

Qualche tempo fa, se mi avessi chiesto come automatizzare un compito online—tipo raccogliere i prezzi dei prodotti da un sito rivale o fare test sull’interfaccia di un sito—ti avrei subito parlato di Selenium o Puppeteer, ti avrei passato un paio di snippet e ti avrei detto “in bocca al lupo”. Ma oggi la musica è cambiata. L’automazione del browser e l’estrazione dati dal web sono diventate una vera mania, soprattutto per chi lavora in sales, marketing, ecommerce e immobiliare. Tutti vogliono i dati dal web, ma nessuno ha voglia di diventare programmatore per ottenerli.
La realtà è che strumenti come Puppeteer, Selenium e Playwright sono ancora fondamentali per i team tecnici, ma chi lavora nel business cerca altro: soluzioni senza codice, che non si rompano ogni volta che il sito cambia e che non richiedano l’intervento degli sviluppatori. Qui entrano in scena strumenti no-code con AI come Thunderbit, che stanno davvero cambiando le regole del gioco. Ma prima di guardare avanti, diamo un’occhiata ai classici e al perché di questo cambiamento.
Cos’è Puppeteer? Una panoramica rapida
Partiamo da Puppeteer. Se ti è mai venuta voglia di comandare Chrome o Chromium tramite codice—aprire pagine, cliccare bottoni, fare screenshot o estrarre dati—Puppeteer è la libreria Node.js che fa per te. È come avere un telecomando per il browser, ma invece dei tasti usi JavaScript.
Cosa ci fai con Puppeteer:
- Test end-to-end automatizzati per web app (tipo: “Il checkout funziona ancora?”)
- Web scraping—estrazione dati da siti senza API
- Creazione di screenshot o PDF delle pagine web (perfetto per archiviare o fare report)
- Simulazione di interazioni utente per controlli di performance o SEO
Il vero asso nella manica di Puppeteer è la sua integrazione con Chrome. Parla la stessa lingua del browser, è veloce, affidabile e gestisce senza problemi le web app moderne, i contenuti dinamici e molto altro. Ma c’è un limite: praticamente funziona solo con Chrome. Se vuoi automatizzare Firefox o Safari, non è la scelta giusta.
Cos’è Selenium? Il veterano dell’automazione browser
Selenium è il nonno dell’automazione browser. Esiste da quando “Web 2.0” era ancora una novità. Non è solo una libreria, ma un vero ecosistema, con supporto a diversi linguaggi di programmazione (Python, Java, C#, JavaScript, Ruby e altri) e praticamente a tutti i browser principali (Chrome, Firefox, Safari, Edge, persino Internet Explorer per i nostalgici).
Perché Selenium è ancora così usato:
- Supporto multi-linguaggio: Puoi usare il linguaggio che preferisci, senza dover imparare JavaScript se sei un fan di Python.
- Compatibilità multi-browser: Automatizza Chrome, Firefox, Safari, Edge e altri.
- Community enorme: Tantissime guide, plugin e integrazioni.
- Testing UI su larga scala: È la base dell’automazione dei test per tanti team QA.
Il lato negativo? L’architettura di Selenium è un po’ vecchia. Usa un modello “driver + API”, quindi devi sempre gestire driver, versioni dei browser e spesso risolvere problemi di compatibilità. È potente, ma può sembrare di guidare una macchina col cambio manuale nell’epoca delle auto elettriche.
Puppeteer vs Selenium: le differenze chiave
Come si confrontano Puppeteer e Selenium? Ecco una panoramica.
| Caratteristica | Puppeteer | Selenium |
|---|---|---|
| Supporto linguaggi | Solo JavaScript/Node.js | Molti (Python, Java, C#, JS, Ruby, ecc.) |
| Supporto browser | Chrome/Chromium (Firefox sperimentale) | Chrome, Firefox, Safari, Edge, IE |
| Performance | Veloce, ottimizzato per Chrome | Buona, ma può essere più lento per l’astrazione |
| Facilità d’uso | API semplice, sintassi moderna | Più complesso, curva di apprendimento ripida |
| Community/Ecosistema | In crescita, ma più piccola di Selenium | Enorme, maturo, molte risorse |
| Utilizzi principali | Test, scraping, screenshot, PDF | Test, scraping, automazione |
A livello tecnico:
- Entrambi usano un approccio “driver + API”.
- Puppeteer è focalizzato su Chrome, integrato con il protocollo DevTools.
- Selenium è agnostico rispetto al browser, grazie a WebDriver.
In breve:
Se lavori solo con Chrome e ti piace JavaScript, Puppeteer è rapido e moderno. Se ti serve flessibilità—più browser, più linguaggi—Selenium è il mulo da lavoro. Ma entrambi richiedono di scrivere e mantenere script, e nessuno dei due “capisce” davvero la pagina oltre al DOM.
Playwright: l’alternativa di nuova generazione a Puppeteer
Ecco Playwright, la risposta di Microsoft alle esigenze di automazione del web di oggi. Se Puppeteer è una sportiva per Chrome, Playwright è il SUV 4x4 che va ovunque.
Perché Playwright piace a tutti:
- Vero supporto multi-browser: Chrome, Firefox, Safari, Edge—tutto da una sola API.
- Concorrenza integrata: Esegui più contesti browser in parallelo, perfetto per pipeline CI/CD.
- Auto-waiting avanzato: Basta hack “wait for element”—Playwright aspetta da solo che gli elementi siano pronti.
- Selettori potenti: Puoi selezionare elementi per testo, ruolo o attributi ARIA.
- Funzionalità moderne: Supporto nativo per download, upload, geolocalizzazione, permessi e altro.
Ho visto team adottare Playwright a ritmo serrato per test affidabili, veloci e facili da mantenere—soprattutto in ambienti CI/CD. È ottimo anche per scraping, ma come Puppeteer e Selenium, resta uno strumento per chi sa programmare. Se non ami scrivere script, rischi di trovarti bloccato.
Alternative a Playwright: cos’altro c’è in giro?
Diciamolo: il mondo dell’automazione browser è affollato. Ecco altri nomi che potresti incontrare e come si posizionano:
-
Cypress:
Pensato per il testing front-end, Cypress offre un’interfaccia intuitiva e una bella esperienza per gli sviluppatori, ma è limitato ai browser basati su Chrome e non gestisce bene multi-tab o cross-origin. Perfetto per i test, meno per scraping o automazione fuori dal testing. Scopri di più su Cypress.
-
WebdriverIO:
Implementazione Node.js del protocollo WebDriver, WebdriverIO è flessibile, supporta più browser e ha un ricco ecosistema di plugin. Usato sia per test che per scraping, ma sempre tramite codice. Sito ufficiale WebdriverIO.
-
TestCafe:
Un altro strumento basato su JavaScript, TestCafe è facile da configurare e funziona su qualsiasi browser che supporti HTML5. Meno popolare di Cypress o Playwright, ma valido per automazioni semplici. Sito ufficiale TestCafe.
-
Strumenti AI come Thunderbit:
Qui le cose si fanno interessanti per chi lavora nel business. Thunderbit adotta un approccio completamente diverso: niente codice, niente script, solo point & click e lascia che l’AI faccia il lavoro pesante. Tra poco ti spiego come funziona, ma se non sei sviluppatore, questa è la direzione da seguire.
Tabella riassuntiva: strumenti con e senza codice
| Strumento | Supporto browser | Linguaggi | Richiede codice | Ideale per |
|---|---|---|---|---|
| Puppeteer | Chrome/Chromium | JavaScript | Sì | Dev, automazione Chrome |
| Selenium | Tutti i browser principali | Molti | Sì | Dev, test cross-browser |
| Playwright | Tutti i browser principali | JavaScript, ecc. | Sì | Automazione moderna, CI/CD |
| Cypress | Famiglia Chrome | JavaScript | Sì | Test front-end |
| WebdriverIO | Tutti i browser principali | JavaScript | Sì | Automazione flessibile |
| TestCafe | Tutti i browser principali | JavaScript | Sì | Automazione test semplice |
| Thunderbit | Tutti i browser principali* | N/A (No code) | No | Business, scraping |
- Thunderbit funziona direttamente nel browser, quindi ovunque funzioni Chrome.
Dall’automazione browser allo scraping intelligente: il metodo Thunderbit
Estrai dati da qualsiasi sito con l’AI Get Started Free
Qui l’appassionato di automazione che è in me si esalta. I framework classici come Puppeteer, Selenium e Playwright lavorano manipolando il DOM—usano selettori per trovare elementi, cliccare bottoni ed estrarre testo. Ma non “capiscono” davvero cosa c’è nella pagina. Cambia una classe, sposta un bottone o carica contenuti in modo asincrono e lo script si rompe in un attimo.
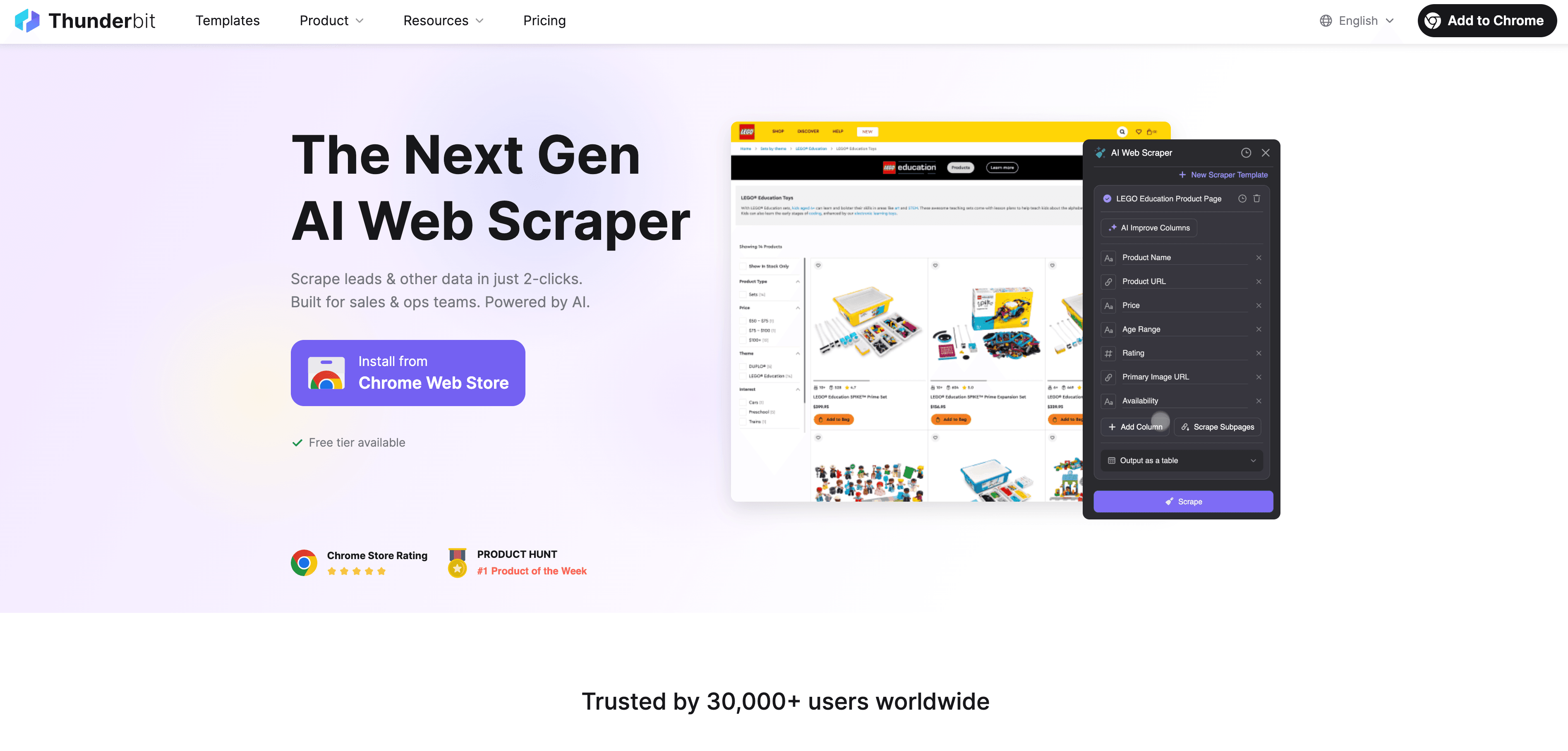
Thunderbit cambia tutto. Invece di limitarsi al DOM, l’AI di Thunderbit legge la pagina come farebbe una persona. Prima trasforma la pagina web in un formato Markdown strutturato, poi lo passa a un modello AI per una comprensione semantica. L’AI capisce il contesto, il significato dei campi e la logica dei dati—così distingue tra nome prodotto, prezzo e recensione, anche se l’HTML è un caos.
Cosa vuol dire in pratica?
- Scraping stabile su pagine complesse o dinamiche: Infinite scroll, pop-up o contenuti generati dagli utenti? Nessun problema.
- Niente più problemi con i selettori: L’AI si adatta ai cambi di layout, quindi non devi riscrivere script a ogni aggiornamento del sito.
- Estrazione semantica: Thunderbit estrae dati strutturati (tabelle, liste, info annidate) anche da pagine caotiche per uno scraper tradizionale.
Ho visto Thunderbit gestire Facebook Marketplace, sezioni commenti infinite e siti ecommerce con contenuti dinamici—situazioni che mettono in crisi la maggior parte degli scraper basati su codice. E lo fa con pochi click.
Perché i team business hanno bisogno di scraping web semantico e no-code
Cos’è il Data Scraping e come farlo nel 2025 Get Started Free
Diciamoci la verità: la maggior parte dei team sales, marketing, ecommerce e real estate non ha uno sviluppatore sempre a disposizione. E anche se c’è, probabilmente è impegnato su progetti più urgenti. Ecco cosa succede di solito con gli strumenti basati su codice:
- Manutenzione infinita degli script: Ogni volta che un sito cambia, qualcuno deve aggiornare i selettori o riscrivere gli script.
- Dipendenza dagli sviluppatori: Chi non è tecnico deve aspettare l’aiuto dell’IT.
- Curva di apprendimento ripida: Anche i framework “semplici” richiedono tempo per essere imparati e debug.
- Flussi fragili: Basta una piccola modifica sul sito target e tutto si blocca.
Thunderbit nasce per risolvere questi problemi. Ecco come:
- Scraping in 2 click: Basta cliccare su “AI Suggerisci Campi” e poi su “Estrai”. L’AI capisce cosa estrarre.
- AI Suggerisci Campi: Thunderbit legge la pagina e suggerisce le colonne e i tipi di dati giusti.
- Scraping di sottopagine: Ti serve estrarre dati da pagine collegate (es: dettagli prodotto o recensioni)? Thunderbit visita ogni sottopagina e arricchisce la tabella in automatico.
- Nessun codice, nessuno script: Può usarlo chiunque, senza competenze tecniche.
Tabella di confronto: esperienza utente business
| Caratteristica | Puppeteer/Selenium/Playwright | Thunderbit |
|---|---|---|
| Richiede codice | Sì | No |
| Manutenzione script | Frequente | Nessuna (AI si adatta) |
| Gestione contenuti dinamici | Script manuali | Comprensione semantica AI |
| Dati da sottopagine/collegamenti | Codice personalizzato | 1 click Sottopagine |
| Esportazione dati (Excel, Sheets) | Parsing manuale | Esportazione integrata, gratuita |
| Curva di apprendimento | Ripida | Minima |
| Ideale per | Sviluppatori, QA | Sales, Marketing, Operazioni, Real Estate |
Quando usare Puppeteer, Selenium, Playwright o Thunderbit? (Guida alla scelta)
Quale strumento scegliere? Ecco la mia opinione, dopo anni di automazione per team tecnici e business:
Usa Puppeteer, Selenium o Playwright se:
- Hai sviluppatori o QA dedicati.
- Ti servono flussi altamente personalizzati (es: test complessi, interazioni browser avanzate).
- Devi integrare con pipeline CI/CD o framework di test automatizzati.
- Il tuo team è a suo agio con la manutenzione del codice e la gestione degli script.
Usa Thunderbit se:
- Vuoi estrarre dati dai siti in modo rapido, senza codice.
- Il tuo team lavora in sales, marketing, ecommerce o real estate e hai bisogno dei dati subito, non dopo uno sprint.
- Sei stanco di script che si rompono a ogni cambiamento del sito.
- Devi gestire pagine web complesse, dinamiche o che cambiano spesso.
- Vuoi esportare i dati direttamente su Excel, Google Sheets, Airtable o Notion.
Matrice decisionale
| Scenario | Strumento migliore |
|---|---|
| Automazione browser personalizzata | Playwright, Puppeteer |
| Test UI cross-browser | Selenium, Playwright |
| Web scraping senza codice | Thunderbit |
| Pagine web dinamiche e variabili | Thunderbit |
| Team business, senza sviluppatori | Thunderbit |
| Integrazione profonda con CI/CD | Playwright, Selenium |
Prova gratis Thunderbit Estrattore Web AI
Il futuro: unire framework di automazione e scraping AI
Qui si fa davvero interessante. Il vecchio mondo dell’“automazione browser” si fonde con il nuovo dell’“estrazione intelligente”. Immagino un futuro in cui team tecnici e business non dovranno più scegliere tra codice e no-code—potranno avere entrambi.
I flussi di lavoro ibridi stanno crescendo:
- Gli sviluppatori possono usare framework come Playwright per automazioni personalizzate, ma integrare moduli AI per l’estrazione semantica dei dati.
- Gli utenti business possono partire da strumenti no-code come Thunderbit, ma passare a soluzioni con codice quando serve personalizzazione avanzata.
- I modelli AI stanno diventando sempre più bravi a comprendere la struttura, il contesto e persino l’intento delle pagine web—rendendo lo scraping più affidabile e meno fragile.
Le aziende che si preparano a questa evoluzione—creando flussi sia programmabili che accessibili ai non tecnici—saranno più agili, data-driven e meno frustrate.
Conclusione: scegli lo strumento giusto per il tuo business
In sintesi:
- Puppeteer è uno strumento veloce, focalizzato su Chrome, ideale per sviluppatori JavaScript.
- Selenium è il veterano multi-browser e multi-linguaggio—potente ma un po’ datato.
- Playwright è l’alternativa moderna, cross-browser e adatta alla concorrenza, perfetta per CI/CD e automazione avanzata.
- Thunderbit è la soluzione no-code, potenziata dall’AI, per chi vuole scraping web affidabile e semantico senza complicazioni.
La vera domanda non è quale sia lo strumento “migliore”, ma quale si adatta alle competenze, alle esigenze e alla voglia di manutenzione del tuo team. Se sei uno sviluppatore che crea flussi personalizzati, i framework classici restano ottimi alleati. Ma se sei un utente business che vuole solo i dati—veloci, precisi e senza stress—Thunderbit merita davvero una prova.
E se vuoi scoprire come l’AI sta rivoluzionando lo scraping e l’automazione web, tieni d’occhio le novità. Stiamo passando da script “clicca qui, aspetta lì” a strumenti che comprendono davvero il web—rendendo l’estrazione dati più intelligente, rapida e anche divertente.
Vuoi approfondire come l’AI sta cambiando lo scraping web? Dai un’occhiata alle nostre altre guide sul Blog di Thunderbit, come Cos’è il Data Scraping e come farlo nel 2025 o Come estrarre dati da qualsiasi sito con l’AI.
E se vuoi provare in prima persona lo scraping AI senza codice, scarica l’estensione Chrome di Thunderbit e scopri cosa significa automazione intelligente. Il tuo futuro (e il tuo team affamato di dati) ti ringrazierà.
Inizia con Thunderbit Estrattore Web AI
Domande frequenti
1. Quali sono le principali differenze tra Puppeteer e Selenium?
Puppeteer è una libreria Node.js pensata soprattutto per automatizzare Chrome e Chromium, con un’API moderna e semplice per test UI, scraping e generazione di screenshot o PDF. Selenium, invece, è un framework più maturo, multi-browser e multi-linguaggio, con una community ampia. Puppeteer è più veloce e facile per attività su Chrome, mentre Selenium offre maggiore flessibilità per test cross-browser e un ecosistema più ricco.
2. In cosa Playwright migliora rispetto a Puppeteer e Selenium?
Playwright, sviluppato da Microsoft, parte dai punti di forza di Puppeteer offrendo vero supporto multi-browser (Chrome, Firefox, Safari, Edge) da una sola API. Introduce funzionalità come la concorrenza integrata, l’auto-waiting avanzato e selettori potenti. È molto apprezzato per il testing di web app moderne e l’automazione in pipeline CI/CD, offrendo un’esperienza più affidabile e facile da mantenere rispetto ai predecessori.
3. Quali vantaggi offrono strumenti no-code e AI come Thunderbit per lo scraping web?
Gli strumenti no-code potenziati dall’AI come Thunderbit sono pensati per chi ha bisogno di dati web in modo rapido e senza ostacoli tecnici. Thunderbit usa l’AI per comprendere semanticamente le pagine, adattandosi ai cambi di layout e ai contenuti dinamici. Permette di estrarre dati strutturati con pochi click, senza scrivere o mantenere script. Così si eliminano problemi come rottura degli script, dipendenza dagli sviluppatori e curve di apprendimento ripide.
4. Quando scegliere uno strumento basato su codice (come Puppeteer, Selenium o Playwright) invece di una soluzione no-code come Thunderbit?
Gli strumenti basati su codice sono ideali per team con sviluppatori o QA dedicati che necessitano di flussi personalizzati, integrazione con pipeline CI/CD o automazione browser avanzata. Se il progetto richiede test complessi, interazioni personalizzate o supporto multi-linguaggio e multi-browser, questi framework sono la scelta giusta. Le soluzioni no-code come Thunderbit sono preferibili quando serve estrarre dati in modo rapido e affidabile da parte di utenti non tecnici, soprattutto in ambito business.
5. Qual è il futuro degli strumenti di automazione browser e scraping web?
Il futuro dell’automazione browser va verso un modello ibrido che unisce la programmabilità dei framework tradizionali con l’intelligenza e l’accessibilità degli strumenti AI no-code. Man mano che i modelli AI migliorano nella comprensione della struttura e del contesto delle pagine web, sia i tecnici che i business user potranno beneficiare di flussi di lavoro più robusti e meno fragili. Le aziende che adotteranno sia soluzioni con codice che no-code saranno più agili e data-driven.
Per saperne di più:
- Come estrarre dati da qualsiasi sito con l’AI
- Converti immagini in Excel: guida da JPG a Word e testo
- Monitoraggio prezzi MAP: guida completa
- Puppeteer vs Selenium: quale scegliere
Prova Estrattore Web AI Get Started Free




