

Lo web scraping ha smesso da un pezzo di essere una competenza da nicchia: oggi è una specie di superpotere per chiunque lavori nelle vendite, nelle operations o nella ricerca di mercato. E con i dati sul web che crescono senza freni — la quantità di dati creati nel mondo è salita di quasi il 193% tra il 2019 e il 2023 — non sorprende che ormai l’81% delle aziende consideri i dati il “cuore” delle proprie decisioni. C’è però un dettaglio scomodo: il 95% delle organizzazioni ammette che gestire i dati non strutturati, tipo l’HTML disordinato, è una bella gatta da pelare. Di team annegati in maratone di copia-incolla per travasare le informazioni dai siti ai fogli di calcolo ne ho visti fin troppi — e credimi, non è uno spettacolo allegro.
Estrarre dati da qualsiasi sito web con l’IA Get Started Free
Qui entra in scena BeautifulSoup, in Python. In questo tutorial pratico ti accompagno passo dopo passo nell’uso di BeautifulSoup per lo web scraping, con un esempio concreto in Python che potrai poi cucire sulle esigenze della tua azienda. E siccome il mio mantra è lavorare in modo più furbo e non più faticoso, ti faccio vedere anche come abbinare BeautifulSoup a Thunderbit, il nostro estrattore web con IA, per snellire il flusso di lavoro e ottenere dati più puliti e strutturati — qualunque sia il tuo livello con il codice.
Cos’è BeautifulSoup e perché usarlo per lo web scraping?
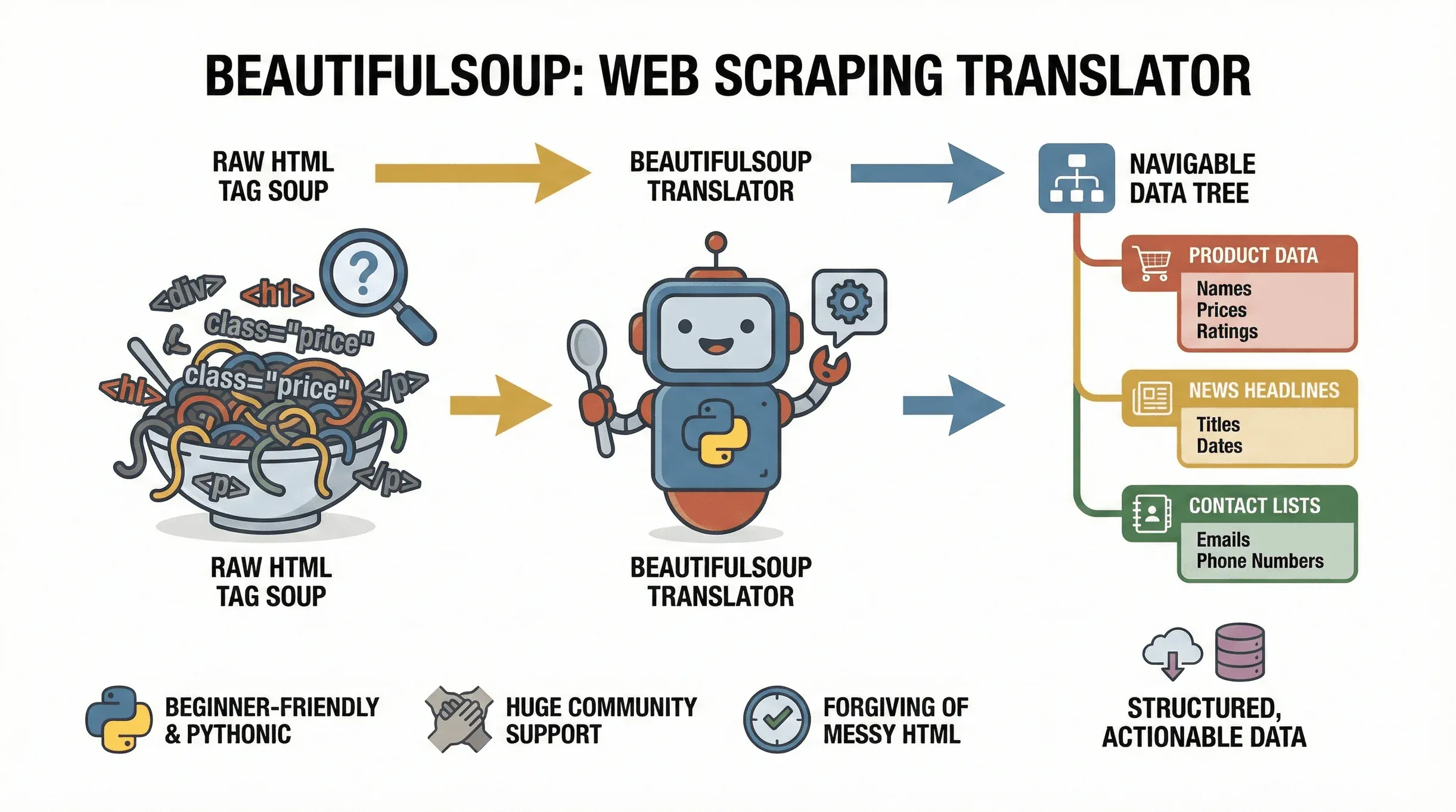 Partiamo dalle fondamenta. BeautifulSoup è una libreria Python che semplifica enormemente l’analisi di documenti HTML e XML. Immaginala come un traduttore: prende il “tag soup” di una pagina web e lo converte in una struttura ad albero su cui ti muovi facilmente, così trovi, estrai e manipoli senza fatica i dati che ti interessano. Il progetto è tuttora attivo —
Partiamo dalle fondamenta. BeautifulSoup è una libreria Python che semplifica enormemente l’analisi di documenti HTML e XML. Immaginala come un traduttore: prende il “tag soup” di una pagina web e lo converte in una struttura ad albero su cui ti muovi facilmente, così trovi, estrai e manipoli senza fatica i dati che ti interessano. Il progetto è tuttora attivo — beautifulsoup4 4.14.3 è arrivato su PyPI a fine 2025 — quindi quello che impari qui è roba attuale. Che tu debba raccogliere i prezzi dei prodotti da un sito e-commerce, i titoli delle notizie o gli elenchi di aziende per trovare lead, BeautifulSoup è lo strumento a cui torni quando vuoi trasformare le pagine web in dati strutturati e pronti all’uso.
Da dove arriva tutta questa popolarità? Innanzitutto, è amichevolissimo con chi inizia. BeautifulSoup digerisce bene l’HTML sporco o malfatto (e diciamocelo: il web ne trabocca), e la sua sintassi in stile Python ti porta da zero allo scraping in una manciata di righe. In più ha alle spalle una community enorme e milioni di download — quindi, se ti incagli, in genere basta una ricerca su Google per trovare la soluzione.
I casi d’uso classici di BeautifulSoup includono:
- Estrarre nomi di prodotti, prezzi e valutazioni dalle pagine e-commerce
- Raccogliere titoli, autori e date di pubblicazione dai siti di notizie
- Analizzare tabelle o directory, come elenchi di aziende o contatti
- Recuperare email o numeri di telefono dai siti di annunci
- Tenere d’occhio gli aggiornamenti, tipo variazioni di prezzo o nuove offerte di lavoro
Se i tuoi dati vivono nell’HTML statico, BeautifulSoup è l’alleato che fa al caso tuo per lo web scraping.
I vantaggi unici di BeautifulSoup per lo web scraping
Di librerie Python per lo scraping ce ne sono a bizzeffe — allora perché proprio BeautifulSoup? Ecco come regge il confronto con la concorrenza:
- Semplicità: è leggera e si impara in fretta. Non devi montare un intero framework né scrivere montagne di codice boilerplate. Perfetta per attività di scraping rapide e occasionali, o per chi è alle prime armi.
- Tolleranza agli errori: se la cava con HTML rotto o malformato, una situazione più frequente di quanto si creda.
- Flessibilità: non ti incastra in un’architettura di crawling rigida. Le passi l’HTML ed estrai ciò che ti serve, punto.
- Integrazione: dialoga benissimo con altre librerie Python come
requestsper scaricare le pagine,csvper salvare i dati epandasper analizzarli.
E rispetto agli altri strumenti?
| Strumento | Ideale per | Vantaggi | Svantaggi |
|---|---|---|---|
| BeautifulSoup | Analisi di HTML statico, principianti | Semplice, configurazione rapida, tollerante, flessibile | Non adatto a siti molto basati su JavaScript |
| Scrapy | Operazioni su larga scala, asincrone | Potente, scalabile, crawling integrato | Curva di apprendimento più ripida, più configurazione |
| Selenium | Contenuti JavaScript/dinamici | Può interagire con JS, compilare moduli, cliccare pulsanti | Più lento, più pesante, più dispendioso in risorse |
Se sei agli inizi o ti serve analizzare al volo pagine statiche, BeautifulSoup è il “coltellino svizzero” dello web scraping (medium.com). Per siti più complessi o dinamici puoi abbinarlo a Selenium o Scrapy — ma per imparare le basi resta la strada migliore.
Configurare l’ambiente Python per BeautifulSoup
Pronto a partire? Ecco come preparare l’ambiente:
-
Installa Python: scarica l’ultima versione da python.org.
-
Crea un ambiente virtuale (facoltativo, ma te lo consiglio):
python -m venv venv source venv/bin/activate # Su Windows: venv\Scripts\activate -
Installa BeautifulSoup e le dipendenze:
pip install beautifulsoup4 requests lxml html5libbeautifulsoup4: la libreria principalerequests: per scaricare le pagine weblxmlohtml5lib: parser HTML più veloci e affidabili
-
Se qualcosa non va:
- Errore “pip not found”? Prova con
pip3oppurepy -m pip. - Su Mac/Linux potresti aver bisogno di
sudoper i permessi. - Su Windows, controlla che Python sia stato aggiunto al PATH.
- Errore “pip not found”? Prova con
Per assicurarti che fili tutto liscio, lancia questo test veloce:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Se compare <title>Example Domain</title>, sei a cavallo (Thunderbit Blog).
Un esempio Python Beautiful Soup passo dopo passo
Mettiamoci le mani sopra con un esempio reale di python beautiful soup. Diciamo che vuoi raccogliere i titoli delle ultime notizie da un sito pubblico di news. Si fa così:
1. Recupera la pagina web
import requests
from bs4 import BeautifulSoup
url = "https://www.bbc.com/news"
response = requests.get(url)
html = response.text
2. Analizza l’HTML
soup = BeautifulSoup(html, "html.parser")
3. Esamina la struttura HTML
Apri gli Strumenti per sviluppatori del browser (clic destro → Ispeziona) e individua i tag che contengono i titoli. Su molti siti di news li trovi dentro tag <h3> con classi ben precise.
Per esempio, potresti imbatterti in qualcosa del genere:
<h3 class="gs-c-promo-heading__title">Titolo della notizia</h3>
4. Estrai i dati
headlines = soup.find_all("h3", class_="gs-c-promo-heading__title")
for h in headlines:
print(h.get_text(strip=True))
Così stamperai tutti i titoli delle notizie presenti nella pagina.
5. Salva i dati in CSV
Mettiamo da parte quei titoli per analizzarli con calma:
import csv
with open("headlines.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["titolo"])
for h in headlines:
writer.writerow([h.get_text(strip=True)])
Ed ecco un file CSV pronto da aprire in Excel o Google Sheets.
Capire la struttura HTML per estrarre i dati in modo efficace
Prima di scrivere una riga di codice, ispeziona sempre l’HTML della pagina. Ecco come si procede:
- Apri gli Strumenti per sviluppatori: clic destro sulla pagina e poi “Ispeziona”.
- Localizza i dati: passa il mouse sugli elementi per scoprire quali tag racchiudono le informazioni che cerchi — titoli, prezzi, autori.
- Annota tag e classi: punta agli identificatori univoci, tipo
class="product-title"oid="main-content". - Testa i selettori: usa i metodi
.find(),.find_all()o.select()di BeautifulSoup per centrare quegli elementi.
Suggerimento spiccio: usa soup.prettify() per stampare l’HTML in una versione leggibile direttamente nella console Python.
Estrarre e strutturare i dati con BeautifulSoup
Mettiamo che tu voglia tirare fuori sia i titoli sia gli autori da una pagina blog:
articles = soup.find_all("article")
data = []
for article in articles:
title = article.find("h2").get_text(strip=True)
author = article.find("span", class_="author").get_text(strip=True)
data.append({"title": title, "author": author})
Ora hai un elenco di dizionari — l’ideale da esportare in CSV o da passare ad analisi successive.
Allo stesso modo puoi estrarre link, immagini o qualsiasi attributo:
for link in soup.find_all("a"):
print(link.get("href"))
Oppure le immagini:
for img in soup.find_all("img"):
print(img.get("src"))
Salvare i dati estratti: da Python a Excel o CSV
Una volta che i dati sono strutturati, esportarli è una passeggiata. Con il modulo csv fai così:
import csv
with open("articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
Oppure, se preferisci pandas:
import pandas as pd
df = pd.DataFrame(data)
df.to_csv("articles.csv", index=False)
df.to_excel("articles.xlsx", index=False)
Usa sempre la codifica UTF-8, così eviti grane con i caratteri speciali — soprattutto quando maneggi dati internazionali.
Caso di studio: fare scraping dei dati di un sito di news con BeautifulSoup
Guardiamo un esempio concreto di python beautiful soup: estrarre titoli, autori e date di pubblicazione degli articoli da un sito di news.
Diciamo che vogliamo raccogliere i dati degli articoli di CNN:
import requests
from bs4 import BeautifulSoup
import csv
url = "https://edition.cnn.com/world"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
articles = soup.find_all("article")
data = []
for article in articles:
title_tag = article.find("h3")
date_tag = article.find("span", class_="date")
author_tag = article.find("span", class_="author")
title = title_tag.get_text(strip=True) if title_tag else ""
date = date_tag.get_text(strip=True) if date_tag else ""
author = author_tag.get_text(strip=True) if author_tag else ""
data.append({"title": title, "date": date, "author": author})
with open("cnn_articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "date", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
Questo script va a prendere gli articoli più recenti, ne estrae titolo, data e autore e li salva in un CSV — a patto che il markup attuale di CNN combaci ancora con i tag qui sopra. I grandi siti di news cambiano spesso classi e struttura del DOM, quindi ricontrolla la pagina prima di usarlo su dati di produzione. La parte stabile è il pattern (<article> come contenitore, poi find sui tag figli); i nomi di classe specifici come "date" e "author" sono segnaposto da adattare a ciò che la pagina live mostra in quel momento.
Migliorare il flusso di lavoro: combinare BeautifulSoup con Thunderbit
Vediamo adesso come rendere ancora più scorrevole il tuo flusso di scraping. Thunderbit è un’estensione Chrome per l’estrazione web basata sull’IA che toglie di mezzo i tentativi a vuoto nell’estrazione dei dati. Con Thunderbit puoi:
- Sfruttare “AI Suggest Fields”: Thunderbit legge la pagina e ti suggerisce da solo quali campi estrarre — niente più caccia all’HTML né selettori da ritoccare.
- Fare scraping delle sottopagine: Thunderbit segue i link verso le sottopagine, come schede prodotto o singoli articoli, e arricchisce il dataset con dettagli aggiuntivi.
- Esportare all’istante: manda i dati dritti in Excel, Google Sheets, Airtable o Notion con un clic.
- Gestire la paginazione: Thunderbit estrae dati su più pagine, scroll infinito compreso.
- Programmare le estrazioni: imposta attività ricorrenti per tenere i dati sempre freschi.
Ecco un flusso ibrido che adoro:
- Parti da Thunderbit: apri il sito di destinazione, clicca l’icona di Thunderbit e lascia che “AI Suggest Fields” individui le colonne giuste, tipo titolo, autore e data.
- Esporta i dati: scaricali in CSV oppure spediscili direttamente su Google Sheets.
- Usa BeautifulSoup per l’elaborazione su misura: se ti serve scendere più in profondità — pulizia del testo, deduplicazione, fusione con altre fonti — carica il CSV esportato in Python e fai il post-processing con BeautifulSoup o pandas.
Questa accoppiata ti dà il meglio dei due mondi: la velocità di Thunderbit con il rilevamento dei campi guidato dall’IA, e la flessibilità di BeautifulSoup per tutta la logica personalizzata.
Prova gratis l’Estrattore Web AI di Thunderbit
Velocità e qualità dei dati: perché usare insieme Thunderbit e BeautifulSoup?
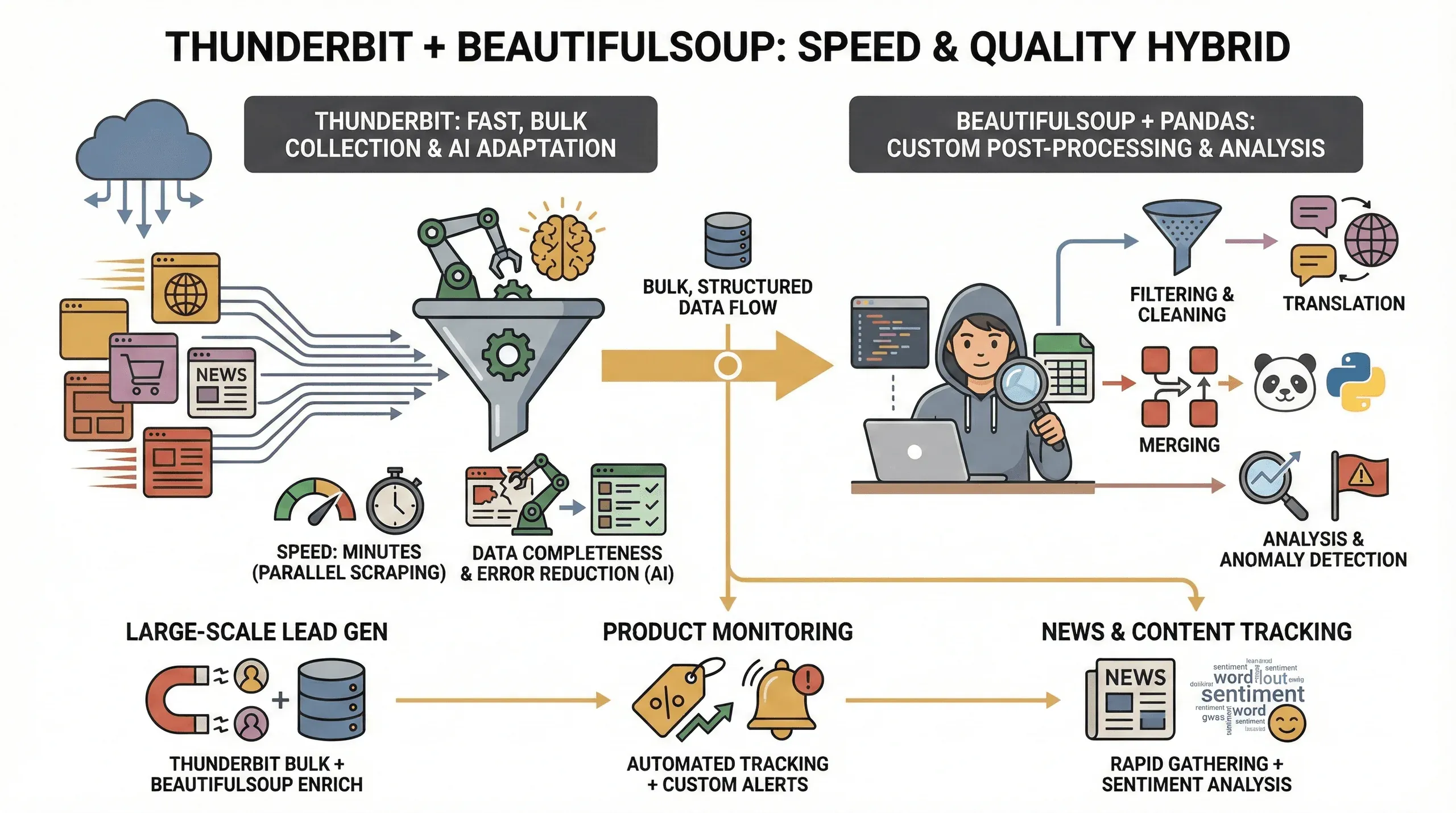 Perché tenerli entrambi nello stesso flusso? Ecco cosa ho notato sul campo:
Perché tenerli entrambi nello stesso flusso? Ecco cosa ho notato sul campo:
- Velocità: Thunderbit estrae decine di pagine in parallelo (fino a 50 alla volta in modalità cloud), così i dati arrivano in minuti invece che in ore.
- Completezza dei dati: l’IA di Thunderbit si adatta ai cambi di layout e riesce a estrarre dati strutturati anche dai siti più ostici, riducendo il rischio di campi mancanti.
- Meno errori: basta script che si rompono al primo cambio di nome di una classe — l’IA di Thunderbit rilegge la pagina ogni volta.
- Post-processing su misura: per le esigenze avanzate, come filtraggio, traduzione o unione di dataset, con BeautifulSoup e pandas hai il pieno controllo.
Questo approccio ibrido brilla soprattutto in casi come:
- Generazione lead su larga scala: raccogli i dati in massa con Thunderbit, poi ripuliscili e arricchiscili con BeautifulSoup.
- Monitoraggio prodotti: Thunderbit si occupa dello scraping ripetitivo, BeautifulSoup ti lascia analizzare i trend o segnalare le anomalie.
- Tracciamento di notizie e contenuti: raccogli velocemente gli articoli con Thunderbit, poi affidati a Python per l’analisi del sentiment o l’estrazione delle parole chiave.
Risolvere i problemi più comuni nello web scraping con BeautifulSoup
Prova l’estensione Chrome di Thunderbit Estrarre qualsiasi sito web con l’IA in 2 clic. Get Started Free
Lo web scraping non è sempre tutto rose e fiori — ecco gli intoppi più frequenti e come venirne a capo:
- Contenuti dinamici: se un sito carica i dati via JavaScript, come scroll infinito o AJAX, BeautifulSoup da solo non li intercetta. In questi casi appoggiati a Selenium o alla modalità browser di Thunderbit.
- Misure anti-bot: alcuni siti bloccano le richieste automatiche. Prova a impostare un header User-Agent personalizzato, a inserire ritardi tra una richiesta e l’altra o a usare lo scraping cloud di Thunderbit per aggirare i blocchi più semplici.
- Cambiamenti nella struttura HTML: se lo script smette di colpo di funzionare, quasi sicuramente l’HTML del sito è cambiato. Ispeziona di nuovo la pagina e aggiorna i selettori. L’IA di Thunderbit ti dà una mano adattandosi al volo.
- Dati mancanti: controlla sempre che un elemento esista prima di chiamare
.get_text(). Per gli attributi usa.get()invece di[], così eviti i KeyError. - Problemi di codifica: salva i file in UTF-8 per gestire correttamente i caratteri speciali.
E soprattutto: rispetta sempre il robots.txt e i termini di servizio del sito. Fai scraping con buon senso — i robot maleducati non piacciono a nessuno.
Conclusione e punti chiave
Lo web scraping con BeautifulSoup è una delle competenze più concrete che puoi portarti a casa in un mondo guidato dai dati come quello di oggi. Ricapitoliamo cosa abbiamo visto in questo tutorial su BeautifulSoup per lo web scraping:
- BeautifulSoup è il punto di partenza ideale per analizzare HTML statico ed estrarre dati strutturati con Python.
- La configurazione è semplicissima — bastano Python, pip e un paio di librerie.
- Ispezionare l’HTML è il passaggio chiave per colpire i dati giusti.
- Esportare in CSV/Excel rende i dati subito pronti per l’analisi aziendale.
- Affiancare Thunderbit ti porta rilevamento dei campi con IA, scraping più rapido ed esportazioni più semplici — perfetto per utenti business e non programmatori.
- I flussi ibridi (Thunderbit per l’estrazione di massa, BeautifulSoup per l’elaborazione su misura) offrono il miglior equilibrio tra velocità, qualità dei dati e flessibilità.
Se sei pronto a fare il salto di qualità nel tuo web scraping, prova entrambi gli strumenti: gioca con un semplice script BeautifulSoup e poi tocca con mano quanto vai più veloce con l’estrattore web AI di Thunderbit. E per altre guide pratiche, fai un salto sul Thunderbit Blog.
Buon scraping — e che i tuoi dati siano sempre puliti, ordinati e pronti all’azione.
Prova l’Estrattore Web AI di Thunderbit Get Started Free
FAQ
1. Cos’è BeautifulSoup e a cosa serve?
BeautifulSoup è una libreria Python per analizzare documenti HTML e XML. Ti aiuta a estrarre dati dalle pagine web e a riversarli in formati strutturati come elenchi o tabelle, il che la rende perfetta per i progetti di web scraping.
2. Come si confronta BeautifulSoup con Selenium e Scrapy?
BeautifulSoup è leggera e facile da usare con le pagine HTML statiche. Selenium è più indicato per lo scraping di siti dinamici e zeppi di JavaScript, mentre Scrapy è un framework completo per lo scraping asincrono su larga scala. Per chi inizia e per i lavori veloci, BeautifulSoup resta la scelta migliore.
3. Posso usare insieme BeautifulSoup e Thunderbit?
Assolutamente sì. Thunderbit individua ed estrae in fretta i campi dalle pagine web grazie all’IA, e BeautifulSoup ti serve per il post-processing su misura o per analizzare più a fondo i dati esportati.
4. Quali sono le sfide più comuni nello web scraping con BeautifulSoup?
I grattacapi tipici sono la gestione dei contenuti dinamici, la presenza di misure anti-bot e l’adattamento ai cambiamenti nella struttura HTML. Le funzionalità IA di Thunderbit, o la sua modalità browser, ti aiutano a superare buona parte di questi ostacoli.
5. Come esportare in Excel o CSV i dati estratti con BeautifulSoup?
Puoi usare il modulo csv integrato in Python oppure la libreria pandas per salvare i dati estratti in file CSV o Excel. Usa sempre la codifica UTF-8 per gestire i caratteri speciali e garantire la compatibilità con i fogli di calcolo.
Pronto a metterti alla prova? Scarica l’estensione Chrome di Thunderbit e comincia subito a fare scraping in modo più intelligente. Per altri tutorial e consigli, visita il Thunderbit Blog.
Scopri di più




