Uno studio basato sul crawling su come i siti web ad alto traffico stiano pubblicando indicazioni leggibili dalle macchine per i modelli linguistici di grandi dimensioni, su come appaiano le prime implementazioni e sul perché misurare l’adozione richieda molto più del semplice conteggio delle risposte HTTP 200.
- Dataset:
data/llms_probe_results_top_10000.csv - Lista Tranco scaricata: 6 maggio 2026
- Ambito:
/llms.txte/llms-full.txta livello di root
Metriche chiave
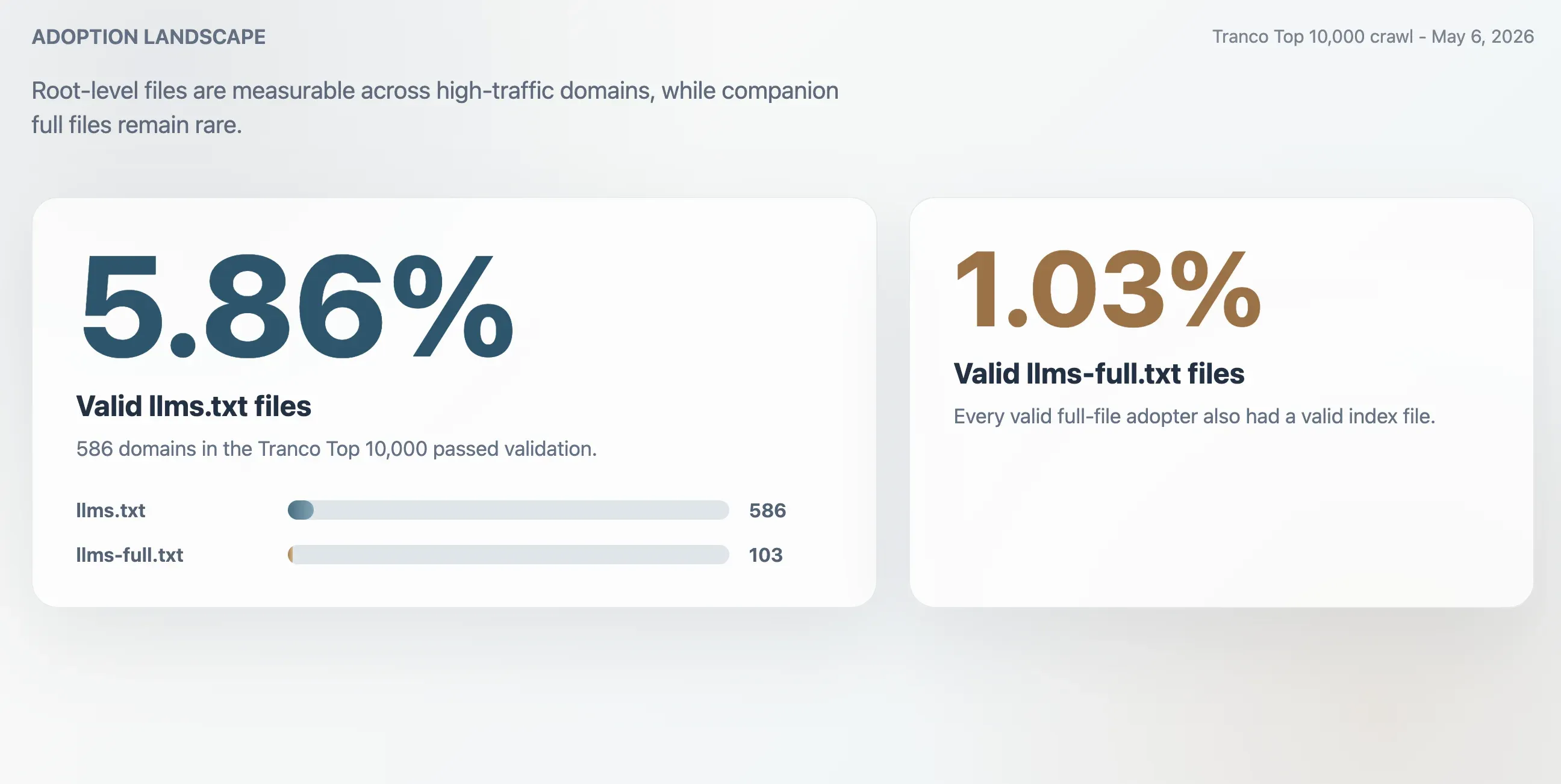
- 5,86%: adozione valida di
llms.txtnel Tranco Top 10.000, pari a 586 domini. - 1,03%: adozione valida di
llms-full.txt, pari a 103 domini. Ogni sito con un file full valido aveva anche un file index valido. - 63,51%: quota delle risposte HTTP 200 per
/llms.txtche non hanno superato la validazione. - 2,74x: sovrastima approssimativa se l’adozione venisse misurata solo sulle risposte HTTP 200 grezze.
Sintesi esecutiva
llms.txt è ancora una convenzione web agli inizi, ma non è più un esperimento marginale. In un crawling del 6 maggio 2026 sui 10.000 domini del Tranco, questo studio ha rilevato 586 file llms.txt validi, per un tasso di adozione osservato del 5,86%. Il file complementare llms-full.txt era molto meno diffuso: 103 domini avevano un file full valido, pari a un tasso di adozione dell’1,03%.
Il risultato metodologico più importante è che i codici di stato sono un cattivo proxy dell’adozione. Il crawler ha osservato 1.606 risposte HTTP 200 per /llms.txt, ma solo 586 hanno superato la validazione. Le restanti 1.020 erano per lo più redirect fuori bersaglio, pagine HTML generiche, corpi vuoti o altre risposte non valide. Un crawler ingenuo che contasse ogni risposta 200 come adozione sovrastimerebbe l’adozione reale di circa 2,74 volte.
Tra gli adottanti validi, la qualità di implementazione è superiore a quanto suggerirebbe una semplice narrativa da segnaposto. Il file valido mediano era di circa 7,1 KB, il 61,77% dei file validi superava i 5 KB, il 70,82% conteneva sei o più sezioni Markdown e il 77,47% conteneva 11 o più link Markdown. Il gruppo dei primi adottanti include Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog e Cloudinary.
llms.txtsi interpreta meglio come un segnale esplicativo e di navigazione per i sistemi IA, non come sostituto dirobots.txt. Il suo valore non sta solo nell’esistenza del file, ma nel fatto che aiuti le macchine a trovare informazioni autorevoli, compatte e aggiornate.
Contesto: il web sta aggiungendo segnali rivolti all’IA
I siti web usano da tempo robots.txt per esprimere le preferenze verso i crawler, sitemap.xml per migliorare la scoperta degli URL e i dati strutturati per aiutare i sistemi di ricerca e piattaforma a interpretare le pagine. L’IA generativa introduce però un problema diverso. I contenuti possono essere usati per training, retrieval, riassunto, navigazione agentica, assistenza al codice, supporto clienti e generazione di risposte. Questo crea due esigenze simultanee: gli editori vogliono più controllo sull’uso automatizzato, ma vogliono anche che i sistemi IA trovino le informazioni canoniche corrette quando interagiscono con i loro siti.
La , introdotta da Jeremy Howard nel 2024, definisce il file come un documento Markdown collocato nella root del sito per fornire informazioni adatte agli LLM al momento dell’inferenza. La proposta sostiene che le pagine HTML spesso includono navigazione, pubblicità, script e altro rumore che le rende più difficili da elaborare per i modelli linguistici. Un file Markdown conciso può indirizzare i modelli verso le pagine, la documentazione, le API, gli esempi, le policy e le informazioni di prodotto più importanti.
La ricerca web esterna fornisce il contesto più ampio. della Data Provenance Initiative descrive un rapido aumento delle restrizioni legate all’IA in robots.txt e nei termini di servizio, sostenendo che gli attuali meccanismi di consenso del web non sono stati progettati per il riuso dei dati IA su larga scala. ha inoltre reso visibili i pattern dei crawler IA e di robots.txt a livello Top 10.000 domini. In questo contesto, llms.txt si colloca sul lato costruttivo della segnalazione all’IA: non “non fare crawling di questo”, ma “se devi capire questo sito, parti da qui”.
Evidenze esterne e dibattito sull’adozione
Il dibattito pubblico su llms.txt si divide tra due tesi. La tesi ottimista è che il file offra ai sistemi IA un percorso più pulito ed efficiente verso contenuti autorevoli. La tesi scettica è che nessun grande provider di LLM abbia pubblicamente promesso di usarlo come segnale di ranking, crawling o citazione, quindi gli editori non dovrebbero aspettarsi benefici di traffico dal solo file. Le tre fonti esterne esaminate per questo aggiornamento supportano una conclusione più sfumata: llms.txt è un’infrastruttura utile, ma le prove di un impatto diretto sul traffico restano limitate e dipendenti dal contesto.
I benchmark esterni di adozione stanno cambiando rapidamente
ha riportato un tasso di adozione dello 0,3% tra i primi 1.000 siti al 22 giugno 2025, cioè 3 siti su 1.000. Descrive scansioni automatizzate mensili di domain.com/llms.txt, con validazione che esclude redirect e risposte HTML. Questa metodologia è direzionalmente simile all’approccio prudente di validazione di questo studio.
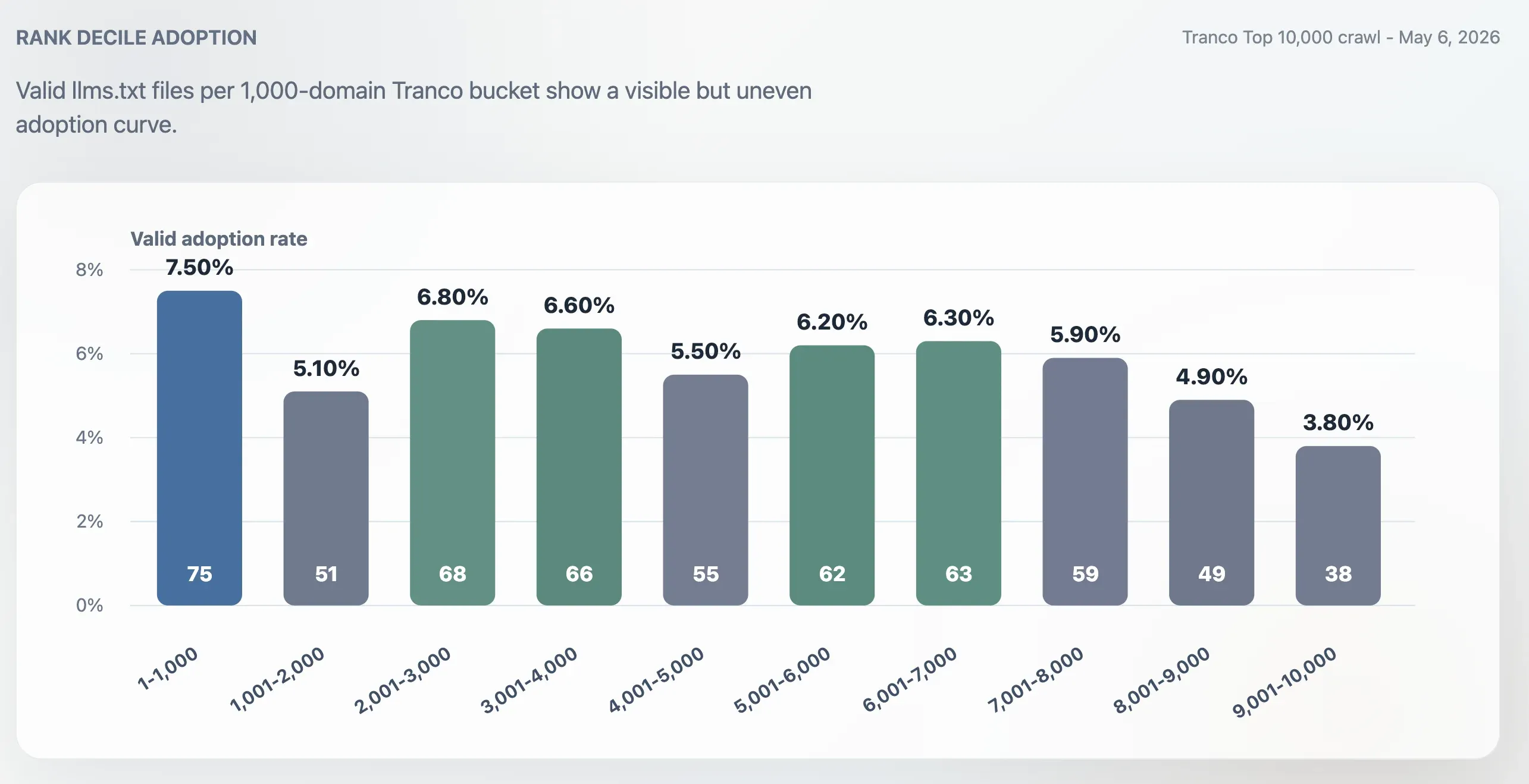
La differenza nei risultati è notevole: questo studio ha trovato 75 file llms.txt validi nel Tranco Top 1.000 il 6 maggio 2026, pari al 7,50%. I due numeri non vanno trattati come una serie temporale rigorosa perché la fonte di ranking, i dettagli di implementazione, la logica di validazione e il timing del crawling possono differire. Tuttavia, il contrasto suggerisce che l’adozione sia cambiata in modo sostanziale tra metà 2025 e maggio 2026, soprattutto tra siti developer, SaaS, cloud, security e ricchi di documentazione.
| Fonte | Snapshot | Campione | Adozione valida riportata | Interpretazione |
|---|---|---|---|---|
| Rankability | 22 giugno 2025 | Top 1.000 siti web | 0,3% | Primo benchmark pubblico che mostra un’adozione minima a metà 2025. |
| Questo studio | 6 maggio 2026 | Tranco Top 1.000 | 7,50% | Crawling successivo che mostra un’adozione visibile tra i siti ad alto traffico. |
| Questo studio | 6 maggio 2026 | Tranco Top 10.000 | 5,86% | Campione più ampio che mostra che l’adozione è misurabile ma non ancora mainstream. |
Gli esperimenti sul traffico restano misti
ha pubblicato nel gennaio 2026 un’analisi su 10 siti che li ha seguiti per 90 giorni prima e 90 giorni dopo l’implementazione. L’articolo riportava che due siti hanno visto aumenti del traffico IA del 12,5% e del 25%, otto non hanno mostrato miglioramenti misurabili e uno è sceso del 19,7%. La sua interpretazione chiave era la cautela causale: i due casi di successo apparente avevano anche lanciato nuovi template, ricostruito centri risorse, aggiunto tabelle di confronto estraibili, ottenuto copertura stampa, risolto problemi tecnici o pubblicato nuovi contenuti in stile FAQ. In questa lettura, llms.txt documentava un lavoro migliore sui contenuti e sulla tecnica; non sembrava aver causato da solo la crescita.
L’esperimento del blog personale di è arrivato a una conclusione più positiva da un’osservazione su scala più piccola. Ha confrontato due periodi di quattro mesi in Yandex.Metrica dopo l’aggiunta di llms.txt e llms-full.txt. Le sessioni di referral da LLM sono passate da 75 a 92, con un aumento del 23%, mentre gli utenti sono saliti da 51 a 64. Le sessioni da Perplexity sono aumentate da 29 a 55, mentre quelle da ChatGPT sono scese da 31 a 26. Lo stesso post osserva anche che il traffico referral totale è cresciuto più rapidamente, da 160 a 290 sessioni, quindi la quota di sessioni LLM è scesa dal 47% al 32%.
| Tipo di evidenza | Risultato osservato | Principale limite | Impatto su questo report |
|---|---|---|---|
| Studio pre/post su 10 siti di Search Engine Land | Due siti sono cresciuti, otto non hanno mostrato cambiamenti misurabili, uno è calato. | I casi positivi avevano anche cambiamenti paralleli di contenuto, PR e aspetti tecnici. | Supporta l’idea di trattare llms.txt come infrastruttura, non come leva di crescita autonoma. |
| Osservazione pre/post del blog personale di Alimbekov | Le sessioni di referral da LLM sono aumentate del 23% nel periodo successivo. | Nessun gruppo di controllo; il traffico referral totale è aumentato dell’81% e la quota LLM è scesa. | Suggerisce un possibile vantaggio per i blog tecnici, soprattutto tramite Perplexity, ma la causalità non è isolata. |
| Questo studio di adozione basato sul crawling | 586 file validi e molte implementazioni strutturate. | Misura presenza e struttura, non l’impatto downstream sul traffico. | Mostra adozione e maturità di implementazione, ma non l’ROI da solo. |
Cosa chiarisce il dibattito
Le evidenze esterne rafforzano l’interpretazione di questo dataset. Un file llms.txt ben strutturato può ridurre l’attrito di parsing per le macchine, soprattutto per documentazione developer, riferimenti API e contenuti di knowledge base. Ma i casi di traffico più forti sembrano dipendere ancora da contenuti utili, estraibili, autorevoli e scopribili anche al di fuori del file. Per questo motivo, la domanda pratica non è “llms.txt conta?”, presa isolatamente. È se il file faccia parte di un sistema più ampio di contenuti leggibili dall’IA.
Interpretazione aggiornata:
llms.txtdovrebbe essere implementato come infrastruttura a basso costo rivolta all’IA. Non va presentato come sostituto di una documentazione migliore, di contenuti strutturati, accessibilità tecnica, citazioni, link o autorevolezza del brand.
Metodologia
Questo studio ha usato come campione i 10.000 domini del Tranco. Tranco è un ranking dei siti top orientato alla ricerca, progettato per essere più stabile e resistente alle manipolazioni rispetto a molte liste top tradizionali. Il file sorgente di Tranco è stato scaricato il 6 maggio 2026, con un timestamp Last-Modified del 5 maggio 2026 alle 22:17:59 GMT.
Il crawler ha verificato due percorsi a livello root per ogni dominio:
https://example.com/llms.txt, con fallback HTTP quando necessario.https://example.com/llms-full.txt, con fallback HTTP quando necessario.
Per ogni verifica, il crawler ha registrato codice di stato, URL finale, metodo di fetch, byte della risposta, content type, messaggio di errore, tempo trascorso ed esito della validazione. I body delle risposte andate a buon fine sono stati salvati in raw_llms_txt/ per la revisione e l’analisi secondaria.
Regole di validazione
Una risposta veniva conteggiata come file valido solo se restituiva un body valido e non sembrava un fallback web generico. Il percorso dell’URL finale doveva rimanere /llms.txt o /llms-full.txt. I body vuoti venivano respinti. I documenti HTML evidenti e gli app shell venivano respinti. Il content type era considerato una prova di supporto, non l’unica regola, perché un piccolo numero di file testuali validi veniva servito con content type insoliti.
Panorama dell’adozione
Il crawling ha trovato 586 file llms.txt validi nel Tranco Top 10.000. Questo corrisponde a un tasso di adozione valido del 5,86%. Il file complementare più קטן llms-full.txt era presente e valido su 103 domini, pari all’1,03% del campione.
| Metrica | Conteggio | Quota del Top 10.000 |
|---|---|---|
| Domini sottoposti a crawling | 10.000 | 100,00% |
| File llms.txt validi | 586 | 5,86% |
| File llms-full.txt validi | 103 | 1,03% |
| Risposte HTTP 200 per /llms.txt | 1.606 | 16,06% |
| Risposte HTTP 200 respinte come non valide | 1.020 | 10,20% |
L’adozione non è solo concentrata in alto
L’adozione era più alta nel Top 1.000 rispetto all’intero Top 10.000, ma non era limitata ai siti più grandi in assoluto. Il tasso di adozione nel Top 1.000 era del 7,50%. L’ultimo blocco di 1.000 domini, dal ranking 9.001 al 10.000, scendeva al 3,80%. La parte centrale della classifica restava attiva: i blocchi 2.001-3.000, 3.001-4.000, 5.001-6.000 e 6.001-7.000 si collocavano tutti intorno al 6%.
Primi adottanti
Il miglior adottante valido in classifica era Cloudflare al rank Tranco 4. Altri adottanti ad alto ranking includevano Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink e OneSignal.
Questi adottanti non sono casuali. Tendono ad avere grandi superfici di documentazione, linee di prodotto che richiedono spiegazione, API o ecosistemi developer, contenuti di supporto, pagine di pricing, materiale su sicurezza e privacy, e abbastanza autorevolezza del brand da tenere a come i sistemi IA interpretano i loro siti.
| Rank | Dominio | Dimensione del file | Pattern osservato |
|---|---|---|---|
| 4 | cloudflare.com | 4.225 B | Indice compatto di prodotto, developer, azienda e pricing. |
| 26 | azure.com | 47.037 B | Strumenti per developer, IA, compute, storage, sicurezza, monitoraggio e risorse opzionali. |
| 28 | github.com | 27.108 B | Accesso programmatico, Copilot, MCP, API REST, Actions, repository e link CLI. |
| 248 | stripe.com | 64.229 B | Pagamenti, Connect, Checkout, Billing, Tax, Atlas, Radar e documentazione developer. |
| 265 | salesforce.com | 1,02 MB | Enorme catalogo di link di prodotto e Agentforce, senza intestazioni di sezione Markdown. |
Categorie degli adottanti nel Top 1.000
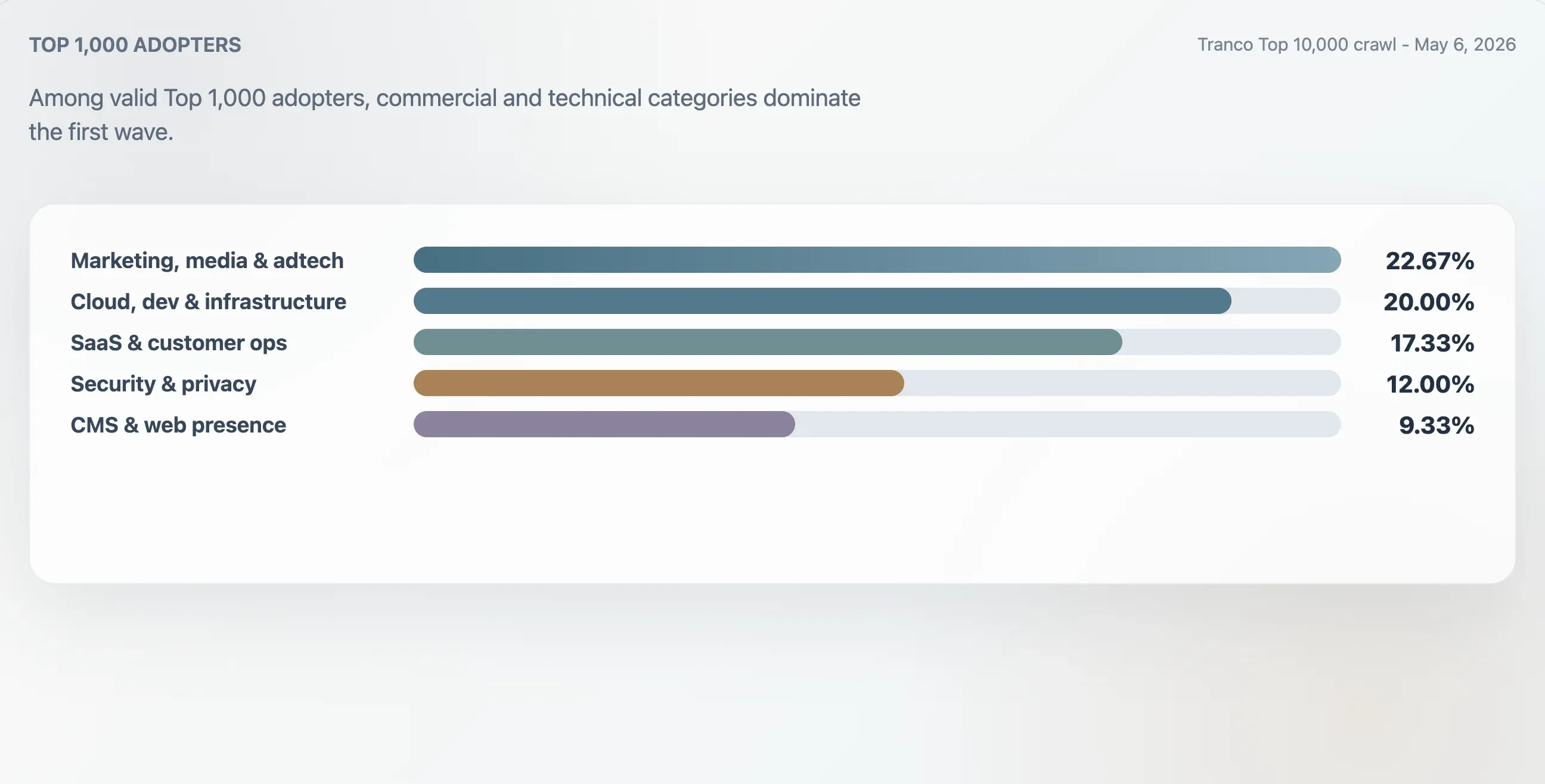
Questo studio ha classificato i 75 adottanti validi nel Tranco Top 1.000 usando il contesto del dominio, le prime intestazioni, la struttura grezza del file e le parole chiave del contenuto. Il gruppo più ampio era marketing, media e adtech con il 22,67%. I siti cloud, developer e infrastruttura rappresentavano il 20,00%. I siti SaaS, produttività e customer operations il 17,33%. I siti security, identity e privacy il 12,00%.
| Categoria | Domini | Quota degli adottanti del Top 1.000 | Punteggio mediano di qualità | Link mediani |
|---|---|---|---|---|
| Marketing, media e adtech | 17 | 22,67% | 94 | 25 |
| Cloud, dev e infrastruttura | 15 | 20,00% | 94 | 62 |
| SaaS, produttività e customer ops | 13 | 17,33% | 94 | 46 |
| Sicurezza, identità e privacy | 9 | 12,00% | 98 | 78 |
| CMS, hosting e presenza web | 7 | 9,33% | 100 | 24 |
Pattern dei TLD
I domini di primo livello non sono etichette di settore, ma sono segnali direzionali utili. Tra i TLD con almeno 50 domini nel campione, .io aveva il tasso di adozione valido più alto, al 14,44%. Seguiva .com con l’8,19%. L’adozione più bassa tra .gov, .edu e .net suggerisce che la base dei primi adottanti sia più commerciale e tecnica che istituzionale.
Qualità dell’implementazione
L’adozione valida non significa qualità di implementazione uniforme. Alcuni file sono indici concisi e ben sezionati. Alcuni sono soprattutto testo narrativo. Alcuni sono cataloghi di link grezzi. Alcuni sono segnaposto quasi vuoti. Alcuni sono dump di contenuti di dimensioni multi-megabyte che possono essere completi ma costosi da recuperare e analizzare.
Tra i file llms.txt validi, 362 erano più grandi di 5 KB, pari al 61,77% degli adottanti validi. La dimensione mediana del file era di circa 7,1 KB. La dimensione P90 era 156 KB, la P95 356 KB, la P99 2,54 MB e il file più grande osservato 7,97 MB.
Segnali di contenuto comuni
Una scansione a livello di keyword dei file validi ha mostrato che molti siti non stanno semplicemente pubblicando una dichiarazione; stanno indirizzando i modelli verso materiale operativamente utile. Termini relativi a supporto o help comparivano nel 70,31% dei file validi. Blog, guide o tutorial nel 67,92%. Sicurezza, privacy, compliance o termini nel 61,43%. Pricing nel 53,92%, documentazione nel 52,22%, API nel 33,96% e segnali di changelog o release nel 27,30%.
Punteggio di qualità e archetipi
Per passare dalla presenza alla maturità, questo studio ha creato un punteggio leggero di implementazione. Il punteggio considera tipo di contenuto, dimensione del file, struttura Markdown, numero di link, copertura dei topic e segnali di allarme come intestazioni mancanti, assenza di link Markdown, content type insoliti, file minuscoli, file molto grandi e comportamento da dump di link. Non è uno standard formale. È un modello di punteggio di ricerca per confrontare le implementazioni osservate.
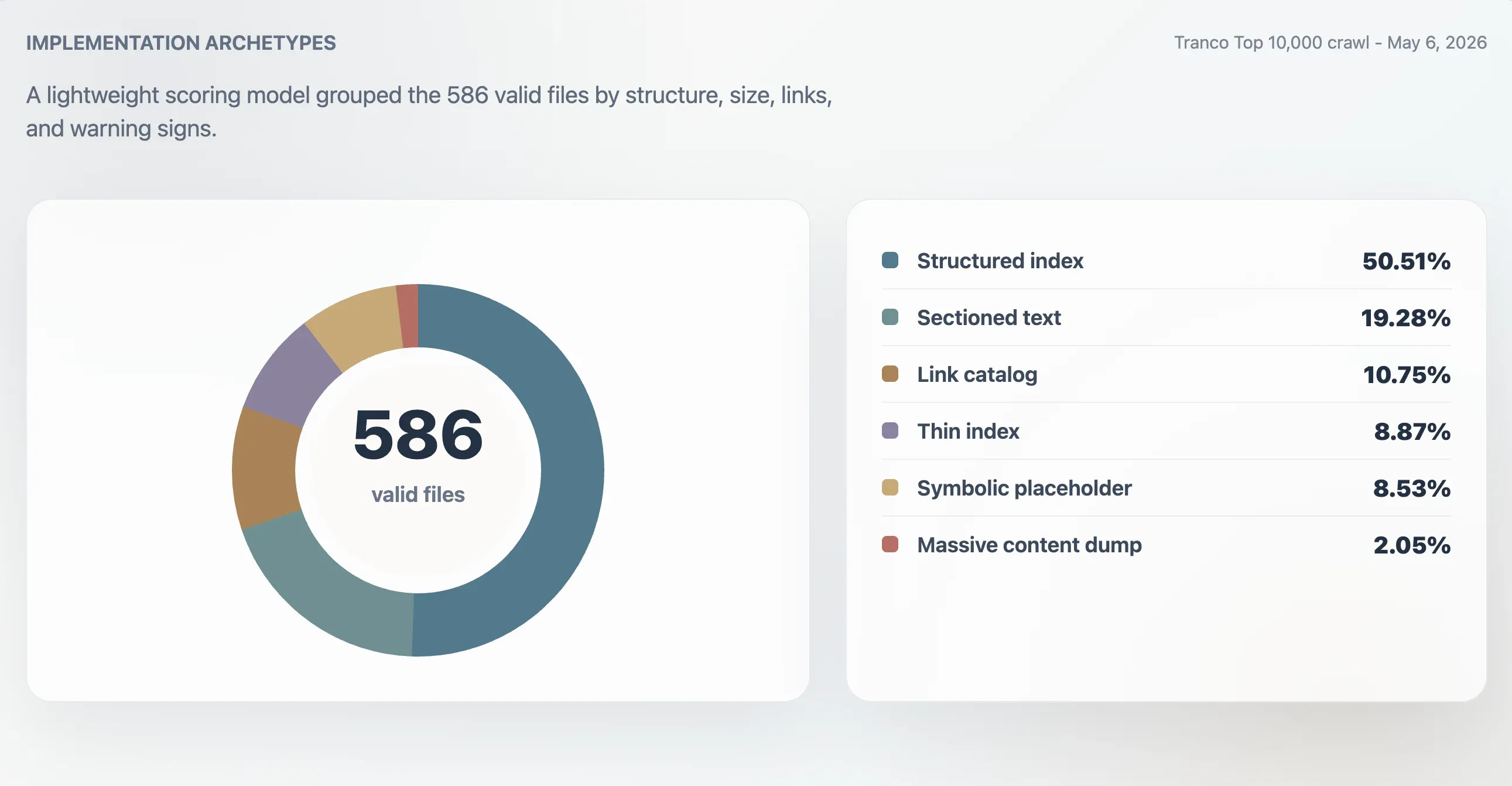
Usando questo modello, 416 file validi sono stati classificati come forti indici strutturati, 107 come indici utilizzabili, 24 come sottili o irregolari e 39 come simbolici o a bassa utilità. Un’analisi separata per archetipi ha trovato 296 indici strutturati, 113 file di testo sezionati, 63 cataloghi di link, 52 indici sottili, 50 file simbolici o segnaposto e 12 dump di contenuti massivi.
| Archetipo | Domini | Quota dei file validi | Punteggio mediano | Dimensione mediana del file | Link mediani |
|---|---|---|---|---|---|
| Indice strutturato | 296 | 50,51% | 98 | 11.241 B | 61,5 |
| Testo sezionato | 113 | 19,28% | 78 | 4.718 B | 0 |
| Catalogo di link | 63 | 10,75% | 86 | 4.160 B | 23 |
| Indice sottile | 52 | 8,87% | 66 | 2.814 B | 0 |
| Simbolico o segnaposto | 50 | 8,53% | 27 | 15 B | 0 |
| Dump di contenuti massivi | 12 | 2,05% | 74 | 2,84 MB | 7.259,5 |
I principali adottanti hanno implementazioni più dense
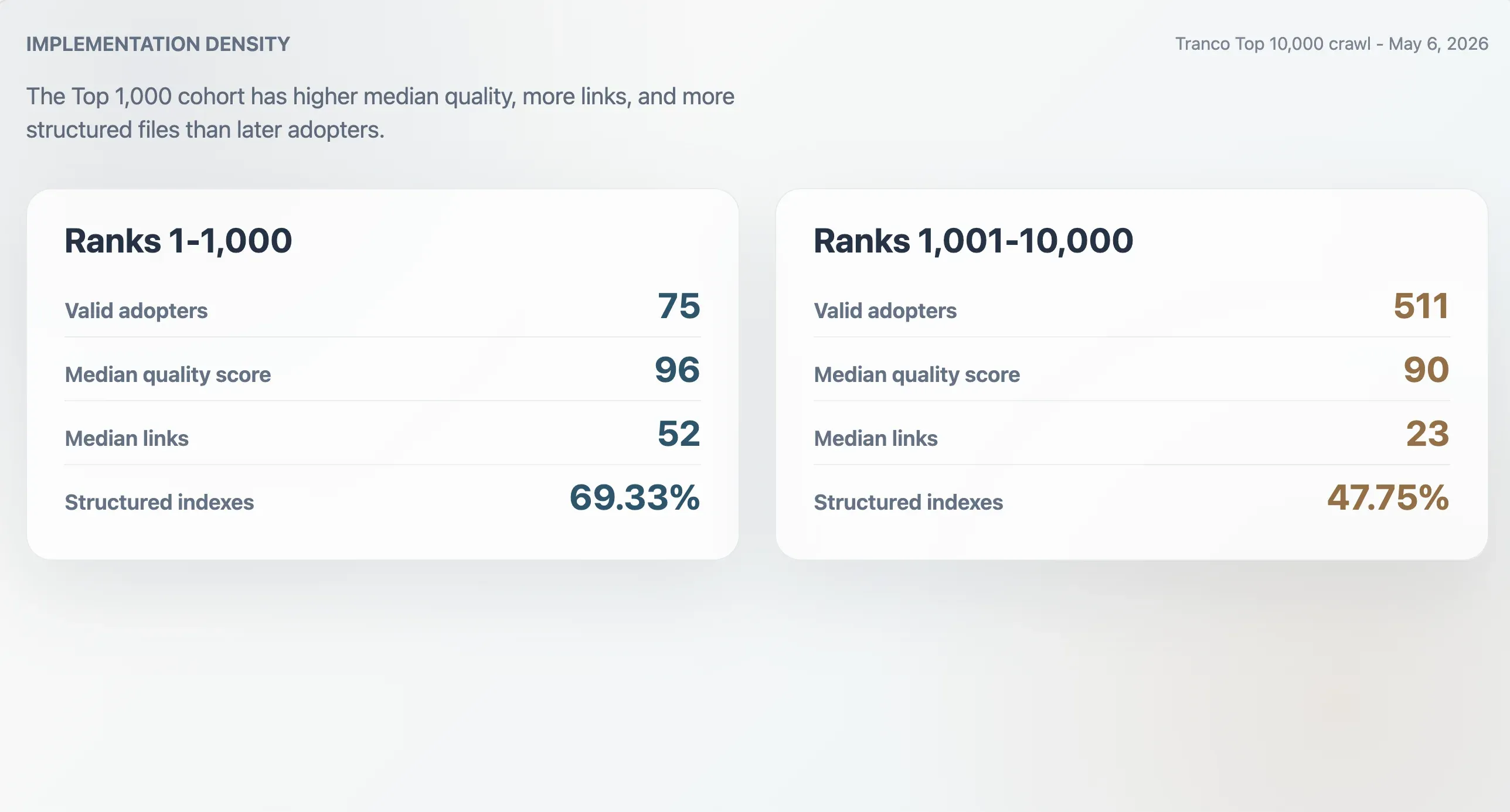
I 75 adottanti validi nel Tranco Top 1.000 avevano un punteggio di qualità mediano di 96, una dimensione mediana del file di 9.068 byte, un numero mediano di link Markdown di 52 e un numero mediano di sezioni di 11. I 511 adottanti classificati tra 1.001 e 10.000 avevano mediane inferiori: punteggio 90, dimensione del file 6.506 byte, 23 link Markdown e 9 sezioni. Gli adottanti del Top 1.000 erano anche più spesso indici strutturati: 69,33% contro 47,75% nella coorte successiva.
Il problema dei falsi positivi

Il rischio di misurazione più grande è quello dei falsi positivi. Dei 1.606 domini che hanno restituito HTTP 200 per /llms.txt, 1.020 non hanno superato la validazione. La ragione di invalidità più comune era il redirect fuori bersaglio, con 618 casi. Altre 367 risposte erano documenti HTML generici. Ventinove restituivano un body vuoto e sei erano altre risposte non valide o non classificate.
Questo conta perché molti siti grandi instradano i percorsi sconosciuti verso pagine di login, home page, app shell, pagine regionali, superfici di consenso o fallback di marketing. Queste risposte possono sembrare sane a un crawler basato sul codice di stato, ma non contengono alcun segnale valido di llms.txt.
llms-full.txt: più raro e più irregolare
Il file complementare llms-full.txt era molto meno comune di llms.txt. Il crawling ha trovato 103 file full validi, pari al 17,58% degli adottanti validi di llms.txt e all’1,03% dell’intero campione Top 10.000.
Le implementazioni del file full erano irregolari. Tra i 103 adottanti con entrambi i file, 57 avevano un llms-full.txt più grande del file index, ma 46 avevano un file full non più grande dell’index oppure un file full sotto i 100 byte. Il rapporto mediano tra full e index era 1,43, ma i casi estremi erano molto più alti. Il file full di Supabase era circa 7.139 volte la dimensione del file index. Made-in-China.com aveva un file full da 89,89 MB.
| Dominio | llms.txt | llms-full.txt | Rapporto |
|---|---|---|---|
| made-in-china.com | 4,49 MB | 89,89 MB | 20,0x |
| sendbird.com | 281,86 KB | 11,99 MB | 42,5x |
| taboola.com | 286,78 KB | 11,73 MB | 40,9x |
| supabase.co | 1,26 KB | 8,98 MB | 7.139,3x |
| neon.tech | 27,44 KB | 5,01 MB | 182,7x |
Raccomandazione: pubblica
llms-full.txtsolo quando il sito ha già una pipeline di documentazione stabile, disciplina di versioning e un motivo chiaro per esporre grandi volumi di contenuti in un unico file leggibile dalle macchine.
llms.txt, robots.txt e sitemap.xml
llms.txt non va trattato come un nuovo robots.txt. Entrambi sono file leggibili dalle macchine a livello root, ma comunicano cose diverse. robots.txt è un segnale di preferenze dei crawler e di controllo degli accessi. sitemap.xml è un segnale di scoperta degli URL. llms.txt è un segnale esplicativo e di navigazione.
| Segnale | Ruolo principale | Lettore tipico | Interpretazione in questo studio |
|---|---|---|---|
robots.txt | Dichiarare le preferenze dei crawler e le restrizioni a livello di percorso. | Crawler di ricerca, crawler IA, crawler di archiviazione, bot generici. | Segnale di governance e accesso. |
sitemap.xml | Elencare gli URL scopribili per i sistemi di indicizzazione. | Motori di ricerca e pipeline di indicizzazione. | Segnale di scoperta. |
llms.txt | Fornire contesto compatto sul sito, link importanti, documentazione, API, esempi e riferimenti alle policy. | Applicazioni LLM, agenti IA, strumenti developer, sistemi di retrieval. | Segnale di spiegazione e navigazione. |
Raccomandazioni
Per i siti che stanno valutando llms.txt, le implementazioni più solide in questo dataset e le evidenze esterne sul traffico suggeriscono un approccio pragmatico:
- Pubblica
/llms.txtnella root e rendilo accessibile senza login, esecuzione JavaScript, barriere di consenso o redirect fuori percorso. - Se possibile, servilo come
text/plainotext/markdown. - Inizia con una breve descrizione del sito, poi raggruppa i link per prodotto, documentazione, API, pricing, changelog, esempi, supporto, policy e risorse aziendali.
- Preferisci link canonici a elenchi esaustivi di URL.
- Evita file simbolici vuoti; al massimo sono un segnale debole.
- Evita dump massivi e non differenziati, a meno che non ci sia un forte caso d’uso per il consumo automatico e una pipeline di generazione affidabile.
- Dopo la pubblicazione, valida URL finale, body della risposta, content type, struttura Markdown, numero di link e dimensione del file.
I team dovrebbero anche impostare aspettative realistiche. Gli esperimenti pubblici disponibili non dimostrano che llms.txt aumenti in modo indipendente il traffico referral da IA. Se un team vuole testare l’impatto di business, dovrebbe tracciare insieme referral LLM, pagine citate, richieste bot, freschezza dell’indicizzazione e cambiamenti di contenuto. Un esperimento utile confronterebbe gruppi di pagine abbinati, manterrebbe costanti gli aggiornamenti di contenuto quando possibile e separerebbe il traffico specifico delle piattaforme come Perplexity, ChatGPT, Gemini, Claude e Bing/Copilot.
Limiti
Questo è uno snapshot basato sul crawling, non una verità assoluta permanente. I siti web possono aggiungere, rimuovere o modificare i file llms.txt in qualsiasi momento. Alcuni domini possono bloccare le richieste automatizzate o comportarsi in modo diverso in base a geografia, configurazione TLS, logica di redirect, user agent o mitigazione bot. Lo studio ha testato solo i file a livello root e non ha cercato sotto-domini o percorsi non standard.
Il punteggio di qualità e gli archetipi sono strumenti di ricerca, non etichette ufficiali di conformità. L’analisi dei topic è basata su keyword e va letta come indicativa. Lo studio non dimostra che una specifica piattaforma IA legga, rispetti o usi attualmente llms.txt in produzione.
Anche le evidenze esterne sul traffico esaminate in questa versione hanno limiti. L’analisi di Search Engine Land è più forte come osservazione cautelativa multi-sito che come esperimento randomizzato. Il risultato di Alimbekov è utile come case study trasparente a livello di sito, ma manca di un gruppo di controllo e include un periodo in cui il traffico referral totale è aumentato in modo sostanziale. Questi riferimenti aiutano a inquadrare il dibattito, ma non trasformano questo crawling in uno studio causale sul traffico.
File e riproducibilità
| File | Scopo |
|---|---|
crawl_llms_txt.py | Crawler per /llms.txt e /llms-full.txt. |
analyze_llms_txt.py | Analisi primaria dell’adozione e generazione dei grafici. |
deep_analyze_llms_txt.py | Analisi secondaria per decili di ranking, TLD, segnali tematici, punteggi di qualità, archetipi e comportamento dei due file. |
deep_dive_early_quality.py | Classificazione dei primi adottanti e approfondimento sulla qualità di implementazione. |
data/llms_probe_results_top_10000.csv | Dataset principale dei risultati del crawling. |
data/deep_analysis_top_10000.json | Sintesi dell’analisi secondaria. |
data/deep_early_quality_analysis.json | Categorie dei primi अपनanti, confronto tra coorti di qualità, dettagli sugli archetipi e case study. |
Fonti
- , Jeremy Howard, 2024.
- .
- .
- .
- , Data Provenance Initiative.
- .
- , Search Engine Land, gennaio 2026.
- , Rankability, giugno 2025.
- , Renat Alimbekov.
Correzioni alla metodologia, problemi del dataset e analisi di follow-up sono benvenuti all’indirizzo support@thunderbit.com. Questo report è pubblicato indipendentemente da qualsiasi posizione commerciale detenuta da Thunderbit. I dati di questo report valgono per sé stessi. — Il team di ricerca Thunderbit, maggio 2026.