

Alcuni collezionano francobolli. Altri collezionano sneaker. Ma se nel 2026 lavori in vendite, marketing, e-commerce o operations, è molto probabile che tu stia collezionando qualcosa di un po’ più… digitale: dati web. E non pochi: le aziende spendono oggi in media 5 milioni di dollari all’anno per la raccolta di dati web, e il web scraping è ormai uno strumento standard in tutti i reparti, dalla strategia al customer service (fonte).
Con questa esplosione della domanda, due nomi ricorrono in ogni tutorial Python sullo scraping e in ogni progetto di business data: Playwright e Selenium. Entrambi sono nati come strumenti di automazione del browser per i test, ma oggi sono i framework di riferimento per chiunque voglia trasformare il web in dati strutturati e utilizzabili. Però c’è un dettaglio: scegliere tra i due non è solo una decisione tecnica, ma significa individuare lo strumento giusto per le tue esigenze reali di scraping. E se non sei uno sviluppatore, o vuoi semplicemente risultati in fretta, c’è una strada ancora più semplice (indizio: non prevede di scrivere nemmeno una riga di Python). Vediamo.
Da strumenti di test a potenze del web scraping: Playwright e Selenium spiegati
Partiamo dalle basi. Selenium esiste dal 2004 ed è il classico affidabile dell’automazione del browser. Nato per i tester QA, ti permette di controllare browser come Chrome, Firefox e persino Internet Explorer (per chi ama vivere pericolosamente). Playwright, invece, è arrivato sulla scena nel 2020 con il supporto di Microsoft e propone un approccio moderno all’automazione del browser: pensalo come il fratello minore di Selenium, più giovane e più veloce.
Entrambi gli strumenti ti permettono di scrivere script (spesso in Python) che aprono un browser, visitano un sito, cliccano pulsanti, compilano moduli e, soprattutto per noi, estraggono dati. Anche se nascono per i test automatizzati, sono diventati la spina dorsale del web scraping per tutto: dal monitoraggio dei prezzi alla lead generation (fonte). E non piacciono solo agli sviluppatori: sempre più utenti business si rimboccano le maniche per costruire i propri scraper, o almeno ci provano.
Ma ecco il punto: quando fai scraping, le priorità cambiano. Ti interessa meno la copertura dei test e molto di più ottenere i dati in modo affidabile, evitare blocchi e non passare il weekend a debuggare errori Python. È qui che emergono le differenze reali tra Playwright e Selenium.
Differenze principali: Playwright vs. Selenium per il web scraping

Andiamo dritti al punto: Playwright e Selenium possono entrambi fare scraping di siti web, ma brillano in scenari diversi.
- Selenium è il veterano. Funziona con quasi tutti i browser e linguaggi, ha una community enorme ed è perfetto per fare scraping su siti vecchi e statici con layout prevedibili.
- Playwright è il nuovo arrivato con funzionalità moderne. È progettato per i siti di oggi, dinamici e pesanti di JavaScript, con strumenti integrati per gestire login, popup, scroll infinito e altro ancora. Inoltre è più veloce e più facile da configurare, soprattutto per chi usa Python.
Ma non fermiamoci alle mie parole: vediamolo punto per punto.
Tabella di confronto delle funzionalità: Playwright vs. Selenium
| Funzionalità | Selenium | Playwright |
|---|---|---|
| Supporto linguaggi | Python, Java, C#, JS, Ruby e altri | Python, JS/TS, Java, C# |
| Supporto browser | Chrome, Firefox, Edge, Safari, IE, Opera | Chromium (Chrome/Edge), Firefox, WebKit |
| Complessità di configurazione | Richiede un browser driver e configurazione manuale | Un solo comando installa tutto |
| Velocità/Prestazioni | Più lento, più pesante in termini di risorse | In genere più veloce su pagine ricche di JavaScript; asincrono/concorrenziale per progettazione |
| Gestione contenuti dinamici | Attese manuali, richiede più codice | Auto-attese, gestisce facilmente i siti ricchi di JavaScript |
| Evasione anti-bot | Più facile da rilevare, richiede componenti aggiuntivi | Stealth integrato, migliore nel mimare gli utenti |
| Strumenti di debugging | Base (Selenium IDE, screenshot) | Inspector, registrazione video, codegen |
| Supporto della community | Enorme, maturo, pieno di tutorial | In rapida crescita, documentazione moderna, sviluppatori attivi |
| Workflow Python per lo scraping | Più configurazione, più boilerplate | Più fluido, meno codice, più semplice per i principianti |
Scegliere lo strumento giusto: quando usare Playwright o Selenium per il web scraping
Quindi, quale dovresti scegliere per il tuo prossimo progetto di scraping? Ecco il mio punto di vista, dopo anni passati a costruire strumenti di automazione e ad aiutare i team a tirare fuori dati dal Far West del web.
- Selenium è il tuo alleato se:
- Il sito da cui fai scraping è vecchio stile: pensa a HTML statico, poco JavaScript e niente popup elaborati.
- Devi supportare browser insoliti (ciao, Internet Explorer) o integrarti con sistemi legacy.
- Vuoi la tranquillità di una community enorme e di risposte infinite su StackOverflow.
- Conosci già Selenium grazie a progetti di testing.
- Playwright è la scelta giusta se:
- Il sito è moderno, dinamico e pieno di JavaScript (pensa a e-commerce, social media o a qualsiasi cosa faccia partire le ventole del tuo portatile).
- Devi fare login, cliccare tra schede, gestire lo scroll infinito o affrontare popup.
- Vuoi partire in fretta, con meno configurazione e meno codice.
- Sei stanco di scrivere
time.sleep(5)ovunque e vuoi che sia lo strumento a gestire i tempi per te.
Ecco una regola pratica semplice: se al primo tentativo di fare scraping con Selenium ti ritrovi spesso a chiederti “perché non si carica?”, probabilmente è il momento di provare Playwright.
Selenium per il web scraping: punti di forza e limiti
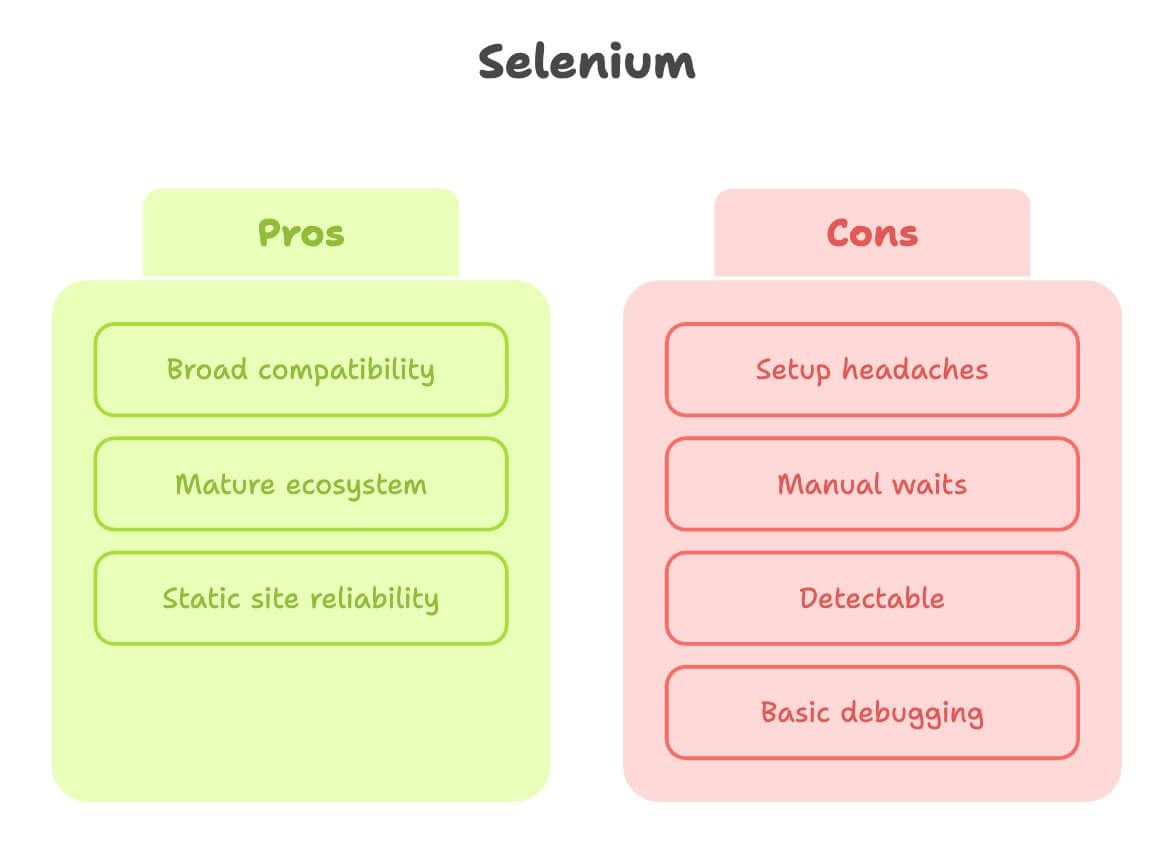
Diamo a Selenium il riconoscimento che merita. È il grande classico dell’automazione del browser e, per molti lavori di scraping, semplicemente funziona.
Punti di forza:
- Ampia compatibilità: Funziona con quasi tutti i browser e linguaggi.
- Ecosistema maturo: Tantissimi tutorial, Q&A e plugin.
- Ottimo per siti statici: Se la pagina cambia poco, Selenium è solidissimo.
Limiti:
- Problemi di configurazione: Devi scaricare e configurare un browser driver (come ChromeDriver) e mantenerlo aggiornato. I principianti spesso si bloccano qui (fonte).
- Attese manuali: Contenuti dinamici? Finirai per scrivere molte attese esplicite o, peggio, istruzioni di sleep messe lì un po’ a caso.
- Più facile da rilevare: Molti siti riconoscono i browser controllati da Selenium e li bloccano, soprattutto se giri su un server cloud.
- Debugging basilare: Nessuna registrazione video integrata né inspector interattivo.
In breve, Selenium è perfetto per siti semplici e stabili, ma può sembrare di spingere un macigno in salita sulle pagine moderne e interattive.
Playwright per il web scraping: punti di forza e limiti
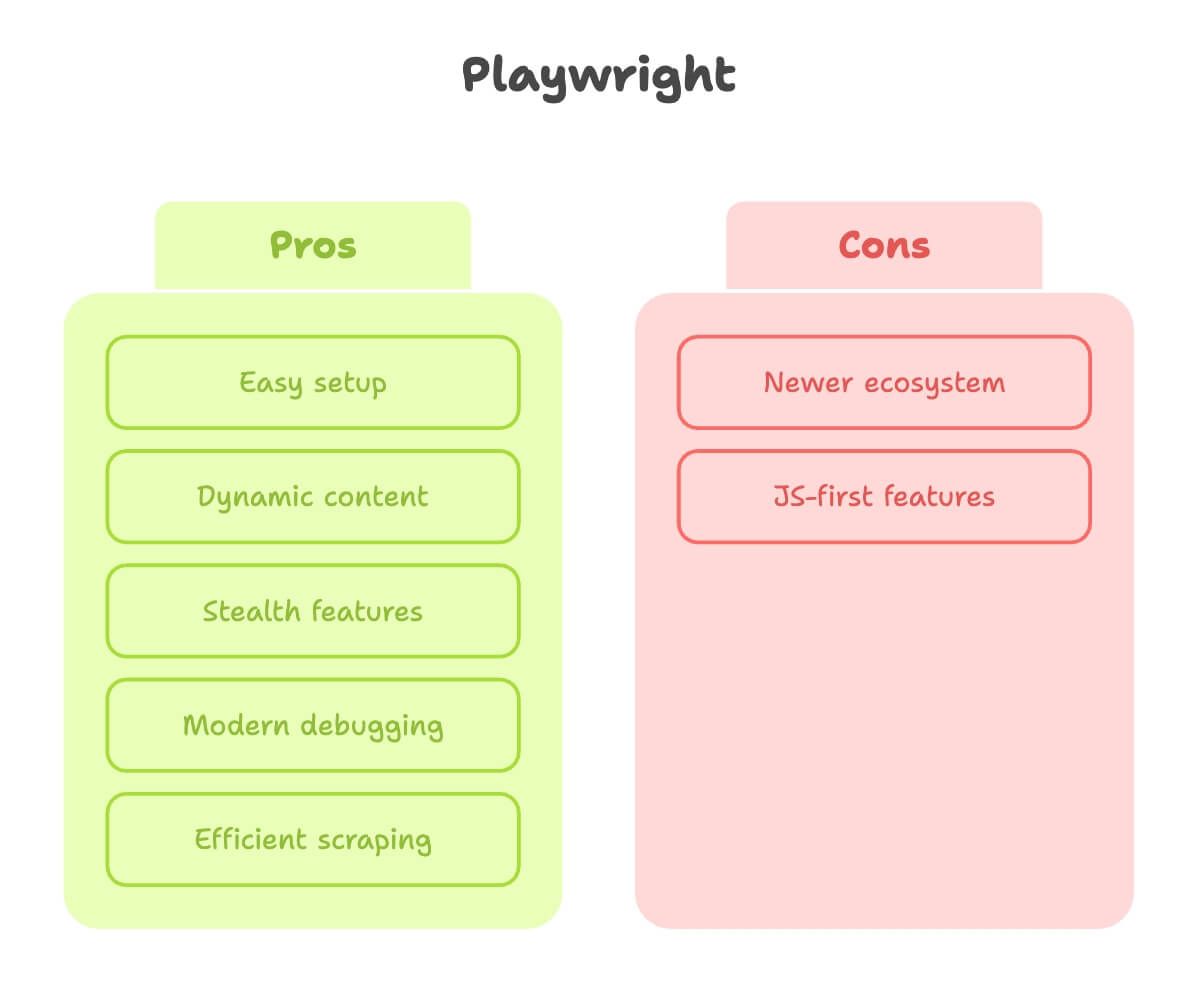
Ora parliamo di Playwright. Da uno che ha passato molto tempo a domare entrambi gli strumenti, posso dire che Playwright sembra costruito da persone che hanno davvero sofferto il web scraping.
Punti di forza:
- Configurazione semplice: Un solo
pip install, un solo comando e sei pronto. Niente drama con i driver. - Gestione dei contenuti dinamici: Fa auto-attesa degli elementi, quindi non devi indovinare quando la pagina è pronta (fonte).
- Funzioni stealth: Mima meglio gli utenti reali, con stealth mode integrato e supporto multi-contesto (ottimo per fare scraping come più “utenti” contemporaneamente).
- Debugging moderno: Inspector, registrazione video e persino generazione del codice a partire dai tuoi click manuali.
- Più veloce ed efficiente: Soprattutto quando devi estrarre tante pagine o eseguire tutto in parallelo.
Limiti:
- Ecosistema più recente: Un po’ meno tutorial, anche se il divario si sta chiudendo in fretta.
- Alcune funzioni sono più orientate a JavaScript: Quasi tutto funziona anche in Python, ma a volte trovi una funzione meglio documentata in JS.
In sintesi: Playwright è la mia scelta di default per qualsiasi sito anche solo un po’ dinamico, o quando voglio risultati rapidi senza lottare con la configurazione.
Evasione anti-bot: quale scraper Python gestisce meglio i siti moderni?
Affrontiamo l’elefante nella stanza: essere bloccati. Nel web scraping, la parte più difficile non è scrivere codice: è fare in modo che il sito non ti chiuda la porta in faccia.
- Selenium: Di default, è più facile da rilevare. I siti possono individuare il flag
webdriver, gli user agent headless e altri segnali evidenti. Esistono soluzioni alternative (come undetected-chromedriver), ma richiedono configurazioni extra e restano sempre inseguendo le tecnologie anti-bot (fonte). - Playwright: Ha funzioni stealth integrate, come nascondere automaticamente le impronte dell’automazione, supportare più contesti browser e aspettare interazioni simili a quelle di un utente reale. Non fa miracoli, ma è meno probabile che ti blocchino al primo tentativo.
Ma la verità è questa: nessuno dei due strumenti è completamente immune alle misure anti-bot. Per scraping ad alto rischio (pensa ai drop di sneaker o ai siti di biglietteria), servono ancora proxy, rotazione degli IP e magari anche la risoluzione dei CAPTCHA. Playwright rende solo tutto un po’ meno doloroso.
Esperienza da sviluppatore: configurazione, curva di apprendimento e debugging
Parliamo dell’esperienza concreta di partire, soprattutto se sei alle prime armi o vuoi semplicemente portare a casa il risultato senza un dottorato in Python.
- Selenium:
- Configurazione: Installa Python, installa Selenium, scarica il browser driver corretto, mettilo nel PATH e prega di aver scelto le versioni giuste. (Ho visto più persone bloccate sul driver che sullo scraping vero e proprio.)
- Curva di apprendimento: Tanti materiali, ma anche tanto codice legacy e tutorial obsoleti.
- Debugging: Soprattutto print statement e screenshot. Esiste Selenium IDE, ma è basilare.
- Playwright:
- Configurazione:
pip install playwright, poiplaywright install. Fine. - Curva di apprendimento: Documentazione moderna, tanti esempi e un’API più “umana” — puoi selezionare elementi per testo, ruolo o persino placeholder.
- Debugging: Inspector ti permette di fare il debug passo passo dello script, osservare il browser e persino registrare video delle esecuzioni di scraping (fonte).
- Configurazione:
Se vuoi vedere risultati rapidamente e passare meno tempo su configurazione e troubleshooting, Playwright è il vincitore netto. Selenium resta ottimo se conosci già i suoi dettagli o ti serve la sua ampia compatibilità.
Passo dopo passo: costruire il tuo primo web scraper Python con Playwright o Selenium
Vediamo concretamente com’è costruire uno scraper con ciascuno strumento — niente codice, solo i passaggi.
Playwright (Python):
- Installa Playwright e i browser:
pip install playwright+playwright install - Avvia il browser: Apri Chromium, Firefox o WebKit, in modalità headless o visibile.
- Vai alla pagina: Usa
page.goto("<https://example.com>") - Attendi il contenuto: Playwright aspetta automaticamente che gli elementi si carichino.
- Estrai i dati: Usa selettori intuitivi (come
get_by_text,locator("span.price")). - Gestisci paginazione o sottopagine: Cicla tra le pagine o clicca sui link: Playwright rende facile eseguire più pagine in parallelo.
- Esporta i dati: Salva in CSV, Excel o database.
- Debug: Usa Inspector o la registrazione video se qualcosa va storto.
Selenium (Python):
- Installa Selenium:
pip install selenium - Scarica il browser driver: (per esempio ChromeDriver per Chrome), poi mettilo nel PATH.
- Avvia il browser: Apri Chrome, Firefox o un altro browser.
- Vai alla pagina:
driver.get("<https://example.com>") - Attendi il contenuto: Aggiungi manualmente attese esplicite (
WebDriverWait) oppure, se ti senti fortunato,time.sleep. - Estrai i dati: Usa
find_elementofind_elements(selettori CSS/XPath). - Gestisci paginazione o sottopagine: Cicla tra URL o clicca sui pulsanti, ma dovrai gestire tu tempi e navigazione.
- Esporta i dati: Salva in CSV, Excel o database.
- Debug: Soprattutto manuale: guarda il browser, stampa l’HTML o fai screenshot.
Noti la differenza? Playwright è semplicemente un po’ più “plug and play” per i siti moderni.
Oltre il codice: web scraping no-code con Thunderbit AI Web Scraper
Estrai dati da qualsiasi sito usando l'IA Get Started Free
Ora, diciamoci la verità. Non tutti vogliono diventare guru di Python solo per ottenere una tabella di prezzi prodotto o una lista di lead. Magari lavori in vendite, marketing, immobiliare o operations, e vuoi solo i dati—subito. Ed è qui che entra in gioco Thunderbit.
Come cofondatore di Thunderbit, ho visto in prima persona quante persone in azienda vogliono semplicemente saltare il codice e arrivare al dunque. Per questo abbiamo costruito un'estensione Chrome basata su IA che ti permette di fare scraping di qualsiasi sito in due clic: niente Python, niente driver, niente debugging.
Come funziona Thunderbit
- Vai sul sito da cui vuoi estrarre dati.
- Fai clic su “Suggerisci campi con IA”. L’IA di Thunderbit analizza la pagina e propone i campi dati (come nome prodotto, prezzo, immagine, valutazione).
- Fai clic su “Estrai”. All’istante ottieni una tabella strutturata di dati.
- Esporta in Excel, Google Sheets, Airtable, Notion, CSV o JSON. Fatto.
Niente tentativi a vuoto sui selettori, niente prove ed errori, niente codice. È semplice come ordinare cibo da asporto (e, diciamolo, probabilmente più veloce che aspettare che arrivi il pranzo).
Prova gratis Thunderbit AI Web Scraper
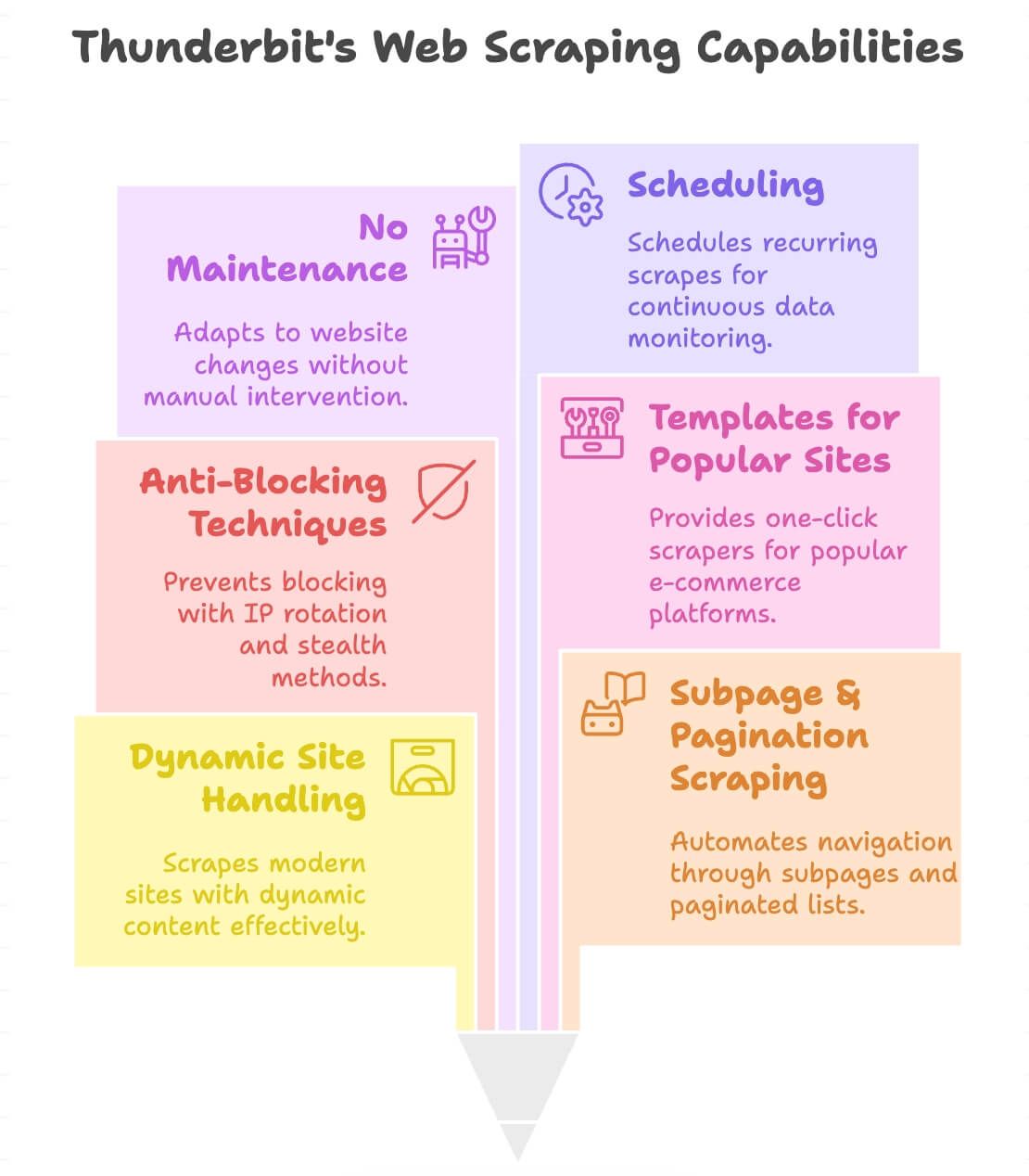
Cosa rende Thunderbit diverso?
- Gestisce i siti dinamici: Fa scraping di e-commerce moderni, directory e persino siti con scroll infinito o popup.
- Scraping di sottopagine e paginazione: Clicca automaticamente tra le pagine prodotto o gli elenchi paginati per ottenere tutti i dati necessari.
- Blocco anti-blocco integrato: Usa rotazione IP sul backend e tecniche stealth, così è meno probabile che tu venga bloccato.
- Template per siti popolari: Scraper con un clic per Amazon, eBay, Shopify, Zillow e altri (vedi il nostro blog per i dettagli).
- Manutenzione ridotta: Quando il layout di un sito cambia, il passaggio “Suggerisci campi con IA” di solito riesce a ridetectare i campi, quindi spesso ti basta rieseguire il suggerimento invece di ricostruire da zero uno script di selettori.
- Pianificazione: Configura scraping ricorrenti per il monitoraggio continuo (per esempio controlli giornalieri dei prezzi).
- Supporta 55 lingue: Estrai e traduci dati da quasi ovunque.
E la parte migliore? Non devi sapere nulla di HTML, CSS o Python. Se sai usare un browser, sai usare Thunderbit.
Qual è la soluzione di web scraping giusta per te?
Chiudiamo con una rapida guida decisionale:
| La tua situazione | Strumento migliore |
|---|---|
| Stai facendo scraping su un sito statico e semplice; la configurazione non ti spaventa | Selenium |
| Stai facendo scraping su un sito moderno e dinamico; vuoi risultati rapidi | Playwright |
| Devi supportare browser o linguaggi legacy | Selenium |
| Vuoi configurazione semplice, debugging moderno e meno codice | Playwright |
| Non sei uno sviluppatore; vuoi i dati subito, senza codice né configurazione | Thunderbit |
| Devi fare scraping di più pagine, sottopagine o pianificare esecuzioni | Thunderbit |
| Vuoi esportare direttamente in Excel, Sheets, Notion, Airtable | Thunderbit |
| Odi debuggare errori Python | Thunderbit |
Se sei uno sviluppatore, o ti piace sperimentare con il codice, Playwright e Selenium sono entrambe scelte potenti. Ma se il tuo obiettivo è portare i dati in un foglio di calcolo nel minor tempo possibile, Thunderbit ti farà risparmiare ore—forse persino giorni—di lavoro.
Inizia con Thunderbit AI Web Scraper
Conclusione: web scraping veloce e affidabile, a modo tuo
Il web scraping è diventato mainstream, e per una buona ragione: le aziende hanno bisogno di dati per competere, e ne hanno bisogno subito. Playwright e Selenium sono passati da semplici strumenti di test a framework essenziali per lo scraping, ciascuno con i propri punti di forza. Selenium è il vecchio affidabile per i siti statici e le configurazioni legacy; Playwright è la scelta moderna e veloce per pagine dinamiche e interattive.
Ma ecco il mio consiglio sincero, dopo anni tra SaaS, automazione e IA: se non sei qui per programmare, non sprecare tempo a lottare con driver, selettori e trucchi anti-bot. Con Thunderbit AI Web Scraper puoi passare da “mi servono questi dati” a “ecco il mio file Excel” in pochi minuti, non in giorni.
Quindi, che tu sia un pro di Python o un utente business che vuole solo risultati, c’è una soluzione di scraping adatta alle tue esigenze—e alla tua pazienza. Provale, vedi cosa funziona nel tuo workflow e ricorda: lo scraper migliore è quello che ti dà i dati che ti servono, con il minimo fastidio.
E se mai dovessi trovarti alle 2 di notte a fare debug di un errore del driver Selenium, sappi solo che Thunderbit sarà ancora qui, pronto a fare scraping in due clic. Buon scraping.
Vuoi saperne di più sul no-code scraping, sull’estrazione dati con IA e su come Thunderbit può aiutare il tuo team? Dai un’occhiata al nostro blog, oppure inizia oggi con la estensione Chrome di Thunderbit.
P.S. Se non sei ancora sicuro di quale strumento usare, o vuoi vedere Thunderbit in azione, passa dal nostro canale YouTube per demo, consigli e ogni tanto una battuta sul web scraping. Sì, le facciamo davvero.
Letture consigliate:
- Cos'è il data scraping e come farlo nel 2025
- Come fare scraping di prodotti e recensioni Amazon nel 2025 usando l'IA
- I migliori strumenti e software per il web scraping nel 2025
Prova l'Estrattore Web AI Get Started Free




