

Qualche mese fa, uno dei nostri utenti mi ha fatto una domanda che mi ha quasi fatto strozzare con il caffè: "Se estraggo i prezzi pubblici dei prodotti da Coupang, finisco in un’aula di tribunale coreana?" Onestamente, non avevo una risposta secca e sicura — e neppure la maggior parte delle guide legali che ho trovato online.
Quella domanda mi è rimasta in testa perché è la stessa che migliaia di operatori e-commerce, team commerciali e founder SaaS digitano in silenzio su Google ogni settimana. Il mercato globale dei servizi di web scraping ha raggiunto circa 1,03 miliardi di USD nel 2024 ed è in rapida crescita. Sempre più aziende raccolgono dati dal web — e sempre più spesso si chiedono dove siano i limiti legali in Corea. La Corea non vieta lo scraping in assoluto.
Ma quattro grandi leggi possono entrare in gioco a seconda di cosa estrai, come lo estrai e perché. Il caso di riferimento che tutti citano è la sentenza della Corte Suprema coreana nel caso Yanolja (2021Do1533, decisa il 12 maggio 2022), che ha assolto il tool di scraping di un concorrente dalle accuse penali — e poi, in un separato giudizio civile, ha colpito la stessa società con circa 1 miliardo di KRW di risarcimento. Questo doppio esito è la cosa più importante che un non avvocato debba capire sul diritto coreano in materia di scraping, ed è la base di questa guida. Nessuna laurea in legge richiesta — solo un quadro pratico del rischio che puoi davvero usare.
Difficoltà: Principiante (nessuna competenza legale o tecnica richiesta)
Tempo necessario: ~15 minuti di lettura; riferimento continuo
Cosa ti serve: Una comprensione di base di cosa faccia il web scraping (se vuoi ripassare, dai un’occhiata al nostro articolo su cos’è il web scraping)
È legale il web scraping in Corea? La risposta breve
Il web scraping in sé non è illegale in Corea. È una tecnologia neutra — come un browser web o una formula di foglio di calcolo. I tribunali coreani si sono concentrati costantemente non sullo strumento, ma sul comportamento legato al suo utilizzo.
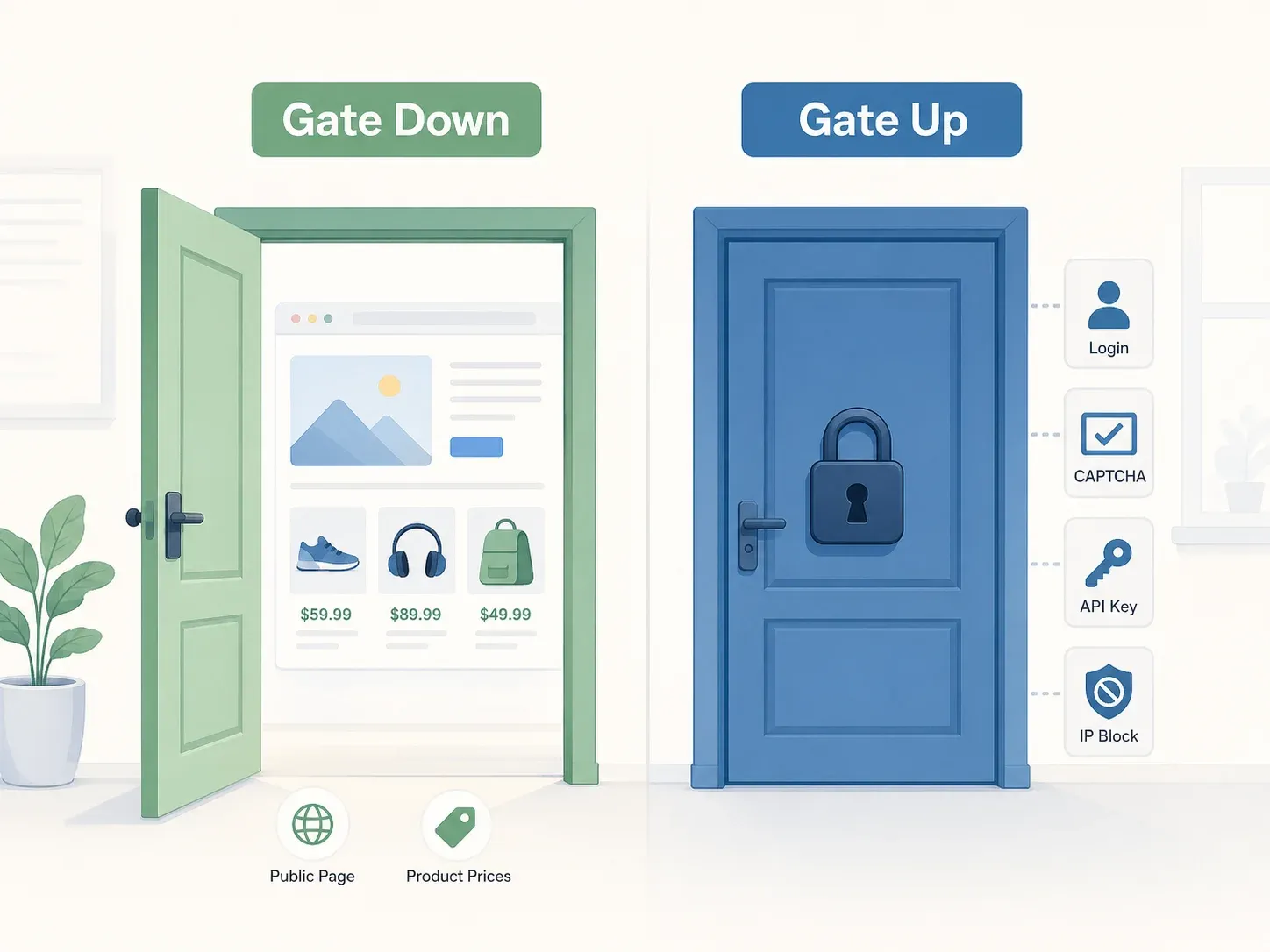
Il modello mentale migliore viene dalla decisione della Corte Suprema nel caso Yanolja: il principio "gate up vs. gate down". Se un sito non ha restrizioni oggettive di accesso — nessun login, nessun CAPTCHA, nessun requisito di API key, nessun blocco IP — il gate è "down" e accedere ai dati pubblicamente disponibili in genere non costituisce reato ai sensi dell’Information and Communications Network Act (ICNA) coreano. La Corte ha esaminato in particolare se "misure di protezione, termini di utilizzo e altre circostanze oggettivamente rivelate" limitassero l’accesso, e ha concluso che il server API di Yanolja fosse liberamente raggiungibile tramite l’app pubblica.
Ma "non penale" non significa "nessun rischio".
La responsabilità civile è una questione completamente separata. Puoi evitare un procedimento penale e ritrovarti comunque con una condanna al risarcimento di un miliardo di won. Il caso Yanolja lo ha dimostrato in modo dolorosamente chiaro.
Quattro leggi coreane possono applicarsi al web scraping:
- ICNA (Information and Communications Network Act) — la regola del "divieto di accesso"
- Copyright Act — diritti del produttore di database
- PIPA (Personal Information Protection Act) — norme sulla raccolta dei dati personali
- UCPA (Unfair Competition Prevention Act) — il contenitore generale contro il "free-riding"
Il resto di questa guida collega queste leggi a scenari reali, così puoi capire dove si colloca davvero il tuo progetto di scraping.
Il framework di rischio verde-giallo-rosso per il web scraping in Corea
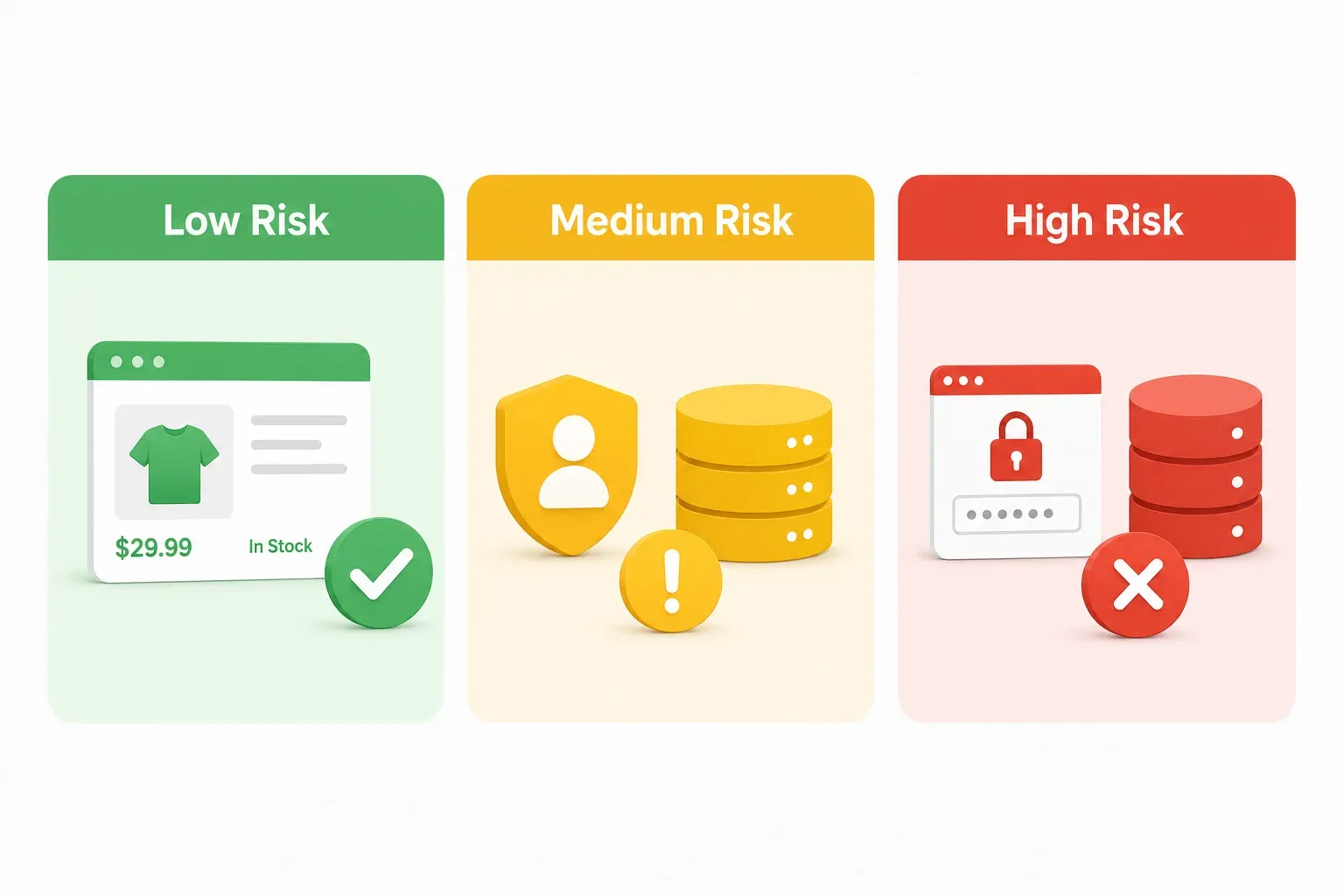
Ogni articolo legale che ho trovato sullo scraping in Corea sembra scritto per avvocati. Se sei un responsabile operations e-commerce o un founder SaaS, non ti serve un’analisi normativa di 40 pagine — ti serve un modo rapido per valutare il rischio prima di avviare un progetto. Pensalo come un semaforo. Verde significa vai pure (con la normale prudenza). Giallo significa rallenta e controlla gli specchietti. Rosso significa fermati e chiama un avvocato.
Zona verde: scenari di scraping a basso rischio
| Scenario | Livello di rischio | Legge/e chiave | Perché |
|---|---|---|---|
| Scraping di schede prodotto pubbliche (senza login, senza CAPTCHA) | 🟢 Basso | ICNA, Copyright Act | Sentenza Yanolja: nessuna restrizione di accesso = nessuna violazione ICNA; i dati fattuali (prezzi, disponibilità) non sono espressione creativa |
| Scraping di prezzi pubblici solo per analisi interne | 🟢 Basso | UCPA, Copyright Act | Dati fattuali, ambito limitato, nessuna ridistribuzione competitiva |
| Raccolta di fatti non personali e non protetti da copyright da pagine pubbliche | 🟢 Basso | ICNA, Copyright Act | Nessun ostacolo di accesso aggirato; i singoli fatti non sono protetti |
La decisione penale Yanolja è il punto di riferimento di questa zona. La Corte Suprema non ha riscontrato alcuna intrusione ai sensi dell’ICNA perché il server API era liberamente raggiungibile — gli utenti normali potevano accedervi tramite l’app con o senza iscrizione, e nessuna misura tecnica separata bloccava l’accesso alle API.
Per gli utenti di Thunderbit, questo è il punto ideale. Se stai estraendo dati da siti e-commerce o immobiliari pubblici in modalità cloud scraping — raccogliendo nomi prodotto, prezzi, disponibilità o metadati degli annunci ed escludendo i campi di dati personali — di solito ti trovi nella zona verde. (Detto questo, "di solito" non significa "sempre", e sotto spiego le sfumature.)
Prova Thunderbit per lo scraping di dati pubblici
Zona gialla: scenari di scraping a rischio medio
| Scenario | Livello di rischio | Legge/e chiave | Perché |
|---|---|---|---|
| Scraping di dati personali (nomi, email, numeri di telefono) anche da pagine pubbliche | 🟡 Medio | PIPA, ICNA | La PIPA si applica indipendentemente dalla visibilità pubblica; gli emendamenti del 2023 hanno inasprito le regole sul consenso |
| Scraping di grandi volumi che potrebbero costituire una "parte sostanziale" del database di un concorrente | 🟡 Medio | Copyright Act, UCPA | Test quantitativo + qualitativo nel diritto coreano |
| Ignorare i segnali robots.txt | 🟡 Medio | Prova di malafede | Non è di per sé un reato, ma può essere usato contro di te in tribunale |
| Scraping di dati pubblici ma utilizzo per competere direttamente con la fonte | 🟡 Medio | UCPA | Free-riding sull’investimento di un’altra piattaforma |
I dati personali sono il principale fattore scatenante della zona gialla.
Anche se un numero di telefono o un’email è visibile su una pagina pubblica, la PIPA continua ad applicarsi. La riforma PIPA del 2023 ha ampliato i diritti degli interessati e reso più severe le regole sul consenso. E nel 2024 la Personal Information Protection Commission (PIPC) coreana ha pubblicato linee guida specifiche sui dati personali pubblicamente disponibili nel contesto dell’IA e della raccolta dati — chiarendo che la mera accessibilità pubblica non equivale a un’autorizzazione generale.
Conta anche il volume. La Corte Suprema nel caso Yanolja ha affermato che sia i fattori quantitativi sia quelli qualitativi determinano se hai copiato una "parte sostanziale" di un database. Confronta la porzione copiata con l’intero database e chiediti se rifletta il sostanziale investimento del produttore.
Zona rossa: scenari di scraping ad alto rischio
| Scenario | Livello di rischio | Legge/e chiave | Perché |
|---|---|---|---|
| Scraping dietro un login wall o aggiramento dei controlli di accesso | 🔴 Alto | ICNA Art. 48 | "Gate up" = accesso non autorizzato; alto rischio di perseguimento |
| Aggiramento di CAPTCHA, blocchi IP o sistemi di rilevamento bot | 🔴 Alto | ICNA Art. 48(4) | L’emendamento 2024 prende di mira in modo specifico strumenti/dispositivi di bypass |
| Copia e rivendita dell’intero database di un concorrente | 🔴 Alto | Copyright Act (diritti DB), UCPA | Riproduzione sostanziale + free-riding commerciale |
| Raccolta di informazioni personali senza base giuridica per marketing/outreach | 🔴 Alto | PIPA | Fino a 5 anni / multa da 50 milioni di KRW; sanzioni amministrative fino al 3% del fatturato |
Un’aggiunta del 2024 all’ICNA — l’Articolo 48(4) — vieta ora in modo specifico l’installazione, il trasferimento o la distribuzione di programmi o dispositivi tecnici che aggirano le "normali procedure di protezione o autenticazione" senza una ragione legittima.
Separatamente, una sentenza della Corte Suprema di novembre 2024 (2021Do5555) ha ribadito che un’intrusione non autorizzata in una rete può esistere anche senza distruzione fisica delle misure di protezione. L’uso degli identificativi di un’altra persona o di comandi impropri per eludere i limiti di accesso è sufficiente.
Le quattro leggi coreane che si applicano al web scraping
| Legge | Cosa protegge | Quando entra in gioco per chi fa scraping |
|---|---|---|
| ICNA Articolo 48 | Stabilità della rete, autorità di accesso | Bypass di login, CAPTCHA, autenticazione, blocchi IP, limiti API key |
| Copyright Act (Art. 93) | Opere creative + diritti del produttore di database | Copia di contenuti espressivi, immagini o di tutte/le parti sostanziali di un database |
| PIPA | Informazioni personali, diritti dell’interessato | Raccolta di nomi, numeri di telefono, email, ID — anche da pagine pubbliche |
| UCPA (Art. 2(1)(k) e (m)) | Concorrenza leale, dati di valore commerciale | Free-riding sull’investimento in dati di un’altra piattaforma per la tua attività concorrente |
ICNA Articolo 48: la regola del "divieto di accesso"
L’Articolo 48(1) dell’ICNA stabilisce che nessuno può intrudere in una rete di informazione e comunicazione "senza una legittima autorità di accesso o oltre l’autorità di accesso consentita". In termini di scraping: se il sito ha restrizioni di accesso che aggiri, stai violando la norma. Se non ci sono restrizioni — pagina pubblica, nessun login — probabilmente sei a posto.
La sanzione per la violazione può arrivare fino a cinque anni di reclusione o una multa fino a 50 milioni di KRW ai sensi dell’Articolo 71 dell’ICNA.
Una sfumatura importante: la Corte Suprema coreana ha costantemente trattato le restrizioni dei Termini di servizio come diverse dalle restrizioni di accesso. I termini dell’app di Yanolja limitavano il riutilizzo commerciale e vietavano programmi automatici che gravavano sul server, ma la Corte ha ritenuto che tali clausole non limitassero oggettivamente l’accesso al server API in sé.
Copyright Act: diritti del produttore di database
Il Copyright Act coreano protegge separatamente i produttori di database rispetto al copyright sui singoli contenuti. Ai sensi dell’Articolo 93, riprodurre "tutto o una parte sostanziale" di un database è illegale — anche se i singoli dati sono fatti pubblici.
Il test è sia quantitativo (quanto hai copiato rispetto all’insieme?) sia qualitativo (la parte copiata riflette il sostanziale investimento del produttore nella costruzione, verifica o manutenzione del database?). Anche la copia ripetuta o sistematica di porzioni più piccole può contare se, di fatto, produce lo stesso risultato della copia di una parte sostanziale.
La pena per la violazione dei diritti del produttore di database arriva fino a tre anni o 30 milioni di KRW ai sensi dell’Articolo 136(2)(3). I danni statutari ai sensi dell’Articolo 125-2 consentono fino a 10 milioni di KRW per opera, o 50 milioni di KRW per opera in caso di violazione intenzionale a fini di lucro.
PIPA: Personal Information Protection Act
La PIPA disciplina la raccolta di dati personali — nomi, contatti, ID — anche se visibili pubblicamente. La riforma del 2023 è stata significativa: ha ampliato i diritti degli interessati, irrigidito i requisiti di consenso, introdotto regole per il processo decisionale automatizzato e fissato sanzioni amministrative fino al 3% delle vendite totali per determinate violazioni.
La guida PIPC 2024 sui dati pubblici e l’IA cita esplicitamente i dati ottenuti tramite "web crawling and scraping" nel contesto delle informazioni personali pubblicamente disponibili. La guida chiarisce che l’interesse legittimo può costituire una base in alcuni contesti, ma le organizzazioni devono prevedere bilanciamento, salvaguardie, tutela dei diritti e governance.
E il trend sta diventando più severo. Nel marzo 2026, la stampa coreana ha riportato un emendamento alla PIPA che aumenta le sanzioni massime per gravi violazioni ripetute dei dati fino al 10% del fatturato, con entrata in vigore più avanti nel 2026.
UCPA: il contenitore generale contro la concorrenza sleale
L’UCPA è la legge che ha colpito GC Company nel caso civile Yanolja. L’attuale testo contiene due disposizioni rilevanti:
- Articolo 2(1)(k): copre l’uso sleale di dati tecnici o aziendali accumulati e gestiti elettronicamente che non sono segreti
- Articolo 2(1)(m): la clausola più ampia contro l’uso, per la propria attività, dei risultati ottenuti da un’altra persona grazie a un investimento o a uno sforzo sostanziale, senza permesso e in contrasto con le corrette pratiche commerciali
Per queste disposizioni l’UCPA è solo civile — nessuna pena penale — ma può portare a ingiunzioni ai sensi dell’Articolo 4, risarcimenti ai sensi dell’Articolo 5 e persino a danni tripli in alcuni casi intenzionali previsti dall’Articolo 14-2. Il caso civile Yanolja ha assegnato circa 1 miliardo di KRW su questa base.
Il caso Yanolja: perché puoi vincere sul penale ma perdere sul civile
Questo è il caso che ogni operatore business in Corea deve capire. Lo racconto come una storia unica, perché è così che si è svolto davvero — e perché l’esito diviso è proprio il punto.
Cosa è successo: GC Company ha estratto i dati di viaggio di Yanolja
GC Company gestiva una piattaforma di viaggi online concorrente. Ha costruito un crawler sviluppato internamente che accedeva al server API dell’app Baro Reservation di Yanolja, apprendendo gli URL delle API e i comandi di richiesta e inviandoli al server. Lo scraper raccoglieva informazioni sulle strutture ricettive — nomi dei partner, indirizzi, prezzi, disponibilità e immagini. GC Company utilizzava questi dati internamente per marketing e posizionamento competitivo.
Yanolja ha presentato sia una denuncia penale sia una causa civile.
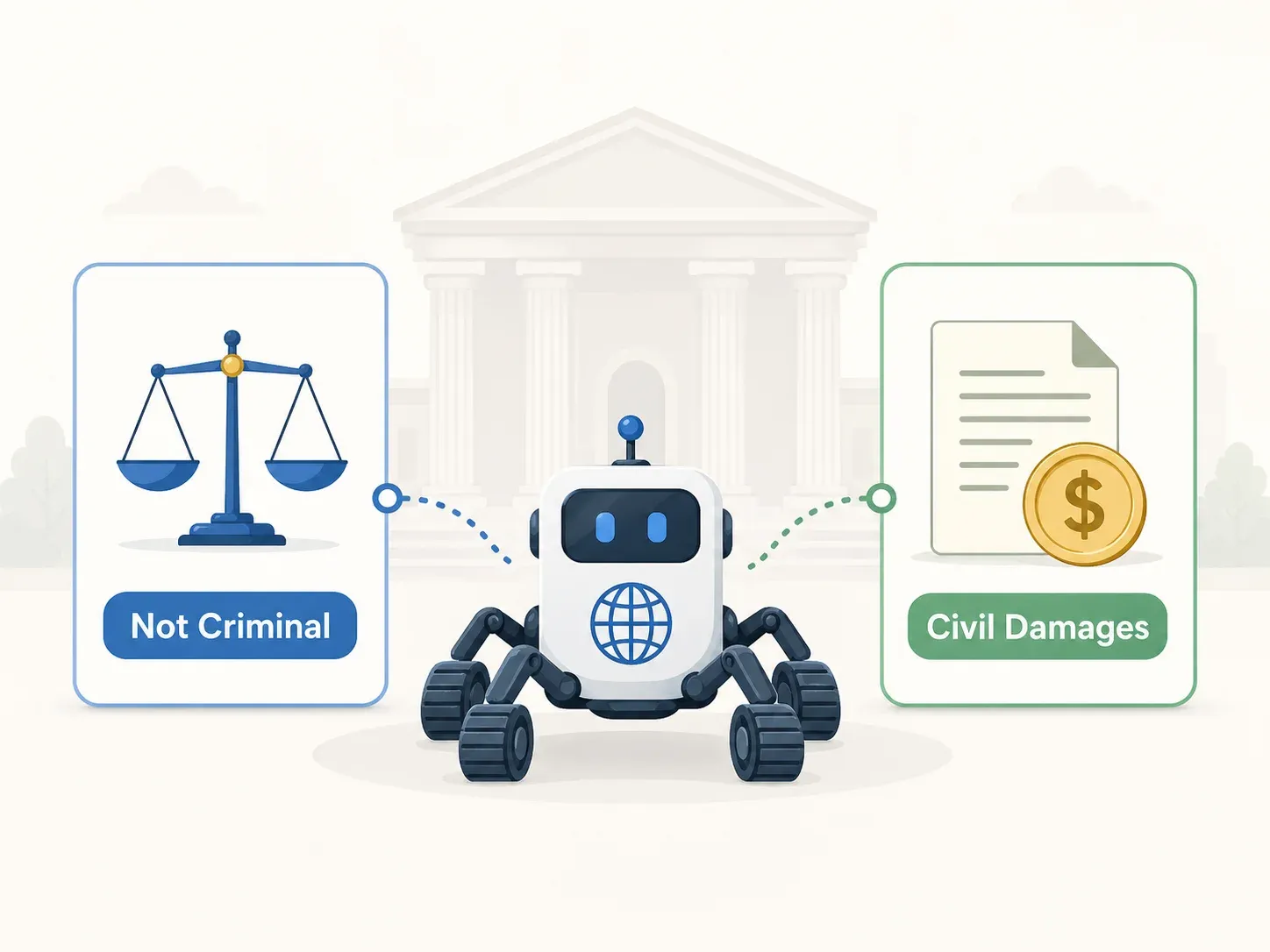
Sentenza penale: assoluzione su tutti i capi d’accusa (Corte Suprema 2021Do1533)
La Corte Suprema ha confermato l’assoluzione della corte d’appello il 12 maggio 2022, su tutti e tre i capi:
- ICNA Articolo 48 (intrusione): Non esistevano restrizioni di accesso. Il server API era accessibile pubblicamente tramite browser e app mobile. Non era presente alcun blocco tecnico. Le clausole dei ToS limitavano l’uso, non l’accesso.
- Copyright Act (diritti del produttore di database): Gli imputati non avevano riprodotto "tutto o una parte sostanziale" del database. I dati copiati erano già pubblicamente noti e le prove non dimostravano che la porzione copiata riflettesse il sostanziale investimento di Yanolja.
- Codice penale Articolo 314 (interferenza con l’attività): Non è stata provata alcuna reale interruzione del funzionamento del server API di Yanolja. Nessuna modifica dei dati. Nessun dolo per interferenza con l’attività.
La regola da citare è questa: le restrizioni di accesso devono essere valutate attraverso "misure di protezione, termini di utilizzo e altre circostanze oggettivamente rivelate". Se il gate è abbassato, attraversarlo non è trespassing.
Sentenza civile: 1 miliardo di KRW di danni sotto l’UCPA
Qui la storia cambia. Il Tribunale distrettuale centrale di Seoul — e poi la Corte d’appello di Seoul (causa 2021Na2034740, decisa il 25 agosto 2022) — ha stabilito che GC Company aveva violato la clausola generale dell’UCPA. Il tribunale ha assegnato circa 1 miliardo di KRW (~800.000 USD) di danni compensativi e ha ordinato la cessazione di ulteriori duplicazioni dei dati.
La motivazione: il database delle strutture di Yanolja aveva valore commerciale e rifletteva un investimento sostanziale — raccolta, verifica e aggiornamento dei dati sulle strutture ricettive. GC Company ha fatto free-riding su quell’investimento. La sentenza civile è diventata definitiva a livello della Corte d’appello di Seoul.
Lezione pratica: l’assoluzione penale non equivale a sicurezza civile
Questa è la lezione più controintuitiva del diritto coreano sullo scraping. Un accesso penalmente lecito non ha immunizzato un uso commercialmente sleale. "Posso essere perseguito penalmente?" e "Posso essere citato in giudizio?" sono domande diverse, con risposte potenzialmente opposte.
Per gli utenti business: anche se il tuo metodo di scraping è chiaramente nella zona verde per fini penali, il tuo uso dei dati — soprattutto se compete direttamente con la fonte — determina il tuo rischio civile.
Corea vs. USA vs. UE: come si confrontano le leggi sul web scraping
Non ho trovato un’altra guida che metta tutto questo in una sola tabella — il che è sorprendente, considerando quanti business fanno scraping oltre confine.
| Dimensione | Corea del Sud | Stati Uniti | UE / SEE |
|---|---|---|---|
| Legge principale | ICNA Art. 48, Copyright Act | CFAA (18 U.S.C. §1030), leggi statali | GDPR, Database Directive (96/9/EC) |
| Caso storico | Yanolja v GC Company (Corte Suprema 2021Do1533, 2022) | hiQ v LinkedIn (9th Cir. 2022), Van Buren v. US (2021) | Ryanair v PR Aviation (CGUE C-30/14, 2015) |
| Scraping di dati pubblici | Legale se non ci sono barriere oggettive di accesso ("gate down") | Legale secondo la logica hiQ (dati pubblici); Van Buren ha ristretto il CFAA | Dipende da diritti DB, contratto, copyright, GDPR e legge del singolo Stato membro |
| Regole sui dati personali | PIPA (emendata nel 2023) — consenso o base giuridica | Settoriale: CCPA (California), leggi statali sulla privacy | GDPR — consenso rigoroso / interesse legittimo; sanzione massima 20 milioni di € o 4% del fatturato globale |
| Violazione dei ToS = reato? | No (i tribunali stabiliscono che ToS ≠ violazione ICNA) | No (Van Buren 2021: ToS ≠ CFAA) | In generale no, ma può esserci violazione contrattuale (Ryanair) |
| Protezione del database | Diritti del produttore di database nel Copyright Act | Nessun diritto federale generale sui database | Diritto sui database sui generis |
| Pena penale massima | Fino a 5 anni / 50M KRW (ICNA) | Fino a 10 anni / 250K $ (CFAA) | Varia in base allo Stato membro |
Differenze chiave che contano per il tuo business
- La Corea non ha un’eccezione ampia per il text and data mining (TDM) come la direttiva DSM dell’UE. Se addestri modelli IA su dati coreani estratti dal web, non hai una deroga legale automatica.
- La clausola generale dell’UCPA in Corea è più ampia e meno prevedibile rispetto al diritto statunitense sulla concorrenza sleale. L’esito civile di Yanolja sarebbe molto più difficile da replicare negli USA.
- Tutte e tre le giurisdizioni concordano: violare solo i Termini di servizio non è un reato.
- La protezione dei database in Corea è normativa (come nell’UE), mentre gli USA non hanno un diritto federale generale sui database. Questo offre ai proprietari di piattaforme coreane più strumenti civili.
- Se fai scraping oltre confine, prevale la legge più severa applicabile. Un progetto che tocca dati coreani, statunitensi ed europei deve soddisfare tutti e tre i regimi.
Scenari specifici per settore: è legale il web scraping in Corea per la tua industry?
Il profilo di rischio cambia moltissimo da settore a settore e nessuna guida che ho trovato mappa il diritto coreano sullo scraping in base ai verticali specifici. Quindi ho messo insieme il quadro da solo.
E-commerce: monitoraggio prezzi e dati prodotto
Estrarre i prezzi pubblici dei prodotti da Coupang, Gmarket o 11Street è l’esempio più pulito di zona verde — resta sui campi fattuali (prezzo, disponibilità, nome prodotto), evita le aree accessibili solo con login, non aggirare blocchi tecnici e usa i dati internamente per il benchmarking.
Il rischio aumenta quando estrai descrizioni prodotto (contenuto creativo → copyright), informazioni di contatto dei venditori (PIPA), immagini (copyright) o un intero catalogo (diritti del produttore di database + UCPA).
Non ho trovato una causa e-commerce coreana di primo piano paragonabile a Yanolja. Il precedente più sviluppato è nel settore viaggi e recruitment — ma l’assenza di cause non equivale ad assenza di rischio.
La scheduled scraper di Thunderbit e la modalità cloud scraping sono pensate proprio per questo scenario: controlli ricorrenti di prezzi e inventario su pagine pubbliche, con AI Suggest Fields che ti consente di selezionare le colonne desiderate ed escludere i campi di dati personali.
Immobiliare: annunci di proprietà
Il real estate è naturalmente una zona gialla. Le inserzioni su piattaforme come Zigbang o Naver Real Estate combinano dati fattuali (prezzo, metratura, quartiere) con nomi degli agenti, numeri di telefono dell’ufficio, cellulari, foto e database curati della piattaforma.
Estrarre i dettagli pubblici degli immobili può essere meno rischioso. Ma raccogliere colonne con i contatti degli agenti fa scattare subito la PIPA — e scaricare tutti gli annunci di un’area inizia ad assomigliare a una copia sostanziale del database.
Mitigazione: escludi le colonne personali, riduci il perimetro geografico, documenta una finalità commerciale legittima, rispetta i rate limit ed evita di riprodurre un servizio concorrente di annunci. L’IA di Thunderbit può essere configurata per estrarre solo i campi immobiliari necessari — prezzo, metri quadri, posizione — saltando i dati di contatto personali.
Recruitment: annunci di lavoro
Il recruitment è un settore ad alto rischio, senza mezzi termini. In Corea esiste un precedente diretto: JobKorea v. Saramin. Saramin ha estratto il database degli annunci di lavoro di JobKorea ed è stata ritenuta responsabile per violazione dei diritti sui database e per concorrenza sleale. I dati del recruitment combinano spesso investimento della piattaforma (annunci curati e verificati), copia di database su larga scala e informazioni personali o di contatto dei recruiter.
Il mio consiglio: in generale, evita di fare scraping di una piattaforma di lavoro concorrente per costruire o arricchire un database di annunci rivale. Se il caso d’uso è ristretto, fai revisionare il quadro legale prima della raccolta, minimizza il volume, rimuovi i contatti personali e non ridistribuire i risultati.
Riferimento completo alle sanzioni: cosa rischi se il web scraping va storto in Corea
| Statuto coreano | Tipo di violazione | Sanzione penale massima | Massimo rimedio civile/amministrativo | Principale cambiamento 2023–2026 |
|---|---|---|---|---|
| ICNA Art. 48 | Accesso non autorizzato / interferenza | 5 anni / multa da 50M KRW | Risarcimento + ingiunzione | 2024: aggiunto l’Art. 48(4), che prende di mira gli strumenti di bypass |
| Copyright Act (diritti DB, Art. 93) | Riproduzione sostanziale del DB | 3 anni / multa da 30M KRW | Danni statutari fino a 50M KRW/opera (intenzionale a fini di lucro) | — |
| PIPA | Raccolta illecita di dati personali | 5 anni / multa da 50M KRW | Sanzione amministrativa fino al 3% del fatturato totale; possibile class action | Riforma 2023; guida AI sui dati pubblici 2024; tendenza 2026 verso il 10% per perdite ripetute |
| UCPA Art. 2(1)(k)/(m) | Acquisizione / uso sleale dei dati | Solo civile (nessuna pena per la clausola generale) | Risarcimento + ingiunzione; danni tripli per alcuni casi intenzionali | Rafforzamento delle disposizioni nel Data Framework Act 2022 |
| Art. 314 del Codice penale | Interferenza con l’attività tramite mezzi tecnologici | 5 anni / multa da 15M KRW | — | Yanolja: nessuna prova di reale interruzione |
Il punto cruciale: i binari penale e civile procedono in modo indipendente. Puoi affrontarli entrambi contemporaneamente — e vincerne uno perdendo l’altro.
La tua checklist di conformità in 10 punti per il web scraping in Corea
Ecco dieci domande sì/no da passare in rassegna prima di iniziare qualsiasi progetto di scraping. Stampala, salvala tra i preferiti, attaccala al monitor — quello che funziona per te.
- Il sito target non richiede login per accedere ai dati che ti servono? Se servono login, token o un account, il rischio si sposta bruscamente verso l’Articolo 48 dell’ICNA.
- Non ci sono restrizioni tecniche di accesso? CAPTCHA, blocchi IP, API key, rate limit e barriere bot sono forti segnali di zona rossa.
- Hai verificato il robots.txt del sito? Non è vincolante di per sé nel precedente coreano, ma è una prova utile delle aspettative del sito e della tua buona fede.
- Stai raccogliendo dati personali? Se nel perimetro ci sono nomi, numeri di telefono, email, ID o dettagli di contatto individuali, serve un’analisi PIPA.
- Stai copiando una "parte sostanziale" del database del sito? Fai domande sia quantitative sia qualitative — quanto, e la porzione copiata riflette l’investimento della fonte?
- Hai definito la tua finalità? L’analisi interna è meno rischiosa della ridistribuzione o della costruzione di un database concorrente. (Ma Yanolja mostra che l’uso competitivo interno non è uno scudo completo.)
- Hai documentato per iscritto la tua finalità commerciale legittima? La documentazione aiuta nel bilanciamento dell’interesse legittimo PIPA e come prova di buona fede.
- Hai rimosso o anonimizzato i campi di dati personali prima di archiviare/usare i dati? Escludere i contatti spesso sposta lo scraping immobiliare, di recruitment e di directory fuori dallo scenario PIPA più pericoloso.
- Stai usando intervalli ragionevoli tra le richieste? Evita di sovraccaricare il server — i rischi dell’Articolo 314 del Codice penale e dell’Articolo 48(3) dell’ICNA crescono quando lo scraping compromette il funzionamento del servizio.
- Hai consultato un legale coreano per progetti ad alto volume, commerciali o cross-border? Potrebbero applicarsi la legge coreana e anche il GDPR/le norme privacy USA o le leggi sull’accesso ai computer.
⚠️ Disclaimer: questa checklist serve come orientamento, non come consulenza legale. Consulta sempre un avvocato locale in Corea per situazioni specifiche.
Come Thunderbit ti aiuta a fare scraping di siti coreani in modo responsabile
Trasparenza totale: lavoro nel team marketing di Thunderbit. Ma credo davvero che qui il prodotto sia ben allineato alla normativa, non sia solo un discorso commerciale.
Thunderbit è progettato per i casi d’uso della zona verde descritti in questo articolo: scraping di dati pubblicamente disponibili senza login. Ecco come alcune funzionalità si collegano al quadro di conformità:
- Modalità cloud scraping per siti pubblici — non serve effettuare login, nessuna sessione locale richiesta, si resta entro i confini dell’accesso pubblico. Questo si allinea con il principio Yanolja del "gate down".
- AI Suggest Fields ti permette di definire esattamente quali colonne di dati estrarre. Ti servono prezzi e disponibilità dei prodotti ma non i numeri di telefono dei venditori? Basta escludere le colonne personali. È il modo più semplice per evitare i trigger della PIPA.
- Scheduled scraper per controlli ricorrenti di prezzi, inventario o annunci a intervalli ragionevoli — senza martellare un server con richieste continue.
- Esportazione gratuita dei dati in Excel, Google Sheets, Airtable e Notion per flussi di lavoro di analisi interna.
- Scraping di sottopagine per arricchire i dati pubblici degli annunci (ad esempio aprendo le singole pagine prodotto per le specifiche) senza accedere ad aree con login o limitate.
- Adattamento del layout con IA — lo scraper legge la struttura del sito ogni volta da capo, adattandosi ai cambiamenti di layout senza selettori rigidi e fragili.
Thunderbit supporta l’uso multilingue in decine di lingue, cosa importante per i team che lavorano su siti in lingua coreana. Puoi provarlo gratis tramite la Thunderbit Chrome Extension.
Nessuno strumento elimina il rischio legale. Ma una configurazione responsabile — pagine pubbliche, dati fattuali, campi personali esclusi, intervalli ragionevoli — ti mantiene nel quadro di conformità descritto in questo articolo.
Punti chiave sulla legalità del web scraping in Corea
Cinque cose da ricordare:
- La tecnologia del web scraping in sé è legale in Corea. La Corte Suprema lo ha confermato nella decisione Yanolja.
- Il rischio dipende dal metodo di accesso (gate up vs. gate down), dal tipo di dato (personale vs. fattuale) e dall’uso (interno vs. ridistribuzione competitiva).
- Assoluzione penale ≠ sicurezza civile. Il caso Yanolja dimostra che puoi evitare il procedimento penale ma comunque affrontare danni da un miliardo di won.
- Quando fai scraping di dati pubblici, non personali e fattuali per uso interno, senza barriere di accesso, di solito sei in una zona sicura. Ma "di solito" conta: ambito, volume e finalità sono tutti importanti.
- Consulta sempre un avvocato locale coreano per progetti su larga scala o commerciali. Questo articolo serve come orientamento, non come consulenza legale.
Se vuoi iniziare a fare scraping di siti coreani in modo responsabile, il piano gratuito di Thunderbit ti permette di testare il flusso su piccola scala. Per saperne di più su come funziona in pratica lo scraping basato sull’IA, consulta le nostre guide su AI web scraping e web scraping senza codice. E se vuoi vedere lo strumento in azione, il nostro canale YouTube offre walkthrough per i casi d’uso più comuni.
FAQ
1. È legale estrarre dati pubblicamente disponibili in Corea?
In generale sì, per fini penali — secondo la sentenza della Corte Suprema nel caso Yanolja, accedere a dati da un sito senza restrizioni oggettive di accesso non viola l’ICNA. Tuttavia, la responsabilità civile ai sensi dell’UCPA o del Copyright Act può comunque applicarsi, a seconda del volume, dell’investimento della fonte e del tuo uso commerciale dei dati.
2. Possono citarmi in giudizio per web scraping in Corea anche se non è un reato?
Sì. I binari penale e civile sono indipendenti. GC Company è stata assolta da tutte le accuse penali ma condannata a pagare circa 1 miliardo di KRW di danni civili ai sensi della clausola generale dell’UCPA. L’assoluzione penale non offre alcuna protezione dalle azioni civili.
3. Violare i Termini di servizio di un sito rende illegale lo scraping in Corea?
I tribunali coreani hanno costantemente stabilito che la sola violazione dei ToS non costituisce reato ai sensi dell’ICNA — la Corte ha distinto tra limitare l’uso (ToS) e limitare l’accesso (barriere tecniche). Detto questo, la violazione dei ToS può comunque sostenere una causa civile per violazione contrattuale o fungere da prova di malafede in un’analisi di concorrenza sleale.
4. Come si confronta la legge coreana sul web scraping con quella statunitense?
Entrambe le giurisdizioni proteggono lo scraping di dati pubblici (Yanolja in Corea, hiQ v LinkedIn negli USA) ed entrambe stabiliscono che la sola violazione dei ToS non è un reato (Van Buren negli USA). La differenza chiave: la Corea ha una protezione statutaria più forte dei database e una clausola generale contro la concorrenza sleale più ampia degli USA, che non hanno un diritto federale generale sui database. I titolari di piattaforme coreane hanno quindi più strumenti civilistici per perseguire gli scraper.
5. Cosa succede se estraggo dati personali da siti coreani?
La PIPA si applica indipendentemente dal fatto che le informazioni siano visibili pubblicamente. Raccogliere informazioni personali — nomi, numeri di telefono, email — senza consenso o senza un’altra base giuridica è una violazione. L’emendamento PIPA del 2023 ha rafforzato queste tutele, e le linee guida PIPC del 2024 sulle informazioni personali pubblicamente disponibili affrontano specificamente web crawling e scraping. Le sanzioni possono arrivare fino a 5 anni di reclusione, 50 milioni di KRW di multa e sanzioni amministrative fino al 3% del fatturato totale.
Prova Thunderbit per uno scraping responsabile del web Get Started Free
Scopri di più




