistema è fortissimo: Playwright per l’automazione del browser, parsel/lxml per il parsing, curl_cffi per aggirare il fingerprint TLS, e una community enorme che condivide pattern che funzionano davvero. Il problema non è Python. Il problema è che Glassdoor è diventato molto più difficile da estrarre.
Se cerchi un’alternativa no-code per estrarre dati da Glassdoor, Thunderbit può aiutarti a ottenere offerte di lavoro, recensioni e pagine degli stipendi senza costruire e mantenere uno stack Python personalizzato.
Quali dati di Glassdoor puoi davvero estrarre?
La maggior parte dei tutorial si ferma agli annunci di lavoro. Ma la domanda degli utenti — basata su thread nei forum, issue su GitHub e domande su Reddit che ho monitorato — è molto più alta per i due tipi di dati che quasi nessuno spiega bene: recensioni e stipendi. Ecco la panoramica completa di ciò che puoi estrarre per tutte e tre le categorie.
Annunci di lavoro
È il tipo di dato più accessibile. Puoi estrarre: titolo del lavoro, nome dell’azienda, località, stima dello stipendio, rating dell’azienda, data di pubblicazione, badge di candidatura rapida e link all’annuncio. Gli annunci sono in parte accessibili anche senza login, anche se Glassdoor può mostrare un popup di accesso dopo alcune pagine.
Recensioni aziendali
Qui la cosa diventa davvero interessante per l’analisi della reputazione del datore di lavoro. I campi estraibili includono: rating complessivo, sotto-rating (work-life balance, culture & values, diversity & inclusion, opportunità di carriera, compensi e benefit, senior management), testo dei pro, testo dei contro, ruolo del recensore, data della recensione e stato occupazionale. Il testo completo delle recensioni è protetto da login: vedi un’anteprima, ma i pro/contro completi richiedono autenticazione.
Dati sugli stipendi
È il tipo di dato più richiesto e più frustrante da ottenere. Puoi estrarre: titolo del lavoro, intervallo dello stipendio base, intervallo della retribuzione totale, numero di report salariali e località. Ma le pagine sugli stipendi sono completamente protette da login e Glassdoor a volte aggiunge un flusso "contribute to unlock" in cui devi inviare il tuo stipendio prima di vedere quelli degli altri. Nessun tutorial concorrente fornisce codice funzionante per questo — lo sistemiamo noi.
Cosa richiede login e cosa no
Questa tabella ti evita di scoprire nel modo peggiore quali pagine ti restituiscono dati vuoti:
| Tipo di dato | Disponibile senza login? | Note |
|---|---|---|
| Titoli degli annunci e informazioni base | Per lo più sì | Il popup può comparire dopo alcune pagine |
| Descrizioni complete dei lavori | Parziale | Spesso protette dopo 2–3 visualizzazioni |
| Recensioni aziendali (testo completo) | No — serve il login | Visibile un estratto, testo completo protetto |
| Dati sugli stipendi | No — serve il login | Può richiedere anche "contribute to unlock" |
Perché il tuo vecchio scraper di Glassdoor è probabilmente rotto
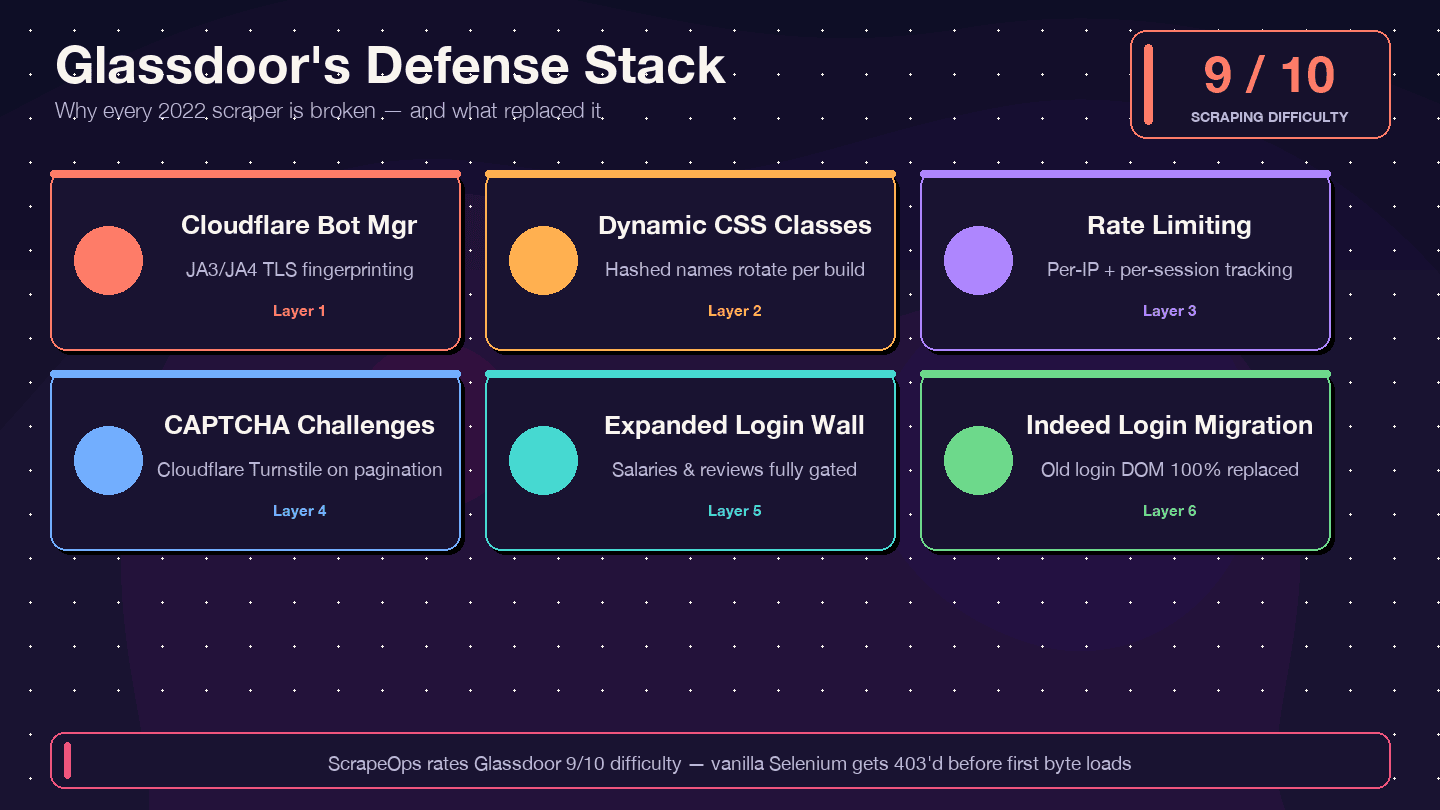
Voglio essere molto chiaro: se stai copiando codice da un tutorial del 2021–2023, non funzionerà. Lo scraper Selenium legacy di Glassdoor più stellato su GitHub (, circa 1,4k stelle) ha oltre 12 issue aperte e mai risolte — tra cui "nuovo design dell’interfaccia Glassdoor", "protezione anti-bot Cloudflare" e "NoSuchElementException". Il repository, di fatto, è abbandonato. L’actor . e 8/10 per il bypass.
Ecco cosa è cambiato e perché il vecchio codice si rompe:
| Livello di difesa | Cosa è cambiato | Impatto sui vecchi scraper |
|---|---|---|
| Cloudflare Bot Management | Fingerprinting JA3/JA4 più severo dal 2024 | Script base con requests/Selenium ricevono subito 403 |
| Classi CSS dinamiche | Le classi vengono randomizzate a ogni build | I vecchi selettori CSS dei tutorial smettono di funzionare senza errori evidenti |
| Rate limiting + tracking della sessione | Limiti più stretti per IP e sessione | Gli scraper vengono bloccati dopo meno pagine |
| CAPTCHA (probabilmente Cloudflare Turnstile) | Più frequenti, soprattutto nella paginazione | I browser headless scatenano i challenge |
| Login wall esteso | Più tipi di pagina richiedono autenticazione | Le pagine di stipendi e recensioni restituiscono dati vuoti |
| Migrazione a Indeed Login (feb 2026) | Il form di login di Glassdoor è stato sostituito del tutto | Qualsiasi codice che punta al vecchio DOM del login è morto |
La contiene un avviso esplicito: "Glassdoor is known for its high blocking rate, so if you get None values while running the Python code, it's likely you're getting blocked." E un lo dice senza giri di parole: "Simple HTTP requests with requests or httpx get blocked instantly."
Le contromisure che ti mostrerò — Patchright (un fork stealth di Playwright), selettori data-test, proxy residenziali rotanti e sessioni persistenti autenticate — sono pensate proprio per gestire ciascuno di questi livelli.
API di Glassdoor vs scraping con Python: scegli prima l’approccio giusto
Molti thread nei forum chiedono "Non sarebbe meglio usare l’API di Glassdoor?" — e la risposta è: non puoi.
La . Il portale developer esiste ancora, ma . Non è mai esistito un endpoint pubblico per le recensioni — lo scraper di MatthewChatham è stato creato proprio "perché Glassdoor non ha un’API per le recensioni". E non c’è alcun percorso di migrazione per recensioni o stipendi tramite la Publisher API di Indeed.
Ecco il confronto onesto:
| Fattore | Glassdoor Partner API v1 | Scraping Python | Thunderbit (no-code) |
|---|---|---|---|
| Accesso | Chiuso ai nuovi richiedenti | Aperto (lo implementi tu) | Estensione Chrome |
| Annunci di lavoro | Limitati / in fase di dismissione | Disponibili con sforzo | Disponibili |
| Recensioni aziendali | Mai esistite pubblicamente | Sì (serve login) | Sì (tramite Browser Mode) |
| Dati sugli stipendi | Mai esistiti pubblicamente | Sì (serve login) | Sì |
| Rate limit | Non documentati | Li controlli tu | Basati su crediti |
| Impegno di setup | Impossibile registrare nuove app | Da ore a giorni | ~2 minuti |
| Manutenzione | N/A | Alta (i cambi HTML rompono il codice) | Bassa (l’AI riesce a suggerire di nuovo i campi) |
Se ti servono recensioni o dati sugli stipendi — e la maggior parte dei lettori sì — lo scraping con Python o uno strumento no-code è l’unica opzione realistica.
Prima di iniziare
- Difficoltà: intermedia (dovresti essere a tuo agio con Python e il terminale)
- Tempo necessario: circa 30–60 minuti per la configurazione completa; circa 10 minuti per ciascun tipo di dato in seguito
- Cosa ti serve:
- Python 3.10+ (consigliati 3.11 o 3.12)
- Browser Chrome installato
- Un account Glassdoor (gratuito — necessario per i dati su stipendi e recensioni)
- Proxy residenziali rotanti (per scraping di più di poche pagine)
- Facoltativo: se vuoi la strada no-code
Strumenti e librerie per fare scraping di Glassdoor con Python nel 2025
Il panorama degli strumenti è cambiato parecchio. Ecco cosa funziona davvero contro le difese attuali di Glassdoor.
Perché Patchright è la scelta migliore per Glassdoor
è un fork stealth di Playwright che corregge la fuga CDP Runtime.Enable — la ragione tecnica specifica per cui Playwright standard fallisce sui siti protetti da Cloudflare. Usa esattamente la stessa API di Playwright, quindi se conosci Playwright, conosci Patchright. La versione 1.58.2 (marzo 2026) è attuale e mantenuta attivamente.
Rispetto alle alternative:
- Playwright standard: viene rilevato nella pagina di login di Glassdoor a causa della fuga Runtime.Enable
- Selenium + undetected-chromedriver: l’ultimo rilascio di undetected-chromedriver è di febbraio 2024 — oggi è praticamente legacy. Il l’ha trovato "fallito su ogni dominio del nostro test"
- requests + BeautifulSoup: non può renderizzare JavaScript ed è bloccato subito dal fingerprinting TLS di Cloudflare
- : ottimo nel fast path (10–20x più veloce di un browser) quando le pagine includono
__NEXT_DATA__nell’HTML iniziale, ma non può gestire login o challenge interstiziali
Librerie di supporto
- parsel (1.11.0) o lxml (6.0.4): parsing HTML/XPath veloce
- csv o pandas: esportazione dati
- asyncio: scraping asincrono per una paginazione più rapida
Proxy: solo residenziali
Il livello Cloudflare di Glassdoor sfida in modo aggressivo gli ASN dei datacenter. . I prezzi di ingresso partono da circa (promozionale) o $3,00/GB con . Per lo scraping in produzione, metti a budget $3–8/GB a seconda del volume.
Ritardi casuali tra le richieste (almeno 3–8 secondi, 5–15 secondi per esecuzioni più lunghe) sono indispensabili, qualunque sia la qualità del proxy.
Passo 1: configurare l’ambiente Python
Crea la cartella del progetto e installa lo stack consigliato:
1mkdir glassdoor-scraper && cd glassdoor-scraper
2python3.11 -m venv .venv
3source .venv/bin/activate
4pip install --upgrade pip
5# Stack principale
6pip install patchright==1.58.2 parsel==1.11.0
7# Installazione dei binari del browser
8patchright install chromium
9# Facoltativo: fast path per l’estrazione di __NEXT_DATA__
10pip install "curl_cffi==0.15.0"Dovresti vedere Patchright scaricare un binario Chromium. Se patchright install chromium fallisce, controlla di avere abbastanza spazio su disco (~300MB) e che la versione di Python sia 3.10+.
Passo 2: avviare Patchright e aprire Glassdoor
Ecco il pattern di avvio base che funziona contro il livello Cloudflare di Glassdoor:
1from patchright.sync_api import sync_playwright
2import random, time
3with sync_playwright() as p:
4 browser = p.chromium.launch(
5 headless=False, # il headless è ancora più facile da rilevare
6 channel="chrome", # usa Chrome reale, non il Chromium incluso
7 )
8 context = browser.new_context(
9 viewport={"width": 1440, "height": 900},
10 locale="en-US",
11 timezone_id="America/New_York",
12 user_agent=(
13 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
14 "AppleWebKit/537.36 (KHTML, like Gecko) "
15 "Chrome/134.0.0.0 Safari/537.36"
16 ),
17 )
18 page = context.new_page()
19 page.goto(
20 "https://www.glassdoor.com/Job/new-york-data-engineer-jobs-"
21 "SRCH_IL.0,8_IC1132348_KO9,22.htm"
22 )
23 # Nascondi l’overlay di login — il contenuto è comunque nel DOM
24 page.add_style_tag(content="""
25 #HardsellOverlay, .LoginModal { display: none !important; }
26 body { overflow: auto !important; position: initial !important; }
27 """)
28 page.wait_for_selector("[data-test='jobListing']")
29 print("Pagina caricata — le offerte di lavoro sono visibili.")Ci sono un paio di cose importanti da notare. Il flag channel="chrome" dice a Patchright di usare il binario Chrome installato sul tuo sistema invece del Chromium integrato — questo produce un fingerprint del browser più autentico. Il trucco add_style_tag nasconde il modal di login di Glassdoor (chiamato #HardsellOverlay) senza dover cliccare nulla. che "all of the content is still there, it's just covered up by the overlay" — l’HTML contiene i dati indipendentemente dal fatto che il modal sia visibile.
Dovresti vedere una finestra Chrome aprirsi, andare alla pagina di ricerca lavori di Glassdoor e mostrare le card degli annunci senza che il popup di login blocchi la vista.
Passo 3: estrarre gli annunci di lavoro di Glassdoor
Identificare selettori stabili
Glassdoor randomizza i nomi delle classi CSS a ogni build — quindi il selettore .jobCard_xyz123 di un tutorial del 2023 oggi non restituisce nulla, senza dare segnali evidenti. Usa invece gli attributi data-test, che sono la convenzione interna di QA di Glassdoor e tendono a restare stabili tra un deploy e l’altro.
Ecco il riferimento dei selettori per i campi degli annunci:
| Campo | Selettore |
|---|---|
| Contenitore card lavoro | [data-test="jobListing"] |
| Titolo del lavoro | [data-test="job-title"] |
| Link all’annuncio | a[data-test="job-link"] |
| Nome azienda | [data-test="employer-name"] |
| Località | [data-test="emp-location"] |
| Fascia salariale | [data-test="detailSalary"] |
| Rating azienda | [data-test="rating"] |
| Data di pubblicazione | [data-test="job-age"] |
| Pagina successiva | [data-test="pagination-next"] |
Estrarre i dati delle offerte
1from parsel import Selector
2import csv, random, time
3def scrape_jobs(page, max_pages=5):
4 all_jobs = []
5 for page_num in range(1, max_pages + 1):
6 html = page.content()
7 sel = Selector(text=html)
8 cards = sel.css('[data-test="jobListing"]')
9 if not cards:
10 print(f"Pagina {page_num}: nessuna card trovata — possibile blocco o cambio selettore.")
11 break
12 for card in cards:
13 job = {
14 "title": card.css('[data-test="job-title"]::text').get("").strip(),
15 "company": card.css('[data-test="employer-name"]::text').get("").strip(),
16 "location": card.css('[data-test="emp-location"]::text').get("").strip(),
17 "salary": card.css('[data-test="detailSalary"]::text').get("").strip(),
18 "rating": card.css('[data-test="rating"]::text').get("").strip(),
19 "link": card.css('a[data-test="job-link"]::attr(href)').get(""),
20 "posted": card.css('[data-test="job-age"]::text').get("").strip(),
21 }
22 if job["link"] and not job["link"].startswith("http"):
23 job["link"] = "https://www.glassdoor.com" + job["link"]
24 all_jobs.append(job)
25 print(f"Pagina {page_num}: estratti {len(cards)} lavori")
26 # Paginazione
27 next_btn = page.query_selector('[data-test="pagination-next"]')
28 if next_btn and page_num < max_pages:
29 next_btn.click()
30 time.sleep(random.uniform(3, 8))
31 page.wait_for_selector("[data-test='jobListing']")
32 else:
33 break
34 return all_jobsSalvare in CSV
1def save_to_csv(jobs, filename="glassdoor_jobs.csv"):
2 if not jobs:
3 print("Nessun lavoro da salvare.")
4 return
5 keys = jobs[0].keys()
6 with open(filename, "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=keys)
8 writer.writeheader()
9 writer.writerows(jobs)
10 print(f"Salvati {len(jobs)} lavori in {filename}")Una nota sui limiti della paginazione: Glassdoor limita i risultati di ricerca a circa 30 pagine, indipendentemente dal numero totale. Se ti serve più copertura, usa i filtri (località, tipo di lavoro, fascia salariale) per restringere ogni ricerca invece di provare a superare il limite con la paginazione.
Nei miei test, estrarre 5 pagine di annunci (circa 75 lavori) ha richiesto circa 45 secondi con ritardi casuali. Farlo a mano richiederebbe almeno 20 minuti di copia-incolla.
Passo 4: estrarre le recensioni aziendali di Glassdoor
Questa è la sezione per la quale nessun altro tutorial fornisce davvero codice funzionante. Le recensioni sono il punto in cui si trova la vera intelligence sul datore di lavoro: sentiment analysis, segnali sulla cultura aziendale, campanelli d’allarme sul management.
Aprire la pagina delle recensioni
Gli URL delle recensioni seguono questo schema: /Reviews/{Company}-Reviews-E{id}.htm. Puoi trovare l’ID del datore di lavoro cercando l’azienda su Glassdoor e controllando l’URL.
1def navigate_to_reviews(page, company_reviews_url):
2 page.goto(company_reviews_url)
3 page.add_style_tag(content="""
4 #HardsellOverlay, .LoginModal { display: none !important; }
5 body { overflow: auto !important; position: initial !important; }
6 """)
7 page.wait_for_selector('[data-test="review"]', timeout=15000)L’endpoint BFF nascosto (il percorso più pulito)
Ecco la scoperta più importante della mia ricerca: le recensioni di Glassdoor hanno una API JSON interna funzionante che bypassa del tutto il parsing HTML. Il documenta questo endpoint, ed è molto più affidabile dello scraping del DOM.
1import json, re, requests
2def get_review_ids(page):
3 """Estrae employerId e dynamicProfileId dall'HTML della pagina recensioni."""
4 html = page.content()
5 sel = Selector(text=html)
6 script_text = sel.xpath(
7 "//script[contains(text(), 'profileId')]/text()"
8 ).get("")
9 employer_match = re.search(r'"employer"\s*:\s*(\{[^}]+\})', script_text)
10 if employer_match:
11 meta = json.loads(employer_match.group(1))
12 return meta.get("id"), meta.get("profileId")
13 return None, None
14def fetch_reviews_bff(page, employer_id, profile_id, max_pages=5):
15 """Chiama l'endpoint BFF interno di Glassdoor per ottenere dati strutturati delle recensioni."""
16 all_reviews = []
17 cookies = {c["name"]: c["value"] for c in page.context.cookies()}
18 for pg in range(1, max_pages + 1):
19 payload = {
20 "applyDefaultCriteria": True,
21 "employerId": employer_id,
22 "dynamicProfileId": profile_id,
23 "employmentStatuses": ["REGULAR", "PART_TIME"],
24 "language": "eng",
25 "onlyCurrentEmployees": False,
26 "page": pg,
27 "pageSize": 10,
28 "sort": "DATE",
29 "textSearch": "",
30 }
31 resp = requests.post(
32 "https://www.glassdoor.com/bff/employer-profile-mono/employer-reviews",
33 json=payload,
34 cookies=cookies,
35 headers={"Content-Type": "application/json"},
36 )
37 if resp.status_code != 200:
38 print(f"BFF ha restituito {resp.status_code} alla pagina {pg}")
39 break
40 data = resp.json()
41 reviews = data.get("data", {}).get("employerReviews", {}).get("reviews", [])
42 total_pages = data.get("data", {}).get("employerReviews", {}).get("numberOfPages", 1)
43 for r in reviews:
44 all_reviews.append({
45 "title": r.get("summary", ""),
46 "rating": r.get("ratingOverall"),
47 "pros": r.get("pros", ""),
48 "cons": r.get("cons", ""),
49 "author_role": r.get("jobTitle", {}).get("text", ""),
50 "date": r.get("reviewDateTime", ""),
51 "recommend": r.get("isRecommend"),
52 })
53 print(f"Pagina recensioni {pg}/{total_pages}: ottenute {len(reviews)} recensioni")
54 if pg >= total_pages:
55 break
56 time.sleep(random.uniform(3, 6))
57 return all_reviewsL’endpoint BFF ti restituisce JSON pulito con tutti i campi delle recensioni — niente parsing HTML, niente rotture dei selettori CSS. Ti servono i cookie di sessione da un contesto Playwright autenticato (coperto nel Passo 6 qui sotto) e devi prima estrarre employerId e dynamicProfileId dall’HTML della pagina recensioni.
Selettori HTML di fallback per le recensioni
Se l’endpoint BFF cambia o preferisci il parsing del DOM, ecco i selettori data-test stabili:
| Campo | Selettore |
|---|---|
| Contenitore recensione | [data-test="review"] |
| Titolo | [data-test="review-title"] |
| Rating complessivo | [data-test="overall-rating"] |
| Pro | [data-test="pros"] |
| Contro | [data-test="cons"] |
| Data | [data-test="review-date"] |
| Ruolo dell’autore | [data-test="author-jobTitle"] |
Passo 5: estrarre i dati salariali di Glassdoor
Le pagine degli stipendi sono completamente protette da login. Devi avere una sessione autenticata (Passo 6) prima che questo codice restituisca dati reali.
Aprire la pagina stipendi
Gli URL degli stipendi seguono questo formato: /Salary/{Company}-Salaries-E{id}.htm, con paginazione come _P{n}.htm.
1def scrape_salaries(page, salary_url, max_pages=3):
2 all_salaries = []
3 for pg in range(1, max_pages + 1):
4 url = salary_url if pg == 1 else salary_url.replace(".htm", f"_P{pg}.htm")
5 page.goto(url)
6 page.add_style_tag(content="""
7 #HardsellOverlay { display: none !important; }
8 body { overflow: auto !important; position: initial !important; }
9 """)
10 time.sleep(random.uniform(3, 7))
11 html = page.content()
12 sel = Selector(text=html)
13 items = sel.css('[data-test="salary-item"]')
14 if not items:
15 print(f"Pagina stipendi {pg}: nessun elemento — possibile login gate o blocco.")
16 break
17 for item in items:
18 salary = {
19 "job_title": item.css('[class*="SalaryItem_jobTitle__"]::text').get("").strip(),
20 "salary_range": item.css('[class*="SalaryItem_salaryRange__"]::text').get("").strip(),
21 "count": item.css('[class*="SalaryItem_salaryCount__"]::text').get("").strip(),
22 }
23 all_salaries.append(salary)
24 print(f"Pagina stipendi {pg}: estratte {len(items)} voci")
25 return all_salariesNota il pattern di prefix-match [class*="SalaryItem_jobTitle__"]. La pagina degli stipendi di Glassdoor usa classi CSS module con hash (ad esempio SalaryItem_jobTitle__XWGpT) dove il suffisso hash cambia a ogni deploy. Il prefisso resta stabile — l’hash no. Non codificare mai il nome completo della classe.
Passo 6: superare il login wall di Glassdoor
Questo è il passaggio fondamentale che sblocca i dati salariali e il testo completo delle recensioni. L’approccio: fai il login manualmente una sola volta in un browser visibile, salva lo stato autenticato della sessione, poi riutilizzalo per tutte le esecuzioni successive.
Salvare la sessione autenticata
Esegui questo script una volta. Apre una finestra Chrome, va alla pagina login di Glassdoor (che ora reindirizza a Indeed Login) e aspetta che tu faccia il login manualmente:
1import asyncio
2from pathlib import Path
3from patchright.async_api import async_playwright
4STATE_FILE = Path("glassdoor_state.json")
5async def login_and_save():
6 async with async_playwright() as p:
7 browser = await p.chromium.launch(headless=False, channel="chrome")
8 context = await browser.new_context(
9 viewport={"width": 1366, "height": 800},
10 locale="en-US",
11 )
12 page = await context.new_page()
13 await page.goto("https://www.glassdoor.com/profile/login_input.htm")
14 print("Accedi dalla finestra del browser, poi premi Invio qui...")
15 input()
16 await context.storage_state(path=str(STATE_FILE))
17 print(f"Sessione salvata in {STATE_FILE}")
18 await browser.close()
19asyncio.run(login_and_save())Dopo aver effettuato l’accesso e premuto Invio, Patchright salva tutti i cookie e il local storage in glassdoor_state.json. Questo file contiene gdId, GSESSIONID, cf_clearance e i token di autenticazione.
Riutilizzare la sessione per lo scraping
Tutte le esecuzioni successive caricano lo stato salvato — niente login manuale richiesto:
1async def scrape_with_auth(target_url):
2 async with async_playwright() as p:
3 browser = await p.chromium.launch(headless=True, channel="chrome")
4 context = await browser.new_context(
5 storage_state="glassdoor_state.json"
6 )
7 page = await context.new_page()
8 await page.goto(target_url)
9 await page.add_style_tag(
10 content="#HardsellOverlay{display:none!important}"
11 )
12 await page.wait_for_load_state("networkidle")
13 html = await page.content()
14 await browser.close()
15 return htmlLa sessione salvata dura in genere 20–30 minuti di utilizzo attivo prima che Glassdoor richieda una nuova verifica. Per esecuzioni più lunghe, inserisci un controllo: se una pagina che dovrebbe contenere dati restituisce zero risultati, rilancia lo script di login per aggiornare il file di stato.
Rilevare e chiudere il popup di login
Per pagine parzialmente protette (annunci che mostrano i dati ma sovrappongono un modal), il metodo di iniezione CSS visto prima funziona:
1page.add_style_tag(content="""
2 #HardsellOverlay, .LoginModal { display: none !important; }
3 body { overflow: auto !important; position: initial !important; }
4""")Funziona solo quando l’HTML sottostante contiene già i dati dietro l’overlay. Per pagine completamente protette lato server (stipendi, pagine di recensioni approfondite), la sessione autenticata del Passo 6 è l’unica strada.
Consigli per mantenere operativo il tuo scraper di Glassdoor
Glassdoor aggiorna spesso il frontend. Ecco come rendere il tuo scraper più robusto.
Preferisci gli attributi data-test ai nomi delle classi
Glassdoor randomizza i nomi delle classi CSS ma tende a mantenere stabili gli attributi data-test. Usa sempre [data-test="jobListing"] invece di .jobCard_abc123. Quando data-test non è disponibile (come per alcune classi dei campi stipendio), usa il pattern di prefix-match: [class*="SalaryItem_jobTitle__"].
Ruota i proxy e randomizza i ritardi
Usa proxy residenziali rotanti — gli IP dei datacenter vengono sfidati quasi subito. Aggiungi ritardi casuali di 3–8 secondi tra i caricamenti delle pagine (5–15 secondi per run più lunghi). Se puoi, evita di fare scraping durante l’orario lavorativo negli Stati Uniti, quando il rilevamento comportamentale di Cloudflare è più aggressivo.
Monitora eventuali rotture
Inserisci un controllo semplice nel tuo scraper: se una pagina che dovrebbe contenere dati restituisce zero record estratti, trattala come un fallimento dei selettori e non come un insieme vuoto di risultati, e avvisati. Esegui un piccolo test di scraping ogni settimana per intercettare le rotture in anticipo — Glassdoor distribuisce cambi frontend senza preavviso.
Usa il fast path __NEXT_DATA__ quando possibile
Glassdoor è una app Next.js + Apollo GraphQL. Molte pagine includono un tag <script id="__NEXT_DATA__"> con tutta la cache GraphQL in JSON. Parsarlo è molto più robusto dello scraping del DOM e :
1import json
2def extract_next_data(html):
3 sel = Selector(text=html)
4 raw = sel.css("script#__NEXT_DATA__::text").get()
5 if raw:
6 return json.loads(raw)["props"]["pageProps"].get("apolloCache", {})
7 return NoneQuesto restituisce la cache Apollo strutturata con tutti i campi di lavori, recensioni e stipendi — senza bisogno di selettori CSS. È la strategia di estrazione più resistente disponibile, perché usa gli stessi dati che alimentano il frontend React di Glassdoor.
Salta il codice: estrai Glassdoor con Thunderbit (senza Python)
Non tutti i lettori di questo articolo sono sviluppatori. Anche team HR, recruiter, analisti di sales ops e ricercatori di mercato hanno bisogno dei dati di Glassdoor — e non dovrebbero dover gestire contesti Playwright e rotazione dei proxy per ottenerli.
è un’estensione Chrome di AI Web Scraper che può estrarre gli stessi dati di lavori, recensioni e stipendi senza scrivere una riga di codice. Lavoro nel team Thunderbit, quindi lo dico con trasparenza — ma il motivo per cui lo includo qui è che risolve davvero i due problemi più difficili nello scraping di Glassdoor.
Come funziona Thunderbit su Glassdoor
Il flusso si fa in due clic:
- Apri qualsiasi pagina Glassdoor in Chrome (ricerca lavori, recensioni aziendali, pagina stipendi)
- Clicca AI Suggest Fields nella sidebar di Thunderbit — l’AI legge il DOM della pagina e propone le colonne (titolo del lavoro, azienda, rating, fascia salariale, pro, contro, ecc.)
- Clicca Scrape — i dati vengono estratti in una tabella senza selettori CSS né codice di automazione del browser
Thunderbit ha un che estrae oltre 23 campi per azienda in una sola esecuzione. Per annunci di lavoro, recensioni o stipendi, il flusso generico AI Suggest Fields funziona con qualsiasi URL di Glassdoor.
Gestire il login wall senza codice
Questo è il vantaggio strutturale di Thunderbit su Glassdoor. Browser Mode gira dentro la tua sessione Chrome: se hai effettuato l’accesso a Glassdoor in Chrome, Thunderbit eredita automaticamente quei cookie. Il login wall che blocca stipendi e recensioni per gli scraper lato server semplicemente non si applica. Niente gestione cookie, niente contesti persistenti, niente codice di sessione.
Scraping delle subpage per arricchire i dati
Parti da una lista (per esempio 30 aziende da una ricerca), lascia che Thunderbit enumeri le righe, poi attiva lo per visitare la pagina recensioni o stipendi di ciascuna azienda e arricchire la tabella con descrizioni complete, testo delle recensioni o dettagli salariali.
Esportazione verso strumenti business
A differenza degli script Python che producono CSV o JSON, Thunderbit esporta direttamente in Google Sheets, Airtable, Notion o Excel — gratuitamente in tutti i piani. È particolarmente utile per i team che devono condividere e analizzare i dati in modo collaborativo.
Python vs Thunderbit: quando usare cosa
| Scenario | Approccio consigliato |
|---|---|
| Costruire una pipeline dati ricorrente | Python + Patchright |
| Ricerca una tantum o progetto di piccolo team | Thunderbit |
| Serve controllo programmatico su ogni campo | Python |
| Non sviluppatore che ha bisogno dei dati di Glassdoor oggi | Thunderbit |
| Scraping di oltre 1.000 pagine in una sola esecuzione | Python + proxy |
| Scraping di 30 aziende con arricchimento | Entrambi vanno bene — Thunderbit è più veloce da configurare |
Il prezzo di Thunderbit parte da gratuito (6 pagine/mese), con il per 3.000 crediti. Con 1 credito per ogni riga di output (2 crediti per lo scraping delle subpage), è sufficiente per circa 33 run da 30 aziende arricchite al mese.
È legale fare scraping di Glassdoor?
Resterò breve e fattuale. I di Glassdoor vietano esplicitamente lo scraping automatizzato: "You may not use any robot, spider, scraper... to access the Services for any purpose without our express written permission."
Il quadro legale, però, è più sfumato di una singola clausola dei ToS:
- (N.D. Cal., gennaio 2024): il tribunale ha stabilito che se non fai mai login, non hai mai accettato i ToS, e lo scraping pubblico senza login non li viola
- hiQ Labs v. LinkedIn (9th Cir.): il CFAA non si applica alla raccolta automatizzata di dati accessibili pubblicamente — ma account finti e scraping dopo login sono un’altra storia
- Van Buren v. United States (Corte Suprema, 2021): ha ristretto il concetto di "exceeds authorized access" nel CFAA
La conclusione pratica: fare scraping di annunci pubblici senza login si colloca in una zona giuridica relativamente più sicura. Fare scraping con una sessione autenticata significa aver accettato i ToS al momento della registrazione, e quei termini vietano esplicitamente l’attività. Questo vale sia per gli script Python sia per il Browser Mode di Thunderbit.
Linee guida etiche da seguire comunque:
- Imposta un rate limit ben al di sotto della velocità di navigazione umana
- Non estrarre né rivendere informazioni personali identificabili dei recensori
- Rispetta le direttive di robots.txt
- Recupera solo i campi che ti servono davvero
Conclusione: quale metodo è giusto per te?
Questa guida ha coperto tutti e tre i tipi di dati di Glassdoor — lavori, recensioni e stipendi — con codice funzionante del 2025 che tiene conto della migrazione a Indeed Login, di Cloudflare Bot Management e della rotazione dei nomi delle classi CSS-module che ha rotto tutti i tutorial precedenti.
Ecco il framework decisionale:
| La tua situazione | Percorso migliore |
|---|---|
| Developer che sta costruendo una pipeline dati | Python + Patchright (segui la guida passo per passo qui sopra) |
| Ricerca una tantum o estrazioni piccole e ricorrenti | Thunderbit (senza codice, basato sul browser) |
| Ti servono solo annunci base su piccola scala | Prima verifica se l’accesso all’API di Glassdoor è ancora disponibile (probabilmente no) |
| Ti servono in particolare dati su stipendi o recensioni | Devi usare scraping Python o Thunderbit — l’API non li ha mai coperti |
| Team di non sviluppatori che ha bisogno di dati condivisi | Thunderbit → esportazione in Google Sheets |
Le difese di Glassdoor continueranno a evolversi. I selettori si romperanno. Appariranno nuove protezioni. Salva questa guida tra i preferiti — e se vuoi un approfondimento sugli strumenti e sulle tecniche di web scraping, dai un’occhiata ai nostri articoli su , e . Puoi anche guardare i tutorial sul .
FAQ
1. Si può fare scraping di Glassdoor senza effettuare login?
Sì, per la maggior parte dei dati degli annunci di lavoro e per i rating aziendali di alto livello. No, per il dettaglio completo degli stipendi o il testo integrale delle recensioni oltre le prime pagine. L’#HardsellOverlay è un modal solo CSS: l’HTML sottostante contiene ancora i dati della prima pagina, ma i contenuti più profondi sono protetti lato server dietro il muro "give-to-get" di Glassdoor.
2. Qual è la libreria Python migliore per fare scraping di Glassdoor nel 2025?
Patchright (un fork stealth di Playwright) è la raccomandazione predefinita. Risolve la fuga CDP Runtime.Enable che Playwright standard presenta e che Cloudflare controlla esplicitamente. Per le pagine che includono __NEXT_DATA__ nell’HTML iniziale, curl_cffi con impersonate="chrome124" è 10–20x più veloce, ma non può gestire le pagine protette da login.
3. Come faccio a evitare il blocco quando faccio scraping di Glassdoor?
Usa Patchright o rebrowser-playwright (non Playwright standard né Selenium). Ruota proxy residenziali — gli IP dei datacenter vengono sfidati subito. Aggiungi ritardi casuali di 3–8 secondi tra le pagine. Mantieni i cookie (gdId, cf_clearance, GSESSIONID) tra una richiesta e l’altra. Aspettati una finestra di sessione di 20–30 minuti prima di un nuovo challenge.
4. Esiste un’API di Glassdoor da usare al posto dello scraping?
In pratica no. La vecchia Partner API è , un endpoint pubblico per le recensioni non è mai esistito e non c’è un percorso di migrazione tramite la Publisher API di Indeed. Per recensioni e dati sugli stipendi, lo scraping o uno strumento no-code come Thunderbit sono le uniche opzioni pratiche.
5. Quanto spesso si rompono gli scraper per Glassdoor?
Molto spesso. Glassdoor distribuisce modifiche al frontend senza annunciarle e gli hash delle classi CSS-module cambiano a ogni build. Le strategie di estrazione più stabili sono: (1) selettori sugli attributi data-test, (2) il blob JSON __NEXT_DATA__, e (3) l’endpoint interno BFF per le recensioni. Inserisci un controllo per i risultati zero e fai un piccolo test di scraping ogni settimana per intercettare le rotture in anticipo.
Scopri di più