Craigslist continua a totalizzare circa su circa 700 siti locali — e non offre ancora una API pubblica. Se vuoi dati strutturati dagli annunci di appartamenti, auto usate, offerte di lavoro o inserzioni per servizi, lo scraping è praticamente l’unica strada.
Il sistema anti-bot personalizzato di Craigslist, però, è spietato. Non usa Cloudflare o DataDome: si affida a un rate limiter basato su nginx, rifinito per oltre dieci anni. Se sbagli approccio, ti ritrovi un secco 403 prima ancora della seconda tazza di caffè. Ho testato a lungo diversi metodi contro le difese di Craigslist e questa guida è il risultato: un tutorial Python aggiornato al 2025, valido per qualsiasi categoria, che copre l’estrazione in JSON-LD (il miglioramento più importante rispetto alle guide datate), strategie realistiche per evitare il ban, il quadro legale e un’alternativa no-code per chi vuole i dati senza scrivere nemmeno una riga di codice.
Cosa significa estrarre Craigslist con Python?
Fare web scraping di Craigslist con Python significa usare script Python per visitare in modo automatico le pagine di Craigslist, estrarre i dati strutturati che ti interessano — titoli, prezzi, descrizioni, immagini, località, date di pubblicazione — e salvarli in un foglio di calcolo, in un database o in un file JSON.
Python è il linguaggio preferito per questo tipo di attività grazie al suo ecosistema di librerie. Con requests, BeautifulSoup, lxml e curl_cffi, puoi costruire uno scraper funzionante per Craigslist in meno di 100 righe. La community è enorme, quindi quando Craigslist cambia qualcosa (e succede), qualcuno ha già trovato la soluzione.
La cosa fondamentale da sapere è questa: Craigslist . L’unica interfaccia programmatica ufficiale è la Bulk Posting Interface (BAPI), che però è solo in scrittura: permette ai inserzionisti approvati e paganti di pubblicare annunci, non di recuperarli. Ogni prodotto che trovi su piattaforme terze e che viene chiamato “Craigslist API” è in realtà uno scraper non ufficiale, non un endpoint autorizzato. Se vuoi dati in massa, devi fare scraping.
Perché estrarre dati da Craigslist? Casi d’uso reali
Craigslist non serve solo a trovare un divano usato. È un dataset enorme, aggiornato continuamente, che copre decine di settori. Ecco chi trae davvero vantaggio dall’estrazione dei dati:
| Caso d'uso | Chi ne beneficia | Cosa estrai |
|---|---|---|
| Monitoraggio prezzi di appartamenti e affitti | Agenti immobiliari, inquilini, aziende PropTech | Prezzo, metri quadrati, camere, quartiere, latitudine/longitudine |
| Analisi del mercato dell’auto usata | Concessionarie, app consumer, ricercatori | Prezzo, marca, modello, anno, chilometraggio, condizioni |
| Ricerca sul mercato del lavoro | Recruiter, economisti del lavoro, analisti HR | Titolo, retribuzione, tipo di contratto, data di pubblicazione |
| Generazione di lead | Team vendite, fornitori di servizi | Contatti, nome dell’attività, area di servizio |
| Pricing competitivo | Fornitori di servizi locali, team e-commerce | Prezzi dei servizi, descrizioni, aree coperte |
L’esempio accademico più citato è il — circa 500.000 annunci di auto usate negli Stati Uniti con 26 variabili, che ha fatto da base a decine di studi, incluso un lavoro su ResearchGate del 2024 sulle dinamiche del mercato dell’auto usata negli USA. Alcuni hedge fund hanno acquistato dati aggregati sugli affitti da Craigslist per studiare l’andamento dei canoni. E i team commerciali estraggono regolarmente le sezioni servizi e gig per generare lead.
Il conto è semplice: 8 ore di copia-incolla manuale contro circa 10 minuti con uno scraper ben fatto.
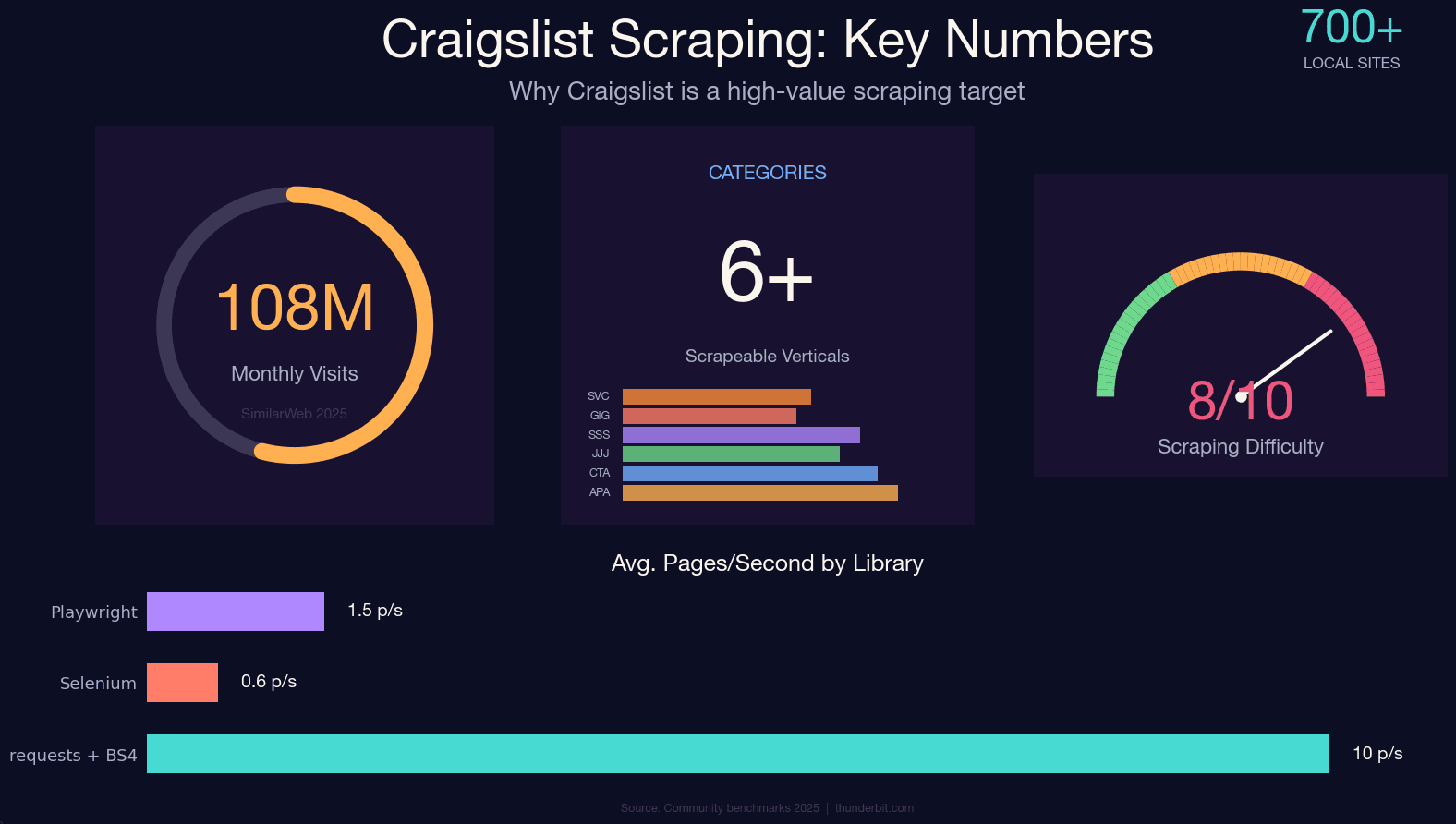
Estrarre Craigslist con Python: tutte le categorie, non solo le auto
Quasi tutte le guide su Craigslist che ho trovato coprono solo le auto in vendita — un po’ come scrivere un tutorial su Google limitandosi alla ricerca immagini. Craigslist ha decine di categorie e i pattern URL cambiano da una all’altra.
La struttura è sempre questa: https://{city}.craigslist.org/search/{category_slug}
Basta cambiare il sottodominio della città e lo slug per passare a un settore completamente diverso. Ecco una tabella di riferimento delle categorie più popolari (verificata ad aprile 2025):
| Categoria | Slug URL | Campi tipici da estrarre |
|---|---|---|
| Appartamenti / Alloggi | /search/apa | Prezzo, mq, camere, posizione, regole per animali |
| Auto e camion | /search/cta | Prezzo, marca, modello, anno, chilometraggio |
| Lavoro | /search/jjj | Titolo, azienda, stipendio, tipo di impiego |
| Servizi | /search/bbb | Titolo, descrizione, numero di telefono, area |
| Gigs | /search/ggg | Titolo, compenso, data, categoria |
| In vendita (generale) | /search/sss | Titolo, prezzo, condizioni, posizione |
Puoi anche combinare parametri di query per filtrare i risultati:
| Parametro | Scopo | Esempio |
|---|---|---|
query | Parola chiave nel testo | ?query=studio |
min_price / max_price | Fascia di prezzo | &min_price=1500&max_price=3000 |
hasPic | Solo annunci con immagini | &hasPic=1 |
postedToday | Ultime 24 ore | &postedToday=1 |
sort | Ordinamento | &sort=priceasc |
s | Offset di paginazione (120 per pagina) | ?s=120 |
Quindi un URL come https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1 ti restituisce gli appartamenti di New York tra 1.500 e 3.000 dollari con foto. Tutti gli script Python di questa guida funzionano su queste categorie: basta cambiare lo slug.
Selettori HTML Craigslist 2025: vecchi e nuovi (e la scorciatoia JSON)
Il motivo numero uno per cui gli scraper di Craigslist si rompono sono i cambiamenti nella struttura HTML. Se stai seguendo un tutorial del 2022 che ti dice di puntare a .result-row o .result-info, il tuo scraper è già fuori gioco.
Craigslist ha riscritto il markup dei risultati di ricerca tra il 2023 e il 2024. I vecchi nomi di classe sono ancora annidati dentro nuovi wrapper, ma se li cerchi nel livello alto del DOM non ottieni nulla. Ecco cosa è cambiato:
| Elemento | Selettore legacy (prima del 2024) | Selettore attuale (2025) |
|---|---|---|
| Contenitore annuncio | .result-info | .cl-search-result |
| Link del titolo | .result-title | .posting-title a |
| Prezzo | .result-price | .priceinfo |
| Metadati (area) | .result-hood | .meta |
Ma ecco la vera svolta — quella che distingue uno scraper davvero attuale nel 2025 da tutti gli altri: non devi affatto fare parsing dell’HTML nei risultati di ricerca.
Craigslist ora incorpora ogni annuncio visibile dentro un tag <script id="ld_searchpage_results"> come dati strutturati JSON-LD. Una singola chiamata requests.get() restituisce l’intero schema.org ItemList con ogni annuncio presente nella pagina — titolo, prezzo, valuta, località, URL dell’immagine, link alla scheda. Nessun rendering JavaScript richiesto. Nessuna fragilità legata ai selettori CSS.
L’approccio JSON-LD è più veloce, più stabile e molto meno soggetto a rotture quando Craigslist ritocca l’interfaccia. È il metodo usato da tutti i repo GitHub attivamente mantenuti, ed è quello che useremo nel tutorial qui sotto.
Un caveat: il blocco JSON-LD è — appartamenti (apa), in vendita (sss), auto (cta), alloggi (hhh). Spesso è assente o ridotto al minimo per lavori (jjj), gigs (ggg), community (ccc) e servizi (bbb), perché questi annunci non hanno pricing basato su schema.org/Offer. In quei casi, bisogna tornare al percorso HTML con .cl-search-result.
Scegliere lo stack Python: Requests + BS4, Selenium o Playwright?
Questa è la domanda che salta fuori in ogni forum di scraping: “Quale libreria dovrei usare?” Per Craigslist, la risposta è più netta che per molti altri siti.
| Fattore | requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|
| Velocità | 5–15 pagine/sec (limitata dalla rete) | 0,3–1 pagine/sec | 0,5–2 pagine/sec |
| Contenuti renderizzati via JS | No | Sì | Sì |
| Memoria | ~30–60 MB | ~400–700 MB | ~300–500 MB |
| Complessità di setup | Bassa | Media | Media |
| Resistenza anti-bot | Bassa (servono header/proxy) | Media (browser reale) | Medio-alta |
| Miglior caso d’uso su Craigslist | Risultati di ricerca (JSON-LD) | Pagine dettaglio con contenuti dinamici | Scraping asincrono su larga scala |
| Curva di apprendimento | Adatta ai principianti | Moderata | Moderata |
Le pagine di Craigslist sono server-rendered. Il blocco JSON-LD è già presente nell’HTML iniziale. Non c’è alcuna sfida JavaScript sul lato lettura. Ogni usa requests + BeautifulSoup oppure Scrapy. Nessuno usa Selenium o Playwright. Non è un caso: un framework di automazione browser aggiunge centinaia di MB di memoria, un rallentamento di 10–100x e una fingerprint più evidente, senza alcun vantaggio reale.
La mia raccomandazione:
- requests + BS4: parti da qui. Si abbina perfettamente all’estrazione JSON-LD e copre il 95% delle esigenze di scraping su Craigslist.
- Selenium: solo se devi interagire con contenuti dinamici su pagine specifiche di dettaglio (cosa rara su Craigslist).
- Playwright: se devi scalare a migliaia di pagine con concorrenza asincrona — ma, a essere onesti, il vero collo di bottiglia è il rate limiter di Craigslist, non la velocità della libreria.
Abbiamo già approfondito il confronto e una panoramica dei in articoli separati, se vuoi l’analisi completa.
L’alternativa no-code: estrarre Craigslist senza scrivere Python
Piccola deviazione prima del codice: questa sezione è per chi non è sviluppatore. Agenti immobiliari, team commerciali, responsabili operations — se ti servono solo i dati e non vuoi scrivere Python, c’è una strada più veloce.
è un AI web scraper che funziona come estensione Chrome. Può estrarre dati da Craigslist in circa 2 clic, senza bisogno di codice. Ecco il flusso:
- Apri qualsiasi pagina dei risultati di ricerca su Craigslist (appartamenti, auto, lavoro — qualsiasi categoria).
- Clicca "AI Suggest Fields" nella sidebar di Thunderbit. L’AI legge la pagina e individua automaticamente le colonne, come titolo dell’annuncio, prezzo, località e link.
- Clicca "Scrape" — i dati vengono estratti in pochi secondi.
- Usa il Subpage Scraping per visitare la pagina di dettaglio di ogni annuncio e arricchire i dati con descrizioni complete, numeri di telefono, immagini e attributi.
- Esporta direttamente in Google Sheets, Excel, Airtable o Notion — completamente gratis.
Per esigenze ricorrenti — ad esempio il monitoraggio quotidiano dei prezzi degli appartamenti o snapshot settimanali degli annunci di lavoro — lo Scheduled Scraper di Thunderbit ti permette di descrivere la pianificazione in linguaggio naturale e lascia che tutto giri in automatico. Niente cron job, niente server da configurare.
Thunderbit gestisce anche le misure anti-bot tramite la modalità Cloud Scraping, quindi non devi preoccuparti di proxy rotanti o header costruiti a mano. Se vuoi provarlo, scarica la e verifica tu stesso.
Se invece vuoi controllo totale e massima personalizzazione, continua a leggere la guida passo passo in Python.
Passo dopo passo: come estrarre Craigslist con Python (tutorial completo)
- Difficoltà: Intermedia
- Tempo richiesto: ~30 minuti (setup + prima estrazione)
- Cosa ti serve: Python 3.8+, browser Chrome (per ispezionare le pagine), un terminale
Passo 1: configura l’ambiente Python
Installa le librerie necessarie:
1pip install requests beautifulsoup4 lxmllxml è opzionale, ma accelera sensibilmente il parsing con BeautifulSoup. Se in seguito incontri problemi di TLS fingerprinting (ne parliamo meglio nella sezione anti-ban), puoi installare anche curl_cffi:
1pip install curl_cffiIl blocco di importazione:
1import requests
2from bs4 import BeautifulSoup
3import json
4import csv
5import time
6import randomA questo punto dovresti avere un ambiente Python pulito con tutte le dipendenze installate.
Passo 2: costruisci l’URL di Craigslist per qualsiasi categoria
Crea dinamicamente l’URL di destinazione usando città + slug della categoria + filtri opzionali:
1from urllib.parse import urlencode
2BASE = "https://{city}.craigslist.org/search/{slug}"
3def build_url(city, slug, **params):
4 return f"{BASE.format(city=city, slug=slug)}?{urlencode(params)}"
5# Esempio: appartamenti a New York, 1500-3000 $, con foto
6url = build_url("newyork", "apa", min_price=1500, max_price=3000, hasPic=1)
7print(url)
8# https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1Sostituisci "apa" con "cta" (auto), "jjj" (lavoro), "bbb" (servizi) o con qualsiasi slug della tabella precedente. Cambia "newyork" con "sfbay", "chicago", "losangeles", ecc.
Passo 3: recupera la pagina ed estrai il JSON incorporato
Invia una richiesta GET con gli header corretti, poi analizza il blocco JSON-LD:
1HEADERS = {
2 "User-Agent": (
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.craigslist.org/",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "same-origin",
14 "Upgrade-Insecure-Requests": "1",
15}
16session = requests.Session()
17r = session.get(url, headers=HEADERS, timeout=20)
18r.raise_for_status()
19soup = BeautifulSoup(r.text, "html.parser")
20tag = soup.select_one("script#ld_searchpage_results")
21data = json.loads(tag.text) if tag else {"itemListElement": []}Se tag è None, il blocco JSON-LD non è presente per quella categoria — passa allora al parsing HTML (vedi la tabella dei selettori sopra). Per appartamenti, auto e categorie in vendita, il blocco JSON-LD è affidabile.
Passo 4: trasforma i dati degli annunci in record strutturati
Scorri gli elementi JSON ed estrai i campi che ti servono:
1listings = []
2for entry in data["itemListElement"]:
3 item = entry["item"]
4 offers = item.get("offers", {}) or {}
5 addr = (offers.get("availableAtOrFrom") or {}).get("address", {})
6 listings.append({
7 "name": item.get("name"),
8 "url": offers.get("url"),
9 "price": offers.get("price"),
10 "currency": offers.get("priceCurrency"),
11 "locality": addr.get("addressLocality"),
12 "region": addr.get("addressRegion"),
13 "image": item.get("image"),
14 })
15print(f"Trovati {len(listings)} annunci")Dovresti vedere qualcosa come “Trovati 120 annunci” (Craigslist mostra 120 risultati per pagina). Alcuni annunci possono avere None come prezzo se chi li ha pubblicati non lo ha inserito — gestiscilo con attenzione nella logica successiva.
Passo 5: estrai le pagine dettaglio per dati più ricchi
I risultati di ricerca forniscono solo informazioni sintetiche. Per descrizioni complete, attributi (camere, mq, regole per animali), coordinate lat/long e immagini, devi visitare la pagina di dettaglio di ogni annuncio.
1def fetch_detail(url, session):
2 r = session.get(url, headers=HEADERS, timeout=20)
3 r.raise_for_status()
4 s = BeautifulSoup(r.text, "html.parser")
5 body = s.select_one("#postingbody")
6 mp = s.select_one("#map")
7 return {
8 "description": body.get_text("\n", strip=True) if body else None,
9 "attributes": [x.get_text(" ", strip=True)
10 for x in s.select("p.attrgroup span, div.attrgroup .attr")],
11 "lat": mp.get("data-latitude") if mp else None,
12 "lng": mp.get("data-longitude") if mp else None,
13 "images": [img["src"] for img in s.select("div.gallery img")],
14 }
15for item in listings:
16 item.update(fetch_detail(item["url"], session))
17 time.sleep(random.uniform(3, 6)) # fondamentale: jitter anti-bantime.sleep(random.uniform(3, 6)) non è facoltativo. Se lo salti, nel giro di poche decine di richieste ti ritroverai un 403. Le pagine dettaglio sono server-rendered e usano selettori stabili (#titletextonly, #postingbody, #map) che non cambiano più o meno dal 2017 — una delle poche cose davvero affidabili su Craigslist.
Passo 6: gestisci la paginazione per estrarre tutti i risultati
Craigslist usa il parametro di offset ?s=120 per la paginazione. Ogni pagina mostra 120 risultati e l’offset massimo è in genere 2999.
1def iter_all(city, slug, max_pages=25, **filters):
2 for page in range(max_pages):
3 offset = page * 120
4 url = build_url(city, slug, s=offset, **filters)
5 r = session.get(url, headers=HEADERS, timeout=20)
6 r.raise_for_status()
7 soup = BeautifulSoup(r.text, "html.parser")
8 tag = soup.select_one("script#ld_searchpage_results")
9 if not tag:
10 break
11 data = json.loads(tag.text)
12 items = data.get("itemListElement", [])
13 if not items:
14 break
15 for entry in items:
16 item = entry["item"]
17 offers = item.get("offers", {}) or {}
18 yield {
19 "name": item.get("name"),
20 "url": offers.get("url"),
21 "price": offers.get("price"),
22 }
23 time.sleep(random.uniform(2.5, 5.0))Non cercare di estrarre migliaia di pagine in rapida successione. Il rate limiter di Craigslist è per IP e la portata sostenibile da un singolo IP si ferma circa a 0,3–0,5 richieste al secondo, indipendentemente dalla libreria usata. Quel limite lo impone Craigslist, non Python.
Passo 7: esporta i dati Craigslist in CSV, JSON o Google Sheets
Salva i risultati:
1# CSV
2with open("craigslist.csv", "w", newline="", encoding="utf-8") as f:
3 w = csv.DictWriter(f, fieldnames=listings[0].keys())
4 w.writeheader()
5 w.writerows(listings)
6# JSON
7with open("craigslist.json", "w", encoding="utf-8") as f:
8 json.dump(listings, f, indent=2, ensure_ascii=False)Se preferisci saltare del tutto il codice di esportazione, Thunderbit offre l’esportazione gratuita direttamente in Google Sheets, Excel, Airtable o Notion dal browser. Ma per pipeline Python, CSV e JSON sono gli output standard. Puoi anche inviare i dati direttamente a pandas per l’analisi o a un database con sqlite3.
Come evitare il ban quando estrai Craigslist con Python
Molti tutorial sorvolano su questa parte. Il sistema anti-bot di Craigslist è costruito su misura, non preso da terze parti, e ha alcune particolarità precise.

Usa header di richiesta realistici
Craigslist verifica l’ordine e la completezza degli header. Una richiesta senza Sec-Fetch-Dest o con un User-Agent obsoleto viene segnalata prima ancora di arrivare al contenuto. L’insieme completo di header stile Chrome 120+ (mostrato al Passo 3) è il minimo indispensabile. Ruota il User-Agent per sessione tra 5–10 stringhe recenti di Chrome/Firefox desktop — ma non cambiarlo a metà sessione, perché sembrerebbe innaturale.
L’assenza degli header Sec-Fetch-* è il motivo più comune per cui gli scraper alle prime armi vengono bloccati subito.
Aggiungi ritardi casuali tra le richieste
Il consenso della community, confermato da (ScrapingBee, Scraperly, Oxylabs, Multilogin), converge su 2–5 secondi casuali tra il recupero delle pagine di ricerca e 3–6 secondi tra le pagine dettaglio. Intervalli fissi sembrano comportamenti da bot. Usa time.sleep(random.uniform(2, 5)) — mai time.sleep(2).
Ruota i proxy se fai scraping su larga scala
Craigslist blocca in anticipo interi intervalli IP di AWS, GCP e Azure. I proxy datacenter spesso sono inutilizzabili fin dall’inizio. Per volumi superiori a poche centinaia di pagine ti servono proxy residenziali rotanti, cambiati ogni 20–30 richieste. I proxy mobile hanno il rischio di rilevamento più basso, ma costano 8–30 $/GB.
| Tipo di proxy | Rischio di rilevamento su Craigslist | Costo (2025) |
|---|---|---|
| Datacenter | Molto alto — spesso bloccato alla prima richiesta | 0,50–2 $/GB |
| Residenziale rotante | Basso — consigliato | 5–15 $/GB |
| Mobile | Il più basso | 8–30 $/GB |
La modalità Cloud Scraping di Thunderbit gestisce automaticamente la rotazione dei proxy, se preferisci non occupartene tu.
Gestisci i CAPTCHA con eleganza
I CAPTCHA su Craigslist sono rari nei flussi di lettura — compaiono soprattutto nei flussi di pubblicazione o risposta. Se ne compare uno: fermati per almeno 60 secondi, cambia IP, svuota i cookie e rallenta. Un CAPTCHA persistente è il segnale che stai andando troppo veloce, non un rompicapo da forzare con un solver.
Rispetta i rate limit e implementa il backoff
Craigslist restituisce 403 (non 429) quando superi il rate limit. Un 403 significa che l’IP corrente è finito in deny list — non riprovare alla cieca. Cambia IP, cambia User-Agent e attendi.
1from requests.adapters import HTTPAdapter
2from urllib3.util.retry import Retry
3retry = Retry(
4 total=5,
5 backoff_factor=1.5, # 1.5, 3, 6, 12, 24s
6 status_forcelist=[429, 500, 502, 503, 504],
7 allowed_methods={"GET"},
8 respect_retry_after_header=True,
9)
10adapter = HTTPAdapter(max_retries=retry)
11session.mount("https://", adapter)Un altro consiglio: i report della community indicano in modo coerente la fascia 2–6 del mattino, ora locale della città target, come la finestra più sicura per lo scraping, con circa il 30–40% di blocchi in meno rispetto alle ore diurne.
Fingerprinting TLS — la trappola nascosta
Il livello bot di Craigslist ispeziona il ClientHello TLS. La libreria Python requests (basata su OpenSSL) ha una fingerprint JA3 che non corrisponde a quella di un browser reale. Un User-Agent perfetto abbinato a una fingerprint TLS non browser è un mismatch rilevabile. La soluzione è usare con impersonate="chrome124", che emula il handshake TLS di Chrome:
1from curl_cffi import requests as cffi_requests
2r = cffi_requests.get(url, headers=HEADERS, impersonate="chrome124")Se ricevi 403 inspiegabili nonostante IP residenziali puliti e header corretti, molto probabilmente il problema è il fingerprinting TLS.
robots.txt, Termini di servizio e scraping etico su Craigslist
Molte guide saltano completamente questo tema o lo liquidano in una riga nelle FAQ. Considerando che Craigslist ha ottenuto una sentenza da contro uno scraper (RadPad, 2017), merita più di una nota a margine.
Cosa dice davvero robots.txt di Craigslist
Il è sorprendentemente breve. Contiene un solo blocco User-agent: * con appena sette percorsi vietati:
1Disallow: /reply
2Disallow: /fb/
3Disallow: /suggest
4Disallow: /flag
5Disallow: /mf
6Disallow: /mailflag
7Disallow: /eafSono tutti endpoint interattivi o mutativi: rispondi, segnala, suggerisci, invia email a un amico. Le pagine degli annunci (/search/..., URL dei singoli post) non sono vietate. Non c’è direttiva Crawl-delay, anche se Craigslist applica comunque un limite tramite blocco IP.
I sottodomini delle città pubblicano anche sitemap — ad esempio https://newyork.craigslist.org/sitemap/index.xml — che rappresentano il percorso ufficialmente individuabile verso gli annunci.
Precedenti legali: le cause che contano
Craigslist v. 3Taps (2013, chiusa nel 2015): 3Taps estraeva annunci da Craigslist e li rivendeva. Quando Craigslist inviò una diffida e bloccò i loro IP, 3Taps aggirò il blocco usando proxy rotanti. Il tribunale stabilì che aggirare i blocchi IP dopo una revoca esplicita equivaleva a operare “senza autorizzazione” ai sensi del CFAA. 3Taps .
Meta v. Bright Data (2024): una sentenza più recente ha stabilito che i termini di servizio di Meta non possono vietare lo scraping, quando si è disconnessi, di dati pubblicamente disponibili. Il tribunale ha ritenuto che uno scraper non autenticato sia “nella stessa posizione di un visitatore”. È la decisione più importante per gli scraper del 2024–2025: se non crei mai un account Craigslist, non effettui mai il login e accedi solo a pagine visibili pubblicamente, i Termini potrebbero non essere applicabili a te come contratto.
Conclusione pratica: il rischio CFAA si riduce in modo significativo dopo Van Buren (2021) e hiQ v. LinkedIn (2022) per le pagine pubblicamente accessibili. Ma restano possibili azioni di diritto statale (trespass-to-chattels, misappropriation) — ed è proprio questo che ha portato sia al patteggiamento 3Taps sia alla sentenza da 60,5 milioni contro RadPad.
Si tratta di informazioni generali, non di consulenza legale. Se fai scraping commerciale di Craigslist, parlane con un avvocato.
Checklist pratica per uno scraping etico
- ✅ Rispetta ogni
Disallowin robots.txt — soprattutto i sette endpoint d’azione - ✅ Stai ampiamente sotto le 1.000 pagine ogni 24 ore per IP (i Termini di Craigslist prevedono oltre quella soglia come danno liquidato)
- ✅ Rimani disconnesso — non creare mai un account Craigslist per fare scraping
- ✅ Non aggirare mai i ban IP con proxy dopo un blocco esplicito (è ciò che ha affondato 3Taps)
- ✅ Inserisci ritardi tra le richieste — almeno 2–5 secondi
- ✅ Non raccogliere contatti personali per spam
- ✅ Non ridistribuire i dati grezzi di Craigslist né presentarli come tua piattaforma
- ✅ Usa i dati per ricerca legittima, analisi o fini personali
- ✅ Preferisci le sitemap pubblicate al crawling brutale quando possibile
- ✅ Rimuovi i dati personali (email, numeri di telefono) in fase di ingestione se li stai archiviando
Abbiamo pubblicato una guida più approfondita sulle se vuoi il quadro completo.
Python o no-code: qual è l’approccio giusto per te?
| Fattore | Python (requests + BS4) | Thunderbit (No-Code) |
|---|---|---|
| Tempo di setup | 30–60 min (installazione, codice) | 2 minuti (installi l’estensione Chrome) |
| Competenza richiesta | Python intermedio | Nessuna |
| Personalizzazione | Controllo totale su logica, campi e flusso | L’AI rileva i campi in automatico; l’utente può modificare |
| Scala | Illimitata (con proxy e scheduling) | Scheduled Scraper per attività ricorrenti |
| Gestione anti-ban | Manuale (header, ritardi, proxy, TLS) | Integrata (Cloud Scraping) |
| Opzioni di export | CSV, JSON (da scrivere tu) | Google Sheets, Excel, Airtable, Notion — gratis |
| Ideale per | Sviluppatori, data scientist, pipeline personalizzate | Team sales, agenti immobiliari, responsabili operations |
Usa Python se ti serve personalizzazione completa, se devi integrarti in una pipeline dati più ampia o se vuoi capire esattamente cosa succede sotto il cofano. Usa se vuoi risultati rapidi senza scrivere o mantenere codice. Entrambi gli approcci sono validi: dipende dal tuo caso d’uso e da dove preferisci passare il tempo, nel terminale o nel browser.
Conclusione
Craigslist è una fonte di dati ricca e aggiornata continuamente, che copre immobili, auto, lavoro, servizi, gigs e molto altro — e senza una API pubblica, lo scraping è l’unico modo per ottenere dati strutturati su larga scala. L’approccio davvero efficace nel 2025 è questo: estrarre il JSON-LD incorporato dai risultati di ricerca (non selettori CSS fragili), usare requests + BeautifulSoup (non Selenium), aggiungere header realistici con i campi Sec-Fetch-*, randomizzare i ritardi e usare proxy residenziali se superi qualche centinaio di pagine.
Il metodo JSON-LD è il miglior salto in avanti rispetto alle guide obsolete. È più veloce, più resistente ai cambi di layout e non richiede alcun rendering JavaScript. Se lo abbini alle strategie anti-ban descritte sopra, eviterai i 403 che bloccano la maggior parte degli scraper.
Se preferisci saltare del tutto il codice, la può estrarre qualsiasi categoria di Craigslist in un paio di clic ed esportare direttamente nel foglio di calcolo o database che preferisci. Se vuoi approfondire, le nostre guide su e spiegano i fondamenti in modo più dettagliato.
FAQ
È legale estrarre dati da Craigslist?
I Termini di utilizzo di Craigslist vietano lo scraping automatizzato e includono una clausola di danni liquidati (0,25 $/pagina oltre 1.000 al giorno). Tuttavia, recenti decisioni dei tribunali — in particolare Meta v. Bright Data (2024) e hiQ v. LinkedIn (2022) — hanno ristretto la responsabilità CFAA per lo scraping, da parte di utenti disconnessi, di dati pubblicamente accessibili. Restano possibili azioni di diritto statale (trespass-to-chattels), soprattutto in caso di ridistribuzione commerciale. Rispetta robots.txt, resta disconnesso, inserisci ritardi e non ridistribuire i dati grezzi. Si tratta di informazioni generali, non di consulenza legale.
Craigslist ha una API pubblica?
No. Craigslist offre solo una Bulk Posting Interface (BAPI) in sola scrittura per inserzionisti approvati e paganti. Non esiste una read API pubblica, né un portale developer, né un livello a consumo per recuperare dati. Ogni prodotto chiamato “Craigslist API” che trovi su piattaforme terze è uno scraper non ufficiale.
Perché il mio scraper per Craigslist continua a rompersi?
Quasi sempre per via di cambiamenti nella struttura HTML. Craigslist ha riscritto il markup dei risultati di ricerca tra il 2023 e il 2024, e le guide che usano selettori legacy come .result-row o .result-info non funzionano più. Passa al metodo JSON-LD incorporato (analizzando script#ld_searchpage_results) per un approccio molto più robusto. Controlla anche che gli header includano i campi Sec-Fetch-* — se mancano, scattano blocchi immediati.
Posso fare scraping di Craigslist senza Python?
Sì. L’estensione Chrome di Thunderbit con AI web scraper funziona su qualsiasi pagina di Craigslist — appartamenti, auto, lavoro, servizi. Clicca “AI Suggest Fields” per rilevare automaticamente le colonne, clicca “Scrape” per estrarre i dati ed esporta gratuitamente in Google Sheets, Excel, Airtable o Notion. Nessuna programmazione, nessun setup, nessuna gestione dei proxy.
Quanto spesso posso fare scraping di Craigslist senza essere bannato?
Con un singolo IP residenziale, la portata sostenibile è circa 0,3–0,5 richieste al secondo, con ritardi casuali di 2–5 secondi tra le pagine. Resta sotto le 1.000 pagine ogni 24 ore per IP per evitare sia i ban sia la soglia dei danni liquidati nei Termini di Craigslist. Fare scraping nelle ore di minor traffico (2–6 del mattino, ora locale della città target) riduce i blocchi di circa il 30–40%. Per volumi maggiori, ruota proxy residenziali ogni 20–30 richieste.
Approfondisci