Il web è sempre più assetato di dati e nel 2025 si conferma come la scelta top per chi vuole fare scraping in modo furbo, non solo a colpi di forza bruta. Che tu sia nel commerciale, nell’ecommerce o semplicemente un fanatico dei dati come me, avrai notato che oggi l’estrattore web non serve solo a “prendere dati”, ma a farlo in modo rapido, su larga scala e senza rischiare di farsi bloccare l’IP. Con un mercato dello scraping web che si prevede passerà da 7,48 miliardi di dollari nel 2025 a quasi 38,4 miliardi entro il 2034 (), la competizione è alle stelle e la posta in gioco non è mai stata così alta.
Ma c’è un ostacolo: il web moderno è una vera fortezza fatta di contenuti dinamici, trappole anti-bot e layout che cambiano in continuazione. Ho visto più di uno scraper andare in tilt—spesso perché non seguiva le best practice o sottovalutava la furbizia delle difese anti-scraping. Vediamo allora le strategie più efficaci per rendere lo scraping web con Node.js davvero efficiente, con qualche aneddoto, un po’ di ironia e tanti consigli pratici.
Perché puntare su Node.js per uno scraping web efficiente?
Se hai mai provato a estrarre dati da centinaia o migliaia di pagine in contemporanea, sai che velocità e concorrenza sono tutto. Qui Node.js dà il meglio: il suo modello asincrono e non bloccante è pensato per gestire una valanga di richieste di rete in parallelo—immaginalo come il multitasker definitivo del web (). Mentre altri linguaggi si bloccano in attesa che ogni richiesta finisca, Node.js continua a far girare il suo event loop, gestendo le richieste come un giocoliere caffeinomane.
Ho visto Node.js superare Python e Java in situazioni che richiedono aggiornamenti in tempo reale e grandi volumi di dati, soprattutto quando i siti target sono pieni di JavaScript. Oggi, usa Node.js per backend e automazione, rendendolo la tecnologia web più diffusa al mondo.
Node.js vs. altri framework per lo scraping web
Facciamo un confronto tecnico. Ecco come si posiziona Node.js rispetto agli altri:
| Framework | Punti di forza | Punti deboli | Migliori utilizzi |
|---|---|---|---|
| Node.js | Asincrono, ottimo per la concorrenza, vasto ecosistema npm, JS nativo per siti dinamici | Può consumare molta memoria, rischio di callback hell (se non si usa async/await) | Scraping in tempo reale, siti ricchi di JS, microservizi scalabili |
| Python | Tante librerie per scraping (BeautifulSoup, Scrapy), sintassi semplice | Più lento nella concorrenza massiva, fatica con siti JS | HTML statico, ricerca, prototipazione |
| Java | Tipizzazione forte, robusto per l’enterprise | Verboso, meno flessibile per script rapidi | Scraping su larga scala, progetti enterprise |
| Go | Veloce, concorrenza efficiente | Ecosistema più piccolo, curva di apprendimento ripida | Scraping ad alte prestazioni, bassa latenza |
Per la maggior parte delle aziende, Node.js è la scelta ideale: veloce, flessibile e perfetto per il web moderno dominato da JavaScript ().
Come impostare un ambiente Node.js solido per lo scraping web
Un estrattore web che si rispetti parte da una base robusta. Ecco la mia configurazione preferita:
- Struttura del progetto: Tieni il codice ordinato e modulare. Usa cartelle come
/src,/libse/config. Conserva info sensibili (API key, proxy) in variabili d’ambiente condotenv(). - Client HTTP: Scegli tra , o per le richieste.
- Parsing HTML: per HTML statico, o Playwright per contenuti dinamici.
- Utility: Usa per manipolare i dati, o per la validazione.
- Testing & linting: Mocha per i test, ESLint per la qualità del codice ().
Librerie essenziali per lo scraping web con Node.js
- axios/got/node-fetch: Per inviare richieste HTTP. Personalmente preferisco Axios per la sua API basata su promise e la gestione JSON integrata.
- Cheerio: Parser HTML veloce, simile a jQuery. Perfetto per pagine statiche—parsing in circa 0,5s ().
- Puppeteer/Playwright: Automazione browser headless per siti dinamici e pieni di JS. Più lenti (~4s a pagina), ma indispensabili per contenuti caricati dopo il load ().
- dotenv: Per la gestione delle variabili d’ambiente.
- csv-writer/jsonfile: Per esportare i dati.
Come evitare gli errori più comuni nello scraping con Node.js
Ho perso il conto di quante volte ho visto estrattori web bloccati, crashare o restituire dati inutilizzabili. Ecco cosa evitare:
- Ignorare robots.txt e i Termini di Servizio: Controlla sempre prima di estrarre dati. Ignorare queste regole può portare al ban dell’IP o a grane legali ().
- Sovraccaricare i server: Non inviare richieste a raffica. Limita la velocità con ritardi casuali (1–3 secondi), controlla la concorrenza e non comportarti come un robot iperattivo ().
- Gestione errori assente: Avvolgi sempre le richieste in try/catch, gestisci gli errori HTTP e registra i fallimenti. Riprova gli errori temporanei con backoff esponenziale ().
- Dimenticare gli header delle richieste: Usa User-Agent realistici e ruotali. Aggiungi Accept-Language, Referer e altri header per simulare un browser vero ().
Come aggirare i sistemi anti-scraping
I siti moderni sono pieni di tecnologie anti-bot. Ecco come superare questi ostacoli:
- Rotazione proxy/IP: Usa un pool di proxy e cambia IP per evitare blocchi ().
- Header randomizzati: Cambia User-Agent, Accept-Language e altri header ad ogni richiesta.
- Stealth browser headless: Usa plugin come
puppeteer-extra-plugin-stealthper mascherare le impronte di automazione. - Simula il comportamento umano: Aggiungi ritardi casuali, movimenti del mouse, scroll e persino errori di battitura ().
Simulare il comportamento umano negli scraper Node.js
Qui ci si può anche divertire. Invece di cliccare e scrollare all’istante, programma l’estrattore web per:
- Attendere intervalli casuali tra le azioni (
await page.waitForTimeout(randomDelay)) - Muovere il mouse a piccoli scatti irregolari (
page.mouse.move(x, y)) - Scrivere con ritardi casuali e qualche errore di battitura (
page.type(selector, text, {delay: random(100,200)})) - Scrollare in modo irregolare, non solo fino in fondo
Questi accorgimenti possono aumentare di molto il successo su siti protetti ().
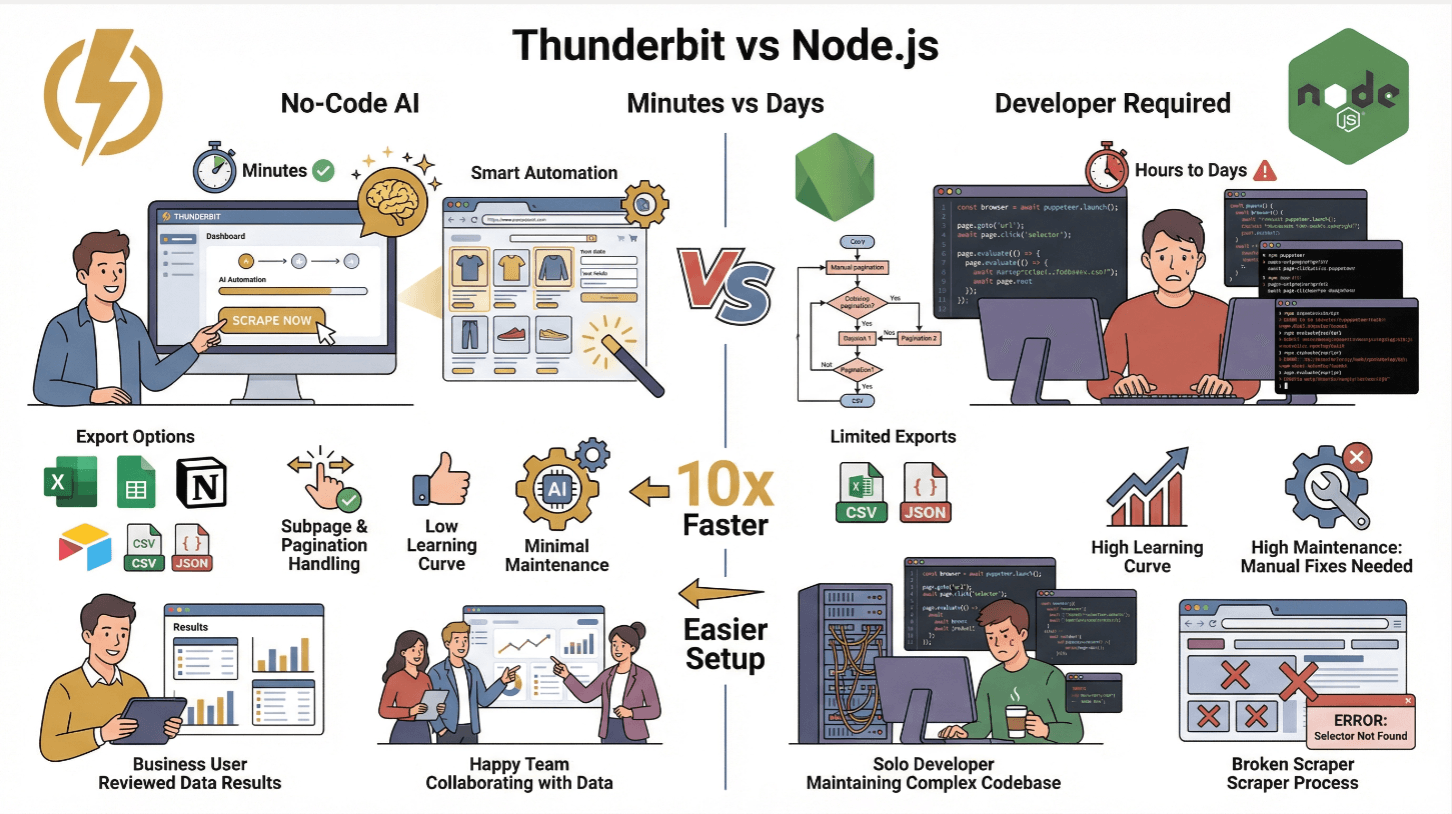
Semplificare l’estrazione dati complessa con Thunderbit
Diciamolo chiaramente: lo scraping può diventare un incubo. Ma non deve per forza esserlo. Ecco perché abbiamo creato .
Thunderbit è un Estrattore Web AI per Chrome che ti permette di estrarre dati da qualsiasi sito usando semplici istruzioni in italiano. Basta cliccare su “AI Suggerisci Campi”, lasciare che l’AI analizzi la pagina e premere “Estrai”. È come avere un assistente junior che lavora 24/7 e non chiede mai ferie.
Ancora meglio, Thunderbit offre anche un’API, così puoi integrarlo direttamente nei tuoi flussi Node.js. Invece di scrivere migliaia di righe di codice, lasci che Thunderbit gestisca tutto il lavoro pesante—contenuti dinamici, sottopagine, paginazione e altro. Tu ricevi i dati già pronti (CSV, JSON o direttamente su Google Sheets, Airtable, Notion) e puoi concentrarti su ciò che conta davvero ().
Thunderbit vs. scraping tradizionale con Node.js
| Funzionalità | Thunderbit | Scraper Node.js tradizionale |
|---|---|---|
| Tempo di setup | Minuti (senza codice) | Da ore a giorni (codice, test) |
| Gestione contenuti dinamici | Sì (AI + browser) | Sì (con Puppeteer/Playwright) |
| Sottopagine & paginazione | 1 click | Richiede codice manuale |
| Esportazione dati | Excel, Sheets, Notion, Airtable, CSV, JSON | CSV/JSON (codice custom) |
| Curve di apprendimento | Bassa (anche per non tecnici) | Alta (per sviluppatori) |
| Manutenzione | Minima (l’AI si adatta) | Elevata (fix manuali ai cambi sito) |
Thunderbit è perfetto per team non tecnici o per chi vuole saltare la parte noiosa e concentrarsi sulle analisi. Gli utenti avanzati possono comunque usare l’API di Thunderbit per automatizzare lo scraping su larga scala ().
Combinare Cheerio e Puppeteer per contenuti dinamici
Questa è la mia combo preferita per scraping con Node.js. Ecco come funziona:
- Usa Puppeteer per caricare la pagina ed eseguire JavaScript (aspetta
networkidleper essere sicuro che sia tutto caricato). - Recupera l’HTML con
await page.content(). - Analizza con Cheerio: Passa l’HTML a Cheerio per un parsing veloce in stile jQuery.
Questo approccio ibrido ti dà il meglio di entrambi: la potenza di Puppeteer per i contenuti dinamici e la velocità di Cheerio per il parsing ().
Consiglio sulle performance: Seleziona solo gli elementi che ti servono. Cheerio carica tutto il DOM in memoria, quindi evita selettori troppo ampi e usa la cache se estrai spesso dalle stesse pagine ().
Ottimizzare il parsing HTML e l’estrazione dati
- Usa selettori specifici: Evita
$('body *')—prendi solo ciò che ti serve. - Gestisci pagine grandi in streaming: Per HTML molto pesante, valuta lo streaming o suddividi il lavoro.
- Cache dell’HTML renderizzato: Se visiti più volte le stesse URL, salva l’HTML per evitare richieste inutili.
- Valida e pulisci i dati: Usa librerie di validazione per evitare di riempire il database di dati sporchi ().
Deploy scalabile di scraper Node.js nel cloud
Scraping su larga scala? È il momento di pensare cloud-native.
- Dockerizza lo scraper: Scrivi un
Dockerfile, copia il codice, installa le dipendenze e imposta l’entrypoint. - Deploy nel cloud: Usa AWS EC2, Google Cloud Compute o Azure VM per lavori semplici. Per la vera scalabilità, scegli Kubernetes o servizi gestiti come AWS ECS/EKS, Google Cloud Run o Azure Kubernetes Service ().
- Orchestrazione con Kubernetes: Avvia più pod, scala automaticamente e usa load balancer per distribuire le URL.
- Schedula i job: Usa scheduler cloud (CloudWatch Events, Cloud Scheduler) o cron job per avviare scraping a intervalli regolari.
In un caso reale, passare da 5 a 10 pod Kubernetes ha ridotto lo scraping di 400 pagine da diversi minuti a meno di un minuto ().
Monitoraggio e auto-scaling dell’infrastruttura di scraping
- Logging: Invia i log a CloudWatch, Stackdriver o Datadog. Imposta alert per errori o rallentamenti.
- Health check: Usa Prometheus e Grafana per metriche come pagine estratte al minuto, tasso di errore e stato dei pod.
- Auto-scaling: Configura l’HPA (Horizontal Pod Autoscaler) di Kubernetes per scalare i pod in base a CPU o numero di richieste.
Implementa sempre i retry con backoff esponenziale per recuperare da errori di rete o ban temporanei.
Best practice per archiviazione e post-processing dei dati
Dopo aver estratto i dati, è fondamentale archiviarli e pulirli:
- Job piccoli: Esporta in CSV, JSON o invia direttamente su Google Sheets, Airtable o Notion (Thunderbit lo fa nativamente).
- Job grandi: Usa SQL (MySQL/PostgreSQL) per dati strutturati, oppure NoSQL (MongoDB, DynamoDB) per schemi flessibili o in evoluzione ().
- Cloud storage: S3 o Google Cloud Storage per file grezzi e backup.
- Pulizia dati: Valida sempre i campi, normalizza i formati (date, numeri) e rimuovi i duplicati. Usa validator di schema per garantire la qualità ().
Conserva sia i dati grezzi che quelli puliti—potrebbero servirti per debug o rielaborazioni future.
Conclusioni: i punti chiave per uno scraping efficiente con Node.js
Ecco i takeaway fondamentali:
- Sfrutta la potenza asincrona di Node.js per scraping massivo e concorrente—soprattutto su siti ricchi di JS.
- Combina gli strumenti giusti: Usa axios/got per le richieste, Cheerio per HTML statico, Puppeteer per contenuti dinamici e mixali per velocità e flessibilità.
- Evita le trappole anti-bot: Ruota proxy e header, simula il comportamento umano e rispetta robots.txt.
- Semplifica con Thunderbit: Per utenti business o prototipi rapidi, ti permette di estrarre dati complessi con l’AI e integrarli via API nei tuoi flussi Node.js.
- Scala il deploy: Dockerizza, orchestra con Kubernetes e monitora tutto per la massima affidabilità.
- Archivia e pulisci i dati: Scegli lo storage più adatto e valida sempre prima di usare i dati.
Il web non diventa più semplice, ma con queste best practice i tuoi estrattori web Node.js saranno veloci, affidabili e sempre un passo avanti rispetto alle difese anti-bot. E se ti stanchi di debuggare selettori alle 2 di notte, ricorda: l’AI di Thunderbit non dorme mai.
Vuoi approfondire? Dai un’occhiata al per altre guide, oppure prova l’ per scoprire quanto può essere semplice lo scraping.
Domande frequenti
1. Perché Node.js è particolarmente adatto allo scraping web nel 2025?
Il modello asincrono ed event-driven di Node.js permette di gestire migliaia di richieste contemporaneamente, ideale per estrarre grandi volumi di dati o aggiornamenti in tempo reale. Il vasto ecosistema npm e il supporto nativo a JavaScript lo rendono perfetto per i siti moderni ricchi di JS ().
2. Come posso evitare di essere bloccato facendo scraping con Node.js?
Usa proxy rotanti, randomizza gli header delle richieste, limita la velocità con ritardi casuali e simula il comportamento umano (movimento mouse, scroll, digitazione) con strumenti come Puppeteer. Rispetta sempre robots.txt e i termini del sito ().
3. Quando usare Cheerio e quando Puppeteer in uno scraper Node.js?
Usa Cheerio per il parsing veloce di HTML statico (quando i dati sono già nel codice sorgente). Scegli Puppeteer per siti che caricano i contenuti dinamicamente con JavaScript. Per il massimo risultato, usa Puppeteer per renderizzare la pagina e poi Cheerio per estrarre i dati ().
4. In che modo Thunderbit semplifica lo scraping web con Node.js?
Thunderbit ti permette di estrarre dati strutturati da qualsiasi sito usando l’AI e prompt in linguaggio naturale—senza scrivere codice. Gestisce contenuti dinamici, sottopagine e paginazione, e offre un’API per l’integrazione con Node.js. I dati possono essere esportati direttamente su Excel, Google Sheets, Airtable o Notion ().
5. Qual è il modo migliore per scalare e monitorare scraper Node.js nel cloud?
Dockerizza l’estrattore web, distribuiscilo su Kubernetes o servizi cloud gestiti e usa l’auto-scaling per gestire i picchi di traffico. Monitora log e metriche con strumenti come CloudWatch o Prometheus e imposta alert per errori o rallentamenti ().
Pronto a portare il tuo scraping al livello successivo? Prova Thunderbit e che i tuoi estrattori web siano sempre veloci, invisibili e un passo avanti.
Scopri di più