
Il web si espande a una velocità che lascia davvero a bocca aperta. Nel 2024, stiamo parlando di oltre 1,1 miliardi di siti web, con 149 zettabyte di dati che circolano online (e si prevede che arriveranno a 181 ZB già l’anno prossimo). Una quantità enorme, tipo un’infinità di menù di pizzerie! Ma ecco la sorpresa: solo circa il 4% dei contenuti online è indicizzato dai motori di ricerca. Tutto il resto è il cosiddetto “deep web”, invisibile alle ricerche di tutti i giorni. Quindi, come fanno motori di ricerca e aziende a orientarsi in questa giungla digitale? Qui entrano in scena i web crawler.
In questa guida ti spiego cos’è il web crawling, come funziona e perché è fondamentale—non solo per chi lavora nell’IT, ma per chiunque voglia sfruttare al massimo i dati online. Vedremo anche la differenza tra web crawling e web scraping (spesso confusi, ma sono due cose diverse), casi d’uso reali e soluzioni sia con codice che senza (incluso il mio preferito, Thunderbit). Che tu sia un curioso alle prime armi o un professionista che vuole ottenere di più dal web, sei nel posto giusto.
Cos’è un Web Crawler? Le Basi del Web Crawling
Partiamo dalle basi. Un web crawler (chiamato anche spider, bot o crawler di siti) è un programma automatico che esplora il web in modo sistematico, visitando pagine e seguendo i link per scoprire nuovi contenuti. Immagina un bibliotecario robot che parte da una lista di libri (URL), li legge uno a uno e poi segue ogni riferimento per trovare altri libri. Ecco, il crawler fa proprio questo—ma con le pagine web, e la “biblioteca” è tutto internet.
Il concetto chiave è:
- Si parte da una lista di URL (i cosiddetti “seed”)
- Si visita ogni pagina, scaricando il contenuto (HTML, immagini, ecc.)
- Si cercano i link presenti nelle pagine e si aggiungono alla coda
- Si ripete—si visitano i nuovi link, si scoprono altre pagine, e così via
Il compito principale di un web crawler è scoprire e catalogare le pagine. Nei motori di ricerca, i crawler copiano i contenuti delle pagine e li inviano per l’indicizzazione e l’analisi. In altri casi, crawler specializzati possono estrarre dati specifici (qui entra in gioco il web scraping, ma ne parliamo tra poco).
Da ricordare:
Il web crawling serve a mappare e scoprire il web, non solo a raccogliere dati. È la base che permette a Google, Bing e simili di sapere cosa c’è online.
Come Funziona un Motore di Ricerca? Il Ruolo dei Crawler
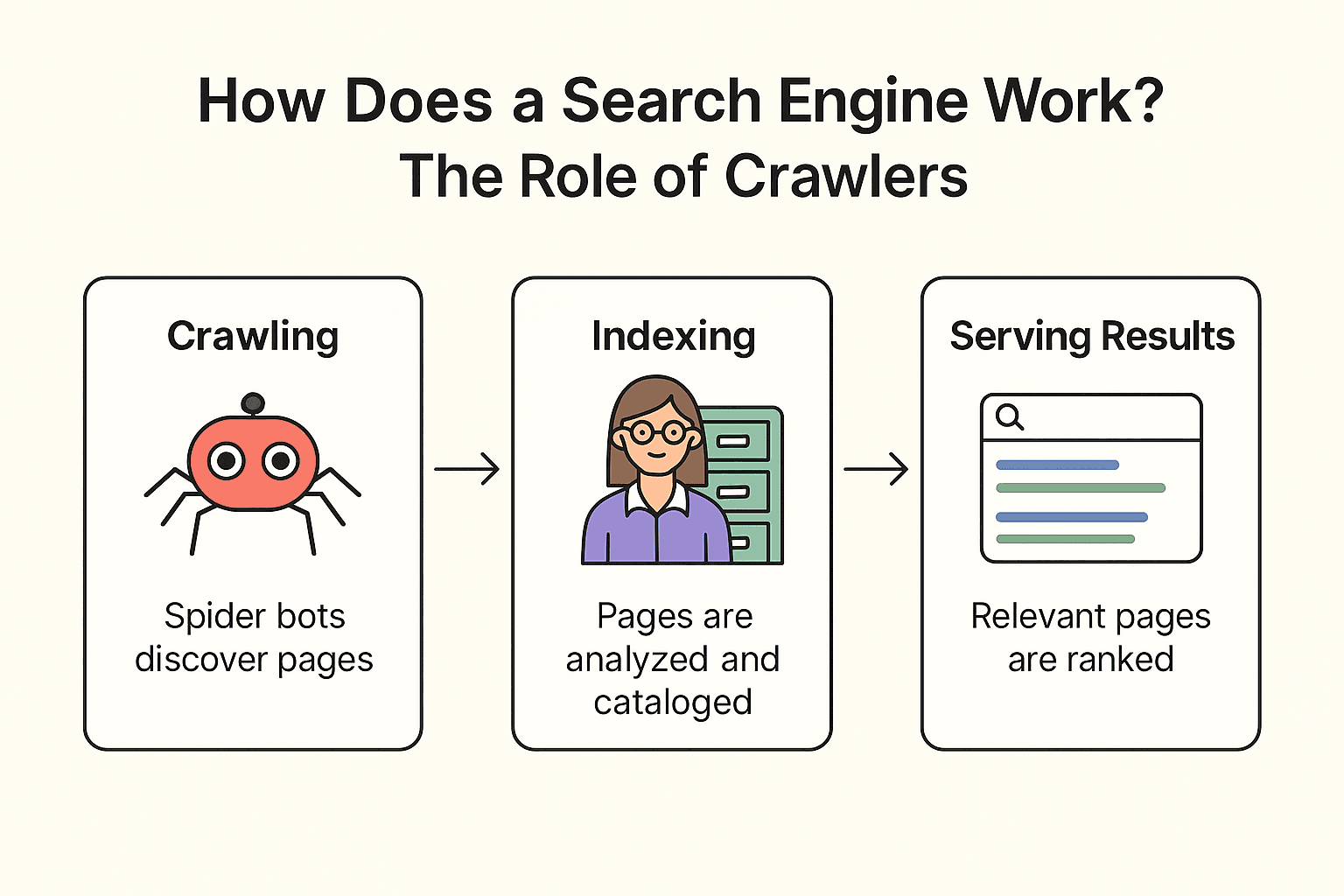
Ma come funziona davvero Google (o Bing, o DuckDuckGo)? Il processo si divide in tre fasi: crawling, indicizzazione e restituzione dei risultati (documentazione ufficiale di Google).
Facciamo un paragone con una biblioteca (perché le metafore sui libri non stancano mai):
-
Crawling:
Il motore di ricerca manda i suoi “spider bot” (come Googlebot) a esplorare il web. Partono da pagine già conosciute, ne scaricano il contenuto e seguono i link per scoprire nuove pagine—proprio come un bibliotecario che controlla ogni scaffale e segue i riferimenti per trovare altri libri.
-
Indicizzazione:
Una volta trovata una pagina, il motore di ricerca ne analizza il contenuto, capisce di cosa parla e salva le informazioni chiave in un enorme catalogo digitale (l’indice). Non tutte le pagine vengono incluse—alcune vengono saltate se bloccate, di bassa qualità o duplicate.
-
Restituzione dei Risultati:
Quando cerchi “migliore pizzeria vicino a me”, il motore di ricerca consulta le pagine più rilevanti nel suo indice e le ordina in base a centinaia di fattori (parole chiave, popolarità, aggiornamento). Il risultato? Un elenco ordinato di pagine web, pronto da consultare.
Curiosità:
I motori di ricerca non esplorano ogni singola pagina del web. Le pagine dietro login, bloccate da robots.txt o senza link in entrata potrebbero non essere mai scoperte. Ecco perché le aziende spesso inviano direttamente a Google i propri URL o sitemap.
Web Crawling vs. Web Scraping: Qual è la Differenza?
Qui spesso si fa confusione. Molti usano “web crawling” e “web scraping” come sinonimi, ma sono due attività distinte.
| Aspetto | Web Crawling (Spidering) | Web Scraping |
|---|---|---|
| Obiettivo | Scoprire e indicizzare il maggior numero di pagine possibile | Estrarre dati specifici da una o più pagine web |
| Analogia | Bibliotecario che cataloga tutti i libri di una biblioteca | Studente che prende appunti da alcuni libri selezionati |
| Risultato | Elenco di URL o contenuti di pagine (per l’indicizzazione) | Dataset strutturato (CSV, Excel, JSON) con le informazioni desiderate |
| Utilizzato da | Motori di ricerca, SEO, archiviatori web | Team commerciali, marketing, ricerca, ecc. |
| Scala | Enorme (milioni/miliardi di pagine) | Mirata (decine, centinaia o migliaia di pagine) |
Guarda qui un confronto visivo.
In parole semplici:
- Web crawling serve a trovare le pagine (mappare il web)
- Web scraping serve a estrarre i dati che ti interessano da quelle pagine (ad esempio, per un foglio Excel)
La maggior parte delle aziende (soprattutto in ambito commerciale, e-commerce o marketing) è più interessata allo scraping—ottenere dati strutturati per analisi—che al crawling dell’intero web. Il crawling è fondamentale per i motori di ricerca e la scoperta su larga scala, mentre lo scraping è ideale per estrazioni mirate.
Perché Usare un Web Crawler? Applicazioni Pratiche per le Aziende
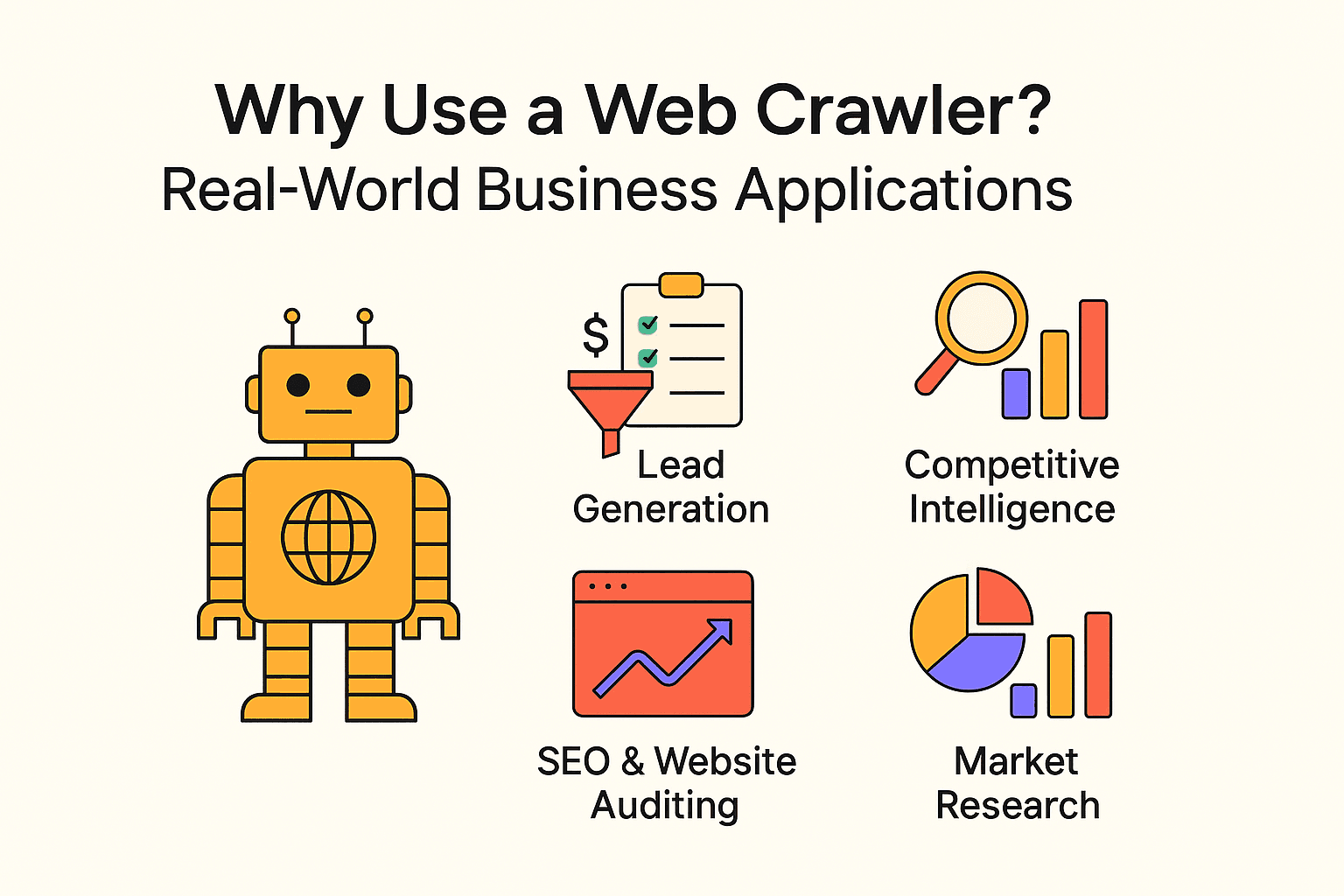
Il web crawling non è solo roba da motori di ricerca. Aziende di ogni dimensione usano crawler ed estrattori per ottenere insight preziosi e automatizzare attività ripetitive. Ecco alcuni esempi concreti:
| Caso d’uso | Destinatari | Beneficio atteso |
|---|---|---|
| Lead Generation | Team commerciali | Automatizzare la ricerca di potenziali clienti, aggiornare il CRM con nuovi contatti |
| Intelligence competitiva | Retail, e-commerce | Monitorare prezzi, disponibilità e novità dei concorrenti |
| SEO & Audit siti web | Marketing, SEO | Individuare link rotti, ottimizzare la struttura del sito |
| Aggregazione di contenuti | Media, ricerca, HR | Raccogliere notizie, offerte di lavoro o dataset pubblici |
| Ricerche di mercato | Analisti, product manager | Analizzare recensioni, trend o sentiment su larga scala |
- Groupon ha raddoppiato i lead in entrata automatizzando la generazione di contatti con il web crawling.
- L’82% delle aziende e-commerce e il 71% delle società finanziarie si affidano al web scraping per prendere decisioni strategiche.
- Il web scraping può ridurre i costi infrastrutturali del 90% e tagliare del 60% i tempi rispetto alla raccolta manuale dei dati.
In sintesi: Se non sfrutti i dati del web, probabilmente lo stanno già facendo i tuoi concorrenti.
Programmare un Web Crawler in Python: Cosa Serve Sapere
Se te la cavi con la programmazione, Python è la scelta ideale per creare crawler personalizzati. La ricetta di base:
- Usa requests per scaricare le pagine web
- Usa BeautifulSoup per analizzare l’HTML ed estrarre link/dati
- Scrivi cicli (o ricorsione) per seguire i link e visitare altre pagine
Vantaggi:
- Massima flessibilità e controllo
- Puoi gestire logiche complesse, flussi personalizzati e integrazione con database
Svantaggi:
- Richiede competenze di programmazione
- Manutenzione: se il sito cambia struttura, lo script potrebbe smettere di funzionare
- Devi gestire da solo blocchi anti-bot, ritardi e gestione degli errori
Esempio semplice di crawler Python:
Ecco uno script che estrae citazioni e autori da quotes.toscrape.com:
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com/page/1/>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
print(f"{text} --- {author}")
Per esplorare più pagine, basta aggiungere la logica per trovare il pulsante “Next” e continuare il ciclo finché ci sono pagine disponibili.
Errori comuni:
- Ignorare robots.txt o i ritardi tra le richieste (non farlo!)
- Essere bloccati da sistemi anti-bot
- Finire in loop infiniti (ad esempio, pagine di calendario senza fine)
Guida Pratica: Come Creare un Web Crawler Semplice in Python
Se vuoi metterti alla prova con il codice, ecco i passaggi base per un crawler elementare.
Passo 1: Configura l’Ambiente Python
Assicurati di avere Python installato. Poi installa le librerie necessarie:
pip install requests beautifulsoup4
Se hai problemi, controlla la versione di Python (python --version) e che pip funzioni correttamente.
Passo 2: Scrivi la Logica Principale del Crawler
Ecco uno schema di base:
import requests
from bs4 import BeautifulSoup
def crawl(url, depth=1, max_depth=2, visited=None):
if visited is None:
visited = set()
if url in visited or depth > max_depth:
return
visited.add(url)
print(f"Crawling: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Estrai i link
for link in soup.find_all('a', href=True):
next_url = link['href']
if next_url.startswith('http'):
crawl(next_url, depth + 1, max_depth, visited)
start_url = "<http://quotes.toscrape.com/>"
crawl(start_url)
Consigli:
- Limita la profondità del crawl per evitare loop infiniti
- Tieni traccia degli URL già visitati
- Rispetta robots.txt e inserisci ritardi (time.sleep(1)) tra le richieste
Passo 3: Estrai e Salva i Dati
Per salvare i dati, puoi scrivere su un file CSV o JSON:
import csv
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Citazione', 'Autore'])
# All’interno del ciclo crawl:
writer.writerow([text, author])
Oppure usa il modulo json di Python per l’output in JSON.
Cosa Considerare e Buone Pratiche per il Web Crawling
Il web crawling è uno strumento potente, ma va usato con responsabilità (e occhio a non farsi bloccare l’IP). Ecco alcune regole d’oro:
- Rispetta il robots.txt: Controlla sempre e segui le regole del file robots.txt del sito. Indica cosa non puoi esplorare.
- Procedi con calma: Inserisci ritardi tra le richieste (almeno qualche secondo). Non sovraccaricare i server.
- Limita il campo d’azione: Esplora solo ciò che ti serve. Imposta limiti di profondità e dominio.
- Identificati: Usa una stringa User-Agent descrittiva.
- Rispetta la legge: Non estrarre dati privati o sensibili. Limita l’attività ai dati pubblici.
- Agisci in modo etico: Non copiare interi siti né usare i dati per spam.
- Testa con cautela: Parti con un piccolo test, poi amplia se tutto funziona.
Per approfondire, leggi questa guida alle best practice.
Quando Scegliere il Web Scraping: Thunderbit per le Aziende
Estrai dati da qualsiasi sito con l’AI Get Started Free
La mia opinione sincera: a meno che tu non debba costruire un motore di ricerca o mappare la struttura completa di un sito, per la maggior parte degli utenti aziendali conviene puntare su strumenti di web scraping.
Qui entra in gioco Thunderbit. Da co-fondatore e CEO, potrei sembrare di parte, ma credo davvero che Thunderbit sia la soluzione più semplice per chi non ha competenze tecniche e vuole estrarre dati dal web.
Perché scegliere Thunderbit?
- Configurazione in due click: Premi “AI Suggerisci Campi” e poi “Estrai”—fatto.
- AI integrata: Thunderbit legge la pagina e suggerisce le colonne migliori da estrarre (nomi prodotti, prezzi, immagini, ecc.).
- Supporto bulk & PDF: Estrai dati da pagine singole, elenchi di URL o anche da PDF.
- Esportazione flessibile: Scarica in CSV/JSON, oppure invia direttamente a Google Sheets, Airtable o Notion.
- Zero codice: Se sai usare un browser, sai usare Thunderbit.
- Estrazione da sottopagine: Vuoi più dettagli? Thunderbit può visitare sottopagine e arricchire i dati in automatico.
- Schedulazione: Imposta estrazioni ricorrenti in linguaggio naturale (es. “ogni lunedì alle 9”).
Prova gratis l’estensione Chrome di Thunderbit
Quando conviene invece un crawler?
Se il tuo obiettivo è mappare un intero sito (ad esempio per creare un indice di ricerca o una sitemap), il crawler è lo strumento giusto. Ma se ti interessa solo estrarre dati strutturati da pagine specifiche (come elenchi prodotti, recensioni o contatti), lo scraping è più veloce, semplice e pratico.
Conclusioni & Punti Chiave
Ricapitolando:
- Il web crawling permette a motori di ricerca e progetti big data di scoprire e mappare il web. È una questione di ampiezza: trovare il maggior numero di pagine possibile.
- Il web scraping punta sulla profondità: estrarre i dati specifici che ti servono da quelle pagine. Per la maggior parte delle aziende, lo scraping è la vera priorità.
- Puoi programmare un crawler da solo (Python è perfetto), ma richiede tempo, competenze e manutenzione.
- Strumenti no-code e AI come Thunderbit rendono l’estrazione dati accessibile a tutti—senza bisogno di programmare.
- Le buone pratiche sono fondamentali: Rispetta sempre le regole dei siti, agisci in modo etico e usa i dati responsabilmente.
Se sei alle prime armi, scegli un progetto semplice—ad esempio estrai i prezzi di alcuni prodotti o raccogli contatti da una directory. Prova uno strumento come Thunderbit per risultati immediati, oppure sperimenta con Python se vuoi imparare i meccanismi di base.
Il web è una miniera d’oro di informazioni. Con il giusto approccio, puoi ottenere insight preziosi, risparmiare tempo e dare una marcia in più al tuo business.
Inizia a estrarre dati con Thunderbit
FAQ
- Qual è la differenza tra web crawling e web scraping?
Il crawling serve a scoprire e mappare le pagine. Lo scraping estrae dati specifici da esse. Crawling = scoperta; scraping = estrazione.
- Il web scraping è legale?
Estrarre dati pubblici di solito è consentito se rispetti robots.txt e i termini d’uso. Evita contenuti privati o protetti da copyright.
- Serve programmare per estrarre dati dai siti?
No. Strumenti come Thunderbit permettono di estrarre dati con pochi click e l’AI—senza scrivere codice.
- Perché Google non indicizza tutto il web?
Perché gran parte dei contenuti è dietro login, paywall o bloccata. Solo circa il 4% è effettivamente indicizzato.
Approfondimenti
- FreeCodeCamp – Web Scraping con Python e BeautifulSoup
- Tutorial ufficiale Scrapy
- Real Python – Come usare Selenium e Python per il Web Scraping
- Apify Academy: Web Scraping e Automazione
Prova Estrattore Web AI Get Started Free




