
Il web è davvero una miniera infinita di dati: non a caso, il mercato globale dei software per l’estrazione dati dai siti web è destinato a toccare i . Che tu sia un data analyst, un marketer o semplicemente curioso di imparare qualcosa di nuovo, saper estrarre dati da un sito web è ormai una skill fondamentale. E se sei come me, probabilmente vuoi saltare la parte noiosa del copia-incolla manuale e arrivare subito al sodo: dati puliti, fogli di calcolo ordinati e magari un po’ di automazione che ti semplifica la vita.
Qui entra in scena Python. È il vero jolly per chi lavora con i dati: facile da imparare per chi parte da zero, ma anche super potente per chi vuole scalare da una singola pagina a interi portali. In questa guida pratica ti spiego le basi del tutorial web scraping con Python, come affrontare i siti dinamici e ti presento anche , il nostro Estrattore Web AI senza codice che rende tutto più semplice di una pizza d’asporto. Che tu voglia imparare a programmare o preferisca una scorciatoia, qui trovi la soluzione giusta.
Cos’è il Web Scraping e Perché Usare Python per Estrarre Dati da un Sito?
Il web scraping è il processo automatico di raccolta di informazioni dai siti web e la loro trasformazione in un formato strutturato—come Excel, CSV o database—per analisi o scopi aziendali (). Invece di copiare e incollare a mano, un estrattore web simula le azioni di un utente, ma a una velocità e una scala che nessuno potrebbe mai raggiungere manualmente.
Perché è così importante? Perché oggi il decision making basato sui dati è la chiave per restare competitivi. Il si affida ai dati (spesso raccolti tramite scraping) per tutto: strategie di prezzo, analisi di mercato, generazione di lead. Immagina di poter monitorare i prezzi dei concorrenti ogni giorno, aggregare annunci immobiliari o creare una lista di potenziali clienti—tutto senza fatica.
Ma perché proprio Python? Ecco perché è la scelta top per chi vuole estrarre dati da un sito web:
- Semplice e leggibile: La sintassi di Python è chiara e immediata, perfetta per chi si avvicina per la prima volta al tutorial web scraping ().
- Ecosistema ricchissimo: Librerie come
requests,BeautifulSoup,ScrapyeSeleniumti permettono di estrarre, analizzare e automatizzare tutto quello che vuoi online. - Comunità enorme: Python è , quindi trovi sempre guide, forum e snippet di codice per ogni problema.
- Scalabile: Funziona sia per piccoli script che per progetti di crawling su larga scala.
In poche parole: Python è il tuo lasciapassare per il mondo dei dati online, sia che tu sia alle prime armi sia che tu sia già un esperto.
Primi Passi: Le Basi del Web Scraping con Python
Prima di vedere il codice, ecco il percorso tipico per estrarre dati da un sito web con Python:
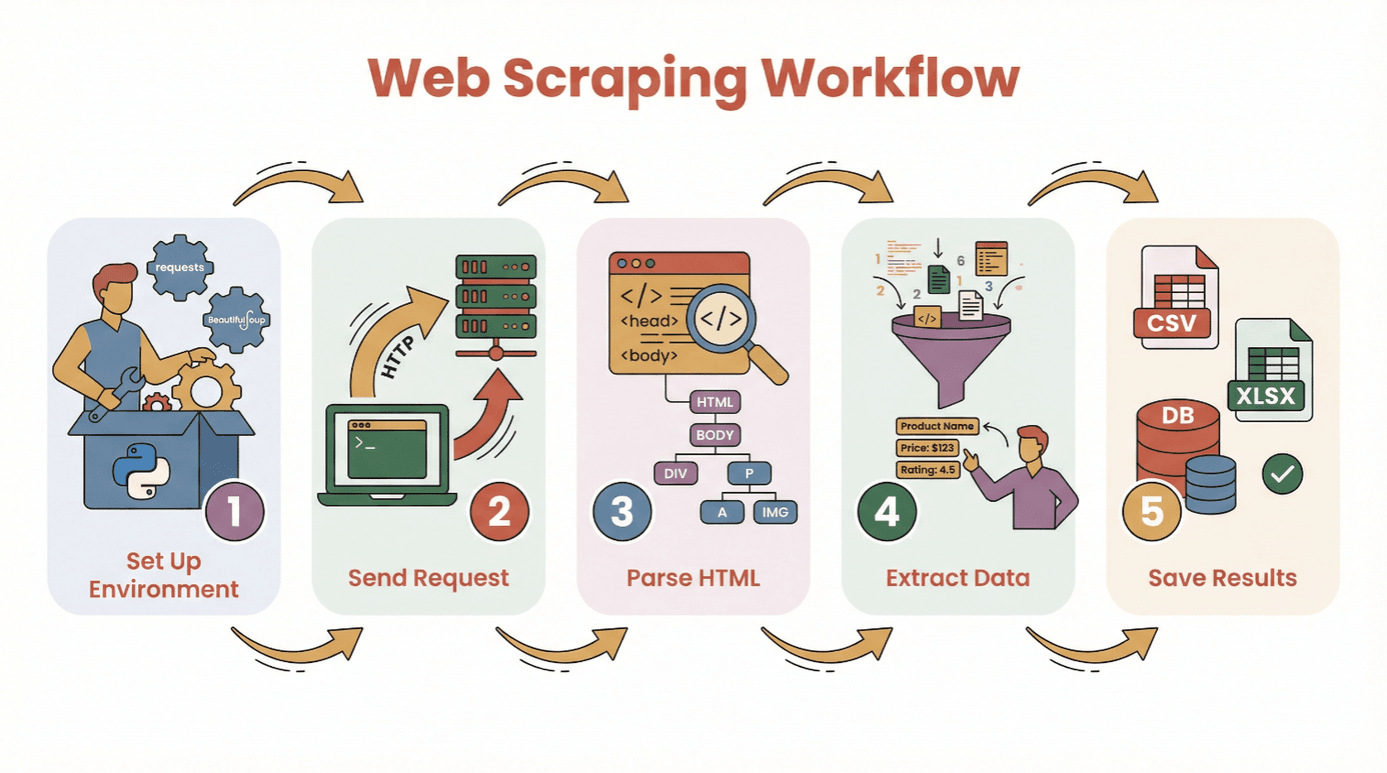
- Prepara l’ambiente: Installa Python e le librerie che ti servono (
requests,BeautifulSoup, ecc.). - Fai una richiesta: Usa Python per scaricare il contenuto HTML della pagina che ti interessa.
- Analizza l’HTML: Naviga nella struttura della pagina con un parser.
- Estrai i dati: Trova e raccogli le informazioni che ti servono.
- Salva i risultati: Esporta tutto in CSV, Excel o database per analisi future.
Non serve essere un programmatore esperto per iniziare. Se sai installare Python e lanciare uno script, sei già a buon punto. Se parti da zero, ti consiglio di usare un o Jupyter notebook, ma va benissimo anche un editor di testo semplice.
Librerie base:
requests— per scaricare le pagine webBeautifulSoup— per analizzare l’HTMLpandas— per pulire e salvare i dati (opzionale, ma super utile)
Scegliere la Libreria Giusta: BeautifulSoup, Scrapy o Selenium?
Non tutti gli strumenti per il tutorial web scraping in Python sono uguali. Ecco una panoramica delle tre soluzioni più usate:
| Strumento | Ideale per | Punti di forza | Limiti |
|---|---|---|---|
| BeautifulSoup | Pagine statiche, progetti semplici | Facile da usare, configurazione minima, ottima documentazione | Non adatto a grandi volumi o contenuti dinamici |
| Scrapy | Crawling su larga scala, più pagine | Veloce, asincrono, pipeline integrate, gestisce crawling e salvataggio dati | Curva di apprendimento più ripida, eccessivo per lavori piccoli, no JS |
| Selenium | Siti dinamici/JavaScript, automazione | Gestisce JS, simula azioni utente, supporta login e click | Più lento, consuma risorse, configurazione più complessa |
BeautifulSoup: Perfetto per HTML Semplice
BeautifulSoup è l’ideale per chi inizia e per progetti piccoli. Ti permette di analizzare l’HTML ed estrarre elementi con poche righe di codice. Se il sito che ti interessa è statico (senza caricamenti JavaScript), BeautifulSoup insieme a requests è tutto quello che ti serve.
Esempio:
1import requests
2from bs4 import BeautifulSoup
3url = "https://example.com"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
7print(titles)Quando usarlo: Estrazioni una tantum, blog semplici, pagine prodotto o elenchi.
Scrapy: Per Progetti Complessi o Crawling su Larga Scala
Scrapy è un framework completo per esplorare interi siti o gestire migliaia di pagine. È asincrono (quindi veloce), offre pipeline per pulizia e salvataggio dati e segue i link in automatico.
Esempio:
1import scrapy
2class ProductSpider(scrapy.Spider):
3 name = "products"
4 start_urls = ["https://example.com/products"]
5 def parse(self, response):
6 for item in response.css('div.product'):
7 yield {
8 'name': item.css('h2::text').get(),
9 'price': item.css('span.price::text').get()
10 }Quando usarlo: Progetti grandi, scraping programmato, quando servono velocità e struttura.
Selenium: Per Siti Dinamici e Caricamenti JavaScript
Selenium controlla un vero browser (come Chrome o Firefox), quindi può gestire siti che caricano dati tramite JavaScript, richiedono login o interazioni come click.
Esempio:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3driver = webdriver.Chrome()
4driver.get("https://example.com/login")
5driver.find_element(By.NAME, "username").send_keys("myuser")
6driver.find_element(By.NAME, "password").send_keys("mypassword")
7driver.find_element(By.XPATH, "//button[@type='submit']").click()
8dashboard = driver.find_element(By.ID, "dashboard").text
9print(dashboard)
10driver.quit()Quando usarlo: Social media, siti finanziari, infinite scroll o pagine che sembrano vuote nel sorgente.
Guida Passo Passo: Estrarre Dati da un Sito con Python (Tutorial Base)
Facciamo un esempio pratico con requests e BeautifulSoup. Estrarremo titoli e prezzi da un sito di libri.
Passo 1: Prepara l’Ambiente Python
Installa le librerie necessarie:
1pip install requests beautifulsoup4 pandasPoi importale nello script:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pdPasso 2: Invia una Richiesta al Sito
Scarica il contenuto HTML:
1url = "http://books.toscrape.com/catalogue/page-1.html"
2response = requests.get(url)
3if response.status_code == 200:
4 html = response.text
5else:
6 print(f"Impossibile recuperare la pagina: {response.status_code}")Passo 3: Analizza il Contenuto HTML
Crea un oggetto BeautifulSoup:
1soup = BeautifulSoup(html, 'html.parser')Trova tutti i contenitori dei libri:
1books = soup.find_all('article', class_='product_pod')
2print(f"Trovati {len(books)} libri in questa pagina.")Passo 4: Estrai i Dati che Ti Servono
Cicla su ogni libro e raccogli i dettagli:
1data = []
2for book in books:
3 title = book.h3.a['title']
4 price = book.find('p', class_='price_color').text
5 data.append({"Titolo": title, "Prezzo": price})Passo 5: Salva i Dati per l’Analisi
Converti in DataFrame e salva:
1df = pd.DataFrame(data)
2df.to_csv('books.csv', index=False)Ora hai un file CSV pronto per essere analizzato!
Consigli pratici:
- Se ottieni risultati vuoti, controlla se i dati sono caricati via JavaScript (vedi la sezione successiva).
- Ispeziona sempre la struttura HTML con gli strumenti per sviluppatori del browser.
- Gestisci dati mancanti con
get_text(strip=True)e controlli condizionali.
Come Gestire Contenuti Dinamici: Estrarre Dati da Siti con JavaScript
I siti moderni usano spesso JavaScript. A volte i dati che cerchi non sono nell’HTML iniziale, ma vengono caricati dopo. Se il tuo script non trova nulla, probabilmente sei davanti a contenuti dinamici.
Come affrontarli:
- Selenium: Simula un browser vero, aspetta che i contenuti si carichino e può interagire con la pagina.
- Playwright/Puppeteer: Soluzioni più avanzate, ma simili (browser headless).
Mini guida a Selenium:
- Installa Selenium e il driver del browser (es. ChromeDriver).
- Usa attese esplicite per far caricare i contenuti.
- Estrai l’HTML renderizzato e analizzalo con BeautifulSoup se serve.
Esempio:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.support.ui import WebDriverWait
4from selenium.webdriver.support import expected_conditions as EC
5driver = webdriver.Chrome()
6driver.get("https://example.com/dynamic")
7WebDriverWait(driver, 10).until(
8 EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
9)
10html = driver.page_source
11soup = BeautifulSoup(html, 'html.parser')
12# Estrai i dati come prima
13driver.quit()Quando serve Selenium?
- Se
requests.get()restituisce HTML senza dati, ma li vedi nel browser. - Se il sito usa infinite scroll, popup o richiede login.
Semplificare il Web Scraping con l’AI: Estrarre Dati con Thunderbit
Diciamolo chiaro: a volte vuoi solo i dati, senza scrivere una riga di codice. Qui entra in gioco . Thunderbit è un’estensione Chrome con AI che ti permette di estrarre dati da qualsiasi sito in pochi click—senza Python.
Come funziona Thunderbit:
- Installa la .
- Apri il sito che ti interessa.
- Clicca sull’icona Thunderbit e scegli “AI Suggerisci Campi.” L’AI analizza la pagina e ti propone quali dati estrarre (es. nomi prodotti, prezzi, email).
- Modifica i campi se vuoi, poi clicca su “Estrai.”
- Esporta i dati direttamente su Excel, Google Sheets, Notion o Airtable.
Perché Thunderbit è una bomba:
- Zero codice. È così facile che anche mia madre lo usa (e mi chiama ancora per il Wi-Fi!).
- Gestisce sottopagine e paginazione. Devi estrarre dati da più pagine? Thunderbit naviga e unisce tutto per te.
- Istruzioni in linguaggio naturale. Basta scrivere cosa vuoi (“estrai tutti i titoli e prezzi”) e l’AI fa il resto.
- Template pronti per i siti più usati. Amazon, Zillow, LinkedIn e altri: un click e hai finito.
- Esportazione gratuita dei dati. Scarica in CSV, Excel o invia direttamente ai tuoi strumenti preferiti.
Thunderbit è già scelto da oltre , e il piano gratuito ti permette di estrarre dati da 6 pagine (o 10 con il boost di prova). Per le aziende è un risparmio di tempo enorme—per chi programma, è perfetto per prototipare prima di scrivere uno scraper Python su misura.
Dopo lo Scraping: Pulizia e Analisi dei Dati con Pandas e NumPy
Estrarre i dati è solo il primo passo. I dati grezzi dal web sono spesso un po’ disordinati: duplicati, valori mancanti, formati strani. Qui entrano in gioco le librerie pandas e NumPy di Python.
Operazioni di pulizia tipiche:
- Rimuovere duplicati:
df.drop_duplicates(inplace=True) - Gestire valori mancanti:
df.fillna('Sconosciuto')odf.dropna() - Convertire tipi di dato:
df['Prezzo'] = df['Prezzo'].str.replace('€','').astype(float) - Analizzare date:
df['Data'] = pd.to_datetime(df['Data']) - Filtrare outlier:
df = df[df['Prezzo'] > 0]
Analisi base:
- Statistiche riassuntive:
df.describe() - Raggruppare per categoria:
df.groupby('Categoria')['Prezzo'].mean() - Grafici veloci:
df['Prezzo'].hist()odf.groupby('Categoria')['Prezzo'].mean().plot(kind='bar')
Per operazioni numeriche avanzate o array super veloci, NumPy è il top. Ma per la maggior parte degli utenti business, pandas basta e avanza.
Risorse: Se sei alle prime armi con pandas, dai un’occhiata alla guida .
Best Practice e Consigli per uno Scraping di Successo con Python
Il web scraping è potentissimo, ma va usato con testa. Ecco la mia checklist per lavorare in modo professionale (e senza rischi):
- Rispetta robots.txt e i Termini di Servizio. Controlla sempre se il sito consente lo scraping ().
- Non stressare i server. Metti delle pause tra le richieste (
time.sleep(2)) e simula la navigazione di una persona vera. - Usa header realistici. Imposta uno User-Agent per sembrare un browser vero.
- Gestisci gli errori. Usa try/except e ripeti le richieste che falliscono.
- Ruota i proxy se serve. Per scraping su larga scala, usa pool di proxy per evitare blocchi IP.
- Agisci in modo etico e legale. Non estrarre dati personali o contenuti protetti senza permesso.
- Documenta il processo. Tieni traccia di cosa hai estratto, da dove e quando.
- Usa API ufficiali quando ci sono. A volte è meglio che estrarre HTML.
Per altri consigli, leggi la .
Conclusioni & Cosa Portare a Casa
Fare web scraping con Python è una super skill per chiunque voglia trasformare il caos del web in dati ordinati e utili. Che tu scelga il codice (requests, BeautifulSoup, Scrapy, Selenium) o uno strumento no-code come , hai tutto quello che ti serve per estrarre dati da un sito web e scoprire nuove opportunità.
Ricorda:
- Parti dalle basi—prova a estrarre dati da una sola pagina prima di buttarti su progetti complessi.
- Scegli lo strumento giusto per le tue esigenze (BeautifulSoup per il semplice, Scrapy per la scala, Selenium per siti dinamici, Thunderbit per il no-code).
- Pulisci e analizza i dati con pandas e NumPy.
- Fai scraping sempre in modo responsabile ed etico.
Vuoi provarci subito? Inizia con un piccolo progetto—magari estrai i titoli delle notizie di oggi o una lista di prodotti—e scopri quanto è veloce passare da una pagina web a un foglio Excel ordinato. E se vuoi saltare la programmazione, e lascia che l’AI faccia il lavoro pesante.
Per altre guide, consigli e approfondimenti sul tutorial web scraping, visita il .
Domande Frequenti
1. Cos’è il web scraping e perché Python è così usato?
Il web scraping è l’estrazione automatica di dati dai siti web. Python è popolare per questa attività grazie alla sua sintassi leggibile, alle librerie potenti (come BeautifulSoup, Scrapy e Selenium) e a una comunità molto attiva ().
2. Quale libreria Python dovrei usare per il web scraping?
Usa BeautifulSoup per pagine semplici e statiche; Scrapy per crawling su larga scala o multi-pagina; Selenium per siti dinamici o ricchi di JavaScript. Ogni strumento ha i suoi punti di forza a seconda delle esigenze ().
3. Come gestisco i siti che caricano dati con JavaScript?
Per contenuti generati da JavaScript, usa Selenium (o Playwright) per simulare un browser e attendi che i dati siano caricati prima di estrarli. A volte puoi trovare un endpoint API nascosto analizzando il traffico di rete.
4. Cos’è Thunderbit e come semplifica il web scraping?
è un’estensione Chrome con AI che ti permette di estrarre dati da qualsiasi sito senza scrivere codice. L’AI suggerisce i campi, gestisce sottopagine e paginazione, ed esporta i dati direttamente su Excel, Google Sheets, Notion o Airtable.
5. Come posso pulire e analizzare i dati estratti in Python?
Usa pandas per rimuovere duplicati, gestire valori mancanti, convertire tipi di dato e fare analisi. NumPy è ottimo per operazioni numeriche. Per visualizzare i dati, pandas si integra con Matplotlib per grafici rapidi ().
Buon scraping—che i tuoi dati siano sempre puliti, ordinati e pronti all’uso.
Scopri di più