

Il web è pieno di dati, e la voglia di estrarli continua a crescere rapidamente — anche se, se vai a cercare un singolo dato di mercato, troverai stime che possono differire anche di un ordine di grandezza, a seconda che l’analista stia contando software, servizi, proxy o tutti e tre. La lettura più onesta è che il web scraping si è ormai assestato in quell’angolo poco appariscente ma indispensabile dello stack dei dati.
Che tu sia un analista di business, un marketer o semplicemente un principiante curioso, saper estrarre dati da un sito web sta diventando rapidamente una competenza indispensabile. E se sei come me, probabilmente vuoi saltare la solita routine infinita del copia-incolla e arrivare subito alla parte interessante: insight utili, fogli di calcolo ordinati e magari anche un po’ di magia dell’automazione.
Ed è qui che entra in gioco Python. È il coltellino svizzero del mondo dei dati: abbastanza semplice per chi è alle prime armi, ma abbastanza potente da gestire tutto, dall’estrazione di una singola pagina al crawling di migliaia di pagine. In questo tutorial pratico ti guiderò attraverso le basi del web scraping con Python, ti mostrerò come affrontare i siti dinamici e ti presenterò anche Thunderbit, il nostro estrattore web con AI e senza codice che rende l’estrazione dei dati facile come ordinare cibo da asporto. Che tu sia qui per imparare a programmare o solo per trovare una scorciatoia, sei nel posto giusto.
Che cos’è il Web Scraping e perché usare Python per estrarre dati da un sito web?
Estrarre dati da qualsiasi sito web con l’AI Get Started Free
Il web scraping è il processo automatizzato di estrazione di informazioni dai siti web e della loro conversione in un formato strutturato — pensa a fogli di calcolo, CSV o database — per l’analisi o per l’uso aziendale (PromptCloud). Invece di copiare e incollare i dati a mano, un estrattore imita ciò che farebbe una persona, ma a una velocità e su una scala enormemente superiori.
Perché è così prezioso? Perché nel business di oggi, il processo decisionale guidato dai dati è tutto. Più cresci, più decisioni vuoi basare su numeri reali invece che su sensazioni — e molti di quei numeri nascono proprio da una pagina web di qualcun altro.
Immagina di poter monitorare ogni giorno i prezzi dei concorrenti, aggregare annunci immobiliari o creare una lista personalizzata di lead, tutto senza sforzo.
Allora, perché Python? Ecco perché è il linguaggio di riferimento per il web scraping:
- Leggibilità e semplicità: la sintassi di Python è pulita e adatta ai principianti, quindi è facile scrivere e capire gli script di scraping (PromptCloud).
- Ecosistema ricco: librerie come
requests,BeautifulSoup,ScrapyeSeleniumrendono semplici lo scraping, il parsing e l’automazione delle azioni nel browser. - Supporto della community: dato che Python è costantemente tra i linguaggi di programmazione più popolari al mondo, non mancano tutorial, forum ed esempi di codice per aiutarti.
- Scalabilità: Python può gestire tutto, da semplici script usa e getta a crawler su larga scala.
In breve: Python è il tuo biglietto d’ingresso nel mondo dei dati web, che tu sia un principiante assoluto o un analista esperto.
Da dove iniziare: basi del tutorial di Web Scraping con Python
Prima di tuffarci nel codice, vediamo il flusso di lavoro di base per estrarre dati da un sito web con Python:
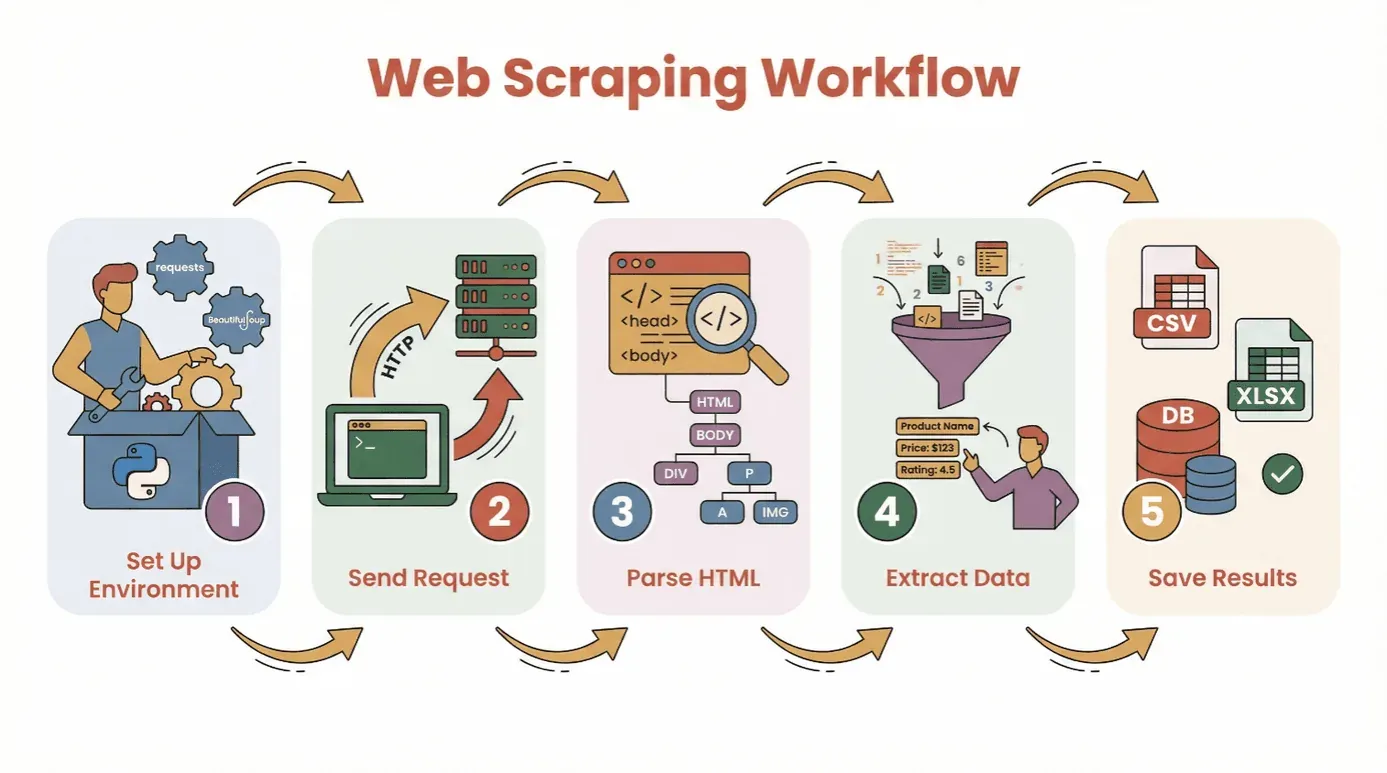
- Configura l’ambiente: installa Python e le librerie necessarie (
requests,BeautifulSoup, ecc.). - Invia una richiesta: usa Python per recuperare il contenuto HTML della pagina web di destinazione.
- Analizza l’HTML: usa un parser per navigare nella struttura della pagina.
- Estrai i dati: individua e recupera le informazioni che ti servono.
- Salva i risultati: memorizza i dati in un CSV, in un file Excel o in un database per l’analisi.
Non serve essere un mago del coding per iniziare. Se sai installare Python ed eseguire uno script, sei già a metà strada. Per chi è alle prime armi, consiglio di usare un ambiente virtuale o un notebook Jupyter, ma va bene anche un semplice editor di testo.
Librerie essenziali:
requests— per recuperare le pagine webBeautifulSoup— per analizzare l’HTMLpandas— per salvare e pulire i dati (opzionale, ma fortemente consigliato)
Scegliere la libreria giusta per il Web Scraping con Python: BeautifulSoup, Scrapy o Selenium?
Non tutti gli strumenti di scraping Python sono uguali. Ecco una rapida panoramica delle tre opzioni più popolari:
| Strumento | Ideale per | Punti di forza | Limiti |
|---|---|---|---|
| BeautifulSoup | Pagine semplici e statiche; principianti | Facile da usare, configurazione minima, documentazione eccellente | Non ideale per crawl di grandi dimensioni o contenuti dinamici |
| Scrapy | Crawling su larga scala, su più pagine | Veloce, asincrono, pipeline integrate, gestisce crawling e archiviazione dati | Curva di apprendimento più ripida, eccessivo per lavori piccoli, non esegue JavaScript |
| Selenium | Siti dinamici o ricchi di JavaScript, automazione | Può renderizzare il JS, simulare azioni dell’utente, supporta login e clic | Più lento, richiede più risorse, configurazione più complessa |
BeautifulSoup: la scelta ideale per il parsing HTML semplice
BeautifulSoup è perfetto per principianti e piccoli progetti. Ti permette di analizzare l’HTML ed estrarre elementi con poche righe di codice. Se il sito di destinazione è per lo più statico (senza sofisticati caricamenti JavaScript), BeautifulSoup + requests è tutto ciò che ti serve.
Esempio:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
print(titles)
Quando usarlo: estrazioni una tantum, blog semplici, pagine prodotto o directory.
Scrapy: per crawling strutturato o su larga scala
Scrapy è un framework completo per eseguire il crawling di interi siti o gestire migliaia di pagine. È asincrono (cioè veloce), supporta pipeline per pulire/salvare i dati e può seguire i link automaticamente.
Esempio:
import scrapy
class ProductSpider(scrapy.Spider):
name = "products"
start_urls = ["https://example.com/products"]
def parse(self, response):
for item in response.css('div.product'):
yield {
'name': item.css('h2::text').get(),
'price': item.css('span.price::text').get()
}
Quando usarlo: progetti grandi, crawl pianificati o quando ti servono velocità e struttura.
Selenium: gestire siti dinamici e ricchi di JavaScript
Selenium controlla un browser reale (come Chrome o Firefox), quindi può gestire siti che caricano dati con JavaScript, richiedono il login o necessitano di clic sui pulsanti.
Esempio:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
driver.find_element(By.NAME, "username").send_keys("myuser")
driver.find_element(By.NAME, "password").send_keys("mypassword")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
dashboard = driver.find_element(By.ID, "dashboard").text
print(dashboard)
driver.quit()
Quando usarlo: social media, siti finanziari, infinite scroll o qualsiasi pagina che sembri vuota quando fai “Visualizza sorgente”.
Passo dopo passo: come estrarre dati da un sito web usando Python (tutorial per principianti)
Vediamo un esempio reale usando requests e BeautifulSoup. Estrarremo da un semplice sito di libri titoli, autori e prezzi.
Passo 1: configurare l’ambiente Python
Per prima cosa, installa le librerie di cui hai bisogno:
pip install requests beautifulsoup4 pandas
Poi importale nel tuo script:
import requests
from bs4 import BeautifulSoup
import pandas as pd
Passo 2: inviare una richiesta al sito web
Recupera il contenuto HTML:
url = "http://books.toscrape.com/catalogue/page-1.html"
response = requests.get(url)
if response.status_code == 200:
html = response.text
else:
print(f"Impossibile recuperare la pagina: {response.status_code}")
Passo 3: analizzare il contenuto HTML
Crea un oggetto BeautifulSoup:
soup = BeautifulSoup(html, 'html.parser')
Trova tutti i contenitori dei libri:
books = soup.find_all('article', class_='product_pod')
print(f"Trovati {len(books)} libri in questa pagina.")
Passo 4: estrarre i dati necessari
Scorri ogni libro e recupera i dettagli:
data = []
for book in books:
title = book.h3.a['title']
price = book.find('p', class_='price_color').text
data.append({"Titolo": title, "Prezzo": price})
Passo 5: salvare i dati per l’analisi
Converti in un DataFrame e salva:
df = pd.DataFrame(data)
df.to_csv('books.csv', index=False)
Ora hai un file CSV pulito, pronto per l’analisi!
Consigli per la risoluzione dei problemi:
- Se ottieni risultati vuoti, controlla se i dati vengono caricati da JavaScript (vedi la sezione successiva).
- Ispeziona sempre la struttura HTML con gli strumenti di sviluppo del browser.
- Gestisci i dati mancanti con
get_text(strip=True)e controlli condizionali.
Superare i contenuti dinamici: estrarre dati da siti renderizzati in JavaScript
I siti moderni amano JavaScript. A volte i dati che cerchi non sono nell’HTML iniziale, ma vengono caricati dopo la comparsa della pagina. Se il tuo estrattore restituisce risultati vuoti, potresti avere a che fare con contenuti dinamici.
Come gestirli:
- Selenium: simula un browser reale, attende il caricamento dei contenuti e può cliccare pulsanti o scorrere la pagina.
- Playwright/Puppeteer: più avanzati, ma con un’idea simile (browser headless).
Mini guida a Selenium:
- Installa Selenium e un driver del browser (ad esempio ChromeDriver).
- Usa attese esplicite per dare il tempo ai contenuti di caricarsi.
- Estrai l’HTML renderizzato e, se necessario, analizzalo con BeautifulSoup.
Esempio:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com/dynamic")
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# Estrai i dati come prima
driver.quit()
Quando serve Selenium?
- Se
requests.get()restituisce HTML senza dati, ma nel browser li vedi. - Se il sito usa infinite scroll, popup o richiede il login.
Semplificare il Web Scraping con l’AI: usare Thunderbit per estrarre dati da un sito web
Prova Thunderbit AI Web Scraper Estrarre dati da qualsiasi sito web in 2 clic: non serve codice. Get Started Free
Diciamolo chiaramente: a volte vuoi solo i dati, non il codice. Ed è qui che entra in gioco Thunderbit. Thunderbit è un’estensione Chrome con AI che ti permette di estrarre dati da qualsiasi sito web in pochi clic, senza bisogno di Python.
Come funziona Thunderbit:
- Installa l’estensione Chrome di Thunderbit.
- Apri il sito web di destinazione.
- Fai clic sull’icona di Thunderbit e premi “AI Suggerisci Campi”. L’AI di Thunderbit analizza la pagina e ti suggerisce quali dati estrarre (per esempio nomi dei prodotti, prezzi, email).
- Modifica i campi se necessario, poi fai clic su “Estrai”.
- Esporta i dati direttamente in Excel, Google Sheets, Notion o Airtable.
Perché Thunderbit è fantastico:
- Non serve programmare. Anche mia madre potrebbe usarlo (e ancora oggi mi chiama per i problemi del Wi‑Fi).
- Gestisce sottopagine e paginazione. Devi estrarre dettagli di prodotti da più pagine? Thunderbit può navigare tra le pagine e unire i dati per te.
- Istruzioni in linguaggio naturale. Basta dirgli cosa vuoi (“estrai tutti i titoli e i prezzi dei prodotti”) e lasciare che l’AI ci pensi.
- Template istantanei per i siti più popolari. Amazon, Zillow, LinkedIn e altri ancora: un clic e hai finito.
- Esportazione gratuita dei dati. Scarica in CSV, Excel oppure invia tutto direttamente ai tuoi strumenti preferiti.
Thunderbit è usato da oltre 100.000 utenti in tutto il mondo. Esiste un piano gratuito che puoi provare senza pagare nulla — consulta la pagina dei prezzi per vedere l’allocazione attuale, perché i limiti sono cambiati un paio di volte. Per chi lavora in azienda è un grande risparmio di tempo; per chi usa Python, è un modo utile per valutare un progetto prima di decidere se vale la pena scrivere un estrattore personalizzato.
Prova Thunderbit gratis – non serve codice
Dopo l’estrazione: pulire e analizzare i dati con Pandas e NumPy
Estrarre i dati è solo il primo passo. I dati web grezzi sono spesso disordinati: duplicati, valori mancanti, formati strani. È qui che brillano le librerie pandas e NumPy di Python.
Attività comuni di pulizia:
- Rimuovere i duplicati:
df.drop_duplicates(inplace=True) - Gestire i valori mancanti:
df.fillna('Sconosciuto')oppuredf.dropna() - Convertire i tipi di dato:
df['Price'] = df['Price'].str.replace('$','').astype(float) - Analizzare le date:
df['Date'] = pd.to_datetime(df['Date']) - Filtrare gli outlier:
df = df[df['Price'] > 0]
Analisi di base:
- Statistiche riassuntive:
df.describe() - Raggruppare per categoria:
df.groupby('Category')['Price'].mean() - Grafici rapidi:
df['Price'].hist()oppuredf.groupby('Category')['Price'].mean().plot(kind='bar')
Per matematica più avanzata o operazioni rapide su array, NumPy è il tuo alleato. Ma per la maggior parte degli utenti business, pandas copre il 95% di ciò che serve.
Risorse: se sei nuovo a pandas, dai un’occhiata alla guida 10 Minutes to pandas.
Best practice e consigli per un Web Scraping con Python di successo
Il web scraping è potente, ma comporta anche responsabilità. Ecco la mia checklist per fare scraping da professionisti (e non farsi bloccare o denunciare):
- Rispetta robots.txt e i Termini di servizio. Controlla sempre se il sito consente lo scraping (PromptCloud).
- Non sovraccaricare i server. Inserisci pause tra le richieste (
time.sleep(2)) ed esegui lo scraping a una velocità simile a quella umana. - Usa header realistici. Imposta una stringa User-Agent per imitare un browser.
- Gestisci gli errori con eleganza. Usa blocchi try/except e ritenta le richieste fallite.
- Ruota i proxy se necessario. Per lo scraping su larga scala, valuta pool di proxy per evitare il blocco degli IP.
- Sii etico e legale. Non estrarre dati personali o contenuti protetti da login senza autorizzazione.
- Documenta il processo. Tieni traccia di cosa hai estratto, da dove e quando.
- Usa le API ufficiali quando disponibili. A volte c’è un modo migliore dell’estrazione dell’HTML.
Per altri consigli, consulta la Guida definitiva al Web Scraping.
Conclusione e punti chiave
Il web scraping con Python è un superpotere per chiunque voglia trasformare il caos del web in dati strutturati e utili all’azione. Che tu stia usando codice (con requests, BeautifulSoup, Scrapy o Selenium) oppure uno strumento no-code come Thunderbit, hai gli strumenti per estrarre dati da un sito web e ricavarne nuove informazioni.
Ricorda:
- Inizia in piccolo: estrai una sola pagina prima di affrontare progetti grandi.
- Scegli lo strumento giusto per le tue esigenze (BeautifulSoup per le basi, Scrapy per la scala, Selenium per i siti dinamici, Thunderbit per il no-code).
- Pulisci e analizza i dati con pandas e NumPy.
- Esegui sempre lo scraping in modo responsabile ed etico.
Pronto a provarci? Parti con un piccolo progetto — magari estrai i titoli di oggi o un elenco di prodotti — e vedi quanto velocemente riesci a passare da una pagina web grezza a un foglio di calcolo pulito. E se vuoi saltare il codice, scarica Thunderbit e lascia che sia l’AI a fare il lavoro pesante.
Per altri tutorial, consigli e approfondimenti sul web scraping, visita il Thunderbit Blog.
Leggi altri tutorial sul Web Scraping
FAQ
1. Che cos’è il web scraping e perché Python è così popolare per farlo?
Il web scraping è l’estrazione automatizzata di dati dai siti web. Python è popolare per il web scraping grazie alla sua sintassi leggibile, alle librerie potenti (come BeautifulSoup, Scrapy e Selenium) e al forte supporto della community (PromptCloud).
2. Quale libreria Python dovrei usare per il web scraping?
Usa BeautifulSoup per pagine semplici e statiche; Scrapy per crawling su larga scala o su più pagine; Selenium per siti dinamici o ricchi di JavaScript. Ognuna ha i suoi punti di forza, a seconda delle tue esigenze (IPRoyal).
3. Come gestisco i siti che caricano dati con JavaScript?
Per contenuti renderizzati in JavaScript, usa Selenium (o Playwright) per simulare un browser e attendere il caricamento dei contenuti prima di estrarre i dati. A volte puoi trovare un endpoint API sottostante ispezionando il traffico di rete.
4. Che cos’è Thunderbit e come semplifica il web scraping?
Thunderbit è un’estensione Chrome con AI che ti permette di estrarre dati da qualsiasi sito web senza programmare. Usa l’AI per suggerire i campi, gestire sottopagine e paginazione, ed esporta i dati direttamente in Excel, Google Sheets, Notion o Airtable.
5. Come posso pulire e analizzare i dati estratti in Python?
Usa pandas per rimuovere duplicati, gestire valori mancanti, convertire i tipi di dato ed eseguire analisi. NumPy è ottimo per le operazioni numeriche. Per la visualizzazione, pandas si integra con Matplotlib per grafici rapidi (10 Minutes to pandas).
Buon scraping — e che i tuoi dati siano sempre puliti, strutturati e pronti all’uso.
Prova AI Web Scraper Get Started Free
Scopri di più




