
I web crawler sono i veri eroi silenziosi di internet. Ogni volta che cerchi una ricetta nuova, dai un’occhiata al prezzo aggiornato delle tue sneakers preferite o confronti gli hotel per la prossima vacanza, c’è quasi sicuramente un web crawler che è passato di lì prima di te, raccogliendo e mettendo in ordine senza far rumore le informazioni che hai sotto gli occhi. Tanto che, secondo le stime, circa metà del traffico internet viene oggi generato da bot e crawler, non da persone in carne e ossa — le indagini di settore più recenti parlano di una quota di bot tra il 49 e il 51%. Proprio così: mentre tu dormi, questi esploratori digitali continuano a mappare il web senza sosta, mettendo le informazioni di tutto il mondo a un clic di distanza.
Ma cosa sono, di preciso, i web crawler? Perché contano così tanto per le aziende, i ricercatori e chiunque viva di dati aggiornati? E come hanno fatto strumenti moderni come Thunderbit a rendere il web crawling roba per tutti, e non più solo per i programmatori o i giganti della tecnologia? Avendo passato anni a costruire strumenti di automazione e di IA, ho visto coi miei occhi i web crawler trasformarsi da misteriosi “spider” a strumenti irrinunciabili per il business di ogni giorno. Entriamo nel vivo e facciamo chiarezza sul mondo dei web crawler: cosa sono, come funzionano e perché nel 2026 saranno la spina dorsale di un accesso ai dati più intelligente.
I web crawler sono gli esploratori dati di internet
Estrai dati da qualsiasi sito web con l'IA Get Started Free
Allora, cosa sono davvero i web crawler? In sostanza, i web crawler (detti anche spider o bot) sono programmi automatici che girano in modo sistematico per internet, visitando una pagina web dopo l’altra e raccogliendo informazioni strada facendo. Pensali come i tirocinanti più instancabili del mondo — con la differenza che non dormono mai, non si lamentano mai e riescono a visitare milioni di pagine in una sola giornata.
Un web crawler parte da un elenco di indirizzi web (i cosiddetti “seed”), visita ciascuno di essi e poi segue i link che incontra per scovare nuove pagine. Lungo il cammino copia contenuti, indicizza dati e disegna la mappa di un web che cambia di continuo (Cloudflare). È così che motori di ricerca come Google sanno cosa esiste online, ed è così che i siti di confronto prezzi o gli strumenti di ricerca di mercato tengono i dati sempre freschi.
Detta in modo semplice: i web crawler sono gli esploratori che rendono internet ricercabile, confrontabile e davvero utilizzabile.
Le tante facce dei web crawler: tipi e funzioni principali
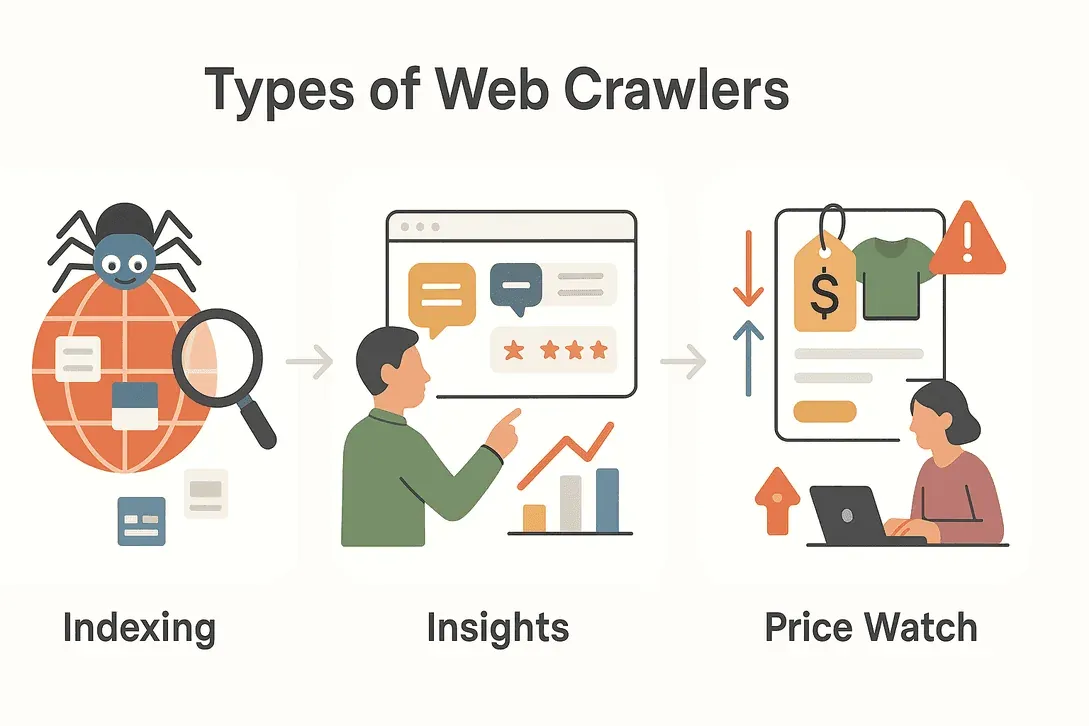 Non tutti i web crawler nascono per la stessa missione. A seconda dello scopo, si presentano in forme diverse, ognuna con la sua specializzazione. Ecco una rapida panoramica dei tipi principali che potresti incrociare:
Non tutti i web crawler nascono per la stessa missione. A seconda dello scopo, si presentano in forme diverse, ognuna con la sua specializzazione. Ecco una rapida panoramica dei tipi principali che potresti incrociare:
| Tipo | Funzione principale | Caso d'uso tipico |
|---|---|---|
| Crawler per motori di ricerca | Indicizzare il web per i risultati di ricerca | Googlebot, Bingbot che indicizzano nuovi siti |
| Crawler per data mining | Raccogliere grandi set di dati per l'analisi | Ricerche di mercato, studi accademici |
| Crawler per il monitoraggio prezzi | Monitorare prezzi e disponibilità dei prodotti | Confronto prezzi e-commerce, pricing dinamico |
| Crawler di aggregazione contenuti | Raccogliere articoli, notizie o post per l'aggregazione | Portali di notizie, content curation |
| Crawler per lead generation | Estrarre informazioni di contatto e dati aziendali | Prospecting commerciale, directory B2B |
Vediamone qualcuno più da vicino:
Crawler per motori di ricerca
Quando digiti una domanda su Google, ti stai appoggiando al lavoro dei crawler dei motori di ricerca. Questi bot battono il web 24 ore su 24, 7 giorni su 7: scoprono pagine nuove, aggiornano quelle vecchie e indicizzano i contenuti perché possano spuntare tra i risultati di ricerca. Senza crawler, i motori di ricerca brancolerebbero nel buio: nessun modo di sapere cosa c’è di nuovo, cosa è cambiato o cosa esiste online (TechTarget).
Crawler per data mining e ricerche di mercato
Aziende e ricercatori usano i crawler per mettere insieme montagne di dati da analizzare. Vuoi sapere quante volte il brand di un concorrente viene citato online? Oppure tenere d’occhio il sentiment attorno al lancio di un nuovo prodotto? I crawler per data mining sanno setacciare forum, recensioni, social media e altro ancora, trasformando il caos del web in insight ben strutturati (DataHut).
Crawler per il monitoraggio prezzi e il tracciamento prodotti
Nel mondo frenetico dell’e-commerce, prezzi e dettagli dei prodotti cambiano in continuazione. I crawler per il monitoraggio prezzi tengono d’occhio i concorrenti e avvisano le aziende quando un prezzo cala, le scorte cambiano o esce un nuovo prodotto. È quello che rende possibili le strategie di pricing dinamico e aiuta le aziende a non farsi superare (AIMultiple).
Perché i web crawler sono fondamentali per l'accesso ai dati di oggi
Diciamolo senza giri di parole: internet è troppo sterminato perché un essere umano possa starle dietro a mano. Oggi ci sono più di 1,4 miliardi di siti web (e il numero continua a salire), con circa un milione di siti nuovi che si aggiungono ogni giorno. I web crawler rendono possibile:
- Scalare la raccolta dati: visitare milioni di pagine in poche ore, non in mesi.
- Restare sempre aggiornati: seguire di continuo modifiche, nuovi contenuti o notizie dell’ultima ora.
- Accedere a informazioni dinamiche e in tempo reale: reagire ai movimenti del mercato, alle variazioni di prezzo o ai temi del momento mentre succedono.
- Abilitare decisioni basate sui dati: alimentare di tutto, dai motori di ricerca alla ricerca di mercato, dalla gestione del rischio alla modellazione finanziaria (DEV Community).
In un mondo in cui i dati sono la spina dorsale della strategia digitale, i web crawler sono i motori che tengono i dati in movimento.
Casi d'uso comuni dei web crawler nei vari settori
I web crawler non sono roba esclusiva dei colossi tech o dei motori di ricerca. Ecco come vengono messi al lavoro nei diversi settori:
| Settore | Caso d'uso | Vantaggio |
|---|---|---|
| Vendite | Lead generation | Creare liste mirate di prospect a partire dalle directory |
| E-commerce | Monitoraggio prezzi | Tenere d'occhio prezzi, stock e cambiamenti nei prodotti dei concorrenti |
| Marketing | Aggregazione contenuti | Selezionare notizie, articoli e menzioni sui social media |
| Immobiliare | Aggregazione annunci immobiliari | Riunire gli annunci da più fonti |
| Viaggi | Confronto tariffe e hotel | Monitorare prezzi, disponibilità e policy |
| Finanza | Monitoraggio del rischio | Seguire notizie, documenti depositati e sentiment per gli investimenti |
Esempio dal mondo reale:
Un’agenzia immobiliare usa i crawler per estrarre dettagli degli immobili, foto e servizi da più portali di annunci, così da offrire ai clienti una visione unica e sempre aggiornata del mercato (DataHut).
Un team e-commerce imposta i crawler per tenere d’occhio gli SKU e i prezzi dei concorrenti, e aggiusta la propria strategia in tempo reale (AIMultiple).
Come funzionano i web crawler: panoramica passo per passo
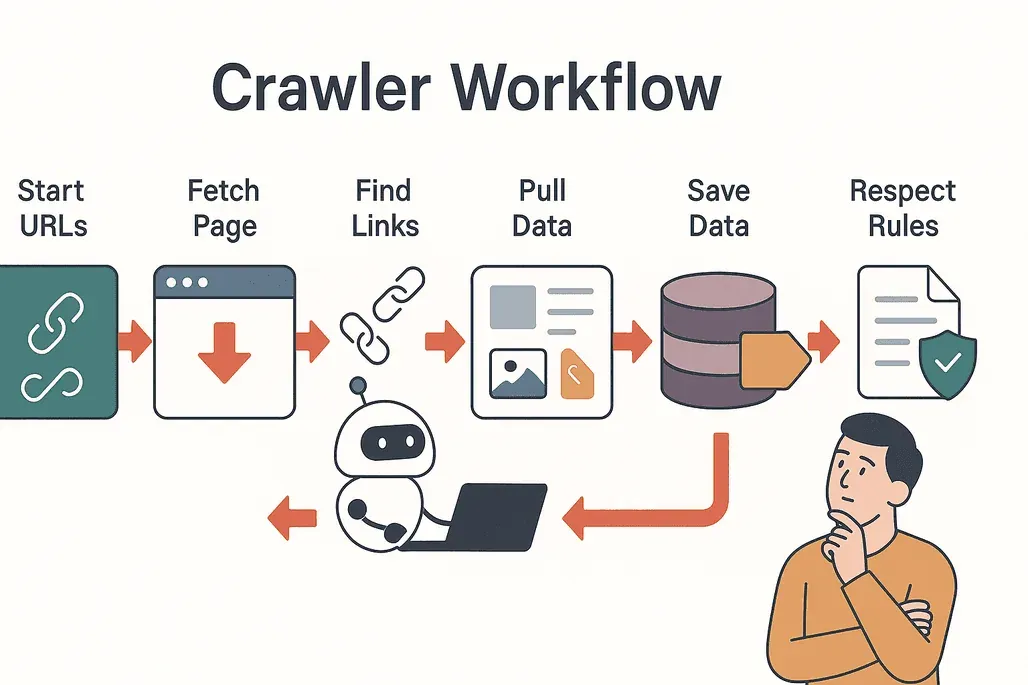 Facciamo chiarezza sul meccanismo. Ecco come lavora di solito un web crawler:
Facciamo chiarezza sul meccanismo. Ecco come lavora di solito un web crawler:
- Si parte dai seed: il crawler comincia da un elenco di URL di partenza.
- Visita e scarica: visita ogni pagina e ne scarica il contenuto.
- Estrae i link: individua tutti i link presenti nella pagina.
- Segue i link: mette in coda i nuovi link non ancora visitati.
- Estrae i dati: le informazioni che servono (testo, immagini, prezzi, ecc.) vengono copiate e strutturate.
- Salva i risultati: i dati finiscono in un database o vengono esportati per l’analisi.
- Rispetta le regole: il crawler controlla il file
robots.txtdi ogni sito per capire cosa è permesso, evitando le aree off-limits (Cloudflare).
Buone pratiche:
- Fai crawling con buona educazione (niente server sovraccaricati).
- Rispetta la privacy e i limiti di legge.
- Evita i contenuti duplicati e le richieste inutili.
Sfide e accortezze quando si usano i web crawler
Il web crawling non è sempre tutto rose e fiori. Ecco qualche ostacolo classico:
- Carico sul server: troppe richieste possono rallentare un sito o mandarlo in crash.
- Contenuti duplicati: i crawler rischiano di rivisitare le stesse pagine o di finire in un loop.
- Privacy e aspetti legali: non tutti i dati sono lì liberi da prendere — controlla sempre i termini di servizio e le leggi sulla privacy.
- Barriere tecniche: certi siti usano CAPTCHA, contenuti dinamici o misure anti-bot per sbarrare la strada ai crawler (DEV Community).
Consigli per riuscirci:
- Tieni ritmi di crawling rispettosi.
- Sta’ attento ai cambiamenti nella struttura dei siti.
- Resta aggiornato sulle norme di protezione dei dati.
Thunderbit: i web crawler alla portata di tutti
Ed è qui che la faccenda si fa interessante. Una volta, mettere in piedi un web crawler voleva dire scrivere codice, smanettare con le impostazioni e bruciare ore a risolvere problemi. Con Thunderbit, però, abbiamo ribaltato il copione.
Thunderbit è un’estensione Chrome per il web scraping basata sull’IA, pensata per chi lavora in azienda — niente programmazione richiesta. Ecco cosa la rende diversa:
- Istruzioni in linguaggio naturale: descrivi e basta quali dati ti servono (“Prendi tutti i nomi e i prezzi dei prodotti da questa pagina”) e l’IA di Thunderbit fa il resto.
- Suggerimenti di campi basati su IA: clicca su “AI Suggest Fields” e Thunderbit legge la pagina, proponendoti le colonne migliori da estrarre.
- Scraping delle sottopagine: ti servono più dettagli? Thunderbit può visitare ogni sottopagina (dettagli prodotto, profili LinkedIn) e arricchire da solo il tuo dataset.
- Modelli istantanei: per i siti più gettonati (Amazon, Zillow, Shopify, ecc.) usi i modelli già pronti per estrarre dati con un clic.
- Esportazione semplice: manda i dati direttamente su Excel, Google Sheets, Airtable o Notion — senza passaggi extra.
- Esportazione dati gratuita: scarichi i risultati in CSV o JSON, gratis fino in fondo.
Thunderbit è usato con fiducia da oltre 100.000 utenti in tutto il mondo, dai team di vendita a chi gestisce e-commerce fino ai professionisti dell’immobiliare.
Prova gratis Thunderbit AI Web Scraper
Thunderbit vs. i web crawler tradizionali
Vediamo come se la cava Thunderbit rispetto all’approccio tradizionale:
| Funzionalità | Thunderbit | Crawler tradizionali |
|---|---|---|
| Tempo di configurazione | 2 clic (ci pensa l'IA) | Ore/giorni (configurazione manuale, codice) |
| Competenze tecniche richieste | Nessuna (istruzioni in inglese semplice) | Elevate (codice, selettori, scripting) |
| Flessibilità | Funziona su qualsiasi sito, si adatta ai cambiamenti | Si rompe quando cambia il layout |
| Scraping delle sottopagine | Integrato, senza configurazioni aggiuntive | Richiede scripting manuale |
| Opzioni di esportazione | Excel, Sheets, Airtable, Notion, CSV, JSON | Di solito solo CSV/JSON |
| Manutenzione | L'IA si adatta da sola | Correzioni manuali frequenti |
Con Thunderbit non devi essere uno sviluppatore né perdere ore a ritoccare le impostazioni. Ti basta puntare, cliccare e lasciare il lavoro pesante all’IA (Thunderbit Blog).
Iniziare a usare i web crawler con Thunderbit
Voglia di provarci? Ecco come partire con Thunderbit in pochi minuti:
- Installa la Thunderbit Chrome Extension.
- Apri il sito web su cui vuoi fare crawling.
- Clicca sull’icona di Thunderbit e premi “AI Suggest Fields.” L’IA ti suggerirà le colonne in base al contenuto della pagina.
- Sistema i campi se serve, poi clicca su “Scrape.” Thunderbit estrarrà i dati, anche dalle sottopagine se vuoi.
- Esporta i risultati su Excel, Google Sheets, Airtable, Notion oppure scaricali in CSV/JSON.
Cos'è il data scraping e come farlo nel 2025 Get Started Free
Tutto qui — niente script, niente codice, niente grattacapi. Che tu stia monitorando prezzi, costruendo una lista di lead o aggregando notizie, Thunderbit rende la maggior parte delle attività quotidiane di web crawling qualcosa che anche chi non è sviluppatore può portare a casa in un pomeriggio.
Conclusione: i web crawler sono la chiave per un accesso ai dati più intelligente
I web crawler sono i motori invisibili che fanno girare il nostro mondo digitale, rendendo le informazioni accessibili, ricercabili e utilizzabili da chiunque. Dai motori di ricerca ai team di vendita, dall’e-commerce all’immobiliare, i crawler sono diventati strumenti irrinunciabili per chiunque abbia bisogno di dati affidabili e aggiornati.
E grazie a strumenti moderni basati sull’IA come Thunderbit, non serve essere programmatori per sfruttarne la potenza. Con pochi clic, chiunque può trasformare il web in una risorsa strutturata e pronta all’uso — dando carburante a decisioni più intelligenti e a nuove opportunità.
Curioso di scoprire cosa possono fare i web crawler per la tua azienda? Scarica Thunderbit e comincia oggi stesso a esplorare i dati nascosti del web. Per altri consigli e approfondimenti, fatti un giro sul Thunderbit Blog.
Prova AI Web Scraper Get Started Free
FAQ
1. Che cos'è esattamente un web crawler?
Un web crawler è un programma automatico (a volte chiamato spider o bot) che gira in modo sistematico per internet, visitando pagine web, seguendo i link e raccogliendo informazioni per l’indicizzazione o l’analisi.
2. Che differenza c'è tra web crawler e web scraper?
I web crawler sono fatti per scoprire e mappare ampie porzioni del web, spesso seguendo i link da una pagina all’altra. I web scraper, invece, si concentrano sull’estrazione di dati specifici da pagine mirate. Molti strumenti moderni (come Thunderbit) mettono insieme entrambe le funzioni.
3. Perché i web crawler sono importanti per le aziende?
I web crawler permettono alle aziende di accedere a informazioni aggiornate su larga scala — che si tratti di tenere d’occhio i prezzi dei concorrenti, aggregare contenuti o costruire liste di lead. Sostengono decisioni in tempo reale e aiutano le aziende a non farsi staccare dalla concorrenza.
4. È legale usare i web crawler?
Il web crawling è in generale legale se lo fai in modo responsabile e nel rispetto dei termini di servizio e delle policy sulla privacy di un sito. Controlla sempre il file robots.txt del sito e rispetta le norme sulla protezione dei dati.
5. In che modo Thunderbit rende il web crawling più semplice?
Thunderbit usa l’IA per automatizzare configurazione, scelta dei campi ed estrazione dei dati. Con le istruzioni in linguaggio naturale e i modelli istantanei, chiunque può fare crawling ed estrarre dati dai siti web — senza bisogno di programmare né di competenze tecniche. I dati si esportano direttamente in Excel, Google Sheets, Airtable o Notion, pronti all’uso.
Scopri di più




