

Siamo onesti: nessuno si sveglia la mattina entusiasta di copiare e incollare 500 righe di prezzi dei prodotti in un foglio di calcolo. (Se lo fai, mi complimento per la tua resistenza e ti consiglio un buon tutore per il polso.) Che tu lavori nelle vendite, nelle operations o semplicemente cerchi di tenere la tua azienda un passo avanti rispetto alla concorrenza, probabilmente hai già provato la fatica di raccogliere dati dai siti web. Oggi il mondo gira intorno ai dati del web, e la domanda di estrazione automatizzata sta esplodendo: il mercato dei software di web scraping dovrebbe superare gli 11 miliardi di dollari entro il 2032.
Ho passato anni nelle trincee del SaaS e dell’automazione, e ne ho viste di tutti i colori: dalle eroiche macro di Excel agli script Python rattoppati alle 2 di notte. In questa guida ti mostrerò come usare un parser HTML Python per estrarre dati reali (sì, prenderemo insieme le valutazioni dei film di IMDb), e ti spiegherò anche perché, nel 2026, esiste un modo migliore: strumenti basati su AI come Thunderbit, che ti permettono di saltare il codice e arrivare subito agli insight.
Cos’è un parser HTML e perché usarlo in Python?
Partiamo dalle basi: cosa fa davvero un parser HTML? Pensalo come il tuo bibliotecario personale del web. Legge il codice HTML disordinato dietro una pagina web e lo organizza in una struttura ordinata, simile a un albero. In questo modo puoi estrarre solo i dati che ti servono — titoli, prezzi, link — senza perderti in un mare di parentesi angolari e div.
Python è il linguaggio di riferimento per questo lavoro, e per una buona ragione. È leggibile, adatto ai principianti e ha un ecosistema enorme di librerie per il web scraping e il parsing. In effetti, Python è di gran lunga il linguaggio più usato per il web scraping, grazie alla sua curva di apprendimento dolce e al forte supporto della community.
La formazione dei parser HTML in Python
Ecco i principali strumenti che incontrerai quando analizzi HTML in Python:
- BeautifulSoup: la scelta classica e adatta ai principianti. È ancora mantenuta attivamente —
beautifulsoup44.14.3 è stato pubblicato su PyPI alla fine del 2025 — quindi non stai leggendo una lezione su una libreria obsoleta. - lxml: veloce e potente, con funzionalità di query avanzate.
- html5lib: estremamente tollerante verso HTML disordinato, proprio come il tuo browser.
- PyQuery: ti permette di usare selettori in stile jQuery in Python.
- HTMLParser: il parser integrato di Python, sempre disponibile ma un po’ essenziale.
Ognuno ha le sue particolarità, ma tutti ti aiutano a trasformare HTML grezzo in dati strutturati.
Casi d’uso chiave: come i parser HTML Python aiutano le aziende
L’estrazione di dati dal web non è solo roba da tecnici o data scientist. È diventata un’attività aziendale fondamentale, soprattutto nelle vendite e nelle operations. Ecco perché:
| Caso d’uso (settore) | Dati tipicamente estratti | Risultato di business |
|---|---|---|
| Monitoraggio dei prezzi (Retail) | Prezzi dei concorrenti, livelli di stock | Prezzi dinamici, margini migliori (fonte) |
| Intelligence sui prodotti dei concorrenti | Inserzioni, recensioni, disponibilità | Individuazione delle lacune, generazione di lead (fonte) |
| Generazione di lead (vendite B2B) | Nomi aziende, email, contatti | Prospecting automatizzato, crescita del funnel (fonte) |
| Sentiment di mercato (Marketing) | Post social, recensioni, valutazioni | Feedback in tempo reale, individuazione dei trend (fonte) |
| Aggregazione immobiliare | Annunci, prezzi, informazioni sugli agenti | Analisi di mercato, strategia di prezzo (fonte) |
| Intelligence sul recruiting | Profili candidati, stipendi | Ricerca di talenti, benchmark retributivo (fonte) |
In breve: se stai ancora copiando i dati a mano, stai lasciando sul tavolo tempo e denaro.
Il toolkit dei parser HTML Python: confronto tra le librerie più popolari
Passiamo alla pratica. Ecco un rapido confronto delle librerie parser HTML Python più popolari, così puoi scegliere quella giusta per il tuo lavoro:
| Libreria | Facilità d’uso | Velocità | Flessibilità | Esigenze di manutenzione | Ideale per |
|---|---|---|---|---|---|
| BeautifulSoup | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | Media | Principianti, HTML disordinato |
| lxml | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Media | Velocità, XPath, documenti grandi |
| html5lib | ⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ | Basse | Parsing simile al browser, HTML rotto |
| PyQuery | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | Media | Fan di jQuery, selettori CSS |
| HTMLParser | ⭐⭐⭐ | ⭐⭐⭐ | ⭐ | Basse | Attività semplici, integrato |
BeautifulSoup: la scelta adatta ai principianti
BeautifulSoup è il “hello world” del parsing HTML. La sua sintassi è intuitiva, la documentazione è ottima ed è tollerante con HTML brutto e malformato (scopri di più). Il lato negativo? Non è il più veloce, soprattutto su pagine grandi o complesse, e non supporta subito selettori avanzati come XPath.
lxml: veloce e potente
Se ti serve velocità o vuoi usare query XPath, lxml fa per te (dettagli). È basato su librerie C, quindi è velocissimo, ma può essere più complicato da installare e ha una curva di apprendimento più ripida.
Altre opzioni: html5lib, PyQuery e HTMLParser
- html5lib: analizza l’HTML esattamente come il browser — ottimo per markup rotto o strano, ma lento (confronto).
- PyQuery: ti permette di usare selettori in stile jQuery in Python, utile se arrivi dal front-end (vedi documentazione).
- HTMLParser: l’opzione integrata di Python — veloce e sempre disponibile, ma meno ricca di funzionalità.
Step 1: configurare l’ambiente per il parser HTML Python
Prima di poter analizzare qualsiasi cosa, devi configurare il tuo ambiente Python. Ecco come fare:
-
Installa Python: scaricalo da python.org se non ce l’hai già.
-
Installa pip: di solito è incluso con Python 3.4+, ma puoi verificarlo eseguendo
pip --versionnel terminale. -
Installa le librerie (useremo BeautifulSoup e requests per questo tutorial):
pip install beautifulsoup4 requests lxmlbeautifulsoup4è il parser.requeststi permette di scaricare le pagine web.lxmlè un parser veloce che BeautifulSoup può usare internamente.
-
Controlla l’installazione:
python -c "import bs4, requests, lxml; print('Tutto ok!')"
Suggerimenti per la risoluzione dei problemi:
- Se ricevi errori di autorizzazione, prova
pip install --user ... - Su Mac/Linux, potresti dover usare
python3epip3 - Se vedi “ModuleNotFoundError”, ricontrolla l’ortografia e l’ambiente Python.
Step 2: analizzare la tua prima pagina web con Python
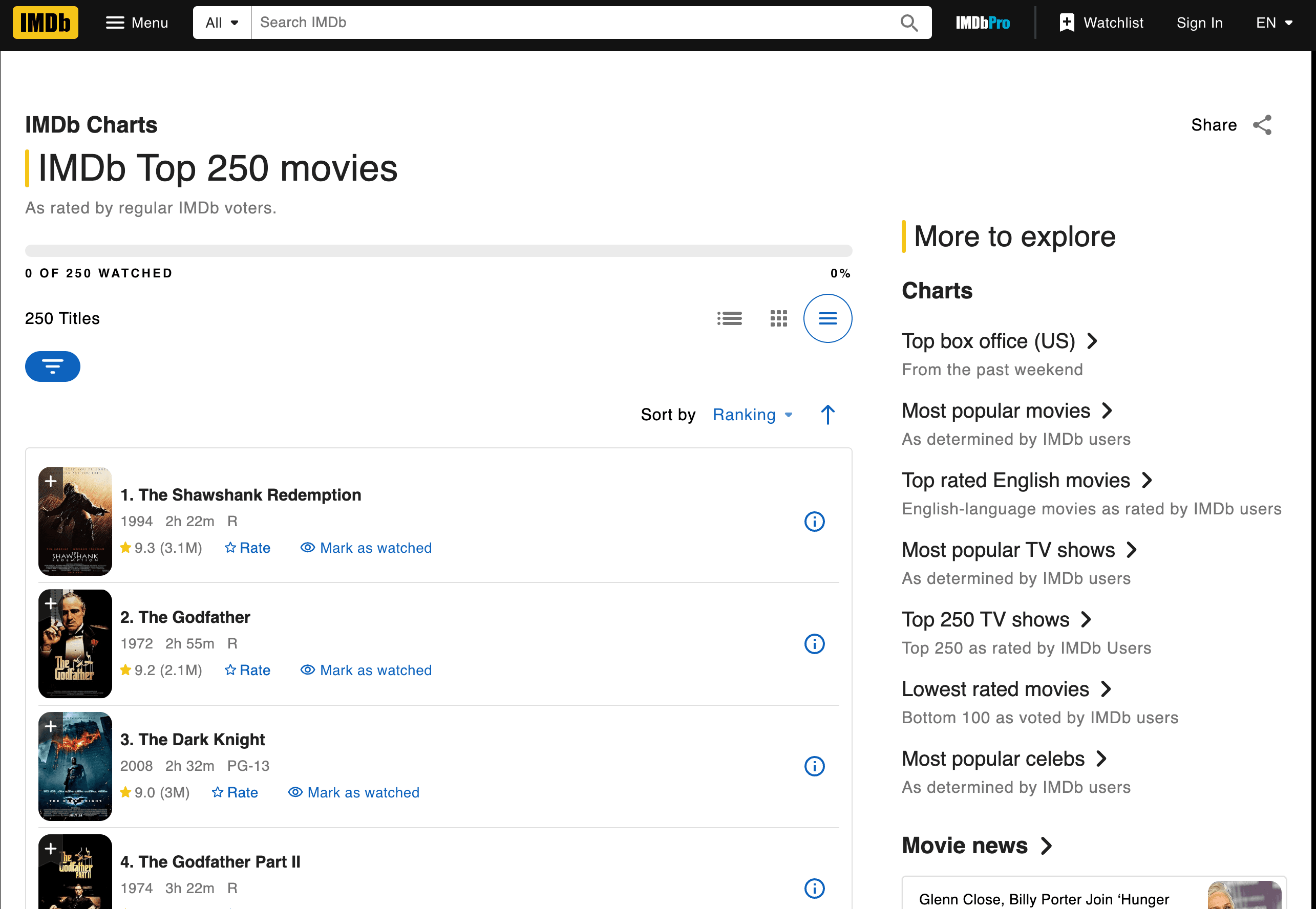
Mettiamo le mani in pasta e estraiamo i film Top 250 di IMDb. Recupereremo titoli, anni e valutazioni.
Recuperare e analizzare la pagina
Ecco uno script passo dopo passo. Prima di copiarlo, una nota importante: IMDb ha ridisegnato la pagina Top 250 nel giugno 2023, quindi i vecchi selettori td.titleColumn / td.ratingColumn che trovi ancora in alcuni tutorial non corrispondono più a nulla. Il markup attuale usa classi con prefisso ipc- generate dal loro sistema di componenti, e IMDb ha ristrutturato la pagina ancora alcune volte da allora (compresa la metà del 2025), quindi conviene riaprire DevTools e riesaminare la pagina ogni volta che torni su questo esempio.
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/top/"
headers = {"User-Agent": "Mozilla/5.0"} # IMDb restituisce markup ridotto senza un vero UA
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, "html.parser")
# Ogni riga è un elemento lista sotto il contenitore della classifica
rows = soup.select("li.ipc-metadata-list-summary-item")
for i, row in enumerate(rows[:3], start=1):
title_el = row.select_one("h3.ipc-title__text")
year_el = row.select_one("span.cli-title-metadata-item")
rating_el = row.select_one("span.ipc-rating-star--rating")
title = title_el.get_text(strip=True) if title_el else None
# Il testo dell'h3 torna come "1. The Shawshank Redemption" — rimuovi il prefisso della posizione
if title and ". " in title:
title = title.split(". ", 1)[1]
year = year_el.get_text(strip=True) if year_el else None
rating = rating_el.get_text(strip=True) if rating_el else None
print(f"{i}. {title} ({year}) -- Valutazione: {rating}")
Cosa succede qui?
- Usiamo
requests.get()per recuperare la pagina (con unUser-Agentcredibile — IMDb a volte restituisce una struttura ridotta ai clientpython-requestsprivi di UA reale). BeautifulSoupanalizza l’HTML.- Recuperiamo ogni riga del film tramite
li.ipc-metadata-list-summary-item, poi prendiamo il titolo (h3.ipc-title__text), l’anno (span.cli-title-metadata-item) e la valutazione (span.ipc-rating-star--rating) conselect_one(). - Estraiamo il testo di titolo, anno e valutazione, rimuovendo il numero di posizione iniziale (
"1. ") che IMDb incorpora nel testo del titolo.
Se vuoi qualcosa di più robusto rispetto all’inseguire il cambio dei nomi delle classi ogni pochi mesi, IMDb include anche un blocco <script type="application/ld+json"> nella stessa pagina con gli stessi dati in formato strutturato — puoi analizzarlo con json.loads(soup.find("script", type="application/ld+json").string) e scorrere l’array itemListElement. È l’approccio che sceglierei in produzione; la versione con i selettori CSS qui sopra è più semplice da spiegare ma più fragile.
Output:
1. The Shawshank Redemption (1994) -- Rating: 9.3
2. The Godfather (1972) -- Rating: 9.2
3. The Dark Knight (2008) -- Rating: 9.0
Estrarre i dati: trovare titoli, valutazioni e altro
Come ho fatto a capire quali tag e classi usare? Ho ispezionato l’HTML della pagina IMDb (clic destro > Ispeziona elemento nel browser). Cerca i pattern: qui, ogni riga del film si trova dentro un <li class="ipc-metadata-list-summary-item">, con il titolo sotto <h3 class="ipc-title__text"> e la valutazione sotto <span class="ipc-rating-star--rating">. Una cosa importante da tenere a mente: IMDb ha cambiato questo markup più di una volta (il layout td.titleColumn che trovi ancora in vecchie guide non funziona più dalla riprogettazione del giugno 2023), quindi considera sempre le stringhe esatte delle classi come esempi indicativi e riesamina la pagina prima di eseguire lo script.
Consiglio pratico: se stai facendo scraping su un altro sito, inizia sempre ispezionando la struttura HTML e identificando classi o tag unici.
Salvare ed esportare i risultati
Salviamo i dati in un file CSV:
import csv
movies = []
for i in range(len(title_cells)):
title_cell = title_cells[i]
rating_cell = rating_cells[i]
title = title_cell.a.text
year = title_cell.span.text.strip("()")
rating = rating_cell.strong.text if rating_cell.strong else rating_cell.text
movies.append([title, year, rating])
with open('imdb_top250.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['Titolo', 'Anno', 'Valutazione'])
writer.writerows(movies)
Consigli per la pulizia dei dati:
- Usa
.strip()per rimuovere gli spazi bianchi. - Gestisci i dati mancanti con controlli
if. - Per esportare in Excel, puoi aprire il CSV in Excel oppure usare
pandasper scrivere file.xlsx.
Step 3: gestire le modifiche HTML e le sfide di manutenzione
Qui le cose si fanno serie. I siti web adorano cambiare il loro layout — a volte solo per tenere sulle spine gli scraper (o almeno così sembra). Se IMDb cambia class="titleColumn" in class="movieTitle", il tuo script improvvisamente restituirà risultati vuoti. Ci sono passato, l’ho già debuggato.
Quando gli script si rompono: problemi reali
Problemi comuni:
- Selettori non trovati: il codice non riesce a trovare il tag/la classe che hai specificato.
- Risultati vuoti: la struttura della pagina è cambiata oppure il contenuto ora si carica tramite JavaScript.
- Errori HTTP: il sito ha aggiunto misure anti-bot.
Passi per la risoluzione dei problemi:
- Controlla che l’HTML che stai analizzando corrisponda a quello che vedi nel browser.
- Aggiorna i selettori per adattarli alla nuova struttura.
- Se il contenuto si carica dinamicamente, potresti dover passare a uno strumento di automazione del browser (come Selenium) oppure trovare un endpoint API.
Il vero problema? Se fai scraping su 10, 50 o 500 siti diversi, potresti finire per passare più tempo a sistemare gli script che ad analizzare davvero i dati (leggi le esperienze degli sviluppatori).
Step 4: scalare il tutto — i costi nascosti del parsing HTML Python manuale
Mettiamo che tu voglia estrarre dati non solo da IMDb, ma anche da Amazon, Zillow, LinkedIn e una dozzina di altri siti. Ognuno richiede il suo script. E ogni volta che un sito cambia, torni nell’editor di codice.
I costi nascosti:
- Manodopera di manutenzione: alcuni stimano che la manutenzione costi 10 volte il lavoro iniziale di sviluppo.
- Infrastruttura: ti servono proxy, gestione degli errori e monitoraggio.
- Prestazioni: scalare significa gestire concorrenza, limiti di richiesta e altro ancora.
- Garanzia di qualità: più script = più punti in cui qualcosa può rompersi.
Per i team non tecnici, questo diventa rapidamente insostenibile. È come assumere una squadra di stagisti per copiare e incollare dati tutto il giorno — solo che gli stagisti sono script Python e si mettono in malattia ogni volta che un sito web cambia.
Una nota rapida sugli agenti di coding AI
Prima di passare agli strumenti no-code, vale la pena citare una via di mezzo che ai tempi in cui sono stati scritti molti tutorial “impara BeautifulSoup” praticamente non esisteva: gli agenti di coding AI. Strumenti come Claude Code o Cursor prendono volentieri una descrizione in inglese (“recupera il Top 250 di IMDb, estrai titolo / anno / valutazione in un CSV”) e ti generano in un colpo solo uno script funzionante requests + BeautifulSoup, incluso il tipo di pulizia dei selettori che abbiamo appena fatto a mano. Per i flussi browser in linguaggio naturale — login, paginazione, gestione dei banner cookie — una libreria come Browser Use può pilotare un browser headless direttamente da un prompt.
Non eliminano però le parti difficili. Rate limit, robots.txt, schermate di accesso e difese anti-bot restano comunque un tuo problema, e quando un selettore si rompe in silenzio (come è successo a IMDb) devi ancora capire cosa ha generato l’agente e correggerlo. Quindi anche con un agente nel flusso, capire il workflow del parser HTML in questo tutorial è ciò che ti permette di fare debug dell’output invece di fissare elenchi vuoti.
Oltre i parser HTML Python: scopri Thunderbit, l’alternativa potenziata dall’AI
Ed ecco la parte interessante. E se potessi saltare il codice, saltare la manutenzione e ottenere semplicemente i dati che ti servono — indipendentemente da come cambia il sito?
È esattamente quello che abbiamo costruito con Thunderbit. È un’estensione Chrome AI web scraper che ti permette di estrarre dati strutturati da qualsiasi sito in due clic. Niente Python, niente script, niente mal di testa.
Parser HTML Python vs. Thunderbit: confronto affiancato
| Aspetto | Parser HTML Python | Thunderbit (vedi i prezzi) |
|---|---|---|
| Tempo di configurazione | Alto (installazione, codice, debug) | Basso (installa l’estensione, clicca) |
| Facilità d’uso | Richiede programmazione | Nessun codice: punta e clicca |
| Manutenzione | Alta (gli script si rompono spesso) | Bassa (l’AI si adatta automaticamente) |
| Scalabilità | Complessa (script, proxy, infrastruttura) | Integrata (cloud scraping, job in batch) |
| Arricchimento dati | Manuale (serve altro codice) | Integrato (etichettatura, pulizia, traduzione, sottopagine) |
Perché costruire, quando puoi risolvere il problema con l’AI?
Perché scegliere l’AI per l’estrazione di dati dal web?
L’agente AI di Thunderbit legge la pagina, capisce la struttura e si adatta quando le cose cambiano. È come avere uno stagista superdotato che non dorme mai e non si lamenta mai quando cambiano i nomi delle classi.
- Nessun codice richiesto: può usarlo chiunque — vendite, operations, marketing, chiunque.
- Scraping in batch: estrai oltre 10.000 pagine nel tempo che servirebbe per debuggare uno script Python.
- Nessuna manutenzione: l’AI gestisce cambi di layout, paginazione, sottopagine e altro ancora.
- Arricchimento dati: pulisci, etichetta, traduci e riassumi i dati mentre li estrai.
Il rovescio della medaglia del flusso BeautifulSoup che abbiamo appena visto è proprio il tipo di fragilità che incontriamo con i selettori IMDb qui sopra: quando la pagina si riorganizza, lo script restituisce risultati vuoti senza avvisare, e tu passi il pomeriggio in DevTools invece che a guardare i dati. Un AI scraper no-code nasconde quel passaggio dietro il proprio livello di inferenza; è un vero compromesso (stai affidando a qualcun altro la correttezza dell’estrazione), non una bacchetta magica.
Passo dopo passo: estrarre le valutazioni dei film IMDb con Thunderbit
Vediamo come Thunderbit gestisce lo stesso task su IMDb:
- Installa la Thunderbit Chrome Extension.
- Vai alla pagina Top 250 di IMDb.
- Fai clic sull’icona di Thunderbit.
- Fai clic su “Suggerisci campi con AI.” Thunderbit leggerà la pagina e suggerirà le colonne (Titolo, Anno, Valutazione).
- Rivedi o modifica le colonne, se necessario.
- Fai clic su “Estrai.” Thunderbit estrarrà istantaneamente tutte le 250 righe.
- Esporta in Excel, Google Sheets, Notion o CSV — come preferisci.
Tutto qui. Niente codice, niente debug, niente momenti in cui ti chiedi “perché questa lista è vuota?”.
Vuoi vedere tutto in azione? Dai un’occhiata al canale YouTube di Thunderbit per le guide pratiche, oppure leggi la nostra guida passo dopo passo per estrarre dati da Amazon per un altro esempio reale.
Conclusione: scegliere lo strumento giusto per le tue esigenze di dati web
I parser HTML Python come BeautifulSoup e lxml sono potenti, flessibili e gratuiti. Sono ideali per gli sviluppatori che vogliono il pieno controllo e non temono di rimboccarsi le maniche. Ma hanno una curva di apprendimento ripida, richiedono manutenzione continua e comportano costi nascosti — soprattutto quando le esigenze di scraping crescono.
Per chi fa business, per i team commerciali e per chiunque voglia solo i dati, non il codice, strumenti basati su AI come Thunderbit sono una boccata d’aria fresca. Ti permettono di estrarre, pulire e arricchire i dati del web su larga scala, senza scrivere codice e senza manutenzione.
Il mio consiglio? Usa Python se ami programmare e ti serve una personalizzazione totale. Ma se tieni al tuo tempo (e alla tua sanità mentale), prova Thunderbit. Perché costruire e babysitterare script quando puoi lasciare che sia l’AI a fare il lavoro pesante?
Vuoi saperne di più su web scraping, estrazione dati e automazione AI? Approfondisci altri tutorial sul blog di Thunderbit, come Come estrarre dati da un sito web in Excel usando l’AI o I migliori strumenti e software per il web scraping nel 2025.




