
Ogni tutorial su fetch per Node.js ti insegna await fetch(url) e basta. Poi la tua app in produzione si ingoia in silenzio un errore 500, una richiesta resta bloccata per 90 secondi senza timeout e tu finisci a passare il venerdì sera a debuggare qualcosa che avrebbe dovuto essere ovvio.
Da un po’ di tempo sviluppo strumenti interni e pipeline dati in e te lo dico senza giri di parole: il divario tra «fetch funziona nel mio tutorial» e «fetch funziona in produzione» è proprio il punto in cui si nascondono la maggior parte dei problemi. Un developer su Reddit lo ha detto benissimo: «quando entri in produzione, capisci di aver bisogno di qualcosa di più resiliente del fetch nativo.»
Un altro ha ammesso: «Ho lavorato 3 anni come web developer e solo oggi ho capito che il blocco catch della fetch API NON serve per gli errori HTTP.» Questa guida copre le cinque cose che la maggior parte dei tutorial salta — la trappola degli errori, i timeout con AbortController, la logica di retry, il riuso delle connessioni e quando andare oltre fetch per l’estrazione strutturata dei dati. Se ti è mai capitato che una chiamata fetch fallisse in silenzio in produzione, questa guida fa per te.
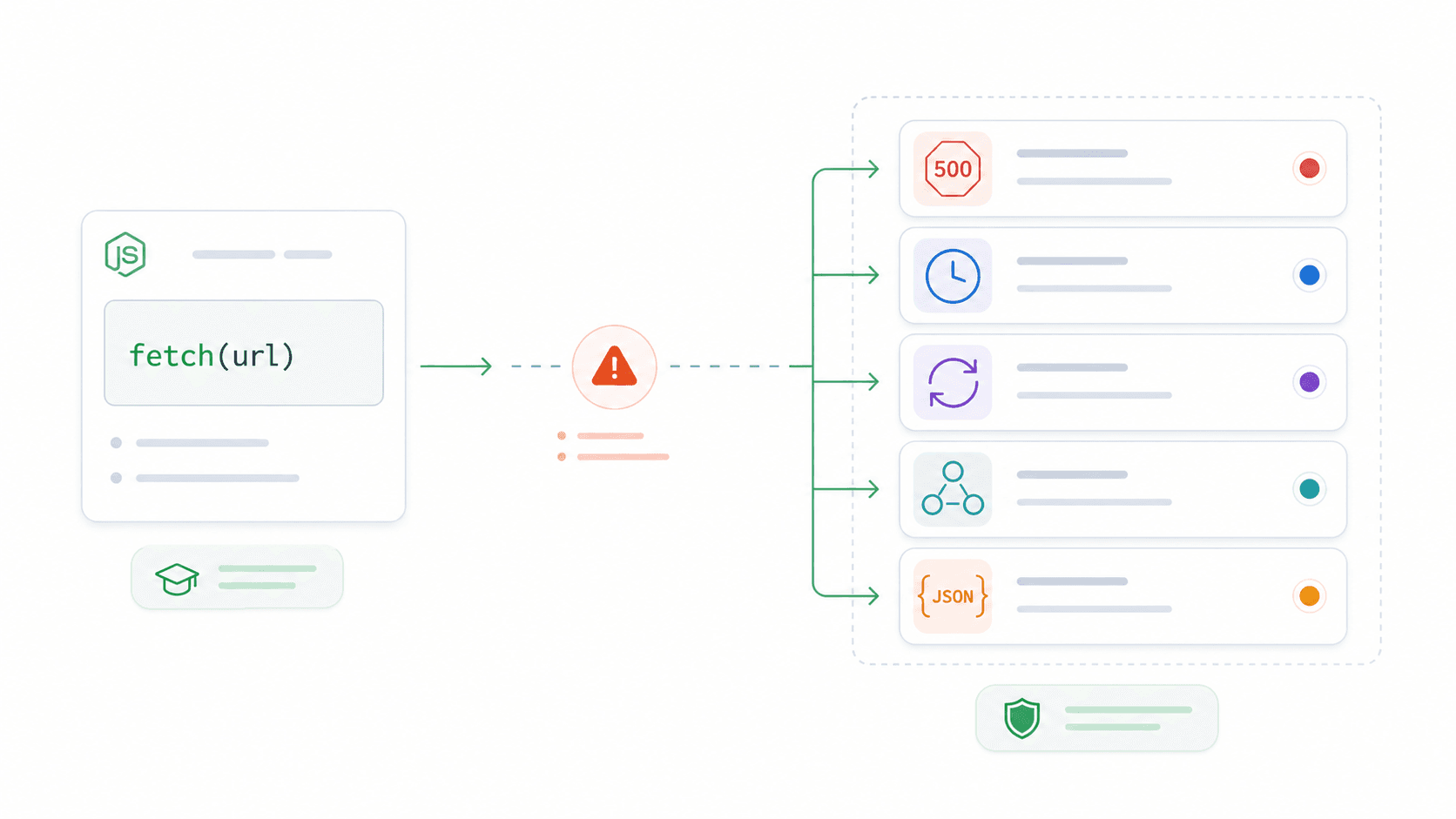
Che cos’è la Fetch API di Node.js?
La Fetch API di Node.js è il modo integrato e compatibile con il browser per fare richieste HTTP (GET, POST, PUT, DELETE, ecc.) da Node.js, senza installare Axios, node-fetch o altri pacchetti. Se hai già usato fetch() nel browser, conosci già la sintassi. Ora la stessa API funziona anche sul server.
Ecco una rapida cronologia delle versioni:
| Tappa | Versione Node | Cosa è successo |
|---|---|---|
| Flag fetch sperimentale | v17.5.0 / v16.15.0 | aggiunta di fetch dietro --experimental-fetch |
| Fetch globale predefinito | v18.0.0 | fetch sperimentale disponibile globalmente, basato su Undici |
| Fetch stabile | v21.0.0 | non più sperimentale |
| Baseline di produzione 2026 | v22 LTS / v24 LTS | consigliate per la produzione; v20 è ora EOL |
Sotto il cofano, fetch di Node è alimentato da Undici — un client HTTP ad alte prestazioni costruito appositamente per Node.js. Non si appoggia al vecchio modulo http incluso nel runtime. Il vantaggio pratico: ottieni una moderna API HTTP basata su Promise che si comporta allo stesso modo nel codice browser, nel backend Express, nelle funzioni serverless e negli script CLI.
Perché la Fetch API di Node.js conta per i tuoi progetti
Prima di Node 18, ogni nuovo progetto iniziava con lo stesso rituale: npm install axios oppure npm install node-fetch. Nel 2026, se il tuo progetto gira su una versione LTS mantenuta di Node, per le richieste HTTP di base non servono dipendenze. È un vantaggio vero per la dimensione del bundle, la sicurezza della supply chain e l’onboarding (frontend e backend finalmente condividono la stessa API).
Ecco dove il fetch nativo dà il meglio:
| Scenario | Perché il fetch nativo funziona bene | Nota di produzione |
|---|---|---|
| Backend Express/Fastify che chiama API REST | async/await familiare, nessuna dipendenza | aggiungi timeout e controlli su response.ok |
| Funzioni serverless (Lambda, Vercel, ecc.) | superficie di cold start ridotta, nessuna installazione di pacchetti | mantieni il timeout sotto la durata massima della piattaforma |
| Script CLI e automazioni | GET/POST semplici senza configurazione del progetto | aggiungi retry/backoff per API instabili |
| Consegna o inoltro di webhook | metodi HTTP e header standard | non ritentare alla cieca i POST non idempotenti |
| Report e dashboard | ottimo per prelevare JSON dalle API | usa paginazione e pooling delle connessioni nei loop |
| Comunicazione tra microservizi | va bene per semplici chiamate HTTP interne | valuta Got o Undici direttamente per retry, hook o HTTP/2 |
Per i nuovi progetti Node 22+, il fetch nativo è la scelta predefinita più sensata — a meno che tu non sappia di aver bisogno di funzionalità che non offre (interceptor, retry integrato, HTTP/2, ecc.). I numeri di download npm raccontano bene un mercato in transizione: , ma gran parte proviene da dipendenze legacy e transitive. , , e . La tendenza è chiara: il fetch nativo è la nuova base di partenza, mentre i client di terze parti servono per esigenze specifiche.
Fetch nativo vs node-fetch vs Axios vs Got vs Ky: la matrice decisionale 2026
La domanda che vedo più spesso nei forum degli sviluppatori è: «Quale client HTTP dovrei usare in Node.js?» Un utente Reddit l’ha riassunta così: «perché importare una libreria… quando il linguaggio/framework ha già la funzionalità integrata?» Osservazione corretta — ma la risposta dipende da ciò che ti serve.
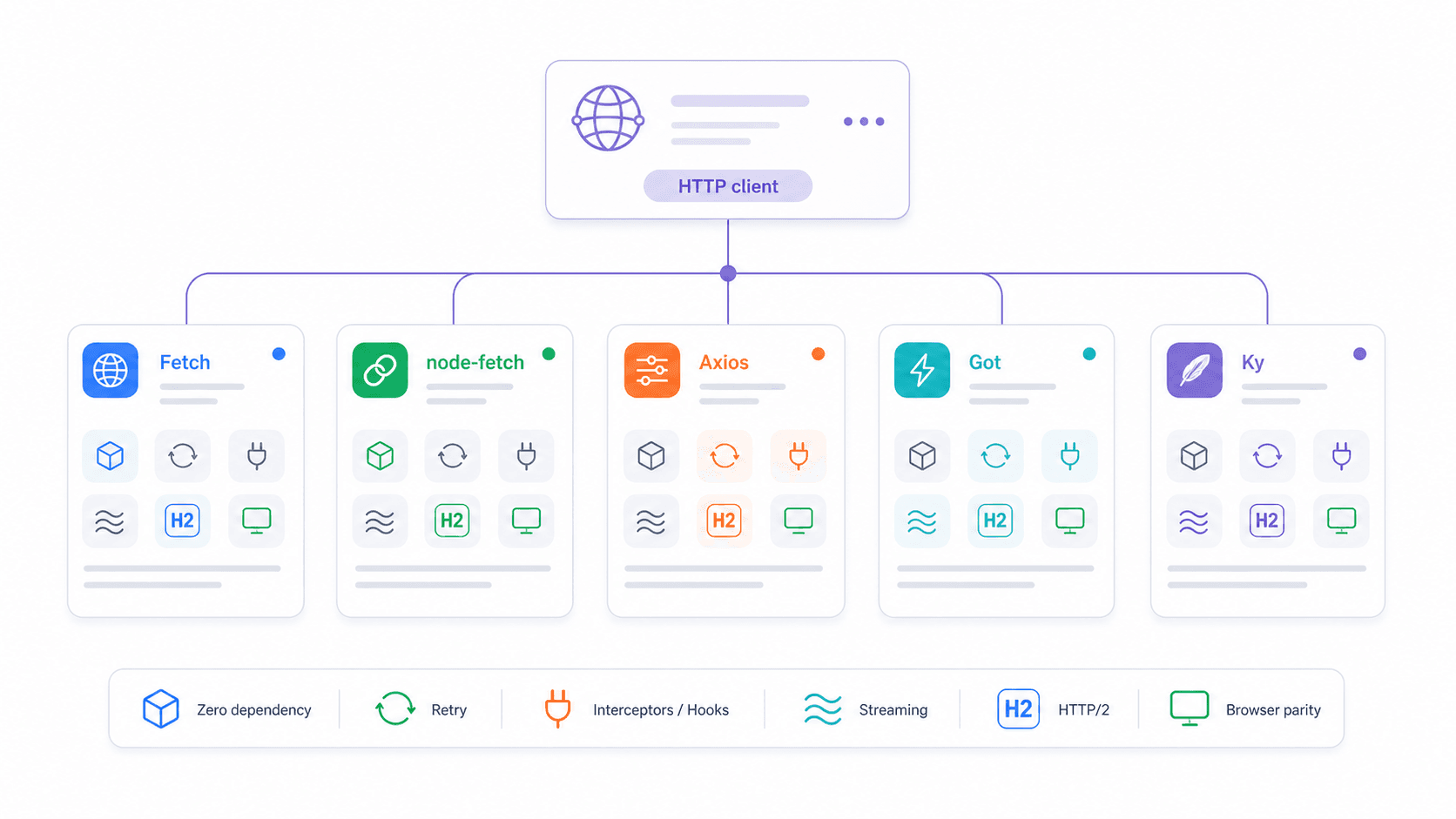
| Funzionalità | fetch nativo | node-fetch v3 | axios | got v15 | ky v2 |
|---|---|---|---|---|---|
| Versione Node.js | ≥18 (consigliate 22/24 LTS) | ≥12.20 | Ampia | ≥22 | ≥22 |
| Installazione richiesta | No | Sì | Sì | Sì | Sì |
| Supporto ESM + CJS | Entrambi (globale) | Solo ESM (v3) | Entrambi | Solo ESM | Solo ESM |
| Reiezione automatica su 4xx/5xx | No | No | Sì | Sì | Sì |
| Retry integrato | No | No | No | Sì | Sì |
| Interceptor delle richieste | No | No | Sì | Sì (hook) | Sì (hook) |
| Supporto streaming | Web ReadableStream | Sì | Limitato | Forti stream Node | Basato su fetch |
| Ingombro bundle/installazione | 0 KB | ~107 KB, 3 dipendenze | ~2,8 MB, 4 dipendenze | ~355 KB, 12 dipendenze | ~405 KB, 0 dipendenze |
| Supporto HTTP/2 | Tramite dispatcher Undici | No | No | Sì | No (wrapper fetch) |
Una nota veloce sul grattacapo ESM/CJS: node-fetch v3 è solo ESM, e questo ha rotto parecchi progetti che usavano require(). Il fetch nativo è globale: funziona sia nei file CJS sia in quelli ESM senza acrobazie con gli import. Se sei bloccato su node-fetch v2 per via di CommonJS, il fetch nativo risolve del tutto il problema.
E riguardo ai dubbi iniziali sulla stabilità: sì, all’inizio c’erano bug reali nell’implementazione di fetch in Node 18. Un developer su Reddit ha raccontato: «Di recente ho avuto un bug assurdo con il fetch nativo di Node 18, quindi ho dovuto convertire la nostra app.» Questo era nel 2023. Nel 2026, con Node 22 e 24 LTS, quei problemi sono stati risolti. Il fetch nativo è pronto per la produzione.
Quando restare sul fetch nativo
Scegli il fetch nativo quando:
- il tuo progetto gira su Node 22 LTS o Node 24 LTS;
- le richieste sono semplici chiamate REST (GET, POST, PUT, DELETE);
- sei disposto ad aggiungere un piccolo wrapper per
response.ok, parsing JSON, timeout e retry; - vuoi zero dipendenze e meno rischi legati alla supply chain;
- ti interessa la parità tra API browser e server;
- lavori in ambienti serverless o edge dove le API integrate sono preferibili.
Quando Axios, Got o Ky hanno più senso
Axios è la scelta giusta quando il tuo team si affida agli interceptor di richiesta/risposta (per esempio refresh automatico dei token di autenticazione, header per tenant, logging centralizzato), quando vuoi che gli errori HTTP vengano rigettati di default o quando ti serve compatibilità con runtime Node più vecchi.
Got è pensato per servizi Node ad alto throughput che hanno bisogno di retry integrati, hook, fasi di timeout avanzate, stream, helper per la paginazione, socket Unix, workflow con proxy/caching o supporto HTTP/2. È il coltellino svizzero per il lavoro HTTP solo lato Node.
Ky è il punto d’equilibrio se ti piace la semplicità di fetch ma vuoi meno boilerplate — aggiunge retry, timeout, hook e HTTPError in un pacchetto leggerissimo e senza dipendenze.
Come fare richieste GET con la Fetch API di Node.js
Una richiesta GET con async/await si presenta così:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts/1');
2const post = await response.json();
3console.log(post.title);
4// → "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"E, se preferisci, la versione con catena .then():
1fetch('https://jsonplaceholder.typicode.com/posts/1')
2 .then(response => response.json())
3 .then(post => console.log(post.title))
4 .catch(error => console.error(error));Entrambe funzionano. Ma nessuna delle due è ancora sicura per la produzione (ne parliamo tra un attimo).
Reader di response che dovresti conoscere:
| Metodo | Quando usarlo |
|---|---|
response.json() | Il server restituisce JSON |
response.text() | Il server restituisce HTML, testo semplice, CSV, Markdown |
response.arrayBuffer() | Ti servono dati binari (immagini, file) |
response.body | Ti serve elaborazione in streaming/chunk |
Un pattern migliore — uno che controlla davvero gli errori:
1async function getPost(id) {
2 const response = await fetch(`https://jsonplaceholder.typicode.com/posts/$\{id\}`);
3 if (!response.ok) {
4 throw new Error(`HTTP $\{response.status\} $\{response.statusText\}`);
5 }
6 return response.json();
7}
8const post = await getPost(1);
9console.log(post.title);Quella riga if (!response.ok) è la differenza tra un tutorial e codice di produzione. Ed è qui che entriamo nella trappola più grande.
Come inviare richieste POST con la Fetch API di Node.js
Le richieste POST seguono la stessa struttura — devi solo impostare method, header e body:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts', {
2 method: 'POST',
3 headers: {
4 'Content-Type': 'application/json',
5 },
6 body: JSON.stringify({
7 title: 'Guida a Node fetch',
8 body: 'Il fetch in produzione richiede gestione degli errori.',
9 userId: 1,
10 }),
11});
12if (!response.ok) {
13 throw new Error(`HTTP $\{response.status\}`);
14}
15const created = await response.json();
16console.log(created.id); // → 101Invio di altri tipi di richiesta (PUT, DELETE, PATCH)
PUT, PATCH e DELETE usano la stessa identica struttura, con un diverso valore di method:
1// PUT — sostituzione completa
2await fetch('https://jsonplaceholder.typicode.com/posts/1', {
3 method: 'PUT',
4 headers: { 'Content-Type': 'application/json' },
5 body: JSON.stringify({ id: 1, title: 'Sostituito', body: 'Sostituzione completa', userId: 1 }),
6});
7// PATCH — aggiornamento parziale
8await fetch('https://jsonplaceholder.typicode.com/posts/1', {
9 method: 'PATCH',
10 headers: { 'Content-Type': 'application/json' },
11 body: JSON.stringify({ title: 'Aggiornamento parziale' }),
12});
13// DELETE
14await fetch('https://jsonplaceholder.typicode.com/posts/1', {
15 method: 'DELETE',
16});La trappola di body-parser in Express: se stai inviando JSON a un server Express e req.body torna undefined, la soluzione è quasi sempre questa: usa express.json(), non express.urlencoded(). Il server ha bisogno del middleware express.json() prima della route per interpretare i body Content-Type: application/json. È una delle riguardo a Express, e mette in difficoltà ogni volta.
1import express from 'express';
2const app = express();
3app.use(express.json()); // ← Questo è quello che ti serve per i body JSON nei POST
4app.post('/api/posts', (req, res) => {
5 res.json({ received: req.body });
6});La trappola di fetch() sugli errori che manda in crisi le app in produzione
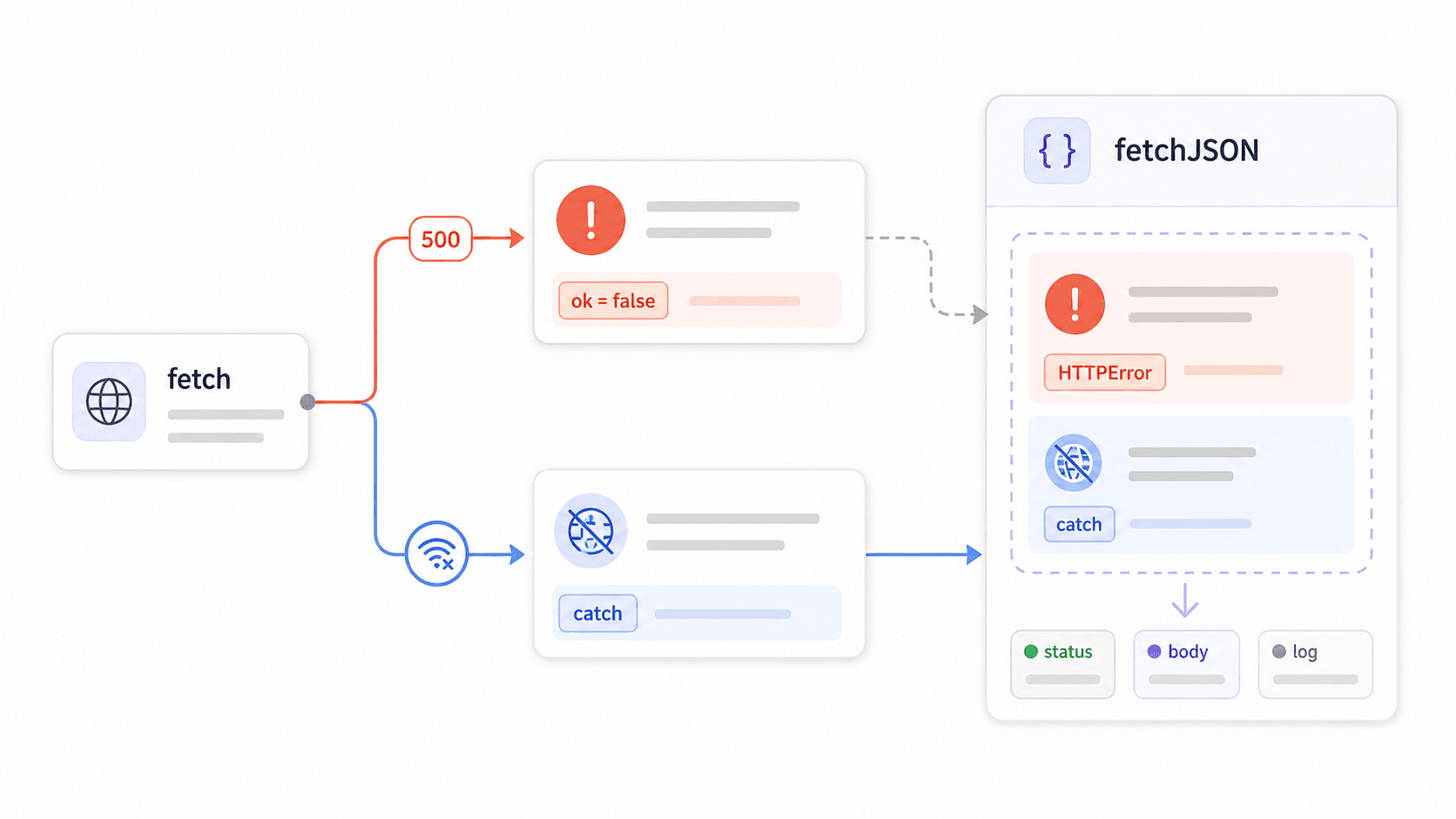
È qui che nascono la maggior parte dei bug di fetch in produzione.
fetch() non rigetta la Promise in caso di errori HTTP 4xx o 5xx. Rigetta solo per fallimenti a livello di rete — errori DNS, assenza di connessione, richieste annullate. Se il server restituisce un 403 Forbidden o un 500 Internal Server Error, fetch considera comunque la risposta come successo. Il tuo blocco .catch() non parte mai. Il tuo try/catch non intercetta nulla. Il tuo codice elabora felice quello che il server ha restituito.
lo spiega chiaramente, ma la maggior parte dei tutorial sorvola su questo punto. Il risultato? Codice che sembra corretto ma ingoia gli errori senza farsi notare:
1try {
2 const response = await fetch('https://api.example.com/private');
3 const data = await response.json(); // ← Viene eseguito anche con un 403
4 console.log('Sembra andato a buon fine:', data);
5} catch (error) {
6 // Qui finiscono solo i fallimenti a livello di rete
7 console.error('Catturato:', error);
8}Ecco una rapida panoramica di cosa intercetta davvero ogni pattern:
| Pattern | Intercetta errori di rete | Intercetta 4xx/5xx | Parsa JSON in modo sicuro | Riutilizzabile |
|---|---|---|---|---|
Raw .then(res => res.json()) | Sì (tramite .catch()) | No | Nessuna protezione sul content-type | No |
try/catch con await fetch() | Sì | No | Nessuna protezione sul content-type | No |
Controllo manuale if (!res.ok) per ogni chiamata | Sì | Sì | Dipende da ogni chiamata | Parziale |
Wrapper personalizzato fetchJSON() | Sì | Sì | Sì | Sì |
Crea un wrapper riutilizzabile fetchJSON()
Costruisci un solo wrapper. Importalo ovunque. Smetti di copiare e incollare if (!response.ok) in ogni file:
1export class HTTPError extends Error {
2 constructor(message, { status, statusText, url, body }) {
3 super(message);
4 this.name = 'HTTPError';
5 this.status = status;
6 this.statusText = statusText;
7 this.url = url;
8 this.body = body;
9 }
10}
11export async function fetchJSON(url, options = {}) {
12 const response = await fetch(url, {
13 headers: {
14 Accept: 'application/json',
15 ...options.headers,
16 },
17 ...options,
18 });
19 const contentType = response.headers.get('content-type') || '';
20 const isJSON = contentType.includes('application/json');
21 const body = isJSON ? await response.json().catch(() => null) : await response.text();
22 if (!response.ok) {
23 throw new HTTPError(`HTTP $\{response.status\} $\{response.statusText\}`, {
24 status: response.status,
25 statusText: response.statusText,
26 url: response.url,
27 body,
28 });
29 }
30 return body;
31}Ora, quando il server restituisce un 403:
1try {
2 const data = await fetchJSON('https://api.example.com/private');
3} catch (error) {
4 if (error instanceof HTTPError) {
5 console.error(`Il server ha restituito $\{error.status\}:`, error.body);
6 } else {
7 console.error('Errore di rete o altro fallimento:', error);
8 }
9}L’errore porta con sé il codice di stato, il body della risposta e l’URL — tutto quello che serve per logging, alert o messaggi rivolti all’utente. Importalo una volta, usalo ovunque.
AbortController e timeout: il pattern di produzione per la Fetch API di Node.js
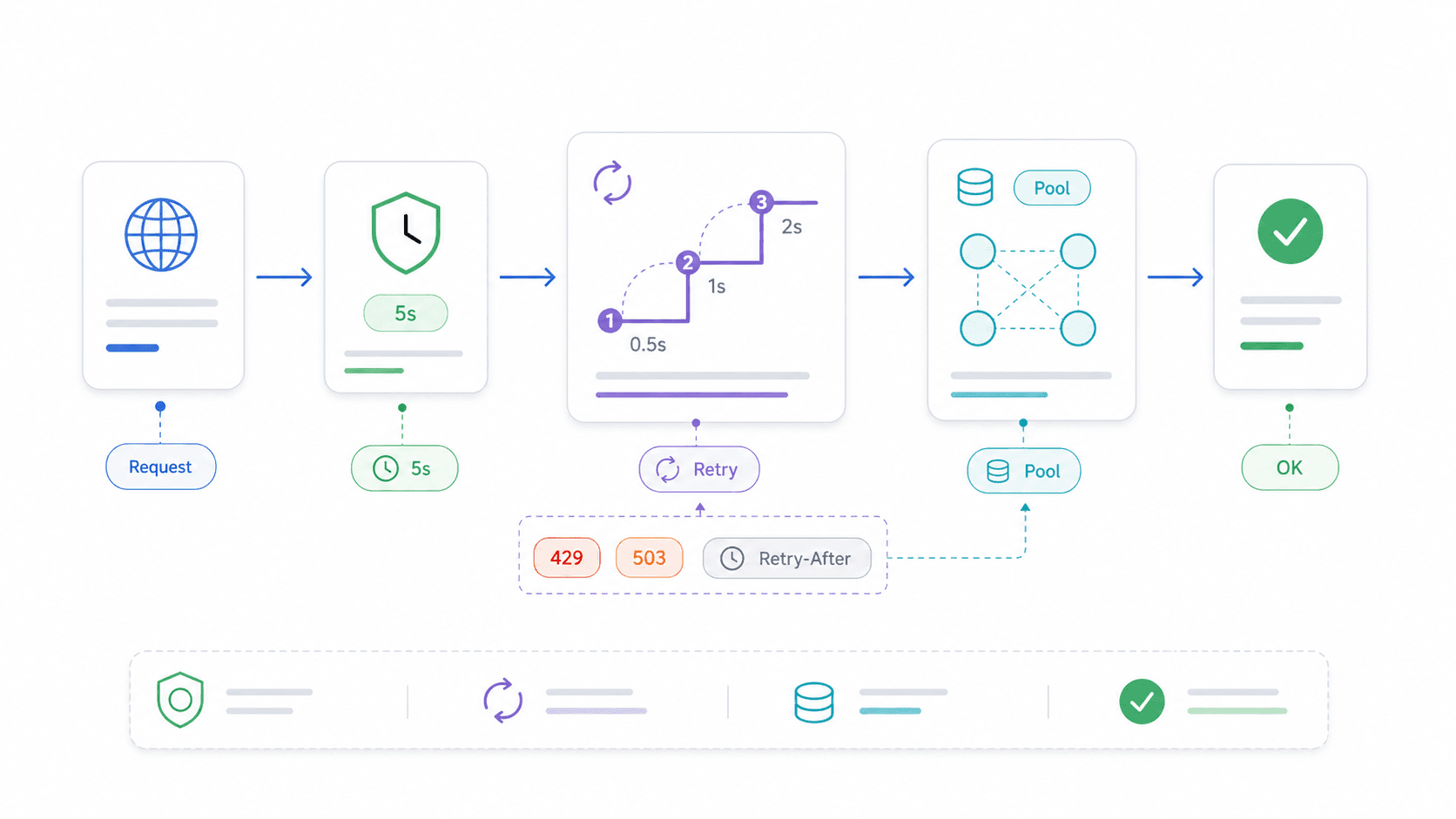
Senza un timeout, una chiamata fetch resta appesa all’infinito quando il server remoto smette di rispondere. La tua route Express si blocca. La tua Lambda consuma tutto il budget di esecuzione. Il tuo script semplicemente... resta lì.
Ho controllato i primi risultati di ricerca: non c’è un solo tutorial su fetch specifico per Node.js che tratti davvero cancellazione delle richieste o timeout. Eppure i timeout sono una delle principali ragioni per cui gli sviluppatori restano su Axios o Got. Un thread Reddit ha persino come titolo «Node fetch does not timeout».
Usare AbortSignal.timeout() (Node 18.11+)
L’approccio più semplice — una sola opzione in più:
1try {
2 const response = await fetch('https://api.example.com/data', {
3 signal: AbortSignal.timeout(5000), // 5 secondi
4 });
5 if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
6 const data = await response.json();
7 console.log(data);
8} catch (error) {
9 if (error.name === 'TimeoutError') {
10 console.error('La richiesta è andata in timeout dopo 5 secondi.');
11 } else {
12 throw error;
13 }
14}Nota: AbortSignal.timeout() genera un TimeoutError, non un AbortError. È un dettaglio che anche alcuni sviluppatori esperti sbagliano.
Timeout manuale con AbortController
Per avere più controllo — o se devi annullare una richiesta in base all’azione dell’utente, non solo a un timer:
1const controller = new AbortController();
2const timeout = setTimeout(() => controller.abort(), 5000);
3try {
4 const response = await fetch('https://api.example.com/data', {
5 signal: controller.signal,
6 });
7 const data = await response.json();
8 console.log(data);
9} catch (error) {
10 if (error.name === 'AbortError') {
11 console.error('La richiesta è stata annullata manualmente.');
12 } else {
13 throw error;
14 }
15} finally {
16 clearTimeout(timeout);
17}Gestire AbortError vs TimeoutError
Questa distinzione conta per il logging e per i messaggi rivolti all’utente:
| Percorso di abort | Nome dell’errore nel blocco catch |
|---|---|
AbortSignal.timeout(ms) | TimeoutError |
controller.abort() | AbortError |
| Fallimento DNS/rete | Di solito TypeError: fetch failed |
Ecco uno scenario pratico — una route Express che chiama un’API esterna e deve rispondere entro 3 secondi:
1app.get('/dashboard', async (req, res, next) => {
2 try {
3 const data = await fetchJSON('https://api.example.com/report', {
4 signal: AbortSignal.timeout(3000),
5 });
6 res.json(data);
7 } catch (error) {
8 if (error.name === 'TimeoutError') {
9 res.status(504).json({ error: 'Timeout dell’API upstream' });
10 return;
11 }
12 next(error);
13 }
14});Senza questo pattern, un’API upstream lenta bloccherebbe l’intera route finché il client non si arrende.
Logica di retry e riuso delle connessioni: rendere la Fetch API di Node.js pronta per la produzione
Il fetch nativo non ha retry integrati. Un piccolo problema di rete o un 503 temporaneo fanno semplicemente fallire la richiesta. Per la maggior parte delle operazioni di lettura in produzione, non è accettabile.
Un wrapper di retry componibile con backoff esponenziale
È volutamente corto — circa 10 righe di logica reale:
1const wait = ms => new Promise(resolve => setTimeout(resolve, ms));
2export async function fetchWithRetry(url, options = {}, retries = 2) {
3 for (let attempt = 0; ; attempt++) {
4 try {
5 const response = await fetch(url, options);
6 if (response.ok || ![408, 429, 500, 502, 503, 504].includes(response.status)) {
7 return response;
8 }
9 if (attempt >= retries) return response;
10 } catch (error) {
11 if (attempt >= retries) throw error;
12 }
13 await wait(250 * 2 ** attempt); // 250 ms, 500 ms, 1000 ms...
14 }
15}Quando ritentare e quando no
- Ritenta: richieste GET e HEAD idempotenti, stati temporanei (408, 429, 500, 502, 503, 504), problemi di rete momentanei.
- Non ritentare: richieste POST non idempotenti che creano record, addebitano denaro o attivano effetti collaterali — a meno che non usi idempotency key.
- Rispetta Retry-After: per 429 (rate limit) e 503 (servizio non disponibile), controlla l’header
Retry-Afterprima di procedere col backoff.
Se preferisci non costruire da solo la logica di retry, è un wrapper fetch leggero che aggiunge retry, timeout, hook e HTTPError già pronti — senza dipendenze.
Riuso delle connessioni con Agent e Pool di Undici
Per loop ad alto throughput — scraping di centinaia di pagine, chiamate API in batch, polling di un servizio — riutilizzare le connessioni TCP fa risparmiare parecchio tempo. Ogni nuova connessione implica una nuova risoluzione DNS, un handshake TCP e, per HTTPS, una negoziazione TLS.
Dato che il fetch di Node è alimentato da Undici, puoi passare un dispatcher personalizzato:
1import { Agent } from 'undici';
2const agent = new Agent({
3 keepAliveTimeout: 10_000,
4 keepAliveMaxTimeout: 60_000,
5});
6const response = await fetch('https://api.example.com/data', {
7 dispatcher: agent,
8});Per un controllo ancora maggiore con un origin specifico:
1import { Pool } from 'undici';
2const pool = new Pool('https://api.example.com', { connections: 10 });
3const response = await fetch('https://api.example.com/data', {
4 dispatcher: pool,
5});
6// Quando hai finito:
7await pool.close();I mostrano che il riuso delle connessioni e il pooling possono migliorare drasticamente il throughput — undici - dispatch ha registrato circa 22.234 req/sec contro circa 5.904 req/sec di undici - fetch nel benchmark locale. I numeri reali variano, ma la direzione è chiara: se fai molte richieste verso lo stesso origin, il pooling conta.
Un’altra cosa: consuma o annulla sempre i body delle response. I body non consumati possono causare leak di risorse nelle internals HTTP di Node.
Response in streaming con la Fetch API di Node.js
Download di file grandi, feed JSON chunked, server-sent events, output di LLM — sono tutti casi in cui aspettare la risposta completa prima di elaborare significa sprecare tempo e memoria. Lo streaming ti consente di trattare i dati man mano che arrivano.
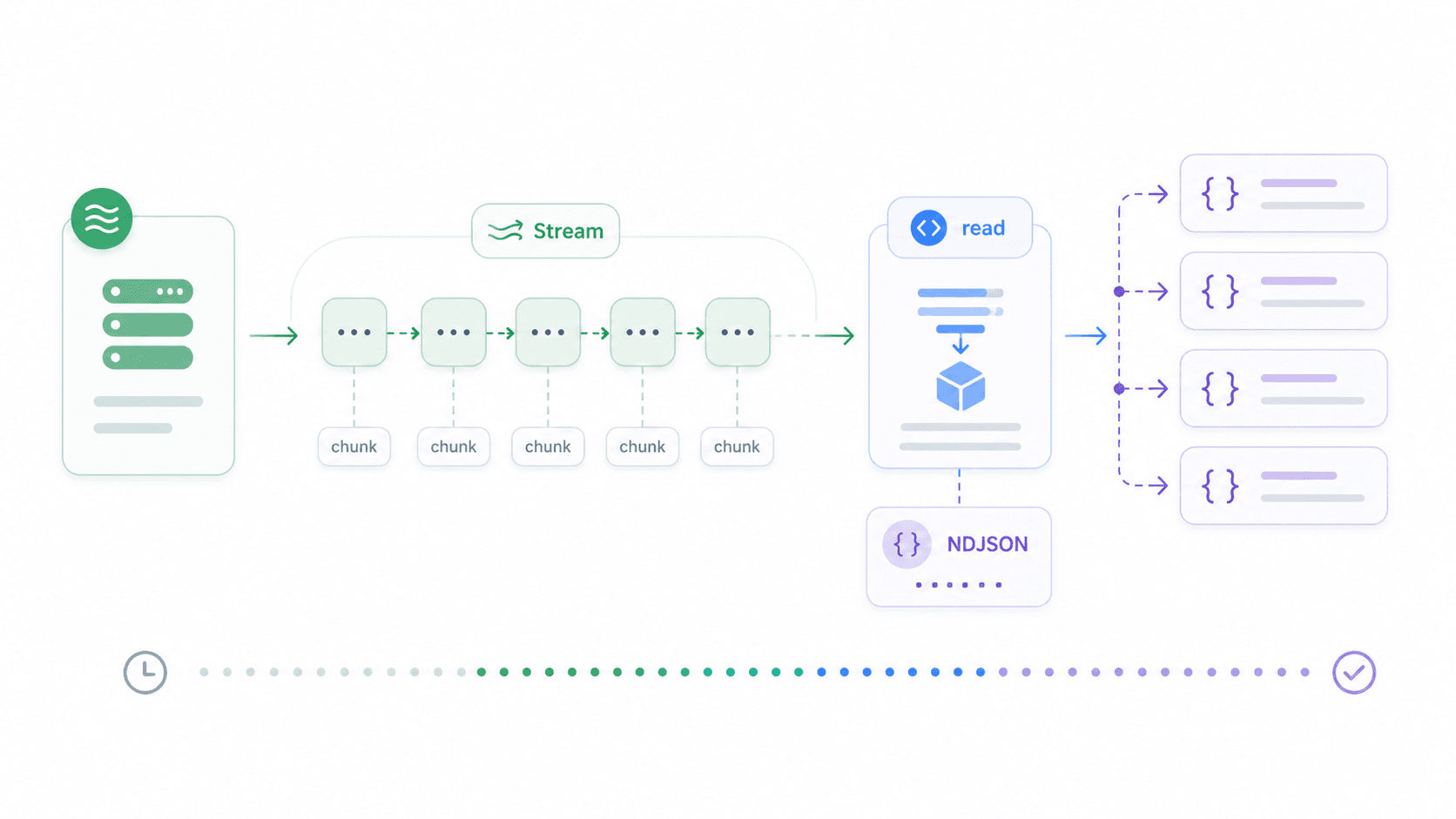
Node 18+ include ReadableStream compatibile con il browser. Ecco come fare streaming di una risposta JSON delimitata da newline ed elaborare ogni riga all’arrivo:
1const response = await fetch('https://example.com/large-file.ndjson');
2if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
3const reader = response.body.getReader();
4const decoder = new TextDecoder();
5let buffer = '';
6while (true) {
7 const { value, done } = await reader.read();
8 if (done) break;
9 buffer += decoder.decode(value, { stream: true });
10 let newlineIndex;
11 while ((newlineIndex = buffer.indexOf('\n')) >= 0) {
12 const line = buffer.slice(0, newlineIndex).trim();
13 buffer = buffer.slice(newlineIndex + 1);
14 if (line) {
15 const item = JSON.parse(line);
16 console.log('Elaborato:', item.id);
17 }
18 }
19}Per uno streaming di testo più semplice (ad esempio, inviare l’output di un LLM su stdout):
1const response = await fetch('https://example.com/stream');
2const reader = response.body.getReader();
3const decoder = new TextDecoder();
4for (;;) {
5 const { value, done } = await reader.read();
6 if (done) break;
7 process.stdout.write(decoder.decode(value, { stream: true }));
8}Lo streaming è un’area in cui sia il fetch nativo sia Got eccellono. Il supporto streaming di Axios è più limitato.
Quando fetch() arriva ai suoi limiti: scraping web strutturato con le API
A un certo punto, fetch non è più il collo di bottiglia. Il problema reale diventa: «Ho HTML, e adesso?»
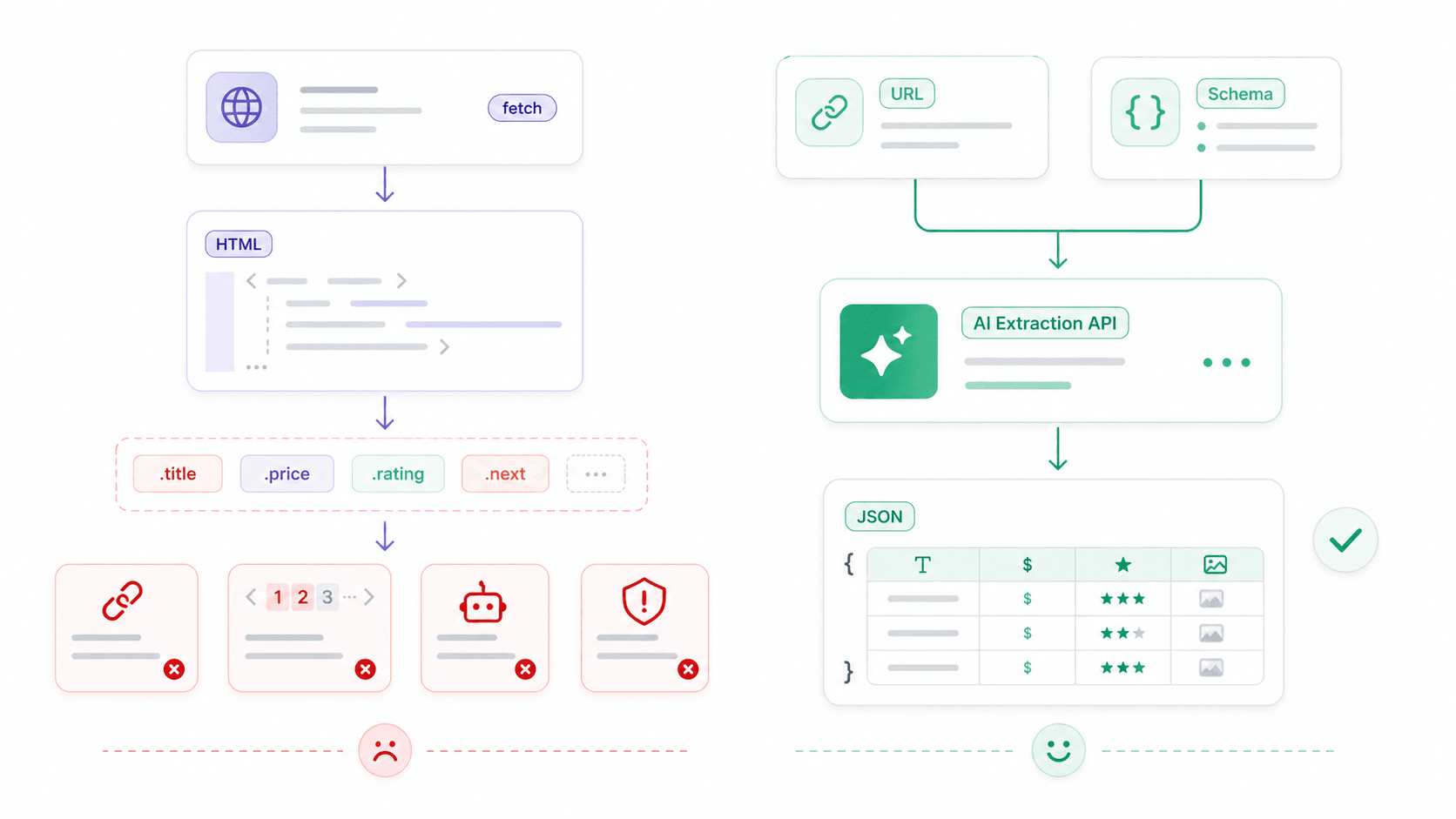
Fetch è un client HTTP — recupera byte, testo, JSON o HTML. Non ha alcun concetto di scheda prodotto, prezzo, valutazione o tabella contatti. Per lo scraping web strutturato, lo stack grezzo tipico è questo:
fetch()per scaricare l’HTML- Cheerio (o simili) per selezionare gli elementi con i selettori CSS
- Logica personalizzata di paginazione
- Rendering JavaScript quando le pagine sono client-side
- Gestione di proxy, anti-bot e CAPTCHA
- Manutenzione dei selettori ogni volta che cambia il layout del sito
Ecco un tipico esempio fetch + Cheerio — circa 15 righe per estrarre i titoli dei prodotti:
1import * as cheerio from 'cheerio';
2const response = await fetch('https://example-store.com/products');
3if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
4const html = await response.text();
5const $ = cheerio.load(html);
6const products = $('.product-card')
7 .map((_, el) => ({
8 name: $(el).find('.product-title').text().trim(),
9 price: $(el).find('.price').text().trim(),
10 url: new URL($(el).find('a').attr('href'), response.url).href,
11 }))
12 .get();
13console.log(products);Funziona per pagine stabili con HTML prevedibile. Diventa fragile rapidamente — contenuti renderizzati in JavaScript, classi che cambiano, misure anti-bot e paginazione aggiungono tutti complessità.
L’Open API di Thunderbit: da HTML grezzo a dati strutturati in una sola chiamata
È qui che entra in gioco un tipo diverso di strumento. In , abbiamo creato un livello API che gestisce le parti più ostiche — rendering JavaScript, protezione anti-bot, cambi di layout — così puoi concentrarti sui dati che ti servono davvero.
Distill API (POST /distill): converte qualsiasi URL in Markdown pulito. Utile per alimentare LLM, costruire knowledge base o fare analisi dei contenuti — senza bisogno di un parser HTML.
Extract API (POST /extract): definisci uno schema JSON che descrive i dati strutturati che vuoi ottenere (nome prodotto, prezzo, valutazione) e l’IA li estrae. Niente selettori CSS, niente rotture quando cambia il layout.
Ecco la stessa attività di scraping dei prodotti usando l’Extract API di Thunderbit — chiamata con il fetch nativo:
1const response = await fetch('https://openapi.thunderbit.com/openapi/v1/extract', {
2 method: 'POST',
3 headers: {
4 Authorization: `Bearer $\{process.env.THUNDERBIT_API_KEY\}`,
5 'Content-Type': 'application/json',
6 },
7 body: JSON.stringify({
8 url: 'https://example-store.com/products',
9 renderMode: 'basic',
10 schema: {
11 type: 'object',
12 properties: {
13 products: {
14 type: 'array',
15 items: {
16 type: 'object',
17 properties: {
18 name: { type: 'string', description: 'Nome del prodotto' },
19 price: { type: 'string', description: 'Prezzo visualizzato del prodotto' },
20 rating: { type: 'number', description: 'Valutazione media dei clienti' },
21 },
22 required: ['name', 'price'],
23 },
24 },
25 },
26 required: ['products'],
27 },
28 }),
29});
30if (!response.ok) throw new Error(`Thunderbit API: $\{response.status\}`);
31const result = await response.json();
32console.log(result.data);Il confronto: circa 15 righe di fetch + Cheerio (più selettori fragili) contro una singola chiamata API che restituisce JSON pulito. Per i job batch, Thunderbit supporta fino a 50 URL per chiamata batch extract e fino a 100 URL per chiamata batch distill.
Thunderbit non sostituisce fetch — fetch è il trasporto. Thunderbit è il livello di estrazione a cui ricorri quando il parsing dell’HTML grezzo diventa il vero problema. Se ti incuriosiscono i prezzi, il ti offre 600 unità API per sperimentare e i piani a pagamento partono da 6 $/mese. Puoi anche dare un’occhiata all’ per un’estrazione no-code direttamente dal browser.
Per approfondire gli approcci allo scraping strutturato, le nostre guide su , e spiegano in dettaglio workflow specifici.
Riferimento rapido: cheat sheet della Fetch API di Node.js
Questa sezione vale la pena salvarla nei preferiti. Torna qui quando ti serve un pattern da copiare e incollare.
| Pattern | Snippet |
|---|---|
| GET base | const res = await fetch(url); const data = await res.json(); |
| POST base | await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload) }); |
| Controllo errore HTTP | if (!res.ok) throw new Error(\HTTP ${res.status}`);` |
| Timeout (semplice) | await fetch(url, { signal: AbortSignal.timeout(5000) }); |
| Abort manuale | const c = new AbortController(); setTimeout(() => c.abort(), 5000); await fetch(url, { signal: c.signal }); |
| Stati da ritentare | Ritenta 408, 429, 500, 502, 503, 504. Non ritentare i POST alla cieca. |
| Wrapper JSON | Usa fetchJSON() per controllare ok, parsare il content type e lanciare HTTPError. |
| Pool di connessioni | import { Pool } from 'undici'; const pool = new Pool(origin, { connections: 10 }); fetch(url, { dispatcher: pool }); |
| Chunk di stream | const reader = res.body.getReader(); loop over await reader.read() |
| Estrazione strutturata | Usa l’Extract API di Thunderbit quando l’obiettivo sono i campi di una pagina web, non l’HTML grezzo. |
Conclusione e punti chiave
Il fetch nativo in Node.js è pronto per la produzione nel 2026 — per i nuovi progetti non serve node-fetch e non serve nemmeno una dipendenza Axios di default. Ma il fetch() grezzo da solo non è una strategia HTTP completa per la produzione.
Le cinque cose che la maggior parte dei tutorial salta — e che questa guida ha coperto:
- La trappola degli errori:
fetch()non lancia eccezioni su 4xx/5xx. Controlla sempreresponse.okoppure usa un wrapper comefetchJSON(). - Timeout: usa
AbortSignal.timeout()nei casi semplici.AbortSignal.timeout()generaTimeoutError;controller.abort()manuale generaAbortError. - Logica di retry: non è integrata. Aggiungi backoff esponenziale per richieste idempotenti e fallimenti temporanei. Oppure usa Ky per ottenere il retry in stile fetch già pronto.
- Riuso delle connessioni: per i loop ad alto throughput, usa
AgentoPooldi Undici tramite l’opzionedispatcher. - Estrazione strutturata: quando ti servono dati dalle pagine web, non solo HTML grezzo, valuta un’API di estrazione come Thunderbit invece di mantenere selettori CSS fragili.
La matrice decisionale in una frase: usa il fetch nativo per la maggior parte dei progetti, Axios per gli interceptor, Got per retry integrato e HTTP/2, Ky per fetch con impostazioni migliori, e l’API di Thunderbit quando gli script di scraping basati su fetch diventano troppo complessi da mantenere.
Prova i pattern di questa guida. E se vuoi vedere come Thunderbit gestisce l’estrazione strutturata, il è un ottimo punto di partenza — oppure guarda una guida pratica sul .
FAQ
1. fetch è integrato in Node.js o devo installarlo?
Fetch è integrato in Node.js 18 e versioni successive — non serve installarlo. È diventato stabile in Node 21 ed è completamente supportato in Node 22 LTS e Node 24 LTS. Per versioni più vecchie di Node, puoi usare il pacchetto npm node-fetch, ma i nuovi progetti dovrebbero puntare a una release LTS mantenuta.
2. fetch lancia un errore su risposte 404 o 500?
No. Fetch rigetta la Promise solo per fallimenti a livello di rete (errori DNS, assenza di connettività, richieste annullate). Le risposte HTTP come 404, 403 e 500 si risolvono normalmente con response.ok === false. Devi controllare esplicitamente response.ok o response.status — oppure usare un wrapper come la funzione fetchJSON() mostrata in questa guida.
3. Come aggiungo un timeout a fetch in Node.js?
L’approccio più semplice è AbortSignal.timeout(ms), disponibile da Node 18.11+: await fetch(url, { signal: AbortSignal.timeout(5000) }). Questo genera un TimeoutError se la richiesta supera i 5 secondi. Per un controllo maggiore, crea manualmente un AbortController e chiama controller.abort() da un setTimeout. Cattura AbortError per il pattern manuale e TimeoutError per AbortSignal.timeout().
4. Posso usare fetch per fare web scraping in Node.js?
Sì, ma fetch restituisce solo HTML grezzo. Ti serve un parser come Cheerio per estrarre elementi specifici, oltre a logica personalizzata per paginazione, pagine renderizzate in JavaScript e misure anti-bot. Per l’estrazione di dati strutturati su larga scala — quando vuoi JSON pulito con nomi prodotto, prezzi o informazioni di contatto — valuta , che usa l’IA per restituire dati strutturati senza selettori CSS o codice dipendente dal layout.
5. Nel 2026 dovrei passare da Axios al fetch nativo?
Per i nuovi progetti su Node 22+, il fetch nativo è una scelta di partenza molto solida. È senza dipendenze, basato su Promise e condivide la stessa API del fetch del browser. Tieni Axios se fai affidamento sugli interceptor di richiesta/risposta, sulla reiezione predefinita degli errori HTTP o se ti serve compatibilità con versioni più vecchie di Node. Entrambe sono scelte valide — la decisione dipende dalle funzionalità che il tuo progetto usa davvero.
Scopri di più