Il web è davvero una miniera d’oro di dati e ormai ogni azienda vuole accaparrarsi la fetta più grande possibile. Ma diciamocelo: copiare a mano informazioni da centinaia di pagine web è una fatica che non augurerei a nessuno. Qui entra in gioco il node web scraping. Negli ultimi anni ho visto sempre più team—dal commerciale all’operations, dal marketing alla ricerca di mercato—affidarsi all’automazione per raccogliere insight preziosi dal web su larga scala. Non a caso, il mercato globale dell’estrazione dati dal web è destinato a superare i , e non sono solo i giganti tech a beneficiarne. Dal monitoraggio dei prezzi online alla generazione di lead, il node web scraping è ormai una skill fondamentale per chi vuole restare competitivo.
Se ti sei mai chiesto come si fa a estrarre dati dai siti web usando Node.js—o perché Node.js sia così efficace per siti dinamici e pieni di JavaScript—questa guida è fatta apposta per te. Ti spiegherò cos’è il node web scraping, perché è diventato così importante per le aziende e come puoi costruire da zero il tuo primo flusso di scraping. E se vuoi andare subito al sodo, ti mostrerò anche come strumenti come possano farti risparmiare ore di lavoro automatizzando tutto il processo. Pronto a trasformare il web nella tua fonte personale di dati? Partiamo!
Cos’è il Node Web Scraping? Il tuo passaporto per l’estrazione automatica dei dati
In parole semplici, il node web scraping significa usare Node.js (il famoso runtime JavaScript) per estrarre in automatico informazioni dai siti web. Immagina di avere un robot super veloce che visita le pagine, legge i contenuti e recupera solo i dati che ti servono—che siano prezzi, contatti o le ultime news.
Ecco come funziona in pratica:
- Il tuo script Node.js manda una richiesta HTTP a un sito (proprio come fa il browser).
- Riceve l’HTML grezzo della pagina.
- Con librerie come Cheerio, analizza l’HTML e ti permette di “interrogare” la pagina per trovare i dati che cerchi (in stile jQuery).
- Per i siti dove i contenuti vengono caricati tramite JavaScript (come le web app moderne), puoi usare Puppeteer per controllare un vero browser in background, renderizzare la pagina e recuperare i dati dopo che tutti gli script sono stati eseguiti.
Perché proprio Node.js? JavaScript è la lingua madre del web e Node.js ti permette di usarlo anche fuori dal browser. Così puoi gestire sia siti statici che dinamici, automatizzare interazioni complesse (come login o click su pulsanti) e processare dati a velocità altissime. Inoltre, l’architettura event-driven e non bloccante di Node ti consente di estrarre dati da tante pagine in parallelo—perfetto per scalare l’estrazione dei dati.
Gli strumenti principali per il node web scraping:
- Axios: Recupera le pagine web (gestisce le richieste HTTP).
- Cheerio: Analizza e interroga l’HTML dei siti statici.
- Puppeteer: Automatizza un browser reale per siti dinamici o interattivi.
Se ti immagini un esercito di browser-robot che raccolgono dati mentre ti prendi un caffè… sei sulla strada giusta.
Perché il Node Web Scraping è strategico per le aziende
Parliamoci chiaro: il web scraping non è più roba da smanettoni o data scientist. È una vera arma segreta. Aziende di ogni settore usano il node web scraping per:
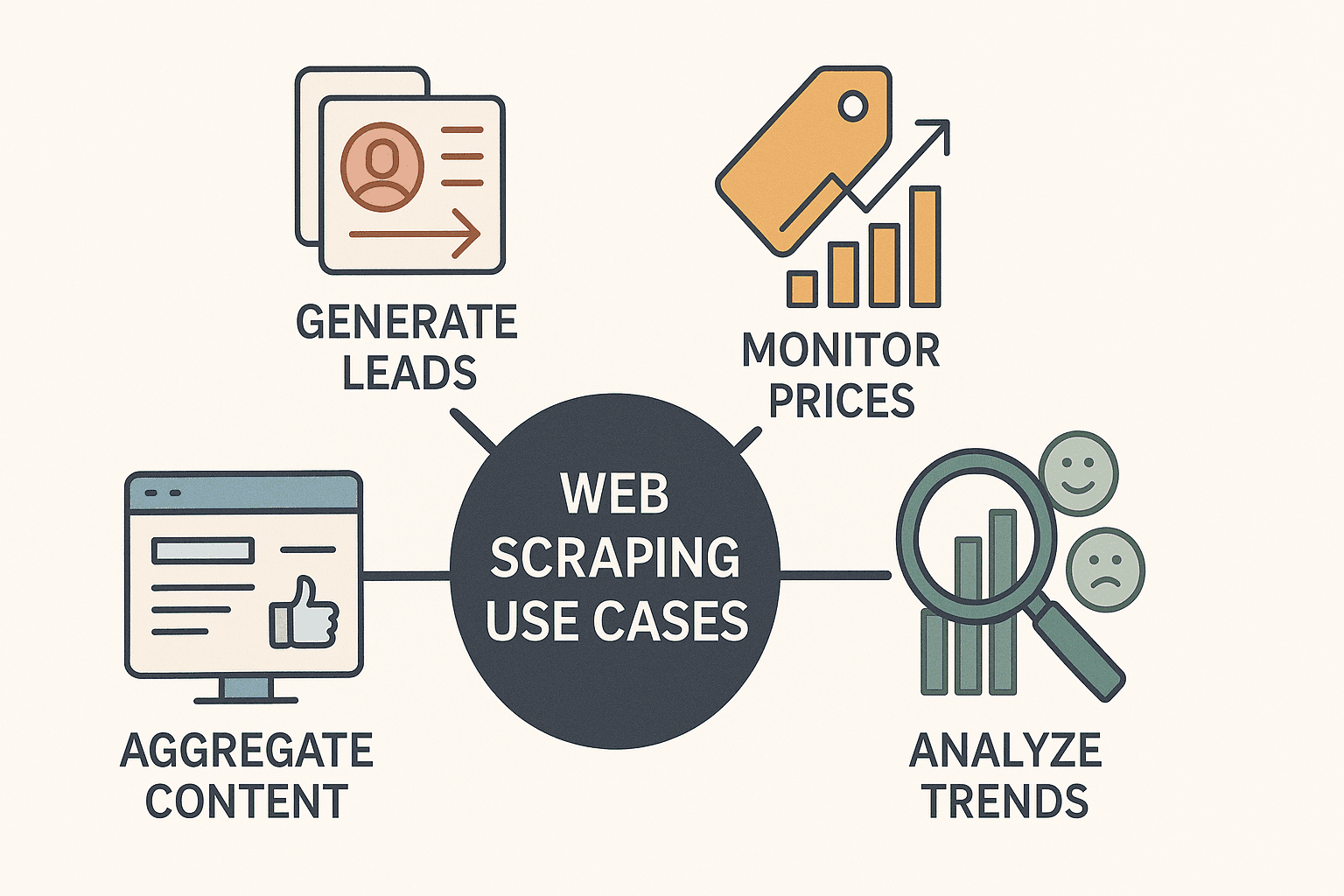
- Generare lead: Recuperare contatti da directory o LinkedIn per attività commerciali.
- Monitorare i prezzi dei concorrenti: Tenere d’occhio i listini e aggiornare i propri prezzi in tempo reale (oltre l’80% dei principali e-commerce ).
- Aggregare contenuti: Creare dashboard con news, recensioni o menzioni social.
- Analizzare trend di mercato: Estrarre dati da recensioni, forum o portali di lavoro per capire sentiment e opportunità.
Il bello? Node.js rende tutto questo più veloce, flessibile e facile da automatizzare che mai. Grazie alla sua natura asincrona puoi processare decine (o centinaia) di pagine contemporaneamente, e le sue radici JavaScript lo rendono perfetto per siti costruiti con framework moderni.
Ecco una panoramica di casi d’uso reali:
| Caso d’uso | Descrizione & Esempio | Vantaggi di Node.js |
|---|---|---|
| Generazione Lead | Estrai email, nomi e numeri da directory aziendali. | Scraping veloce e parallelo; facile integrazione con CRM e API. |
| Monitoraggio Prezzi | Tieni traccia dei prezzi dei concorrenti su siti e-commerce. | Richieste asincrone per molte pagine; facile pianificazione di controlli giornalieri/orari. |
| Analisi Trend Mercato | Aggrega recensioni, forum o post social per analisi del sentiment. | Gestione versatile dei dati; ecosistema ricco per elaborazione e pulizia dei testi. |
| Aggregazione Contenuti | Raccogli articoli o post in un’unica dashboard. | Aggiornamenti in tempo reale; integrazione con strumenti di notifica (Slack, email, ecc.). |
| Analisi Competitor | Estrai cataloghi prodotti, descrizioni e valutazioni da siti rivali. | Parsing JavaScript per siti complessi; codice modulare per crawl multi-pagina. |
Node.js è particolarmente utile quando devi estrarre dati da siti pieni di JavaScript—dove Python e altri linguaggi spesso arrancano. E con la giusta configurazione, puoi passare dal “mi servono questi dati” al “ecco il mio file Excel” in pochi minuti.
Node Web Scraping: strumenti e librerie indispensabili
Prima di mettere mano al codice, vediamo gli strumenti principali per lo scraping con Node.js:
1. Axios (Client HTTP)

- A cosa serve: Recupera pagine web inviando richieste HTTP.
- Quando usarlo: Ogni volta che vuoi ottenere l’HTML grezzo di una pagina.
- Perché è utile: API semplice basata su promise; gestisce facilmente redirect e header.
- Installa con:
npm install axios
2. Cheerio (Parser HTML)

- A cosa serve: Analizza l’HTML e permette di usare selettori simili a jQuery per trovare i dati.
- Quando usarlo: Per siti statici dove i dati sono già presenti nell’HTML iniziale.
- Perché è utile: Veloce, leggero e familiare se conosci jQuery.
- Installa con:
npm install cheerio
3. Puppeteer (Automazione browser headless)

- A cosa serve: Controlla un vero browser Chrome in background, permettendo di interagire con le pagine come un utente.
- Quando usarlo: Per siti dinamici o interattivi (infinite scroll, login, pop-up).
- Perché è utile: Può cliccare pulsanti, compilare form, scorrere e estrarre dati dopo l’esecuzione degli script.
- Installa con:
npm install puppeteer
Extra: Esistono anche strumenti come Playwright (automazione multi-browser) e framework come Crawlee di Apify per flussi avanzati, ma Axios, Cheerio e Puppeteer sono il trio perfetto per chi inizia.
Prerequisiti: Assicurati di avere Node.js installato. Avvia un nuovo progetto con npm init -y e installa le librerie sopra.
Guida pratica: crea il tuo primo Node Web Scraper da zero
Rimbocchiamoci le maniche e costruiamo uno scraper semplice. Useremo Axios e Cheerio per estrarre dati di libri dal sito demo .
Step 1: Recupera l’HTML della pagina
1import axios from 'axios';
2import { load } from 'cheerio';
3const startUrl = 'http://books.toscrape.com/';
4async function scrapePage(url) {
5 const resp = await axios.get(url);
6 const html = resp.data;
7 const $ = load(html);
8 // ...estrai i dati nel prossimo step
9}Step 2: Analizza ed estrai i dati
1$('.product_pod').each((i, element) => {
2 const title = $(element).find('h3').text().trim();
3 const price = $(element).find('.price_color').text().replace('£', '');
4 const stock = $(element).find('.instock').text().trim();
5 const ratingClass = $(element).find('p.star-rating').attr('class') || '';
6 const rating = ratingClass.split(' ')[1];
7 const relativeUrl = $(element).find('h3 a').attr('href');
8 const bookUrl = new URL(relativeUrl, startUrl).href;
9 console.log({ title, price, rating, stock, url: bookUrl });
10});Step 3: Gestisci la paginazione
1const nextHref = $('.next > a').attr('href');
2if (nextHref) {
3 const nextUrl = new URL(nextHref, url).href;
4 await scrapePage(nextUrl);
5}Step 4: Salva i dati
Dopo aver raccolto i dati, puoi salvarli in un file JSON o CSV usando il modulo fs di Node.
1import fs from 'fs';
2// Dopo aver terminato lo scraping:
3fs.writeFileSync('books_output.json', JSON.stringify(booksList, null, 2));
4console.log(`Estratti ${booksList.length} libri.`);Ecco fatto: uno scraper Node.js funzionante! Questo metodo è perfetto per siti statici, ma come gestire quelli pieni di JavaScript?
Come gestire siti dinamici: usare Puppeteer con Node Web Scraping
Alcuni siti nascondono i dati dietro livelli di JavaScript. Se provi a estrarli con Axios e Cheerio, otterrai pagine vuote o dati mancanti. Qui entra in gioco Puppeteer.
Perché usare Puppeteer? Avvia un vero browser (headless), carica la pagina, aspetta che tutti gli script siano eseguiti e ti permette di recuperare i contenuti come farebbe un utente reale.
Esempio di script Puppeteer
1import puppeteer from 'puppeteer';
2async function scrapeWithPuppeteer(url) {
3 const browser = await puppeteer.launch({ headless: true });
4 const page = await browser.newPage();
5 await page.goto(url, { waitUntil: 'networkidle2' });
6 await page.waitForSelector('.product_pod'); // Attendi il caricamento dei dati
7 const data = await page.evaluate(() => {
8 let items = [];
9 document.querySelectorAll('.product_pod').forEach(elem => {
10 items.push({
11 title: elem.querySelector('h3').innerText,
12 price: elem.querySelector('.price_color').innerText,
13 });
14 });
15 return items;
16 });
17 console.log(data);
18 await browser.close();
19}Quando usare Cheerio/Axios e quando Puppeteer:
- Cheerio/Axios: Veloci e leggeri, ideali per contenuti statici.
- Puppeteer: Più lento, ma indispensabile per pagine dinamiche o interattive (login, infinite scroll, ecc.).
Consiglio: prova sempre prima Cheerio/Axios per velocità. Se mancano dati, passa a Puppeteer.
Node Web Scraping avanzato: paginazione, login e pulizia dati
Dopo aver imparato le basi, puoi affrontare scenari più complessi.
Gestire la paginazione
Cicla tra le pagine rilevando e seguendo i link “next”, oppure generando gli URL se seguono uno schema.
1let pageNum = 1;
2while (true) {
3 const resp = await axios.get(`https://example.com/products?page=${pageNum}`);
4 // ...estrai i dati
5 if (!hasNextPage) break;
6 pageNum++;
7}Automatizzare il login
Con Puppeteer puoi compilare i form di login come un utente:
1await page.type('#username', 'myUser');
2await page.type('#password', 'myPass');
3await page.click('#loginButton');
4await page.waitForNavigation();Pulizia dei dati
Dopo lo scraping, pulisci i dati:
- Elimina i duplicati (usa un Set o filtra per chiavi uniche).
- Formatta numeri, date e testi.
- Gestisci i valori mancanti (riempi con null o salta i record incompleti).
Espressioni regolari e i metodi stringa di JavaScript sono ottimi alleati.
Best practice per il Node Web Scraping: evitare errori e lavorare in modo efficiente
Il web scraping è potente, ma presenta alcune sfide. Ecco come evitarle:
- Rispetta robots.txt e le policy dei siti: Controlla sempre se il sito consente lo scraping ed evita le aree vietate.
- Regola la frequenza delle richieste: Non sovraccaricare il sito con centinaia di richieste al secondo. Aggiungi ritardi e randomizzali per simulare il comportamento umano ().
- Ruota user agent e IP: Usa header realistici e, per scraping su larga scala, cambia IP per evitare blocchi.
- Gestisci gli errori: Cattura le eccezioni, ritenta le richieste fallite e registra gli errori per il debug.
- Valida i dati: Controlla campi mancanti o malformati per individuare subito cambiamenti nella struttura del sito.
- Scrivi codice modulare e manutenibile: Separa logica di fetch, parsing e salvataggio. Usa file di configurazione per selettori e URL.
E soprattutto—agisci in modo etico. Il web è una risorsa condivisa e nessuno ama i bot invadenti.
Thunderbit vs. Node Web Scraping fai-da-te: quando costruire e quando affidarsi a uno strumento
Arriviamo alla domanda chiave: conviene sviluppare uno scraper da zero o affidarsi a uno strumento come ?
Scraper Node.js fai-da-te:
- Pro: Massimo controllo, personalizzazione totale, integrazione con qualsiasi workflow.
- Contro: Richiede competenze di programmazione, tempi lunghi per setup e manutenzione, si rompe se il sito cambia.
Thunderbit Estrattore Web AI:
- Pro: Nessun codice richiesto, rilevamento automatico dei campi tramite AI, gestisce sottopagine e paginazione, esportazione istantanea su Excel, Google Sheets, Notion e altro (). Nessuna manutenzione—l’AI si adatta automaticamente ai cambiamenti dei siti.
- Contro: Meno flessibilità per workflow estremamente personalizzati (ma copre il 99% dei casi aziendali).
Ecco un confronto rapido:
| Aspetto | Node.js Scraper fai-da-te | Thunderbit Estrattore Web AI |
|---|---|---|
| Competenze tecniche | Richiesto saper programmare | Nessun codice, point-and-click |
| Tempo di setup | Da ore a giorni | Minuti (AI suggerisce i campi) |
| Manutenzione | Continua (cambi sito) | Minima (AI si adatta da sola) |
| Contenuti dinamici | Setup manuale con Puppeteer | Gestione integrata |
| Paginazione/Sottopagine | Codifica manuale | 1 click per gestire tutto |
| Esportazione dati | Codice manuale per export | 1 click su Excel, Sheets, Notion |
| Costo | Gratis (tempo dev, proxy) | Piano gratuito, crediti pay-as-you-go |
| Ideale per | Sviluppatori, logiche custom | Aziende, risultati rapidi |
Thunderbit è la soluzione ideale per team sales, marketing e operations che hanno bisogno di dati subito—senza settimane di sviluppo e debug. E per gli sviluppatori, è perfetto per prototipare o gestire task di scraping ricorrenti senza reinventare la ruota.
Conclusioni e takeaway: inizia il tuo percorso nel Node Web Scraping
Il node web scraping è la chiave per accedere ai dati nascosti del web—che tu voglia creare liste di lead, monitorare prezzi o alimentare la tua prossima idea vincente. Ecco cosa ricordare:
- Node.js + Cheerio/Axios è perfetto per siti statici; Puppeteer è la scelta giusta per pagine dinamiche e ricche di JavaScript.
- L’impatto sul business è concreto: Le aziende che usano il web scraping per decisioni data-driven vedono risultati tangibili, da al raddoppio delle vendite internazionali.
- Parti semplice: Crea uno scraper base, poi aggiungi funzionalità come paginazione, login automatico e pulizia dati.
- Scegli lo strumento giusto: Per scraping rapido e senza codice, è imbattibile. Per workflow personalizzati e integrati, gli script Node.js offrono il massimo controllo.
- Agisci responsabilmente: Rispetta le policy dei siti, regola la frequenza dei bot e mantieni il codice pulito e manutenibile.
Vuoi iniziare? Prova a costruire il tuo scraper Node.js, oppure e scopri quanto può essere semplice estrarre dati dal web. Se vuoi altri consigli, visita il per guide approfondite, tutorial e novità sullo scraping AI.
Buono scraping—che i tuoi dati siano sempre freschi, ordinati e un passo avanti alla concorrenza.
Domande frequenti
1. Cos’è il node web scraping e perché scegliere Node.js?
Il node web scraping consiste nell’usare Node.js per automatizzare l’estrazione di dati dai siti web. Node.js è particolarmente efficace perché gestisce richieste asincrone in modo efficiente ed è ideale per siti ricchi di JavaScript, grazie a strumenti come Puppeteer.
2. Quando usare Cheerio/Axios e quando Puppeteer per lo scraping?
Usa Cheerio e Axios per siti statici dove i dati sono già nell’HTML iniziale. Scegli Puppeteer quando devi estrarre contenuti caricati da JavaScript, interagire con la pagina (login, scroll infinito, ecc.).
3. Quali sono i principali casi d’uso aziendali per il node web scraping?
I casi più comuni sono generazione di lead, monitoraggio prezzi dei competitor, aggregazione di contenuti, analisi di trend di mercato e scraping di cataloghi prodotti. Node.js rende questi task rapidi e scalabili.
4. Quali sono gli errori più comuni nel node web scraping e come evitarli?
Gli errori più frequenti sono blocchi da sistemi anti-bot, cambiamenti nella struttura dei siti e gestione della qualità dei dati. Per evitarli, regola la frequenza delle richieste, ruota user agent/IP, valida i dati e scrivi codice modulare.
5. Come si confronta Thunderbit con uno scraper Node.js sviluppato in proprio?
Thunderbit offre una soluzione AI senza codice che rileva automaticamente i campi, gestisce sottopagine e paginazione. È ideale per chi vuole risultati rapidi, mentre lo scraping Node.js fai-da-te è perfetto per sviluppatori che necessitano di personalizzazione o integrazione avanzata.
Per altre guide e ispirazione, visita il e iscriviti al nostro per tutorial pratici.
Scopri di più