Lascia che ti porti indietro ai miei primi giorni nel mondo SaaS e dell’automazione, quando sentivo parlare di “web crawling” e mi immaginavo un ragno che si gode il weekend. Oggi invece il web crawling è il motore silenzioso dietro Google Search e i siti di comparazione prezzi che consulti ogni giorno. Il web è un ambiente che cambia di continuo e chiunque – dagli sviluppatori ai team commerciali – vuole mettere le mani sui suoi dati. Ma qui sta il punto: anche se Python ha reso più accessibile creare un python web crawler, la maggior parte delle persone vuole solo i dati, non un corso accelerato su HTTP header o su come si gestisce il rendering JavaScript.
Ed è qui che la faccenda si fa interessante. Da co-fondatore di , ho visto con i miei occhi quanto la fame di dati web sia esplosa in ogni settore. I team di vendita cercano nuovi lead, chi gestisce e-commerce vuole tenere d’occhio i prezzi dei concorrenti, i marketer sono assetati di insight sui contenuti. Ma non tutti hanno il tempo (o la voglia) di diventare esperti di web crawler python. Quindi, vediamo insieme cos’è davvero un python web crawler, perché conta così tanto e come strumenti AI come Thunderbit stanno cambiando le regole del gioco sia per le aziende che per gli sviluppatori.
Web Crawler Python: Cos’è e Perché Conta?
Facciamo subito chiarezza su un errore comune: web crawler e estrattore web non sono la stessa cosa. Lo so, spesso vengono confusi, ma sono diversi come un Roomba e un Dyson (entrambi puliscono, ma in modo molto diverso).
- Web Crawler: sono gli esploratori del web. Il loro compito è scoprire e indicizzare sistematicamente le pagine, seguendo i link da una pagina all’altra – proprio come fa Googlebot per mappare Internet.
- Estrattore Web: sono più simili a raccoglitori esperti. Estraggono dati specifici dalle pagine, come prezzi, contatti o contenuti di articoli.

Quando si parla di “web crawler python”, di solito si intende l’uso di Python per creare bot automatici che navigano (e a volte estraggono dati) dal web. Python è la scelta preferita perché è facile da imparare, ha una vasta gamma di librerie e – diciamolo – nessuno vuole scrivere un web crawler in Assembly.
Il Valore del Web Crawling e Web Scraping per il Business
Perché così tante aziende sono interessate a web crawling e web scraping? Perché i dati web sono il nuovo oro nero – ma invece di trivellare, basta programmare (o, come vedremo, cliccare un paio di volte).
Ecco alcuni degli usi più comuni in ambito business:
| Caso d’uso | Chi lo usa | Valore aggiunto |
|---|---|---|
| Generazione Lead | Vendite, Marketing | Creazione di liste di potenziali clienti da directory e social |
| Monitoraggio Concorrenti | E-commerce, Operazioni | Tracciamento prezzi, stock e nuovi prodotti dei rivali |
| Tracciamento Prodotti | E-commerce, Retail | Monitoraggio di cataloghi, recensioni e valutazioni |
| Analisi SEO | Marketing, Content | Analisi di keyword, meta tag e backlink per l’ottimizzazione |
| Annunci Immobiliari | Agenti, Investitori | Raccolta dati su immobili e contatti proprietari da più fonti |
| Aggregazione Contenuti | Ricerca, Media | Raccolta di articoli, news o post dai forum per insight |
La cosa bella è che sia i team tecnici che quelli non tecnici possono trarne vantaggio. Gli sviluppatori possono creare crawler personalizzati per progetti complessi, mentre chi lavora nel business vuole solo dati rapidi e precisi – senza dover imparare cosa sia un selettore CSS.
Le Librerie Python più Usate per Web Crawling: Scrapy, BeautifulSoup e Selenium
La popolarità di Python nel web crawling non è solo una moda: è sostenuta da tre librerie principali, ognuna con i suoi punti di forza (e qualche stranezza).
| Libreria | Facilità d’uso | Velocità | Supporto contenuti dinamici | Scalabilità | Ideale per |
|---|---|---|---|---|---|
| Scrapy | Media | Veloce | Limitato | Alta | Crawl automatizzati su larga scala |
| BeautifulSoup | Facile | Media | Nessuno | Bassa | Parsing semplice, piccoli progetti |
| Selenium | Più complesso | Lento | Ottimo | Bassa-Media | Siti con molto JavaScript, interattivi |
Vediamo cosa rende unica ciascuna di queste librerie.
Scrapy: Il Framework Completo per il Web Crawling in Python
Scrapy è il coltellino svizzero del web crawling in Python. È un framework completo pensato per crawl automatizzati su larga scala – perfetto per chi deve analizzare migliaia di pagine, gestire richieste simultanee ed esportare dati in pipeline.
Perché gli sviluppatori lo amano:
- Gestisce crawling, parsing ed esportazione dati in un unico ambiente.
- Supporta nativamente la concorrenza, la pianificazione e le pipeline.
- Ideale per progetti che richiedono crawling e scraping su vasta scala.
Ma… Scrapy ha una curva di apprendimento. Come dice un dev, è “troppo complesso se devi solo estrarre poche pagine” (). Bisogna capire i selettori, la programmazione asincrona e, a volte, anche proxy e strategie anti-bot.
Come funziona Scrapy in breve:
- Definisci uno Spider (la logica del crawler).
- Imposta le pipeline per il trattamento dei dati.
- Avvia il crawl ed esporta i dati.
Se vuoi scandagliare il web come Google, Scrapy è la scelta giusta. Se ti serve solo una lista di email, forse è troppo.
BeautifulSoup: Parsing Semplice e Leggero
BeautifulSoup è il “ciao mondo” del parsing web. È una libreria leggera, perfetta per chi inizia o per progetti piccoli, focalizzata sull’analisi di HTML e XML.
Perché piace tanto:
- Facilissima da imparare e usare.
- Ottima per estrarre dati da pagine statiche.
- Flessibile per script veloci e semplici.
Ma… BeautifulSoup non effettua crawling, si limita al parsing. Serve abbinarla a requests per scaricare le pagine e bisogna scrivere la logica per seguire i link o gestire più pagine ().
Se vuoi iniziare a esplorare il web crawling, BeautifulSoup è un ottimo punto di partenza. Ma non aspettarti che gestisca JavaScript o grandi volumi.
Selenium: Per Siti Dinamici e Pagine Caricate in JavaScript
Selenium è il re dell’automazione browser. Può controllare Chrome, Firefox o Edge, interagire con pulsanti, compilare form e – soprattutto – visualizzare pagine ricche di JavaScript.

Perché è potente:
- Può “vedere” e interagire con le pagine come farebbe un utente reale.
- Gestisce contenuti dinamici e dati caricati via AJAX.
- Essenziale per siti che richiedono login o simulano azioni utente.
Ma… Selenium è lento e pesante. Avvia un browser completo per ogni pagina, il che può rallentare molto se devi analizzare tanti siti (). Anche la manutenzione è impegnativa: bisogna gestire i driver dei browser e aspettare che i contenuti dinamici si carichino.
Selenium è la soluzione quando devi estrarre dati da siti “blindati” per i normali scraper.
Le Sfide del Costruire e Gestire un Web Crawler Python
Parliamo ora del lato meno affascinante del web crawling in Python. Ho passato più ore di quante vorrei a debuggare selettori e combattere contro sistemi anti-bot. Ecco le principali difficoltà:
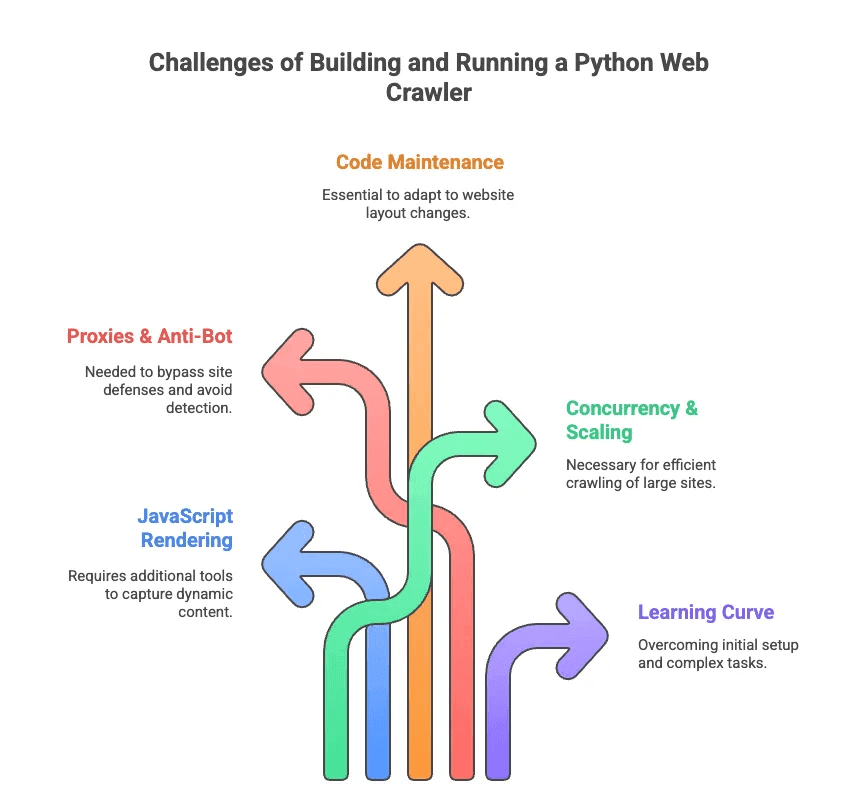
- Rendering JavaScript: Molti siti moderni caricano i contenuti in modo dinamico. Scrapy e BeautifulSoup non vedono questi dati senza strumenti aggiuntivi.
- Proxy & Anti-Bot: I siti non amano essere “crawled”. Bisogna ruotare proxy, cambiare user agent e, a volte, risolvere CAPTCHA.
- Manutenzione del Codice: I siti cambiano spesso layout. Il tuo estrattore web può smettere di funzionare da un giorno all’altro e dovrai aggiornare selettori o logica.
- Concorrenza & Scalabilità: Se devi analizzare migliaia di pagine, serve gestire richieste asincrone, errori e pipeline dati.
- Curva di Apprendimento: Per chi non è sviluppatore, anche solo installare Python e le dipendenze può essere complicato. Figurarsi gestire paginazione o login.
Come ha detto un ingegnere, scrivere estrattori web personalizzati spesso sembra “dover prendere un dottorato in configurazione dei selettori” – non proprio quello che cerca chi lavora in vendite o marketing ().
Estrattore Web AI vs. Python Web Crawler: La Nuova Frontiera per il Business
E se volessi solo i dati, senza complicazioni? Ecco che entrano in gioco gli estrattori web AI. Questi strumenti – come – sono pensati per chi lavora nel business, non per i programmatori. Usano l’intelligenza artificiale per leggere le pagine, suggerire quali dati estrarre e gestire tutto il lavoro sporco (paginazione, sottopagine, anti-bot) dietro le quinte.
Ecco un confronto rapido:
| Funzionalità | Web Crawler Python | Estrattore Web AI (Thunderbit) |
|---|---|---|
| Configurazione | Codice, librerie, setup | Estensione Chrome in 2 click |
| Manutenzione | Aggiornamenti manuali, debug | L’AI si adatta ai cambiamenti |
| Contenuti Dinamici | Serve Selenium o plugin | Browser/cloud integrato |
| Gestione Anti-Bot | Proxy, user agent | AI & cloud per aggirare blocchi |
| Scalabilità | Alta (con sforzo) | Alta (cloud, scraping parallelo) |
| Facilità d’uso | Per sviluppatori | Per tutti |
| Esportazione dati | Codice o script | 1 click su Sheets, Airtable, Notion |
Con Thunderbit, non devi preoccuparti di richieste HTTP, JavaScript o proxy. Basta cliccare su “AI Suggerisci Campi”, lasciare che l’AI individui i dati importanti e avviare l’estrazione. È come avere un maggiordomo dei dati – senza papillon.
Thunderbit: L’Estrattore Web AI di Nuova Generazione per Tutti
Andiamo al sodo. Thunderbit è un’ pensata per rendere la raccolta dati semplice come ordinare una pizza. Ecco cosa la rende speciale:
- Rilevamento Campi con AI: L’AI di Thunderbit legge la pagina e suggerisce quali colonne estrarre – addio tentativi con i selettori CSS ().
- Supporto Pagine Dinamiche: Funziona sia su pagine statiche che su siti ricchi di JavaScript, grazie alle modalità browser e cloud.
- Sottopagine & Paginazione: Vuoi dettagli da ogni prodotto o profilo? Thunderbit può entrare in ogni sottopagina e raccogliere tutto in automatico ().
- Adattabilità dei Template: Un solo template di scraping si adatta a più strutture di pagina – non serve rifare tutto se il sito cambia.
- Bypass Anti-Bot: L’AI e l’infrastruttura cloud aiutano a superare i blocchi anti-scraping più comuni.
- Esportazione Dati: Invia i dati direttamente su Google Sheets, Airtable, Notion o scarica in CSV/Excel – senza costi nascosti, anche nella versione gratuita ().
- Pulizia Dati con AI: Riepiloga, categorizza o traduci i dati al volo – addio fogli Excel disordinati.
Esempi pratici:
- Team di vendita estraggono liste di potenziali clienti da directory o LinkedIn in pochi minuti.
- Manager e-commerce monitorano prezzi e prodotti dei concorrenti senza fatica manuale.
- Agenti immobiliari aggregano annunci e contatti proprietari da più siti.
- Team marketing analizzano contenuti, keyword e backlink per la SEO – tutto senza scrivere una riga di codice.
Il flusso di lavoro di Thunderbit è così semplice che anche i miei amici meno tecnologici lo usano – e con successo. Basta installare l’estensione, aprire il sito di interesse, cliccare su “AI Suggerisci Campi” e il gioco è fatto. Per siti popolari come Amazon o LinkedIn ci sono anche template pronti all’uso – un click e hai tutto ().
Quando Usare un Web Crawler Python e Quando un Estrattore Web AI
Quindi, meglio costruire un web crawler python o affidarsi a Thunderbit? Ecco la mia opinione sincera:
| Scenario | Web Crawler Python | Estrattore Web AI (Thunderbit) |
|---|---|---|
| Serve logica personalizzata o grande scala | ✔️ | Forse (modalità cloud) |
| Integrazione profonda con altri sistemi | ✔️ (con codice) | Limitata (tramite esportazione) |
| Utente non tecnico, risultati rapidi | ❌ | ✔️ |
| Cambi frequenti nel layout dei siti | ❌ (aggiornamenti manuali) | ✔️ (AI si adatta) |
| Siti dinamici/ricchi di JS | ✔️ (con Selenium) | ✔️ (integrato) |
| Budget limitato, piccoli progetti | Forse (gratis, ma serve tempo) | ✔️ (piano free, nessun paywall) |
Scegli un web crawler python se:
- Sei uno sviluppatore e vuoi il massimo controllo.
- Devi analizzare milioni di pagine o creare pipeline dati personalizzate.
- Sei disposto a gestire manutenzione e debug continui.
Scegli Thunderbit se:
- Vuoi i dati subito, senza settimane di codice.
- Lavori in vendite, e-commerce, marketing o immobiliare e ti servono solo i risultati.
- Non vuoi impazzire con proxy, selettori o sistemi anti-bot.
Non sei ancora sicuro? Ecco una checklist veloce:
- Hai dimestichezza con Python e tecnologie web? Se sì, prova Scrapy o Selenium.
- Vuoi solo i dati, in modo rapido e pulito? Thunderbit è la soluzione.
Conclusione: Sblocca il Potere dei Dati Web – Scegli lo Strumento Giusto per Te
Web crawling e web scraping sono ormai competenze fondamentali nell’era dei dati. Ma diciamolo: non tutti vogliono diventare esperti di web crawling. Strumenti Python come Scrapy, BeautifulSoup e Selenium sono potenti, ma richiedono tempo per imparare e costante manutenzione.
Ecco perché sono entusiasta della nuova generazione di estrattori web AI come . Abbiamo creato Thunderbit per mettere la potenza dei dati web nelle mani di tutti – non solo degli sviluppatori. Con il rilevamento automatico dei campi, il supporto alle pagine dinamiche e flussi di lavoro no-code, chiunque può estrarre i dati che gli servono in pochi minuti.
Che tu sia uno sviluppatore appassionato di codice o un professionista che vuole solo i dati, c’è lo strumento giusto per te. Valuta le tue esigenze, il tuo livello tecnico e le tempistiche. E se vuoi scoprire quanto può essere semplice estrarre dati dal web, : il tuo futuro (e i tuoi fogli di calcolo) ti ringrazieranno.
Vuoi approfondire? Scopri altre guide sul , come o . Buon crawling – e buon scraping!
Domande Frequenti
1. Qual è la differenza tra un Web Crawler Python e un Estrattore Web?
Un web crawler python è progettato per esplorare e indicizzare sistematicamente le pagine web seguendo i link – ideale per scoprire la struttura di un sito. Un estrattore web, invece, estrae dati specifici da queste pagine, come prezzi o email. I crawler mappano il web; gli estrattori raccolgono ciò che ti interessa. Spesso, in Python, vengono usati insieme per flussi di estrazione dati completi.
2. Quali sono le migliori librerie Python per creare un Web Crawler?
Le più popolari sono Scrapy, BeautifulSoup e Selenium. Scrapy è veloce e scalabile per grandi progetti; BeautifulSoup è perfetta per chi inizia e per pagine statiche; Selenium è ideale per siti ricchi di JavaScript ma è più lenta. La scelta dipende dalle tue competenze, dal tipo di contenuto e dalla dimensione del progetto.
3. Esiste un modo più semplice per ottenere dati web senza programmare un Web Crawler Python?
Sì – Thunderbit è un’estensione Chrome AI che permette a chiunque di estrarre dati web in due click. Niente codice, nessuna configurazione. Rileva automaticamente i campi, gestisce paginazione e sottopagine, ed esporta i dati su Sheets, Airtable o Notion. Perfetta per team di vendita, marketing, e-commerce o immobiliare che vogliono dati puliti – subito.
Scopri di più: