

Il web nel 2025 è un posto selvaggio: metà del traffico che vedi non è nemmeno umano. Esatto: bot e crawler oggi rappresentano oltre il 50% di tutta l’attività su internet (Thales Group), e solo una piccola parte di questi sono i “buoni” bot che vuoi davvero: motori di ricerca, anteprime per i social e strumenti di analytics. Gli altri? Diciamo solo che non sono sempre lì per darti una mano. Dopo anni passati a costruire strumenti di automazione e AI in Thunderbit, ho visto con i miei occhi come il crawler giusto — o quello sbagliato — possa fare la differenza per il tuo SEO, falsare le analytics, consumare banda o persino innescare un vero e proprio incidente di sicurezza.
Se gestisci un’azienda, un sito web o stai semplicemente cercando di tenere in ordine la tua presenza digitale, sapere chi sta bussando alla porta del tuo server è più importante che mai. Per questo ho preparato questa guida 2025 ai crawler più importanti: cosa fanno, come riconoscerli e come mantenere il tuo sito aperto ai bot buoni tenendo fuori quelli cattivi.
Cosa rende un crawler “noto”? User-Agent, IP e verifica
Partiamo dalle basi: cos’è esattamente un crawler “noto”? In parole semplici, è un bot che si identifica con una stringa user-agent coerente (come Googlebot/2.1 o bingbot/2.0) e, idealmente, esegue la scansione da intervalli IP pubblicati o da blocchi ASN che puoi verificare (verifica di Googlebot). I grandi player — Google, Microsoft, Baidu, Yandex, DuckDuckGo — pubblicano documentazione sui propri bot e, in molti casi, mettono a disposizione strumenti o file JSON con i loro IP ufficiali (lista IP di Googlebot, lista IP di Bingbot, IP di DuckDuckBot).
Ma c’è un problema: affidarsi solo allo user-agent è rischioso. Lo spoofing è diffusissimo: bot malevoli spesso fingono di essere Googlebot o Bingbot per aggirare le difese (SecurityWeek). Ecco perché lo standard migliore è la doppia verifica: controlla sia lo user-agent sia l’indirizzo IP (o l’ASN), usando reverse DNS lookup o liste pubblicate. Se usi uno strumento come Thunderbit, puoi automatizzare tutto il processo: estrarre i log, confrontare gli user-agent e incrociare gli IP per costruire una lista affidabile e in tempo reale di chi sta scansionando il tuo sito.
Come usare questo elenco di crawler
Quindi, cosa fai concretamente con un elenco di crawler noti? Ecco come ti consiglio di usarlo:
- Allowlist: assicurati che i bot che desideri (motori di ricerca, anteprime social) non vengano mai bloccati per errore da firewall, CDN o WAF. Usa i loro IP e user-agent ufficiali per una allowlist precisa.
- Filtraggio analytics: escludi il traffico bot dalle analytics, così i numeri riflettono visitatori umani reali e non solo Googlebot e AhrefsBot che girano in tondo sul tuo sito (SecurityWeek).
- Gestione dei bot: imposta regole di crawl-delay o throttling per gli strumenti SEO più aggressivi e blocca o sfida i bot sconosciuti o malevoli.
- Analisi automatica dei log: usa strumenti AI (come Thunderbit) per estrarre, classificare ed etichettare l’attività dei crawler nei log, così puoi individuare trend, identificare impostori e mantenere aggiornate le tue policy.
Mantenere aggiornata la lista dei crawler non è un’attività da fare “una volta e basta”. Nascono nuovi bot, quelli vecchi cambiano comportamento e gli attaccanti diventano ogni anno più astuti. Automatizzare gli aggiornamenti — ad esempio estraendo la documentazione ufficiale o i repository GitHub con Thunderbit — può farti risparmiare ore e grattacapi.
1. Thunderbit: identificazione dei crawler e gestione dei dati con AI
Gestione dei crawler con AI grazie a Thunderbit Get Started Free
Thunderbit non è solo un AI Web Scraper: è un assistente dati per i team che vogliono capire e gestire il traffico dei crawler. Ecco cosa rende Thunderbit diverso:

- Pre-elaborazione semantica: prima di estrarre i dati, Thunderbit converte pagine web e log in contenuti strutturati in stile Markdown. Questa pre-elaborazione “a livello semantico” permette all’AI di capire davvero contesto, campi e logica di ciò che sta leggendo. È una salvezza per pagine complesse, dinamiche o pesanti di JavaScript (pensa a Facebook Marketplace o a thread di commenti lunghi) dove gli scraper tradizionali basati sul DOM falliscono.
- Doppia verifica: Thunderbit può raccogliere rapidamente la documentazione ufficiale sugli IP dei crawler e gli elenchi ASN, quindi confrontarli con i log del server. Il risultato? Un “allowlist di crawler attendibili” su cui puoi davvero contare — niente più controlli manuali incrociati.
- Estrazione automatica dei log: fornisci a Thunderbit i tuoi log grezzi e lui li trasforma in tabelle strutturate (Excel, Sheets, Airtable), etichettando visitatori frequenti, percorsi sospetti e bot noti. Da lì, puoi inviare i risultati al tuo WAF o CDN per blocchi automatici, throttling o challenge CAPTCHA.
- Compliance e audit: l’estrazione semantica di Thunderbit mantiene una traccia di audit chiara — chi ha accesso a cosa, quando e come è stato gestito. Un enorme vantaggio per GDPR, CCPA e altri requisiti di conformità.
Ho visto team usare Thunderbit per ridurre dell’80% il carico di lavoro nella gestione dei crawler — e finalmente capire quali bot aiutano, quali danneggiano e quali stanno solo fingendo.
Prova Thunderbit per la gestione dei crawler
2. Googlebot: lo standard dei motori di ricerca
Googlebot è il riferimento assoluto per i crawler web. È responsabile dell’indicizzazione del tuo sito su Google Search: se lo blocchi, è come appendere un cartello “Chiuso” alla vetrina del tuo negozio digitale.
- User-Agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Verifica: usa il metodo DNS inverso di Google o la lista IP ufficiale.
- Consigli di gestione: consenti sempre Googlebot. Usa robots.txt per guidarne la scansione, non per bloccarla, e se necessario regola il crawl rate in Google Search Console.
3. Bingbot: il crawler web di Microsoft
Bingbot alimenta i risultati di ricerca di Bing e Yahoo. Per la maggior parte dei siti è il secondo crawler più importante.
- User-Agent:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Verifica: usa lo strumento di verifica di Microsoft e la lista IP ufficiale.
- Consigli di gestione: consenti Bingbot, gestisci il crawl rate in Bing Webmaster Tools e usa robots.txt per rifinire il comportamento.
4. Baiduspider: il principale crawler di ricerca in Cina
Baiduspider è la porta d’accesso al traffico di ricerca cinese.
- User-Agent:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - Verifica: non esiste una lista IP ufficiale; controlla
.baidu.comnel reverse DNS, ma tieni presenti i limiti di questo metodo. - Consigli di gestione: consentilo se vuoi traffico dalla Cina. Usa robots.txt per impostare regole, ma sappi che Baiduspider a volte le ignora. Se non ti serve il SEO cinese, valuta di limitare o bloccare il traffico per risparmiare banda.
5. YandexBot: il crawler del motore di ricerca russo
YandexBot è essenziale per i mercati russo e CIS.
- User-Agent:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - Verifica: il reverse DNS dovrebbe terminare in
.yandex.ru,.yandex.neto.yandex.com. - Consigli di gestione: consentilo se punti a utenti di lingua russa. Usa Yandex Webmaster per controllare la scansione.
6. DuckDuckBot: crawler di ricerca orientato alla privacy
DuckDuckBot alimenta la ricerca di DuckDuckGo, centrata sulla privacy.
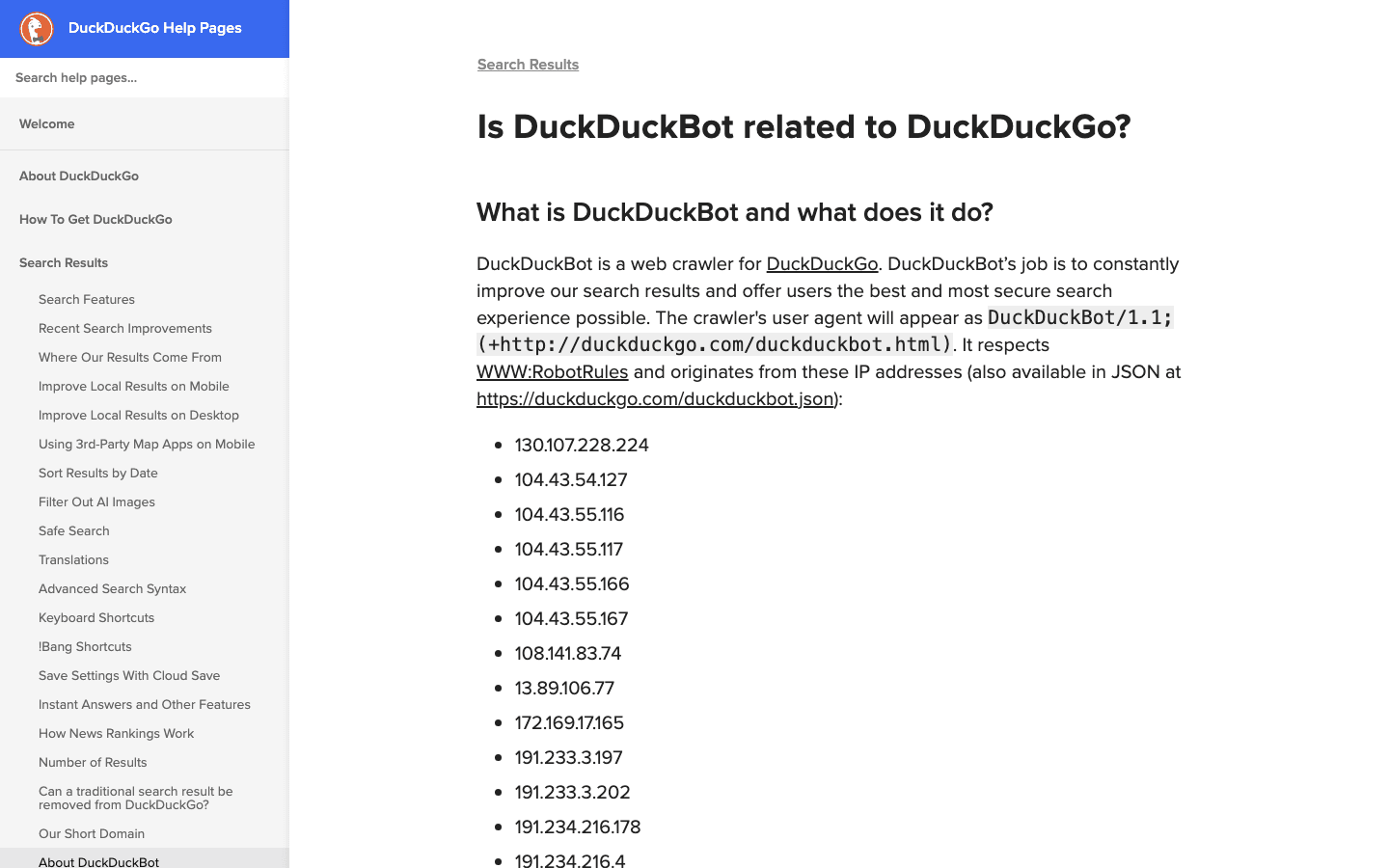
- User-Agent:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - Verifica: lista IP ufficiale (JSON).
- Consigli di gestione: consentilo, a meno che non ti interessino proprio per nulla gli utenti attenti alla privacy. Ha un carico di scansione basso ed è facile da gestire.
7. AhrefsBot: analisi SEO e backlink
AhrefsBot è un crawler di riferimento per gli strumenti SEO: ottimo per l’analisi dei backlink, ma può consumare molta banda.
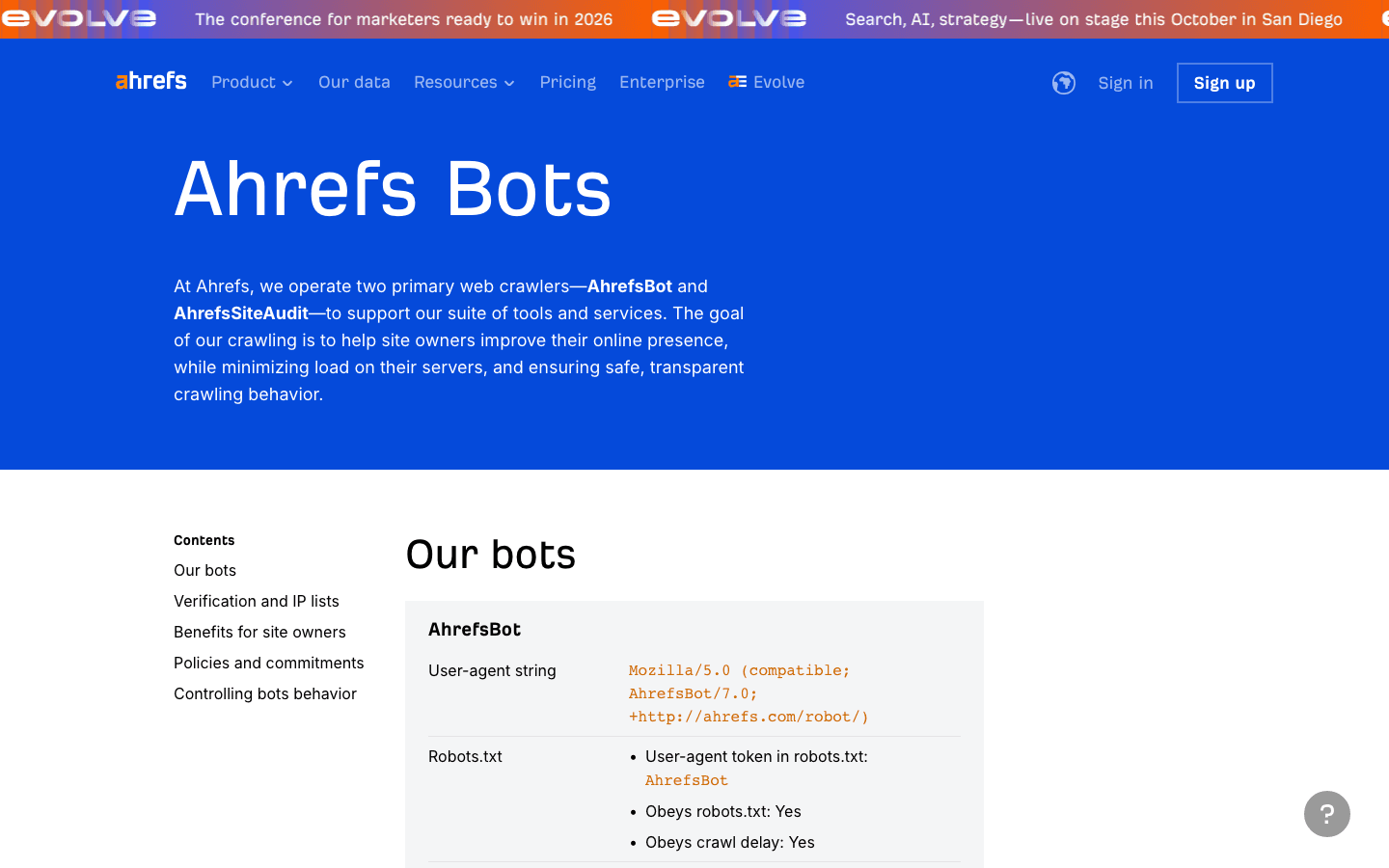
- User-Agent:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - Verifica: non esiste una lista IP pubblica; verifica tramite user-agent e reverse DNS.
- Consigli di gestione: consentilo se usi Ahrefs. Usa robots.txt per impostare crawl-delay o blocchi. Puoi disattivarlo via email.
8. SemrushBot: insight SEO competitivi
SemrushBot è un altro crawler SEO importante.
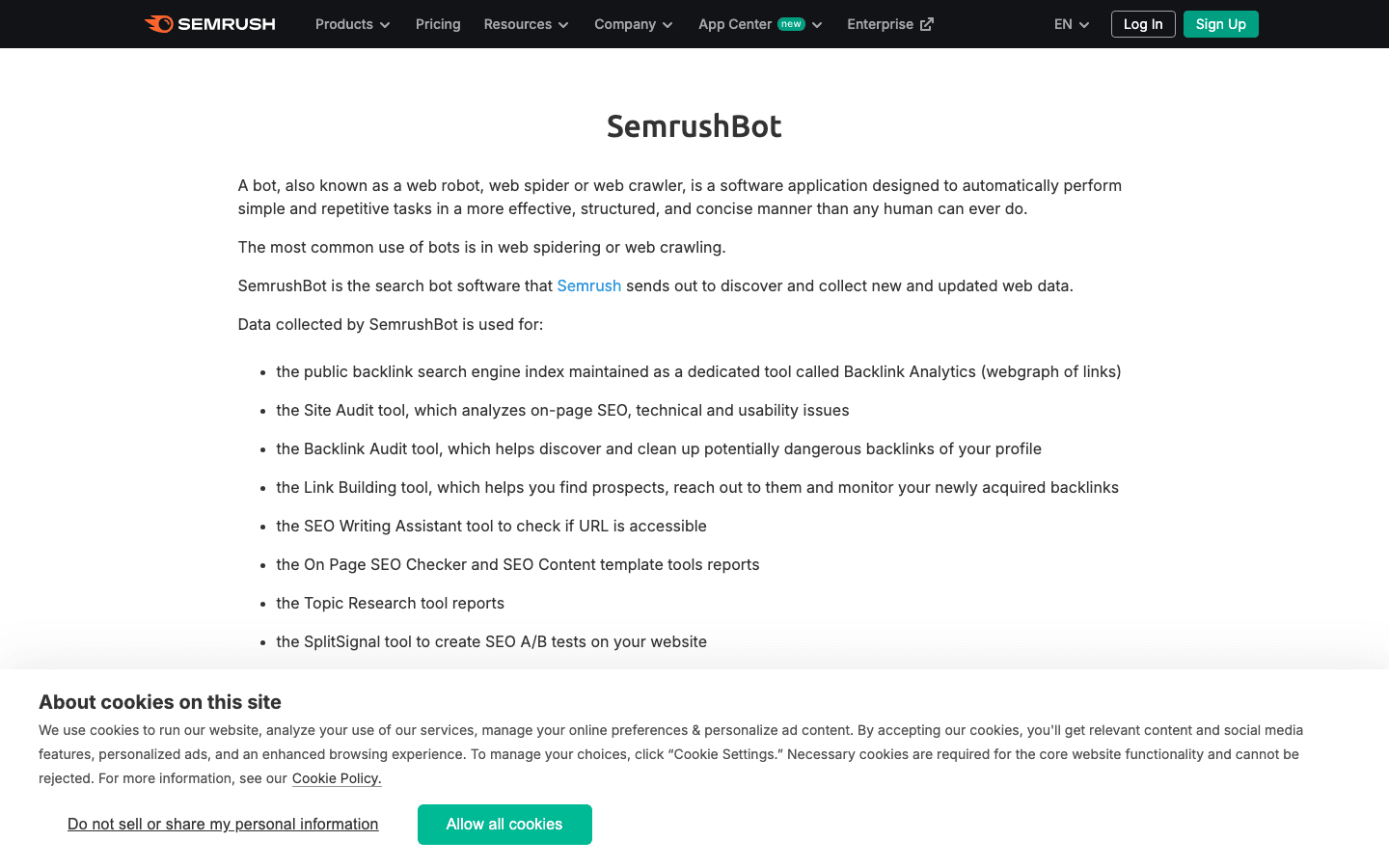
- User-Agent:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(più varianti comeSemrushBot-BA,SemrushBot-SI, ecc.) - Verifica: tramite user-agent; non esiste una lista IP pubblica.
- Consigli di gestione: consentilo se usi Semrush, altrimenti limita o blocca con robots.txt o con regole lato server.
9. FacebookExternalHit: bot per le anteprime social
FacebookExternalHit recupera i dati Open Graph per le anteprime dei link su Facebook e Instagram.
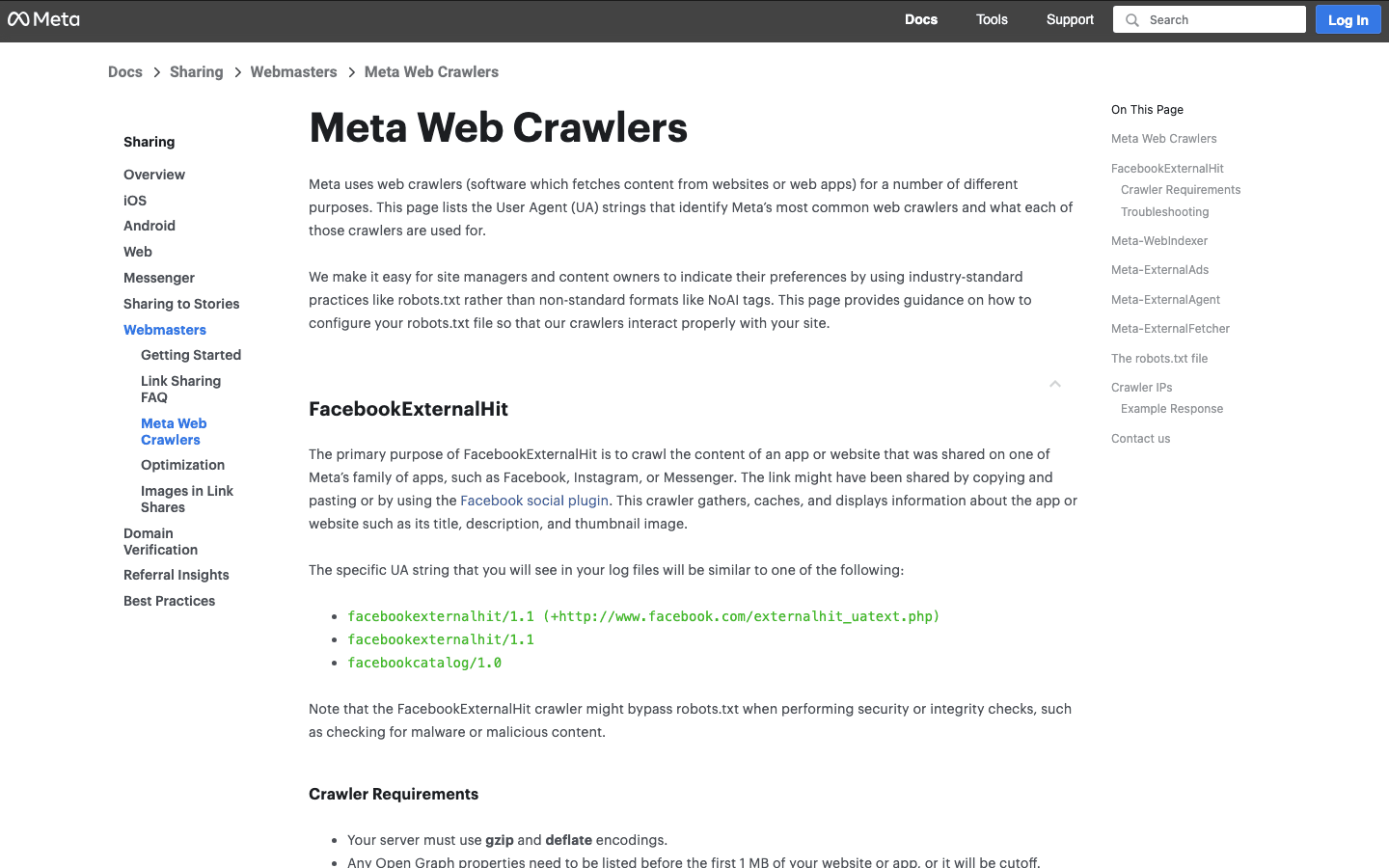
- User-Agent:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - Verifica: tramite user-agent; gli IP appartengono all’ASN di Facebook.
- Consigli di gestione: consentilo per anteprime social più ricche. Bloccarlo significa niente miniature o riepiloghi su Facebook e Instagram.
10. Twitterbot: crawler per le anteprime dei link di X (Twitter)
Twitterbot recupera i dati delle Twitter Card per X (Twitter).
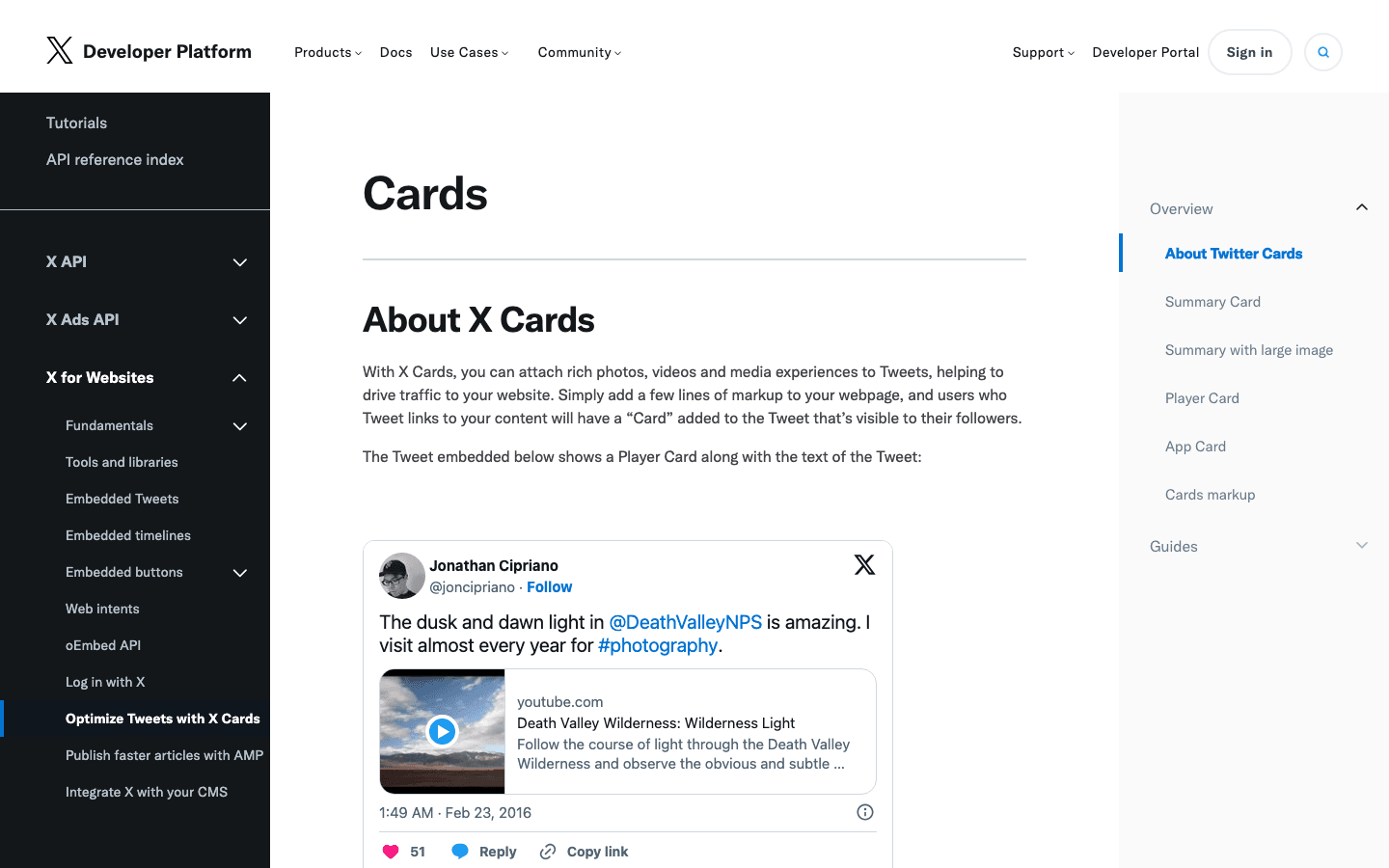
- User-Agent:
Twitterbot/1.0 - Verifica: tramite user-agent; ASN di Twitter (AS13414).
- Consigli di gestione: consentilo per le anteprime su Twitter. Usa i meta tag Twitter Card per ottenere i migliori risultati.
Tabella comparativa: elenco dei crawler in sintesi
| Crawler | Scopo | Esempio di User-Agent | Metodo di verifica | Impatto sul business | Consigli di gestione |
|---|---|---|---|---|---|
| Thunderbit | Analisi AI di log/crawler | N/D (strumento, non un bot) | N/D | Gestione dati, classificazione bot | Usalo per estrarre log e creare allowlist |
| Googlebot | Indicizzazione di Google Search | Googlebot/2.1 | DNS e lista IP | Fondamentale per il SEO | Consenti sempre, gestisci tramite Search Console |
| Bingbot | Bing/Yahoo Search | bingbot/2.0 | DNS e lista IP | Importante per il SEO di Bing/Yahoo | Consenti, gestisci tramite Bing Webmaster Tools |
| Baiduspider | Ricerca Baidu (Cina) | Baiduspider/2.0 | Reverse DNS, stringa UA | Chiave per il SEO in Cina | Consenti se punti alla Cina, monitora la banda |
| YandexBot | Ricerca Yandex (Russia) | YandexBot/3.0 | Reverse DNS verso .yandex.ru | Chiave per Russia/Europa orientale | Consenti se punti a RU/CIS, usa gli strumenti Yandex |
| DuckDuckBot | Ricerca DuckDuckGo | DuckDuckBot/1.1 | Lista IP ufficiale | Pubblico attento alla privacy | Consenti, impatto ridotto |
| AhrefsBot | Analisi SEO/backlink | AhrefsBot/7.0 | Stringa UA, reverse DNS | Strumento SEO, può consumare molta banda | Consenti/limita/blocca tramite robots.txt |
| SemrushBot | Analisi SEO/competitiva | SemrushBot/1.0 (più varianti) | Stringa UA | Strumento SEO, può essere aggressivo | Consenti/limita/blocca tramite robots.txt |
| FacebookExternalHit | Anteprime dei link social | facebookexternalhit/1.1 | Stringa UA, ASN di Facebook | Engagement sui social | Consenti per le anteprime, usa i tag OG |
| Twitterbot | Anteprime dei link su Twitter | Twitterbot/1.0 | Stringa UA, ASN di Twitter | Engagement su Twitter | Consenti per le anteprime, usa i tag Twitter Card |
Gestire la lista dei crawler: best practice per il 2025
Scopri di più sul list crawling con l’AI Get Started Free
- Aggiorna regolarmente: il panorama dei crawler cambia rapidamente. Pianifica revisioni trimestrali e usa strumenti come Thunderbit per estrarre e confrontare gli elenchi ufficiali (Human Security).
- Verifica, non fidarti: controlla sempre sia user-agent sia IP/ASN. Non lasciare che gli impostori entrino e falsino le analytics o estraggano i tuoi dati (FriendlyCaptcha).
- Metti in allowlist i bot buoni: assicurati che i crawler di ricerca e social non vengano mai bloccati da regole anti-bot o firewall.
- Limita o blocca i bot aggressivi: usa robots.txt, crawl-delay o regole lato server per gli strumenti SEO che colpiscono troppo duramente.
- Automatizza l’analisi dei log: usa strumenti con AI (come Thunderbit) per estrarre, classificare ed etichettare l’attività dei crawler, risparmiando tempo e intercettando trend che potresti perdere.
- Bilancia SEO, analytics e sicurezza: non bloccare i bot che fanno crescere il tuo business, ma non lasciare nemmeno che i cattivi facciano il bello e il cattivo tempo.
Scarica l’estensione Chrome di Thunderbit
Conclusione: mantenere l’elenco dei crawler aggiornato e utile
Nel 2025, gestire la lista dei crawler non è solo una faccenda IT: è un’attività critica per il business che tocca SEO, analytics, sicurezza e conformità. Con i bot che ormai costituiscono la maggior parte del traffico web, devi sapere chi visita il tuo sito, perché lo fa e cosa farci. Tieni aggiornata la tua lista, automatizza dove puoi e usa strumenti come Thunderbit per restare sempre un passo avanti. Il web diventa sempre più affollato — e una strategia intelligente e operativa sui crawler è la tua migliore difesa (e il tuo migliore attacco) nel mondo alimentato dai bot.
FAQ
1. Perché è importante mantenere aggiornata la lista dei crawler?
Perché oggi i bot rappresentano oltre metà del traffico web e solo una piccola parte è davvero utile. Tenere la lista aggiornata ti permette di consentire i bot buoni (per SEO e anteprime social) e bloccare o limitare quelli cattivi, proteggendo analytics, banda e sicurezza dei dati.
2. Come posso capire se un crawler è autentico o falso?
Non fidarti solo dello user-agent: verifica sempre l’indirizzo IP o l’ASN usando liste ufficiali o reverse DNS lookup. Strumenti come Thunderbit possono automatizzare questo processo confrontando i log con gli IP e gli user-agent pubblicati dei bot.
3. Cosa devo fare se un bot sconosciuto sta scansionando il mio sito?
Indaga su user-agent e IP. Se non è nella tua allowlist e non corrisponde a un bot noto, valuta di limitarlo, sfidarlo o bloccarlo. Usa strumenti AI per classificare e monitorare i nuovi crawler non appena compaiono.
4. In che modo Thunderbit aiuta nella gestione dei crawler?
Thunderbit usa l’AI per estrarre, strutturare e classificare l’attività dei crawler dai log, semplificando la creazione di allowlist, l’identificazione degli impostori e l’automazione dell’applicazione delle policy. La sua pre-elaborazione semantica è particolarmente robusta per siti complessi o dinamici.
5. Qual è il rischio di bloccare un crawler importante come Googlebot o Bingbot?
Bloccare i crawler dei motori di ricerca può far sparire il tuo sito dai risultati di ricerca, azzerando il traffico organico. Ricontrolla sempre firewall, robots.txt e regole anti-bot per evitare di escludere per errore i bot più importanti.
Scopri di più:
- Come estrarre qualsiasi sito web usando l’AI
- Guida Python al web scraping: impara con esempi reali
- L’elenco definitivo 2025 dei crawler web e dei bot buoni: identificazione, esempi e best practice
- I bot crawler web più diffusi
Prova Thunderbit per la gestione dei crawler con AI Get Started Free




