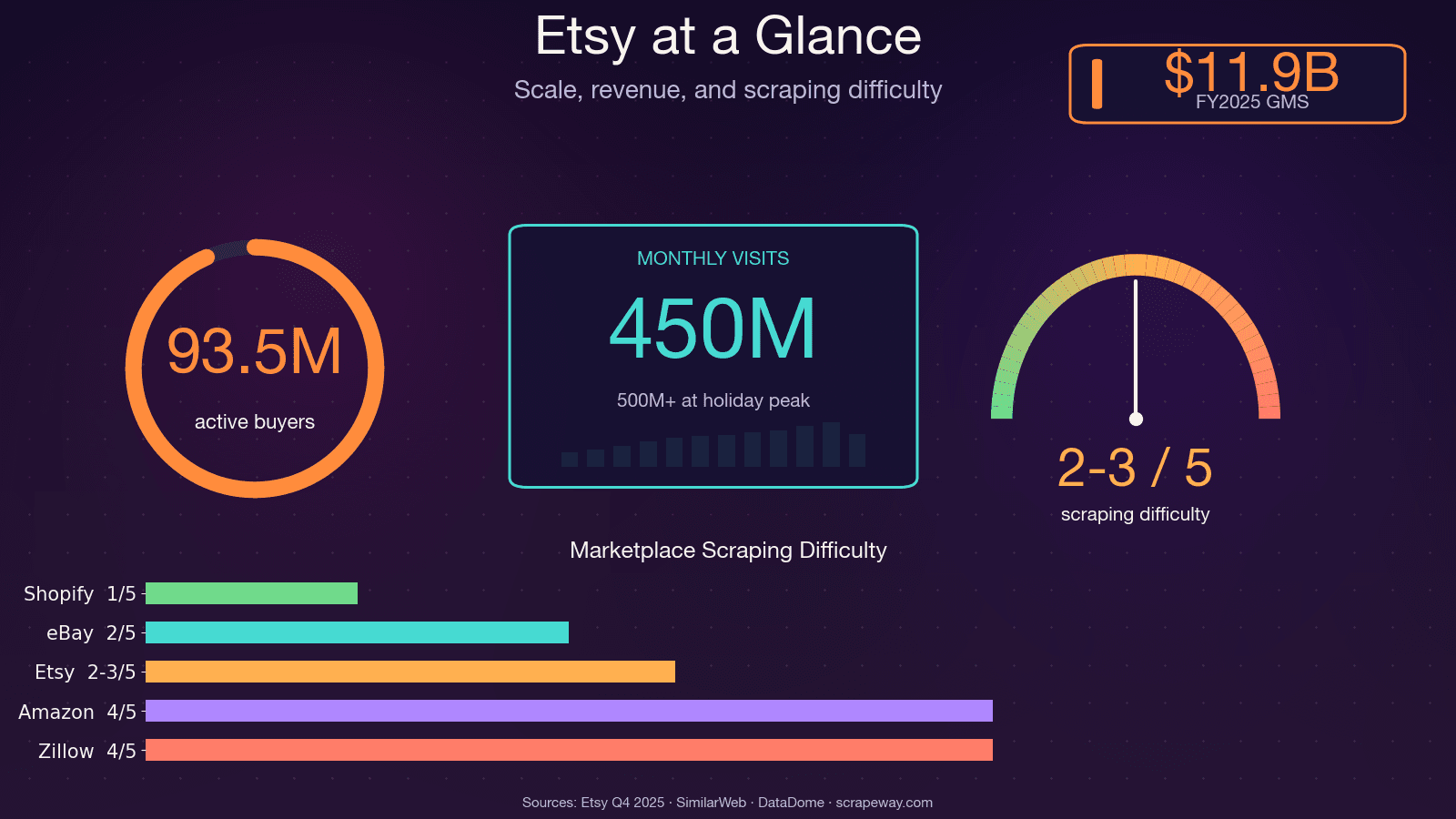
Etsy ha oltre 100 milioni di inserzioni attive, 5,6 milioni di venditori e circa 450 milioni di visite mensili. Parliamo quindi di una quantità enorme di dati pubblicamente disponibili su prezzi, trend, recensioni e concorrenti — e se hai mai provato a raccoglierli a mano, sai bene quanto può essere frustrante.
Una volta ho passato un intero weekend a catalogare manualmente i prodotti di un concorrente per un progetto di ricerca di mercato. Al prodotto numero 30 stavo già mettendo in discussione ogni scelta di vita che mi aveva portato davanti a quel foglio di calcolo. Il punto è che i dati di Etsy sono incredibilmente utili per l’analisi dei prezzi, lo sviluppo di prodotto, la scoperta di nicchie e il benchmark dei venditori — ma solo se riesci davvero a raccoglierli su larga scala. È di questo che parla questa guida: un tutorial completo che spiega come estrarre dati da Etsy con Python su tutte e quattro le principali tipologie di pagina (risultati di ricerca, pagine prodotto, pagine shop e recensioni), oltre a una panoramica onesta sulle difese anti-bot di Etsy e a un’alternativa no-code per chi preferisce evitare del tutto lo scripting.
Cosa significa estrarre dati da Etsy con Python?
In parole semplici, il web scraping consiste nello scrivere codice che visita le pagine web ed estrae automaticamente i dati che ti interessano — nomi dei prodotti, prezzi, descrizioni, immagini, valutazioni, recensioni, dettagli dello shop — organizzandoli in un formato strutturato come un foglio di calcolo o un database.
Python è il linguaggio di riferimento per questo tipo di lavoro. È adatto ai principianti, ha una community enorme e offre un ecosistema di librerie perfetto per lo scraping: Requests (per scaricare le pagine), BeautifulSoup (per analizzare l’HTML), Selenium e Playwright (per l’automazione del browser) e pandas (per organizzare ed esportare i dati). Python si classifica costantemente tra i 3 linguaggi più popolari nel sondaggio annuale di Stack Overflow tra gli sviluppatori, e le sue librerie per lo scraping sono tra le più scaricate su PyPI.
Quando estrai dati da Etsy, stai prelevando informazioni dall’HTML (e a volte da JSON nascosto) che Etsy invia al browser. I tipi di dati che puoi ottenere includono:
- Nomi dei prodotti, prezzi, descrizioni, immagini e varianti
- Informazioni sul venditore/shop (nome, numero di vendite, località, valutazione)
- Valutazioni e testo completo delle recensioni
- Risultati di ricerca, categorie e segnali di tendenza
Perché estrarre dati da Etsy? Casi d’uso reali che generano ROI
Fare scraping di Etsy non è solo un esercizio tecnico: è un vantaggio competitivo. Che tu sia un venditore, un product manager o un data analyst, avere dati strutturati di Etsy a portata di mano può incidere direttamente sui risultati economici.
| Caso d’uso | Cosa estrai | Chi ne beneficia | Impatto sul business |
|---|---|---|---|
| Analisi competitiva dei prezzi | Risultati di ricerca + prezzi dei prodotti | Operations e-commerce, venditori | Il pricing dinamico può aumentare i ricavi in media del 5–22% |
| Scoperta di nicchie e trend | Risultati di ricerca, inserzioni in tendenza | Fondatori, analisti | Individua in anticipo le nicchie emergenti (ad es. “preppy pajamas” ha registrato un +1.112% nelle ricerche) |
| Sviluppo e miglioramento prodotto | Recensioni, dettagli prodotto | Team prodotto | Un brand di utensili da cucina ha riconquistato il primo posto tra i Best Seller in 60 giorni usando i dati di sentiment delle recensioni |
| SEO e ricerca di keyword | Risultati di ricerca, titoli/tag dei prodotti | Team marketing | Identifica keyword ad alta domanda e bassa concorrenza |
| Benchmark dei venditori | Pagine shop, conteggio vendite | Team commerciali, analisti | Crea liste di lead qualificati a 0,01–0,10 $ per record, contro le liste acquistate |
| Monitoraggio inventario e stock | Disponibilità dei prodotti | Operations e-commerce | Reagisci più rapidamente ai cambi di stock dei concorrenti |
Ognuno di questi casi d’uso richiede dati da diverse tipologie di pagine Etsy — ed è proprio per questo che questo tutorial le copre tutte e quattro.
Risparmio di tempo: manuale vs automatico
- Ricerca manuale su Etsy: 30–45 minuti per prodotto (50–75 ore per 100 prodotti)
- Scraping automatico: 100 inserzioni in 2–5 minuti
- Lo scraping basato su AI è con una precisione fino al 99,5%
Etsy API vs web scraping: cosa conviene scegliere?
Prima di scrivere una sola riga di codice, vale la pena chiedersi: conviene usare l’API ufficiale di Etsy o estrarre direttamente i dati dal sito? È una domanda che vedo emergere continuamente nei forum, e la risposta dipende dai dati di cui hai bisogno.
Cosa può e non può fare l’API di Etsy
Etsy offre un’API v3 con autenticazione OAuth 2.0. Funziona per accedere ai dati del tuo shop — inserzioni, ordini, ricevute. Ma ha limiti concreti:
- Dati dei concorrenti: l’API è perlopiù limitata al tuo shop. Non puoi estrarre prezzi, vendite o inserzioni di un altro venditore.
- Recensioni: non esiste un endpoint robusto per ottenere in massa il testo completo delle recensioni.
- Rate limit: 10 richieste/secondo, 10.000 richieste/giorno di default. Il limite di offset è di 12.000 record.
- Uso di AI/ML: rifiutato esplicitamente nella revisione dell’app.
- Documentazione: le lamentele della community sono diffuse — esempi scarsi, endpoint deprecati, supporto lento.
Quando il web scraping è la strada migliore
Se ti servono intelligence sui concorrenti, sentiment delle recensioni, analisi tra shop o dati oltre ciò che espone l’API, lo scraping è la soluzione giusta. Il compromesso: dovrai fare i conti con le difese anti-bot di Etsy (ne parliamo più sotto) e investire nella configurazione.
Tabella di confronto: API vs scraping vs no-code
| Criterio | API ufficiale Etsy | Web scraping con Python | Thunderbit (no-code) |
|---|---|---|---|
| Accesso ai prezzi dei prodotti | ✅ (campi limitati) | ✅ HTML/JSON-LD completo | ✅ L’AI estrae qualsiasi campo visibile |
| Dati delle recensioni | ❌ Non disponibili in massa | ✅ Tramite endpoint/HTML delle recensioni | ✅ Scraping delle sottopagine |
| Dati dello shop dei concorrenti | ❌ Solo il tuo shop | ✅ Qualsiasi shop pubblico | ✅ Qualsiasi shop pubblico |
| Autenticazione richiesta | ✅ OAuth 2.0 | ⚠️ Cookie per dati con login | ⚠️ Scraping nel browser per il login |
| Rischio anti-bot | Nessuno | ALTO (DataDome) | Gestito (browser nativo) |
| Tempo di configurazione | Medio (chiavi API, OAuth) | Alto (codice + proxy) | ~2 minuti |
Se ti servono dati dei concorrenti, recensioni o analisi tra shop, l’API semplicemente non basta. Questa è la realtà, senza giri di parole.
Scegli il tuo approccio Python prima di scrivere codice
Una domanda che vedo continuamente su Reddit e Stack Overflow: “Devo usare Requests + BeautifulSoup, Selenium, una proxy API o altro?” La risposta giusta dipende dal tuo livello, dal budget e dal caso d’uso.
| Approccio | Ideale per | Curva di apprendimento | Gestisce JS? | Gestione anti-bot | Costo |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | Sviluppatori che vogliono controllo totale | Media | ❌ | Manuale (header, proxy) | Gratis + costi proxy |
| Selenium / Playwright | Pagine molto basate su JS, flussi di login | Alta | ✅ | Parziale (fingerprint del browser) | Gratis + costi proxy |
| Servizi proxy API | Scala + bypass anti-bot | Media | ✅ (via API) | ✅ Integrata | Da 49 $/mese |
| Thunderbit (no-code) | Non sviluppatori, estrazione rapida | Molto bassa | ✅ (browser nativo) | ✅ (sessione browser) | Piano gratuito disponibile |
Se vuoi il massimo controllo e ti senti a tuo agio con Python, vai con Requests + BeautifulSoup. Se ti serve rendering JS o un flusso di login, usa Selenium. Se vuoi aggirare l’anti-bot su larga scala, valuta un servizio proxy. E se vuoi dati Etsy senza scrivere o mantenere codice, Thunderbit merita un’occhiata — più avanti ti spiego perché.
Come reagisce Etsy: capire la protezione anti-bot DataDome
La maggior parte delle guide sullo scraping ti dice semplicemente di “usare un proxy” e andare avanti. Per Etsy non basta. Etsy usa DataDome, uno dei sistemi anti-bot più aggressivi del web. Un cita Etsy come un caso di successo, osservando che gli scraper rappresentavano un tempo circa l’1% dei costi di calcolo di Etsy.
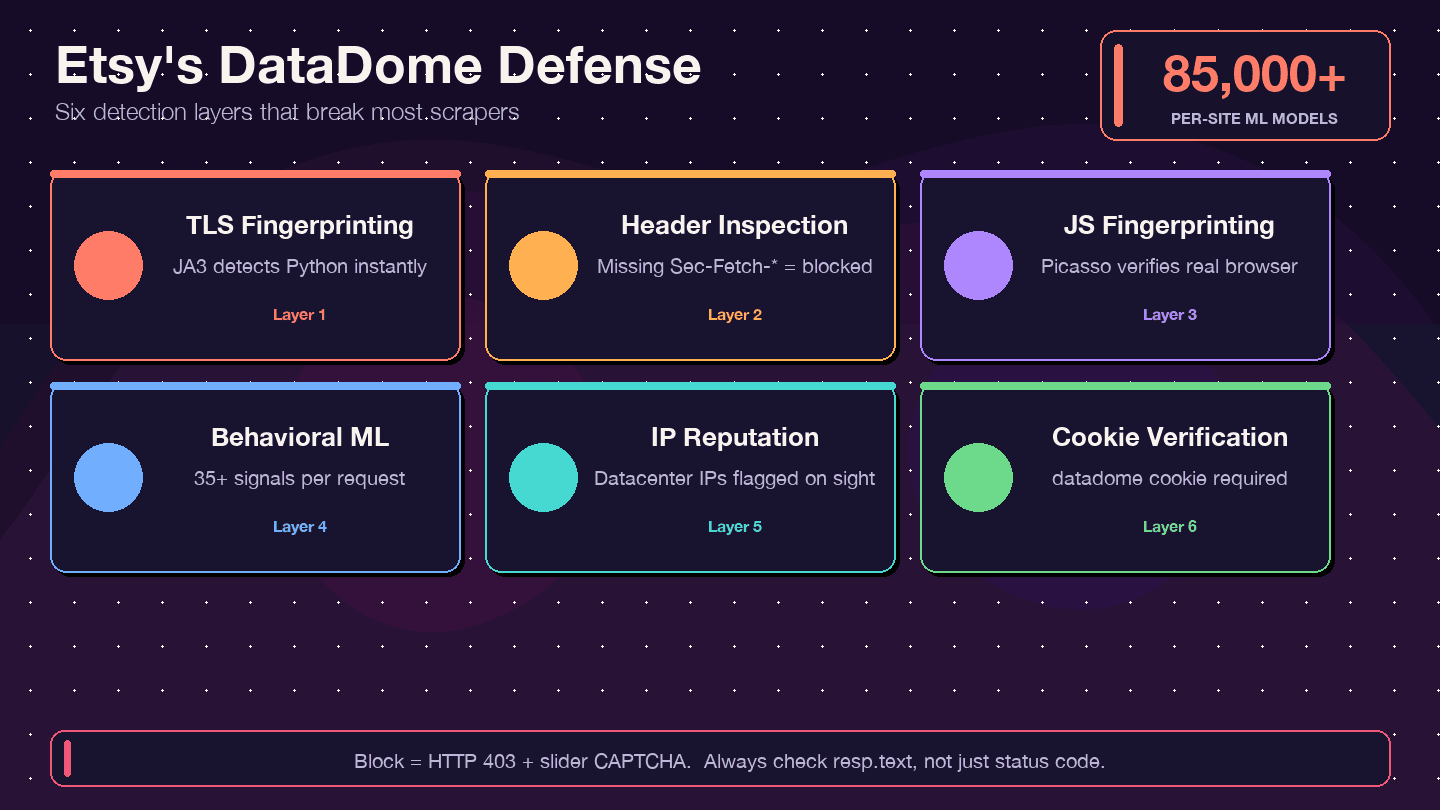
Cos’è DataDome e come funziona?
DataDome non controlla solo il tuo indirizzo IP. Usa uno stack di rilevamento multilivello:
- Fingerprint TLS (JA3): la libreria
requestsdi Python ha una firma TLS distintiva che DataDome può riconoscere subito. - Analisi degli header/protocolli HTTP: verifica che gli header del browser siano completi e coerenti — header mancanti o fuori ordine sono un campanello d’allarme.
- Fingerprint JavaScript (protocollo Picasso): esegue sfide JS nel browser per verificare che tu sia un utente reale.
- ML comportamentale: analizza oltre 35 segnali per richiesta, con più di 85.000 modelli per singolo sito.
- Punteggio di reputazione IP: gli IP dei data center vengono segnalati immediatamente.
- Verifica dei cookie: il cookie
datadomedeve essere presente e valido.
Segnali che sei stato bloccato (e come verificarlo)
Uno dei problemi più comuni: ricevi una risposta 200 OK, ma l’HTML è in realtà una pagina CAPTCHA, non i dati che volevi. Altri segnali:
- Errori 403 Forbidden
- Loop di redirect
- Il corpo della risposta contiene un oggetto JavaScript
ddo HTML di un CAPTCHA slider
Controlla sempre il corpo della risposta, non solo il codice di stato. Un controllo rapido:
1if "captcha" in resp.text.lower() or "datadome" in resp.text.lower():
2 print("Bloccato! Ho ricevuto una pagina CAPTCHA invece dei dati.")Header e cookie che riducono il rilevamento
Non puoi garantire di non essere bloccato, ma header realistici e una buona gestione dei cookie aiutano molto:
1session = requests.Session()
2session.headers.update({
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/133.0.0.0 Safari/537.36",
4 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
5 "Accept-Language": "en-US,en;q=0.9",
6 "Accept-Encoding": "gzip, deflate, br",
7 "Sec-Ch-Ua": '"Chromium";v="133", "Not-A.Brand";v="99", "Google Chrome";v="133"',
8 "Sec-Ch-Ua-Mobile": "?0",
9 "Sec-Ch-Ua-Platform": '"Windows"',
10 "Sec-Fetch-Dest": "document",
11 "Sec-Fetch-Mode": "navigate",
12 "Sec-Fetch-Site": "none",
13 "Upgrade-Insecure-Requests": "1",
14})Altri aspetti importanti:
- Mantieni i cookie tra le richieste usando
requests.Session(). - Aggiungi ritardi casuali (2–7 secondi) tra le richieste.
- Simula una catena di referrer: visita prima la homepage, poi la ricerca, poi le pagine prodotto.
- Su larga scala, la rotazione dei proxy residenziali è essenziale. Gli IP dei data center vengono segnalati quasi all’istante.
Queste tecniche riducono il rilevamento, ma non lo eliminano. Per scraping ad alto volume, probabilmente avrai bisogno di un servizio proxy o di un approccio basato su browser.
Configurare l’ambiente Python per estrarre dati da Etsy
Prima di iniziare:
- Difficoltà: intermedia
- Tempo richiesto: circa 30–60 minuti (configurazione + primo scraping)
- Cosa ti serve: Python 3.8+, pip, un editor di codice, browser Chrome (per l’ispezione con DevTools)
Installa le dipendenze
Crea una cartella di progetto, configura un ambiente virtuale e installa le librerie necessarie:
1mkdir etsy-scraper && cd etsy-scraper
2python -m venv venv
3source venv/bin/activate # Su Windows: venv\Scripts\activate
4pip install requests beautifulsoup4 lxml pandas- requests — scarica le pagine web
- beautifulsoup4 — analizza l’HTML
- lxml — parser HTML più veloce (opzionale ma consigliato)
- pandas — struttura ed esporta i dati in CSV/Excel
Se più avanti ti serve l’automazione del browser (per login o pagine molto basate su JS), installa anche:
1pip install seleniumCapisci la struttura delle pagine Etsy prima di scrivere codice
Ecco un suggerimento che fa risparmiare un sacco di tempo: Etsy incorpora i dati strutturati dei prodotti dentro tag <script type="application/ld+json"> nella maggior parte delle pagine. Questi dati JSON-LD sono già organizzati — nome prodotto, prezzo, valutazione, immagini — quindi non devi combattere con selettori CSS fragili per ogni campo.
Apri una qualsiasi pagina prodotto Etsy, fai clic destro, scegli “Visualizza sorgente pagina” e cerca application/ld+json. Troverai un blocco con @type: Product che contiene gran parte dei dati necessari. Le pagine dei risultati di ricerca hanno @type: ItemList.
I selettori CSS restano utili come fallback (per i dati non presenti nel JSON-LD, come i dettagli di spedizione o il testo delle recensioni), ma il JSON-LD dovrebbe essere il tuo primo punto di partenza.
Passo 1: estrarre i risultati di ricerca Etsy con Python
I risultati di ricerca sono il punto di partenza per la maggior parte dei progetti di scraping su Etsy — che tu stia monitorando una nicchia, tracciando i prezzi dei concorrenti o costruendo un database prodotti.
Costruisci l’URL di ricerca
Gli URL di ricerca di Etsy seguono questo schema:
1https://www.etsy.com/search?q=\{keyword\}&ref=pagination&page=\{page_number\}Per query composte da più parole, codifica gli spazi nell’URL (ad es. handmade+jewelry oppure handmade%20jewelry). Il parametro ref=pagination fa sembrare la richiesta più simile a una vera navigazione del browser.
Altri parametri utili: order (most_relevant, price_asc, price_desc, date_desc), min_price, max_price, ship_to, free_shipping=true. Ogni pagina restituisce 48 elementi.
Invia la richiesta e analizza l’HTML
1import requests
2from bs4 import BeautifulSoup
3import json
4import time
5import random
6headers = {
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
10}
11def scrape_etsy_search(query, max_pages=3):
12 all_products = []
13 for page in range(1, max_pages + 1):
14 url = f"https://www.etsy.com/search?q=\{query\}&ref=pagination&page=\{page\}"
15 resp = requests.get(url, headers=headers, timeout=30)
16 if "captcha" in resp.text.lower():
17 print(f"Bloccato alla pagina \{page\}. Prova ad aggiungere ritardi o proxy.")
18 break
19 soup = BeautifulSoup(resp.text, "lxml")
20 for script in soup.find_all("script", type="application/ld+json"):
21 data = json.loads(script.string)
22 if data.get("@type") == "ItemList":
23 for item in data.get("itemListElement", []):
24 all_products.append({
25 "name": item.get("name"),
26 "url": item.get("url"),
27 "image": item.get("image"),
28 "price": item.get("offers", {}).get("price"),
29 "currency": item.get("offers", {}).get("priceCurrency"),
30 "position": item.get("position"),
31 })
32 time.sleep(random.uniform(2, 5))
33 return all_productsEstrai i dati delle inserzioni dal JSON-LD
L’array itemListElement ti restituisce nome, URL, immagine, prezzo e valuta di ogni inserzione. Se ti servono anche le valutazioni a stelle o il numero di risultati (non sempre presenti nel JSON-LD), passa ai selettori CSS:
- Scheda inserzione:
.v2-listing-card - Titolo:
h3.v2-listing-card__title - Prezzo:
span.currency-value - Link:
a.listing-link(href)
Gestisci la paginazione
Scorri le pagine e aggiungi un ritardo casuale tra una richiesta e l’altra. Etsy in genere restituisce fino a 20–250 pagine a seconda della query.
1results = scrape_etsy_search("handmade+jewelry", max_pages=5)
2print(f"Estratte {len(results)} inserzioni.")Per uno scraping su 5 pagine, nei miei test ci sono voluti circa 20 secondi — contro oltre 30 minuti di copia-incolla manuale.
Passo 2: estrarre le pagine prodotto Etsy con Python
Una volta ottenuto un elenco di URL prodotto dalla ricerca, il passo successivo è raccogliere i dati dettagliati da ciascuna pagina inserzione.
Recupera la pagina prodotto
1def scrape_etsy_product(url):
2 resp = requests.get(url, headers=headers, timeout=30)
3 soup = BeautifulSoup(resp.text, "lxml")
4 for script in soup.find_all("script", type="application/ld+json"):
5 data = json.loads(script.string)
6 if data.get("@type") == "Product":
7 offers = data.get("offers", {})
8 price = offers.get("price") or offers.get("lowPrice")
9 rating_data = data.get("aggregateRating", {})
10 return {
11 "name": data.get("name"),
12 "description": data.get("description", "")[:500],
13 "brand": data.get("brand", {}).get("name") if isinstance(data.get("brand"), dict) else data.get("brand"),
14 "category": data.get("category"),
15 "price": price,
16 "currency": offers.get("priceCurrency"),
17 "availability": offers.get("availability"),
18 "rating": rating_data.get("ratingValue"),
19 "review_count": rating_data.get("reviewCount"),
20 "images": data.get("image", []),
21 "sku": data.get("sku"),
22 "material": data.get("material"),
23 }
24 return NoneGestisci le variazioni di prezzo
Alcuni prodotti hanno un solo offers.price. Altri, con varianti come taglia o colore, usano offers.lowPrice e offers.highPrice. Il codice sopra gestisce entrambi i casi passando da price a lowPrice.
Analizza campi aggiuntivi con selettori CSS
Per i dati non presenti nel JSON-LD — informazioni sulla spedizione, opzioni di variante, dettagli completi del venditore — servono selettori CSS:
- Titolo:
h1[data-buy-box-listing-title] - Varianti:
select[data-selector-id]oppurediv[data-option-set] - Spedizione:
div.wt-text-captionvicino alla sezione spedizione
Il compromesso è questo: il JSON-LD è più pulito e più stabile rispetto ai cambi di layout. I selettori CSS sono più fragili, ma coprono più campi.
Passo 3: estrarre le pagine shop Etsy con Python
Questa è la sezione che la maggior parte delle guide dei concorrenti salta del tutto — e probabilmente è la più preziosa per i team sales e gli analisti competitivi.
Costruisci l’URL dello shop e recupera la pagina
1def scrape_etsy_shop(shop_name):
2 url = f"https://www.etsy.com/shop/\{shop_name\}"
3 resp = requests.get(url, headers=headers, timeout=30)
4 soup = BeautifulSoup(resp.text, "lxml")
5 # Metadati dello shop dall’HTML (non nel JSON-LD)
6 sales_el = soup.select_one("div.shop-sales-reviews a")
7 rating_el = soup.find("input", {"name": "initial-rating"})
8 location_el = soup.select_one("div.shop-location")
9 shop_data = {
10 "name": shop_name,
11 "sales": sales_el.text.strip() if sales_el else None,
12 "rating": rating_el["value"] if rating_el else None,
13 "location": location_el.text.strip() if location_el else None,
14 }
15 # Inserzioni dal JSON-LD
16 listings = []
17 for script in soup.find_all("script", type="application/ld+json"):
18 data = json.loads(script.string)
19 if data.get("@type") == "ItemList":
20 for item in data.get("itemListElement", []):
21 listings.append({
22 "name": item.get("name"),
23 "url": item.get("url"),
24 "price": item.get("offers", {}).get("price"),
25 })
26 shop_data["listings"] = listings
27 return shop_dataCosa puoi estrarre dalle pagine shop
Il JSON-LD nelle pagine shop è @type: ItemList — copre le inserzioni, ma non i metadati a livello di shop come numero di vendite, località o valutazione. Per quelli servono i selettori CSS:
| Dato | Selettore | Note |
|---|---|---|
| Nome shop | h1 o meta title | Di solito nel titolo della pagina |
| Vendite totali | div.shop-sales-reviews a | Testo tipo “12.345 vendite” |
| Valutazione a stelle | valore di input[name="initial-rating"] | Numerico da 1 a 5 |
| Località | div.shop-location | Città, Paese |
| Membro dal | div.shop-info | Testo con la data |
I dati degli shop sono particolarmente utili per costruire liste di lead, fare benchmark dei concorrenti o identificare i top seller in una nicchia.
Passo 4: estrarre le recensioni Etsy con Python
Le recensioni sono tra i dati più preziosi — e più difficili — su Etsy. Il testo completo, le valutazioni e le date non sono nell’HTML iniziale della pagina; vengono caricati tramite un endpoint API interno.
Approccio 1: individuare l’endpoint API interno delle recensioni di Etsy
Apri una pagina prodotto in Chrome, apri DevTools (F12), vai nella scheda Network e scorri fino alla sezione recensioni. Vedrai una richiesta POST verso qualcosa di simile:
1https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviewsQuesto endpoint restituisce frammenti HTML contenenti le card delle recensioni. Per usarlo, ti servono:
- listing_id — l’ID numerico dall’URL del prodotto
- shop_id — da estrarre dall’HTML della pagina prodotto con una regex
- csrf_nonce — da estrarre da un tag
<meta>nella pagina
Estrai ID e token CSRF
1import re
2def get_review_params(product_url):
3 resp = requests.get(product_url, headers=headers)
4 html = resp.text
5 listing_id = product_url.split("/")[-1].split("?")[0]
6 shop_id_match = re.search(r'"shopId"\s*:\s*(\d+)', html)
7 shop_id = shop_id_match.group(1) if shop_id_match else None
8 soup = BeautifulSoup(html, "lxml")
9 csrf_meta = soup.find("meta", {"name": "csrf_nonce"})
10 csrf = csrf_meta["content"] if csrf_meta else None
11 return listing_id, shop_id, csrfEstrarre le recensioni con paginazione
1def scrape_reviews(listing_id, shop_id, csrf, max_pages=5):
2 session = requests.Session()
3 session.headers.update(headers)
4 all_reviews = []
5 for page in range(1, max_pages + 1):
6 payload = {
7 "specs": {
8 "deep_dive_reviews": {
9 "module_path": "neu/specs/deep_dive_reviews",
10 "listing_id": listing_id,
11 "shop_id": shop_id,
12 "page": page,
13 }
14 }
15 }
16 resp = session.post(
17 "https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews",
18 json=payload,
19 headers={"x-csrf-token": csrf, "Content-Type": "application/json"},
20 )
21 data = resp.json()
22 html_fragment = data.get("output", {}).get("deep_dive_reviews", "")
23 review_soup = BeautifulSoup(html_fragment, "lxml")
24 for card in review_soup.select("div.review-card"):
25 rating_el = card.find("input", {"name": "rating"})
26 text_el = card.select_one("div.wt-text-body")
27 user_el = card.select_one("a[data-review-username]")
28 date_el = card.select_one("p.wt-text-body-small")
29 all_reviews.append({
30 "rating": rating_el["value"] if rating_el else None,
31 "text": text_el.text.strip() if text_el else None,
32 "reviewer": user_el.text.strip() if user_el else None,
33 "date": date_el.text.strip() if date_el else None,
34 })
35 time.sleep(random.uniform(2, 5))
36 return all_reviewsApproccio 2: analizzare le recensioni dall’HTML (fallback)
Se l’approccio API fallisce (ad esempio per problemi con il token CSRF), puoi analizzare la prima pagina delle recensioni direttamente dall’HTML della pagina prodotto. Il limite è che solo il primo blocco di recensioni è presente nell’HTML statico. Per ottenere di più, serve l’API oppure uno strumento di automazione browser come Selenium.
Gestire dati che richiedono il login: estrarre il tuo shop Etsy
È un vuoto che nessun altro tutorial copre, ma è un’esigenza reale — soprattutto per i venditori Etsy che vogliono estrarre ordini, ricavi e statistiche del proprio shop.
Il problema: requests da solo non può accedere alla dashboard Etsy perché non porta con sé i cookie della tua sessione di login.
Opzione 1: Selenium con login manuale e acquisizione dei cookie
Usa Selenium per aprire un browser, fare login manualmente (o automatizzarlo), quindi continuare a fare scraping mentre sei autenticato:
1from selenium import webdriver
2driver = webdriver.Chrome()
3driver.get("https://www.etsy.com/signin")
4# Effettua il login manualmente nella finestra del browser, poi:
5input("Premi Invio dopo aver effettuato l’accesso...")
6cookies = driver.get_cookies()
7# Ora usa driver.get() per navigare nelle pagine della dashboard ed estrarre i datiPuoi anche salvare i cookie della sessione Selenium e riutilizzarli con requests.Session() per uno scraping più veloce e leggero dopo il login iniziale.
Opzione 2: esportare i cookie del browser da usare con Requests
Usa un’estensione del browser (come “EditThisCookie”) per esportare i cookie della tua sessione Etsy attiva, poi caricali in una sessione Requests:
1import requests
2session = requests.Session()
3# Aggiungi i cookie esportati dal browser
4session.cookies.set("uaid", "YOUR_UAID_VALUE", domain=".etsy.com")
5session.cookies.set("user_prefs", "YOUR_USER_PREFS_VALUE", domain=".etsy.com")
6# ... aggiungi altri cookie di sessione se necessario
7resp = session.get("https://www.etsy.com/your/orders", headers=headers)La strada più semplice: la modalità Browser Scraping di Thunderbit
Dato che gira dentro il tuo browser Chrome, eredita automaticamente la tua sessione Etsy attiva. Niente codice di autenticazione, niente esportazione di cookie — ti basta aprire la dashboard Etsy ed estrarre i dati. È davvero utile per ottenere ordini, ricavi, statistiche e altri dati riservati ai venditori senza scrivere una sola riga di codice.
Esportare e usare i dati Etsy raccolti
Salva in CSV o JSON
1import pandas as pd
2df = pd.DataFrame(results)
3df.to_csv("etsy_products.csv", index=False, encoding="utf-8")
4df.to_json("etsy_products.json", orient="records", indent=2)Best practice: includi timestamp nei nomi dei file, usa la codifica UTF-8 e gestisci correttamente i caratteri speciali nei nomi dei prodotti (i venditori Etsy adorano emoji e caratteri accentati).
Esporta in Google Sheets, Airtable o Notion
Per chi usa Python, librerie come gspread (Google Sheets) o l’API di Airtable consentono di inviare i dati in modo programmatico. Ma se usi , tutte le esportazioni — verso Google Sheets, Excel, Airtable e Notion — sono gratuite e con un solo clic. Nessuna chiave API, nessuna configurazione OAuth.
Salta il codice: come estrarre dati da Etsy con Thunderbit (alternativa no-code)
Non tutti vogliono scrivere script Python, gestire configurazioni proxy o debuggare selettori CSS alle 2 di notte. Se sei tra questi, ecco come ottenere dati Etsy con .
Installa l’estensione Chrome di Thunderbit
Vai al e installa Thunderbit. Crea un account gratuito — il piano free include e tutte le esportazioni sono gratuite.
Usa “AI Suggest Fields” su qualsiasi pagina Etsy
Apri una pagina Etsy di ricerca, prodotto o shop. Fai clic su "AI Suggest Fields" nella barra laterale di Thunderbit. L’AI analizza la pagina e propone le colonne — nome prodotto, prezzo, valutazione, immagini, nome shop, tag, informazioni di spedizione. Puoi modificare o aggiungere colonne secondo le tue esigenze.
Clicca su Scrape ed esporta
Fai clic su "Scrape" per estrarre i dati della pagina corrente. Per risultati multipagina, usa lo scraping con paginazione di Thunderbit. Per arricchire un elenco di URL prodotto con dettagli da ciascuna pagina (descrizioni, recensioni, spedizione), usa lo scraping delle sottopagine — Thunderbit visita ogni link ed estrae automaticamente i dati extra.
Esporta in Excel, Google Sheets, Airtable o Notion — tutto gratis.
Quando Thunderbit batte Python per lo scraping di Etsy
- Nessuna configurazione proxy o codice anti-bot necessario. Thunderbit gira nel tuo vero browser Chrome, quindi eredita la tua sessione e appare a DataDome come un utente normale.
- L’AI si adatta automaticamente ai cambi di layout. Niente selettori rotti da sistemare quando Etsy aggiorna il frontend.
- Perfetto per ricerche una tantum, analisi competitive o membri non tecnici del team. Se ti serve solo un dataset veloce, non hai bisogno di un ambiente Python.
- Lo scraping delle sottopagine ti consente di arricchire un elenco di URL prodotto con dati dettagliati senza scrivere loop annidati.
Per una dimostrazione, dai un’occhiata al .
Confronto dei costi a 6 mesi: Python vs Thunderbit
| Fattore | Python fai-da-te | Thunderbit |
|---|---|---|
| Tempo di configurazione | 8–20 ore | Meno di 5 minuti |
| Costo in 6 mesi (inclusi lavoro e proxy) | 2.720–9.450 $ | 90–228 $ |
| Manutenzione mensile | 4–10+ ore (gli aggiornamenti dei selettori = oltre l’80% dell’overhead) | 0–1 ore |
| Gestione anti-bot | Proxy residenziali al costo di credito 85x rispetto al normale | Basato su browser, bypass nativo di DataDome |
| Qualità dei dati | Alta (con impegno) | Alta (guidata dall’AI) |
Non sto dicendo che Python sia la scelta sbagliata — se ti serve controllo totale, logica personalizzata o integrazione in una pipeline più ampia, il codice resta il re. Ma per la maggior parte degli utenti business che hanno solo bisogno dei dati di Etsy, il calcolo del ROI favorisce uno strumento no-code.
Consigli legali ed etici per lo scraping di Etsy
Mi chiedono sempre della legalità in ogni articolo sullo scraping, quindi ecco la versione breve:
- I Termini di utilizzo di Etsy vietano esplicitamente l’accesso automatizzato. Detto questo, Etsy si affida all’applicazione tecnica (DataDome) più che al contenzioso — non risultano cause note specifiche contro scraper legate a Etsy.
- Estrai solo dati pubblicamente disponibili. Non aggirare l’autenticazione né accedere a dashboard private di venditori che non ti appartengono.
- Usa frequenze di richiesta ragionevoli. Ritardi di 2–7 secondi tra le richieste e niente stress inutile ai server di Etsy.
- Rispetta
robots.txt. Etsy consente le pagine di ricerca ma limita alcuni percorsi. - Gestisci con responsabilità i dati personali in base a leggi sulla privacy come il GDPR.
- Consulta un legale per progetti di scraping su scala commerciale.
Per maggiori dettagli, leggi il nostro articolo sulle — incluso Meta v. Bright Data (2024), in cui è stato confermato l’uso di dati pubblici.
In conclusione: i punti chiave
Abbiamo coperto davvero tanto. Ecco cosa vorrei che portassi a casa:
- I dati strutturati JSON-LD di Etsy rendono l’estrazione più pulita rispetto all’analisi dell’HTML grezzo per la maggior parte dei campi.
- DataDome è un ostacolo reale — usa header corretti, ritardi, gestione dei cookie e proxy residenziali per lo scraping Python su larga scala.
- L’API di Etsy è limitata. Se ti servono recensioni, shop dei concorrenti o analisi tra venditori, lo scraping è la strada pratica.
- Thunderbit offre un’alternativa no-code che gestisce nativamente anti-bot e autenticazione — vale la pena provarlo se vuoi dati Etsy senza mantenere script.
- Fai sempre scraping in modo responsabile e rispetta i termini di Etsy.
Se vuoi iniziare senza scrivere codice, . Oppure usa il codice Python di questo tutorial per costruire il tuo scraper personalizzato — e che i tuoi selettori non si rompano mai di venerdì pomeriggio.
Per altre guide sullo scraping, dai un’occhiata alla nostra e alla rassegna dei .
FAQ
1. È legale estrarre dati da Etsy con Python?
In generale, l’estrazione di dati pubblicamente disponibili è consentita alla luce di recenti precedenti legali (ad es. Meta v. Bright Data, hiQ v. LinkedIn). Tuttavia, i Termini di utilizzo di Etsy vietano l’accesso automatizzato, quindi controlla sempre i ToS e robots.txt prima di fare scraping. Per utilizzi commerciali o su larga scala, consulta un legale.
2. Posso estrarre dati da Etsy senza essere bloccato?
Etsy usa DataDome, uno dei sistemi anti-bot più severi in circolazione. Header realistici, ritardi nelle richieste, persistenza dei cookie e rotazione dei proxy residenziali aiutano a ridurre i blocchi. L’approccio browser-native di Thunderbit evita la maggior parte dei rilevamenti perché opera dentro la tua sessione Chrome reale.
3. Etsy ha un’API che posso usare al posto dello scraping?
Sì — Etsy offre un’API v3, ma è in gran parte limitata ai dati del tuo shop e non offre un accesso robusto alle recensioni. La maggior parte dei casi d’uso di competitive intelligence e analisi tra shop richiede lo scraping.
4. Quali librerie Python mi servono per estrarre dati da Etsy?
Al minimo: requests, beautifulsoup4, pandas (per l’esportazione) e json (incluso nella libreria standard). Per pagine molto basate su JS o che richiedono login, aggiungi selenium. Per un parsing HTML più veloce, usa lxml.
5. Come faccio a estrarre specificamente le recensioni di Etsy?
Le recensioni Etsy vengono caricate tramite un endpoint API interno (/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews). Devi estrarre dalla pagina prodotto l’ID dell’inserzione, l’ID dello shop e il token CSRF, quindi inviare una POST all’endpoint con paginazione. In alternativa, puoi analizzare il primo blocco di recensioni dall’HTML della pagina prodotto — in questo tutorial trovi entrambi gli approcci passo per passo.
Scopri di più