Lasciatemelo dire: se avessi un dollaro per ogni volta che qualcuno mi ha inviato un PDF pieno di “dati importanti” aspettandosi che lo trasformassi magicamente in un foglio di calcolo, probabilmente avrei abbastanza soldi per comprarmi caffè a vita scorta (e magari anche qualche estensione Chrome in più). I PDF sono ovunque: contratti di vendita, cataloghi di prodotti, articoli di ricerca, fatture, tutto quello che vuoi. Ma quando si tratta di usare davvero i dati contenuti in quei file? Ecco, lì iniziano i problemi.
Ci sono passato anch’io: copiare, incollare, riformattare e, a volte, semplicemente mollare quando la formattazione andava in tilt o immagini e link sparivano nel nulla. La buona notizia, però, è che il mondo del PDF scraping è cambiato radicalmente, soprattutto con l’arrivo degli strumenti basati su AI. Se sei stanco di passare ore a reinserire numeri o di impazzire per tabelle rovinate, sei nel posto giusto. Immergiamoci nel mondo del PDF scraping, vediamo perché conta e come strumenti come lo stanno rendendo finalmente semplice.
Cos’è il PDF Scraping? Le basi dell’estrazione dati dai PDF
Partiamo dalle basi: PDF scraping è solo un modo sofisticato per dire “estrarre automaticamente dati strutturati dai file PDF”. Un PDF scraper è uno strumento (software, estensione o servizio) che recupera ciò che ti interessa—testo, tabelle, immagini, link, tutto quello che vuoi—e lo porta in un formato davvero utilizzabile, come Excel, Google Sheets o un database.
Ma c’è un problema: i PDF non sono come le pagine web o i file Excel. Sono più simili a stampe digitali, progettate per apparire uguali ovunque, non per essere facilmente smontate da un computer. Alcuni PDF contengono testo selezionabile, altri sono solo immagini scansionate (che richiedono OCR, cioè riconoscimento ottico dei caratteri), e la formattazione può essere completamente caotica. Quindi estrarre dati da un PDF non significa solo copiare del testo: significa decifrare un puzzle fatto di layout, font e, a volte, persino metadati nascosti.
Cosa puoi estrarre da un PDF?
- Testo semplice (paragrafi, titoli, ecc.)
- Tabelle (pensa a: dati finanziari, specifiche di prodotto, risultati di sondaggi)
- Immagini e grafica (grafici, loghi, firme scansionate)
- Collegamenti ipertestuali e riferimenti (URL incorporati, citazioni)
- Dati dei moduli (campi di moduli compilabili)
- Metadati (autore, titolo, data di creazione, tag)
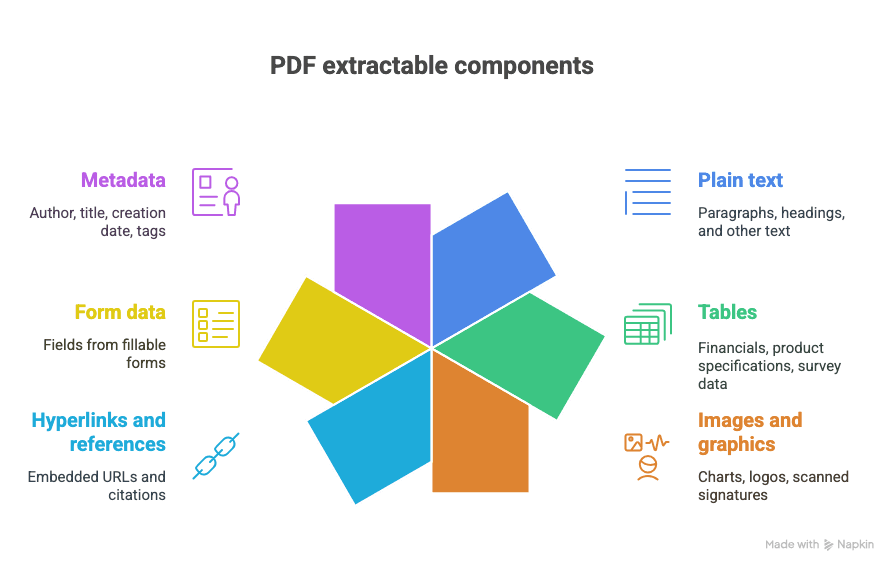
E sì, a volte tutti questi elementi finiscono mescolati nello stesso glorioso e caotico documento.
Perché il PDF Scraping è importante: casi d’uso reali e vantaggi per il business
Quindi, perché darsi pena di estrarre dati dai PDF? Perché tutti li usano, e i dati che contengono sono spesso fondamentali per il business. Ecco dove il PDF scraping dà il meglio di sé:
| Caso d’uso | Lavoro manuale | Con un PDF Scraper | Risparmio di tempo ed errori |
|---|---|---|---|
| Estrazione lead di vendita | Ore a copiare contatti da proposte commerciali o PDF di eventi, con il rischio di perdere lead | Porta subito tutti i lead in un foglio di calcolo | 80–90% più veloce, meno errori |
| Dati prodotto per e-commerce | Giorni a inserire specifiche di prodotto da PDF dei fornitori, con caos nella formattazione | Estrazione massiva in CSV o Sheets | Oltre il 95% di tempo risparmiato, dati coerenti |
| Analisi di dati di ricerca | Settimane a trascrivere tabelle da articoli accademici, con alto rischio di refusi | Estrae tabelle, riferimenti e persino testo scansionato | 80% di tempo risparmiato, maggiore accuratezza |
Mettiamo qualche numero sul tavolo:
- Ogni anno vengono creati .
- Il usa il PDF come formato principale per condividere informazioni.
- L’amministrazione digitale manuale (come l’inserimento di dati da PDF) assorbe .
- Gli strumenti automatizzati possono ridurre il tasso di errore dal .
Se lavori in vendita, e-commerce o ricerca, automatizzare l’estrazione dei dati dai PDF non è solo una comodità: è un vantaggio competitivo.
Metodi tradizionali di PDF Scraping: sfide e limiti
Diciamolo chiaramente: i vecchi modi di estrarre dati dai PDF non sono… granché. Ecco cosa abbiamo provato in molti (e perché è così frustrante):

1. Copia e incolla manuale
- Problemi: La formattazione si rovina, le tabelle diventano un pasticcio, immagini e link spariscono, e ti resta solo un gran mal di testa.
- Costo di lavoro: Alto. Se hai 5.000 PDF, anche a 1 minuto ciascuno, sono oltre 80 ore della tua vita che non torneranno più.
- Tasso di errore: 5–10%. Refusi, righe saltate, cancellazioni accidentali: già visto, già fatto.
2. Convertire in Word/Excel e poi sistemare tutto
- Problemi: A volte funziona per documenti semplici, ma layout complessi o tabelle vengono scombussolati. Poi devi comunque ripulire il caos.
- Immagini/link: Di solito si perdono per strada.
- Estrazione mirata: Lascia perdere: ottieni tutto il documento, non solo ciò che ti serve.
3. Script personalizzati (Python, ecc.)
- Problemi: Devi saper programmare (o avere qualcuno sempre disponibile). Ogni nuovo formato PDF significa ritoccare lo script. PDF scansionati? Buona fortuna.
- Manutenzione: Alta. Ogni volta che un fornitore cambia il modello della fattura, lo script si rompe.
- Scalabilità: Non per i deboli di cuore (o per chi non è tecnico).
4. Convertitori online
- Problemi: Comodi per lavori occasionali, ma devi caricare documenti sensibili su un server di terzi (ciao problemi di compliance). Controllo limitato su ciò che viene estratto.
- Formattazione: Variabile. Potresti passare più tempo a sistemare che a risparmiare.
In sintesi: i metodi tradizionali sono lenti, soggetti a errori e non scalano. Ecco perché tanti team finiscono per “convivere con il problema” — ma a un costo enorme in termini di produttività.
Soluzioni moderne per il PDF Scraping: dal codice agli strumenti no-code
Per fortuna non siamo più bloccati nell’età oscura. Il panorama si è arricchito di opzioni di PDF scraping più intelligenti, veloci e facili da usare.
1. Librerie di programmazione (per sviluppatori)
- Esempi: , , .
- Punti di forza: Molto flessibili, automatizzabili su grandi volumi, gratuite (open source).
- Punti deboli: Configurazione lunga, richiedono competenze di programmazione, fragili (si rompono con nuovi formati), supporto OCR/immagini limitato.
2. Convertitori PDF online
- Esempi: , , .
- Punti di forza: Nessuna configurazione, facili per chi non è tecnico, veloci per piccoli lavori.
- Punti deboli: Personalizzazione limitata, problemi di privacy, errori di formattazione, limiti di dimensione/pagine.
3. PDF scraper basati su AI
- Esempi: , Nanonets, Docparser.
- Punti di forza: Nessun codice richiesto, gestiscono testo/tabelle/immagini/link, l’AI suggerisce cosa estrarre, supportano lavori in batch, si integrano con Sheets/Notion/Airtable.
- Punti deboli: Alcuni hanno limiti di crediti/pagine, possono richiedere connessione internet, per documenti complessi può esserci una breve curva di apprendimento.
Confronto tra strumenti di PDF Scraping: quale approccio è adatto alle tue esigenze?
| Strumento/Metodo | Configurazione | Ideale per | Estrae | Personalizzabile? | Costo |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Moderata (interfaccia/codice) | Tabelle nei PDF | Tabelle | In parte | Gratis |
| PDFMiner | Richiede codice | PDF ricchi di testo | Testo | Sì (con codice) | Gratis |
| PyPDF2 | Richiede codice | Testo/metadati semplici | Testo, metadati | Sì (con codice) | Gratis |
| Smallpdf/convertitori online | Nessuna (via web) | Conversioni rapide | Intero documento (Word/Excel) | No | Freemium |
| Thunderbit | Installazione in 2 clic | Utenti business, team | Testo, tabelle, immagini, link | Sì (prompt AI) | Freemium (16,5 $/mese per Pro) |
Scopri Thunderbit: l’estensione Chrome con AI per il PDF Scraping
Ora parliamo dello strumento che ha reso la mia vita (e quella di molti utenti business) molto più semplice: .
Cosa rende Thunderbit diverso?
- Estrazione in 2 clic: Apri un PDF in Chrome, fai clic sull’estensione Thunderbit e lascia fare all’AI il resto.
- Suggerimenti sui campi guidati dall’AI: La funzione “AI Suggest Fields” di Thunderbit legge il PDF e ti propone le colonne che probabilmente ti servono (come “Nome”, “Email”, “Prezzo”, ecc.).
- Gestisce immagini, link e tabelle: Non solo testo semplice: Thunderbit può estrarre immagini, hyperlink e persino applicare OCR ai documenti scansionati.
- Prompt personalizzati: Ti servono solo numeri di telefono o specifiche di prodotto? Aggiungi un’istruzione personalizzata e Thunderbit si concentrerà solo su quello.
- Esportazione ovunque: Invia i dati direttamente a Excel, Google Sheets, Airtable o Notion. Niente più acrobazie con CSV.
- Estrazione in batch e su sottopagine: Hai un elenco di PDF o link? Thunderbit può elaborarli tutti in un’unica sessione.
- Affidabilità di livello business: Progettato per accuratezza, privacy e flussi di lavoro reali.
In breve, è come avere uno stagista digitale che ama fare inserimento dati (e non si stanca mai).
Come estrarre dati da un PDF con Thunderbit: guida passo passo
Pronto a vedere quanto può essere semplice? Ecco come uso Thunderbit per trasformare i PDF in dati strutturati e utilizzabili:
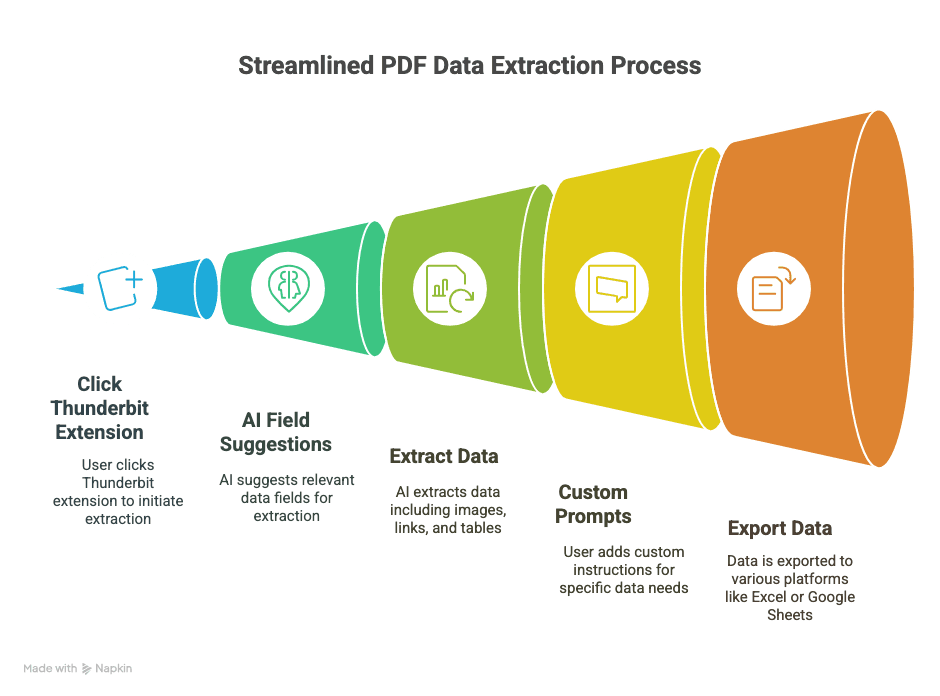
1. Installa Thunderbit
- Scarica la .
- Registrati (con account Google o email: bastano pochi secondi).
2. Apri il tuo PDF in Chrome
- Apri un PDF da un link web oppure trascina un PDF locale in una scheda di Chrome.
3. Avvia Thunderbit sul PDF
- Fai clic sull’icona di Thunderbit nella barra degli strumenti del browser.
- Seleziona “AI Web Scraper”: Thunderbit rileverà il PDF e sarà pronto a lavorare.
4. Lascia che l’AI suggerisca i campi
- Fai clic su “AI Suggest Columns”.
- L’AI di Thunderbit analizza il PDF e suggerisce le colonne (come “Data”, “Importo”, “Nome contatto”, ecc.).
- Visualizza in anteprima i dati estratti in una tabella direttamente nell’estensione.
5. Personalizza, se serve
- Rinomina le colonne, elimina quelle in eccesso o aggiungi le tue (per esempio “Termine di garanzia” o “URL prodotto”).
- Per dati complicati, seleziona il testo nel PDF per addestrare l’AI su ciò che desideri.
6. Scegli il formato di esportazione
- Scegli tra CSV, Google Sheets, Airtable o Notion.
- Autorizza Thunderbit alla connessione (configurazione una tantum).
7. Estrai ed esporta
- Premi “Scrape” o “Export”.
- Thunderbit elabora il PDF e invia i dati dove vuoi tu, di solito in pochi secondi.
Tutto qui. Niente codice, niente copia-incolla, niente drammi.
Consigli per un’estrazione accurata dei dati dai PDF con Thunderbit
- Controlla i campi suggeriti dall’AI: L’AI è intelligente, ma un’occhiata veloce ti garantisce di ottenere esattamente ciò che ti serve.
- Gestisci tabelle complesse: Per tabelle multi-pagina o formattate in modo strano, usa l’anteprima per individuare i problemi e regolare le colonne se necessario.
- Estrai immagini/link: Assicurati di includere questi campi se il PDF li contiene: Thunderbit può recuperarli senza problemi.
- PDF scansionati: L’OCR integrato di Thunderbit è solido, ma più la scansione è pulita, migliori saranno i risultati.
- Prompt personalizzati: Vuoi solo email o numeri di telefono? Aggiungi un prompt come “Estrai tutti gli indirizzi email” e Thunderbit si concentrerà su quelli.
PDF Scraping avanzato: estrarre immagini, link e dati personalizzati
Thunderbit non serve solo per il testo semplice. Ecco come puoi ricavare ancora di più dai tuoi PDF:
- Immagini: Estrai loghi, grafici o qualsiasi grafica incorporata. Thunderbit può persino applicare OCR al testo contenuto nelle immagini.
- Hyperlink: Recupera tutti gli URL o i riferimenti: perfetto per articoli di ricerca o curriculum.
- Tipi di dati personalizzati: Usa i prompt AI per estrarre solo ciò che ti serve (per esempio: “Trova tutti gli SKU dei prodotti e i loro prezzi”).
- Riepiloghi e categorizzazione: Aggiungi una colonna e chiedi a Thunderbit di riassumere una sezione o categorizzare i dati al volo.
Estrarre dati da PDF per esigenze aziendali specifiche
- Vendite: Estrai solo le informazioni di contatto da un batch di proposte commerciali.
- E-commerce: Recupera specifiche di prodotto, prezzi e immagini dai cataloghi dei fornitori.
- Ricerca: Estrai tabelle, riferimenti e persino genera riepiloghi da articoli accademici.
E una volta ottenuti i dati, strutturali in modo da analizzarli facilmente in Excel, Google Sheets o Notion: Thunderbit fa il lavoro pesante, tu devi solo usare i risultati.
Esportare e usare i dati PDF: dall’estrazione all’azione
Estrarre i dati è solo l’inizio. Ecco come farli lavorare per te:
- Opzioni di esportazione: CSV, Excel, Google Sheets, Airtable, Notion: scegli quella che preferisci.
- Consigli di formattazione: Usa le impostazioni del tipo di colonna di Thunderbit (numero, data, testo) per ottenere dati puliti e pronti per l’analisi.
- Integrazione nel workflow: Collega i dati esportati a CRM, sistemi di inventario o dashboard di analytics.
- Collaborazione: Condividi fogli Google o basi Airtable con il tuo team: tutti lavorano sugli stessi dati aggiornati.
La parte migliore? Niente più fogli di calcolo inviati avanti e indietro via email, né dubbi su eventuali righe mancanti.
Errori comuni nel PDF Scraping e come evitarli
Anche con gli strumenti migliori, qualche insidia può sempre presentarsi. Ecco quello che ho imparato, a volte nel modo più difficile:
- Errori OCR: Scansioni sfocate o font strani possono mettere in difficoltà persino il miglior OCR. Cerca di usare PDF il più puliti possibile e verifica manualmente i campi critici.
- Layout complessi: Tabelle su più colonne o annidate potrebbero richiedere un po’ di guida manuale: usa la selezione manuale o i prompt di Thunderbit.
- Tipi di dati: Numeri con virgole o date in formati insoliti? Imposta il tipo di colonna prima dell’esportazione, oppure ripulisci tutto in Excel/Sheets.
- Limiti di dimensione/pagine: PDF enormi? Spezzali in blocchi più piccoli, oppure usa la modalità cloud di Thunderbit per i lavori in batch.
- “Allucinazioni” dell’AI: Rare, ma a volte l’AI può indovinare il nome di una colonna o riempire dati mancanti. Controlla sempre il risultato, soprattutto per i numeri importanti.
- Revisione manuale: Per dati mission-critical, fai una verifica rapida: gli strumenti automatici sono accurati, ma un controllo umano non guasta mai.
E se incontri un ostacolo, il supporto e la community di Thunderbit sono lì per aiutarti.
Conclusione e punti chiave: far funzionare il PDF Scraping per il tuo business
Tiriamo le somme. Estrarre dati dai PDF era un incubo: lento, soggetto a errori e semplicemente noioso. Ma con strumenti moderni come , oggi è veloce, preciso e, oserei dire, quasi piacevole.
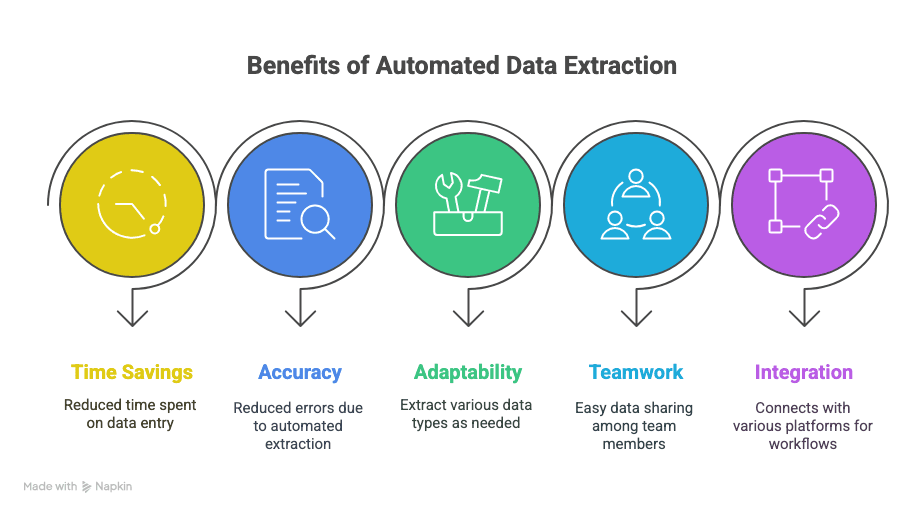
Ecco cosa ottieni:
- Tempo recuperato: Ore, o persino settimane, risparmiate nell’inserimento manuale dei dati.
- Meno errori: L’estrazione automatica significa meno refusi e meno righe perse.
- Flessibilità: Estrai esattamente ciò che ti serve: testo, tabelle, immagini, link, tutto quello che vuoi.
- Collaborazione: Condividi i dati istantaneamente con il tuo team, ovunque si trovi.
- Workflow più intelligenti: Integrazione con Sheets, Notion, Airtable e altro ancora.
Pronto a provarlo? Scarica la , usala sul tuo prossimo PDF e scopri quanto può essere più facile la vita. Il tuo futuro te stesso (e il tuo tunnel carpale) ti ringrazieranno.
Per altri consigli e guide, visita il oppure approfondisci con .
Trasformiamo insieme questi grattacapi dei PDF in risultati di produttività: un clic alla volta.
Shuai Guan, Co-fondatore e CEO, Thunderbit