Il ritmo delle notizie digitali di oggi è davvero vertiginoso. Ogni minuto vengono pubblicati, aggiornati o modificati in sordina migliaia di titoli, tra testate mainstream, blog di nicchia e feed social.
Per dare un’idea della scala, acquisisce oltre 4 milioni di articoli di news al giorno, mentre il monitora le notizie in oltre 100 lingue e aggiorna il proprio feed globale ogni 15 minuti.
Per chi lavora nei media, nella ricerca o nella business intelligence, provare a stare dietro a questo flusso a mano è come svuotare una barca che affonda con una tazza da caffè.
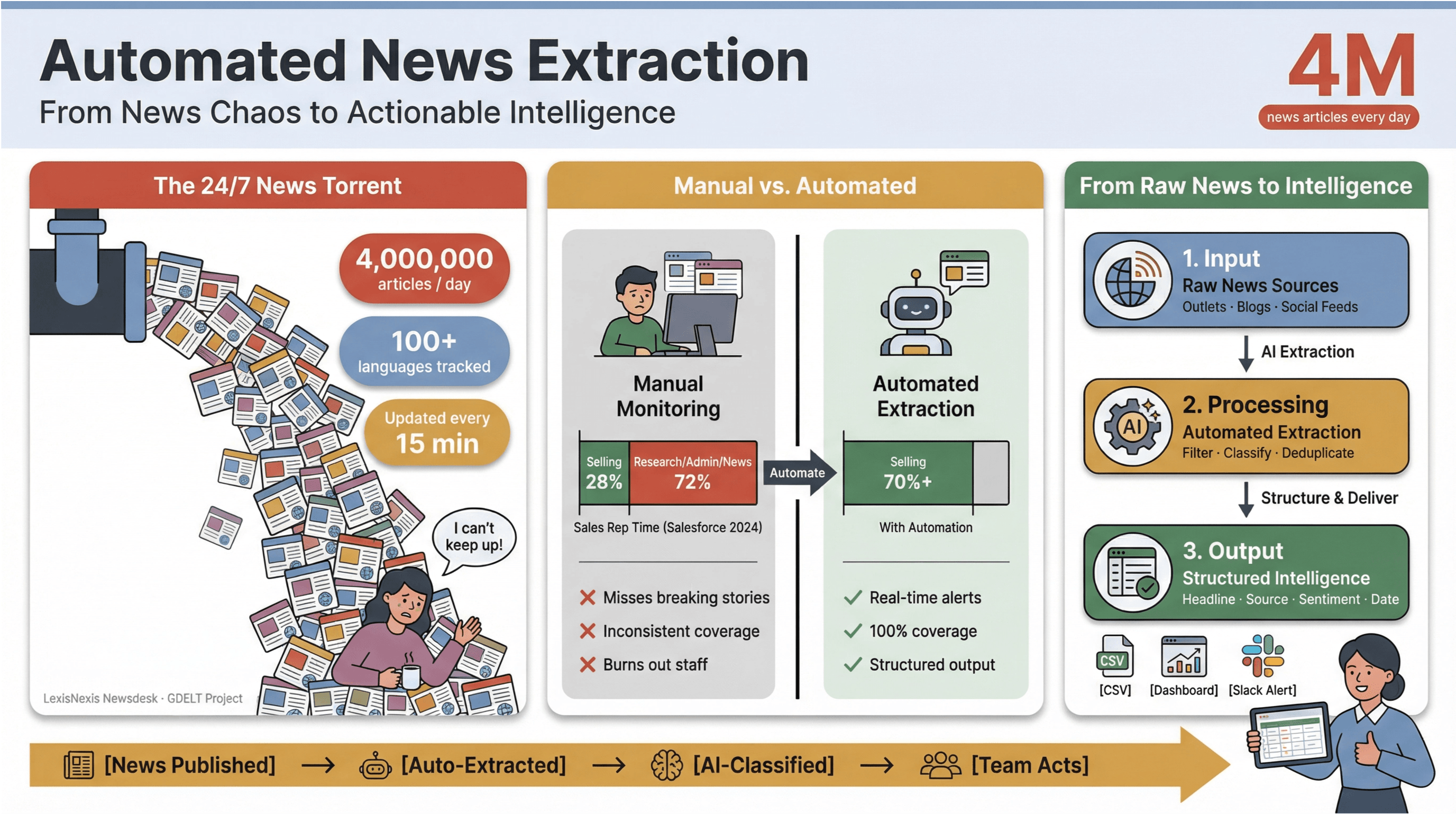
Ho visto in prima persona quanto il monitoraggio manuale delle notizie consumi tempo e risorse. I team di vendita dedicano alla vendita effettiva meno di un terzo della settimana — — mentre il resto si perde tra ricerche, attività amministrative e, sì, infiniti salti da una scheda all’altra delle news.
Per questo l’estrazione automatizzata delle notizie è diventata l’arma segreta dei team moderni: è l’unico modo per trasformare il caos del ciclo informativo 24/7 in intelligence strutturata e utilizzabile — senza mandare allo stremo il team o perdersi gli articoli davvero importanti.
Vediamo allora che cosa significa davvero estrazione automatizzata delle notizie, perché è essenziale per chiunque lavori con dati news in tempo reale e come costruire un flusso di lavoro solido e conforme usando i migliori strumenti, incluso il modo in cui rende l’intero processo sorprendentemente semplice — anche per i non tecnici come mia madre.
Estrazione automatizzata delle notizie: perché è essenziale per le redazioni moderne
L’estrazione automatizzata delle notizie è esattamente ciò che sembra: usare software per raccogliere automaticamente i contenuti news e trasformarli in dati strutturati e ricercabili — pensa a righe e colonne invece che a pagine web disordinate o PDF. In pratica, puoi monitorare centinaia (o migliaia) di fonti, estrarre campi chiave come titolo, timestamp, autore e testo dell’articolo, e convogliare quei dati in dashboard, alert o analisi downstream — senza mai toccare Ctrl+C/Ctrl+V.
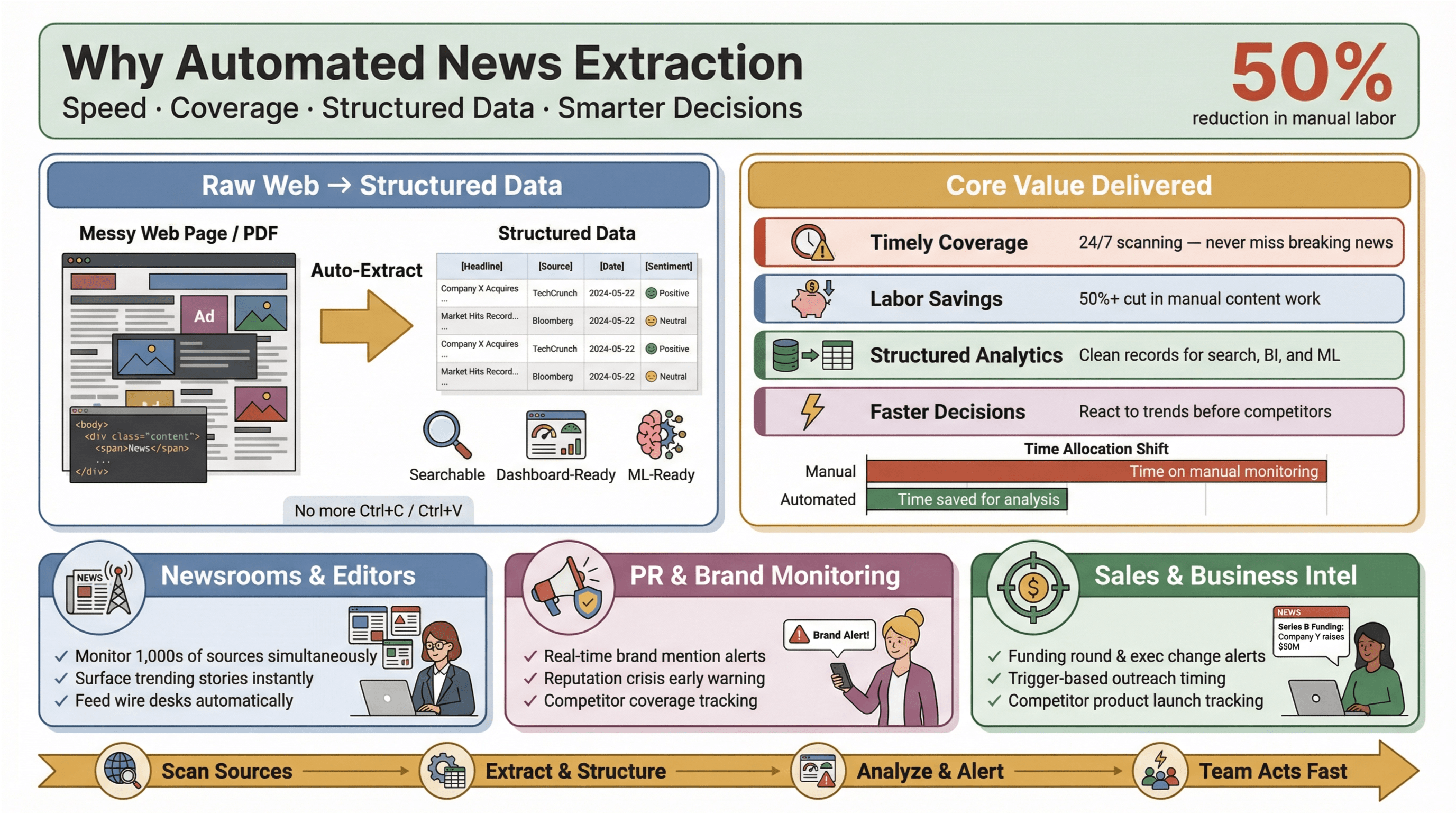 Perché è importante? Perché nel panorama delle news di oggi, la velocità è tutto. Che tu sia un editor di una redazione, un responsabile PR che monitora le menzioni del brand o un analista di business che segue le mosse dei concorrenti, essere i primi a sapere qualcosa può fare la differenza tra cogliere un’opportunità e inseguire gli eventi. Gli strumenti di estrazione automatizzata permettono anche ai piccoli team di competere con strutture molto più grandi: raccolgono dati news in tempo reale dal web, riducono il carico manuale e mettono in evidenza le storie che contano di più.
Perché è importante? Perché nel panorama delle news di oggi, la velocità è tutto. Che tu sia un editor di una redazione, un responsabile PR che monitora le menzioni del brand o un analista di business che segue le mosse dei concorrenti, essere i primi a sapere qualcosa può fare la differenza tra cogliere un’opportunità e inseguire gli eventi. Gli strumenti di estrazione automatizzata permettono anche ai piccoli team di competere con strutture molto più grandi: raccolgono dati news in tempo reale dal web, riducono il carico manuale e mettono in evidenza le storie che contano di più.
E l’impatto è reale: gli studi mostrano che l’automazione può ridurre il lavoro manuale per gli aggiornamenti dei contenuti di almeno il 50%, liberando tempo per analisi e decisioni vere.
Valore centrale dell’estrazione automatizzata delle notizie nel settore media
Passiamo al pratico. Che cosa offre davvero l’estrazione automatizzata delle notizie a redazioni e team aziendali?
- Copertura tempestiva e completa: niente più articoli breaking persi perché qualcuno si è dimenticato di controllare un feed. Gli strumenti automatici scandagliano le fonti 24/7, così non ti perdi nulla.
- Risparmio di tempo e costi: team piccoli e medi possono monitorare tante fonti quanto i grandi, senza assumere un esercito di stagisti.
- Dati strutturati per l’analisi: invece di rovistare tra articoli non strutturati, ottieni record puliti e pronti per ricerca, dashboard e machine learning.
- Decisioni più rapide e intelligenti: i dati news in tempo reale ti permettono di reagire prima a cambiamenti di mercato, crisi PR o trend emergenti.
Pensiamo a PR e comunicazione: piattaforme come e presentano il monitoraggio media in tempo reale come essenziale per proteggere la reputazione e intervenire rapidamente su coperture dannose. Nelle vendite, gli alert news in tempo reale diventano “context card” per il prospecting — round di finanziamento, cambi di executive o lanci di prodotto che attivano il contatto nel momento giusto.
Come scegliere gli strumenti giusti per l’estrazione di news in scenari diversi
Non tutti gli strumenti di news scraping sono uguali. La scelta giusta dipende dai tuoi obiettivi, dal livello di competenza tecnica e dal tipo di notizie che ti interessano. Ecco un quadro utile per trovare la soluzione più adatta:
Valutare semplicità d’uso e accessibilità
Per la maggior parte degli utenti business e dei giornalisti, la semplicità d’uso non è negoziabile. Ti serve uno strumento che funzioni subito, senza coding né configurazioni complicate. Piattaforme no-code e low-code come , e ti permettono di costruire scraper in modo visuale: basta puntare, cliccare ed estrarre.
Thunderbit, in particolare, si distingue per il suo processo in due passaggi: descrivi ciò che vuoi, lascia che l’AI suggerisca i campi e premi “Scrape”. Anche chi non ha competenze tecniche può creare una pipeline per i dati news in pochi minuti, non in ore.
Considerazioni su sicurezza e privacy dei dati
Ai grandi dati corrisponde una grande responsabilità. Gli strumenti di estrazione delle notizie spesso accedono a contenuti sensibili, quindi sicurezza e conformità devono essere una priorità. Cerca:
- Crittografia dei dati (in transito e a riposo)
- Policy sulla privacy chiare (Thunderbit, per esempio, dichiara di non vendere i dati degli utenti e di accedere solo ai contenuti che scegli di estrarre)
- Permessi granulari (soprattutto per le estensioni browser: controlla sempre a quali dati può accedere lo strumento)
- Conformità alle leggi locali (GDPR, CCPA e, per gli utenti UE, la )
Per stare ancora più tranquilli, scegli fornitori affidabili, verifica i permessi dell’estensione e limita l’accesso solo a ciò che è necessario.
Abbinare gli strumenti ai tipi di news e alle esigenze del settore
Alcuni strumenti eccellono in specifici ambiti editoriali:
- Finanza: API come e offrono clustering, sentiment e rilevamento degli eventi per le notizie finanziarie.
- Tech e startup: lo scraping personalizzato con Thunderbit o Octoparse ti consente di puntare blog di nicchia, comunicati stampa o elenchi di eventi.
- Politica e policy: database con licenza come e danno accesso a fonti premium e archivi.
Se devi monitorare un mix di fonti mainstream, di nicchia e internazionali — incluse quelle senza API — gli scraper flessibili basati su AI come Thunderbit sono la scelta migliore.
I vantaggi distintivi di Thunderbit per l’estrazione di dati news in tempo reale
Ora parliamo di ciò che rende una scelta eccellente per l’estrazione automatizzata delle notizie, soprattutto se vuoi dati news in tempo reale senza grattacapi tecnici.
Thunderbit è un’estensione Chrome con web scraper basato su AI progettata per utenti business, giornalisti e analisti che hanno bisogno di contenuti news aggiornati e strutturati da qualsiasi sito web. Ecco perché è diventato il mio strumento di riferimento:
- AI Suggest Fields: Thunderbit legge la pagina news e suggerisce automaticamente le colonne migliori da estrarre — titolo, timestamp, autore, riepilogo e altro. Niente più selettori o template da gestire.
- Subpage Scraping: ti serve l’articolo completo, non solo il titolo? Thunderbit può visitare ogni link news, estrarre il testo completo, le entità e i tag, e unire tutto in una tabella unica e strutturata.
- Esportazione in blocco e aggiornamenti istantanei: esporta i tuoi dati news direttamente in Excel, Google Sheets, Airtable o Notion con un clic. Basta maratone di copia-incolla e lotte con i CSV.
- Scheduled Scraping: imposta attività ricorrenti (ogni ora, ogni giorno o a intervalli personalizzati) per mantenere sempre fresco il tuo flusso di notizie — ideale per breaking news, monitoraggio di mercato o ricerche continuative.
- Adattabilità: l’AI di Thunderbit si adatta ai cambi di layout e ai siti news di lunga coda, così passi meno tempo a sistemare scraper rotti e più tempo ad analizzare i dati.
Con oltre e una valutazione di 4,8 stelle, è apprezzato da team di tutto il mondo per tutto, dal monitoraggio PR all’intelligence competitiva.
Rilevamento dei campi guidato dall’AI e scraping delle sottopagine
Una delle funzionalità più forti di Thunderbit è il suo rilevamento dei campi guidato dall’AI. Basta cliccare su “AI Suggest Fields” e lo strumento analizza la pagina news — identificando campi chiave come titolo, data, autore e riepilogo. Puoi ritoccare o aggiungere campi personalizzati (per esempio, “etichetta questo articolo come ‘earnings’ se menziona i risultati trimestrali”), e l’AI di Thunderbit farà il resto.
Lo scraping delle sottopagine è una svolta per le news: estrai la homepage o una lista di sezioni per i titoli, poi lascia che Thunderbit visiti ogni URL dell’articolo per estrarre la storia completa, le entità e persino le immagini. In questo modo ottieni record news completi e arricchiti, pronti per ricerca, dashboard o analisi AI downstream.
Esportazione in blocco e aggiornamenti istantanei
Thunderbit rende semplice esportare i dati news. Con un clic puoi inviare il tuo feed strutturato a Google Sheets, Airtable o Notion, oppure scaricarlo come CSV/Excel. Per i team che lavorano in fogli di calcolo o strumenti BI, è un enorme risparmio di tempo.
E poiché Thunderbit supporta lo scheduled scraping, puoi impostarlo per eseguire l’estrazione ogni ora, ogni giorno o secondo un programma personalizzato, assicurando che i tuoi dati news siano sempre aggiornati. Niente più attese perché Google Alerts indicizzi gli articoli con giorni di ritardo.
Superare le sfide operative nelle soluzioni di dati news in tempo reale
Anche con gli strumenti migliori, l’estrazione delle news in tempo reale porta con sé alcune sfide. Ecco come affrontare le più comuni:
Gestire latenza e freschezza dei dati
- Programma le estrazioni in base alla velocità delle news: per le breaking news, imposta gli scraper per girare ogni 15–30 minuti (in linea con il ). Per i ritmi più lenti, possono bastare esecuzioni giornaliere o orarie.
- Monitora il ritardo tra pubblicazione e acquisizione: traccia la differenza tra quando un articolo viene pubblicato e quando il tuo sistema lo recupera. Se il ritardo aumenta, controlla blocchi o rallentamenti.
- Riestrae per le “modifiche silenziose”: gli articoli di news vengono spesso aggiornati dopo la pubblicazione. Pianifica una seconda estrazione 24 ore dopo per intercettare correzioni o modifiche nascoste ().
Gestire limiti API e variabilità delle fonti
- Rispetta le quote API: se usi API di news, fai attenzione ai rate limit — distribuisci le richieste nel tempo e, quando possibile, memorizza nella cache i risultati ().
- Deduplica e canonicalizza: gli articoli spesso compaiono su più URL o vengono aggiornati. Raccogli gli URL canonici e usa hash (per esempio titolo + data) per evitare duplicati ().
- Gestisci i contenuti dinamici: per siti con infinite scroll o caricamento lazy, usa strumenti che supportano il rendering dinamico e monitora i cambi di layout ().
Analisi intelligente dei dati news: il ruolo di AI e machine learning
Estrarre le notizie è solo il primo passo. Il vero valore arriva da analizzare quei dati e agire di conseguenza — ed è qui che AI e machine learning danno il meglio.
- Estrazione di entità: usa l’NLP per estrarre persone, organizzazioni e luoghi menzionati in ogni articolo ().
- Classificazione per argomento: etichetta automaticamente gli articoli per tema, sentiment o urgenza, consentendo dashboard e alert più intelligenti ().
- Clustering degli eventi: raggruppa articoli duplicati o correlati tra diverse testate, così vedi il quadro generale e