Sintesi esecutiva
poneva una domanda di policy: quanti dei siti web più visitati al mondo stanno dicendo ai crawler AI cosa possono e non possono fare?
Questo seguito pone la domanda operativa che sta dietro a quella: quanto è affidabile robots.txt come infrastruttura a cui oggi viene chiesto di sostenere quella policy?
La risposta è scomoda. robots.txt funziona ancora perché è pubblico, economico, leggibile dalle macchine e già compreso dai crawler. Ma gli si sta chiedendo molto più di quanto sia stato progettato per fare. Nel 2026, lo stesso file di testo semplice può contenere controlli di crawl per la SEO, sitemap index, estensioni legacy per i motori di ricerca, opt-out per l’addestramento AI, lessico di policy inserito da Cloudflare, riserve di copyright e linguaggio legale pensato per controversie future.
Questo è debito di configurazione.
Il dataset dietro questo report è lo stesso crawl del Tranco Top 10.000 usato nello studio originale sui crawler AI. Dei 10.000 domini, 6.638 hanno restituito un robots.txt leggibile; altri 610 hanno restituito 404, che il protocollo considera un via libera implicito. Questo offre 7.248 siti analizzabili per le decisioni di accesso dei bot e 6.638 file concreti per l’analisi della complessità di configurazione.
Emergono sei risultati principali:
-
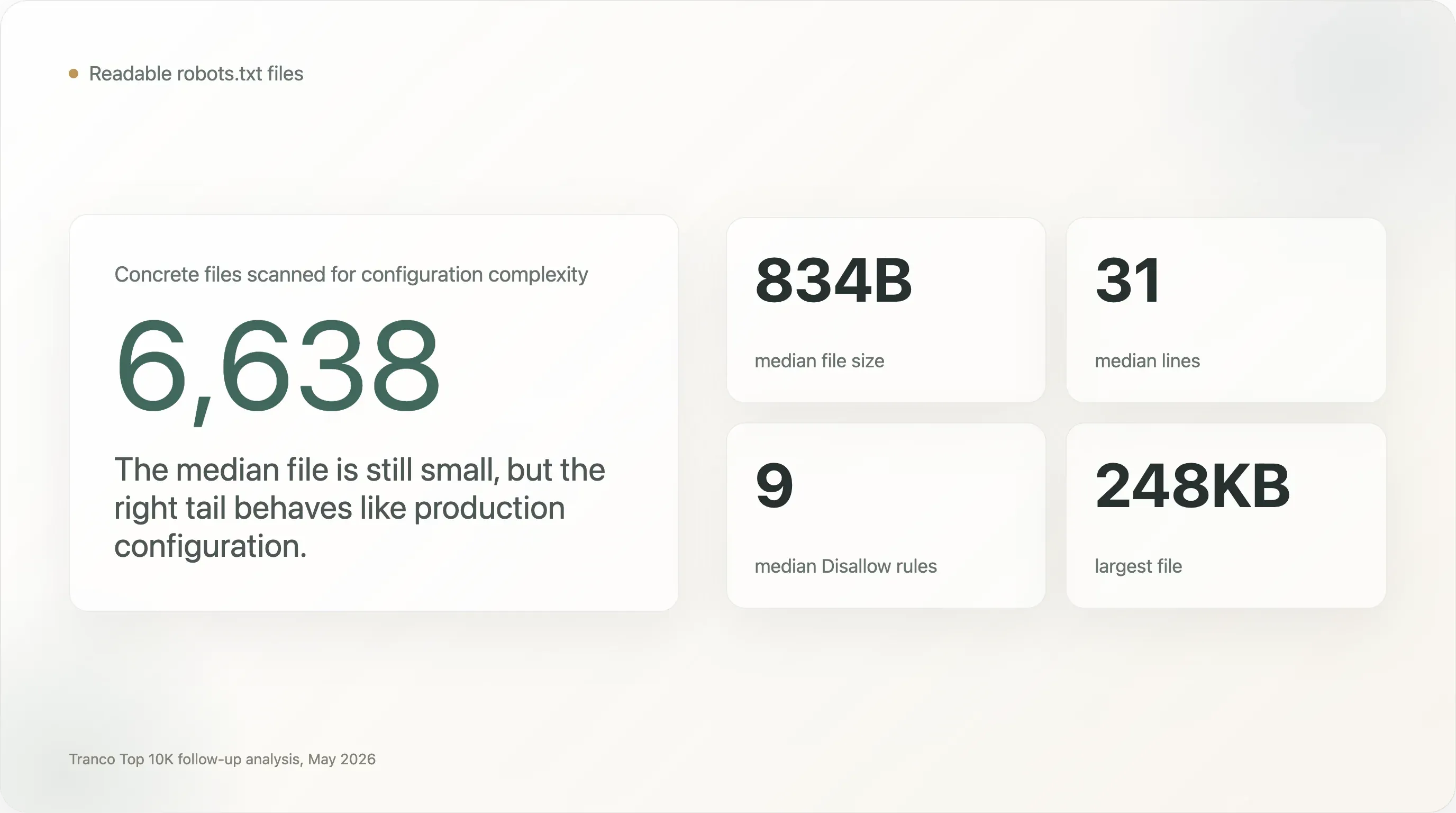
La maggior parte dei file
robots.txtè piccola, ma la coda lunga è estremamente complessa. Il file mediano è di soli 834 byte e 31 righe. Ma 1.005 file sono grandi almeno 5 KB, 273 almeno 20 KB e 28 almeno 100 KB. Il file più grande del campione è di 248 KB. -
Centinaia di siti web di primo livello eseguono file che somigliano più a configurazioni di produzione che a note di policy. Il file mediano ha 9 direttive
Disallow. Ma 707 siti hanno almeno 100 regoleDisallow, 13 ne hanno almeno 1.000, 240 nominano almeno 50 user agent e 110 ne nominano almeno 100. -
La deriva del protocollo non è teorica. Tra i 6.638 file leggibili, 685 contengono
Crawl-delay, 303 contengonoHost, 200 contengonoClean-param, 9 contengonoRequest-rate, 5 contengonoVisit-timee 271 contengono un linguaggio in stile CloudflareContent-Signal. Non fanno tutti parte dello stesso standard pulito. Sono folklore dei crawler accumulato nel tempo. -
Googlebot viene trattato come un cittadino speciale. 562 domini analizzabili bloccano almeno un crawler di ricerca tradizionale. In 404 di quei casi, Googlebot è consentito mentre almeno un altro crawler di ricerca è bloccato. La discriminazione tra crawler AI non è emersa in un ecosistema neutrale;
robots.txtcodificava già una gerarchia dei motori di ricerca. -
La policy AI rende il debito più visibile. 1.377 file leggibili contengono linguaggio di policy AI; 719 contengono copyright, termini, licenze o linguaggio di riserva dei diritti; e 501 contengono entrambi. Il file è diventato sia interfaccia per le macchine sia documento legale. È utile, ma fragile.
-
I file più rischiosi non sono sempre i file più anti-AI. Ecommerce, viaggi, social, finanza, accademia e news producono tutti file complessi per motivi diversi: controllo del budget di crawl, percorsi legacy, contenuti generati dagli utenti, riserve di diritti ed eccezioni specifiche per i bot. Le regole AI si stanno stratificando sopra una base già disordinata.
La conclusione principale: robots.txt resta la superficie di policy per crawler più importante del web pubblico, ma è una base debole per una governance AI ad alto rischio, a meno che l’ecosistema non standardizzi identità dei crawler, lessico d’uso dell’AI e auditabilità delle policy.
Metodologia
Questo report riutilizza il dataset dell’analisi originale di Thunderbit sulla policy dei crawler AI sui domini Tranco Top 10.000.
I materiali di input erano:
tranco_top10k.csv— l’elenco originale dei 10K domini Tranco.out/fetch_meta.csv— stato del fetch, conteggio byte, schema, esito del redirect e metadati degli errori.out/sites.csv— dominio, posizione in classifica, categoria, lingua e stato dirobots.txt.out/site_meta.csv— una riga analitica per sito, inclusa classe di template, flag di blocco AI, dimensione del file e campi riepilogativi della policy bot.out/bot_status.csv— una riga per dominio e crawler, inclusi se quel bot è bloccato e se esiste una regola specifica.raw_robots/— corpirobots.txtmemorizzati nella cache per i 6.638 siti che hanno restituito stato200.
Per questo seguito, ogni file robots.txt leggibile è stato analizzato per:
- dimensione del file e numero di righe;
- righe attive non commentate;
- conteggi di direttive
User-agent,Disallow,AlloweSitemap; - direttive legacy o non core come
Crawl-delay,Host,Clean-param,Request-rateeVisit-time; - lessico dell’era AI, inclusi
Content-Signal,llms.txt, AI, LLM, machine learning, TDM e2019/790; - lessico legale come copyright, termini di servizio, licenze, permessi e linguaggio di riserva dei diritti;
- trattamento dei crawler di ricerca per Googlebot, Bingbot, DuckDuckBot, Slurp, Baiduspider e YandexBot.
Il report definisce inoltre un semplice punteggio di debito di configurazione per la prioritizzazione. Combina dimensione del file, conteggio degli user agent, conteggio di Disallow, conteggio di Allow, numero di direttive non standard e miscela di policy AI e linguaggio legale. Il punteggio non vuole essere una misura universale di correttezza. È un modo per individuare i file che probabilmente saranno difficili da mantenere, rivedere o interpretare.
Tutte le tabelle e i grafici derivati sono inclusi nella cartella di consegna.
Risultato 1: Il file mediano è semplice; la coda no
Il tipico file robots.txt sul web più visitato è ancora piccolo.
Tra i 6.638 file leggibili:
| Metrica | Mediana | P90 | P95 | P99 | Massimo |
|---|---|---|---|---|---|
| Dimensione file | 834 byte | 6,7 KB | 15,8 KB | 76,0 KB | 248,3 KB |
| Righe | 31 | 238 | 332 | 1.008 | 4.998 |
| Righe attive | 23 | 198 | 282 | 837 | 4.998 |
Direttive User-agent | 1 | 21 | 39 | 137 | 823 |
Direttive Disallow | 9 | 103 | 176 | 422 | 4.997 |
Direttive Allow | 1 | 17 | 33 | 69 | 890 |
Questa distribuzione conta perché robots.txt viene spesso descritto come se fosse una piccola dichiarazione:
1User-agent: *
2Disallow: /private/Questo modello mentale è sbagliato per una parte significativa del web ad alto traffico.
In questo dataset:
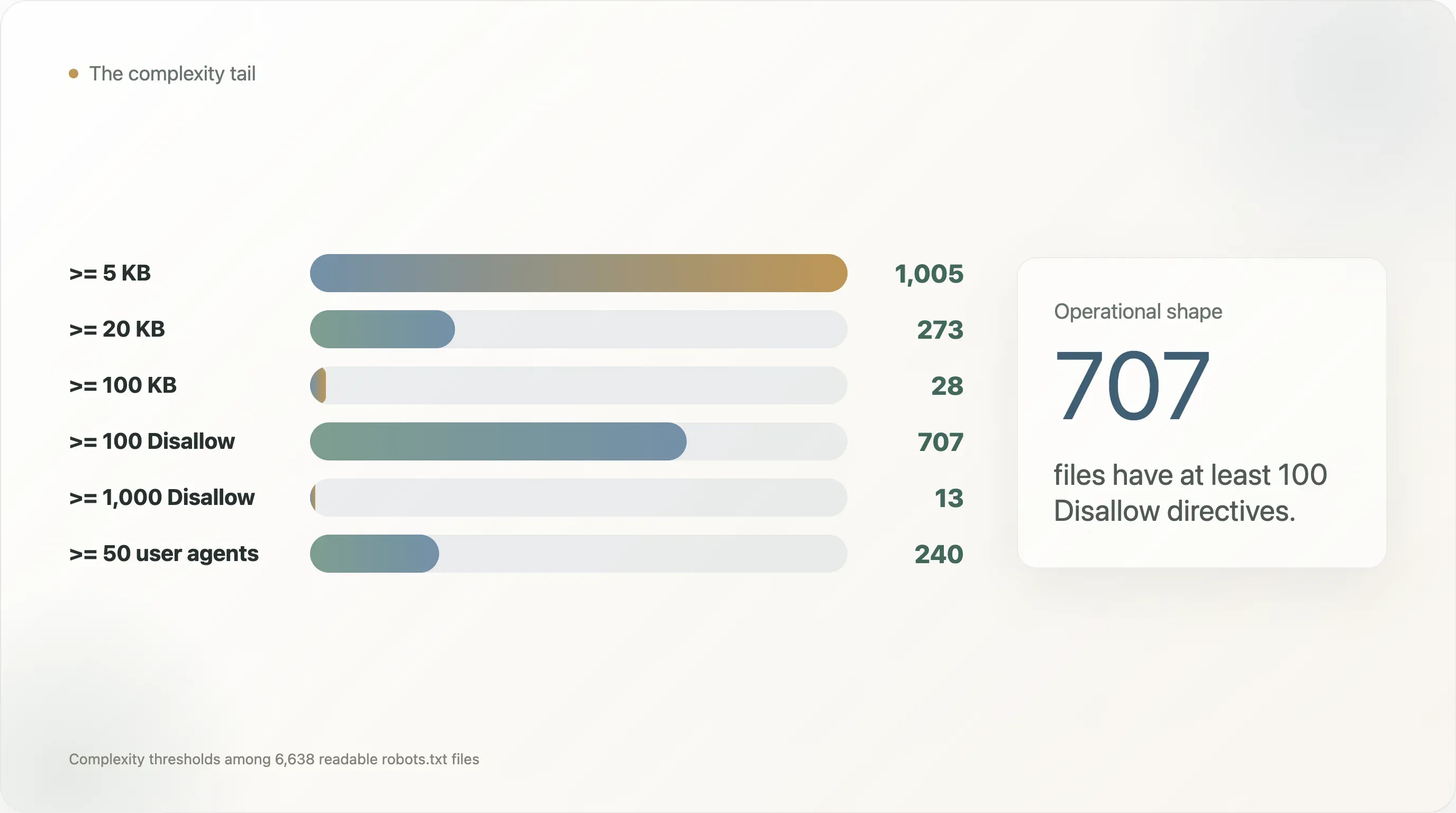
| Soglia di complessità | Siti |
|---|---|
robots.txt maggiore o uguale a 5 KB | 1.005 |
| Maggiore o uguale a 20 KB | 273 |
| Maggiore o uguale a 100 KB | 28 |
Almeno 50 direttive User-agent | 240 |
Almeno 100 direttive User-agent | 110 |
Almeno 100 direttive Disallow | 707 |
Almeno 1.000 direttive Disallow | 13 |
Almeno 100 direttive Allow | 40 |
I file più grandi e più complessi non sono curiosità accademiche. Appartengono a proprietà reali e molto trafficate:
| Dominio | Posizione | Categoria | Byte | User-agent | Disallow | Allow |
|---|---|---|---|---|---|---|
linkedin.com | 17 | social | 114.341 | 76 | 4.184 | 281 |
runescape.com | 5.226 | unknown | 113.393 | 1 | 4.997 | 0 |
academia.edu | 832 | academia | 57.384 | 63 | 2.044 | 227 |
etsy.com | 286 | ecommerce | 51.320 | 3 | 1.621 | 120 |
thepaper.cn | 9.395 | news | 56.867 | 1 | 1.496 | 0 |
opentable.com | 4.137 | unknown | 70.494 | 32 | 1.683 | 176 |
alfabank.ru | 2.625 | finance | 73.158 | 2 | 1.566 | 133 |
Questi file somigliano più a tabelle di routing di produzione che a slogan di policy. Codificano anni di lanci di prodotto, percorsi legacy, pattern di parametri bloccati, eccezioni per crawler, esperimenti SEO, decisioni CDN e ora regole per i crawler AI.
La coda lunga non è solo una storia sull’AI. Dei 273 file da almeno 20 KB, 131 contengono linguaggio di policy AI e 142 no. Dei 707 file con almeno 100 direttive Disallow, solo 207 contengono linguaggio di policy AI. In altre parole, l’AI non ha creato il problema dei file grandi. È arrivata dopo anni di normale operatività web che avevano già riempito il file di regole di percorso, riferimenti a sitemap ed eccezioni per i crawler.
Questo è importante perché la manutenibilità dipende dalla forma, non solo dall’intento. Un file piccolo con un blocco AI diretto può essere facile da verificare. Un file ecommerce o travel da 70 KB può essere difficile da verificare anche se non dice nulla sull’AI. Il rischio non è che ogni file grande sia sbagliato. Il rischio è che la policy effettiva diventi troppo difficile da controllare per chi ne è responsabile.
Il rischio operativo è semplice: man mano che robots.txt cresce, diventa più difficile per un publisher, un ingegnere di piattaforma, un avvocato o un responsabile SEO rispondere alla domanda di base: che cosa consente davvero questo file?
Quella domanda non è più banale. Con un parsing in stile RFC, un crawler può corrispondere a un gruppo di user agent più specifico invece di User-agent: *; corrispondenze di percorso più lunghe possono sovrascrivere quelle più corte; le direttive Allow e Disallow interagiscono per precedenza; e regole generiche di divieto totale possono catturare per errore nuovi crawler che non esistevano quando il file è stato scritto.
Per un file da 30 righe, una persona può ragionarci sopra. Per un file da 4.000 righe con dozzine di bot nominati, nessuno dovrebbe.
Risultato 2: robots.txt sta gestendo più di semplici regole di crawl
Il dibattito sui crawler AI ha reso robots.txt politicamente visibile, ma il file sottostante stava già accumulando responsabilità non correlate.
Un moderno robots.txt di un sito di primo piano può includere:
- controlli dei percorsi per i crawler;
- scoperta delle sitemap;
- estensioni specifiche per i motori di ricerca;
- suggerimenti sul ritmo di crawl;
- suggerimenti di canonicalizzazione dell’host;
- suggerimenti di pulizia dei parametri URL;
- lessico di policy inserito dal CDN;
- testo di riserva del copyright;
- opt-out per l’addestramento AI;
- commenti legali leggibili dagli esseri umani.
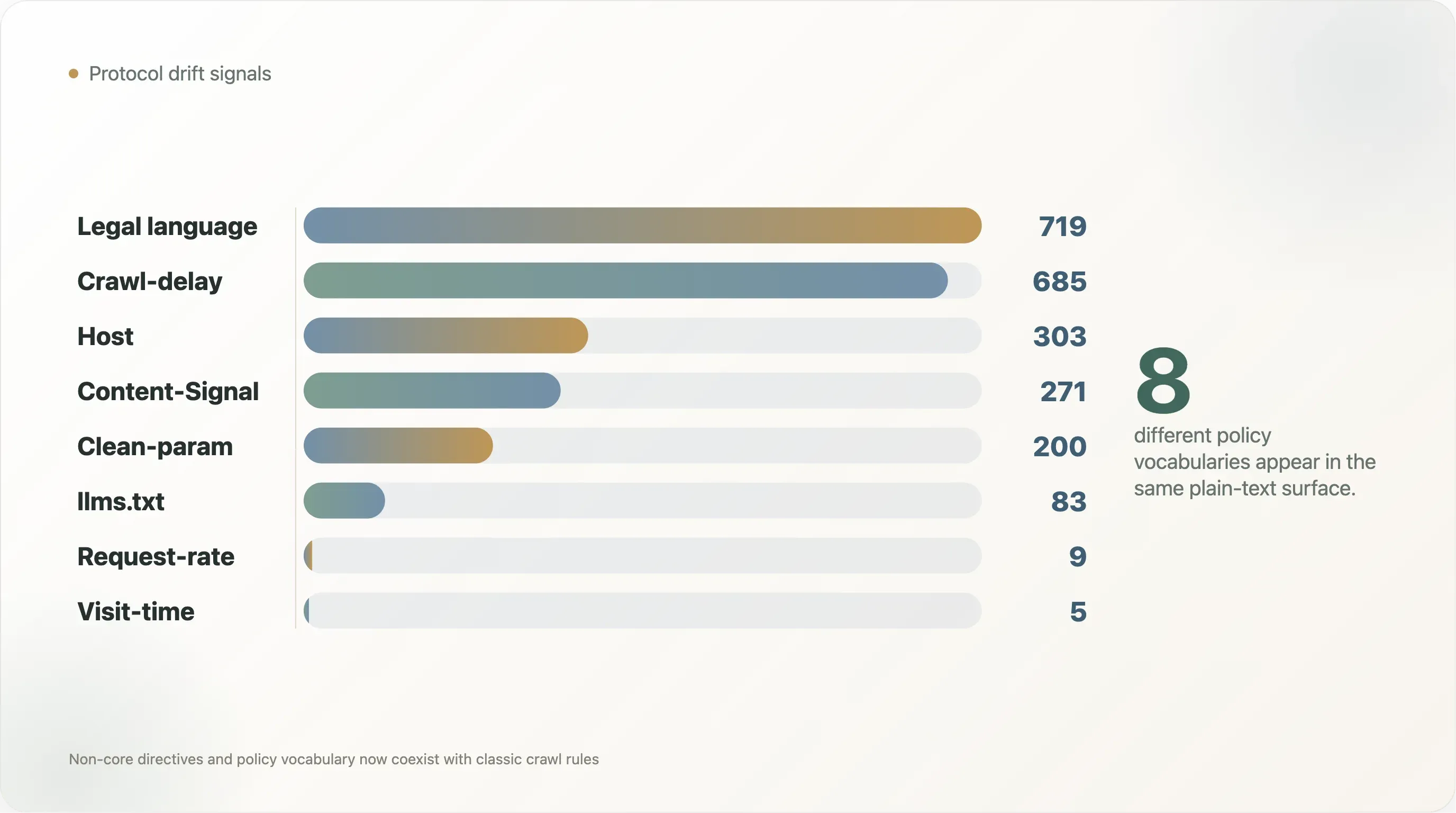
Il dataset mostra chiaramente questo stratificarsi.
| Segnale | File | Quota dei file leggibili |
|---|---|---|
Crawl-delay | 685 | 10,3% |
Host | 303 | 4,6% |
Clean-param | 200 | 3,0% |
Content-Signal | 271 | 4,1% |
Request-rate | 9 | 0,1% |
Visit-time | 5 | 0,1% |
Menzione di llms.txt | 83 | 1,3% |
| Linguaggio di copyright, termini, licenze o permessi | 719 | 10,8% |
| Linguaggio di policy AI | 1.377 | 20,7% |
Alcune di queste direttive sono ampiamente riconosciute da crawler specifici. Alcune sono convenzioni legacy. Alcune sono specifiche di un vendor. Alcune non sono davvero direttive per crawler, ma linguaggio legale o di prodotto inserito nei commenti.
Questo è ciò che assomiglia alla deriva del protocollo.
Crawl-delay è un buon esempio. È familiare a molti operatori di siti, ma il supporto è disomogeneo tra i principali crawler. Host e Clean-param sono stati storicamente associati al comportamento di Yandex. Content-Signal fa parte del vocabolario di policy dell’era AI di Cloudflare. llms.txt è un formato di scoperta adiacente proposto, non uno standard universalmente rispettato. Eppure tutti questi elementi compaiono nello stesso tipo di file, spesso accanto alle classiche regole User-agent e Disallow.
I numeri mostrano anche come le convenzioni vecchie e nuove coesistano ora. Crawl-delay appare in 685 file, più del doppio rispetto ai 271 file con Content-Signal. Host appare in 303 file e Clean-param in 200, riflettendo in gran parte convenzioni dell’era dei motori di ricerca. llms.txt, nonostante si parli molto di esso nei circoli dell’AI search, è menzionato solo in 83 file leggibili. Il web reale non sta convergendo su un unico vocabolario. Sta impilando vocabolari.
Il problema non è che una singola estensione sia sbagliata. Il problema è che il file è diventato un contenitore non versionato per diversi sistemi di governance sovrapposti.
Questo crea tre tipi di debito:
- Debito semantico. Crawler diversi possono interpretare lo stesso file in modo diverso.
- Debito di ownership. I team SEO, legale, infrastruttura, sicurezza e prodotto possono tutti avere motivi per modificare il file, ma nessun singolo team può essere proprietario dell’intera policy.
- Debito di audit. Un sito può pubblicare una policy che sembra intenzionale mentre solo un parser può determinarne il comportamento effettivo.
L’AI rende tutto questo più importante perché le poste in gioco sono cambiate. Quando un suggerimento legacy sul ritmo di crawl viene ignorato, il risultato può essere traffico extra. Quando un opt-out per l’addestramento AI è ambiguo, il risultato può diventare una prova in una controversia su copyright o licenze.
Risultato 3: Il file è diventato sia interfaccia macchina sia artefatto legale
Il report originale sui crawler AI mostrava che il 17,0% dei siti analizzabili aveva scritto regole esplicite specifiche per l’AI. Questo seguito esamina il peso testuale che tali policy aggiungono.
Tra i 6.638 file robots.txt leggibili:
- 1.377 contengono linguaggio di policy AI;
- 719 contengono copyright, termini, licenze, diritti o linguaggio di permesso;
- 271 contengono
Content-Signal; - 83 menzionano
llms.txt.
La sovrapposizione è dove la storia diventa più interessante:
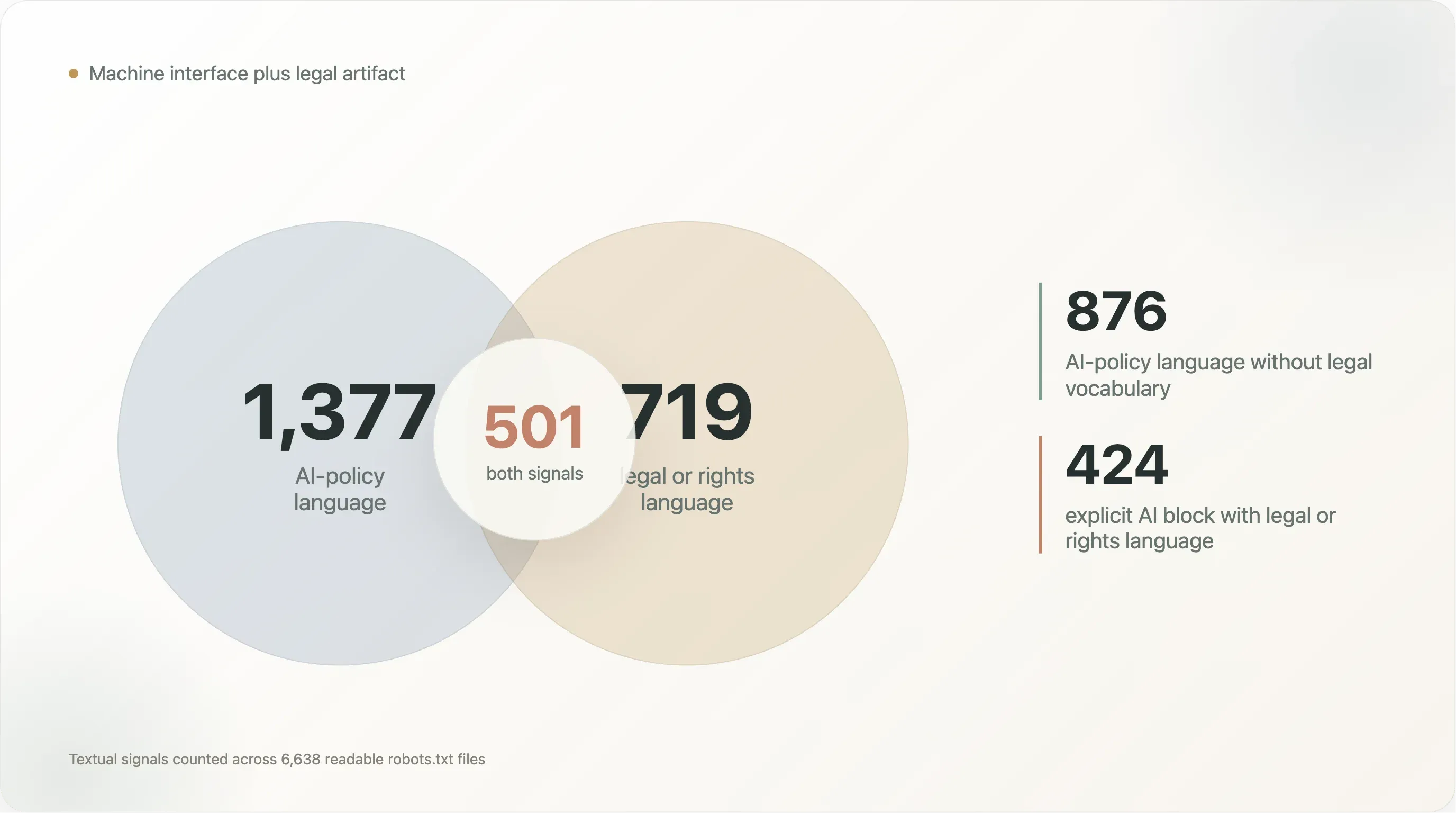
| Schema testuale | File |
|---|---|
| Linguaggio di policy AI e linguaggio legale/di diritti | 501 |
| Linguaggio di policy AI senza linguaggio legale/di diritti | 876 |
| Linguaggio legale/di diritti senza linguaggio di policy AI | 218 |
Content-Signal con linguaggio legale/di diritti | 242 |
| Blocco AI esplicito con linguaggio legale/di diritti | 424 |
Questo è un nuovo tipo di file.
Un file robots.txt tradizionale è indirizzato ai crawler. Un file robots.txt con preambolo legale è indirizzato ad almeno quattro pubblici contemporaneamente:
- operatori di crawler, che hanno bisogno di direttive leggibili dalle macchine;
- vendor di ricerca e AI, che hanno bisogno di segnali di policy;
- avvocati, che vogliono una riserva esplicita dei diritti;
- futuri auditor, tribunali o giornalisti, che possono leggere i commenti come prova dell’intento.
Questo design multi-pubblico spiega perché alcuni file ora sembrano documenti di policy. Ma indebolisce anche la separazione netta tra ciò che un crawler può analizzare e ciò che un avvocato vuole dichiarare.
Gli 876 file con linguaggio di policy AI ma senza lessico legale sono per lo più file di policy macchina: nomi di bot, blocchi Disallow e linguaggio da template. I 501 file con linguaggio sia AI sia legale sono diversi. Cercano di essere allo stesso tempo istruzioni per i crawler e riserve di diritti. I 218 file con linguaggio legale ma senza lessico AI mostrano che questo schema non è iniziato con gli LLM; robots.txt era già usato come luogo in cui indicare termini, confini di permesso e rivendicazioni di diritti.
Per esempio, un commento può dire che il machine learning è vietato, mentre il blocco di direttive effettivo può solo disalloware un sottoinsieme di user agent noti. Un sito può rivendicare diritti in modo globale ma nominare solo alcuni crawler. Un template CDN può iniettare lessico legato all’AI in un file il cui operatore non ha mai scritto a mano il linguaggio legale. Un sito può scrivere una regola ampia User-agent: * che blocca involontariamente i crawler futuri.
Dal punto di vista della governance, robots.txt è diventato attraente proprio perché è pubblico e leggibile dalle macchine. Ma più policy contiene, più ne emergono i limiti:
- non c’è un livello di autenticazione che provi che una policy specifica sia stata revisionata dal titolare dei diritti e non ereditata dall’infrastruttura;
- non c’è una cronologia nativa delle versioni;
- non c’è un campo strutturato per l’uso previsto, come training, retrieval, indicizzazione, caching o valutazione del modello;
- non esiste un registro universale delle identità dei crawler AI;
- non esiste un meccanismo di enforcement.
Questo non rende il file inutile. Lo rende fragile.
L’interpretazione migliore è che robots.txt stia diventando un livello di notifica: una dichiarazione pubblica e verificabile di preferenza e intento. Non è, da solo, un sistema completo di gestione dei diritti.
Risultato 4: La ricerca era già diseguale prima che arrivasse l’AI
Uno dei risultati più forti del report originale era che molti publisher distinguono tra crawler di addestramento AI e crawler di ricerca. Bloccano CCBot, GPTBot o Google-Extended preservando però la visibilità nella ricerca Google.
Questo seguito aggiunge un punto diverso: anche i crawler di ricerca tradizionali non vengono trattati allo stesso modo.
Abbiamo verificato sei crawler di ricerca:
- Googlebot;
- Bingbot;
- DuckDuckBot;
- Slurp;
- Baiduspider;
- YandexBot.
Tra i 7.248 siti analizzabili:
| Trattamento dei crawler di ricerca | Siti |
|---|---|
| Blocca almeno un crawler di ricerca | 562 |
| Consente Googlebot ma blocca almeno un altro crawler di ricerca | 404 |
| Blocca tutti e sei i crawler di ricerca verificati | 152 |
I conteggi dei bot bloccati non sono distribuiti in modo uniforme:
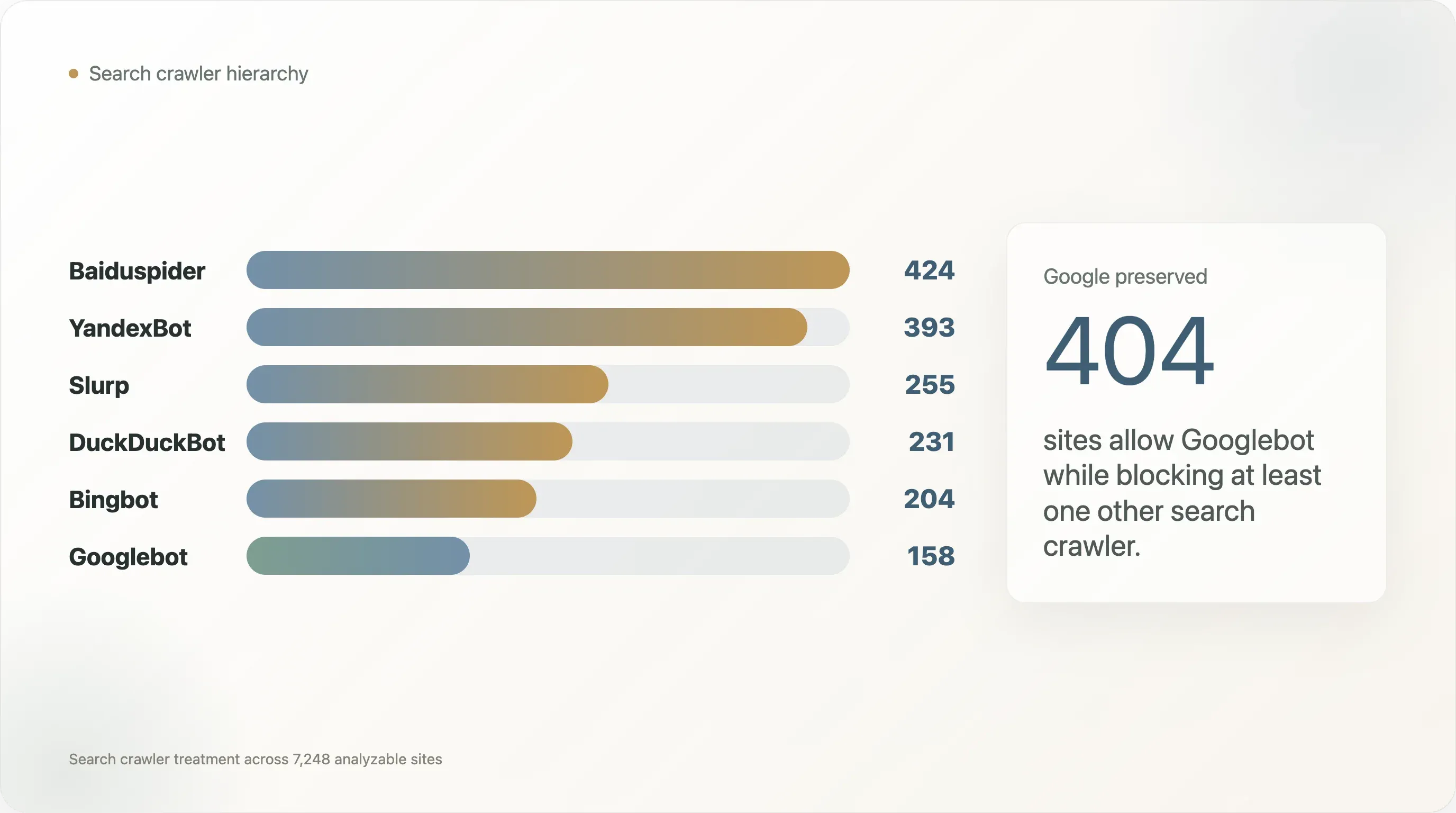
| Crawler di ricerca | Siti che lo bloccano |
|---|---|
| Baiduspider | 424 |
| YandexBot | 393 |
| Slurp | 255 |
| DuckDuckBot | 231 |
| Bingbot | 204 |
| Googlebot | 158 |
Googlebot è il crawler meno bloccato in questo set. Baiduspider e YandexBot vengono bloccati molto più spesso e, nella maggior parte di quei casi, Googlebot rimane consentito. Tra i 404 siti che consentono Googlebot mentre bloccano un altro crawler di ricerca, 269 bloccano Baiduspider e 240 bloccano YandexBot.
Gli esempi sono di alto profilo:
| Dominio | Crawler di ricerca bloccati mentre Googlebot è consentito |
|---|---|
facebook.com | Baiduspider, YandexBot |
apple.com | Baiduspider |
twitter.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
netflix.com | DuckDuckBot, Slurp |
x.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
tiktok.com | Baiduspider |
baidu.com | Bingbot, DuckDuckBot, Slurp, YandexBot |
washingtonpost.com | YandexBot |
wsj.com | YandexBot |
bilibili.com | DuckDuckBot, Slurp, YandexBot |
temu.com | Slurp |
t-mobile.com | Baiduspider, YandexBot |
Questo è rilevante per il dibattito sull’AI perché mostra che robots.txt non era un protocollo neutrale di accesso universale nemmeno prima dell’arrivo dei crawler LLM. Il web pubblico aveva già una gerarchia:
- Googlebot viene spesso preservato perché il traffico da Google Search è troppo prezioso per rischiare.
- I crawler regionali o concorrenti sono più facili da bloccare.
- Alcuni siti trattano l’accesso dei crawler di ricerca come una decisione per mercato o per vendor.
I crawler AI sono entrati in un ecosistema in cui l’accesso differenziato era già la norma.
Questo rende più facile capire la transizione di policy. Un publisher che scrive "blocca Google-Extended, consenti Googlebot" non sta inventando una nuova forma di discriminazione. Sta applicando un vecchio schema a una nuova classe di crawler: preservare la distribuzione, limitare l’estrazione.
La domanda irrisolta è se questo vecchio schema possa scalare. Con la ricerca, c’erano solo pochi crawler economicamente importanti. Con l’AI, l’identità dei crawler è frammentata tra vendor di modelli, bot di retrieval, broker di dati, crawler accademici, agenti browser sintetici e fetcher a livello infrastrutturale. Il numero di user agent nominati continuerà a crescere a meno che l’ecosistema non si consolidi attorno a un insieme più ridotto di segnali basati sullo scopo.
È così che il debito di configurazione si accumula.
Risultato 5: La complessità varia per settore, ma non come i tassi di blocco AI
Il report originale mostrava una forte variazione settoriale nel blocco AI: le news bloccano a tassi elevati; telecom, governo e SaaS bloccano a tassi bassi.
La complessità di configurazione taglia il web in modo diverso.
Tra le categorie selezionate con abbastanza file robots.txt leggibili per un confronto utile:
| Categoria | n | Byte medi | Byte P90 | Disallow mediano | Disallow P90 | User-agent mediano | User-agent P90 |
|---|---|---|---|---|---|---|---|
| ecommerce | 215 | 1.738 | 10.388 | 37 | 164 | 3 | 49 |
| travel | 63 | 2.074 | 27.368 | 41 | 779 | 5 | 34 |
| news | 647 | 1.534 | 7.039 | 19 | 114 | 6 | 68 |
| finance | 121 | 1.002 | 8.337 | 17 | 132 | 2 | 23 |
| academia | 253 | 839 | 3.959 | 14 | 75 | 1 | 11 |
| government | 151 | 1.227 | 3.263 | 13 | 46 | 1 | 4 |
| SaaS | 368 | 485 | 12.606 | 4 | 56 | 1 | 10 |
| dev tools | 119 | 273 | 9.255 | 3 | 58 | 1 | 10 |
P90 Disallow by category chart here<<<<<<<<<<<<<<<<<<<<<<<<<
Le news sono politicamente complesse perché scrivono regole AI esplicite e testo legale. Ma ecommerce e travel sono operativamente complesse perché hanno cataloghi vasti, navigazione a faccette, pagine dei risultati di ricerca, filtri, percorsi per account utente e URL parametrizzati.
Questa distinzione è importante.
Il travel è l’esempio più chiaro. Ha solo 63 file leggibili in questo sottoinsieme di categoria, ma il suo robots.txt P90 è di 27,4 KB e il suo conteggio P90 di Disallow è 779, molto più alto delle news. Questo non significa che i siti travel abbiano una policy AI più sviluppata. Significa che i siti travel hanno più superfici su cui gli operatori dei crawler possono sprecare budget per errore: ricerche per date, pagine di disponibilità, paginazione delle recensioni, flussi di prenotazione, combinazioni di filtri e percorsi di inventario localizzati.
SaaS è il tipo opposto di sorpresa. Il suo file mediano è di soli 485 byte, ma il file P90 sale a 12,6 KB. La maggior parte dei siti SaaS è aperta e leggera; un sottoinsieme più piccolo porta con sé file di controllo dei percorsi molto lunghi, spesso perché documentazione, aree di login, route dell’app e pagine marketing convivono sotto lo stesso dominio.
Le news stanno nel mezzo sul piano operativo ma in cima sul piano politico. Il loro conteggio P90 di User-agent è 68, più alto di ecommerce, travel, finance, academia, government, SaaS e dev tools in questa tabella. È un segnale di policy specifica per bot, non solo di igiene dei percorsi.
Il robots.txt di un publisher può essere complesso per ragioni di policy sui diritti. Il file di un marketplace può essere complesso per la gestione del budget di crawl. Il file di un’università può essere complesso perché migliaia di percorsi legacy si sono accumulati sotto un unico dominio. Il file di una piattaforma social può essere complesso perché deve esporre alcune superfici e sopprimerne altre su scala enorme.
La policy AI si stratifica sopra tutto questo. Non sostituisce le ragioni esistenti per cui un file è complesso.
Questo aiuta a spiegare perché la governance di robots.txt nell’era AI non può essere risolta con una blocklist universale. I file sottostanti hanno lavori diversi:
- i siti ecommerce gestiscono percorsi duplicati e superfici di inventario;
- i siti travel gestiscono listing, calendari, recensioni e pagine di ricerca dinamiche;
- i siti news gestiscono copyright, archivi e postura di licenza;
- i siti SaaS e dev tools spesso vogliono visibilità AI;
- i governi spesso hanno bisogno di accesso pubblico ma possono comunque avere sistemi sensibili da escludere;
- le piattaforme social gestiscono contenuti generati dagli utenti, superfici di profilo e problemi di abuso.
La stessa regola per crawler AI significa cose diverse in ciascun ambiente.
Risultato 6: Un indice di debito di configurazione identifica il rischio di revisione, non il fallimento morale
Questa analisi ha creato un semplice punteggio di debito di configurazione per individuare i file robots.txt che probabilmente saranno difficili da rivedere.
Il punteggio pesa:
- dimensione del file;
- numero di direttive
User-agent; - numero di direttive
Disallow; - numero di direttive
Allow; - numero di direttive non core;
- presenza di linguaggio di policy AI;
- miscela di blocco AI esplicito e linguaggio legale o di copyright.
Non è un punteggio di correttezza. Un file ad alta complessità può essere perfettamente intenzionale. Un file a bassa complessità può comunque essere sbagliato. L’obiettivo è la prioritizzazione: se un file è grande, ricco di policy, specifico per bot e pieno di eccezioni, merita una disciplina di revisione più forte.
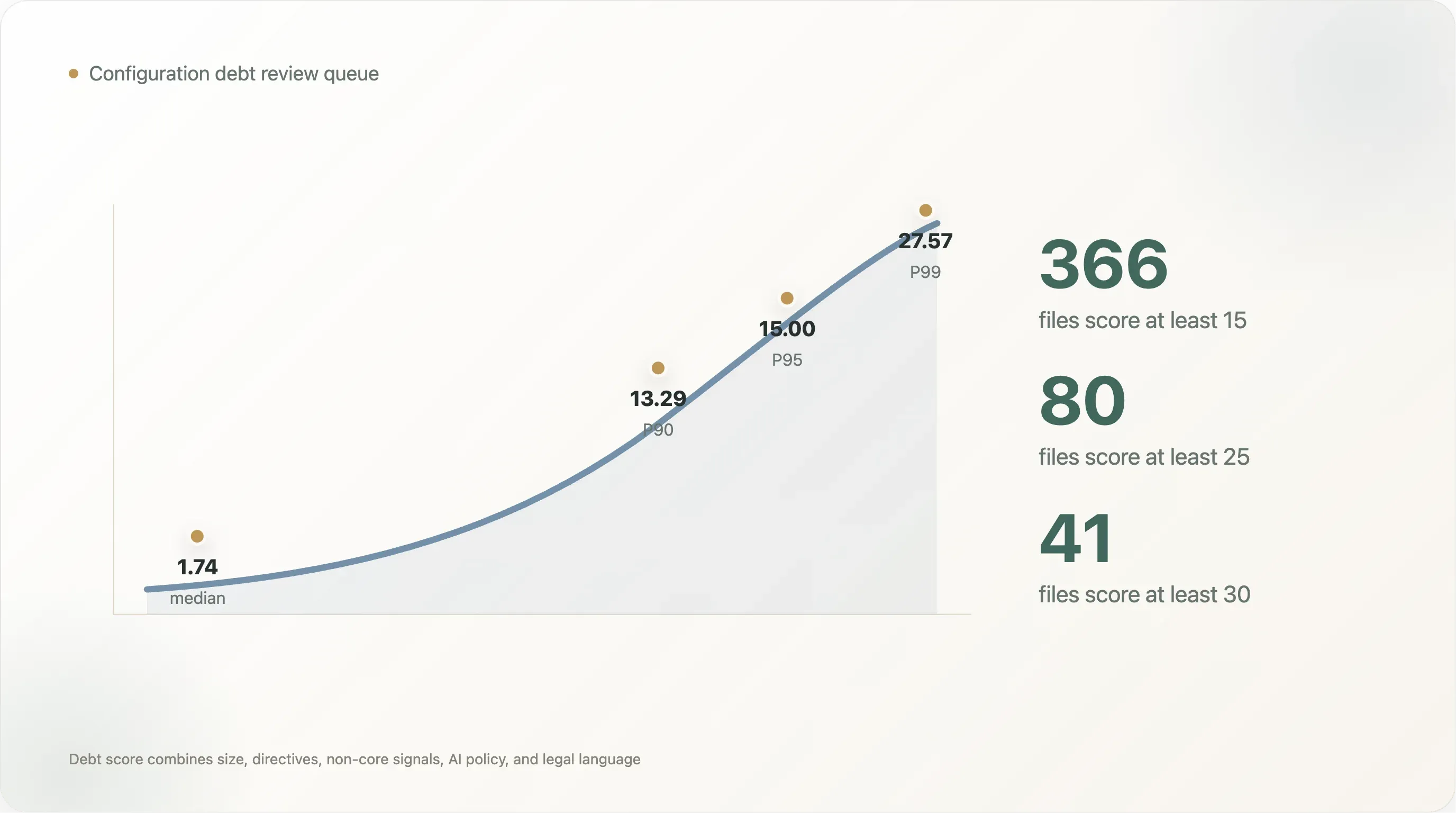
La distribuzione del punteggio è ripida. Il file leggibile mediano ottiene 1,74. Il P90 è 13,29, il P95 è 15,00 e il P99 è 27,57. Solo 366 file raggiungono almeno 15, 80 raggiungono almeno 25 e 41 raggiungono almeno 30. Questa è la coda pratica di revisione: non tutti i siti hanno bisogno di un progetto di governance, ma la parte alta della distribuzione sì.
Anche la vista per categoria mostra perché un’etichetta unica "blocco AI" sia troppo piatta:
| Categoria | Punteggio mediano | Punteggio P90 |
|---|---|---|
| travel | 4,92 | 28,94 |
| search | 2,97 | 24,23 |
| social | 2,25 | 15,00 |
| news | 4,91 | 14,92 |
| finance | 1,67 | 12,61 |
| SaaS | 0,98 | 11,85 |
| ecommerce | 3,88 | 10,87 |
| government | 1,57 | 6,38 |
Travel e search hanno i punteggi P90 più alti perché una minoranza di file diventa molto grande e molto carica di regole. Le news hanno uno dei punteggi mediani più alti perché il linguaggio di policy e il trattamento specifico dei bot sono più comuni nell’intera categoria. Ecommerce ha un conteggio mediano di Disallow elevato, ma il suo punteggio di debito P90 è più basso di travel perché la complessità è più concentrata nelle regole di percorso che nei segnali misti di policy/legale.
Tra i file con punteggio più alto in questo dataset figurano:
| Dominio | Perché il punteggio è alto |
|---|---|
linkedin.com | File molto grande, migliaia di regole di percorso, molti user agent nominati, linguaggio esplicito di policy AI |
lnkd.in | Stessa superficie di policy dell’infrastruttura shortlink di LinkedIn |
fragrantica.com | Centinaia di blocchi user-agent nominati più linguaggio di policy AI |
sovcombank.ru | Centinaia di blocchi user-agent e linguaggio legale/policy |
academia.edu | Ampia matrice allow/disallow e policy esplicita di blocco AI |
opentable.com | Grande insieme di regole di percorso, molte direttive sitemap, superficie di policy legata all’AI |
etsy.com | Grande file di controllo dei percorsi ecommerce con più di 1.600 regole Disallow |
runescape.com | Quasi 5.000 direttive Disallow sotto un unico gruppo di user agent |
Non andrebbero presi in giro questi file per essere complessi. La complessità spesso riflette bisogni aziendali reali. Ma dimostrano perché la policy robots.txt meriti la stessa disciplina ingegneristica delle altre configurazioni di produzione:
- la proprietà deve essere esplicita;
- le modifiche devono essere revisionate;
- le sezioni generate devono essere etichettate;
- i commenti legali dovrebbero essere separati dalle direttive macchina, quando possibile;
- i test dovrebbero verificare l’accesso atteso dei bot critici;
- la cronologia delle versioni dovrebbe essere conservata;
- i vecchi nomi dei bot dovrebbero essere ritirati o documentati;
- training AI, retrieval AI, indicizzazione di ricerca e archiviazione dovrebbero essere trattati come scopi separati.
L’ultimo punto è il più importante. La grammatica attuale è centrata prima sugli user agent: chiede agli operatori del sito di nominare i bot. Il bisogno dell’era AI è centrato sullo scopo: chiede agli operatori del sito di dire quali usi sono consentiti.
Non sono la stessa cosa.
È questa discrepanza il motivo per cui gli elenchi di blocco sempre più lunghi non reggeranno bene nel tempo. Un publisher può aggiungere oggi GPTBot, ClaudeBot, CCBot, Google-Extended, Bytespider, Applebot-Extended e PerplexityBot, ma il prossimo nome di crawler, agente di retrieval o broker di dataset può comparire domani. Una policy basata sullo scopo permetterebbe al sito di dire "indicizzazione di ricerca sì, training AI no, retrieval attivato dall’utente forse" senza trasformare robots.txt in una rubrica di bot.
Cosa significa per la governance dell’AI
Il dibattito pubblico spesso presenta robots.txt come significativo oppure obsoleto. I dati suggeriscono una risposta più pratica:
robots.txt è significativo, ma sovraccarico.
È significativo perché i grandi siti lo usano, i crawler possono leggerlo e le scelte di policy sono visibili a ricercatori, giornalisti, vendor e tribunali. Il report originale ha trovato che il 17,0% dei top siti analizzabili aveva regole deliberate specifiche per l’AI. Non è rumore simbolico.
È sovraccarico perché il file ora deve esprimere più dell’accesso dei bot:
- "Non addestrarti su questo contenuto."
- "Puoi usare questo contenuto per l’indicizzazione di ricerca."
- "Puoi usare questo contenuto per il retrieval in tempo reale."
- "Non puoi creare dataset cachetizzati."
- "Questa riserva legale si applica ai sensi della legge UE sul text and data mining."
- "Questo sito gestito da CDN invia
Content-Signal: ai-train=no." - "Questo sito vuole Googlebot ma non YandexBot."
- "Questo sito ha 1.000 percorsi URL legacy che non dovrebbero essere crawled."
La grammatica non è stata progettata per così tanti compiti.
Tre cambiamenti ridurrebbero il debito:
-
L’identità dei crawler ha bisogno di un registro. Gli operatori dei siti non dovrebbero dover mantenere un elenco in continua crescita di
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Applebot-Extended,Bytespider,OAI-SearchBot,ChatGPT-Usere molti altri. Senza un registro, la policy resterà sempre indietro rispetto al comportamento dei crawler. -
L’uso dell’AI ha bisogno di un vocabolario strutturato. Training, retrieval, indicizzazione, riassunto, rivendita di dataset, valutazione del modello e navigazione avviata dall’utente sono usi diversi. Esprimerli tramite nomi di user agent specifici di un vendor è fragile.
-
La policy deve essere auditabile. Il web ha bisogno di un modo per distinguere le riserve di diritti scritte a mano dai default ereditati dal CDN, dai template CMS generati, dalle vecchie regole legacy e dai blocchi generici accidentali. La distinzione conta per la fiducia e per il contenzioso.
Niente di questo significa sostituire robots.txt da un giorno all’altro. La strada migliore è la stratificazione: mantenere robots.txt come superficie di scoperta e compatibilità, ma standardizzare una policy machine-readable adiacente per gli usi specifici dell’AI.
llms.txt è un tentativo in questa direzione, ma l’adozione in questo dataset è ancora minima: solo 83 file leggibili lo menzionano. Content-Signal è più visibile perché Cloudflare può distribuirlo attraverso l’infrastruttura, e tutti i 271 file Content-Signal in questa scansione corrispondevano anche al linguaggio di policy AI. Tuttavia, distribuzione non significa consenso. Una soluzione duratura probabilmente ha bisogno della parte noiosa della standardizzazione: campi chiari, semantica chiara, impegni dei crawler e suite di test pubbliche.
Conclusione
La battaglia sui crawler AI ha trasformato robots.txt in un artefatto di governance. È sia utile sia rischioso.
Utile, perché il file è pubblico. I ricercatori possono verificarlo. I publisher possono modificarlo. I crawler possono rispettarlo. I tribunali possono leggerlo. I provider di infrastruttura possono distribuirlo su larga scala.
Rischioso, perché sta portando troppo peso.
Il file robots.txt mediano nel Tranco Top 10K è ancora abbastanza piccolo da poter essere compreso. Ma la coda lunga del web ad alto traffico è piena di file grandi, vecchi, stratificati, specifici di vendor e carichi di implicazioni legali. Centinaia di siti ora mantengono configurazioni robots.txt che è meglio intendere come sistemi di policy di produzione, non come semplici suggerimenti per i crawler.
La lezione centrale non è che robots.txt abbia fallito. È che il web lo ha promosso senza rifattorizzarlo.
Se la policy di accesso AI dovrà dipendere da dichiarazioni pubbliche leggibili dalle macchine, il passo successivo non è un’altra blocklist più lunga. È una migliore infrastruttura di policy: permessi basati sullo scopo, identità stabile dei crawler, template verificabili e trail di audit.
Fino ad allora, il livello di governance AI del web pubblico continuerà a poggiare su un file di testo che non era mai stato pensato per sostenere tutto questo peso.
Note sulla riproducibilità
La cartella di consegna include:
source_data/analysis.json— metriche aggregate originali.source_data/site_meta.csv— tabella analitica originale per sito.source_data/bot_status.csv— tabella originale delle policy dominio-per-bot.source_data/fetch_meta.csv— metadati di fetch originali.source_data/sites.csv— tabella originale dominio/categoria/stato.derived_data/robots_complexity_by_site.csv— metriche di complessità per sito generate per questo report.derived_data/search_bot_treatment.csv— matrice di trattamento dei crawler di ricerca.derived_data/category_complexity_summary.csv— riepilogo della complessità a livello di categoria.derived_data/top_config_debt_sites.csv— siti principali in base al punteggio di prioritizzazione descritto sopra.derived_data/summary_metrics.json— tutte le metriche principali citate in questo report.
Correzioni sulla metodologia, problemi del dataset e analisi successive sono benvenuti a support@thunderbit.com. Questo report è pubblicato in modo indipendente da qualsiasi posizione commerciale detenuta da Thunderbit; costruiamo un web scraper con AI e abbiamo un interesse strutturale nel fatto che robots.txt continui a essere un contratto significativo e leggibile dalle macchine sul web pubblico. I dati di questo report valgono da soli. — Il team di ricerca Thunderbit, maggio 2026.