Il web è una vera miniera di dati, e diciamocelo: nessuno ha voglia di copiare e incollare a mano migliaia di annunci di lavoro o schede prodotto. Ecco perché l’estrazione automatica dei dati dai siti è diventata una skill fondamentale per chi lavora in ambito commerciale, operativo, ecommerce e non solo. Python, con la sua sintassi semplice e le sue librerie super potenti, è oggi il linguaggio preferito per creare un Estrattore Web. Basti pensare che oltre il usa Python, staccando di parecchio tutti gli altri linguaggi.
C’è però un lato meno facile: anche se Python è molto efficace, per chi parte da zero può sembrare un po’ ostico, e persino i più esperti si scontrano con siti dinamici, blocchi anti-bot e dati disordinati. Per questo ho preparato questa guida passo passo. Partiremo dalle basi, vedremo insieme un esempio estrattore web python e scopriremo come integrare Python con strumenti AI come per rendere tutto più semplice e smart. Che tu voglia automatizzare la generazione di lead, monitorare i prezzi dei concorrenti o semplicemente raccogliere dati web in un foglio di calcolo, qui trovi istruzioni pratiche e consigli utili.
Web Scraping con Python: Le Basi per Iniziare da Zero
Partiamo dalle basi. Web scraping vuol dire automatizzare la raccolta di dati dai siti web. Invece di copiare a mano le informazioni, un estrattore visita la pagina, legge l’HTML e recupera solo quello che ti serve: prezzi, contatti, recensioni e molto altro. Per chi lavora nel business, questo si traduce in dati aggiornati in tempo reale per lead commerciali, monitoraggio prezzi o analisi di mercato, tutto a portata di click ().
Passo 1: Installa Python
Per prima cosa, ti serve Python 3. Scarica l’ultima versione dal . Su Windows, lancia l’installer e seleziona “Add Python to PATH”. Su Mac, puoi usare con brew install python oppure scaricare direttamente. Dopo l’installazione, apri il terminale (o il Prompt dei comandi) e digita:
1python --versionoppure
1python3 --versionSe vedi qualcosa tipo Python 3.11.0, sei pronto a partire.
Passo 2: Crea un Ambiente Virtuale
Un ambiente virtuale ti permette di gestire le dipendenze del progetto senza incasinare altri progetti Python. Nella cartella del tuo progetto, esegui:
1# Su macOS/Linux
2python3 -m venv .venv
3# Su Windows
4py -m venv .venvAttivalo con:
- macOS/Linux:
source .venv/bin/activate - Windows:
.venv\Scripts\activate
Così tutti i pacchetti che installerai saranno isolati solo per questo progetto ().
Passo 3: Installa le Librerie Fondamentali
Ti servono alcuni pacchetti base:
- Requests: per scaricare le pagine web.
- BeautifulSoup (bs4): per analizzare l’HTML.
- Scrapy: per scraping avanzato e su larga scala.
Installa tutto con:
1pip install requests beautifulsoup4 scrapy- Requests semplifica le chiamate HTTP.
- BeautifulSoup ti aiuta a trovare ed estrarre dati dall’HTML.
- Scrapy è un framework completo per gestire tanti siti, errori e l’esportazione dei dati.
Se sei alle prime armi, Requests + BeautifulSoup bastano e avanzano. Scrapy è perfetto quando vuoi scalare.
Passo 4: Organizza la Cartella del Progetto
Tieni tutto in ordine! Crea una cartella per il progetto e dentro salva script, file di dati e ambiente virtuale. Ti tornerà utilissimo in futuro.
esempio estrattore web python: Script Base e Struttura del Codice
Costruiamo insieme un estrattore semplice. Scaricheremo una pagina web, la analizzeremo e tireremo fuori alcuni dati. Ecco un esempio base e commentato che estrae i paragrafi da :
1import requests
2from bs4 import BeautifulSoup
3URL = "https://example.com"
4response = requests.get(URL)
5response.raise_for_status() # Segnala errore se la risposta non è 200 OK
6soup = BeautifulSoup(response.text, "html.parser")
7# Trova tutti i tag paragrafo
8paragraphs = soup.find_all('p')
9for idx, p in enumerate(paragraphs, start=1):
10 print(f"Paragrafo {idx}: {p.get_text()}")Cosa succede qui?
- Importiamo le librerie.
- Scarichiamo la pagina con
requests.get. - Analizziamo l’HTML con BeautifulSoup.
- Troviamo tutti i tag
<p>e stampiamo il testo.
Errori comuni:
- Non controllare
response.status_code(verifica sempre che sia 200 OK). - Usare
.get_text()su un oggettoNone(se l’elemento non esiste). - Dimenticare di attivare l’ambiente virtuale (le importazioni potrebbero fallire).
Questa struttura—importa, scarica, analizza, estrai, esporta—è la base di quasi tutti gli estrattori Python.
Usare Python per Estrarre Dati dal Web: Passaggi Dettagliati
Vediamo nel dettaglio il flusso di lavoro per un’attività di scraping reale.
1. Ispeziona il Sito Web
Apri il browser, clicca col tasto destro sui dati che ti interessano e scegli “Ispeziona”. Si apriranno gli Strumenti per Sviluppatori che mostrano la struttura HTML. Cerca tag, classi o ID unici che identificano i dati da estrarre ().
2. Scarica la Pagina
Usa Requests per ottenere l’HTML:
1headers = {"User-Agent": "Mozilla/5.0"}
2response = requests.get(URL, headers=headers)
3response.raise_for_status()Aggiungere uno User-Agent aiuta a evitare i blocchi anti-bot più semplici.
3. Analizza l’HTML
1soup = BeautifulSoup(response.text, "html.parser")4. Trova ed Estrai i Dati
Supponiamo di voler estrarre annunci di lavoro, ognuno in un <div class="job-card">:
1job_cards = soup.find_all('div', class_='job-card')
2for card in job_cards:
3 title = card.find('h2', class_='title').get_text(strip=True)
4 company = card.find('h3', class_='company').get_text(strip=True)
5 print(title, company)Puoi usare .find(), .find_all() o .select() con i selettori CSS per ricerche più complesse.
5. Gestisci Più Elementi (Liste)
Cicla tra i contenitori (come prodotti, annunci, ecc.), estraendo i campi che ti servono. Salvali in una lista di dizionari per esportarli facilmente.
6. Risoluzione dei Problemi
- Se ottieni risultati vuoti, controlla i selettori: magari la classe è cambiata o i dati sono caricati via JavaScript.
- Stampa
response.text[:500]per verificare se stai ricevendo l’HTML atteso.
esempio estrattore web python: Salvataggio ed Esportazione dei Dati
Una volta ottenuti i dati, dovrai salvarli. Ecco le opzioni più comuni:
Stampa su Console
Utile per controlli rapidi, ma non per progetti reali.
Scrivi su CSV
1import csv
2data = [
3 {"Name": "Alice", "Age": 25},
4 {"Name": "Bob", "Age": 30},
5]
6with open("output.csv", "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=["Name", "Age"])
8 writer.writeheader()
9 writer.writerows(data)Esporta su Excel
Se hai installato pandas e openpyxl:
1import pandas as pd
2df = pd.DataFrame(data)
3df.to_excel("output.xlsx", index=False)Salva in un Database
Per esigenze semplici, SQLite è già incluso in Python:
1import sqlite3
2conn = sqlite3.connect("scraped_data.db")
3cursor = conn.cursor()
4cursor.execute("CREATE TABLE IF NOT EXISTS people (name TEXT, age INTEGER)")
5for row in data:
6 cursor.execute("INSERT INTO people VALUES (?, ?)", (row["Name"], row["Age"]))
7conn.commit()
8conn.close()Quando usare cosa?
- CSV: Perfetto per fogli di calcolo e condivisione.
- Excel: Per report più curati e con più fogli.
- Database: Per progetti grandi o ricorrenti.
Ricorda di usare sempre encoding="utf-8" per evitare problemi con i caratteri ().
Thunderbit e Python: Potenzia il Tuo Flusso di Lavoro di Web Scraping
 Parliamo ora di , l’estensione Chrome Estrattore Web AI che sta cambiando il modo di estrarre dati per chi lavora nel business.
Parliamo ora di , l’estensione Chrome Estrattore Web AI che sta cambiando il modo di estrarre dati per chi lavora nel business.
Cosa Rende Thunderbit Unico?
- AI Suggerisce i Campi: L’intelligenza artificiale di Thunderbit analizza la pagina e ti suggerisce subito quali colonne estrarre—senza dover cercare nell’HTML o scrivere selettori.
- Flusso di Lavoro Punta e Clicca: Apri l’estensione, lascia che l’AI suggerisca i campi, clicca su “Estrai” e hai già fatto.
- Estrazione da Sottopagine: Thunderbit può visitare automaticamente pagine di dettaglio (come schede prodotto o profili) e arricchire il tuo dataset con informazioni extra.
- Esporta Ovunque: Scarica i dati in CSV, Excel o esporta direttamente su Google Sheets, Notion o Airtable ().
Come Thunderbit Si Integra con Python?
Immagina di dover estrarre dati da un sito ecommerce pieno di JavaScript e con login. Gli script Python classici potrebbero avere difficoltà, ma Thunderbit—lavorando direttamente nel browser—gestisce questi casi senza problemi. Una volta estratti i dati, puoi esportarli e analizzarli con Python per report, automazioni o analisi approfondite.
Esempio pratico:
- Usa Thunderbit per estrarre schede prodotto (immagini, prezzi, recensioni) da un sito dinamico.
- Esporta in CSV.
- Analizza le tendenze, unisci altri dati o automatizza alert con Python.
Questa combinazione ti permette di affrontare anche le sfide di scraping più toste, a prescindere dal tuo livello di programmazione.
Come Rendere il Tuo Estrattore Web Python Affidabile e Preciso
Fare scraping non vuol dire solo raccogliere dati, ma farlo in modo affidabile e preciso. Ecco come mantenere i tuoi estrattori sempre funzionanti:
1. Gestisci i Cambiamenti dei Siti
I siti cambiano HTML spesso. Scrivi selettori il più possibile robusti: preferisci ID unici o classi stabili invece di posizioni di tag fragili.
2. Usa la Gestione degli Errori
Racchiudi le richieste e il parsing in blocchi try/except:
1import time
2for attempt in range(3):
3 try:
4 response = requests.get(url, timeout=10)
5 response.raise_for_status()
6 break
7 except Exception as e:
8 if attempt < 2:
9 time.sleep(5)
10 else:
11 print(f"Fallito dopo 3 tentativi: {e}")3. Ruota User-Agent e Usa Proxy
Molti siti bloccano gli script che sembrano bot. Cambia lo User-Agent e, per scraping intensivo, usa proxy per evitare blocchi IP ().
4. Rispetta robots.txt ed Etica
Controlla sempre il file robots.txt e le condizioni d’uso del sito. Estrai solo dati pubblici, evita informazioni personali e non sovraccaricare i server ().
5. Log e Monitoraggio
Usa il modulo logging di Python per tracciare errori e successi. Se il tuo estrattore gira in automatico, imposta alert per errori o risultati vuoti.
Come le Funzionalità AI di Thunderbit Migliorano il Web Scraping con Python
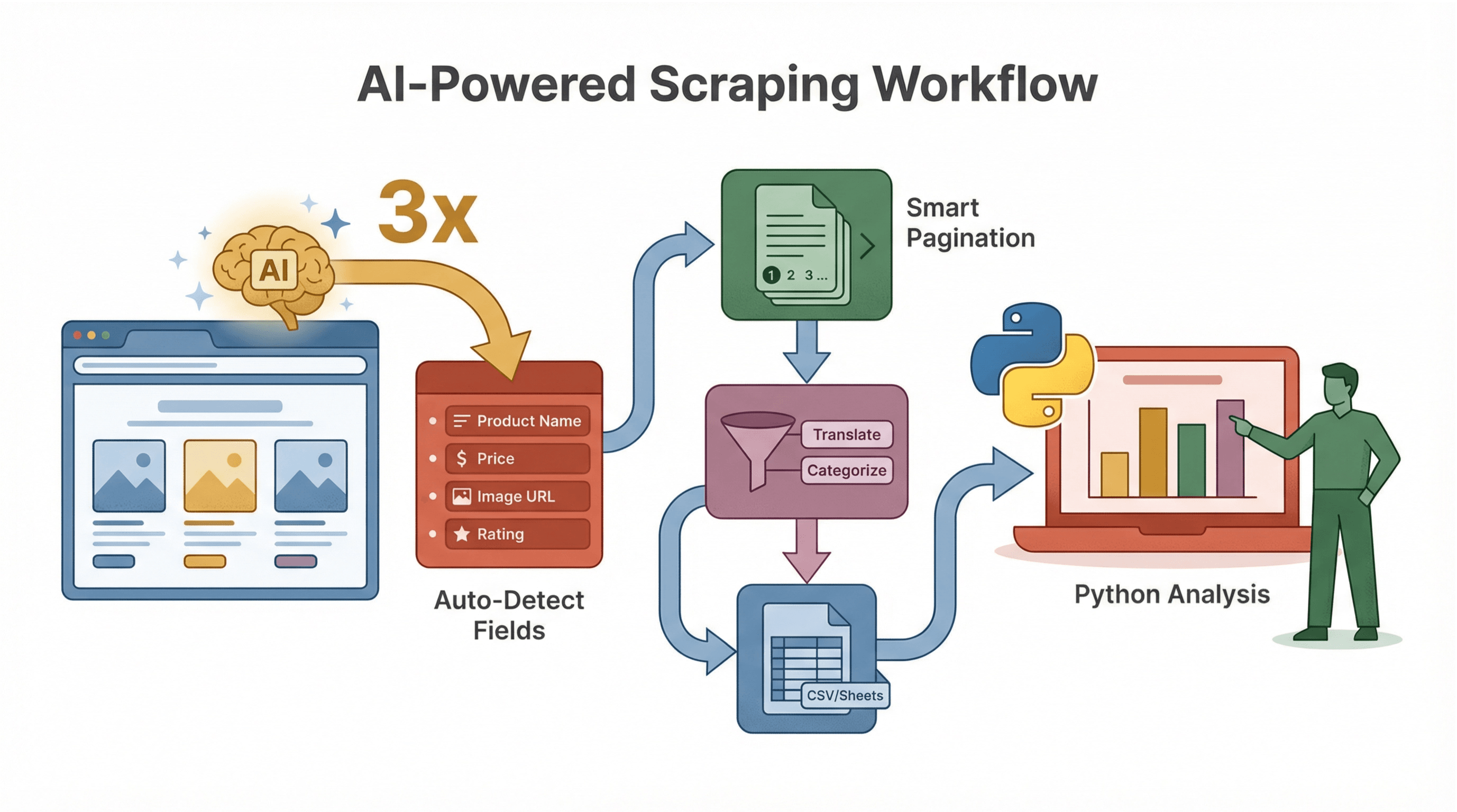 Thunderbit non si limita a estrarre dati: rende tutto il processo più smart e veloce.
Thunderbit non si limita a estrarre dati: rende tutto il processo più smart e veloce.
Schema Dati Suggerito dall’AI
L’AI di Thunderbit suggerisce subito quali campi estrarre, evitandoti di dover ispezionare l’HTML o scrivere selettori. Ad esempio, su una pagina prodotto, può individuare automaticamente “Nome prodotto”, “Prezzo”, “URL immagine” e altro.
Gestione Sottopagine e Paginazione
Thunderbit rileva automaticamente la presenza di pagine di dettaglio o risultati multipli e li estrae tutti—senza bisogno di codice aggiuntivo. Perfetto per ecommerce, immobiliare o lead generation.
Pulizia e Arricchimento Dati con l’AI
Vuoi tradurre, riassumere o categorizzare i dati mentre li estrai? Thunderbit ti permette di aggiungere prompt AI a ogni campo, così puoi ad esempio etichettare le recensioni come “Positive” o “Negative”, oppure estrarre solo la parte numerica di un prezzo.
Esempio di Flusso di Lavoro
- Usa Thunderbit per estrarre e strutturare i dati (con i campi suggeriti dall’AI).
- Esporta in CSV o Google Sheets.
- Analizza, visualizza o automatizza azioni successive con Python.
Questo flusso è perfetto per team dove non tutti sanno programmare: Thunderbit si occupa dell’estrazione, Python dell’analisi avanzata.
esempio estrattore web python: Consigli Avanzati e Problemi Comuni
Vuoi fare un salto di livello? Ecco qualche dritta da professionista:
Estrazione di Contenuti Dinamici
Molti siti moderni usano JavaScript per caricare i dati. Se Requests + BeautifulSoup restituiscono dati vuoti o incompleti, prova:
- Selenium o Playwright: Automatizza un vero browser per caricare la pagina e poi estrai l’HTML.
- Cerca API: Spesso i dati sono caricati tramite chiamate API in background (di solito in JSON). Usa la scheda Network del browser per trovare questi endpoint—sono molto più facili da estrarre!
Gestione della Paginazione
Cicla tra le pagine modificando il parametro nell’URL (es. ?page=2). Oppure usa BeautifulSoup per trovare il link “Successivo” e seguilo finché ci sono pagine.
Pianifica le Estrazioni
Usa la libreria schedule di Python o un cron job per eseguire automaticamente l’estrattore. Oppure sfrutta la funzione di pianificazione integrata di Thunderbit per una soluzione senza codice.
Problemi Comuni
- CAPTCHA: Rallenta le richieste, usa proxy o valuta soluzioni con intervento umano.
- Problemi di Codifica: Specifica sempre
encoding="utf-8"quando salvi file. - Blocchi IP: Ruota proxy, cambia User-Agent e rispetta i limiti di richiesta.
Conclusioni & Punti Chiave
Imparare a fare web scraping con Python non deve essere complicato. Parti dalle basi:
- Prepara l’ambiente e le librerie essenziali.
- Ispeziona il sito target e pianifica i selettori.
- Scrivi uno script semplice per scaricare, analizzare ed estrarre i dati.
- Esporta i risultati nel formato più adatto alle tue esigenze.
Quando sarai più esperto, integra Python con strumenti AI come per gestire scraping complessi, dinamici o su larga scala. Le funzionalità AI di Thunderbit—come suggerimenti sui campi, estrazione da sottopagine ed esportazione immediata—possono farti risparmiare ore di lavoro manuale e permettere anche a chi non programma di ottenere risultati.
Ricorda: i migliori estrattori sono affidabili, etici e costruiti pensando all’obiettivo finale. Che tu sia un commerciale, un manager ecommerce o un appassionato di dati, il web scraping può aprirti un mondo di opportunità—basta iniziare in piccolo, migliorare passo dopo passo e non smettere mai di imparare.
Vuoi approfondire? Dai un’occhiata al per altre guide, oppure prova l’ per vedere l’AI in azione.
Domande Frequenti
1. Qual è il modo più semplice per iniziare a fare web scraping con Python?
Installa Python 3, poi usa le librerie Requests e BeautifulSoup per scaricare e analizzare le pagine web. Parti da siti semplici e passa gradualmente a quelli più complessi man mano che prendi confidenza.
2. Come gestire i siti che usano JavaScript per caricare i dati?
Per siti ricchi di JavaScript, usa strumenti di automazione browser come Selenium o Playwright, oppure cerca chiamate API in background nella scheda Network del browser che restituiscano dati strutturati (come JSON).
3. Qual è il modo migliore per esportare i dati estratti per uso aziendale?
Il formato CSV è il più universale (aperto da Excel, Google Sheets, ecc.), ma puoi anche esportare in Excel, JSON o database come SQLite. Thunderbit supporta anche l’esportazione diretta su Google Sheets, Notion e Airtable.
4. Come evitare di essere bloccati durante lo scraping?
Cambia User-Agent, usa proxy per scraping su larga scala, rispetta i limiti di richiesta e controlla sempre il file robots.txt del sito. Evita di estrarre dati personali o sensibili.
5. In che modo Thunderbit semplifica il web scraping per chi non sa programmare?
Thunderbit sfrutta l’AI per suggerire i campi dati, gestire sottopagine e paginazione, ed esportare dati strutturati in pochi clic—senza bisogno di scrivere codice. È perfetto per chi vuole risultati rapidi e affidabili senza complicazioni tecniche.
Vuoi automatizzare la raccolta dati? Prova gratis e lascia che l’AI porti il tuo web scraping al livello successivo.
Approfondisci