

Il web del 2025 è davvero un campo di battaglia in continua trasformazione: un momento stai controllando i prezzi dei competitor, quello dopo ti ritrovi a fare i conti con JavaScript che cambia al volo e sistemi anti-bot sempre più furbi. Dopo anni passati a creare strumenti di automazione per team sales e operation, posso dirlo senza dubbi: saper estrarre dati dal web non è più un “nice to have”, ma una vera marcia in più per chi fa business. Con il 90% delle aziende che oggi si affida ai dati per le decisioni strategiche e un volume di informazioni online cresciuto di quasi 193% in soli quattro anni, la capacità di trasformare il caos del web in dati utili è ciò che separa chi guida il mercato da chi resta indietro.

Diciamocelo: oggi l’estrazione dati non è più quella di una volta. I tempi in cui bastavano due righe di Python per scaricare una pagina statica sono finiti. Ora ci troviamo davanti a contenuti dinamici, scroll infiniti e barriere anti-bot degne di una spy story. Che tu sia alle prime armi o voglia affinare la tua strategia, questa guida ti porta tra best practice, strumenti e flussi di lavoro per dominare lo scraping con Python nel 2025—e ti mostra come dare una marcia in più ai tuoi progetti con strumenti AI come Thunderbit.
Estrai dati da qualsiasi sito web con l’AI Get Started Free
Da Zero a Ninja: Le Basi dello Scraping con Python
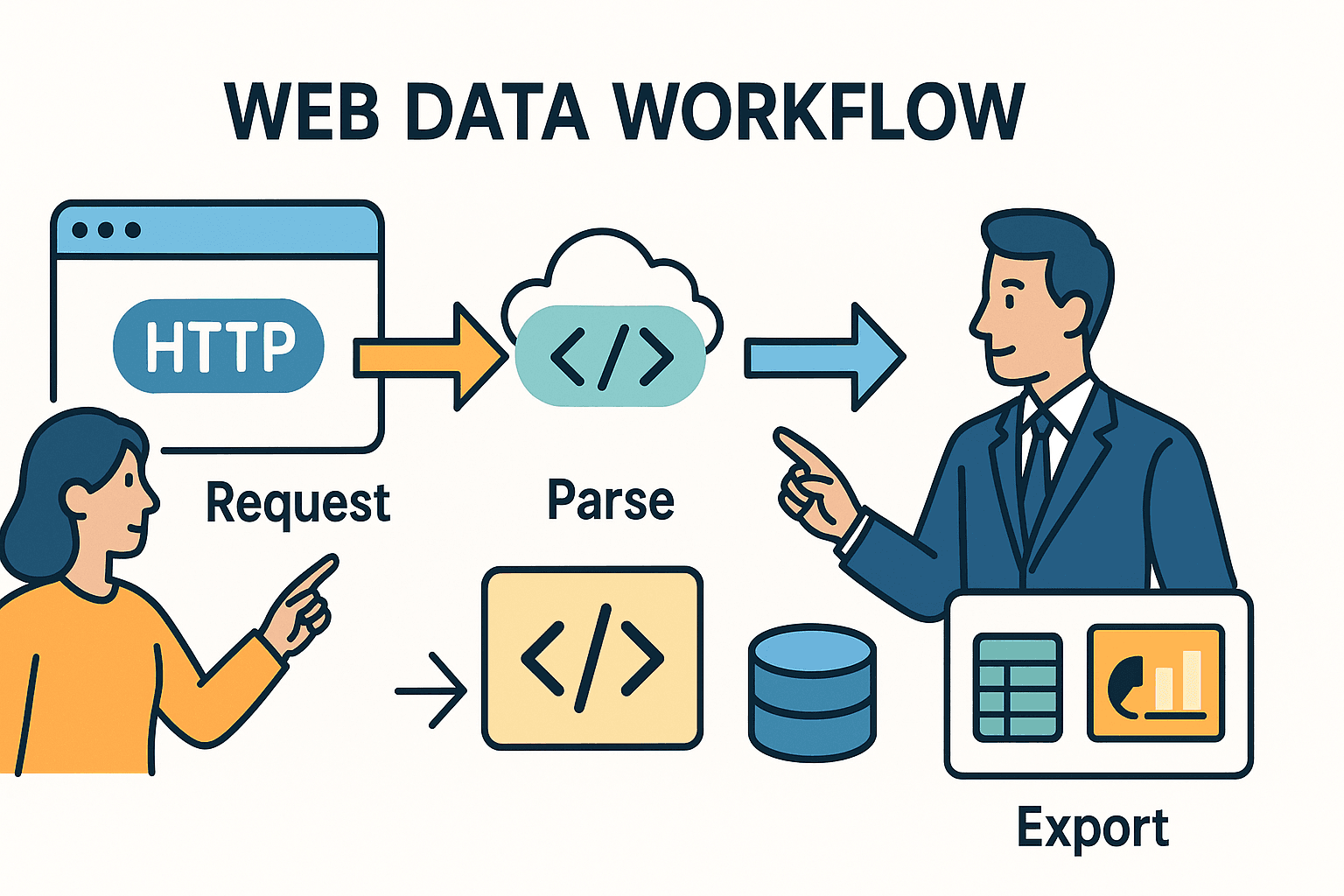
Partiamo dalle basi. Fare scraping vuol dire automatizzare quello che normalmente faresti a mano: apri una pagina, cerchi i dati che ti servono e li salvi per dopo. In Python, di solito il processo si divide in tre step:
- Inviare una richiesta HTTP (proprio come fa il browser quando navighi).
- Analizzare l’HTML per trovare i dati che ti interessano.
- Esportare o lavorare su quei dati—magari su un foglio Excel, un database o una dashboard.
La scelta degli strumenti (e le difficoltà che incontrerai) dipende da quanto è complicato il sito e da cosa vuoi ottenere.
Python Scraping 101: Come Funziona
Immagina lo scraping come mandare un bibliotecario a recuperare un giornale e poi usare le forbici per ritagliare solo gli articoli che ti interessano. La libreria requests di Python è il tuo bibliotecario—recupera l’HTML. BeautifulSoup sono le tue forbici—ti permette di selezionare e isolare le informazioni utili.
Ma se il giornale fosse scritto con inchiostro invisibile (cioè, JavaScript!) o gli articoli fossero sparsi su decine di pagine? In questi casi servono strumenti più avanzati—o un pizzico di intelligenza artificiale.
Confronto tra gli Strumenti Principali
Ecco una panoramica dei principali strumenti Python per lo scraping e quando usarli:
| Strumento/Libreria | Quando usarlo... | Vantaggi | Svantaggi |
|---|---|---|---|
| Requests + BeautifulSoup | Per pagine statiche o piccoli progetti | Semplice, veloce, ideale per chi inizia. Massimo controllo. | Non gestisce JavaScript né grandi volumi di dati. |
| Scrapy | Progetti su larga scala, molti siti o pagine | Alte prestazioni, crawling integrato, asincrono, pipeline, gestione errori avanzata. | Curva di apprendimento più ripida, configurazione iniziale. |
| Selenium/Playwright | Siti con JavaScript, login o interazioni utente | Può estrarre tutto ciò che vede un browser. Gestisce contenuti dinamici, login, scroll infiniti. | Più lento, richiede più risorse, implementazione più complessa. |
| Thunderbit (AI) | Dati non strutturati, PDF, immagini, no-code | L’AI rileva automaticamente i campi, gestisce sottopagine, esporta su Excel/Sheets, nessun codice richiesto. | Meno personalizzabile per casi particolari, consumo a crediti. |
Per la maggior parte degli utenti business, partire con requests e BeautifulSoup è perfetto per siti semplici e statici. Per progetti più complessi o voluminosi, Scrapy è la scelta giusta. E quando incontri ostacoli—contenuti dinamici, anti-bot o dati non strutturati—strumenti AI come Thunderbit possono davvero fare la differenza.
Prova gratis Thunderbit Estrattore Web AI
Mappare il Terreno: Best Practice Step-by-Step per Scraping Complessi
Come si passa dal “voglio quei dati” a uno scraper robusto e affidabile? Ecco il mio flusso di lavoro collaudato:
1. Analizza e Comprendi il Sito di Destinazione
Prima di scrivere una sola riga di codice, apri gli Strumenti per Sviluppatori del browser (F12 o tasto destro > Ispeziona). Individua i dati che ti servono nell’HTML. Sono in una tabella? In una serie di <div>? C’è una chiamata API nascosta che restituisce JSON? Spesso la soluzione più semplice è proprio davanti ai tuoi occhi.
Consiglio: se noti una richiesta di rete che recupera dati JSON quando clicchi su “pagina successiva” o “carica altro”, puoi spesso evitare il parsing HTML e replicare direttamente quella chiamata API con Python.
2. Fai un Test su una Sola Pagina
Inizia in piccolo. Usa requests per scaricare una pagina, poi BeautifulSoup per estrarre un paio di campi. Stampa i risultati. Se vieni bloccato o i dati mancano, prova ad aggiungere header (come lo User-Agent del browser), oppure verifica se i contenuti sono caricati via JavaScript (in tal caso, vedi Step 3).
3. Gestisci Contenuti Dinamici e Paginazione
Se i dati non sono nell’HTML, probabilmente vengono caricati da JavaScript. Ecco cosa fare:
- Automazione Browser: Usa Selenium o Playwright per aprire la pagina, attendere il caricamento e recuperare l’HTML renderizzato.
- Chiamate API: Cerca richieste XHR nella scheda Network. Se trovi un endpoint che restituisce JSON, replica quella chiamata con
requests. - Paginazione: Per dati su più pagine, cicla sui numeri di pagina o segui i link “Next”. Per scroll infinito, usa Selenium per scorrere o simula le chiamate API attivate dallo scroll.
4. Gestione Errori e Rispetto delle Regole
I siti web non sempre gradiscono gli scraper. Per evitare blocchi:
- Rispetta
robots.txt: Controlla sempreexample.com/robots.txtper percorsi vietati o ritardi richiesti. - Rate Limiting: Inserisci
time.sleep()tra le richieste. Serobots.txtindicaCrawl-delay: 5, attendi almeno 5 secondi. - User-Agent Personalizzato: Identifica il tuo scraper in modo trasparente (es.
"MyScraper/1.0 (tuamail@email.com)"). - Retry e Gestione Errori: Usa try/except per gestire errori. Riprova in caso di fallimento, rallenta se ricevi HTTP 429 (Troppe richieste).
5. Estrai e Pulisci i Dati
Usa BeautifulSoup o i selettori di Scrapy per estrarre i campi. Elimina spazi inutili, converti prezzi in numeri, formatta le date e verifica la completezza. Per dataset ampi, utilizza pandas per pulizia e deduplicazione.
6. Scraping di Sottopagine
Spesso le informazioni più preziose sono nelle pagine di dettaglio. Estrai una lista di link, poi visita ciascuno per raccogliere dati aggiuntivi. In Python, significa ciclare sugli URL e scaricare ogni pagina. In Thunderbit, puoi usare la funzione “Scrape Subpages” per automatizzare questo passaggio—l’AI visiterà ogni sottopagina e arricchirà il tuo dataset.
7. Esporta e Automatizza
Esporta i dati puliti in CSV, Excel, Google Sheets o su un database. Per attività ricorrenti, pianifica lo script con cron, Airflow o (se usi Thunderbit) imposta una raccolta cloud programmata con linguaggio naturale (“ogni lunedì alle 9:00”).
Come estrarre dati da siti web in Excel con l’AI Get Started Free
Thunderbit: Quando l’AI Potenzia il Tuo Flusso di Lavoro Python
Parliamo dell’elefante nella stanza: a volte, anche il miglior codice Python non basta per gestire dati disordinati, non strutturati o protetti. Qui entra in gioco Thunderbit.
Come Thunderbit Si Integra con Python
Thunderbit è un’estensione Chrome basata su AI che legge pagine web (ma anche PDF, immagini, ecc.) e restituisce dati strutturati—senza scrivere codice. Ecco come lo uso insieme a Python:
- Per Dati Non Strutturati: Se mi trovo davanti a un PDF, un’immagine o un sito con HTML imprevedibile, lascio che l’AI di Thunderbit lo analizzi. Può estrarre tabelle da PDF, testo da immagini e suggerire automaticamente i campi.
- Per Scraping di Sottopagine e Flussi Complessi: La funzione “Scrape Subpages” di Thunderbit fa risparmiare tantissimo tempo. Estraggo una lista, poi l’AI visita ogni pagina di dettaglio e unisce i risultati—senza dover scrivere cicli annidati o gestire lo stato.
- Per l’Esportazione: Thunderbit esporta direttamente su Excel, Google Sheets, Notion o Airtable. Posso poi integrare questi dati nella mia pipeline Python per analisi o reportistica avanzata.
Esempio Pratico: Python + Thunderbit in Azione
Supponiamo che io stia monitorando annunci immobiliari. Uso Python e Scrapy per raccogliere gli URL degli annunci da vari siti. Ma su uno di questi, i dettagli sono solo in PDF scaricabili. Invece di scrivere un parser PDF personalizzato, carico i file su Thunderbit, lascio che l’AI estragga le tabelle e le esporto in CSV. Poi unisco tutto in Python per un’analisi di mercato completa.
Oppure, se sto creando una lista di lead per le vendite, uso Python per estrarre gli URL aziendali, poi sfrutto gli estrattori email e telefono di Thunderbit (funzionalità gratuite!) per recuperare i contatti da ogni sito—senza impazzire con le regex.
Estrai dati non strutturati con Thunderbit AI
Costruire un Flusso di Lavoro Sostenibile: Dal Codice alla Pipeline
Uno script estemporaneo può bastare per un’esigenza occasionale, ma la maggior parte delle aziende ha bisogno di processi continuativi. Ecco come strutturo una pipeline di scraping scalabile e affidabile:
Il Framework CCCD: Crawl, Collect, Clean, Debug
- Crawl: Raccogli tutti gli URL target (da sitemap, pagine di ricerca o liste).
- Collect: Estrai i dati da ogni URL (con Python, Thunderbit o entrambi).
- Clean: Normalizza, deduplica e valida i dati.
- Debug/Monitor: Registra ogni esecuzione, gestisci errori e imposta alert per anomalie o fallimenti.
Visualizza il tutto come una pipeline:
URL → [Crawler] → [Scraper] → [Cleaner] → [Exporter] → [Piattaforma Business]
Pianificazione e Monitoraggio
- Con Python: Usa cron, Airflow o scheduler cloud per eseguire gli script a intervalli regolari. Registra i log, invia alert via email o Slack in caso di errori.
- Con Thunderbit: Sfrutta il pianificatore integrato—basta scrivere “ogni lunedì alle 9:00” e Thunderbit eseguirà lo scraping in cloud ed esporterà i dati dove ti servono.
Documentazione e Passaggio di Consegne
Tieni il codice sotto controllo versione (Git), documenta il flusso di lavoro e assicurati che almeno un’altra persona sappia come eseguire o aggiornare la pipeline. Per workflow misti Python/Thunderbit, annota quale strumento gestisce quale sito e dove finiscono i dati (es. “Thunderbit estrae il Sito C su Google Sheets, Python unisce tutti i dati settimanalmente”).
Etica e Conformità: Scraping Responsabile nel 2025
Un grande potere di scraping comporta grandi responsabilità. Ecco come restare nel rispetto delle regole e delle buone pratiche:
Robots.txt e Rate Limiting
- Controlla robots.txt: Esamina sempre il file robots.txt del sito per percorsi vietati e ritardi richiesti. Usa il modulo
robotparserdi Python per automatizzare i controlli. - Scraping Educato: Inserisci pause tra le richieste, soprattutto se è specificato un
Crawl-delay. Non sovraccaricare mai un sito con richieste troppo rapide. - User-Agent: Identifica sempre il tuo scraper in modo trasparente. Non fingere di essere Googlebot o un altro browser.
Privacy dei Dati e Conformità
- GDPR/CCPA: Se estrai dati personali (nomi, email, numeri di telefono), sei responsabile della loro gestione secondo le normative sulla privacy. Raccogli solo ciò che serve, proteggi i dati e sii pronto a cancellarli su richiesta.
- Termini di Servizio: Non estrarre dati da aree protette da login senza autorizzazione. Molti ToS vietano l’accesso automatizzato—violare queste regole può portare a ban o conseguenze legali.
- Solo Dati Pubblici: Limita lo scraping a dati pubblicamente accessibili. Non tentare di estrarre informazioni private, protette da copyright o sensibili.
Checklist di Conformità
- Controllato robots.txt per regole e ritardi
- Inserito rate limiting e User-Agent personalizzato
- Estrazione solo di dati pubblici e non sensibili
- Gestione dei dati personali conforme alle leggi sulla privacy
- Nessuna violazione di ToS o copyright
Errori Comuni e Consigli di Debug: Rendere lo Scraping Affidabile
Anche i migliori scraper incontrano ostacoli. Ecco i problemi più frequenti—e come li affronto:
| Tipo di Errore | Sintomo/Messaggio | Consiglio di Debug |
|---|---|---|
| HTTP 403/429/500 | Blocco, rate limit o errore server | Controlla gli header, rallenta, ruota gli IP o usa proxy. Rispetta i ritardi di crawling. |
| Dati Mancanti/NoneType | Dati non trovati nell’HTML | Stampa e ispeziona l’HTML. Forse la struttura è cambiata o sei stato bloccato. |
| Dati Generati da JavaScript | Dati assenti nell’HTML statico | Usa Selenium/Playwright o trova la chiamata API sottostante. |
| Problemi di Parsing/Encoding | Errori Unicode, caratteri strani | Imposta la codifica corretta, usa .text o html.unescape(). |
| Duplicati/Incoerenze | Dati ripetuti o non corrispondenti | Deduplica tramite ID univoco o URL. Verifica la completezza dei campi. |
| Anti-Bot/CAPTCHA | Pagina CAPTCHA o login richiesto | Rallenta, usa automazione browser o passa a Thunderbit/AI per i casi più complessi. |
Flusso di Debug:
- Stampa l’HTML grezzo quando qualcosa non va.
- Usa gli strumenti DevTools del browser per confrontare ciò che vede lo script con il browser.
- Registra ogni passaggio—URL, codici di stato, numero di elementi estratti.
- Fai test su un piccolo campione prima di scalare.
Idee Avanzate: Progetti per Migliorare lo Scraping con Python
Vuoi mettere in pratica le best practice? Ecco alcuni progetti reali da provare:
1. Dashboard di Monitoraggio Prezzi per E-commerce
Estrai prezzi e disponibilità da Amazon, eBay e Walmart. Gestisci anti-bot, contenuti dinamici ed esporta ogni giorno su Google Sheets per analisi delle tendenze. Usa i template istantanei di Thunderbit per risultati rapidi.
2. Aggregatore di Offerte di Lavoro
Raccogli annunci da Indeed e portali di nicchia. Estrai titoli, aziende, sedi e date di pubblicazione. Gestisci la paginazione e deduplica tramite ID annuncio. Pianifica esecuzioni giornaliere ed esporta su Airtable.
3. Estrazione Contatti per Lead Generation
Data una lista di URL aziendali, estrai email e numeri di telefono da homepage e pagine contatti. Usa regex in Python o gli estrattori gratuiti di Thunderbit per risultati immediati. Esporta in Excel per il team commerciale.
4. Comparatore di Annunci Immobiliari
Estrai annunci da Zillow e Realtor.com per una specifica area. Normalizza indirizzi e prezzi, confronta le tendenze e visualizza i risultati su Google Sheets.
5. Monitoraggio delle Citazioni sui Social
Tieni traccia delle menzioni del brand su Reddit tramite la loro API JSON. Aggrega il numero di post, analizza il sentiment ed esporta dati temporali per insight di marketing.
Conclusione: I Punti Chiave dello Scraping con Python nel 2025
Ricapitoliamo gli aspetti fondamentali:
- Lo scraping web è più importante che mai per intelligence, vendite e operations. Il web è una miniera d’oro—se sai come estrarre i dati.
- Python è il tuo coltellino svizzero: Parti semplice con
requestseBeautifulSoup, scala con Scrapy e usa l’automazione browser per siti dinamici. - Gli strumenti AI come Thunderbit sono la tua arma segreta per dati non strutturati, complessi o per scraping senza codice. Combina Python e AI per la massima efficienza.
- Le best practice fanno la differenza: Analizza prima, scrivi codice modulare, gestisci gli errori, pulisci i dati e automatizza il flusso di lavoro.
- La conformità non è opzionale: Controlla sempre robots.txt, rispetta le leggi sulla privacy e agisci in modo etico.
- Resta flessibile: Il web cambia—monitora i tuoi scraper, fai debug spesso e sii pronto ad aggiornare la strategia.
Il futuro dello scraping è ibrido, etico e orientato al business. Che tu sia un principiante o un esperto, continua a imparare, sii curioso e lascia che i dati guidino il tuo prossimo successo.
Appendice: Risorse e Strumenti per lo Scraping con Python
Ecco la mia lista di riferimento per imparare e risolvere problemi:
- Documentazione Requests – HTTP per tutti, con tutte le funzionalità.
- Documentazione BeautifulSoup – Impara a fare parsing HTML come un professionista.
- Documentazione Scrapy – Per scraping su larga scala e in produzione.
- Selenium con Python / Playwright per Python – Per automazione browser e contenuti dinamici.
- Thunderbit Chrome Extension – L’estrattore web AI più semplice per utenti business.
- Thunderbit Blog – Tutorial, casi d’uso e best practice per scraping AI.
- Guida Legale di AIMultiple – Aggiornamenti su conformità ed etica.
- Stack Overflow / Reddit r/webscraping** – Domande e risposte dalla community.
E se vuoi vedere come Thunderbit può semplificare la tua vita da estrattore web, dai un’occhiata al nostro canale YouTube per demo e approfondimenti.
Domande Frequenti
1. Qual è la migliore libreria Python per lo scraping nel 2025?
Per pagine statiche e piccoli progetti, requests + BeautifulSoup resta la combinazione vincente. Per scraping su larga scala o multi-pagina, Scrapy è la scelta ideale. Per contenuti dinamici, usa Selenium o Playwright. Per dati non strutturati o complessi, strumenti AI come Thunderbit sono insostituibili.
2. Come gestire siti dinamici o ricchi di JavaScript?
Utilizza strumenti di automazione browser come Selenium o Playwright per renderizzare la pagina ed estrarre i dati. In alternativa, controlla la scheda Network per chiamate API che restituiscono JSON—spesso sono più semplici e affidabili da estrarre.
3. Lo scraping web è legale?
L’estrazione di dati pubblici è generalmente legale negli USA, ma controlla sempre il robots.txt, rispetta i termini del sito e le normative sulla privacy come GDPR/CCPA. Non estrarre mai dati privati, protetti da copyright o sensibili.
4. Come posso automatizzare e pianificare i miei flussi di scraping?
Per script Python, usa cron, Airflow o scheduler cloud. Per automazione senza codice, Thunderbit offre la pianificazione integrata—basta descrivere la frequenza in italiano e lasciare che lavori in cloud.
5. Cosa fare se il mio scraper smette di funzionare?
Per prima cosa, verifica se la struttura del sito è cambiata o se sei stato bloccato (HTTP 403/429). Controlla l’HTML, aggiorna i selettori, rallenta le richieste e verifica la presenza di sistemi anti-bot. Se i problemi persistono, prova le funzionalità AI di Thunderbit o passa all’automazione browser.
Buon scraping—che i tuoi dati siano sempre puliti, conformi e pronti all’uso. Se vuoi scoprire come Thunderbit può integrarsi nel tuo workflow, scarica l’estensione Chrome e provala subito. E se cerchi altri consigli, il Thunderbit Blog è sempre a disposizione.
Prova gratis Thunderbit Estrattore Web AI Get Started Free




