

Il web nel 2026 è un posto selvaggio: ormai metà del traffico internet è generata dai bot, e i crawler web open-source sono gli eroi silenziosi che lavorano dietro le quinte, alimentando tutto, dal monitoraggio dei prezzi all’addestramento dell’IA. Ho passato anni nel mondo SaaS e dell’automazione e, se c’è una cosa che ho imparato, è che scegliere il crawler web self-hosted giusto può far risparmiare al tuo team mesi di grattacapi (e magari anche qualche sessione di debug notturna). Che tu debba estrarre una manciata di pagine prodotto o fare crawling di milioni di URL per una ricerca, le alternativa open-source a firecrawl in questa lista hanno quello che ti serve, qualunque sia la tua scala, il tuo stack tecnologico o la tua tolleranza alla complessità.
Ma ecco il punto: non esiste una soluzione valida per tutti. Alcuni team hanno bisogno della potenza grezza di Scrapy o della solidità archivistica di Heritrix, mentre altri potrebbero trovare troppo onerosa la manutenzione delle librerie open-source. Quindi analizziamo le 9 migliori alternative open-source a Firecrawl per il 2026, vediamo in cosa eccelle ciascuna e aiutiamoti a trovare lo strumento giusto per le esigenze della tua azienda, senza il dolore dei tentativi ed errori.
Come scegliere la migliore alternativa open-source a Firecrawl per la tua azienda
Prima di buttarti nell’elenco, parliamo di strategia. Il panorama del web crawling open-source è più vario che mai e la tua scelta dovrebbe dipendere da alcuni fattori chiave:
- Facilità d’uso: preferisci un’interfaccia punta-e-clicca o ti senti a tuo agio a scrivere Python, Go o JavaScript?
- Scalabilità: devi estrarre dati da un solo sito o fare crawling di milioni di pagine su centinaia di domini?
- Tipo di contenuto: il sito di destinazione è HTML statico oppure si basa molto su JavaScript e caricamento dinamico?
- Esigenze di integrazione: come vuoi usare i dati: esportarli in Excel, inviarli a un database o alimentarli in una pipeline di analytics?
- Manutenzione: hai le risorse per mantenere codice personalizzato o vuoi uno strumento che si adatti automaticamente ai cambiamenti del sito?
Ecco una guida rapida per aiutarti a decidere:
| Scenario | Strumento/i migliore/i |
|---|---|
| No-code, navigazione offline | HTTrack |
| Crawling su larga scala, multi-dominio | Scrapy, Apache Nutch, StormCrawler |
| Siti dinamici / con molti JS | Puppeteer |
| Automazione di form / login richiesti | MechanicalSoup |
| Download/archiviazione di siti statici | Wget, HTTrack, Heritrix |
| Sviluppatore Go, alte prestazioni | Colly |
Ora entriamo nel vivo delle 9 migliori alternative open-source a Firecrawl per il 2026.
1. Scrapy: il migliore per il crawling Python su larga scala

Scrapy è il campione dei pesi massimi del web crawling open-source. Costruito in Python, è il framework di riferimento per gli sviluppatori che devono fare crawling su larga scala: milioni di pagine, aggiornamenti frequenti e logiche di sito complesse.
Perché Scrapy?
- Scala enorme: Scrapy può gestire migliaia di richieste al secondo ed è usato da aziende che estraggono miliardi di pagine al mese (Zyte).
- Estendibile e modulare: puoi scrivere spider personalizzati, aggiungere middleware per i proxy, gestire i login ed esportare in JSON, CSV o database.
- Community attiva: tantissimi plugin, documentazione e risposte su Stack Overflow.
- Collaudato in produzione: usato da team di e-commerce, news e ricerca in tutto il mondo.
Limiti: curva di apprendimento ripida per chi non sviluppa, e dovrai mantenere gli spider quando i siti cambiano. Ma se vuoi controllo totale e scalabilità, Scrapy è difficile da battere.
2. Apache Nutch: il migliore per i motori di ricerca enterprise
Apache Nutch è il capostipite dei crawler open-source, progettato per crawling di livello enterprise e su scala internet. Se sogni di costruire il tuo motore di ricerca o di eseguire crawling su milioni di domini, Nutch è il tuo alleato.
Perché Apache Nutch?
- Scala supportata da Hadoop: costruito su Hadoop, Nutch può fare crawling di miliardi di pagine su cluster di server (Common Crawl lo usa per eseguire crawling del web pubblico).
- Crawling batch: gli passi un elenco di URL seed e lo lasci lavorare: perfetto per job pianificati e su larga scala.
- Integrazione: funziona con Solr, Elasticsearch e pipeline big data.
Limiti: configurazione complessa (pensa a cluster Hadoop e file di configurazione Java) ed è più orientato al crawling grezzo che all’estrazione di dati strutturati. Eccessivo per piccoli progetti, ma imbattibile per il crawling su scala web.
3. Heritrix: il migliore per web archiving e conformità

Heritrix è il crawler dell’Internet Archive, progettato appositamente per l’archiviazione del web e la conservazione digitale.
Perché Heritrix?
- Completezza da livello archivistico: cattura ogni pagina, asset e link, perfetto per conformità legale o snapshot storici.
- Output WARC: salva tutto in file Web ARChive standardizzati, pronti per il replay o l’analisi.
- Amministrazione via web: configura e monitora i crawl tramite un’interfaccia browser.
Limiti: pesante, richiede molto spazio su disco e memoria, non esegue JavaScript e produce archivi grezzi invece di tabelle di dati strutturati. Ideale per biblioteche, archivi o settori regolamentati.
4. Colly: il migliore per sviluppatori Go ad alte prestazioni
Colly è il preferito dagli sviluppatori Go: un web scraper veloce, leggero e altamente concorrente.
Perché Colly?
- Velocissimo: la concorrenza di Go permette a Colly di estrarre migliaia di pagine con un uso minimo di CPU/RAM (Oxylabs).
- API semplice: definisci callback per gli elementi HTML, gestisci cookie e robots.txt automaticamente.
- Perfetto per siti statici: ideale per pagine renderizzate lato server, API o per integrare lo scraping in un backend Go.
Limiti: niente rendering JavaScript integrato (per i siti dinamici dovrai affiancarlo a qualcosa come Chromedp) e devi conoscere Go.
5. MechanicalSoup: il migliore per la semplice automazione dei form

MechanicalSoup è una libreria Python che colma il divario tra semplici richieste HTTP e automazione completa del browser.
Perché MechanicalSoup?
- Automazione dei form: login, compilazione di form e gestione delle sessioni in modo semplice: ottimo per scraping dietro autenticazione.
- Leggero: usa Requests e BeautifulSoup sotto il cofano, quindi è veloce e facile da configurare.
- Perfetto per siti interattivi: se devi inviare form di ricerca o estrarre dati dopo il login, MechanicalSoup è un’ottima scelta (Apify Blog).
Limiti: nessuna esecuzione JavaScript, quindi non funziona con siti pesanti in JS. Ideale per pagine statiche o renderizzate lato server con interazioni semplici.
6. Puppeteer: il migliore per siti dinamici e ricchi di JavaScript
Puppeteer è il coltellino svizzero per lo scraping dei siti moderni e ricchi di JavaScript. È una libreria Node.js che ti offre il controllo totale di un browser Chrome headless.
Perché Puppeteer?
- Gestisce contenuti dinamici: estrae dati da SPA, infinite scroll e pagine che caricano dati via AJAX (Browserless Guide).
- Simulazione dell’utente: clicca pulsanti, compila form, fa screenshot e persino risolve CAPTCHA (con i plugin giusti).
- Automazione potente: ottimo per testing, monitoring ed estrazione di tutto ciò che un utente reale può vedere.
Limiti: richiede molte risorse (esegue istanze complete di Chrome), è più lento degli scraper solo HTTP e per scalare servono hardware robusto o orchestrazione cloud.
7. Wget: il migliore per download rapidi da riga di comando

Wget è lo strumento classico da riga di comando per scaricare siti statici e file.
Perché Wget?
- Semplicità: scarica interi siti o directory con un solo comando, senza bisogno di programmare.
- Velocità: scritto in C, è veloce ed efficiente.
- Ottimo per contenuti statici: perfetto per siti di documentazione, blog o download di file in massa (HuggingFace Guide).
Limiti: niente esecuzione JavaScript né gestione dei form, e scarica pagine grezze, non dati strutturati. Pensalo come un aspirapolvere digitale per siti statici.
8. HTTrack: il migliore per la navigazione offline, senza codice
HTTrack è il cugino più user-friendly di Wget, con un’interfaccia grafica per rispecchiare i siti web.
Perché HTTrack?
- Semplicità GUI: una procedura guidata passo dopo passo lo rende accessibile anche agli utenti non tecnici.
- Navigazione offline: adatta i link in modo che tu possa navigare localmente i siti copiati.
- Ottimo per l’archiviazione: perfetto per ricercatori, marketer o chiunque voglia uno snapshot di un sito senza scrivere codice (Reddit DataHoarder).
Limiti: non supporta contenuti dinamici, può essere lento sui siti grandi e non è progettato per l’estrazione di dati strutturati.
9. StormCrawler: il migliore per il crawling distribuito in tempo reale

StormCrawler è il crawler distribuito moderno per i team che hanno bisogno di dati web continui e in tempo reale su larga scala.
Perché StormCrawler?
- Crawling in tempo reale: costruito su Apache Storm, elabora i dati come stream: perfetto per il monitoraggio delle notizie o i motori di ricerca (Wikipedia).
- Modulare e scalabile: aggiungi parsing, indexing e bolt di elaborazione personalizzati secondo le necessità.
- Usato da Common Crawl: alimenta il dataset news di uno dei più grandi archivi web aperti.
Limiti: richiede sviluppo Java e un cluster Storm, quindi è adatto soprattutto a team con esperienza in sistemi distribuiti. Eccessivo per piccoli progetti.
Confronto tra le alternative open-source a Firecrawl: quale competitor gratuito fa al caso tuo?
Ecco una panoramica affiancata di tutti e 9 gli strumenti:
| Strumento | Caso d’uso migliore | Vantaggi principali | Svantaggi | Linguaggio / configurazione |
|---|---|---|---|---|
| Scrapy | Crawling su larga scala e frequente | Potente, scalabile, enorme community | Curva di apprendimento ripida, richiede Python | Framework Python |
| Apache Nutch | Crawling enterprise, su scala web | Supportato da Hadoop, collaudato su larga scala | Configurazione complessa, orientato al batch | Java/Hadoop |
| Heritrix | Crawling per archiviazione e conformità | Cattura completa del sito, output WARC | Pesante, niente JS, archivi grezzi | App Java, interfaccia web |
| Colly | Sviluppatori Go, scraping ad alte prestazioni | Veloce, API semplice, concorrenza | Niente JS, richiede Go | Libreria Go |
| MechanicalSoup | Automazione dei form, scraping con login | Leggero, gestione sessioni | Niente JS, scala limitata | Libreria Python |
| Puppeteer | Siti dinamici e ricchi di JS | Controllo completo del browser, automazione | Richiede molte risorse, Node.js necessario | Libreria Node.js |
| Wget | Download di siti statici, accesso offline | Semplice, veloce, CLI | Niente JS, pagine grezze | Strumento da riga di comando |
| HTTrack | Utenti non tecnici, archiviazione siti | GUI, navigazione offline semplice | Niente JS, lento sui siti grandi | App desktop (GUI) |
| StormCrawler | Crawling distribuito in tempo reale | Scalabile, modulare, in tempo reale | Serve esperienza con Java/Storm | Cluster Java/Storm |
Conviene costruire il tuo crawler o usare un’alternativa open-source a Firecrawl già esistente?
Ecco la verità sincera: costruire il proprio crawler sembra divertente, finché non ti ritrovi immerso nella manutenzione, nei proxy e nei problemi anti-bot. Gli strumenti open-source sopra raccolgono anni di esperienza maturata sul campo e la saggezza della community. Secondo i rapporti di settore, usare soluzioni già esistenti è il modo più veloce e affidabile per ottenere risultati ed evitare di reinventare la ruota (IveerData).
- Adotta l’open-source se: le tue esigenze corrispondono a ciò che esiste già, vuoi ridurre i tempi di sviluppo e dai valore al supporto della community.
- Costruisci il tuo se: hai requisiti davvero unici, una profonda competenza interna e lo scraping è centrale per il tuo business.
Tuttavia, l’open-source non è davvero “gratis” se consideri il costo del tempo degli ingegneri, della manutenzione dei server e degli aggiornamenti continui per contrastare le misure anti-scraping. Se vuoi i vantaggi di un crawler potente senza scrivere codice, c’è un’altra opzione.
Bonus: quando l’open-source è troppo complesso, prova Thunderbit
Anche se gli strumenti elencati sopra sono incredibili per gli sviluppatori, condividono tutti alcune limitazioni: richiedono competenze di programmazione, faticano con i sistemi anti-bot dinamici basati su IA e necessitano di manutenzione costante.
Thunderbit è la mia raccomandazione di riferimento per chiunque voglia superare questi limiti. Colma il divario tra scraping potente e facilità d’uso.
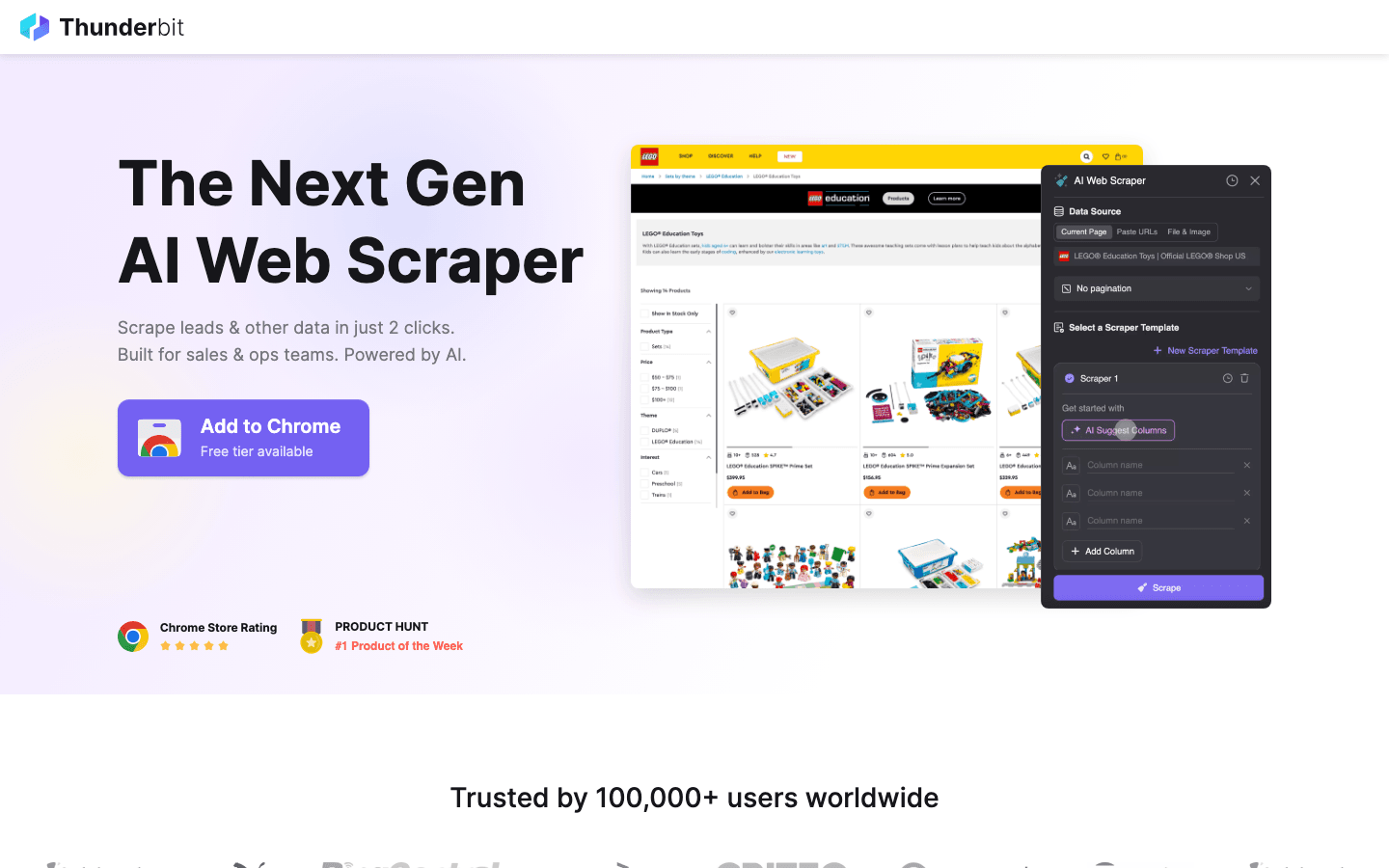
Perché considerare Thunderbit invece dell’open-source?
- Zero codice richiesto: a differenza di Scrapy o Puppeteer, Thunderbit è un’estensione Chrome con IA. Fai clic su “AI Suggest Fields” e lo scraper viene costruito per te.
- Gestisce le parti difficili: contenuti dinamici, scroll infinito e paginazione vengono gestiti automaticamente dall’IA, facendoti risparmiare ore di scrittura di script personalizzati.
- Esportazione immediata: passa dal sito a Excel, Google Sheets o Notion in due clic.
- Nessuna manutenzione: non devi aggiornare il codice quando un sito cambia layout; l’IA di Thunderbit si adatta per te.
Se sei un commerciale, un marketer o un ricercatore che vuole i dati subito senza imparare Python o Go, Thunderbit è il complemento perfetto agli strumenti open-source di questa lista.
Vuoi vederlo in azione? Scarica l’estensione Chrome e provala tu stesso.
Prova Thunderbit AI Web Scraper
Conclusione: trovare il crawler web self-hosted giusto per il 2026
Leggi altre guide sul web scraping Get Started Free
Il mondo delle alternative open-source a Firecrawl è più ricco che mai. Che tu abbia bisogno della potenza di Scrapy o Nutch, o della precisione archivistica di Heritrix, esiste una soluzione per ogni scenario aziendale. La chiave è abbinare lo strumento alle tue esigenze: non esagerare con l’ingegneria se ti serve solo un rapido recupero di dati, e non risparmiare troppo se devi fare crawling su scala internet.
E ricorda: se la strada open-source si rivela troppo tecnica o dispendiosa in termini di tempo, strumenti IA come Thunderbit sono pronti a prendere il posto.
Pronto a partire? Avvia Scrapy per il tuo prossimo grande progetto dati, oppure Prova Thunderbit per uno scraping semplice e potenziato dall’IA. Se vuoi altri consigli sul web scraping, dai un’occhiata al Thunderbit Blog per approfondimenti e tutorial.
Prova Thunderbit per il Web Scraping con IA
FAQ
1. Qual è il principale vantaggio di usare alternative open-source a Firecrawl?
Le alternative open-source offrono flessibilità, risparmio sui costi e la possibilità di self-hosting e personalizzazione del crawler. Eviti il vendor lock-in e benefici del supporto e degli aggiornamenti della community.
2. Quale strumento è il migliore per utenti non tecnici che hanno bisogno di risultati rapidi?
HTTrack è una scelta open-source solida per la navigazione offline. Tuttavia, per l’estrazione di dati strutturati (come tabelle Excel), consigliamo lo strumento bonus Thunderbit grazie alle sue capacità IA.
3. Come gestisco siti web dinamici e ricchi di JavaScript?
Puppeteer è la scelta migliore: controlla un browser reale, quindi può estrarre qualsiasi cosa un utente possa vedere, incluse le SPA e i contenuti caricati via AJAX.
4. Quando dovrei usare un crawler pesante come Apache Nutch o StormCrawler?
Se devi fare crawling di milioni di pagine su molti domini, o hai bisogno di crawling distribuito in tempo reale (per esempio per motori di ricerca o monitoraggio delle notizie), questi strumenti sono progettati per scala e affidabilità.
5. È meglio costruire un mio crawler o usare una soluzione open-source già esistente?
Per la maggior parte dei team, usare e personalizzare uno strumento open-source esistente è più veloce, economico e affidabile. Costruisci il tuo solo se hai esigenze molto specialistiche e le risorse per mantenerlo nel lungo periodo.
Buon crawling — e che i tuoi dati siano sempre freschi, strutturati e pronti all’uso.
Prova gratis Thunderbit AI Web Scraper Get Started Free
Scopri di più
- Le 5 migliori software per lo scraping di dati web nel 2026
- I 15 migliori AI Web Crawler da conoscere nel 2025
- Le 5 migliori software per lo scraping di dati web nel 2026
- I 7 strumenti più popolari per il web scraping da usare nel 2026
- I 6 strumenti essenziali per il web scraper per avere successo nel 2025




