La maggior parte dei tutorial su come scrapare eBay dura più o meno tre mesi. Lo so perché il team di Thunderbit ha visto sviluppatori inseguire snippet di codice già rotti, selettori CSS ormai superati e repository GitHub “funzionanti” che hanno smesso di andare in silenzio già due redesign di eBay fa.
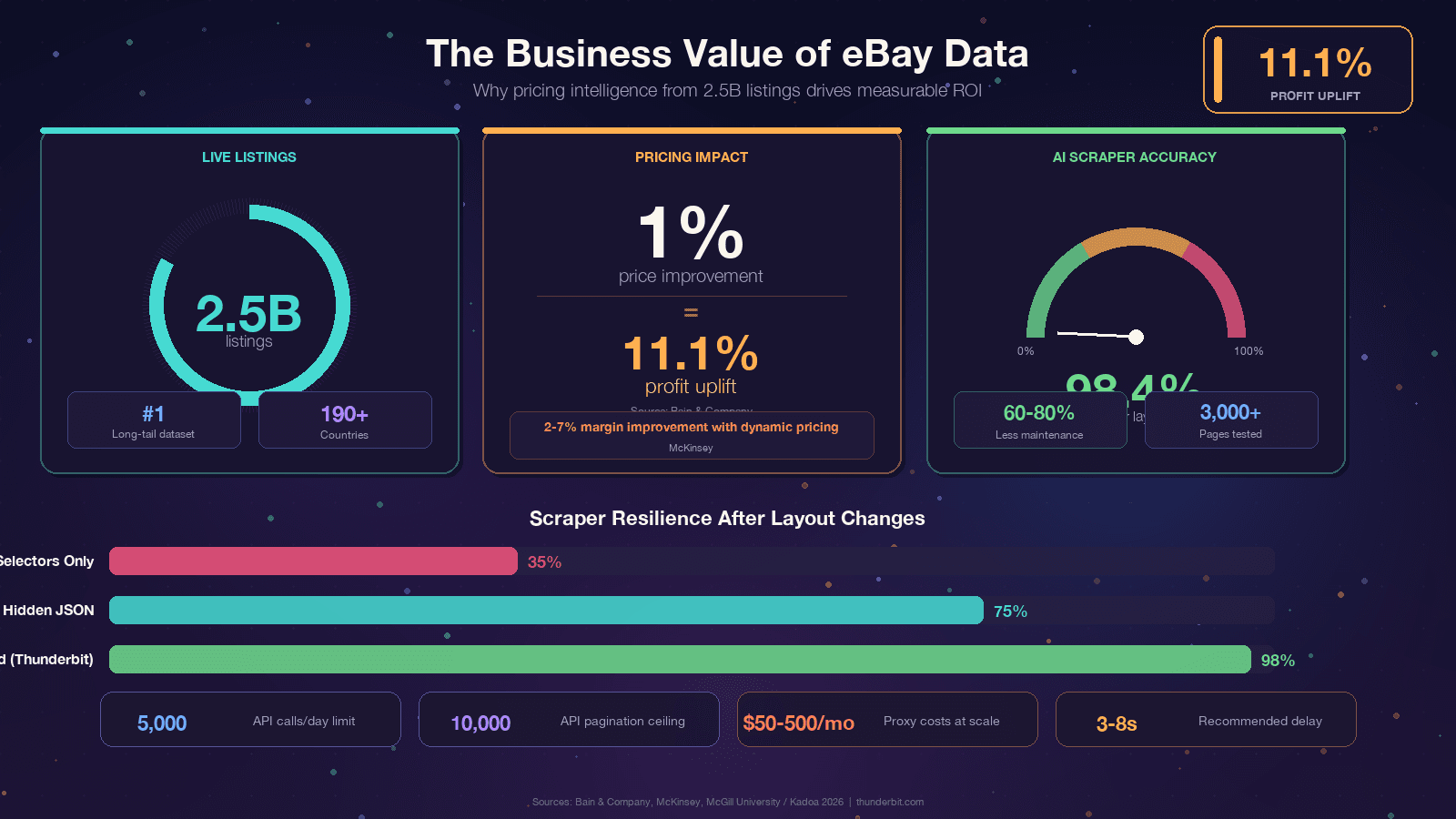
eBay ospita — il più grande database pubblico di prezzi long-tail sul web, subito dopo Amazon. Questi dati alimentano di tutto: dal pricing per i rivenditori all’analisi della concorrenza. Ma arrivarci in modo programmatico è un bersaglio che si muove di continuo: il frontend di eBay basato su React cambia spesso i nomi delle classi CSS, gli A/B test mostrano strutture DOM diverse a utenti diversi e Akamai Bot Manager si mette in mezzo tra te e l’HTML. Questa guida ti dà codice Python che funziona oggi, spiega perché gli scraper si rompono così puoi costruirne di più robusti, mette a confronto in modo onesto API di eBay e scraping, e ti mostra un’alternativa no-code quando Python non vale la complessità del setup.
Cosa significa scrapare eBay con Python?
Scrapare eBay con Python significa scrivere script che scaricano in modo programmatico le pagine web di eBay, analizzano l’HTML (o il JSON nascosto) ed estraggono dati strutturati — titoli, prezzi, informazioni sul venditore, date di vendita, dettagli delle varianti — in un formato davvero utile, come CSV, foglio di calcolo o database.
Puoi scrapare diversi tipi di pagine eBay:
- Risultati di ricerca (per esempio tutte le inserzioni “AirPods Pro”)
- Pagine di dettaglio prodotto (specifiche complete, immagini, dati del venditore)
- Inserzioni vendute/completate (prezzi e date reali delle transazioni)
- Profili venditore e recensioni
Python è il linguaggio più usato per questo tipo di lavoro. Il suo ecosistema — Requests, BeautifulSoup, lxml, pandas — rende facile scaricare pagine, leggere l’HTML e rielaborare i dati. C’è però una differenza importante tra scrapare l’HTML del sito e usare l’API ufficiale di eBay: la vediamo tra poco.
Perché scrapare eBay? Casi d’uso reali per i team business
Se stai leggendo questa guida, probabilmente hai già un motivo preciso. Vale comunque la pena legare il discorso a un valore di business concreto, perché il ROI dei dati di eBay è davvero forte. Bain ha scoperto che un in migliaia di aziende. McKinsey attribuisce al dynamic pricing nel retail.
I casi d’uso che vedo più spesso:
| Caso d’uso | Dati necessari | Risultato di business |
|---|---|---|
| Monitoraggio prezzi e repricing | Prezzi delle inserzioni attive, spedizione, condizioni | Prezzi competitivi, protezione dei margini |
| Analisi dei concorrenti | Assortimento prodotti, promozioni, condizioni di spedizione | Posizionamento strategico, lacune di assortimento |
| Ricerca di mercato e individuazione trend | Velocità delle inserzioni, trend di categoria, modelli di domanda | Identificazione di nuovi prodotti, previsione della domanda |
| Pricing per rivenditori / valutazioni | Prezzi venduti, date di vendita, condizioni | Valore di mercato corretto, decisioni di acquisto |
| Analisi del sentiment | Recensioni, valutazioni, politica dei resi | Insight sulla qualità del prodotto, soddisfazione cliente |
| Lead generation | Profili venditore, informazioni sul negozio, contatti | Outreach B2B verso venditori ad alto GMV |
Il punto è semplice: eBay ha i dati, ma sono chiusi dentro pagine web.
Lo scraping è il modo per trasformarli in un vantaggio competitivo.
API ufficiale di eBay vs scraping Python: quale scegliere?
È la domanda a cui vorrei che più tutorial rispondessero con sincerità. eBay offre API ufficiali — soprattutto la — e molti si chiedono se convenga usarle oppure fare scraping diretto. La risposta dipende solo dai dati che ti servono.
| Criterio | API eBay Browse/Finding | Scraping Python |
|---|---|---|
| Inserzioni vendute/completate | Limitate — esiste la Marketplace Insights API, ma l’accesso viene spesso rifiutato | Accesso completo tramite parametri URL LH_Sold=1&LH_Complete=1 |
| Limiti di chiamata | 5.000 chiamate/giorno nel livello base | Gestione autonoma (dipende dai proxy) |
| Campi disponibili | Predefiniti (titolo, prezzo, categoria, basi del venditore) | Tutto ciò che è visibile nella pagina (recensioni, specifiche complete, varianti) |
| Complessità di setup | OAuth 2.0, registrazione app, chiavi API | pip install + codice |
| Stabilità | Endpoint stabili | Si rompe quando cambia l’HTML |
| Costo | C’è un piano gratuito, poi a pagamento per volumi | Codice gratuito, ma costi dei proxy su larga scala |
| Dati varianti/MSKU | Parziale — spesso solo SKU padre | Completo (tramite parsing del JSON nascosto) |
| Profondità della paginazione | Tetto massimo di 10.000 elementi | Teoricamente illimitata |
Nota veloce: la vecchia Finding API (con findCompletedItems) è stata . Se stai usando ebaysdk-python o qualsiasi libreria che interroga il modulo Finding, in produzione oggi non funziona.
Il mio consiglio: usa la Browse API per query stabili, con volumi moderati e dati strutturati sulle inserzioni attive. Usa lo scraping Python quando ti servono prezzi di vendita, recensioni, dati delle varianti o qualsiasi campo che l’API non espone. Molti team usano entrambi.
Strumenti e librerie necessari per scrapare eBay con Python
Prima di scrivere codice, ecco il set di strumenti. Per la maggior parte delle pagine eBay non serve un browser headless: i dati sono già incorporati nell’HTML renderizzato dal server.
| Libreria | Scopo |
|---|---|
requests o httpx | Client HTTP per scaricare le pagine eBay |
curl_cffi | Client HTTP con fingerprint TLS da browser reale (fondamentale per aggirare Akamai) |
beautifulsoup4 | Parser HTML per estrarre tramite selettori CSS |
lxml | Backend di parsing veloce per BeautifulSoup |
jmespath | Linguaggio di query per analizzare blob JSON annidati |
pandas | Manipolazione dati ed esportazione CSV/Excel |
gspread | Integrazione con Google Sheets |
Installa tutto con una sola riga:
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadUsa Python 3.11+ — pandas 3.0 richiede almeno la 3.10, e la 3.11 porta miglioramenti di velocità del 10–60% nei carichi I/O-bound.
Una libreria merita una menzione speciale: curl_cffi è l’upgrade singolo più utile che uno scraper eBay del 2026 possa adottare. eBay usa e il principale vettore di rilevamento di Akamai è il fingerprinting TLS. Le richieste requests standard generano un fingerprint JA3 riconoscibile come Python, che viene segnalato subito. curl_cffi imita l’handshake TLS di un vero browser Chrome, e gestisce circa il 90% dei target protetti da Akamai senza bisogno di un browser headless.
Guida passo passo: come scrapare i risultati di ricerca eBay con Python
Questa è la guida centrale. Faremo scraping delle pagine dei risultati di ricerca eBay per ottenere le inserzioni.
- Difficoltà: Principiante–Intermedio
- Tempo richiesto: circa 30 minuti per il primo scraping funzionante
- Cosa ti serve: Python 3.11+, le librerie sopra, un terminale e un URL di ricerca eBay di destinazione
Passo 1: prepara il progetto Python
Crea una cartella di progetto e installa le dipendenze:
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasCrea un file chiamato scrape_ebay.py. Sarà il tuo spazio di lavoro.
Passo 2: costruisci l’URL di ricerca eBay
La struttura dell’URL di ricerca di eBay è semplice. Il parametro chiave è _nkw (keyword):
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # elementi per pagina: 60, 120 o 240 (240 può far scattare i filtri anti-bot)
7 "_pgn": "1", # numero di pagina
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1Altri parametri utili:
LH_BIN=1— solo Buy It Now_sacat=175673— categoria specifica_sop=12— ordina per miglior corrispondenza (10 = prezzo+spedizione più bassi, 13 = inserzioni appena pubblicate)LH_Complete=1&LH_Sold=1— inserzioni vendute/completate (trattate in una sezione dedicata più sotto)
Passo 3: invia una richiesta e gestisci la risposta
Qui curl_cffi fa la differenza. Una semplice requests.get() restituisce spesso un 403 da Akamai. Con curl_cffi, impersoniamo un vero browser Chrome:
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Status {r.status_code}, nuovo tentativo tra {sleep_for:.1f}s...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" Errore nella richiesta: {e}, nuovo tentativo...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"Fallito dopo {max_retries} tentativi: {url}")Il backoff esponenziale con jitter è importante: intervalli di attesa fissi sono già di per sé un segnale da bot.
Passo 4: analizza le inserzioni dalla pagina di ricerca
eBay è attualmente a metà migrazione tra due layout dei risultati di ricerca. Uno scraper robusto deve gestire entrambi:
| Campo | Layout legacy | Nuovo layout |
|---|---|---|
| Contenitore card | li.s-item | li.s-card o div.su-card-container |
| Titolo | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Prezzo | span.s-item__price | .s-card__price |
Il codice di parsing che gestisce entrambi i layout:
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # Titolo — prova entrambi i layout
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # Salta la card fantasma “Shop on eBay”
11 if not title or "Shop on eBay" in title:
12 continue
13 # Prezzo
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # Immagine
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # Spedizione
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return resultsLa trappola della prima card fantasma è un classico errore. La prima li.s-item in molte pagine di ricerca eBay è un segnaposto nascosto con il titolo “Shop on eBay” e senza un prezzo reale. Filtrala sempre.
Passo 5: gestisci la paginazione per scrapare più pagine
eBay usa il parametro _pgn per la paginazione. Il link alla pagina successiva usa a.pagination__next:
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Scraping pagina {page_num}: {url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" Nessun risultato alla pagina {page_num}, interrompo.")
12 break
13 all_results.extend(results)
14 print(f" Trovate {len(results)} inserzioni (totale: {len(all_results)})")
15 # Pausa cortese — 3-8 secondi con jitter
16 time.sleep(random.uniform(3, 8))
17 return all_resultsIl jitter casuale tra 3 e 8 secondi non è opzionale.
eBay e il suo strato Akamai segnalano traffico sostenuto sopra 1 richiesta al secondo dallo stesso IP.
Passo 6: esporta i dati estratti in CSV o JSON
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"Esportate {len(df)} inserzioni in CSV e JSON.")A questo punto dovresti avere un foglio di calcolo pulito con le inserzioni eBay. Sulla mia macchina, scrapare 3 pagine (360 inserzioni) ha richiesto circa 45 secondi, pause incluse.
Come scrapare le pagine di dettaglio prodotto eBay con Python
I risultati di ricerca ti danno una sintesi. Le pagine di dettaglio prodotto contengono il meglio: descrizioni complete, punteggi di feedback del venditore, specifiche dell’oggetto, caroselli di immagini e dati delle varianti.
Analizzare una singola pagina di inserzione
Le pagine degli articoli eBay si trovano in /itm/<ITEM_ID>. Il percorso di estrazione più stabile è il JSON-LD — eBay incorpora un blocco schema Product che resiste a quasi tutti i cambi di CSS:
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — percorso di estrazione più stabile
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. Fallback CSS per i campi non presenti nel JSON-LD
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. Specifiche dell’oggetto
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemIl pattern qui — prima JSON-LD, poi fallback CSS — è la chiave per costruire scraper che non si rompono ogni trimestre. Ne parliamo più avanti.
Scraping delle varianti prodotto eBay (dati MSKU)
Alcune inserzioni eBay hanno più varianti — colori diversi, taglie diverse, capacità di archiviazione diverse. Il DOM visibile mostra solo un intervallo di prezzo tipo “899 € - 1.099 €” finché l’utente non seleziona un’opzione. Il prezzo reale per ogni variante si trova in un oggetto JavaScript nascosto chiamato MSKU.
Questo è uno dei casi in cui l’API di eBay fornisce solo dati parziali (SKU padre), rendendo lo scraping la scelta migliore.
1import re, json
2def extract_variants(html):
3 # Il match non greedy è fondamentale — il .+ greedy ingoia l’intera pagina
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusQuel (.+?) non greedy nella regex è il punto in cui inciampa ogni scraper eBay. Il .+ greedy ingoia tutto fino all’ultimo "QUANTITY" della pagina, producendo JSON malformato. Ho visto questo bug in almeno tre tutorial “funzionanti”.
Come scrapare le inserzioni vendute e completate di eBay con Python
Questo è il caso d’uso che giustifica davvero lo scraping rispetto all’API. I dati degli articoli venduti — cosa è stato effettivamente transato, a quale prezzo, in quale data — sono lo standard d’oro per ricerche di mercato, pricing per rivenditori e valutazioni. La Browse API di eBay non li fornisce esplicitamente. La in teoria sì, ma l’accesso è una “Limited Release” e viene .
I parametri URL necessari sono LH_Complete=1 (inserzioni completate) e LH_Sold=1 (solo effettivamente vendute). Devono esserci entrambi. Usare solo LH_Sold=1 su alcune categorie riporta in silenzio alle inserzioni attive: è la trappola più comune nella community.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Scraping pagina venduti {page_num}...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # Includi solo gli articoli effettivamente venduti (prezzo verde nel wrapper POSITIVE)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # Inserzione completata ma non venduta — salta
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # Estrai la data di vendita
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldLa differenza chiave nell’HTML: gli articoli venduti mostrano il prezzo in verde (dentro un wrapper .POSITIVE), mentre le inserzioni completate ma non vendute mostrano il prezzo in rosso barrato. Filtra sempre sulla classe .POSITIVE.
Perché gli scraper eBay si rompono (e come costruirne di resistenti)
Se il tuo scraper eBay ha smesso di funzionare, sei in buona compagnia. È il problema numero uno in ogni thread dei forum sullo scraping di eBay che ho letto. La domanda non è se il tuo scraper si romperà — è quando.
Perché succede:
- eBay usa rendering basato su React con classi generate in modo dinamico che cambiano a ogni deploy
- Gli A/B test servono strutture DOM diverse a utenti diversi (il doppio layout
s-item/s-cardne è un esempio vivo) - I redesign periodici del sito cambiano il nesting HTML, anche quando i dati restano identici
- I vecchi selettori come
#itemTitlee#prcIsumsono stati rimossi anni fa ma continuano ad apparire nei tutorial
Come dice la : “La vera sfida nello scraping di eBay è gestire i cambiamenti dei selettori CSS. eBay aggiorna regolarmente il frontend, rompendo gli scraper che si affidano a nomi di classe specifici.”
Strategie di difesa per scraper eBay di lunga durata
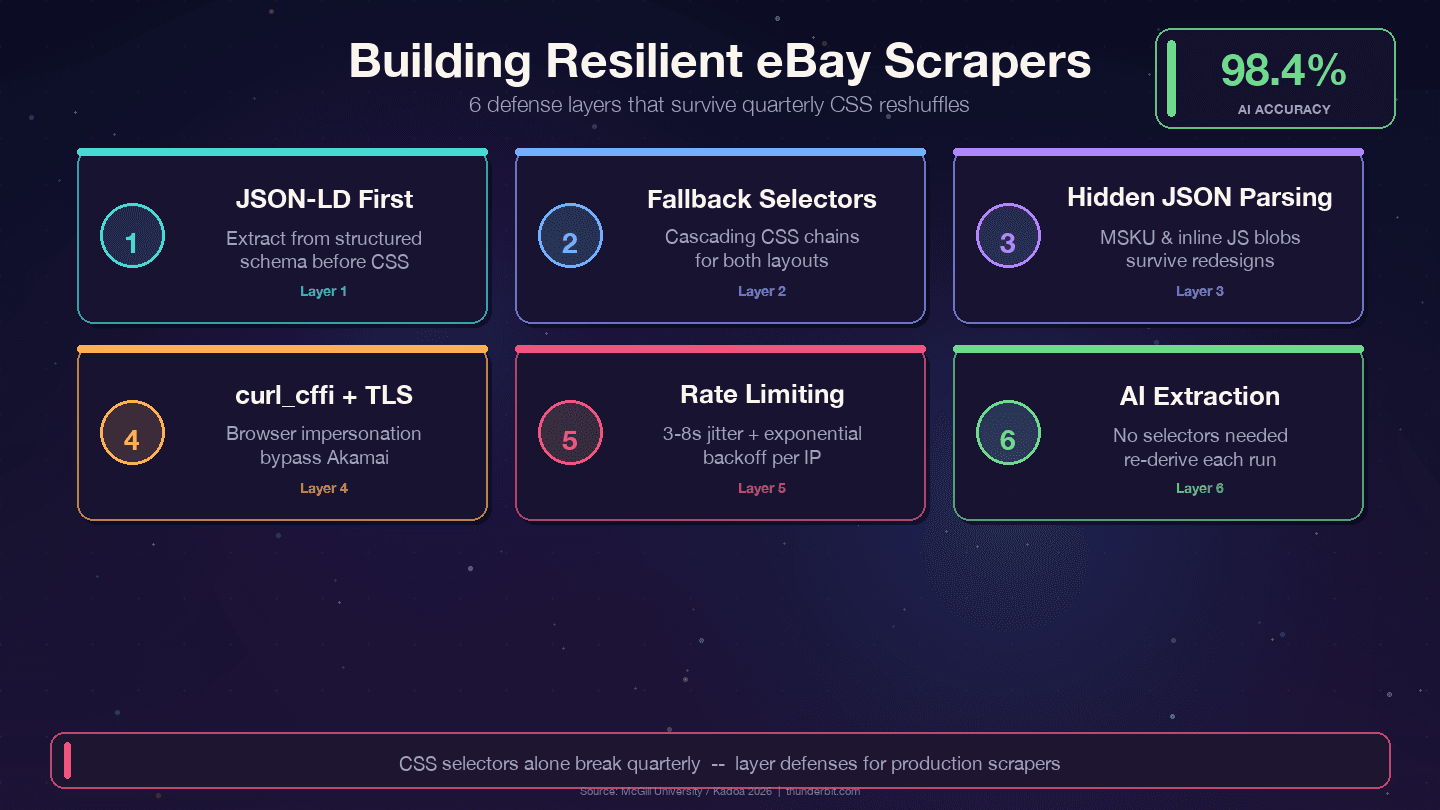
Quattro strategie che reggono meglio ai rimescolamenti trimestrali di eBay:
1. Dai priorità al JSON-LD rispetto ai selettori CSS. eBay incorpora dati strutturati dello schema Product in ogni pagina articolo. Il livello dati cambia molto meno del livello di presentazione — i designer rifanno le classi CSS ogni trimestre, ma i nomi dei campi backend come price, name e seller sono collegati ad API interne e raramente vengono rinominati.
2. Usa selettori di fallback a cascata. Non affidarti mai a un solo selettore CSS. Fornisci sempre alternative:
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. Analizza blob JSON nascosti. L’oggetto varianti MSKU e i dati JavaScript inline sopravvivono ai cambi CSS perché vengono generati lato server. Estrarre con regex dai tag <script> richiede più lavoro all’inizio, ma riduce molto la manutenzione.
4. Registra i fallimenti dei selettori. Aggiungi un monitoraggio per sapere quando un selettore smette di corrispondere, non solo che i dati sono vuoti:
1if title is None:
2 print(f"WARNING: title selector failed for {url}")5. Usa curl_cffi con impersonificazione del browser. Questo gestisce il TLS fingerprinting di Akamai senza bisogno di un browser headless.
L’alternativa basata su AI: niente manutenzione dei selettori
Se sei stufo di sistemare i selettori ogni pochi mesi, c’è un approccio completamente diverso. Strumenti come usano l’AI per leggere la pagina da zero ogni volta e dedurre al volo la logica di estrazione. Uno studio della McGill University ha testato scraper basati su AI e su selettori su 3.000 pagine e ha rilevato che , con benchmark di settore che citano .
| Approccio | Si rompe quando eBay cambia l’HTML? | Impegno di manutenzione |
|---|---|---|
| Selettori CSS hardcoded | Sì, ogni trimestre | Alto — patch continue |
| Estrazione da JSON nascosto / JSON-LD | Raramente | Basso |
| Scraping basato su AI (Thunderbit) | No — l’AI ricalcola i selettori a ogni esecuzione | Nessuno |
Più avanti vedremo in dettaglio il flusso di lavoro di Thunderbit. Per ora, il punto chiave è questo: se stai costruendo uno scraper che dovrà girare per mesi, conviene investire in estrazione JSON-first e selettori di fallback. Se invece non vuoi mantenere selettori per niente, l’approccio AI merita attenzione.
Automatizzare scraping eBay ricorrenti per il monitoraggio prezzi
Uno scraping una tantum è utile. Ma il monitoraggio prezzi, il tracking delle scorte e l’analisi dei concorrenti richiedono raccolte dati ricorrenti. Ogni articolo dei competitor che ho letto cita il monitoraggio prezzi come caso d’uso, ma quasi nessuno mostra davvero come automatizzarlo.
Opzione 1: cron job (Linux/macOS) o Utilità di pianificazione (Windows)
L’approccio più semplice. Incapsula il tuo script Python in un cron job. Usa sempre il percorso assoluto dell’interprete Python del virtual environment — cron gira con un ambiente minimo:
1crontab -e
2# Ogni giorno alle 08:15
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1Su Windows, usa PowerShell:
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $TServe una macchina sempre accesa, e devi gestire tu proxy e misure anti-bot.
Opzione 2: funzioni cloud (serverless)
AWS Lambda o Google Cloud Functions ti permettono di eseguire scraper senza un server dedicato. Richiedono più setup — devi impacchettare le dipendenze, gestire i timeout (Lambda limita a 15 minuti) e comunque controllare i proxy. Però non c’è manutenzione del server.
Opzione 3: scheduling no-code con Thunderbit
La funzione di Thunderbit ti consente di descrivere l’intervallo in linguaggio naturale (per esempio “ogni giorno alle 8”), inserire gli URL di eBay e cliccare su Schedule. Il processo gira nel cloud con gestione anti-bot integrata.
| Approccio | Sforzo di setup | Serve un server? | Gestisce l’anti-bot? |
|---|---|---|---|
| Cron + script Python | Medio | Sì (macchina sempre attiva) | Devi gestire i proxy |
| Funzione cloud (Lambda) | Alto | No (serverless) | Devi gestire i proxy |
| Thunderbit Scheduled Scraper | Basso (descrivi a parole) | No (cloud) | Integrato |
Per archiviare i dati di scraping ricorrenti, un database SQLite locale è la soluzione migliore per la cronologia prezzi. Usa ON CONFLICT ... DO UPDATE (non INSERT OR REPLACE, che ):
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);Non vuoi programmare? Come scrapare eBay in 2 minuti con Thunderbit
Ho dedicato 2.000 parole al codice Python. Ora voglio essere sincero su quando non ti serve.
Se sei un utente business che fa una ricerca di mercato una tantum, un rivenditore che controlla i comparabili, o un team ecommerce che ha bisogno di dati oggi senza uno sprint di sviluppo, Python è troppo. Il setup, la manutenzione dei selettori, la gestione dei proxy — è molto overhead per un “mi servono solo queste 200 inserzioni in un foglio di calcolo”.
Come Thunderbit scrapare eBay (passo dopo passo)
- Installa la — non serve carta di credito.
- Apri in Chrome una qualsiasi pagina di risultati di ricerca o una pagina prodotto eBay.
- Clicca “AI Suggest Fields” nella sidebar di Thunderbit. L’AI legge la pagina e propone le colonne: Titolo, Prezzo, Condizione, Spedizione, Venditore, Valutazione.
- Clicca “Scrape.” L’estensione segue la paginazione e compila la tabella dati. In particolare per eBay, Thunderbit offre che funzionano con un solo clic.
- Esporta su Google Sheets, Airtable, Notion, CSV, JSON o Excel — gratis.
L’intero processo richiede meno di 2 minuti.
L’ho cronometrato.
Arricchimento delle sottopagine: ottieni i dati delle pagine dettaglio senza codice extra
Dopo aver estratto una pagina di risultati, Thunderbit può visitare la pagina di dettaglio di ciascuna inserzione e aggiungere campi extra — specifiche complete, dati del venditore, descrizione, tutte le immagini. In pratica sostituisce le 20+ righe di codice Python per lo scraping delle sottopagine che abbiamo scritto prima con un solo clic.
Quando ha ancora senso usare Python
Python vince quando ti servono:
- Scraping su larga scala (decine di migliaia di pagine per esecuzione)
- Logiche di parsing o trasformazione dati molto personalizzate
- Integrazione in pipeline dati esistenti (Airflow, dbt, Kafka)
- Controllo fine di TLS/sessione per lavori anti-bot avanzati
- Economia unitaria — su milioni di righe, uno stack mantenuto internamente batte un SaaS a crediti
Per la maggior parte dei progetti one-off o di media scala, Thunderbit è più veloce e più semplice. Per pipeline di produzione su larga scala, Python ti dà il controllo totale.
Consigli per evitare il blocco quando scrapare eBay con Python
eBay e il suo livello Akamai sono reali. Ecco cosa funziona davvero nella pratica:
- Usa
curl_cfficonimpersonate="chrome124"— è il miglior salto in avanti rispetto arequestsstandard - Ruota gli User-Agent da una lista di versioni browser recenti (Chrome 143, Firefox 124, Safari 26)
- Aggiungi ritardi casuali di — gli intervalli fissi sono un fingerprint
- Usa proxy residenziali o rotanti per qualsiasi lavoro oltre poche decine di pagine. Gli IP da data center (AWS, GCP, DigitalOcean) vengono segnalati in fretta da Akamai.
- Rispetta
robots.txt— molti URL di browse filtrati sono esplicitamente Disallow; le pagine dettaglio articolo (/itm/<id>) di solito no - Gestisci i CAPTCHA con calma — rilevali e riprova con un IP diverso, oppure usa un servizio di solving
- Non martellare il server. Il precedente dice che il “trespass to chattels” si applica quando lo scraping degrada davvero i server. Restare sotto 1 richiesta al secondo per IP ti tiene ben lontano da quella soglia.
Per un uso commerciale ad alto volume, considera di usare la Browse API per le inserzioni attive e lo scraping mirato solo per comparabili venduti e dati che l’API non espone. Questo approccio ibrido è più pulito sia dal punto di vista tecnico sia legale.
È legale scrapare eBay con Python?
Non sono un avvocato, e questo articolo non è consulenza legale. Quindi sarò breve.
Il quadro legale si è spostato a favore dello scraping dei dati pubblicamente accessibili. I precedenti chiave:
- (9th Cir., 2022): scrapare dati pubblicamente accessibili non viola il CFAA
- Van Buren v. United States (SCOTUS, 2021): ha ristretto la clausola “exceeds authorized access” del CFAA
- (N.D. Cal., 2024): lo scraping da logout non viola i termini della piattaforma perché lo scraper non è un “utente”
Detto questo, l’ proibisce esplicitamente “buy-for-me agents, LLM-driven bots, o qualunque flusso end-to-end che tenti di effettuare ordini senza revisione umana.” Il confine è chiaro: lo scraping in sola lettura di pagine pubbliche è su basi solide; automatizzare il checkout no.
Buone pratiche: scrapa solo dati pubblicamente visibili. Non creare account falsi e non aggirare le barriere di login. Non rivendere in blocco immagini protette da copyright. E consulta un legale per progetti commerciali su larga scala.
Conclusione e punti chiave
Python è il modo più flessibile per scrapare eBay, ma richiede manutenzione continua quando cambia l’HTML del sito. La logica decisionale è questa:
- Usa la Browse API di eBay per query stabili, con volumi moderati, sulle inserzioni attive
- Usa lo scraping Python per inserzioni vendute, recensioni, dati delle varianti e qualsiasi campo che l’API non espone
- Usa se vuoi i dati eBay senza scrivere o mantenere codice
Il codice di questa guida privilegia la resilienza: prima l’estrazione JSON-LD, poi i fallback CSS a cascata, infine il parsing del JSON nascosto per le varianti. Questo approccio a livelli fa sì che il tuo scraper non muoia al prossimo rifacimento del frontend di eBay.
Se vuoi provare la strada no-code, il ti permette di testarlo subito sulle pagine eBay. E se vuoi vedere come funziona il , è a un clic di distanza.
Per altri contenuti sugli strumenti di web scraping, dai un’occhiata alle nostre guide sui , su e sui . Puoi anche guardare i tutorial sul .
FAQ
1. Posso scrapare eBay gratuitamente con Python?
Sì. Tutte le librerie (Requests, BeautifulSoup, curl_cffi, pandas) sono gratuite e open source. I costi arrivano con la scala — i proxy residenziali per scraping ad alto volume costano in genere 50–500 $ al mese, a seconda della banda. Per progetti piccoli (qualche centinaio di pagine), puoi lavorare dal tuo IP domestico con un rate limiting attento.
2. Come faccio a scrapare gli articoli venduti e le inserzioni completate di eBay con Python?
Aggiungi LH_Complete=1&LH_Sold=1 ai parametri dell’URL di ricerca. Devono esserci entrambi — LH_Sold=1 da solo, in alcune categorie, riporta in silenzio alle inserzioni attive. Filtra i risultati controllando la classe CSS .POSITIVE sull’elemento prezzo, che indica una vendita reale e non una inserzione scaduta invenduta.
3. eBay blocca il web scraping?
eBay usa Akamai Bot Manager, che rileva gli scraper soprattutto tramite fingerprint TLS e analisi comportamentale. Le chiamate requests standard spesso ricevono risposte 403. Usare curl_cffi con impersonificazione del browser, User-Agent rotanti e ritardi casuali di 3–8 secondi tra le richieste risolve la maggior parte dei blocchi. I proxy residenziali aiutano su scala.
4. Dovrei usare l’API di eBay o lo scraping web?
Usa la Browse API per query stabili, a volume moderato, sulle inserzioni attive (fino a 5.000 chiamate/giorno). Usa lo scraping quando ti servono storico dei prezzi venduti, dati completi delle varianti/MSKU, recensioni o qualsiasi campo che l’API non espone. La Marketplace Insights API in teoria fornisce i dati venduti, ma l’accesso è limitato e .
5. Qual è il modo più semplice per scrapare eBay senza programmare?
La usa l’AI per leggere le pagine eBay, suggerire le colonne dati ed estrarre le inserzioni con un clic. Gestisce la paginazione, l’arricchimento delle sottopagine ed esporta su Google Sheets, Excel, Airtable o Notion. I già pronti lo rendono ancora più veloce per i casi d’uso più comuni.
Scopri di più