

Per tanti sviluppatori, il primo incontro con il web scraping nasce dalla voglia di capire come recuperare dati da un sito concorrente, magari per estrarre le informazioni di un prodotto. Tra le prime soluzioni che saltano fuori c’è BeautifulSoup, ma i primi passi possono sembrare un po’ ostici. Dopo qualche tentativo, riuscire finalmente a lanciare pip install beautifulsoup4 e a estrarre un semplice elemento HTML—come un titolo—diventa spesso il momento in cui tutto si sblocca. È una piccola soddisfazione che accende la passione e dà fiducia a chi si avvicina a Python.
Se stai iniziando a muovere i primi passi nel mondo dell’estrazione dati dal web, BeautifulSoup sarà probabilmente il primo nome che sentirai. E non è un caso: è semplice, potente e da più di dieci anni è la libreria di riferimento per chi fa scraping in Python. In questa guida ti spiego come installare BeautifulSoup con pip, ti accompagno nei primi esperimenti pratici e ti racconto perché è ancora così amata da sviluppatori e data analyst. Ma sarò anche sincero sui suoi limiti—e sul motivo per cui sempre più team (soprattutto chi non scrive codice) stanno passando a strumenti AI come Thunderbit.
Cos’è BeautifulSoup e perché è ancora così usato?
BeautifulSoup vs. AI Web Scraper: Confronto Completo Get Started Free
Partiamo dalle basi: cos’è BeautifulSoup? Immaginalo come un “traduttore” HTML per Python, facilissimo da usare. Gli dai in pasto un blocco di HTML o XML e lui lo trasforma in una struttura ad albero che puoi esplorare, cercare e modificare con poche righe di codice. È come avere una lente a raggi X sulle pagine web: tutti quei tag e attributi caotici diventano dati facilmente accessibili.
Perché BeautifulSoup è ancora così popolare?
Nonostante l’arrivo di framework più moderni, BeautifulSoup resta la scelta numero uno per chi inizia con Python. Viene scaricato oltre 150 milioni di volte al mese da PyPI. E non è solo una questione di numeri: su Stack Overflow ci sono più di 32.000 domande con il tag “beautifulsoup”, segno di una community attivissima e di un supporto enorme per chi inizia.
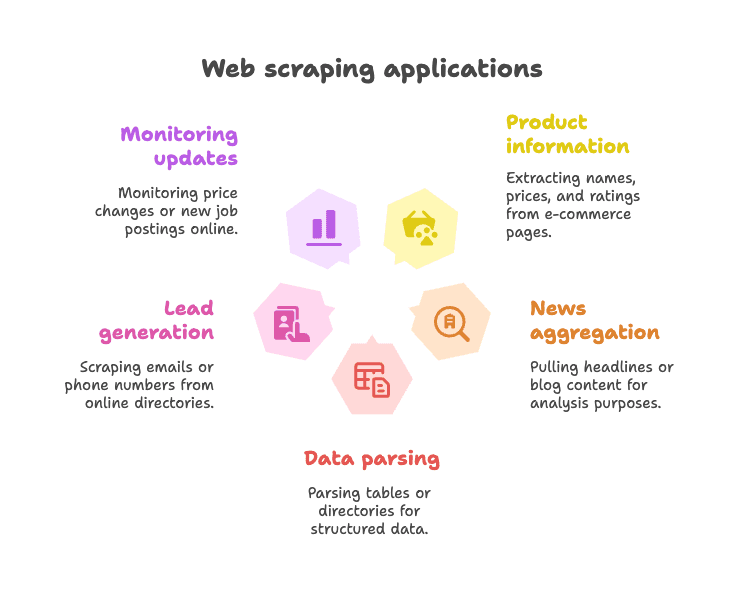
Esempi d’uso tipici:
- Estrazione di dati prodotto da pagine e-commerce (nomi, prezzi, valutazioni)
- Raccolta di titoli di notizie o contenuti di blog per analisi o aggregazione
- Parsing di tabelle o elenchi per ottenere dati strutturati (es. elenchi aziendali)
- Lead generation tramite estrazione di email o numeri di telefono da directory
- Monitoraggio di aggiornamenti (variazioni di prezzo, nuove offerte di lavoro, ecc.)
BeautifulSoup è particolarmente efficace con pagine web statiche—cioè dove i dati sono già presenti nell’HTML. È flessibile, tollerante anche con HTML disordinato e non ti costringe a seguire schemi rigidi. Ecco perché, anche nel 2025, resta il “primo amore” di tanti scraper Python (scopri di più sulla sua popolarità).
Pip Install BeautifulSoup: Il Modo Più Semplice per Iniziare
Cos’è pip e perché usarlo?
Se sei alle prime armi con Python, pip è il gestore di pacchetti che ti permette di installare librerie dal Python Package Index (PyPI). È come l’App Store, ma per il codice Python. Installare BeautifulSoup con pip è il modo più veloce e sicuro per iniziare.
Consiglio: il nome giusto del pacchetto è beautifulsoup4 (non solo beautifulsoup). Ricorda sempre il “4” per avere la versione aggiornata.
Passo dopo passo: installare BeautifulSoup
1. Controlla la versione di Python
BeautifulSoup richiede Python 3.7 o superiore. Puoi verificarlo nel terminale:
python --version
oppure
python3 --version
2. Installa BeautifulSoup4 con pip
Apri il terminale o il prompt dei comandi e digita:
pip install beautifulsoup4
Se hai più versioni di Python, potresti dover usare:
pip3 install beautifulsoup4
Su Windows puoi anche usare:
py -m pip install beautifulsoup4
3. (Opzionale ma consigliato) Installa un parser
BeautifulSoup funziona già con il parser integrato di Python ("html.parser"), ma per prestazioni e precisione migliori, installa anche lxml e html5lib:
pip install lxml html5lib
4. (Opzionale) Installa Requests
BeautifulSoup non scarica le pagine web—si occupa solo di analizzare l’HTML. La maggior parte delle persone usa la libreria Requests per scaricare le pagine:
pip install requests
5. Verifica l’installazione
Prova in Python:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Se vedi <title>Example Domain</title>, sei pronto per partire.
Installare BeautifulSoup in un ambiente virtuale
Consiglio sempre di usare un ambiente virtuale per i progetti Python. Così tieni le dipendenze in ordine ed eviti casini.
Come crearlo:
python -m venv venv
# Su Windows:
venv\Scripts\activate
# Su macOS/Linux:
source venv/bin/activate
pip install beautifulsoup4 requests lxml html5lib
In questo modo, tutto quello che installi resta confinato nella cartella del progetto. Addio ai problemi di “manca il pacchetto”!
Metodi alternativi di installazione (Conda, ecc.)
Se usi Anaconda, puoi installare BeautifulSoup con:
conda install beautifulsoup4
E per il parser:
conda install lxml
Assicurati solo che l’ambiente conda sia attivo.
BeautifulSoup Python: Primi Passi con Esempi di Codice
Vediamo subito come usare BeautifulSoup in uno script Python vero.
Esempio 1: Scaricare una pagina web ed estrarre il titolo
from bs4 import BeautifulSoup
import requests
url = "https://en.wikipedia.org/wiki/Python_(programming_language)"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# Ottieni il titolo della pagina
title_text = soup.title.string
print("Titolo della pagina:", title_text)
Questo script scarica la pagina Wikipedia di Python, analizza l’HTML e stampa il titolo. Facile, vero?
Esempio 2: Estrarre tutti i link
links = soup.find_all('a')
for link in links[:10]: # Mostra i primi 10 link
href = link.get('href')
text = link.get_text()
print(f"{text}: {href}")
Così visualizzi testo e URL dei primi 10 collegamenti della pagina.
Esempio 3: Estrarre i titoli (headlines)
headings = soup.find_all('h2')
for h in headings:
print(h.get_text().strip())
Vuoi tutti i titoli <h2>? Bastano queste righe.
Esempio 4: Usare i selettori CSS
items = soup.select("ul.menu > li")
for item in items:
print(item.get_text())
Il metodo select() ti permette di usare i selettori CSS che già conosci.
Esempio 5: Ottenere attributi e tag annidati
first_link = soup.find('a')
print(first_link['href']) # Accesso diretto (errore se manca)
print(first_link.get('href')) # Accesso sicuro (restituisce None se manca)
Esempio 6: Estrarre tutto il testo
text_content = soup.get_text()
print(text_content)
Così ottieni tutto il testo della pagina—utile per analisi rapide.
Attività comuni con BeautifulSoup per chi inizia
Ecco alcune delle operazioni più frequenti con BeautifulSoup:
-
Trovare un singolo elemento:
soup.find('div', class_='price') -
Trovare tutti gli elementi:
soup.find_all('p', class_='description') -
Ottenere il testo di un elemento:
element.get_text() -
Ottenere il valore di un attributo:
element.get('href') -
Usare selettori CSS:
soup.select('table.data > tr') -
Gestire elementi mancanti:
price = soup.find('span', class_='price') if price: print(price.get_text())
La sintassi è chiara, adatta ai principianti e tollerante—anche se l’HTML è un po’ caotico (vedi la documentazione).
I Limiti di BeautifulSoup per il Web Scraping Moderno
Parliamo ora dei limiti. BeautifulSoup è ottimo per pagine statiche e progetti semplici, ma non è la soluzione a tutto.
Ecco i principali punti critici:
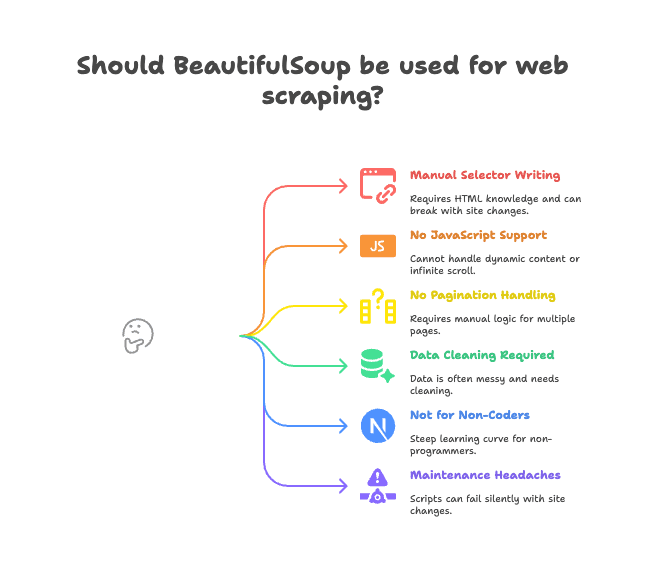
- Scrittura manuale dei selettori: Devi leggere l’HTML e scrivere i percorsi giusti. Se il sito cambia, lo script si rompe.
- Nessun supporto per JavaScript: BeautifulSoup vede solo l’HTML inviato dal server. Se i dati vengono caricati via JavaScript (infinite scroll, contenuti dinamici), non li vedrai (scopri di più).
- Nessuna gestione integrata di paginazione o sottopagine: Vuoi estrarre dati da più pagine o entrare nei dettagli di un prodotto? Devi scrivere tutta la logica da solo.
- Pulizia dei dati necessaria: I dati estratti spesso sono sporchi—spazi in eccesso, caratteri strani, formati incoerenti.
- Non adatto a chi non programma: Se lavori in sales, marketing o operation e non sai programmare, BeautifulSoup è una salita ripida.
- Manutenzione complicata: Se il sito cambia struttura, il tuo script può smettere di funzionare senza avvisarti.
Per molti team, questi “piccoli” problemi diventano veri colli di bottiglia. Ho visto più di un progetto bloccarsi perché lo script di scraping richiedeva continue correzioni.
Perché Sempre Più Team Scelgono Thunderbit per l’Estrazione di Dati Web
Prova Thunderbit Estrattore Web AI Estrai dati da qualsiasi sito con l’AI. Nessuna programmazione richiesta. Get Started Free
Qual è l’alternativa? Qui entra in gioco Thunderbit. Thunderbit non è una semplice libreria Python—è un’estensione Chrome che funziona come un assistente AI per l’estrazione di dati web.
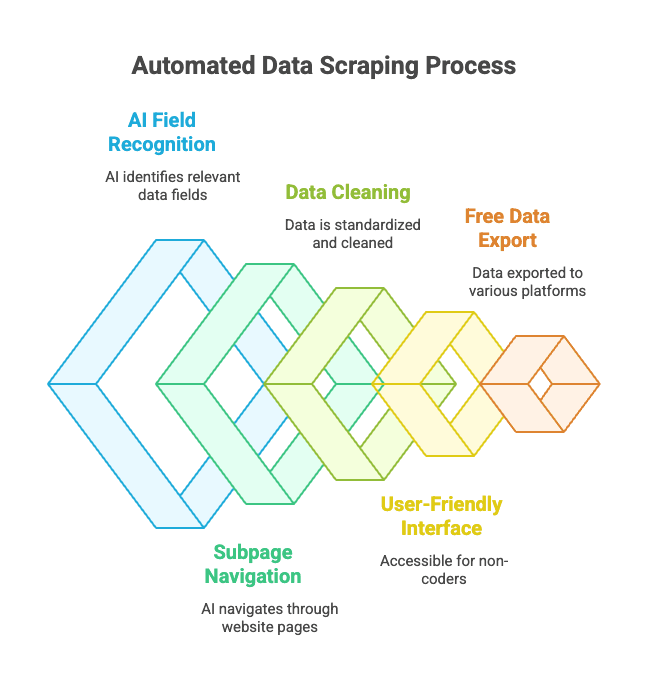
Come funziona?
- Apri il sito da cui vuoi estrarre i dati.
- Clicca su “AI Suggerisci Campi”—l’AI di Thunderbit legge la pagina e suggerisce le colonne giuste (es. “Nome Prodotto”, “Prezzo”, “Località”).
- Puoi modificare nomi e tipi delle colonne se vuoi.
- Premi “Estrai” e Thunderbit raccoglie, pulisce e struttura i dati per te.
- Esporta in Excel, Google Sheets, Notion, Airtable o dove preferisci con un click.
Nessun codice. Nessun selettore. Niente più manutenzione.
I punti di forza di Thunderbit:
- Riconoscimento campi tramite AI: L’intelligenza artificiale individua i dati giusti anche in HTML disordinati.
- Gestione automatica di sottopagine e paginazione: Può entrare nelle pagine prodotto o gestire i “prossima pagina” in automatico.
- Pulizia e formattazione dei dati: Thunderbit standardizza numeri di telefono, email, immagini e altro.
- Facile anche per chi non programma: Se sai usare un browser, sai usare Thunderbit.
- Esportazione gratuita dei dati: Esporta in Excel, Google Sheets, Airtable, Notion—senza costi per le funzioni base.
- Estrazione programmata: Puoi pianificare scraping automatici e ricorrenti.
Per chi lavora in azienda, questo cambia completamente il modo di estrarre dati dal web. Niente più script Python da gestire: basta puntare, cliccare e ottenere i dati.
Prova gratis Thunderbit Estrattore Web AI
Thunderbit vs. BeautifulSoup: Quale Scegliere?
Ecco un confronto diretto:
| Caratteristica | BeautifulSoup (Codice Python) | Thunderbit (AI No-Code) |
|---|---|---|
| Installazione | Richiede Python, pip, codice | Estensione Chrome, 2 click |
| Velocità di estrazione | Ore per il primo script | Minuti per sito |
| Gestione JavaScript | No (servono strumenti extra) | Sì (funziona nel browser) |
| Paginazione/Sottopagine | Serve codice manuale | Integrato, opzione attivabile |
| Pulizia dati | Manuale, via codice | Automatica, tramite AI |
| Esportazione | Devi scrivere tu CSV/Excel | Un click su Sheets, Notion, ecc. |
| Ideale per | Sviluppatori, smanettoni | Utenti business, chi non programma |
| Costo | Gratis (ma richiede tempo) | Freemium (gratis per piccoli lavori) |
Quando usare BeautifulSoup:
- Hai dimestichezza con Python e vuoi il massimo controllo.
- Devi estrarre dati da siti statici o hai bisogno di logiche personalizzate.
- Vuoi integrare lo scraping in un flusso Python più ampio.
Quando usare Thunderbit:
- Vuoi risultati rapidi, senza scrivere codice.
- Devi gestire siti dinamici (con JavaScript).
- Lavori in sales, marketing, operation o non vuoi occuparti di codice.
- Vuoi esportare i dati direttamente nei tuoi strumenti aziendali.
Anche da sviluppatore, a volte scelgo Thunderbit quando mi serve estrarre dati al volo senza avviare un intero progetto Python. È come avere un superpotere nel browser.
Best Practice per Installare e Usare BeautifulSoup
Se scegli di lavorare con BeautifulSoup, ecco qualche dritta per evitare grane:
- Usa sempre un ambiente virtuale: Mantieni le dipendenze in ordine ed evita problemi di compatibilità.
- Aggiorna pip e i pacchetti: Esegui regolarmente
pip install --upgrade pipepip list --outdated. - Installa i parser consigliati:
pip install lxml html5libper prestazioni migliori. - Scrivi codice modulare: Separa la logica di download da quella di parsing per facilitare il debug.
- Rispetta robots.txt e i limiti di richiesta: Non sovraccaricare i siti—usa
time.sleep()tra le richieste. - Usa selettori descrittivi ma stabili: Evita percorsi troppo specifici che si rompono facilmente.
- Testa il parsing su HTML salvato: Scarica una pagina e prova il codice offline per evitare richieste ripetute.
- Sfrutta la community: Stack Overflow è una risorsa preziosa per risolvere problemi.
Risoluzione dei Problemi di Installazione di BeautifulSoup
Hai incontrato errori? Ecco una checklist rapida:
- “ModuleNotFoundError: No module named bs4”
- Hai installato
beautifulsoup4nell’ambiente giusto? Provapython -m pip install beautifulsoup4.
- Hai installato
- Installato il pacchetto sbagliato (
beautifulsoupinvece dibeautifulsoup4)- Disinstalla quello vecchio:
pip uninstall beautifulsoup - Installa quello giusto:
pip install beautifulsoup4
- Disinstalla quello vecchio:
- Avvisi sul parser o errori Unicode
- Installa
lxmlehtml5lib, e specifica il parser:BeautifulSoup(html, "lxml")
- Installa
- Elementi non trovati
- I dati sono caricati via JavaScript? BeautifulSoup non li vede. Controlla il sorgente della pagina, non il DOM renderizzato dal browser.
- Errori pip o permessi
- Usa un ambiente virtuale, oppure prova
pip install --user beautifulsoup4 - Aggiorna pip:
pip install --upgrade pip
- Usa un ambiente virtuale, oppure prova
- Problemi con Conda
- Prova
conda install beautifulsoup4o usa pip dentro l’ambiente conda.
- Prova
Se hai ancora problemi, la documentazione di BeautifulSoup e Stack Overflow coprono quasi ogni scenario.
Conclusioni: Cosa Ricordare su BeautifulSoup
-
BeautifulSoup è la libreria Python più usata per il web scraping—semplice, flessibile e perfetta per chi inizia.
-
Installala con pip:
pip install beautifulsoup4 lxml html5lib requests -
Usa un ambiente virtuale per mantenere tutto ordinato.
-
BeautifulSoup è ideale per pagine statiche e progetti piccoli, ma fatica con JavaScript, paginazione e manutenzione.
-
Thunderbit è l’alternativa moderna basata su AI per utenti business e chi non programma—niente codice, niente complicazioni, solo dati.
-
Scegli lo strumento giusto per le tue esigenze:
- Sviluppatori e smanettoni: BeautifulSoup offre controllo totale.
- Utenti business e team: Thunderbit ti dà risultati rapidi.
Prova entrambi gli approcci—spesso la soluzione migliore è quella che ti fa ottenere risultati con meno fatica.
Prova gratis Thunderbit Estrattore Web AI Get Started Free
Domande Frequenti: Pip Install BeautifulSoup e Oltre
D: Qual è la differenza tra beautifulsoup e beautifulsoup4?
R: Installa sempre beautifulsoup4—è la versione aggiornata e supportata. Il vecchio pacchetto beautifulsoup non è compatibile con Python 3. L’import corretto è from bs4 import BeautifulSoup (dettagli qui).
D: Devo installare lxml o html5lib insieme a BeautifulSoup?
R: Non è obbligatorio, ma fortemente consigliato. Migliorano velocità e robustezza del parsing. Installa con pip install lxml html5lib (perché è importante).
D: BeautifulSoup gestisce siti web ricchi di JavaScript?
R: No—BeautifulSoup vede solo l’HTML statico. Per contenuti caricati via JavaScript, usa strumenti come Selenium o prova una soluzione AI come Thunderbit (scopri di più).
D: Come disinstallo BeautifulSoup?
R: Esegui pip uninstall beautifulsoup4 nel terminale (guida passo passo).
D: Thunderbit è gratuito?
R: Thunderbit offre un piano freemium—gratis per piccoli lavori, a pagamento per volumi maggiori o funzioni avanzate. Puoi provarlo gratis direttamente dal browser (dettagli sui prezzi).
Se vuoi vedere un confronto reale tra Thunderbit e BeautifulSoup, dai un’occhiata al nostro approfondimento. E se vuoi saperne di più sul web scraping, non perderti le nostre guide su cos’è il data scraping e come estrarre prodotti e recensioni da Amazon.
Buon scraping! Che tu sia un esperto Python o voglia solo i tuoi dati in un foglio di calcolo, c’è uno strumento (e una community) pronta ad aiutarti a raggiungere il tuo obiettivo.




