
La scorsa settimana ho buttato via un intero pomeriggio cercando di far compilare a un agente AI un modulo per fornitori su un portale protetto da login. Dopo tre ore ero lì a guardare un errore “Connection Refused”, il mio VPS aveva finito la memoria e stavo davvero pensando di fare tutto a mano.
Questa esperienza è, in sostanza, il kit base di sopravvivenza di OpenClaw browser automation. Lo strumento può navigare pagine, estrarre dati, compilare moduli e concatenare flussi di lavoro complessi usando semplici istruzioni in inglese naturale: davvero notevole. Però il salto tra “sembra fantastico” e “funziona davvero sul mio computer” è proprio il punto in cui si inceppa la maggior parte delle persone.
Ho passato molto tempo su entrambi i lati di quel salto, sia costruendo strumenti di automazione in Thunderbit sia testando quello che l’ecosistema open source ha da offrire. Questa guida è quella che avrei voluto avere: una vera procedura di configurazione, la scelta della modalità browser che manda tutti in confusione, un percorso nativo per Windows (perché WSL non dovrebbe essere un prerequisito), una guida di sopravvivenza anti-bot, esempi reali di output, errori comuni con correzioni concrete e uno sguardo sincero su quando OpenClaw è lo strumento giusto — e quando invece è troppo.
Prova Thunderbit per estrarre dati dal web senza fatica
Estrai dati da qualsiasi sito con l’AI Get Started Free
Che cos’è OpenClaw Browser Automation?
OpenClaw è una piattaforma di agenti AI gratuita e open source (licenza MIT) che può controllare un browser al tuo posto. Invece di scrivere script Selenium o codice Puppeteer, descrivi in linguaggio naturale quello che vuoi ottenere — “Vai su questa pagina ed estrai tutti i nomi e i prezzi dei prodotti” — e l’AI capisce come farlo. Usa un sistema di snapshot numerati in cui l’agente identifica gli elementi della pagina, assegna numeri di riferimento e interagisce con essi passo dopo passo.
L’architettura si divide in tre parti — ed è per questo che la configurazione richiede più di una semplice estensione:
- Gateway (VPS/server): il “cervello” che elabora le istruzioni e si collega agli LLM. Di default usa la porta 18789.
- Node Host (macchina locale): un relay che permette al Gateway di inviare istruzioni del browser al tuo Chrome locale. Si collega tramite un tunnel sicuro come Tailscale.
- Chrome Extension (Browser Relay): consente all’agente di controllare direttamente le schede del browser nel tuo browser reale.
Le porte aggiuntive includono Control Service (18791), CDP Relay (18792) e browser CDP gestito (18800–18899, con supporto fino a 100 profili paralleli).
Sì, sono tanti pezzi in movimento. Ma quando capisci a cosa serve ciascuno, tutto torna. Pensalo come un’auto telecomandata: il Gateway è il controller, il Node Host è il segnale radio e l’estensione Chrome è l’auto stessa.

Perché OpenClaw Browser Automation è importante per i team business
I knowledge worker passano fino al 60% del loro tempo in attività amministrative di routine invece che in lavoro ad alto valore, comprese 1,8 ore al giorno solo per cercare e raccogliere informazioni. Smartsheet ha scoperto che oltre il 40% dei lavoratori dedica almeno un quarto delle ore settimanali a compiti manuali e ripetitivi. La sola immissione manuale dei dati costa alle aziende statunitensi una stima di $8.500 per dipendente all’anno.
È proprio questo il problema che OpenClaw browser automation vuole risolvere. In pratica, si traduce in flussi di lavoro aziendali molto concreti:
| Caso d’uso | Cosa fa OpenClaw | Risultato per il business |
|---|---|---|
| Generazione di lead | Estrae informazioni di contatto da directory e pagine aziendali | Pipeline commerciale riempita più velocemente |
| Monitoraggio prezzi dei concorrenti | Visita ogni giorno le pagine prodotto ed estrae i prezzi | Intelligence competitiva in tempo reale |
| Compilazione moduli / data entry | Compila moduli web ripetitivi (CRM, portali, richieste) | Ore risparmiate ogni settimana |
| Monitoraggio contenuti | Controlla blog dei competitor, job board e comunicati stampa | Segnali competitivi anticipati |
| QA / test | Esegue flussi web per verificarne il corretto funzionamento | Meno esperienze utente interrotte |
Il mercato degli agenti AI ha raggiunto $7,38 miliardi nel 2025, quasi raddoppiando rispetto ai $3,7 miliardi del 2023, e l’88% delle organizzazioni usa ormai l’automazione AI in almeno una funzione. Non è più una nicchia.
Chromium in sandbox, Browser Relay o Chrome Remote Debugging: come scegliere la modalità giusta
Scegliere la modalità browser sbagliata è, per esperienza, la principale fonte di frustrazione per chi inizia con OpenClaw. Ho visto persone perdere ore a fare debug di problemi di connessione che si sarebbero evitati scegliendo subito una modalità diversa. OpenClaw offre tre modi per collegarsi, e ognuno ha compromessi reali:
- Sandbox Chromium (Managed Profile): OpenClaw avvia il proprio browser headless sul server. Nessuna sessione di login, configurazione rapida e semplice — ma è più facile da rilevare per i sistemi anti-bot.
- Browser Relay (Existing-Session): un node host sulla tua macchina locale inoltra le istruzioni dal VPS al tuo vero browser Chrome. Supporta sessioni con login e cookie, e eredita il fingerprint del tuo browser reale.
- Chrome Remote Debugging (Remote CDP): si connette a browser remoti tramite WebSocket URL. Accesso completo alla sessione, massima complessità di setup. Funziona con provider cloud come Browserless o Browserbase.

Tabella comparativa: tutte e tre le modalità browser
| Fattore | Sandbox Chromium | Browser Relay | Remote CDP |
|---|---|---|---|
| Supporto login | ❌ No (profilo nuovo) | ✅ Sì (sessioni reali) | ✅ Sì (pre-autenticato) |
| Rischio anti-bot | ⚠️ Medio-Alto | ✅ Basso (fingerprint reale) | ✅ Basso (gestito dal provider) |
| Velocità | ✅ Veloce | ⚠️ Più lenta (relay di rete) | ⚠️ Variabile |
| Complessità di setup | Bassa | Media | Alta |
| Supporto completo alle funzioni | ✅ Sì (tutte le funzioni) | ⚠️ Limitato (niente batch, niente intercetto download) | Dipende dal provider |
| Ideale per | Pagine pubbliche, estrazioni rapide | Siti con login, compilazione moduli | Infrastruttura cloud, monitoraggio sempre attivo |
Diagramma decisionale: quale modalità dovresti scegliere?
Segui queste domande in ordine:
- “Devi effettuare il login?” — No → Sandbox Chromium. Sì → domanda successiva.
- “Il sito ha protezioni anti-bot aggressive?” — Sì → Browser Relay (il fingerprint del tuo browser reale riduce il rischio di rilevamento). No → Browser Relay o Remote CDP.
- “Ti serve una sessione persistente, sempre attiva (per esempio per monitorare una dashboard 24/7)?” — Sì → Remote CDP con un provider cloud. No → Browser Relay.
Mappatura su scenari reali:
- Estrarre listing pubblici di Amazon → Sandbox Chromium
- Compilare un modulo CRM dietro login → Browser Relay
- Monitorare una dashboard di analytics interna 24 ore su 24 → Remote CDP con Browserless/Browserbase
Scegliere bene questa decisione ti farà risparmiare ore di debugging. Davvero.
Prima di iniziare
- Difficoltà: intermedia (serve dimestichezza con la CLI)
- Tempo necessario: 45–75 minuti per la configurazione completa; 10–15 minuti per ogni fase
- Cosa ti serve: un VPS (minimo 2GB di RAM, 4GB consigliati), Node.js v22.12.0+, un account Tailscale (gratuito), il browser Chrome e pazienza
Passo 1: avvia OpenClaw su un VPS (o in locale)
Il VPS è il posto in cui vive il “cervello” di OpenClaw. Ci sono due modi per metterlo in funzione:
Opzione A: hosting VPS con un clic
Diversi provider offrono immagini OpenClaw già configurate:
| Provider | Prezzo iniziale | Note |
|---|---|---|
| Hostinger | Da $6.99/mese | Immagine preconfigurata |
| Tencent Cloud Lighthouse | Da circa $0.08/anno (promo) | Consigliati 2 core/4GB |
| Hetzner | Da $4.09/mese (CX22) | Miglior rapporto qualità/prezzo; installazione manuale |
| DigitalOcean | Da $4/mese | Installazione manuale |
| Vultr | Da $3.50/mese | Installazione manuale |
Opzione B: installazione manuale via CLI
# Installa tramite npm (richiede Node.js v22.12.0+)
npm install -g openclaw
# Avvia la procedura guidata di onboarding
openclaw onboard
# Genera il token del gateway (conservalo: ti servirà per il node host)
openclaw doctor --generate-gateway-token
# Verifica la configurazione
openclaw doctor --fix
Specifiche minime: 2GB di RAM (con 1GB va in crash), 4GB consigliati. Ogni istanza di browser headless consuma 400–800 MB da inattiva. Se usi Docker, imposta shm_size: '2gb' — è fondamentale per la stabilità.
Dopo questo passaggio, dovresti avere OpenClaw in esecuzione e un token Gateway salvato in un posto sicuro. (Io lo tengo in un password manager. Non perderlo.)
Passo 2: configura Tailscale per collegare VPS e macchina locale
Tailscale crea un tunnel privato e cifrato tra il tuo VPS e il tuo dispositivo locale, così le istruzioni del browser non vengono esposte a Internet. Considerando che OpenClaw aveva 512 vulnerabilità segnalate da Kaspersky all’inizio del 2026, saltare questo passaggio sarebbe una pessima idea.
# Sul VPS
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up --ssh=true
# Prendi nota dell'IP Tailscale del VPS (100.x.x.x)
# Configura il Gateway affinché ascolti sulla rete Tailscale
openclaw config set gateway.listen "100.x.x.x:18789"
Installa Tailscale sulla tua macchina locale da tailscale.com/download. Entrambi i dispositivi devono usare lo stesso account Tailscale.
Alternative se Tailscale non fa per te:
| Fattore | Tailscale | Cloudflare Tunnel | WireGuard |
|---|---|---|---|
| Tempo di configurazione | 5 min | 10–15 min | 20–30 min |
| Costo | Gratis (uso personale) | Gratis | Gratis |
| Traversal NAT | Automatico | Automatico | Manuale |
A questo punto dovresti riuscire a pingare l’IP Tailscale del VPS dalla tua macchina locale. Se non funziona, controlla che entrambi i dispositivi siano nello stesso account Tailscale.
Passo 3: installa il Node Host sul tuo dispositivo locale
Il node host inoltra le istruzioni del browser dal Gateway VPS a Chrome locale — il traduttore tra server e browser.
# Installa il pacchetto node host
npm install -g @openclaw/node-host
# Imposta il token del gateway dal Passo 1
export OPENCLAW_GATEWAY_TOKEN="your-token-here"
# Avvia il node host, puntando all'IP Tailscale del tuo VPS
openclaw node install --host 100.x.x.x --port 18789
# Approva la connessione dal lato VPS
openclaw node approve <node-id>
Dovresti vedere una conferma che il nodo è connesso e approvato. Se la fase di approvazione si blocca, riavvia il processo Gateway sul VPS.
Passo 4: installa l’estensione Chrome di OpenClaw
L’estensione consente all’agente di controllare direttamente le schede del browser. Puoi trovarla anche nel Chrome Web Store cercando “OpenClaw Browser Relay.”
# Installa i file dell'estensione
openclaw browser extension install
# Oppure manualmente:
# 1. Apri chrome://extensions
# 2. Abilita "Developer mode" (interruttore in alto a destra)
# 3. Fai clic su "Load unpacked" → seleziona la cartella dell'estensione
# 4. Fissala alla barra degli strumenti
# 5. Verifica che il badge mostri "ON"
Se il badge mostra “ON”, sei pronto. Se resta su “OFF”, vai alla sezione di troubleshooting qui sotto.
Passo 5: esegui il tuo primo task di OpenClaw browser automation
Apri una scheda di destinazione, poi dall’interfaccia chat di OpenClaw prova qualcosa di semplice:
Vai su https://books.toscrape.com ed estrai il titolo e il prezzo di ogni libro nella pagina
Flusso atteso: istruzione inviata → l’agente acquisisce uno snapshot (identifica gli elementi della pagina con riferimenti numerati) → estrae i dati → l’output strutturato viene restituito come JSON o CSV.
Un consiglio nato dall’esperienza: parti con prompt semplicissimi. Aggiungere troppi dettagli può davvero confondere l’AI — inseriscili solo se l’agente interpreta male la prima istruzione.
Per 20 libri nella prima pagina, aspettati circa 30–60 secondi. Se arrivano dati strutturati, la configurazione di OpenClaw browser automation sta funzionando.
OpenClaw Browser Automation su Windows: il percorso di configurazione nativo
La maggior parte delle guide su OpenClaw dà per scontati macOS o Linux. Se sei su Windows, te ne sarai già accorto. Un utente di un forum l’ha detta bene: “molte soluzioni sembravano valide in teoria, ma nessuna era pensata per Windows nativo.”
Ecco cosa funziona davvero.
Opzione A: Chrome Remote Debugging su Windows (percorso nativo consigliato)
L’approccio nativo per Windows più affidabile. Apri PowerShell e avvia Chrome con il debug remoto abilitato:
& "C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Se Chrome non si trova in quel percorso, prova:
# Controlla percorsi alternativi
Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse
# Oppure verifica AppData
& "$env:LOCALAPPDATA\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
Poi configura OpenClaw per connettersi tramite Remote CDP impostando cdpUrl su ws://localhost:9222 nel file di configurazione openclaw.json.
Opzione B: Docker Desktop come fallback su Windows
Se il percorso nativo dà problemi, Docker Desktop su Windows può eseguire un container Chromium headless:
docker run -d --name openclaw-browser -p 9222:9222 --shm-size=2g browserless/chrome
# Punta OpenClaw a: cdpUrl: "ws://localhost:9222"
Aggiunge un altro livello di complessità, ma per alcuni utenti è più stabile. Funziona, anche se non è elegante.
Catalogo degli errori specifici di Windows
| Errore | Causa | Soluzione (PowerShell) |
|---|---|---|
| La porta 9222 è già in uso | Un’altra sessione DevTools è aperta | `Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess |
| Binario di Chrome non trovato | Percorso errato | Get-ChildItem "C:\Program Files*\Google\Chrome\Application\chrome.exe" -Recurse |
| Connessione Tailscale rifiutata | Windows Firewall blocca il traffico | New-NetFirewallRule -DisplayName "OpenClaw" -Direction Inbound -LocalPort 18789 -Protocol TCP -Action Allow |
| Errori di permessi npm | PowerShell non eseguito come amministratore | Avvia PowerShell come Amministratore oppure usa nvm-windows |
Tutti i comandi sopra sono PowerShell, non bash. Copiali e incollali direttamente.
Guida di sopravvivenza anti-bot per OpenClaw Browser Automation
Il rilevamento dei bot è la frustrazione numero uno per chi usa OpenClaw browser automation. Il Chromium predefinito di OpenClaw non ha misure stealth integrate — i siti lo rilevano tramite il flag WebDriver, le dimensioni dello schermo, il fingerprint dei font e la reputazione dell’IP. Ho visto agenti bloccati in pochi secondi su certi siti.
Ma esiste un approccio graduale. Parti dalla soluzione più semplice e sali di livello solo se serve.
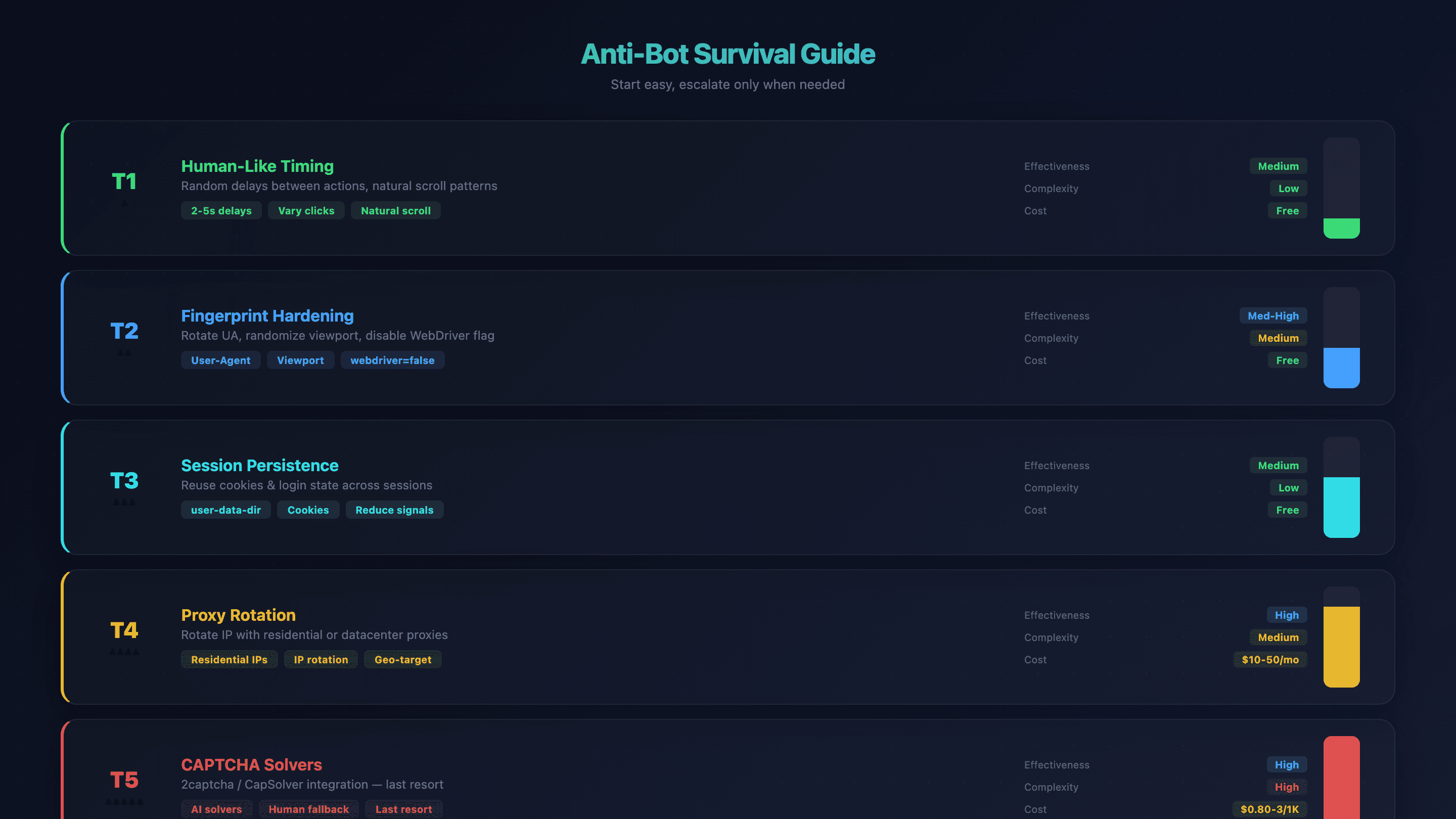
Livello 1: timing e comportamento simili a quelli umani
Aggiungi ritardi casuali tra un’azione e l’altra nei prompt. Invece di far eseguire click alla velocità di una macchina, istruisci l’agente: “aspetta 2–5 secondi tra un click e l’altro”. L’AI varia già il timing in una certa misura, ma istruzioni esplicite aiutano.
Efficacia: media | Complessità: bassa | Costo: gratis
Livello 2: rafforzamento del fingerprint
Ruota le stringhe user-agent, randomizza la dimensione del viewport e lascia che OpenClaw disattivi automaticamente il flag navigator.webdriver (tramite --disable-blink-features=AutomationControlled).
# Imposta header personalizzati
openclaw browser set headers --headers-json '{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36"}'
# Randomizza il viewport
openclaw browser set viewport 1366 768
# Imposta fuso orario e localizzazione
openclaw browser set timezone America/New_York
openclaw browser set locale en-US
Per una protezione anti-rilevamento più profonda, la community consiglia Camoufox (un browser anti-detect basato su Firefox con spoofing del fingerprint a livello di engine C++).
Efficacia: medio-alta | Complessità: media | Costo: gratis
Livello 3: persistenza della sessione
Usa user-data-dir per mantenere cookie e stato di login tra una sessione e l’altra. Questo riduce i segnali da “browser appena avviato” che attivano i sistemi anti-bot.
openclaw config set browser.profiles.persistent.userDataDir "/path/to/chrome-profile"
openclaw config set browser.profiles.persistent.cdpPort 18802
Efficacia: media | Complessità: bassa | Costo: gratis
Livello 4: rotazione proxy
Quando timing e fingerprint non bastano, ruota l’indirizzo IP. I proxy residential sono più difficili da rilevare; quelli datacenter sono più veloci ed economici.
export OPENCLAW_BROWSER_PROXY="http://user:pass@proxy.example.com:8080"
Nota: la configurazione del proxy a livello browser è ancora una richiesta di funzionalità (GitHub Issue #8079). Al momento i proxy devono essere impostati a livello di sistema operativo o di ambiente.
| Provider | Residential | Datacenter | Ideale per |
|---|---|---|---|
| Bright Data | $4–8.40/GB | $0.43–0.60/GB | Enterprise, qualità massima |
| Oxylabs | $6–8/GB | $0.48–5/GB | Scraping su larga scala |
| Decodo (Smartproxy) | $4–5.50/GB | $0.70–5/GB | Budget medio |
| IPRoyal | $5–7/GB | -- | Economico |
| DataImpulse | $1/GB | -- | Costo minimo |
Efficacia: alta | Complessità: media | Costo: $10–50/mese
Livello 5: solver CAPTCHA
Ultima risorsa. Integra servizi come 2captcha o CapSolver.
| Servizio | reCAPTCHA v2 | Cloudflare Turnstile | Latenza |
|---|---|---|---|
| 2Captcha | $2.99/1K | $2.99/1K | 15–45s (operatori umani) |
| CapSolver | $0.80–1.50/1K | $0.80/1K | 0.5–10s (AI) |
FlareSolverr (bypass open source per Cloudflare) viene considerato poco affidabile nel 2025–2026, perché le difese di Cloudflare si sono rafforzate.
Efficacia: alta | Complessità: alta | Costo: $0.80–3/1K solve
Tabella riepilogativa anti-bot
| Tecnica | Efficacia | Complessità | Costo |
|---|---|---|---|
| Timing simile a quello umano | Media | Bassa | Gratis |
| Rafforzamento fingerprint | Medio-alta | Media | Gratis |
| Persistenza sessione | Media | Bassa | Gratis |
| Rotazione proxy | Alta | Media | $10–50/mese |
| Solver CAPTCHA | Alta | Alta | $0.80–3/1K solve |
Per gli utenti che sbattono continuamente contro muri anti-bot e vogliono solo i dati: il cloud scraping di Thunderbit gestisce l’anti-bot nativamente per i siti pubblici — niente configurazione proxy, niente tuning del fingerprint. È un approccio completamente diverso (l’AI legge il sito ogni volta tramite infrastruttura cloud gestita) che bypassa tutta la corsa agli armamenti anti-bot per i normali task di estrazione dati.
Output reale: cosa produce davvero OpenClaw Browser Automation
Prima di investire 45–75 minuti nella configurazione, probabilmente vuoi vedere come appare il risultato finale. Giusto — ecco tre esempi di workflow con output reale.
Esempio 1: web scraping — estrazione dei dati prodotto
Prompt: “Vai su https://books.toscrape.com ed estrai il titolo e il prezzo di ogni libro nella pagina”
Output (prime 5 righe):
| Titolo | Prezzo |
|---|---|
| A Light in the Attic | £51.77 |
| Tipping the Velvet | £53.74 |
| Soumission | £50.10 |
| Sharp Objects | £47.82 |
| Sapiens: A Brief History of Humankind | £54.23 |
Tempo trascorso: circa 45 secondi per 20 righe (una singola pagina). La paginazione ha richiesto un’istruzione successiva: “Fai clic su Next e ripeti per 5 pagine.” Totale: circa 100 righe in circa 3 minuti.
Esempio 2: automazione moduli — compilazione di un form web multi-campo
Scenario: compilazione di un modulo di richiesta fornitore con nome azienda, contatti e interesse di prodotto.
L’agente acquisisce uno snapshot del modulo, identifica ogni campo tramite numero di riferimento e li compila in sequenza. Prima: campi vuoti. Dopo: tutti i campi compilati, messaggio di conferma visualizzato. Eventuali menu a tendina o checkbox vengono gestiti dal sistema di snapshot — l’agente “vede” le opzioni e seleziona quella giusta.
Tempo trascorso: circa 30 secondi per un modulo da 6 campi.
Esempio 3: paginazione — scraping su più pagine
Risultato iniziale: 20 righe dalla pagina 1. Dopo l’istruzione “clicca Next e ripeti per tutte le pagine”: 1.000 righe su 50 pagine di books.toscrape.com. L’agente individua il pulsante “Next” tramite snapshot e lo clicca in loop.
Tempo trascorso: circa 12 minuti per il dataset completo da 1.000 righe.
Confronto affiancato: lo stesso task di scraping in Thunderbit
Per lo stesso esempio su books.toscrape.com, ecco come appare il flusso in Thunderbit:
- Installa la Thunderbit Chrome Extension (~30 secondi)
- Vai alla pagina
- Fai clic su “AI Suggest Fields” → l’AI rileva Title, Price, Availability, Rating
- Fai clic su “Scrape” → vengono estratte 20 righe
- Usa i controlli di paginazione → vengono estratte tutte le pagine
- Esporta su Google Sheets (gratis)
Tempo totale: circa 3 minuti da zero ai dati esportati, senza VPS, senza CLI, senza configurazione.
Il punto non è che uno strumento sia “migliore” in assoluto. Lo strumento giusto dipende da quello che devi davvero fare.
Prova l’estensione Chrome di Thunderbit
Quando OpenClaw Browser Automation è eccessivo (e cosa usare invece)
OpenClaw eccelle nell’automazione complessa e multi-step, guidata da agenti — flussi con login, concatenazione di azioni nel browser con comandi shell, esecuzione 24/7 su un VPS. Ma se l’obiettivo è “estrarre dati prodotto da una pagina elenco” o “raccogliere email da una directory”, l’intero stack VPS + Tailscale + node host probabilmente è sovradimensionato.
Ho visto persone investire oltre 60 minuti di setup per un task che richiede 2 minuti con uno strumento più semplice. Non è un buon compromesso.

Lo strumento giusto per il lavoro: tabella comparativa
| Fattore | OpenClaw Browser Automation | Thunderbit |
|---|---|---|
| Tempo di configurazione | 45–75 min (VPS + Tailscale + node host) | ~2 min (installazione estensione Chrome) |
| Programmazione richiesta | CLI + prompt in linguaggio naturale | Nessuna — clicca “AI Suggest Fields” → “Scrape” |
| Gestione anti-bot | Manuale (proxy, fingerprint config) | Cloud scraping integrato |
| Navigazione di pagine con login | ✅ Browser Relay / remote debug | ✅ Modalità browser scraping |
| Arricchimento delle sottopagine | Scripting personalizzato per ogni flusso | Scraping sottopagine con un clic |
| Esecuzioni programmate / 24×7 | Basate su VPS, sempre attive | Scheduled scraper integrato |
| Costo mensile | $8–14 (hobby) fino a $110–280 (uso intenso) | $0 (free tier) fino a $15/mese |
| Carico di manutenzione | Alto (aggiornamenti, VPS, debugging) | Quasi nullo — l’AI si adatta ai cambi di layout |
| Ideale per | Workflow agentici complessi, pipeline personalizzate | Estrazione dati, compilazione moduli, lead gen, monitoraggio prezzi |
Instradamento per caso d’uso
- Ti servono workflow agentici multi-step che concatenano azioni nel browser con comandi shell, app di messaggistica e database → OpenClaw è la scelta giusta.
- Devi estrarre dati da siti web, compilare moduli o monitorare prezzi senza aprire il terminale → Thunderbit ti porta più velocemente al risultato. Puoi dare un’occhiata al canale YouTube di Thunderbit per demo rapide.
- Ti serve uno script leggero per un singolo endpoint API → potrebbe bastare un semplice script Python con requests.
È davvero il criterio che uso quando qualcuno del mio team mi chiede: “che strumento devo usare per questo?”
Errori comuni di OpenClaw Browser Automation e come risolverli
Salva questa sezione tra i preferiti. È organizzata per sintomi, così puoi usare Ctrl+F per trovare la soluzione.
“Connection Refused” o il Node Host non si connette
Cause probabili (controlla in quest’ordine):
- Tailscale non attivo su entrambi i dispositivi → esegui
tailscale statussu entrambi - Gateway non impostato per ascoltare sulla rete Tailscale (è ancora su localhost) →
openclaw config set gateway.listen "100.x.x.x:18789" - Indirizzo IP errato → verifica con
tailscale ip -4 - Firewall che blocca la porta 18789 →
sudo ufw allow 18789/tcp(Linux) oppure aggiungi una regola su Windows Firewall
Il badge dell’estensione resta su “OFF” o la scheda non viene rilevata
- Estensione non caricata in Developer mode →
chrome://extensions→ abilita Developer mode → ricarica - Node host non in esecuzione → riavvia con
openclaw node start - Conflitto con l’istanza Chrome → chiudi tutte le istanze di Chrome, riavvia e ricarica l’estensione
L’agente restituisce dati vuoti o errati
- Pagina non ancora completamente caricata: istruisci l’agente a “aspettare 3 secondi dopo la navigazione prima di estrarre”. Molte SPA hanno bisogno di tempo per renderizzare.
- Blocco anti-bot: verifica se stai vedendo una pagina CAPTCHA invece del contenuto reale. Passa da Sandbox Chromium a Browser Relay.
- Snapshot obsoleto: chiedi all’agente di “fare un nuovo snapshot” — i numeri di riferimento diventano obsoleti dopo la navigazione.
“Port 9222 Already in Use”
Succede spesso quando Chrome DevTools o un altro strumento di automazione sta già usando la porta.
# macOS/Linux
lsof -i :9222 | grep LISTEN
kill -9 <PID>
# Windows PowerShell
Get-Process -Id (Get-NetTCPConnection -LocalPort 9222).OwningProcess | Stop-Process -Force
Il VPS esaurisce la memoria
Ogni istanza di browser headless usa 400–800 MB di RAM. Eseguirne più di una insieme può mandare in crash un VPS piccolo.
Soluzioni:
- Disabilita il caricamento di immagini/CSS/font:
openclaw browser network route --abort "**/*.{png,jpg,gif,css,woff2}" - Limita le istanze concorrenti a quanto la tua RAM può sostenere
- Imposta
shm_size: '2gb'nelle configurazioni Docker - Abilita l’ibernazione della sessione:
OPENCLAW_HIBERNATE_AFTER=300 - Passa a un VPS da 4GB+ di RAM se ti serve più margine
Suggerimenti per mantenere fluida la tua OpenClaw Browser Automation
Alcune best practice che ho imparato gestendo queste configurazioni nel tempo:
- Disattiva immagini, stylesheet e font per i task di scraping che servono solo a raccogliere dati. Riduce molto il consumo di risorse e accelera l’esecuzione.
- Riutilizza le istanze del browser invece di avviarne una nuova per ogni task. Le istanze nuove sono costose in termini di RAM e generano più segnali anti-bot.
- Inizia con prompt semplici. Aggiungi dettagli solo se l’agente interpreta male. Descrivere troppo può confondere l’AI più che aiutarla.
- Monitora l’uso delle risorse del VPS (CPU, RAM) e scala prima di arrivare al limite. Un VPS in crash alle 2 di notte non è piacevole da debuggare.
- Tieni aggiornati OpenClaw e l’estensione Chrome — ma prova gli aggiornamenti prima in un ambiente di staging. OpenClaw rilascia circa 13 versioni al mese, e non tutte sono perfette.
- Per attività ricorrenti e continuative (controlli prezzi giornalieri, raccolta lead settimanale), il scheduled scraper di Thunderbit ti permette di impostare intervalli in linguaggio naturale e dimenticarti completamente della manutenzione del VPS.
Considerazioni etiche e legali
Breve ma importante. Rispetta robots.txt (formalizzato come standard IETF in RFC 9309), limita la frequenza delle richieste, verifica i termini di servizio dei siti target e gestisci i dati personali secondo GDPR e leggi sulla privacy. Il precedente hiQ v. LinkedIn (2022) ha stabilito che estrarre dati pubblicamente accessibili non viola il CFAA, ma questo non significa che tutto sia consentito. Usare l’automazione in modo responsabile protegge te e la tua azienda. Per approfondire, consulta la nostra guida sulle implicazioni legali del web scraping.
Conclusione
OpenClaw browser automation è una soluzione potente per workflow web complessi e multi-step guidati dal linguaggio naturale. Ecco ciò che conta di più:
- Scegli subito la modalità browser giusta (Sandbox, Relay, Remote CDP) — questa singola decisione può farti risparmiare ore di debugging.
- Gli utenti Windows hanno un percorso praticabile, ma devono seguire comandi specifici per Windows e fare attenzione a firewall e percorsi dei file.
- La gestione anti-bot è una vera sfida — inizia dalle tecniche più semplici (timing, fingerprint) ed espandi solo se necessario.
- Guarda l’output prima di impegnarti. Se ti bastano dati strutturati da una pagina elenco, uno strumento no-code come Thunderbit ti porta al risultato in pochi minuti e senza manutenzione.
- Metti in conto la manutenzione. OpenClaw rilascia circa 13 update al mese, i costi del VPS si accumulano e il debugging fa parte del pacchetto.
Se vuoi provare prima la strada semplice, Thunderbit offre un piano gratuito — installa l’estensione, estrai una pagina e verifica se copre il tuo caso d’uso prima di investire in una configurazione VPS completa. Se invece scegli OpenClaw, salva questa guida tra i preferiti. Prima o poi ti servirà il catalogo degli errori — e che le tue istanze browser abbiano sempre RAM a sufficienza.
FAQ
Qual è la differenza tra OpenClaw Sandbox Chromium e Browser Relay?
Sandbox Chromium esegue un browser headless sul server — è veloce e semplice da configurare, ma crea ogni volta un profilo nuovo (quindi niente sessioni di login) ed è più facile da rilevare per i sistemi anti-bot. Browser Relay invece inoltra le istruzioni al tuo vero browser Chrome sulla macchina locale, quindi supporta i login, eredita il fingerprint reale del browser ed è più difficile da individuare come automazione. Il compromesso è che Browser Relay è più lento a causa del relay di rete e ha alcune limitazioni funzionali (niente azioni batch, niente intercetto dei download).
Posso usare OpenClaw browser automation su Windows senza WSL?
Sì, ma con alcune precisazioni. Il percorso nativo per Windows più affidabile è Chrome Remote Debugging tramite PowerShell (chrome.exe --remote-debugging-port=9222). Docker Desktop è un fallback se quello non funziona in modo affidabile. Il supporto completo del Node Host nativo su Windows può avere qualche asperità — controlla la documentazione aggiornata e preparati a gestire problemi specifici di Windows come blocchi del firewall e differenze nei percorsi dei binari. Tutti i comandi nella sezione Windows di questa guida sono PowerShell, non bash.
Come posso gestire i CAPTCHA in OpenClaw browser automation?
Inizia riducendo il rischio di rilevamento: aggiungi timing simile a quello umano, rafforza il fingerprint del browser e usa la persistenza della sessione per evitare segnali di browser nuovo. Se i CAPTCHA persistono, integra un servizio di solver come 2captcha ($2.99/1K solve) o CapSolver ($0.80–1.50/1K, basato su AI). Per siti pubblici in cui ti servono solo i dati, il cloud scraping di Thunderbit gestisce l’anti-bot automaticamente senza alcuna configurazione di proxy o CAPTCHA.
OpenClaw browser automation è gratuito?
OpenClaw in sé è open source (licenza MIT) e gratuito. Tuttavia, per farlo funzionare serve un’infrastruttura — un VPS da $4–15/mese, più servizi opzionali come rotazione proxy ($10–50/mese) o solver CAPTCHA (paghi per ogni solve). Il costo mensile totale varia da $8–14 per uso amatoriale fino a $110–280 per carichi di automazione pesanti. In confronto, il free tier di Thunderbit copre lo scraping di base senza costi infrastrutturali.
Cosa devo fare se il mio agente OpenClaw continua a restituire risultati vuoti?
Controlla tre cose, in quest’ordine: primo, la pagina potrebbe non essere completamente caricata — istruisci l’agente a “aspettare 3 secondi dopo la navigazione prima di estrarre”. Secondo, potresti trovarti davanti a un muro anti-bot — se l’agente “vede” una pagina CAPTCHA invece del contenuto reale, passa da Sandbox Chromium a Browser Relay. Terzo, i riferimenti dello snapshot potrebbero essere obsoleti — chiedi all’agente di “fare un nuovo snapshot” dopo ogni navigazione. Se niente funziona, verifica l’uso della memoria del VPS — un’istanza browser in crash restituisce risultati vuoti senza segnalazioni evidenti.
Prova Thunderbit per un’estrazione dati web più rapida Get Started Free




