
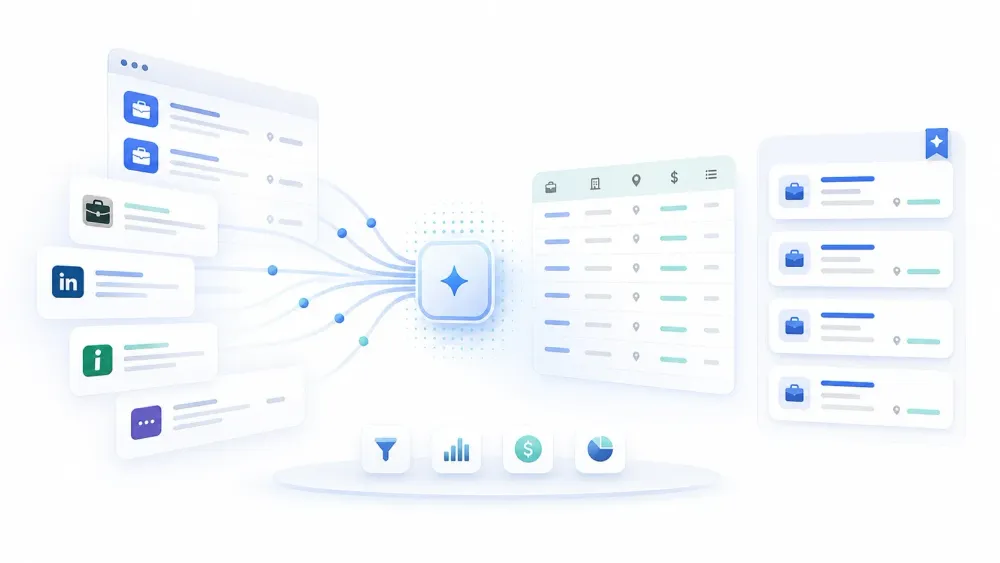
Tenere il passo con il mercato delle assunzioni a mano continua a bloccarsi sempre sugli stessi problemi: troppe pagine, troppi formati e troppo copia-incolla tra job board, pagine carriera aziendali e tracker interni. La differenza nel 2026 è che i team HR e recruiting si aspettano benchmark più rapidi, market intelligence più pulita e dati subito utilizzabili da condividere con hiring manager, finance e leadership.
È qui che il software per lo scraping di annunci di lavoro è diventato davvero utile. I migliori strumenti fanno molto più che portare le inserzioni in un foglio di calcolo. Aiutano i team a standardizzare campi disordinati, aggiornare i dati a intervalli regolari, confrontare ruoli tra più aziende e passare dalla consultazione all’analisi senza costringere l’HR ad aspettare il supporto tecnico. Io sviluppo prodotti di automazione, incluso Thunderbit, quindi questo aggiornamento si concentra su ciò che conta davvero nei flussi di recruiting reali: facilità di configurazione, copertura delle fonti, opzioni di esportazione, profondità dell’automazione e quanto lavoro di pulizia resta da fare dopo lo scraping.
Prova Thunderbit per lo scraping di annunci di lavoro
Cosa aiuta davvero a fare il software di scraping di annunci ai team HR
Il software di scraping di annunci di lavoro raccoglie automaticamente le offerte di lavoro da job board pubbliche, siti carriera alimentati da ATS e pagine assunzioni aziendali, trasformando poi quelle inserzioni in righe strutturate che il team può ordinare, filtrare, esportare e confrontare. Il valore pratico non è "più dati". È un accesso più rapido a dati pronti per prendere decisioni.
Per i team HR, recruiting e people ops, di solito significa:
- creare tracker dei concorrenti senza lavoro manuale su tabelle
- fare benchmarking di job title, sedi, fasce salariali e competenze tra aziende diverse
- creare dataset interni per la pianificazione della forza lavoro e l’analisi dei gap di competenze
- monitorare aziende target o ruoli specifici con cadenza ricorrente
- consegnare esportazioni pulite a Sheets, Excel, Airtable, Notion o database interni
Nel 2026, gli strumenti più forti aiutano anche nel post-processing. Questo può significare unire etichette di campo incoerenti, riassumere descrizioni lunghe, tradurre annunci multilingue o arricchire le pagine delle inserzioni visitando automaticamente ogni pagina di dettaglio del lavoro.
Come ho valutato i migliori strumenti per lo scraping di annunci nel 2026
Ho assegnato un punteggio a questi strumenti in base a sette criteri pratici:
| Criterio | Cosa significa in pratica |
|---|---|
| Usabilità no-code | I team HR e recruiting devono poter avviare uno scraping senza selector CSS, XPath o script personalizzati. |
| Flessibilità delle fonti | Lo strumento dovrebbe funzionare su job board, pagine carriera aziendali e layout ATS personalizzati, non su una sola fonte limitata. |
| Profondità dell’automazione | Paginazione, scraping delle sottopagine, pianificazione e run nel cloud sono fondamentali per il monitoraggio ricorrente del mercato. |
| Impegno di pulizia dei dati | I migliori prodotti riducono il lavoro di pulizia dopo l’esportazione standardizzando campi, etichette o formattazione. |
| Esportazione e integrazioni | Per molti team il solo CSV non basta; contano Sheets, Excel, API e strumenti di workflow. |
| Scalabilità e affidabilità | Le piccole estrazioni occasionali e le raccolte ricorrenti più grandi hanno esigenze diverse, soprattutto su siti dinamici o protetti. |
| Adattamento al team | Una solida piattaforma per sviluppatori non è automaticamente un buon strumento di lavoro per HR, e viceversa. |
Se vuoi una rapida panoramica visiva prima di confrontare i prodotti, questa demo di Thunderbit mostra il flusso di lavoro di base “apri la pagina, rileva i campi, esporta le righe”, che oggi definisce la fascia più semplice di questa categoria.
Confronto rapido: 8 strumenti per lo scraping di annunci a colpo d’occhio
| Strumento | Cosa fa meglio | Ideale per | Sintesi prezzi (2026) | Vincolo principale |
|---|---|---|---|---|
| Thunderbit | Rilevamento AI dei campi ed esportazioni strutturate da quasi qualsiasi pagina di lavoro | Team HR, recruiter, team ops che vogliono la configurazione no-code più veloce | Piano gratuito + piani a pagamento | Non nasce come database di annunci precaricato |
| Octoparse | Scraping visuale con forte supporto ai template e run nel cloud | Analisti e utenti HR ops che vogliono più controllo sul workflow | Piano gratuito; a pagamento da 69 $/mese | Più lavoro di setup rispetto agli strumenti guidati dall’AI |
| Apify | Actor nel cloud e scraping guidato da API | Team con supporto tecnico o esigenze di scraping ricorrenti e di grandi volumi | Piano gratuito; Starter da 29 $/mese più consumo | Più adatto a chi sviluppa che a utenti business occasionali |
| PhantomBuster | Automazione incentrata su LinkedIn e concatenazione dei workflow | Recruiter focalizzati su sourcing pesante su LinkedIn | Prova di 14 giorni + piani Start/Grow/Scale | Più limitato al di fuori dei workflow dei social network |
| Bright Data | Infrastruttura di scraping enterprise e anti-blocco | Team dati di grandi dimensioni e raccolta ad alto volume | Pay-as-you-go da 1,5 $/1K record | Troppo tecnico e potente per la maggior parte dei team HR |
| DataMiner | Estrazione rapida via browser per lavori occasionali | Piccole estrazioni manuali da parte di utenti non tecnici | A pagamento da 19,99 $/mese | Profondità di automazione limitata per lavori ricorrenti più grandi |
| ParseHub | Scraping desktop point-and-click per siti interattivi | Utenti che preferiscono un builder desktop per flussi personalizzati | Piano gratuito; a pagamento da 189 $/mese | Meno supporto AI e curva di apprendimento più ripida |
| Diffbot | Estrazione AI da pagine e pipeline di crawl più ampie | Team di sviluppatori e analytics che monitorano molte fonti | Startup da 299 $/mese | API-first e costoso per casi d’uso recruiting semplici |
1. Thunderbit
Thunderbit è lo strumento più semplice in questa lista per i team non tecnici che hanno bisogno rapidamente di dati puliti sugli annunci di lavoro. È costruito attorno a un flusso guidato dall’AI: apri la pagina dell’annuncio, clicca AI Suggest Fields, controlla le colonne, poi avvia lo scraping. Questo è importante perché le pagine carriera raramente hanno la stessa struttura. Un sito può usare la sezione "Requisiti", un altro "Chi stiamo cercando", e un terzo può nascondere i campi utili tra pagine elenco e pagine di dettaglio.
Il vantaggio di Thunderbit è che tratta queste differenze come un problema di contenuto, non come un esercizio di costruzione di selector. È particolarmente forte quando il team vuole uno strumento unico capace di gestire un mix di pagine carriera aziendali, layout ATS personalizzati, directory di annunci ed esportazioni ripetute verso Sheets o Excel.
Perché Thunderbit si distingue
- Il suggerimento AI dei campi riduce drasticamente i tempi di configurazione per i team non tecnici.
- Lo scraping delle sottopagine aiuta a trasformare elenchi superficiali in record completi e strutturati.
- Il post-processing può standardizzare i campi, riassumere le descrizioni e tradurre i contenuti.
- Le esportazioni verso Sheets, Excel, Airtable, Notion, CSV e JSON si adattano bene ai flussi di consegna dell’HR.
Prezzi: Piano gratuito + piani a pagamento.
Ideale per: team HR, recruiting e ops che vogliono il workflow no-code più veloce.
Attenzione a: devi comunque sapere quali siti pubblici o pagine carriera vuoi monitorare.
2. Octoparse
Octoparse resta uno degli strumenti di scraping visuale più solidi per gli utenti che vogliono più controllo di quanto ne offra un’esperienza completamente guidata dall’AI. Il suo sistema di template, il builder point-and-click e le opzioni di estrazione nel cloud lo rendono utile per progetti di scraping ricorrenti che vanno oltre una semplice esportazione veloce.
Per i team recruiting, Octoparse è più interessante quando il team è disposto a investire più tempo nella configurazione dei lavori in cambio di un controllo più forte su paginazione, elementi dinamici e workflow personalizzati.
Perché Octoparse si distingue
- Forte builder visivo per utenti che vogliono vedere e ottimizzare il workflow.
- Buona scelta per siti dinamici e lavori pianificati ricorrenti.
- Un’ampia libreria di template riduce i costi di avvio sulle fonti comuni.
- I run nel cloud aiutano i team a non dover lasciare acceso un computer locale per estrazioni lunghe.
Prezzi: Piano gratuito; a pagamento da 69 $/mese.
Ideale per: HR ops e analisti che vogliono controllo senza scrivere codice.
Attenzione a: di solito richiede più tempo di configurazione rispetto agli strumenti che rilevano automaticamente i campi.
Questo tutorial di Octoparse è utile se vuoi vedere il lato più visuale e basato sui template dello scraping di annunci prima di impegnarti con uno strumento.
3. Apify
Apify si colloca in un’altra area del mercato. Non è solo uno scraper no-code; è una piattaforma per eseguire actor nel cloud, API e pipeline di automazione più ampie. Questo la rende flessibile e potente, soprattutto quando i team devono estrarre molti dati da più fonti su larga scala o integrare i risultati in un workflow dati più ampio.
Per lo scraping di annunci, il vantaggio principale è l’accesso ad actor pronti all’uso e la possibilità di costruire logiche personalizzate quando una fonte target o un workflow diventano più complessi.

Perché Apify si distingue
- Forte ecosistema di actor pronti all’uso per pattern di scraping comuni.
- L’architettura cloud-first supporta pianificazione, esecuzioni parallele e consegna via API.
- Maggiore margine di scalabilità rispetto alle estensioni browser leggere.
- Buona scelta quando i dati recruiting devono alimentare workflow di engineering o BI.
Prezzi: Piano gratuito; Starter da 29 $/mese più consumo.
Ideale per: team con supporto tecnico, lavori ricorrenti o operazioni dati più grandi.
Attenzione a: è più una piattaforma che uno strumento puntuale, quindi può sembrare pesante per semplici casi d’uso HR.
4. PhantomBuster
PhantomBuster è la scelta specialistica per i workflow centrati su LinkedIn. È noto soprattutto per automatizzare azioni ripetibili su social e network professionali, e questo lo rende utile per i recruiter il cui processo di sourcing inizia e finisce più spesso su LinkedIn che su job board generiche.
Il suo punto di forza non è la copertura ampia dei siti web. È l’automazione di workflow specifici supportati e la possibilità di concatenare i lavori tra loro.
Perché PhantomBuster si distingue
- Workflow di automazione pensati appositamente per il recruiting fortemente basato su LinkedIn.
- Pianificazione utile e concatenazione per attività di sourcing ripetute.
- I moduli no-code rendono la configurazione accessibile.
- I piani a pagamento includono accesso API ed esportazione CSV/JSON illimitata.
Prezzi: Prova di 14 giorni e piani a pagamento Start/Grow/Scale.
Ideale per: recruiter e growth team che vivono dentro i workflow di LinkedIn.
Attenzione a: è una scelta più limitata se il team ha bisogno di scraping multi-sito più ampio oltre le automazioni supportate.
5. Bright Data
Bright Data è la scelta enterprise per l’infrastruttura. Se Thunderbit è l’opzione no-code veloce e Octoparse il builder visuale, Bright Data è la piattaforma per le organizzazioni che tengono soprattutto a volume, sistemi anti-blocco, infrastruttura proxy e consegna programmatica.
Per lo scraping di annunci, questo la rende molto potente per i team dati più grandi, ma in genere troppo tecnica per un team HR autonomo che vuole solo un migliore monitoraggio dei concorrenti e esportazioni più pulite.
Perché Bright Data si distingue
- Progettata per raccolte ad alta scala su siti difficili o protetti.
- Forte infrastruttura proxy e anti-blocco.
- La Web Scraper API supporta job batch, raccolta in tempo reale e output strutturato.
- Migliore dei tool leggeri quando scala e affidabilità sono i vincoli principali.
Prezzi: Pay-as-you-go da 1,5 $/1K record; piani Scale da 499 $/mese.
Ideale per: team dati enterprise e gruppi operativi avanzati.
Attenzione a: per la maggior parte dei team recruiting è eccessiva, sia per complessità sia per costo.
6. DataMiner
DataMiner è l’opzione leggera e pragmatica. Funziona come estensione del browser ed è utile quando qualcuno deve estrarre rapidamente una pagina davanti a sé senza costruire attorno un grande sistema automatizzato.
Questo la rende interessante per ricerche una tantum sulle assunzioni, piccoli task di monitoraggio o esportazioni veloci da siti già aperti nel browser.
Perché DataMiner si distingue
- Molto semplice per estrazioni rapide direttamente nel browser.
- Il modello a recipe è adatto a task semplici ripetuti.
- Esportazioni facili verso CSV e fogli di calcolo.
- Costo d’ingresso inferiore rispetto a molte piattaforme più pesanti.
Prezzi: A pagamento da 19,99 $/mese.
Ideale per: piccoli team e lavori manuali veloci.
Attenzione a: non è lo strumento migliore per pipeline multi-sorgente di grandi dimensioni e pianificate.
7. ParseHub
ParseHub continua ad attrarre gli utenti che amano un’app desktop e non si fanno problemi se la configurazione richiede più intervento manuale. Può gestire siti interattivi e logiche più personalizzate rispetto ai semplici tool browser point-and-click, ma non elimina tanto lavoro di setup quanto i prodotti più recenti basati sull’AI.
Per i team che fanno scraping di annunci, ParseHub è più utile quando un workflow personalizzato conta più della semplicità e il team è disposto a investire tempo per costruire il progetto nel modo giusto.
Perché ParseHub si distingue
- Forte builder di progetti point-and-click per siti interattivi.
- Il flusso desktop si adatta a chi vuole un ambiente di progetto dedicato.
- Supporta pianificazione e funzioni premium nei piani a pagamento.
- Utile quando il sito target richiede una logica di scraping più personalizzata.
Prezzi: Piano gratuito; a pagamento da 189 $/mese.
Ideale per: utenti disposti a scambiare semplicità con controllo personalizzato.
Attenzione a: la curva di apprendimento è più alta e l’aiuto dell’AI è limitato.
8. Diffbot
Diffbot è l’opzione più orientata alle API in questa panoramica. La sua promessa è semplice: fornisci un URL o un target di crawl più ampio, e l’AI gestisce l’estrazione e la strutturazione della pagina. È molto potente quando i team vogliono dati sugli annunci leggibili dalle macchine da molte fonti, senza dover costruire ogni volta regole specifiche per ogni sito.
Per la maggior parte dei team HR, il limite è evidente: Diffbot è prezzato e posizionato più come infrastruttura che come semplice strumento business.
Perché Diffbot si distingue
- Forte estrazione automatica per dati strutturati a livello di pagina di lavoro.
- Migliore di molti strumenti più leggeri quando i team vogliono output nativi per API.
- Utile in pipeline di monitoraggio o analytics più grandi su molte fonti.
- Può ridurre parte del carico di manutenzione delle regole per singolo sito.
Prezzi: Piano Startup da 299 $/mese.
Ideale per: team di analytics, engineering e monitoraggio su larga scala.
Attenzione a: è costoso e superfluo per flussi HR più piccoli.
Quale strumento per lo scraping di annunci è più adatto al tuo team?
Strumenti diversi risolvono problemi diversi. L’errore più comune dei buyer è pensare che ogni prodotto di questa categoria debba essere giudicato con lo stesso metro.
| Se il tuo team ha bisogno di... | La scelta migliore | Perché |
|---|---|---|
| Il modo no-code più veloce per estrarre annunci da fonti miste | Thunderbit | Il rilevamento AI dei campi e le forti opzioni di esportazione riducono il lavoro di setup e pulizia. |
| Un builder visuale con più controllo pratico | Octoparse | Migliore quando il team vuole regolare direttamente workflow, paginazione e run nel cloud. |
| Scraping scalabile integrato con API e automazioni | Apify | Forte ecosistema di actor e architettura cloud più adatta a lavori ricorrenti di grandi dimensioni. |
| Automazione di sourcing incentrata su LinkedIn | PhantomBuster | È la soluzione migliore quando il recruiting è strettamente legato alle automazioni supportate da LinkedIn. |
| Raccolta enterprise ad alto volume con infrastruttura anti-blocco | Bright Data | Progettata per scala, proxy e affidabilità, non per semplicità. |
| Scraping rapido una tantum nel browser | DataMiner | Flusso semplice come estensione con basso overhead di configurazione. |
| Uno scraper desktop point-and-click per progetti personalizzati | ParseHub | Migliore per chi preferisce un builder dedicato e logiche personalizzate. |
| Estrazione di pagine API-first su molti siti | Diffbot | Ideale per estrazione guidata da sviluppatori e pipeline analytics più grandi. |
Se la tua valutazione sta passando dalla ricerca recruiting leggera alla raccolta ricorrente su larga scala, questo video di Bright Data mostra il lato più infrastrutturale del mercato.
Cosa controllare prima di acquistare
Prima di impegnarti con uno strumento, metti sotto pressione queste quattro domande:
- Quante fonti contano davvero? Se al team servono solo cinque o dieci siti ricorrenti, può bastare uno strumento no-code. Se ne servono centinaia, conta di più l’architettura della piattaforma.
- Chi possiederà il workflow? Un recruiter, un analista HR ops, un partner rev ops o uno sviluppatore hanno bisogno di livelli di controllo diversi.
- Quanta pulizia è accettabile? Alcuni prodotti fanno risparmiare tempo in fase di raccolta e spostano il caos nel post-processing. Altri fanno più pulizia a monte.
- Ti servono esportazioni una tantum o un tracker sempre attivo? Gli strumenti manuali possono andare benissimo per ricerche ad hoc. Il monitoraggio ricorrente dei concorrenti richiede pianificazione e affidabilità.
Prendi seriamente anche la compliance. Pubblico non significa sempre senza restrizioni. Il tuo team deve comunque rispettare i termini del sito target, gli obblighi sulla privacy e tutte le regole di governance interne su come vengono usati i dati sugli annunci estratti.
Verdetto finale
Per la maggior parte dei team HR e recruiting, Thunderbit è il punto di partenza più forte perché porta ai dati utilizzabili più velocemente e con il minimo setup tecnico. È la scelta migliore per i team che vogliono trasformare le pagine di lavoro in esportazioni strutturate senza scrivere a mano la logica di scraping.
Octoparse e ParseHub sono più adatti quando il team vuole un controllo diretto maggiore sulla costruzione del workflow. Apify, Bright Data e Diffbot hanno più senso quando il supporto engineering, le API o i requisiti di scala fanno già parte del progetto. PhantomBuster è lo specialista di nicchia per i workflow guidati da LinkedIn, mentre DataMiner è l’opzione leggera per estrazioni manuali rapide.
La domanda pratica non è "quale strumento è il più potente in astratto?" È "quale strumento porta il mio team dalle pagine di lavoro a un dataset di mercato pulito e ripetibile con il minor attrito possibile?" Per la maggior parte degli utenti business, la risposta continua a favorire semplicità d’uso, qualità della pulizia ed esportazione semplice rispetto alla pura ampiezza tecnica.
Se vuoi approfondire, questi sono le letture successive più rilevanti:
- Come estrarre annunci di lavoro usando l’AI
- I migliori strumenti di web scraping
- Estrarre dati da un sito web in Excel
Prova gratis lo scraper AI per annunci di lavoro di Thunderbit Get Started Free
FAQ
1. Che cos’è il software per lo scraping di annunci di lavoro?
Il software per lo scraping di annunci di lavoro raccoglie offerte pubbliche dai siti web e le converte in dati strutturati che il team può esportare, filtrare, confrontare e analizzare.
2. Perché gli strumenti AI per lo scraping di annunci sono più utili oggi rispetto agli scraper più vecchi?
I prodotti migliori oggi riducono il lavoro di configurazione e di pulizia rilevando automaticamente i campi, standardizzando etichette incoerenti e aiutando con riepiloghi, traduzioni o l’estrazione di pagine successive.
3. Qual è il miglior strumento per team HR non tecnici?
Thunderbit è il punto di partenza più semplice per la maggior parte dei team non tecnici perché usa l’AI per suggerire i campi e funziona su molti layout di pagina diversi senza selector manuali.
4. Qual è il miglior strumento per team tecnici o enterprise più grandi?
Apify, Bright Data e Diffbot sono scelte più forti quando il team ha bisogno di API, pipeline ricorrenti più grandi o raccolta più pesante dal punto di vista infrastrutturale.
5. Lo scraping incentrato su LinkedIn è la stessa cosa dello scraping generale di annunci?
No. Gli strumenti specifici per LinkedIn, come PhantomBuster, sono più forti quando il workflow è ancorato a quella piattaforma, mentre prodotti più ampi come Thunderbit, Octoparse, Apify, Bright Data, ParseHub e Diffbot sono migliori per il monitoraggio di mercato da fonti miste.




